Clustering for Unsupervised Learning of Visual Features https://arxiv.org/abs/1807.05520 https://github.com/facebookresearch /deepcluster Unsupervised Pre-Training of Image Features on Non-Curated Data https://arxiv.org/abs/1905.01278 https://github.com/facebookresearch /deepercluster 9
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
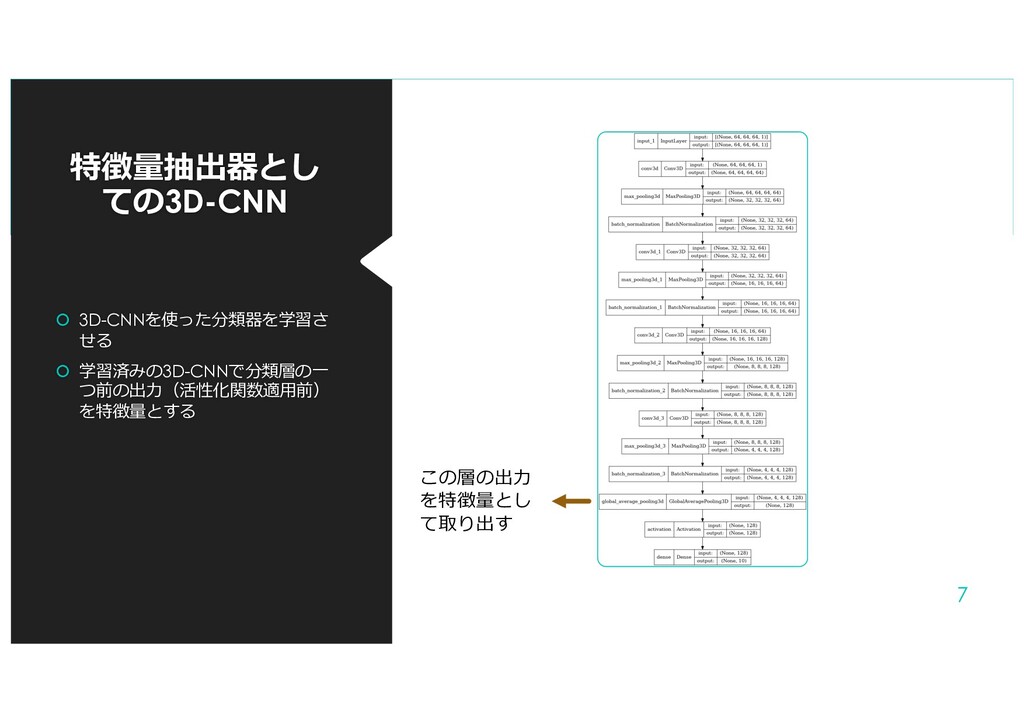{kind=link}
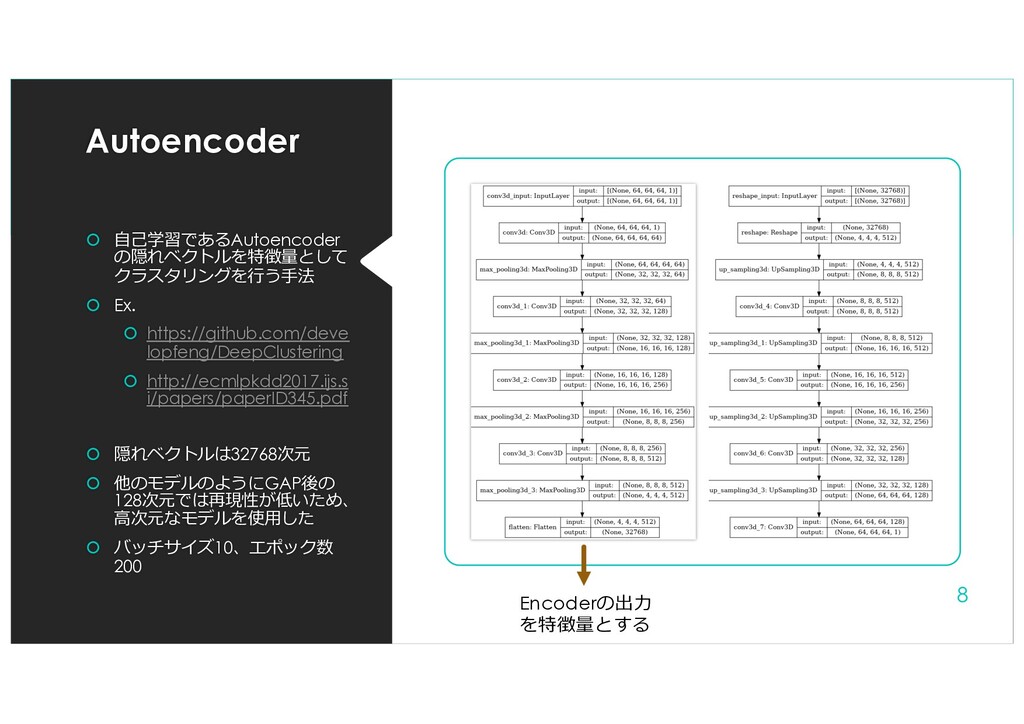{kind=link}
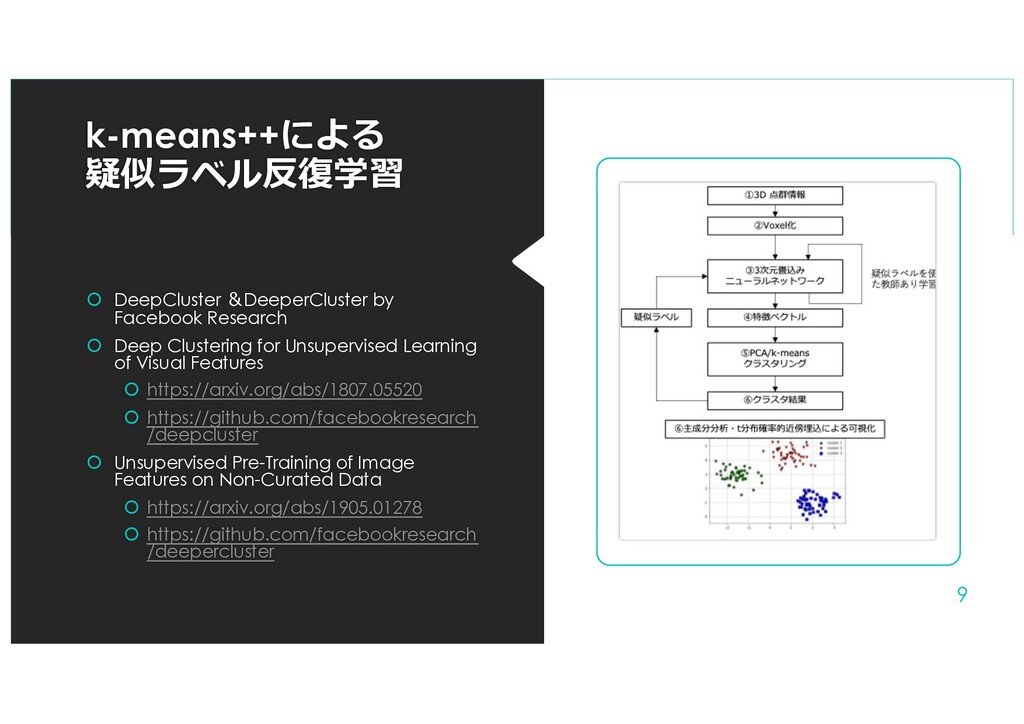{kind=link}
{kind=link}
{kind=link}
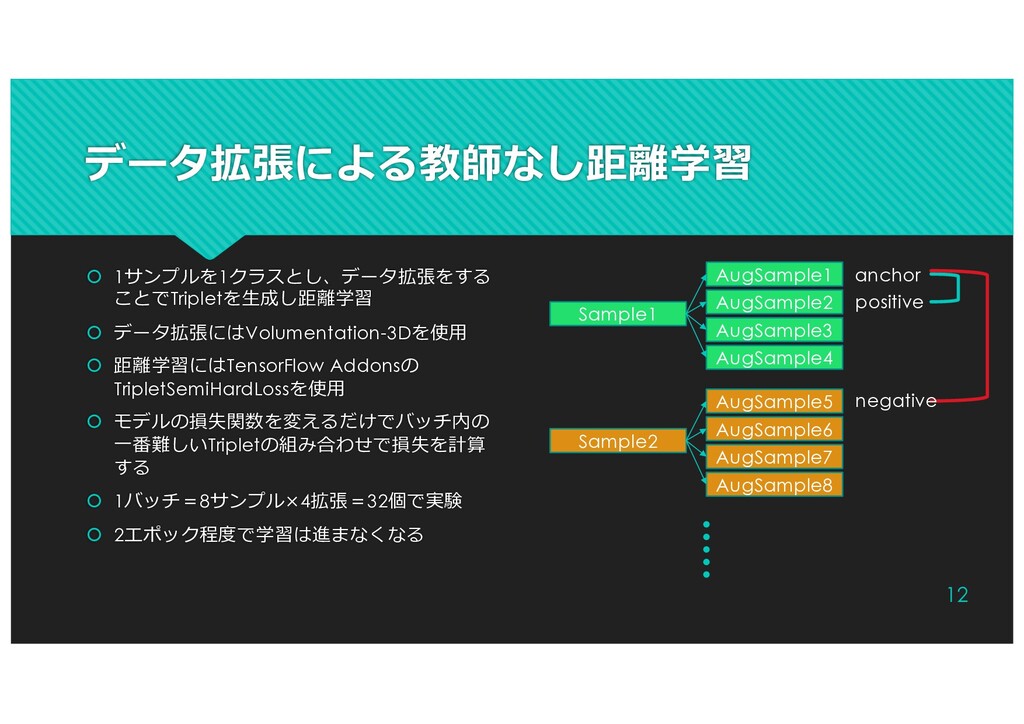{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}