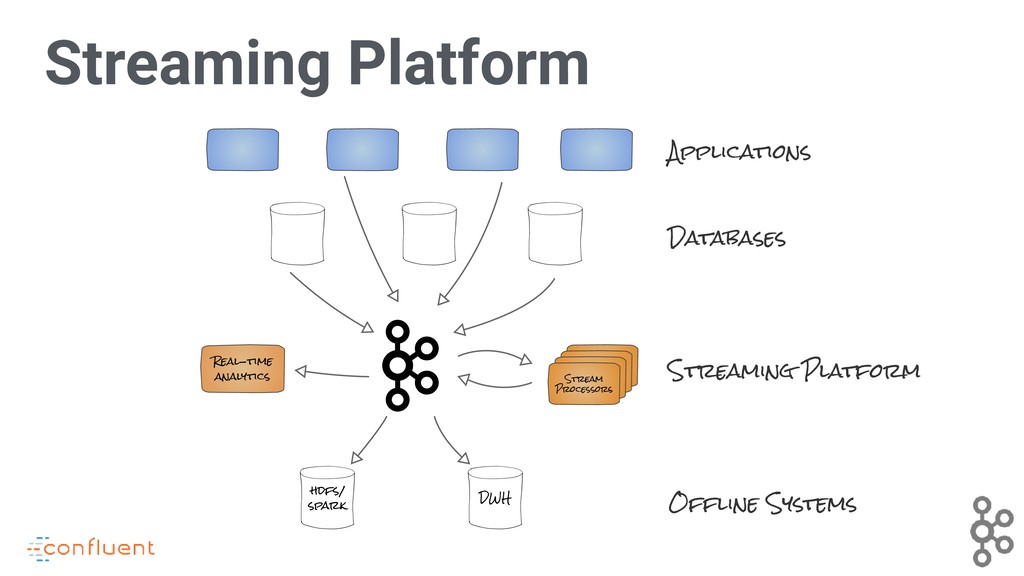
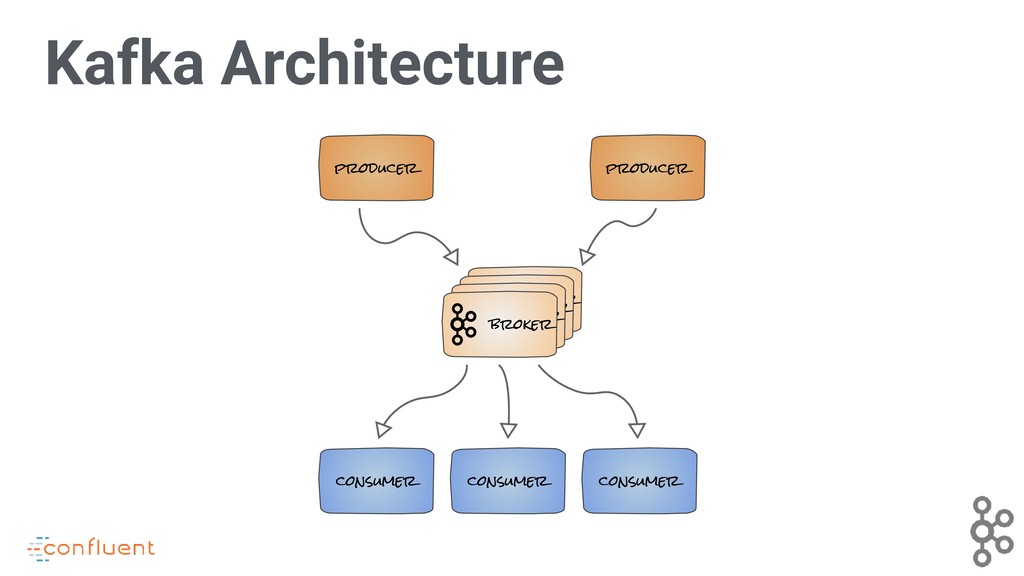
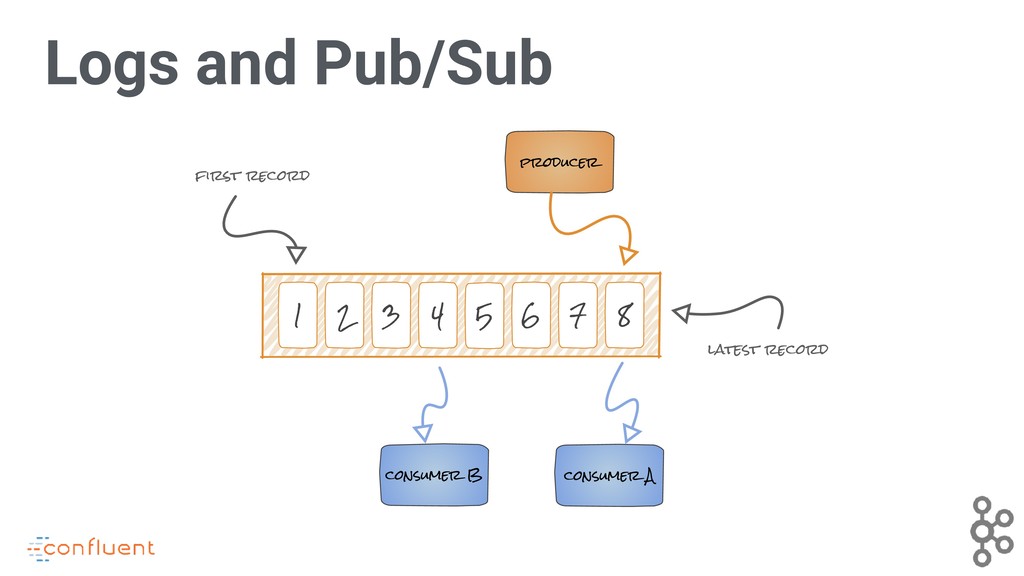
Apache Kafka is a de facto standard streaming data processing platform, being widely deployed as a messaging system, and having a robust data integration framework (Kafka Connect) and stream processing API (Kafka Streams) to meet the needs that common attend real-time message processing. But there’s more!
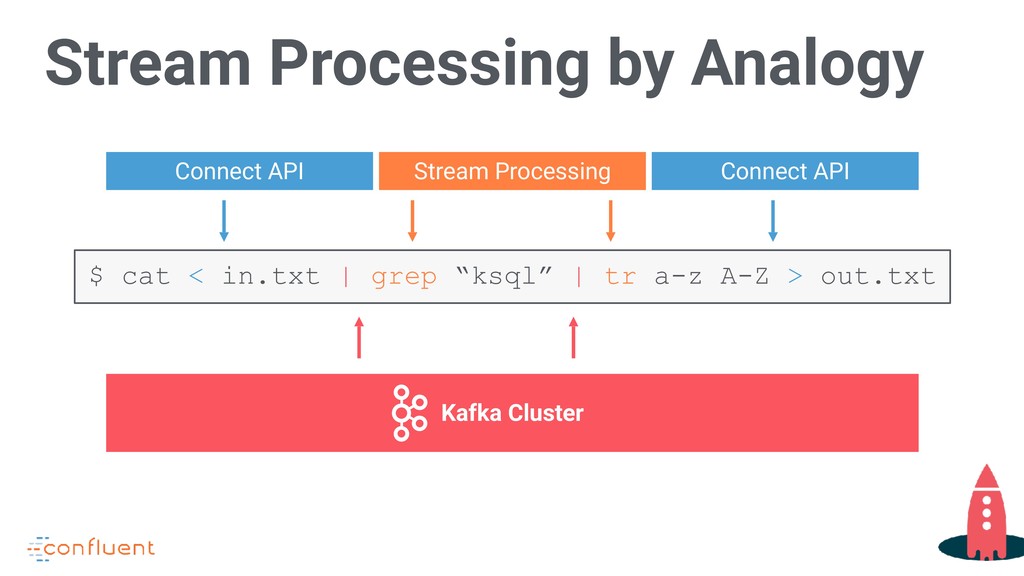
Kafka now offers KSQL, a declarative, SQL-like stream processing language that lets you define powerful stream-processing applications easily. What once took some moderately sophisticated Java code can now be done at the command line with a familiar and eminently approachable syntax. Come to this talk for an overview of KSQL with live coding on live streaming data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Resources and Next Steps https://github.com/confluentinc/ksql http://confluent.io/ksql https://slackpass.io/confluentcommunity #ksql @tlberglund [email protected]](https://files.speakerdeck.com/presentations/2b698fb8835148ed82d8c0eb37b47d91/slide_27.jpg){kind=link}
![Thank you! @tlberglund [email protected]](https://files.speakerdeck.com/presentations/2b698fb8835148ed82d8c0eb37b47d91/slide_28.jpg){kind=link}