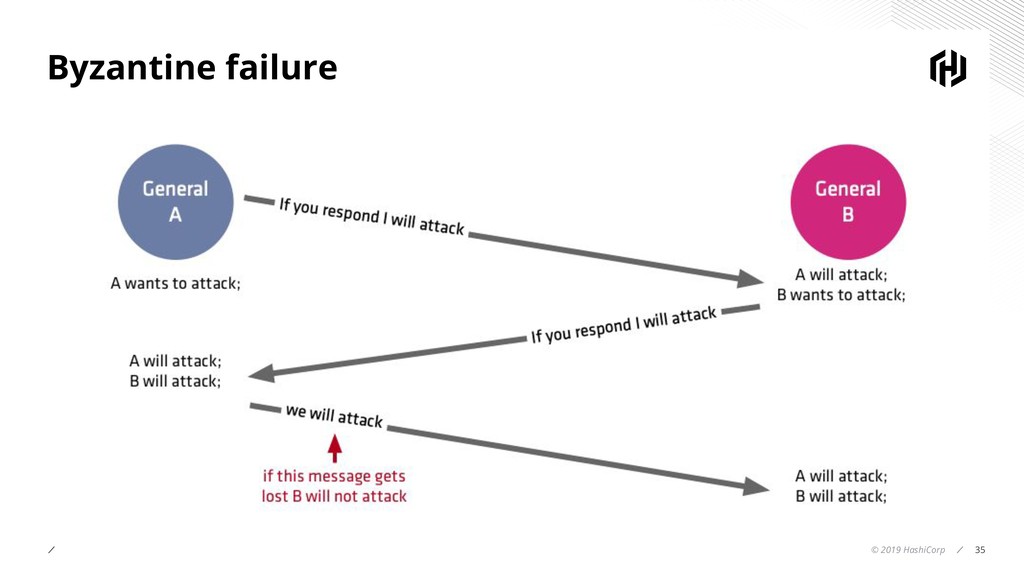
Distributed systems are not a new problem, for as long as there have been n+1 computers in a network, the problem of managing membership in a group and detecting failure has existed. Many of the algorithms we use in today's systems to solve this problem are over 30 years old, and in this talk, we will look at how an algorithm for email replication by a photocopier company, has morphed into SWIM, used to manage group membership and failure detection in modern distributed systems.
Takeaways:
- Introduction to Gossip and epidemic rumor spreading
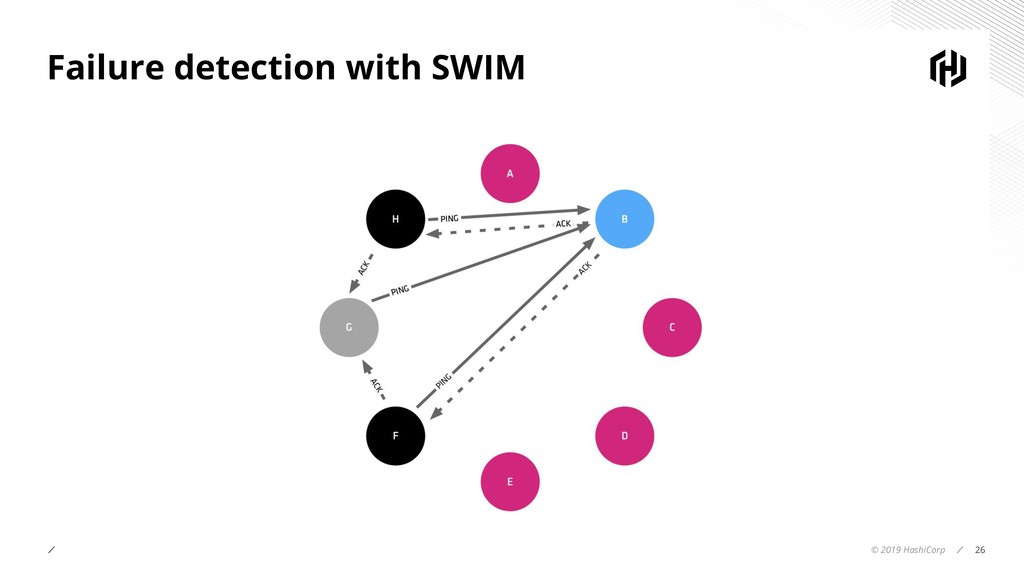
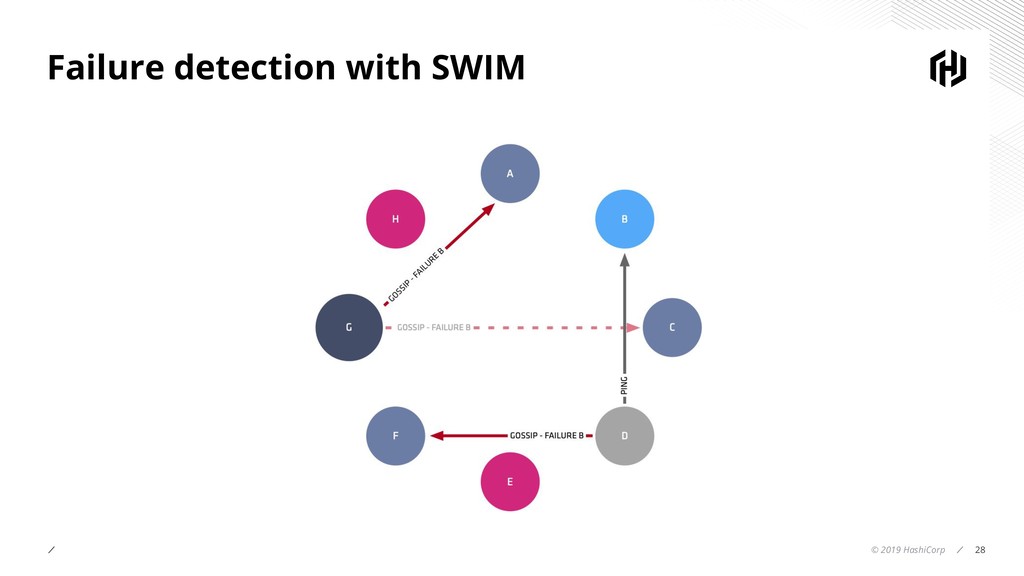
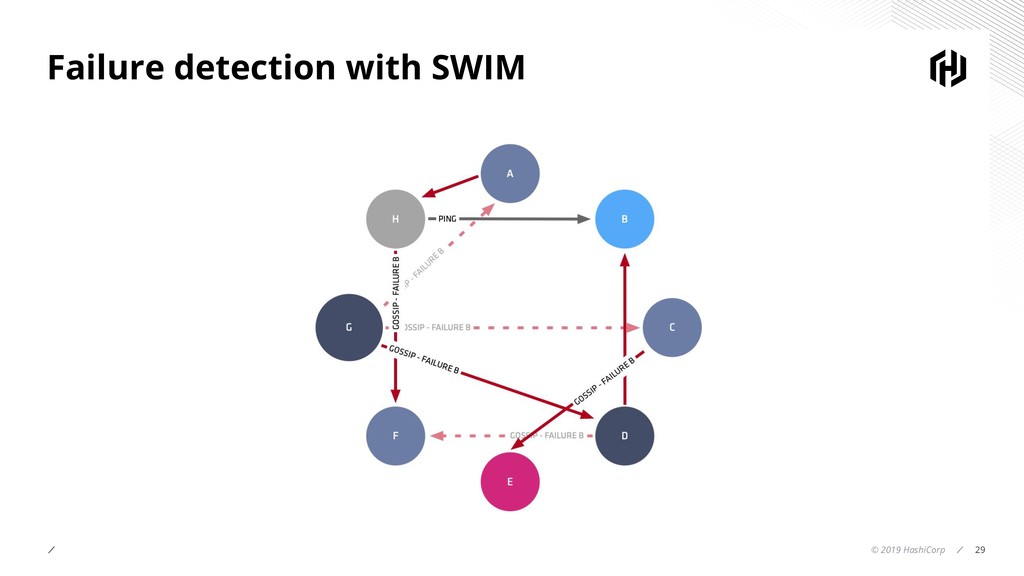
- Deep dive into SWIM which uses Gossip for failure detection in distributed systems
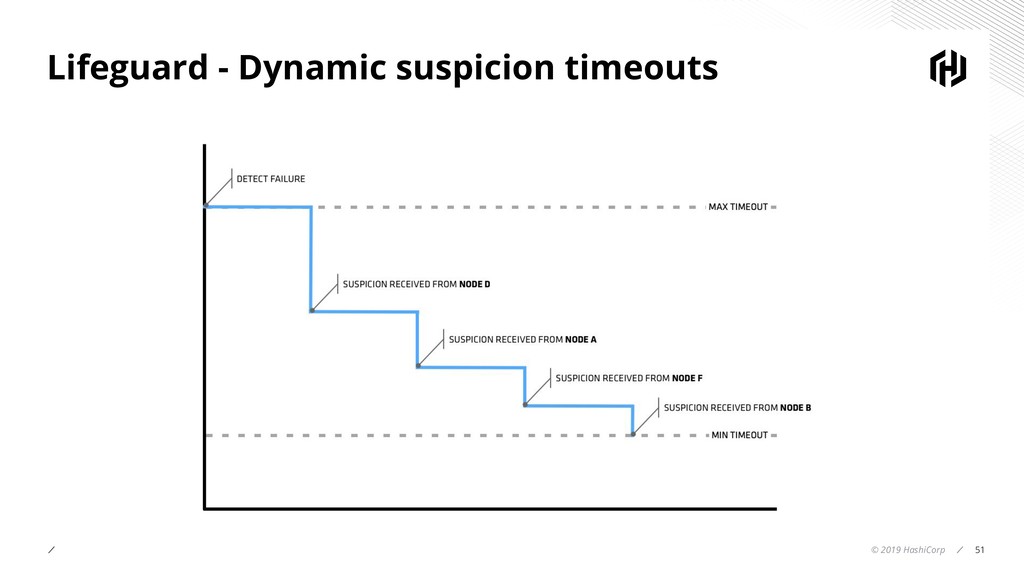
- Investigation of Lifeguard which builds on SWIM adding many improvements
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you @sheriffjackson [email protected] 57](https://files.speakerdeck.com/presentations/9314253a27944192a02e869440c37acd/slide_56.jpg){kind=link}