PUEstimator l Mesh TensorFlow l ⼿動配置 PyTorch l torch_xla l torch.distributed.pipeline l ⼿動配置 l HuggingFace/Transformers では、⼀部のモデルで Attention単位の並列化 (Parallelize)が可能
板垣作成スクリプト https://github.com/masa-ita/train_bigbird Gradient Checkpointing論⽂ Training Deep Nets with Sublinear Memory Cost https://arxiv.org/abs/1604.06174v2 Google Colab Pro https://colab.research.google.com/signup
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
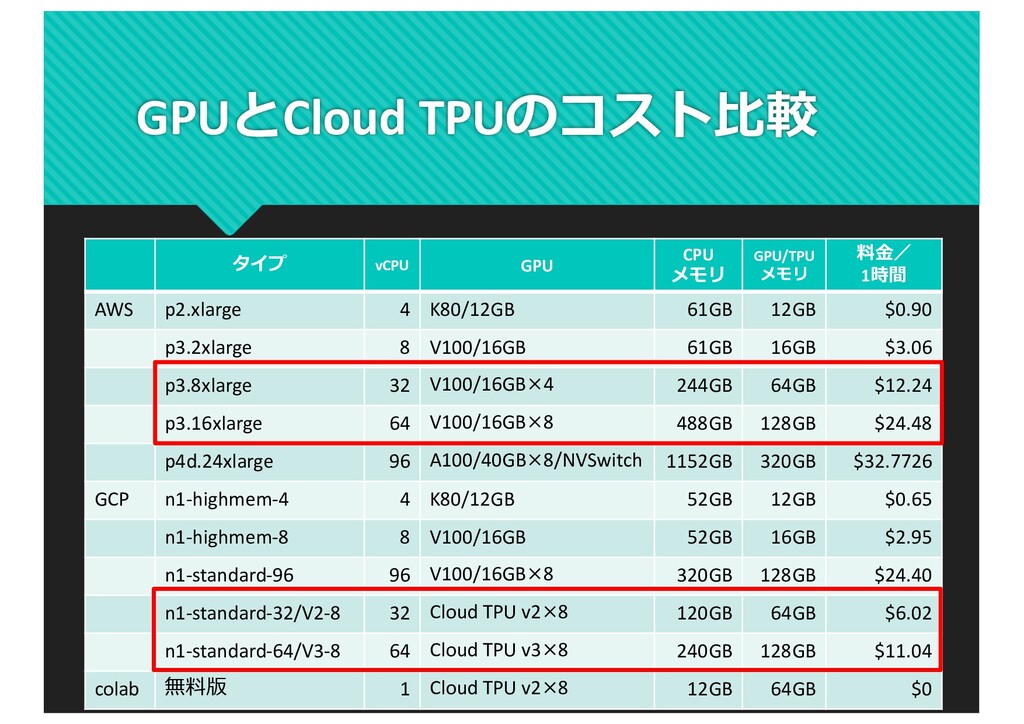{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
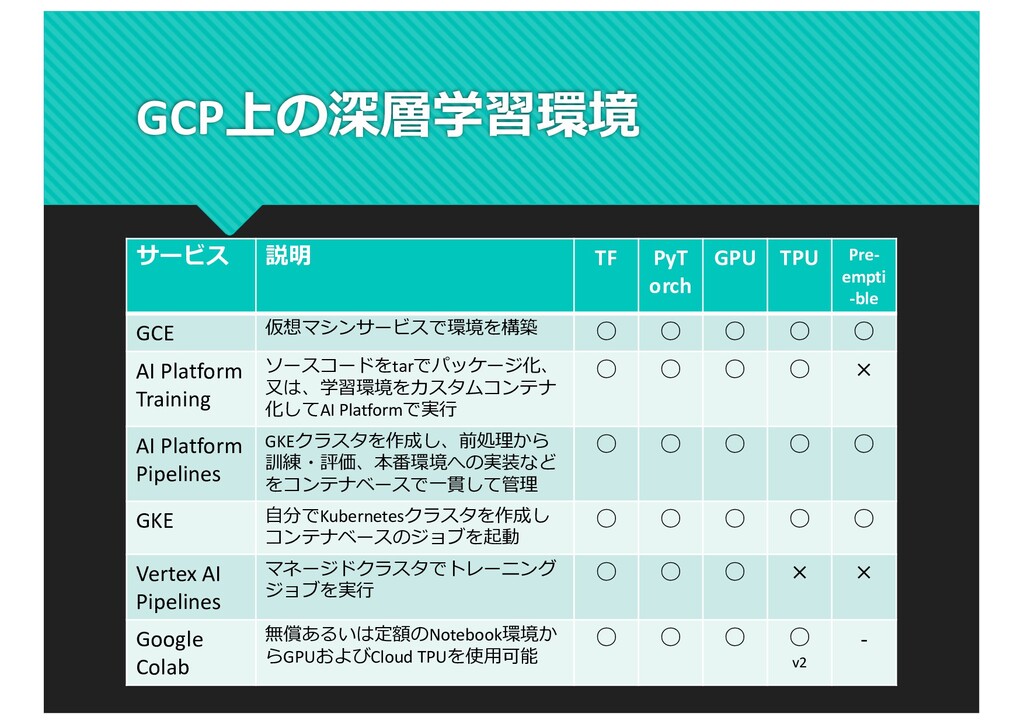{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
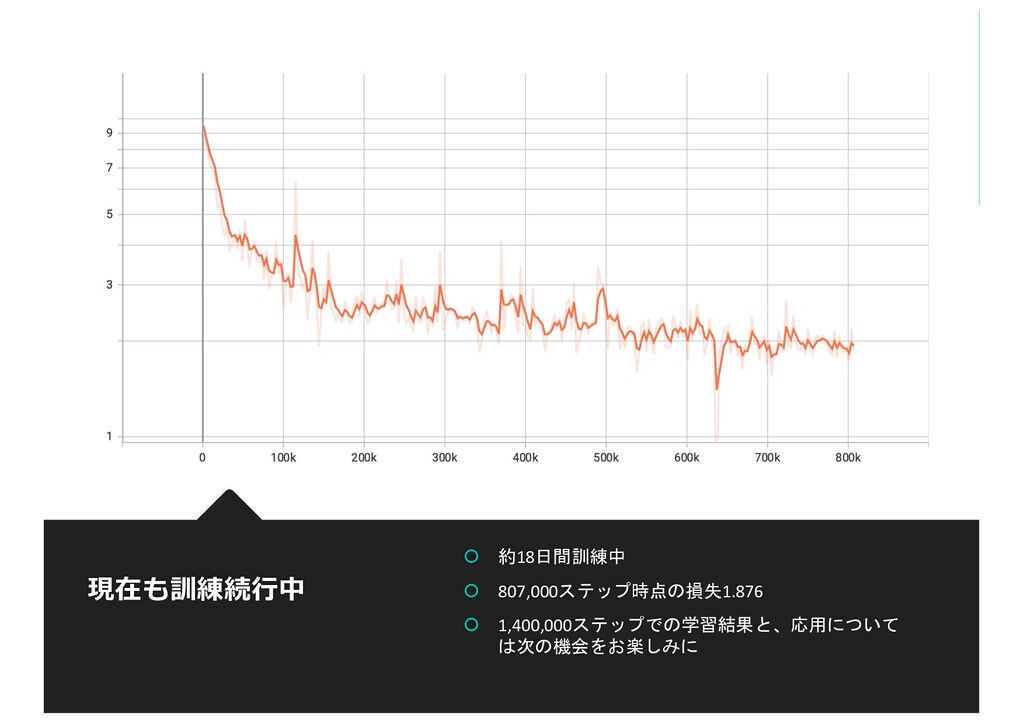{kind=link}
{kind=link}
{kind=link}
{kind=link}