Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AWSのGPUを安く使って TensorFlowモデルを訓練する方法
Search
masa-ita
August 08, 2020
Technology
420
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AWSのGPUを安く使って TensorFlowモデルを訓練する方法
masa-ita
August 08, 2020
More Decks by masa-ita
See All by masa-ita
Ollamaを使ったLocal Language Model活用法
itagakim
1
230
Run Instant NeRF on Docker
itagakim
1
2.3k
3D Clustering and Metric Learning
itagakim
0
410
Cloud TPUの使い方〜BigBirdの日本語学習済みモデルを作る〜
itagakim
0
750
多言語学習済みモデルmT5とは?
itagakim
1
790
最近の自然言語処理モデルの動向
itagakim
1
590
ディープラーニングで芸術はできるか? 〜生成系ネットワークの進展〜
itagakim
0
380
AWSとTerraform初心者が やってみたこと
itagakim
1
530
IntroductionToTensorFlow2_0.pdf
itagakim
1
390
Other Decks in Technology
See All in Technology
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
490
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
230
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
480
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
520
「休む」重要さ
smt7174
6
1.6k
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
5
1.2k
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
280
PHPで作って学ぶリアルタイム音声対話AIとWebSocket入門 by ムナカタ
munakata
0
140
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
440
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
260
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
280
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.5k
Featured
See All Featured
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Typedesign – Prime Four
hannesfritz
42
3.1k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
Visualization
eitanlees
152
17k
Utilizing Notion as your number one productivity tool
mfonobong
4
450
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
The World Runs on Bad Software
bkeepers
PRO
72
12k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Transcript
AWSのGPUを安く使って TensorFlowモデルを訓練する⽅法 板垣正敏@TensorFlow Users Group Niigata Meetup #3 2020/8/8
⾃⼰紹介 板垣 正敏(いたがき まさとし) 1955年 新潟県・村上市⽣まれ Python機械学習勉強会in新潟
世話⼈ NPO法⼈ 新潟オープンソース協会 理事 株式会社BSNアイネット 技術顧問 中⼩企業診断⼠ 2
アジェンダ GPUを持っていない/GPUが⾜りない︖ クラウドGPUの料⾦ Amazon SageMakerとは︖ SageMaker
トレーニングジョブの仕組み ⽤意するもの コンテナ内の標準ディレクトリ構成 訓練⽤プログラムの勘所 Docker ImageのビルドとECRへの登録 トレーニングジョブの投⼊と完了 メトリクスの監視⽅法 どれくらい節約できる︖ まとめ 3
GPUを持っていない/GPUが⾜りない︖ Google Colaboratoryは素晴らしい ⼿元にGPUがない場合に⼀番⼿軽で⼀番安い(なにせ無料)なのがGoogle Colaboratoryです(⽶国では有料プランも) GPU以外にクラウドTPUも無料で使うことができます
ただし、最⼤実⾏時間12時間の制限があるほか、⼀定時間操作を⾏わないと切断さ れます クラウドを使う GPUマシンを購⼊するほどではないが、お⾦がかかってもある程度の時間GPUを使い たいとか、たくさんのGPUが必要なモデルの訓練を⾏う場合などは、クラウドを利⽤ することになります 4
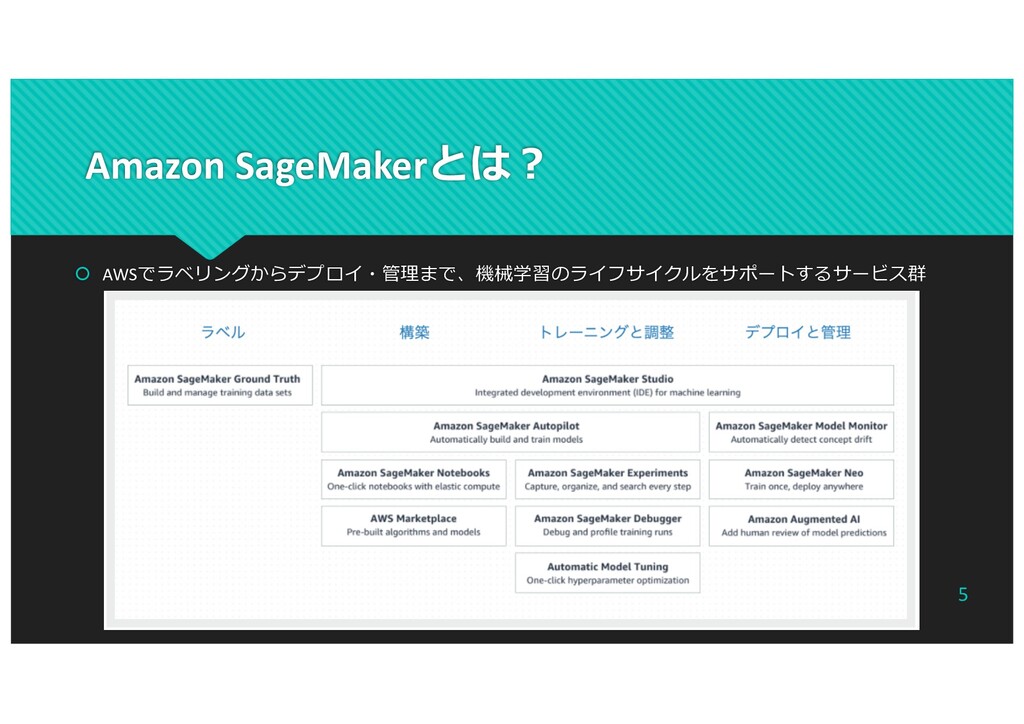
Amazon SageMakerとは︖ AWSでラベリングからデプロイ・管理まで、機械学習のライフサイクルをサポートするサービス群 5
SageMaker トレーニングジョブ の仕組み AWSのコンテナサービスを使 って機械学習モデルの訓練を 行うサービス 利用可能なモデル
AWSあるいはマーケットプレ イスのアルゴリズム カスタムアルゴリズム AWSが用意したコンテナ( TensorFlow, PyTorchなど) カスタムコンテナ(今回はコ レ) https://towardsdatascience.com/a-quick-guide-to-using-spot-instances- with-amazon-sagemaker-b9cfb3a44a68 6
⽤意するもの AWSアカウント Amazon SageMaker⽤のロール(アタッチするポリシーはAmazonSageMakerFullAccessのみで可) ECRのレジストリ S3バケット
訓練⽤プログラム 訓練⽤データ Dockerのビルド環境 7
コンテナ内の標準ディレクトリ構成 /opt/ml ├── checkpoints <= 中断に備えてチェックポイントを保存︓S3バケットにコピー ├── code │ └──
train <= 訓練⽤プログラムのエントリーポイント(既定) ├── input │ ├── config <= SageMakerトレーニングジョブから渡される │ │ ├── hyperparameters.json <= 訓練ジョブ投⼊時に設定したハイパーパラメータが⼊る │ │ └── resourceConfig.json <= Sagemakerが割り当てたリソースに関する情報 │ └── data │ └── training <= 訓練⽤データの場所(既定)︓S3バケットからコピーされる ├── model <= 学習したモデルの保存場所︓圧縮後outputにコピー └── output <= 出⼒⽤ディレクトリ︓S3バケットにコピー 8
訓練⽤プログラムの勘所 訓練⽤プログラムのエントリーポイントは、Shell ファイルまたはPython ファイル Docker コンテナ内の/opt/ml/code/trainが既定の場所と名前 実⾏ファイル名は、環境変数SAGEMAKER_PROGRAMで指定可能
プログラムにパラメータを渡す⽅法は2つ SageMakerトレーニングジョブのハイパーパラメータを通じて渡す 環境変数を通じて渡す スポットインスタンスは中断されることを前提に、チェックポイントを 定期的に保存し、起動したときにチェックポイントがある場合には、そ の続きを実⾏するようにすること 9
中断に備えてチェックポイントを保存 # モデルのチェックポイントをチェックポイントディレクトリに保存する checkpoint_path = os.path.join(checkpoints_dir, 'model_checkpoint_{epoch:05d}’) model_checkpoint_callback = ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=False) model.fit(train_ds, epochs=train_steps, initial_epoch=initial_epoch, validation_data=val_ds, callbacks=[model_checkpoint_callback], verbose=2) 10
チェックポイントを検索する関数 # チェックポイントディレクトリをスキャンし、最も新しいチェックポイントとエポック数を返す def find_last_checkpoint(checkpoint_path): dirs = [d for d
in os.listdir(checkpoint_path) if d.startswith('model_checkpoint_’)] epoch_numbers = [re.search('(¥d+)',f).group() for f in dirs] if epoch_numbers: max_epoch_number = max(epoch_numbers) max_epoch_index = epoch_numbers.index(max_epoch_number) max_epoch_dirname = dirs[max_epoch_index] else: max_epoch_dirname = None max_epoch_number = None return max_epoch_dirname, max_epoch_number 11
チェックポイントがあればロード # チェックポイントを検索し、あれば最新の重みをロードし再開するエポック数をセット last_checkpoint, last_epoch = find_last_checkpoint(checkpoints_dir) if last_checkpoint: model
= models.load_model(os.path.join(checkpoints_dir, last_checkpoint)) initial_epoch = int(last_epoch) print('Model checkpoint #{} was loaded.'.format(last_epoch)) else: model = create_model(num_classes=num_classes) model.compile(loss = 'categorical_crossentropy’, optimizer = 'rmsprop’, metrics = ['accuracy’]) initial_epoch = 0 12
ビルド環境について 開発環境のディレクトリ構造 container ├── Dockerfile ├── build_and_push.sh ├── code │
└── train └── local_test ├── test_dir └── train_local.sh 簡単なDockerfileの例 FROM tensorflow/tensorflow:2.3.0 RUN pip install pillow ENV PATH="/opt/ml/code:${PATH}” COPY /code /opt/ml/code WORKDIR /opt/ml/code 13 ※コンテナにローカルディレクトリをマウントすれば、ローカルでもテスト可能
Docker ImageのビルドとECRへの登録 # Docker Imageのビルドとタグづけ docker build -t sagemaker-example .
docker tag sagemaker-example:latest ¥ 999999999999.dkr.ecr.ap-northeast-1.amazonaws.com/sagemaker-example:latest # AWS へのログインとECRへのDocker ImageのPush aws ecr get-login-password --region ap-northeast-1 | ¥ docker login --username AWS --password-stdin ¥ 999999999999.dkr.ecr.ap-northeast-1.amazonaws.com docker push 999999999999.dkr.ecr.ap-northeast-1.amazonaws.com/sagemaker-example:latest 14
トレーニングジョブの投⼊と完了 import sagemaker from sagemaker.estimator import Estimator hyperparameters = {'train-steps':
5} estimator = Estimator(image_uri=‘999999999999.dkr.ecr.ap-northeast-1.amazonaws.com/sagemaker-example:latest’, role="arn:aws:iam::999999999999:role/SagemakerJobRunner”, instance_count=1, instance_type='ml.p2.xlarge’, max_run=24 * 60 * 60, input_mode='File’, output_path='s3://sagemaker-examples.rails.to/output’, base_job_name='Sagemaker-Example’, hyperparameters=hyperparameters, use_spot_instances=True, max_wait=24 * 60 * 60, checkpoint_s3_uri='s3://sagemaker-examples.rails.to/checkpoints’) estimator.fit('s3://sagemaker-examples.rails.to/input/data/training') 15
メトリクスの監視⽅法 訓練中の標準出⼒はCloudWatchのログストリームに記録される 訓練時にメトリクス定義を正規表現で切り取るように定義しておけば、 SageMakerのアルゴリズムメトリクスおよびCloudWatchのメトリクスとし て管理できるようになる TensorFlowの場合には、Tensorboard⽤のログをチェックポイント⽤ディレ クトリに出⼒することで、実⾏終了後に検証可能
16
どれくらい節約できる︖ トレーニングにかかっ た時間のうち、請求可 能な時間のみ課⾦され る 請求可能な時間×オンデ マンドインスタンスの 単価
節約率は70%前後︖ 17
GPUの料⾦:オンデマンドインスタンス クラウド タイプ vCPU GPU CPUメモリ 料⾦/時間 AWS p2.xlarge 4
K80/12GB 61GB $1.542 p3.2xlarge 8 V100/16GB 61GB $4.194 p3dn.24xlarge 96 V100/32GB×8/NVLink 768GB $42.783 GCP GPUのみ K80/12GB $0.45 GPUのみ P100/16GB $1.46 GPUのみ V100/16GB $2.48 c2 カスタム構成例 4 K80/12GB 52GB $0.82252 c2 カスタム構成例 8 V100/16GB 61GB $3.0239 c2 カスタム構成例 96 V100/16GB×8 624GB $8.58128 ※AWSは東京リージョン、GCPはアイオワリージョンの料⾦ 18
まとめ Amazon Sagemakerでは、流儀にしたがったディレクトリ構造のDockerイメージを作れば、マネージ ドスポットインスタンスでの学習が可能になる データや学習済みモデルなどの受け渡しはS3経由 インスタンスの停⽌に備えるには、頻繁にチェックポイントを保存しておき、起動時に最新の チェックポイントをロードして訓練を⾏うようにする
訓練中の監視はCloudWatchで可能 訓練の実⾏はPythonプログラムからも可能 オンデマンドインスタンスを⽴てての訓練に⽐べて70%程度の節約が可能︖ GPU⾃体の料⾦はAWSよりもGCPが安いので、GCPで「プリエンプティブインスタンス」を使う⾃ 動化を⾏えば、そっちの⽅が安くあがりそう︖ 19
参考 Train a Model with Amazon SageMaker https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-training.html
SageMaker Python SDK https://github.com/aws/sagemaker-python-sdk SageMaker Training Toolkit https://github.com/aws/sagemaker-training-toolkit Amazon SageMaker Examples https://github.com/awslabs/amazon-sagemaker-examples A quick guide to using Spot instances with Amazon SageMaker https://towardsdatascience.com/a-quick-guide-to-using-spot-instances-with-amazon-sagemaker-b9cfb3a44a68 クラスメソッドブログ︓Sagemaker特集カテゴリー https://dev.classmethod.jp/referencecat/amazon-sagemaker/ 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}