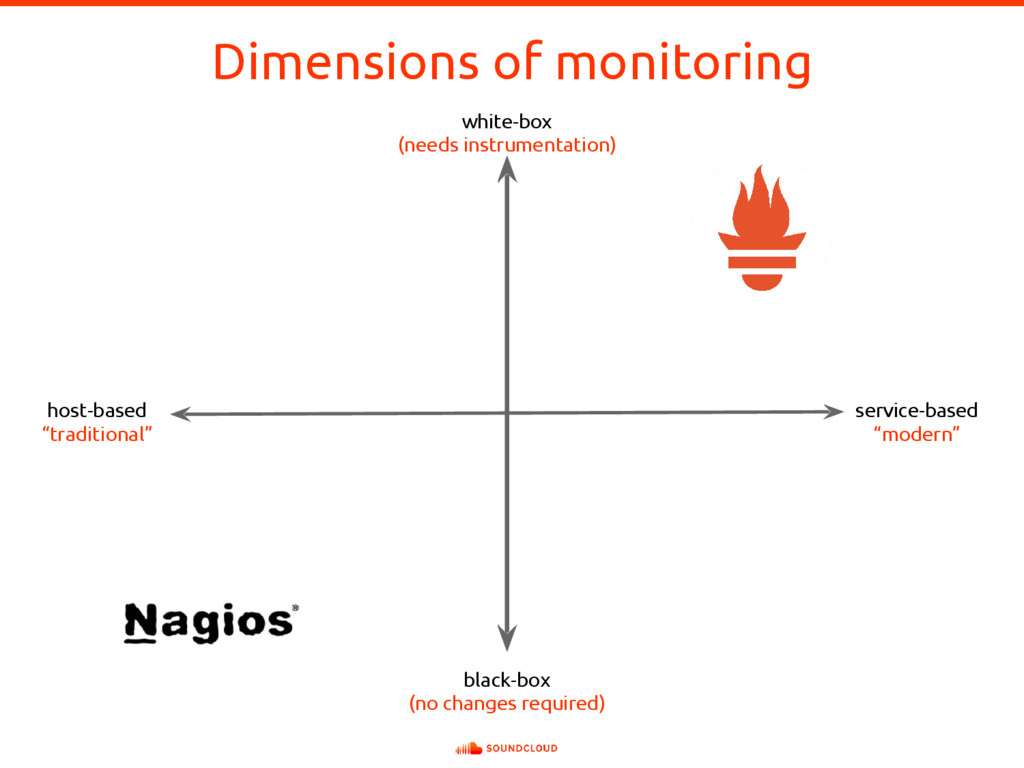
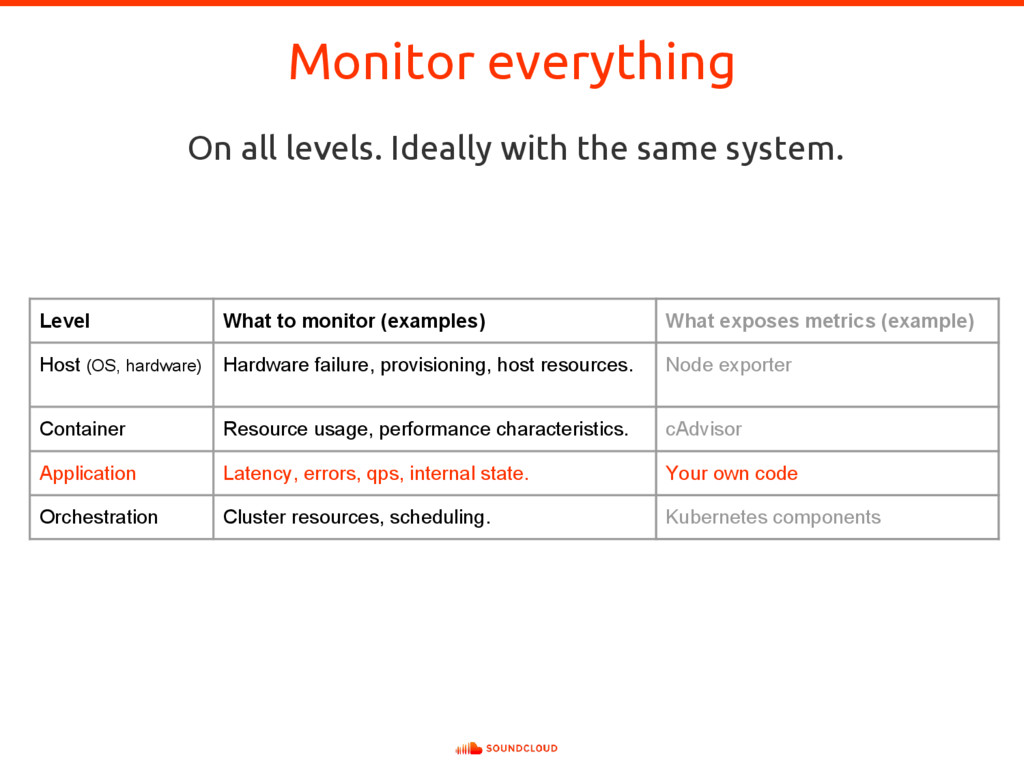
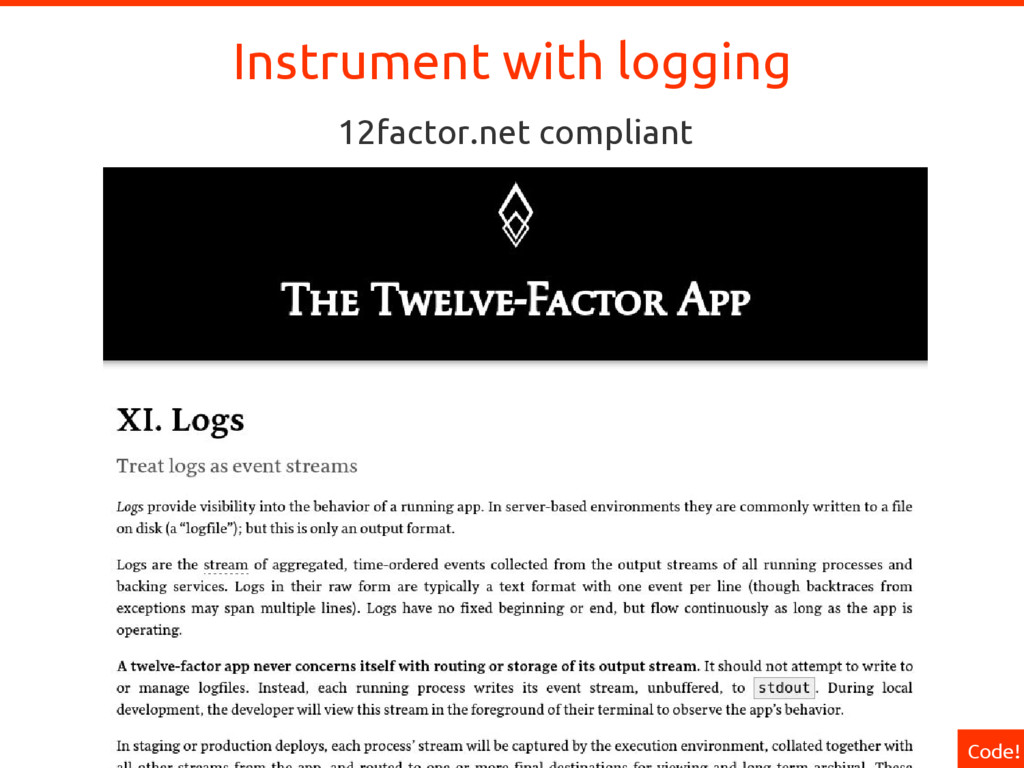
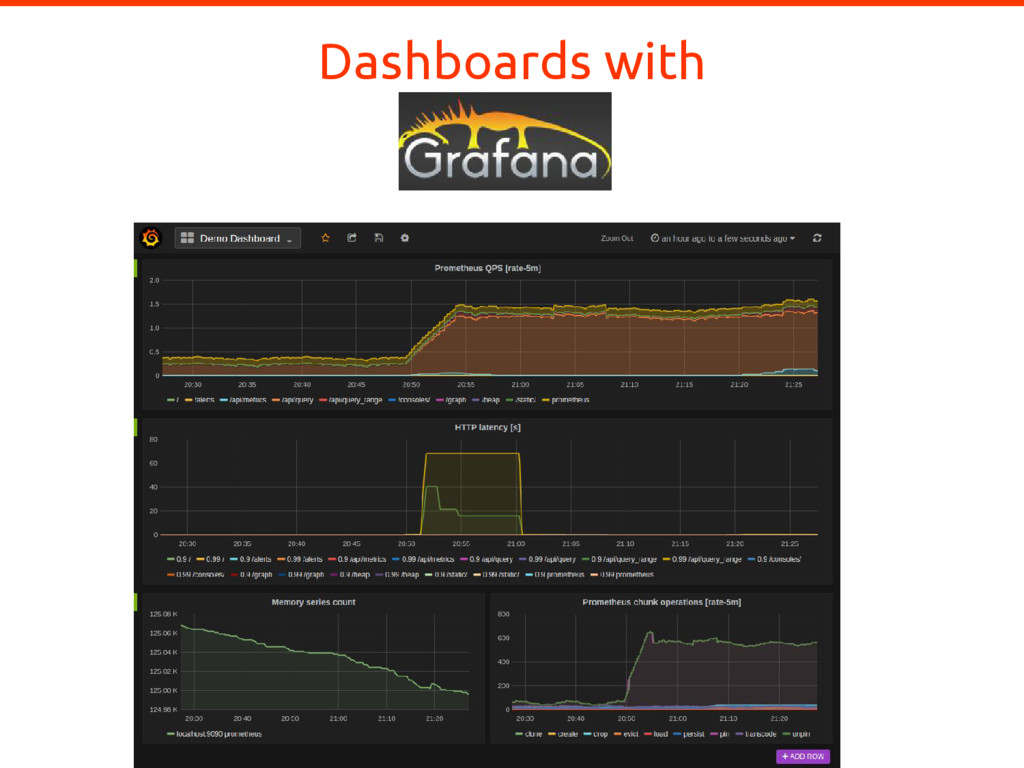
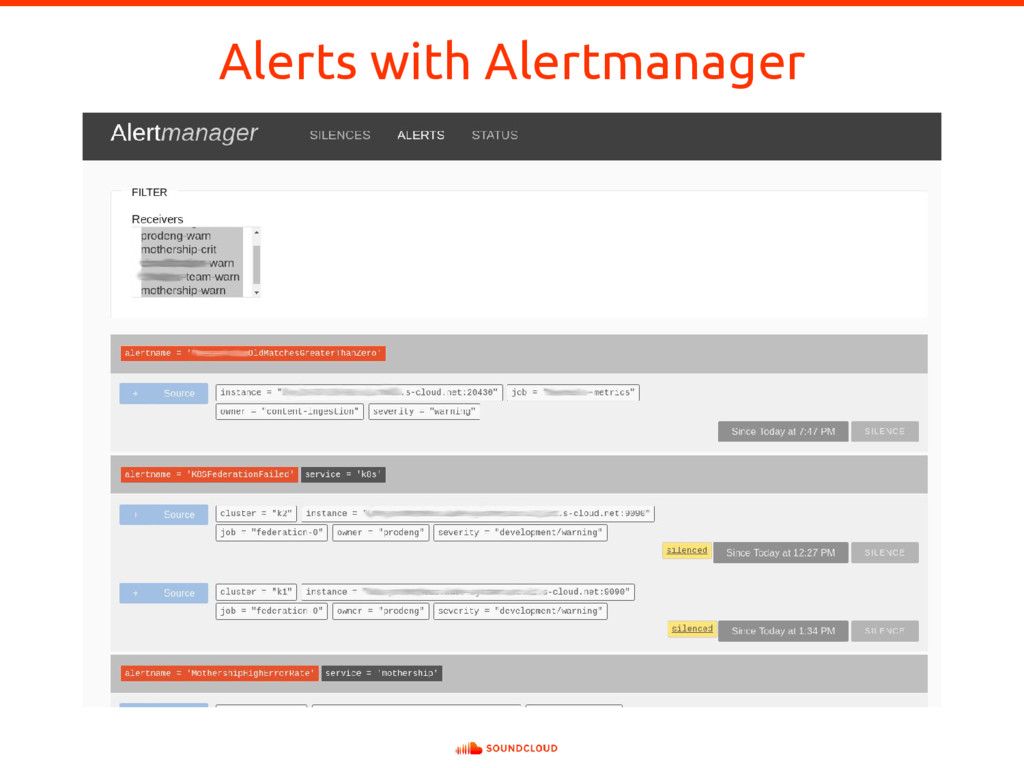
In complex and dynamic distributed systems, instrumenting application code to expose suitable metrics is of paramount importance for meaningful whitebox monitoring. But what are suitable metrics? In which ways are they useful? And how do they differ from logging? Using Prometheus as an example for a next-generation service monitoring system, all those questions will be answered. To put the learned lessons into action, Björn Rabenstein instruments a toy HTTP service on stage.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
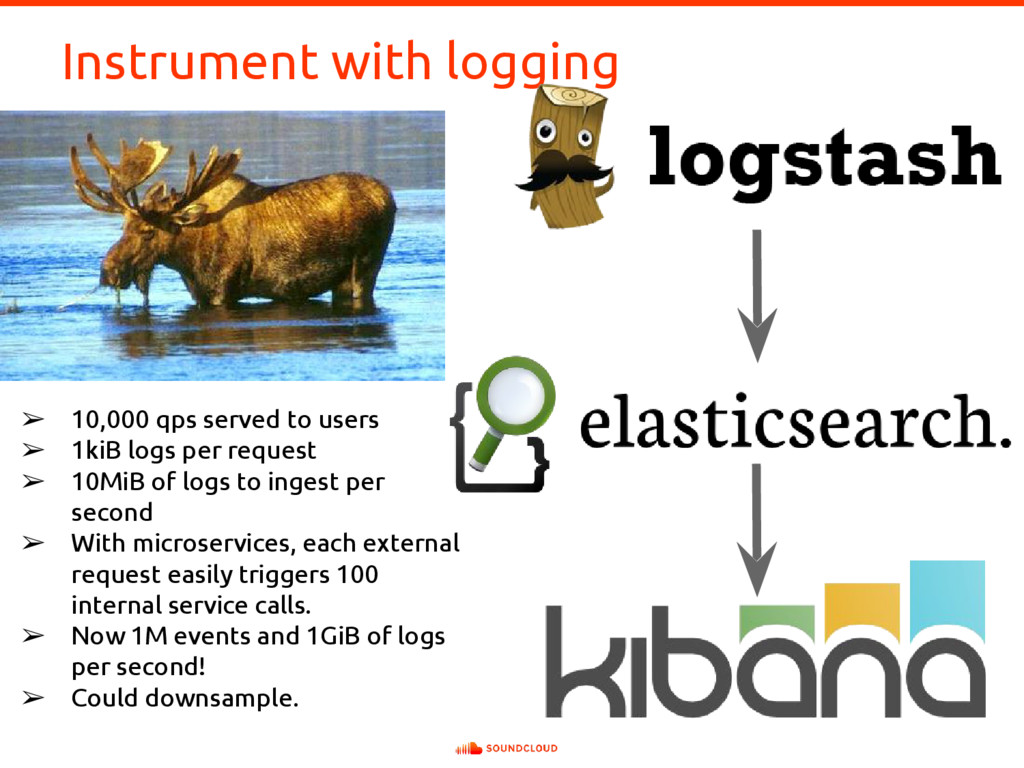{kind=link}
{kind=link}
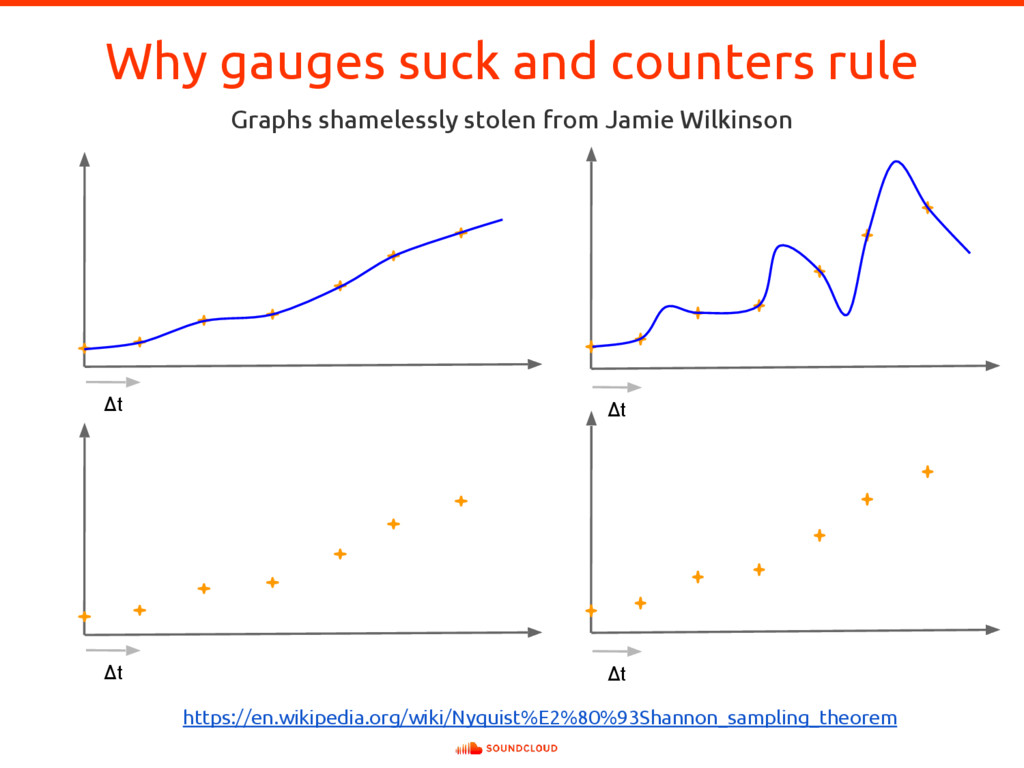{kind=link}
{kind=link}
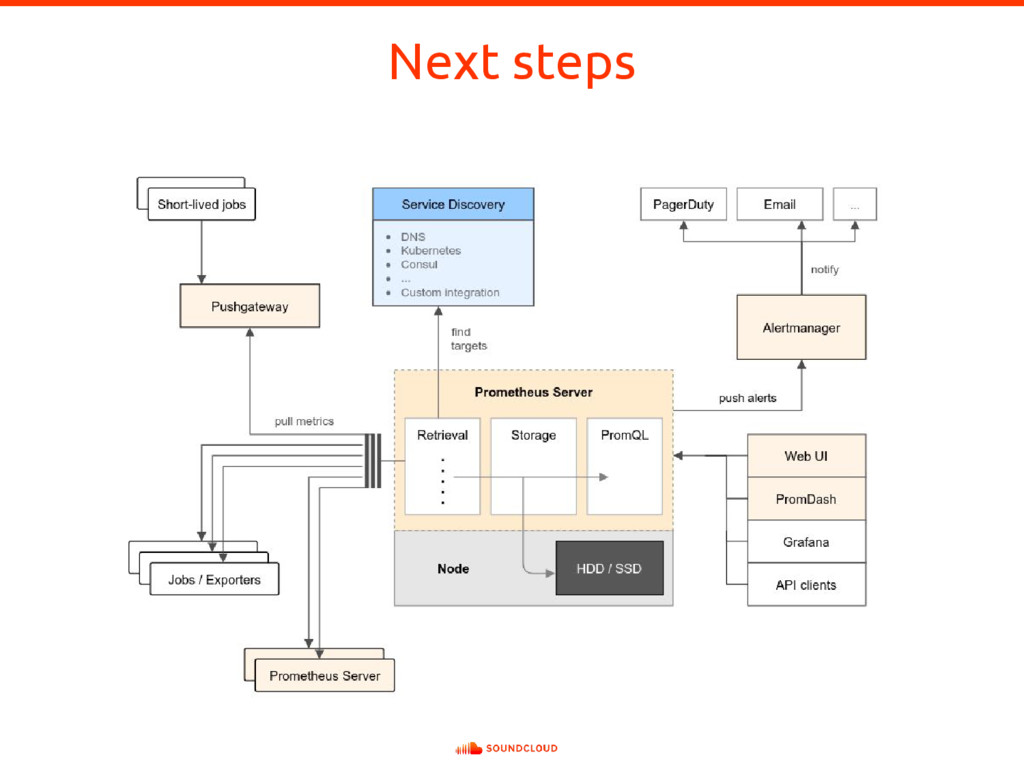{kind=link}
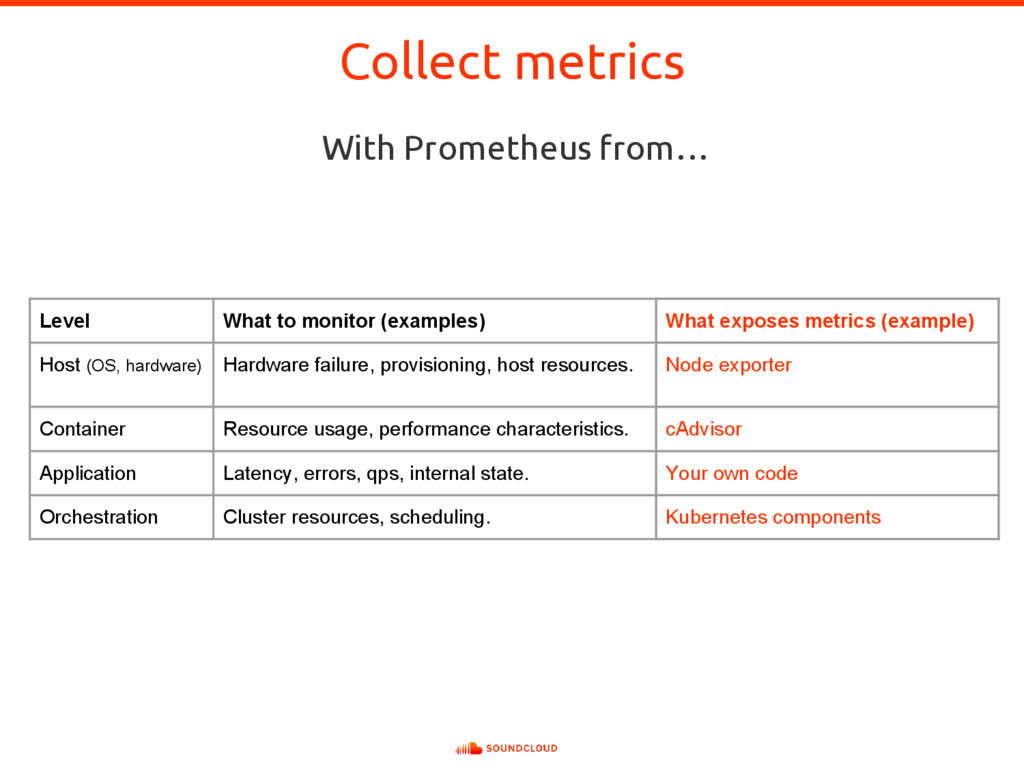{kind=link}
{kind=link}
{kind=link}
{kind=link}