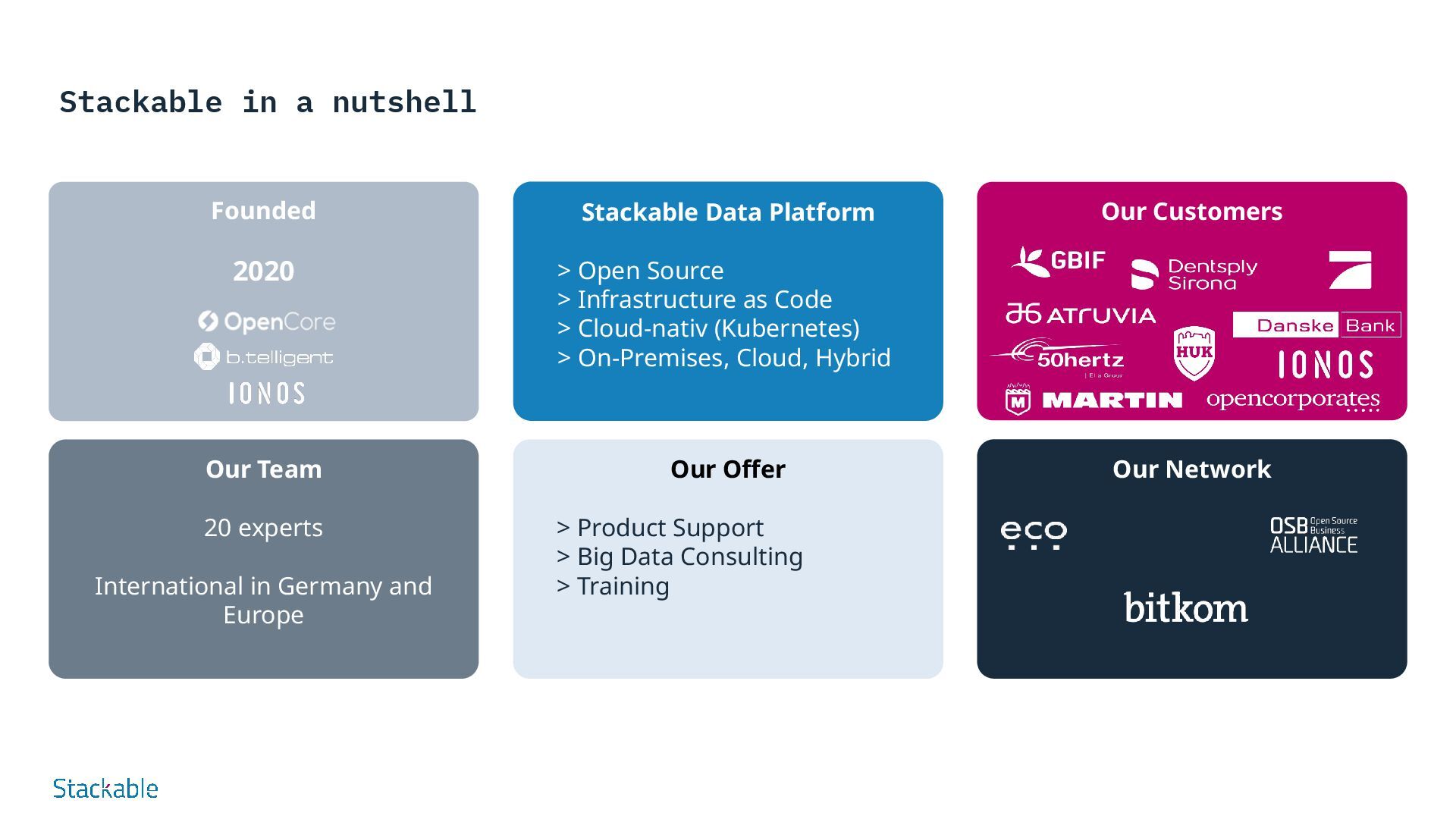
International in Germany and Europe Founded 2020 Our Offer > Product Support > Big Data Consulting > Training Stackable Data Platform > Open Source > Infrastructure as Code > Cloud-nativ (Kubernetes) > On-Premises, Cloud, Hybrid Our Customers Our Network
the (big) data ecosystem • Large customer network around the world • Network of experts and partners from the data and streaming world • Many years of expert knowledge of the data & analytics market • Access to 250+ customers in DACH in all industries • Strong market presence and network • Support of Stackable through the shared services organization of b.telligent • Strategic focus on open source software • Capital and developers for the further development of Stackable • Data centers in Europe and the USA • C5 certificate, BSI IT basic protection & ISO 27001 certified • Consortium partner in GAIA-X funding projects
of b.telligent, founder and investor of several companies in the data-driven B2B sector Jim Halfpenny MD Stackable UK Expert for Big Data solutions, very experienced in the design of big data architectures and open source projects Fabian Jasinski CRO Expert with many years of experience in technology management, digital transformation, product management, and data science Sönke Liebau CPO Co-Founder of Stackable and OpenCore, has been working with (Big)-data open source software, speaker, contributor to various projects Lars Francke CTO Co-founder of Stackable and OpenCore, committer to open source projects, has been working in the (big) data sector since 2008 Dr. Stefan Igel COO Big data expert with many years of experience in IT projects, agile leadership, team and organizational development
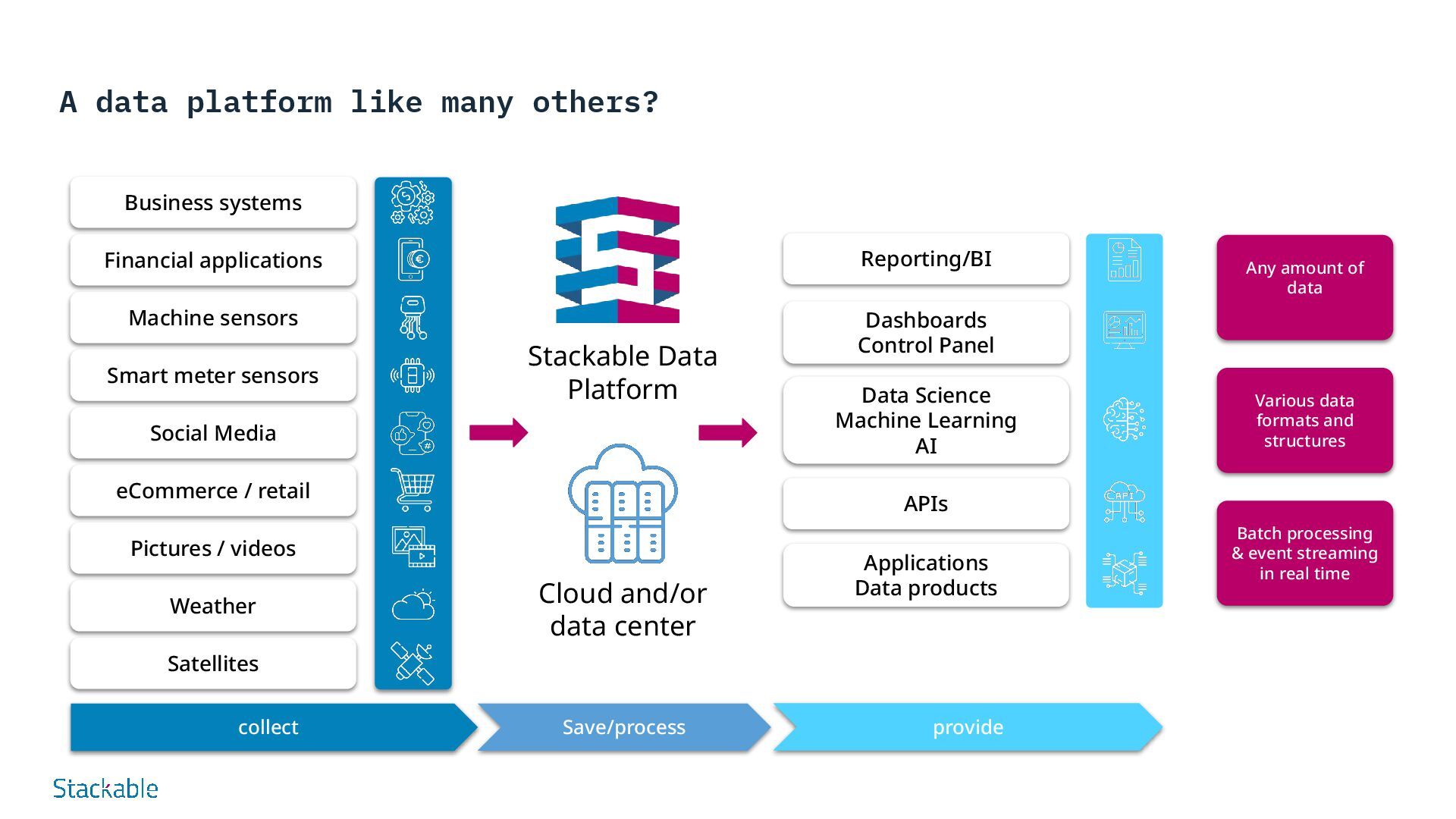
and/or data center Business systems Financial applications Machine sensors Smart meter sensors Social Media eCommerce / retail Pictures / videos Weather Satellites Reporting/BI Dashboards Control Panel Data Science Machine Learning AI APIs Applications Data products collect Save/process provide Any amount of data Batch processing & event streaming in real time Various data formats and structures
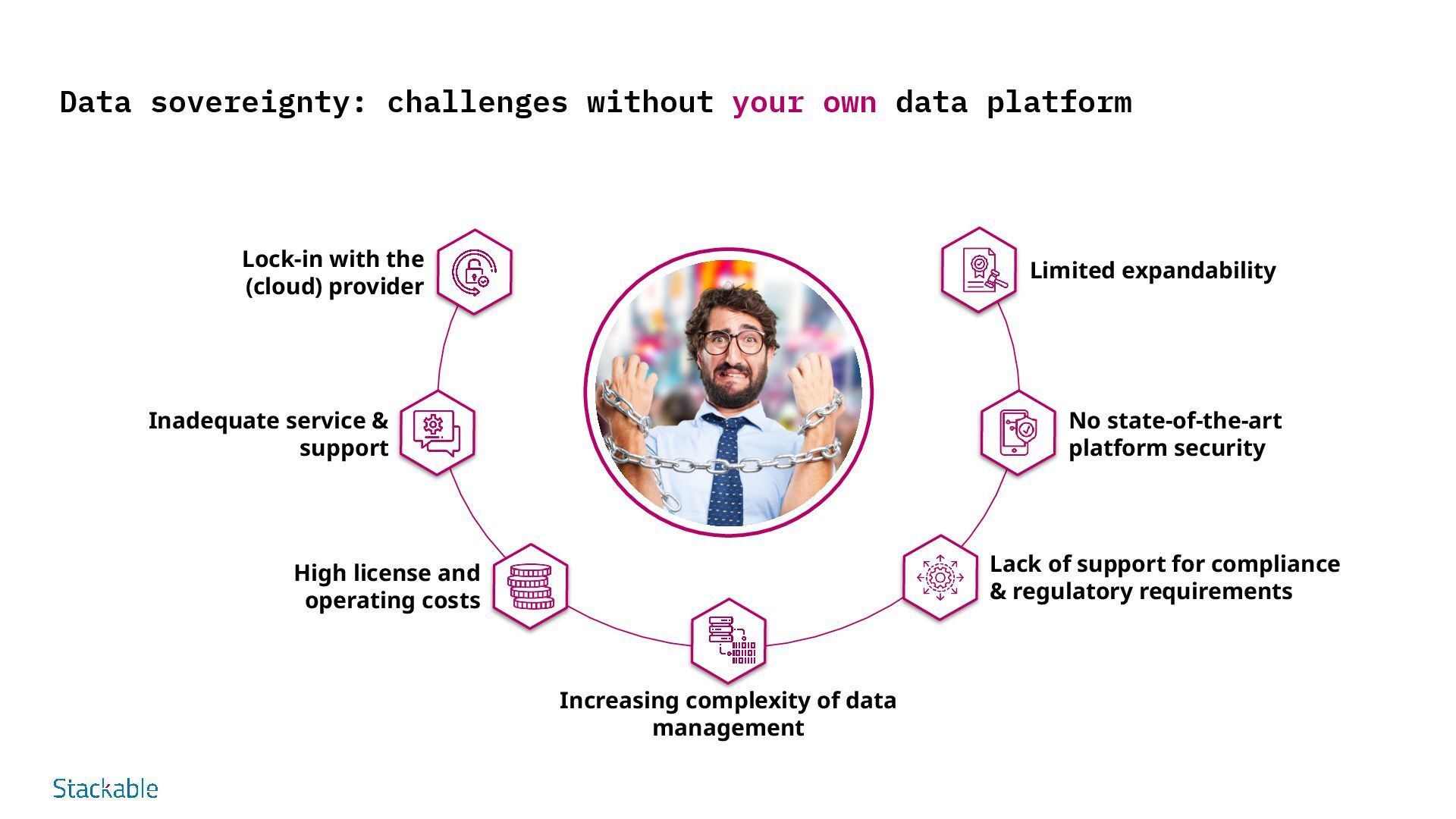
the (cloud) provider Inadequate service & support High license and operating costs Increasing complexity of data management Limited expandability No state-of-the-art platform security Lack of support for compliance & regulatory requirements
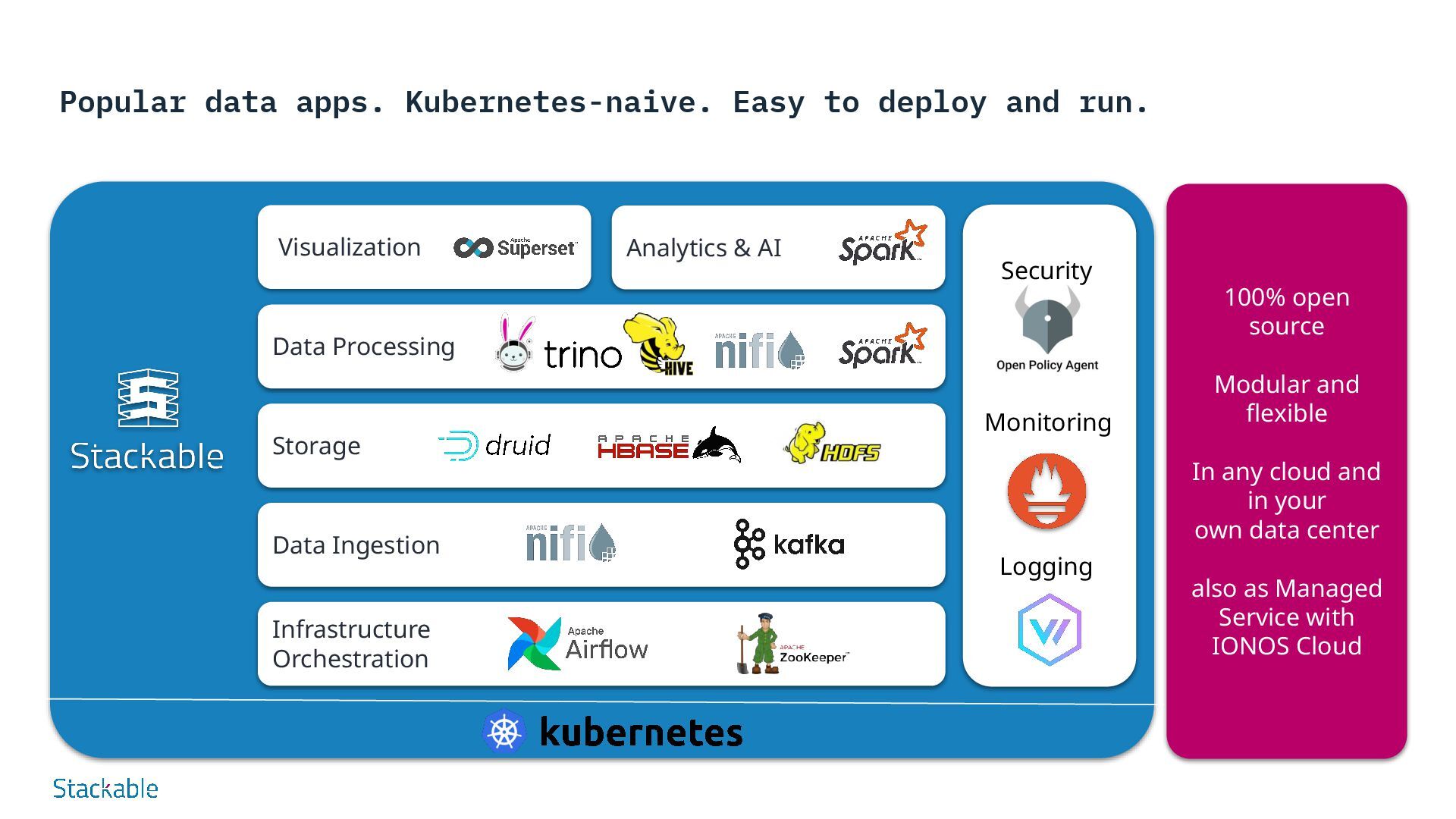
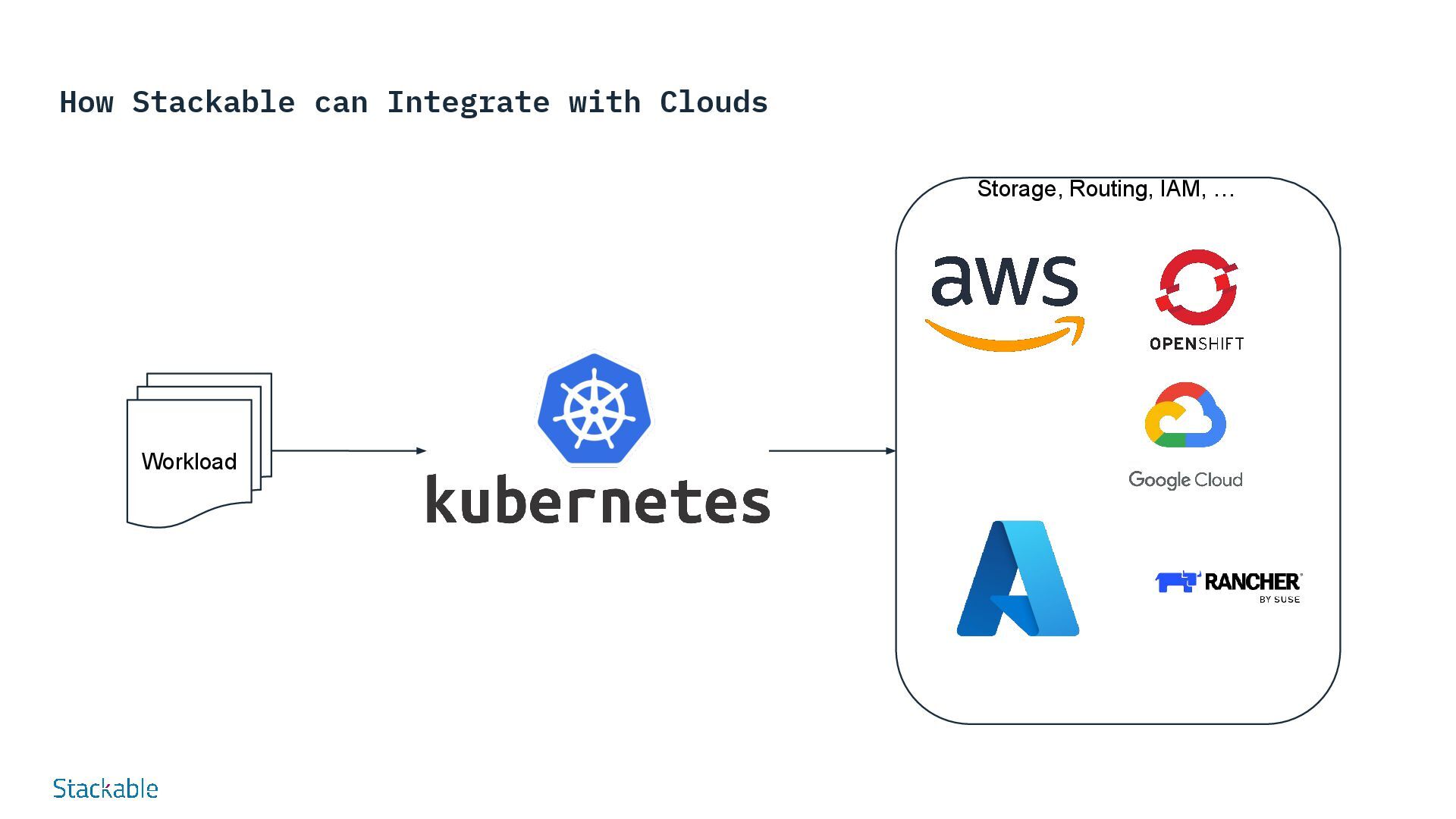
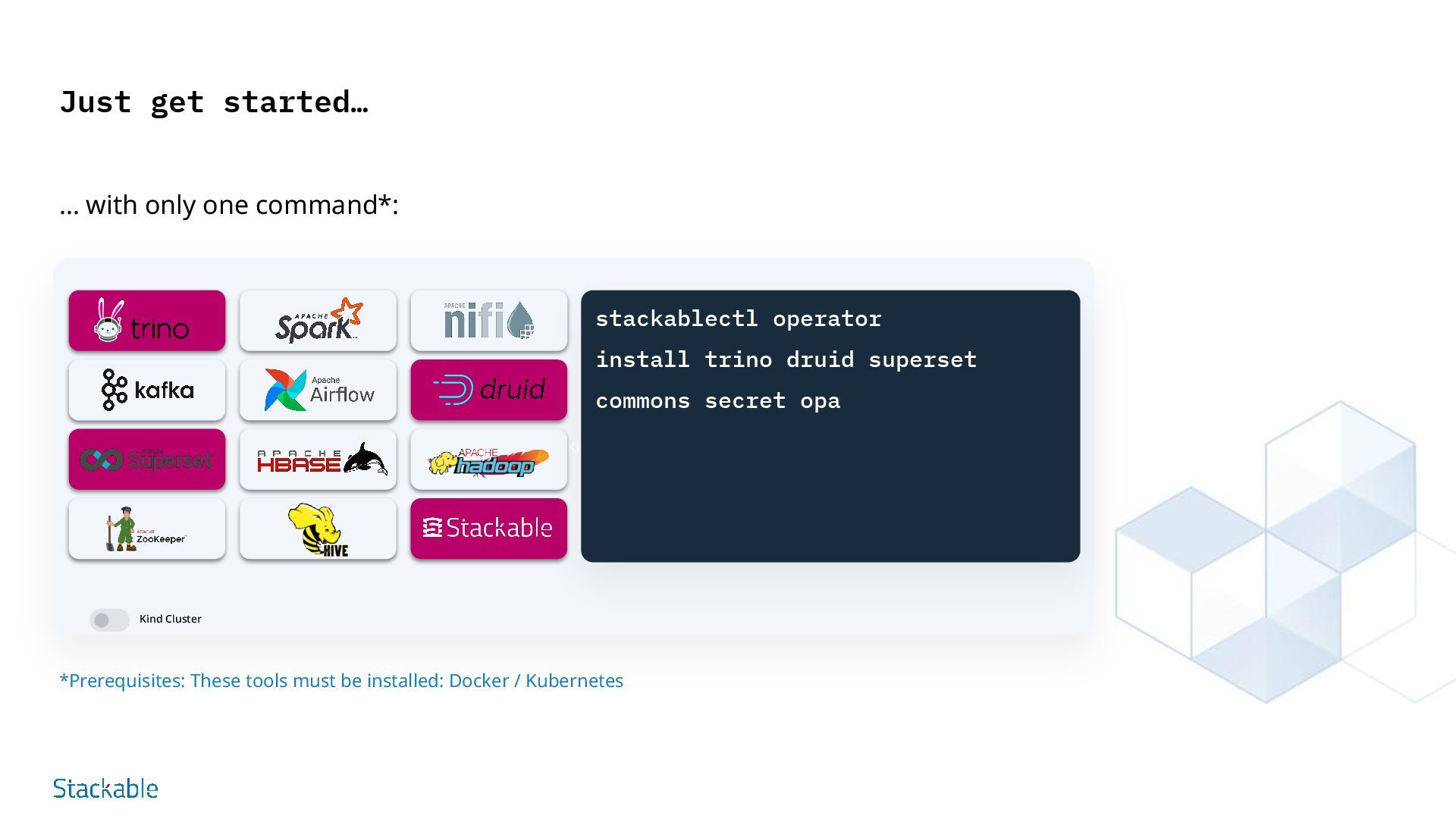
your modern data platform from a single source - no patchwork or vendors and a single point of contact. Flexible, modular, expandable Choose the ideal combination of data tools in different versions and move away from monolithic distributions. Easy integration Uniform interfaces for monitoring, alerting and log management simplify individual integration into your corporate IT. Made in Europe Developed in Europe according to European security standards - including vulnerability management, VEX declarations, consideration of CRA etc. Popular Data Apps Offers a curated selection of the best open source data apps such as Apache Kafka®, Apache Druid, Trino and Apache Spark™. Kubernetes-native Based on Kubernetes, the platform runs everywhere - in your own data center or in the cloud Easy to set up and operate All apps work seamlessly together and can be added or removed to create unique data architectures. Why Stackable? your platform
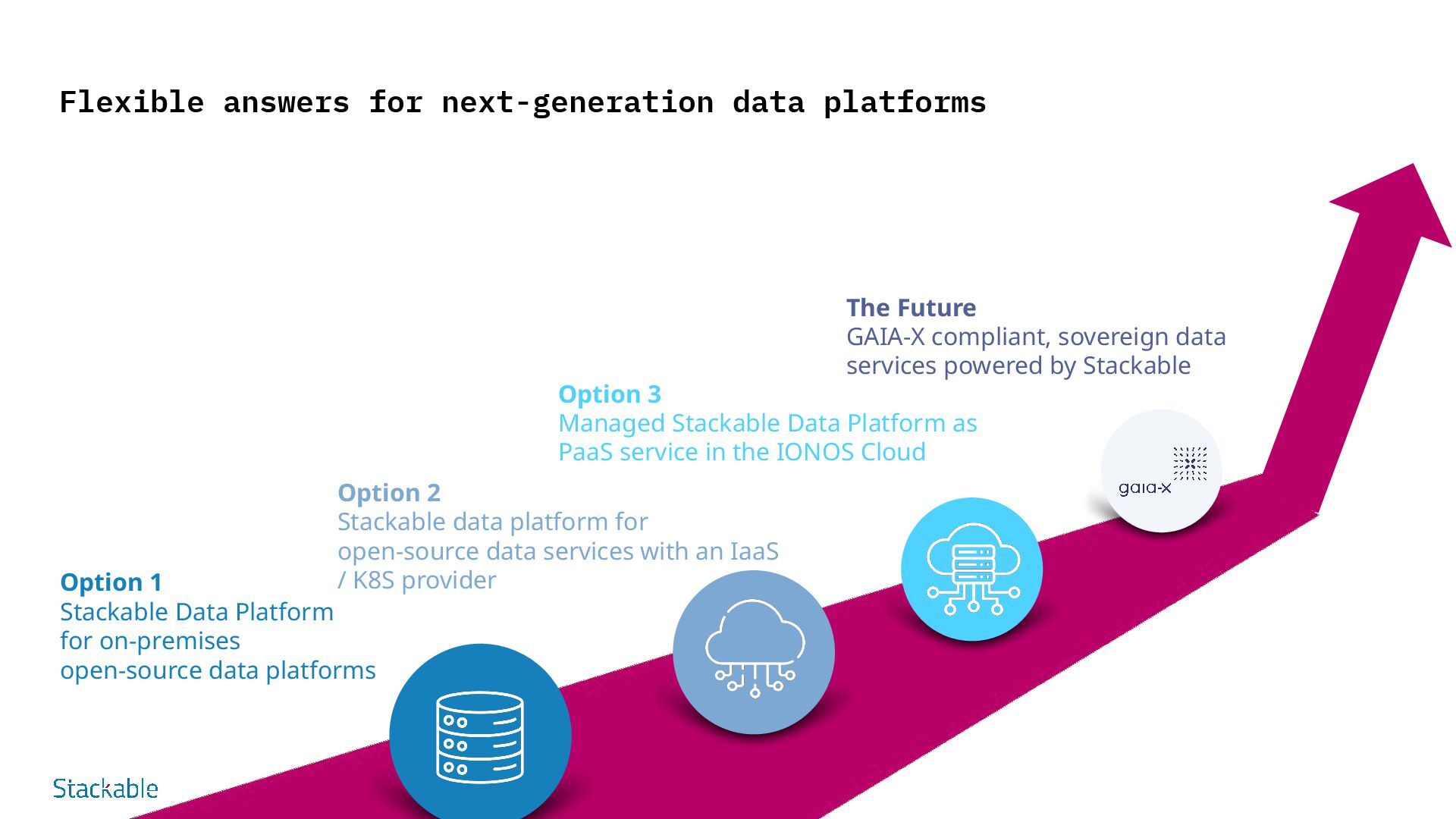
Platform for on-premises open-source data platforms Option 2 Stackable data platform for open-source data services with an IaaS / K8S provider Option 3 Managed Stackable Data Platform as PaaS service in the IONOS Cloud The Future GAIA-X compliant, sovereign data services powered by Stackable
Apache Software Foundation? 2. Do you know what Kerberos is? 3. Have you ever encountered an “No valid path to certificate root”-exception? 4. Ever wonder if the setting “timeout.duration” takes seconds, milliseconds or minutes? 5. Many many many more examples…
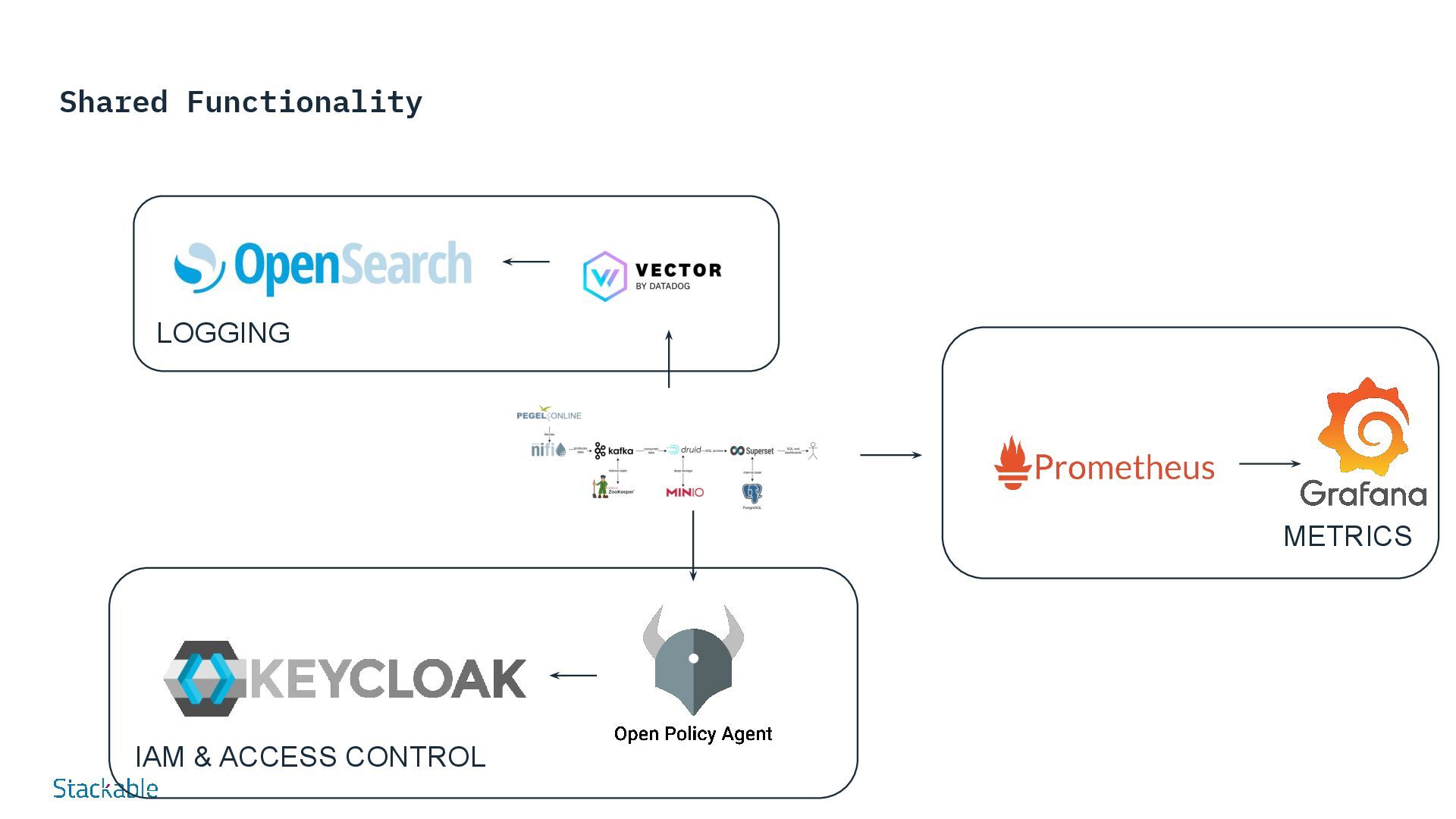
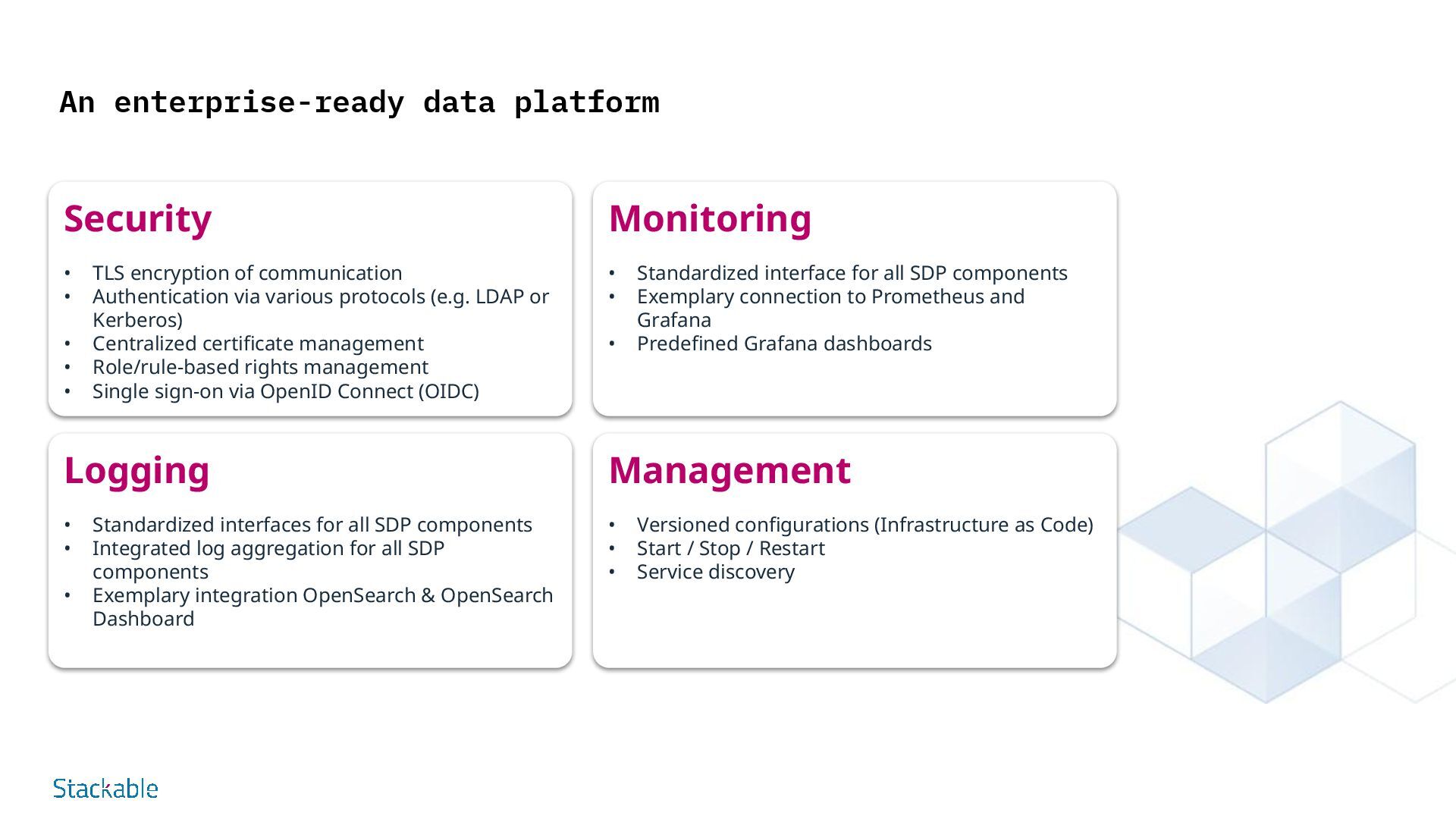
100% open source Modular and flexible In any cloud and in your own data center also as Managed Service with IONOS Cloud Visualization Analytics & AI Data Processing Infrastructure Orchestration Data Ingestion Security Monitoring Logging
and scalability. • Advanced Workflow Orchestration: Apache Airflow provides comprehensive workflow planning and management that enables precise control of data processing tasks within the Stackable Data Platform. • Dynamic Pipeline Creation: Easily define, schedule, and monitor complex data pipelines using Airflow’s intuitive UI and powerful programming framework. Customize your workflows to match your data processing needs perfectly. • Scalable and Reliable: Airflow can be easily scaled. Simultaneous workflows can be handled effortlessly so that data tasks are executed reliably regardless of volume. • Efficient monitoring and logging: Airflow’s monitoring functions enable quick identification and resolution of problems and ensure smooth data operation.
and automated data exchange between systems. • Easy Data Routing and Transformation: Offers a user-friendly interface for data flow management, supporting rapid design and deployment of processing pipelines. • System Integration: Connects to a variety of data sources and sinks, facilitating data ingestion from disparate systems. • Data Lineage: Tracks data flow from source to destination, enhancing auditing and compliance. • Flexibility: Customizable processors and the ability to handle various data formats and sizes. Apache Kafka Distributed event streaming system, providing robust, scalable messaging and stream processing. • High Throughput: Capable of handling millions of messages per second, making it ideal for large-scale message processing tasks. • Scalability: Easily scales out with minimal downtime, supporting growing data needs. • Stability and Reliability: Ensures data is not lost and can withstand failures, maintaining data integrity. • Versatility: Supports a wide range of use cases.
Distributed File System • Fault Tolerance: HDFS is built to handle hardware failures gracefully. It achieves this by data replication and automated recovery. • Scalability: HDFS is designed to handle vast amounts of data and can scale out horizontally by adding more commodity hardware nodes. • High Throughput Access: HDFS is optimized for streaming large files rather than random access. Its design focuses on maximizing data bandwidth, making it ideal for processing large datasets in batch jobs. Apache HBase a distributed, scalable, and NoSQL database designed for real-time read and write access to big data. • Scalability: HBase scales horizontally by adding more nodes to handle increased data and throughput without a significant drop in performance. • High Performance: It is optimized fast random, real-time read/write operations on massive datasets, making it suitable for applications requiring low-latency access to specific rows or columns. • Schema Flexibility: HBase stores data in a column-family format, allowing for sparse datasets and efficient access to specific data subsets. It doesn't enforce a fixed schema, enabling flexibility to add or modify columns on the fly without downtime. Apache Druid Provides real-time analytics and OLAP querying capabilities, ideal for insights on streaming data. • Real-Time Analytics: Designed for sub-second query response times, making it ideal for interactive applications. • Scalability: Handles massive volumes of data and concurrent users without compromising performance. • High Availability: Distributed architecture ensures that the system is always on and can serve queries even during partial failures.
improves the flexibility and speed of queries. • Flexible Table Formats: Supporting Apache Iceberg and Delta Lake. • Fast Query Processing: Engineered for high-speed data querying across distributed data sources. • Federated Queries: Allows querying data from multiple sources, simplifying analytics across disparate data stores (data federation). • Scalable and Flexible: Easily scales to accommodate large datasets and complex queries. Apache Spark Offers powerful data processing capabilities, enabling performant complex analytics and machine learning on big data. • In-Memory Computing: Accelerates processing speeds by keeping data in RAM, significantly faster than disk-based alternatives. • Advanced Analytics: Supports complex algorithms for machine learning, graph processing, and more. • Fault Tolerance: Resilient distributed datasets (RDDs) provide fault tolerance through lineage information. • Language Support: Offers APIs in Python, Java, Scala, and R, broadening its accessibility and usability. Apache Hive Metastore A centralized repository for storing metadata about Hive tables, databases, and other schema-related objects. • Centralized Metadata Management: Maintains metadata for all Hive tables, e.g. schema information, table locations, partitioning, and more. It enables seamless integration with tools like Apache Spark, Trino, and other query engines that rely on Hive for schema discovery. • Partition and Schema Handling: Partition awareness significantly improves query performance for large datasets by partition pruning. • Schema Evolution: It supports schema changes, such as adding or modifying columns, without requiring migration of existing data. SDP: Data Processing
and visualization platform. • Interactive Data Exploration: It provides an intuitive interface for querying and exploring data. Users can write SQL queries or use drag-and-drop features to slice, filter, and group data interactively. • Custom SQL Lab: A powerful SQL IDE for running queries against databases and visualizing results in real time. • Advanced Data Visualization: It supports a wide variety of rich, interactive charts and dashboards, such as bar charts, heatmaps, time series, maps, and more. • Customizable Dashboards: Users can create and organize visualizations into shareable dashboards with drag-and-drop ease. • Integration with Popular Databases: Superset connects seamlessly to a broad range of databases via SQLAlchemy, including Trino, Druid, MySQL, PostgreSQL and others.
367 vulnerabilities that were found in your application from the Compliance department with the request to “comment on these please” ? 2. Have you ever tried to find someone actually knowledgeable in the support department of one of your large vendors? 3. Have you ever tried buying support for an open source product?
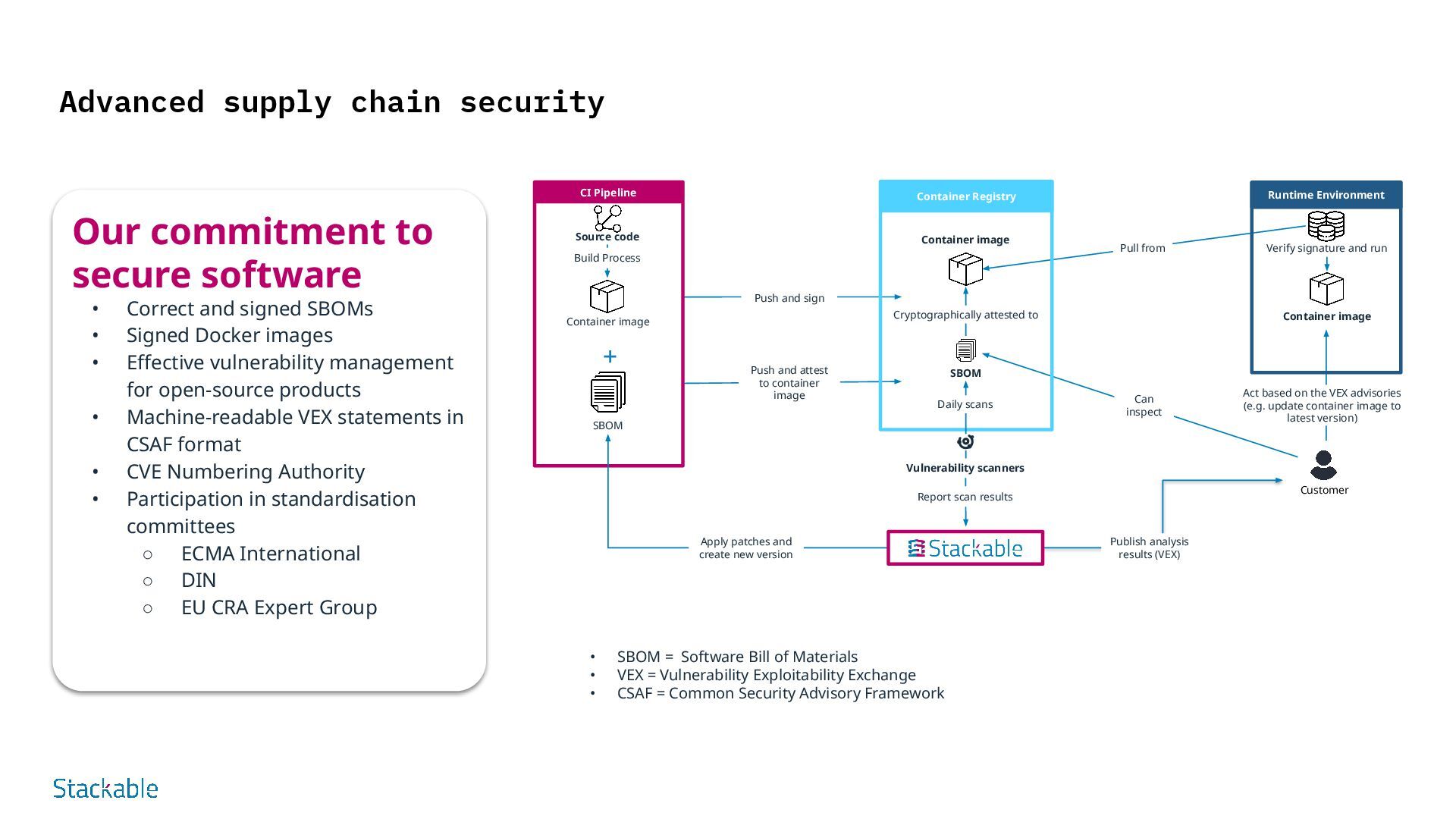
Environment Container Registry Source code Container image SBOM Container image Customer Act based on the VEX advisories (e.g. update container image to latest version) Build Process Report scan results Cryptographically attested to Apply patches and create new version Publish analysis results (VEX) Daily scans Pull from SBOM Container image Push and sign Push and attest to container image Verify signature and run Can inspect + Our commitment to secure software • Correct and signed SBOMs • Signed Docker images • Effective vulnerability management for open-source products • Machine-readable VEX statements in CSAF format • CVE Numbering Authority • Participation in standardisation committees ◦ ECMA International ◦ DIN ◦ EU CRA Expert Group • SBOM = Software Bill of Materials • VEX = Vulnerability Exploitability Exchange • CSAF = Common Security Advisory Framework
Engineer Andrew Data Architect Lukas Software Engineer Benedikt Software Engineer Xenia Site Reliability Engineer Nick Rust Developer Sebastian Software Engineer Maximilian Software Engineer Big Data Consulting • Big data architecture consulting • Data Platform workshops • Migration support • Big data team advisor • Workshops on the open source data products Big Data Training • Stackable Data Platform basics • Big data ecosystem overview • Big data security • High availability • Monitoring and optimization of clusters
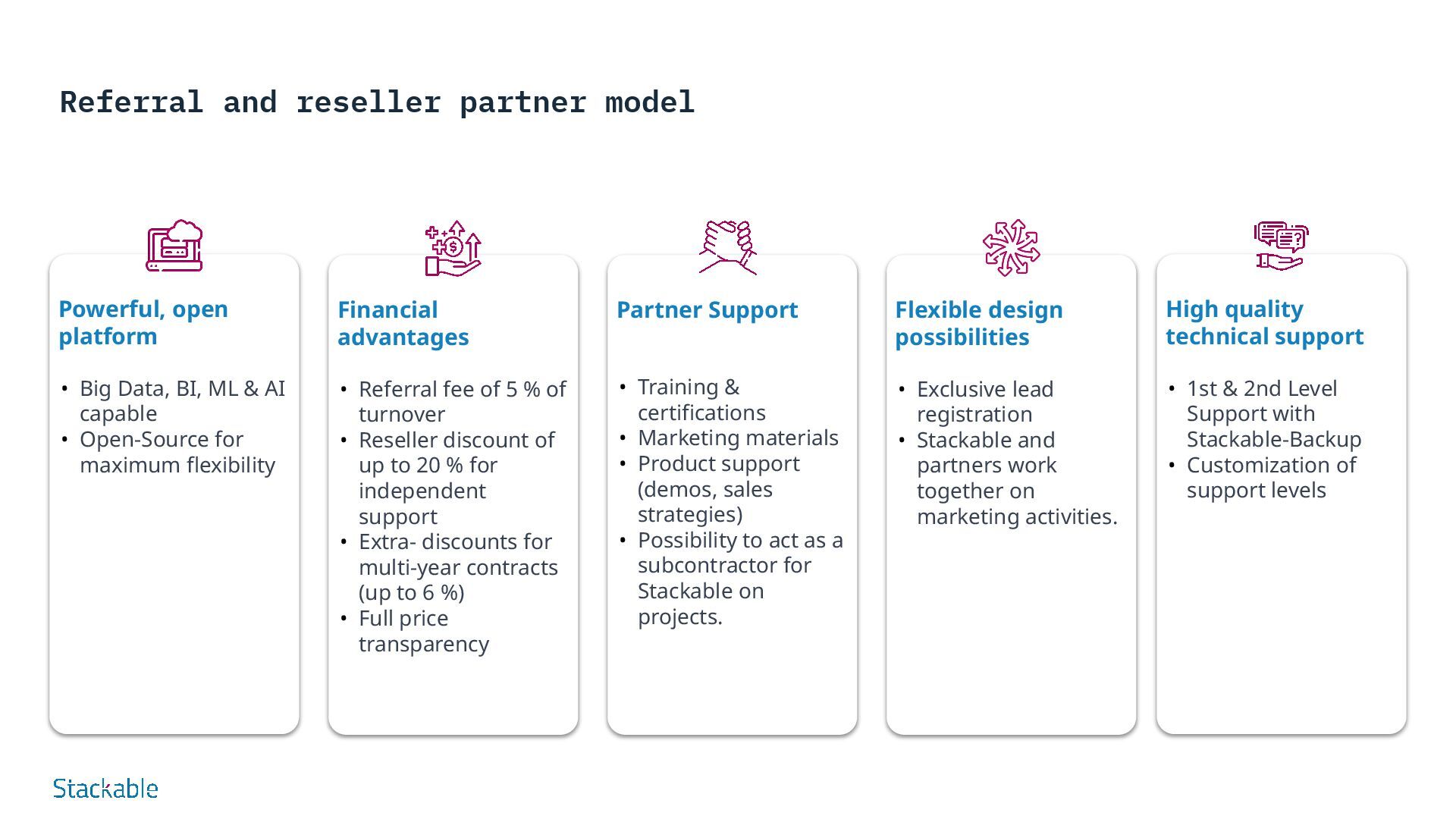
• Big Data, BI, ML & AI capable • Open-Source for maximum flexibility Financial advantages • Referral fee of 5 % of turnover • Reseller discount of up to 20 % for independent support • Extra- discounts for multi-year contracts (up to 6 %) • Full price transparency Partner Support • Training & certifications • Marketing materials • Product support (demos, sales strategies) • Possibility to act as a subcontractor for Stackable on projects. Flexible design possibilities • Exclusive lead registration • Stackable and partners work together on marketing activities. High quality technical support • 1st & 2nd Level Support with Stackable-Backup • Customization of support levels
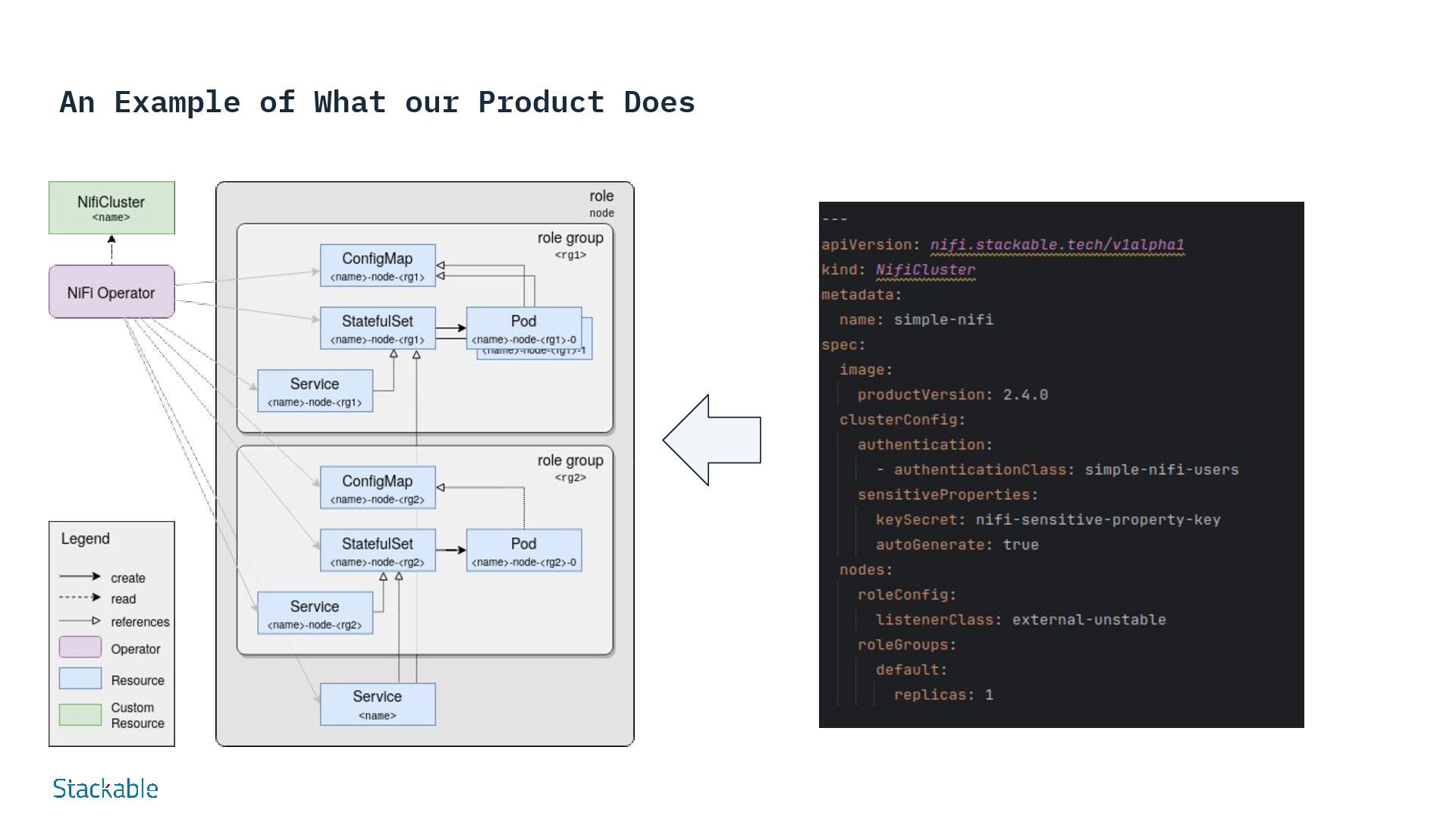
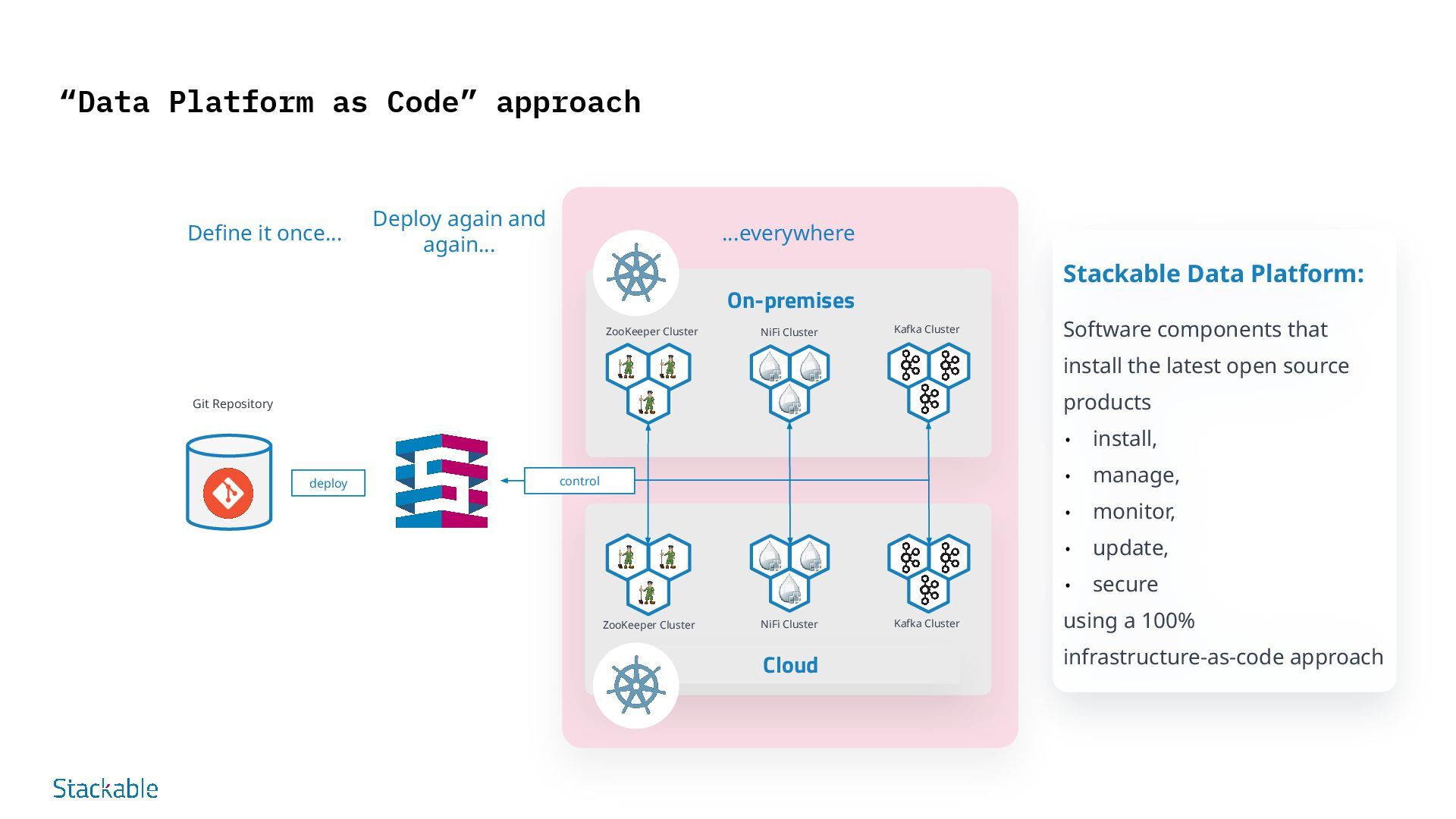
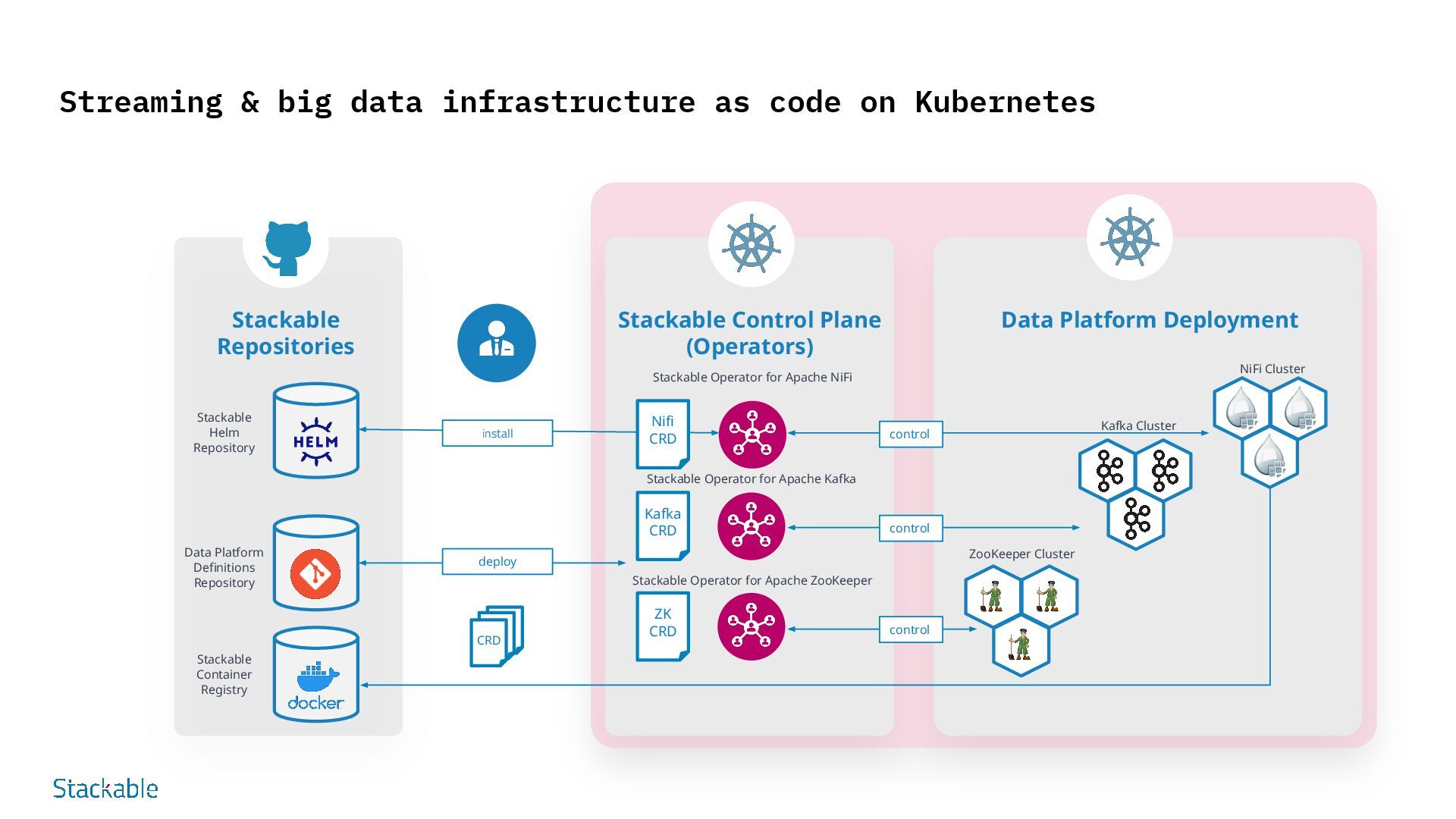
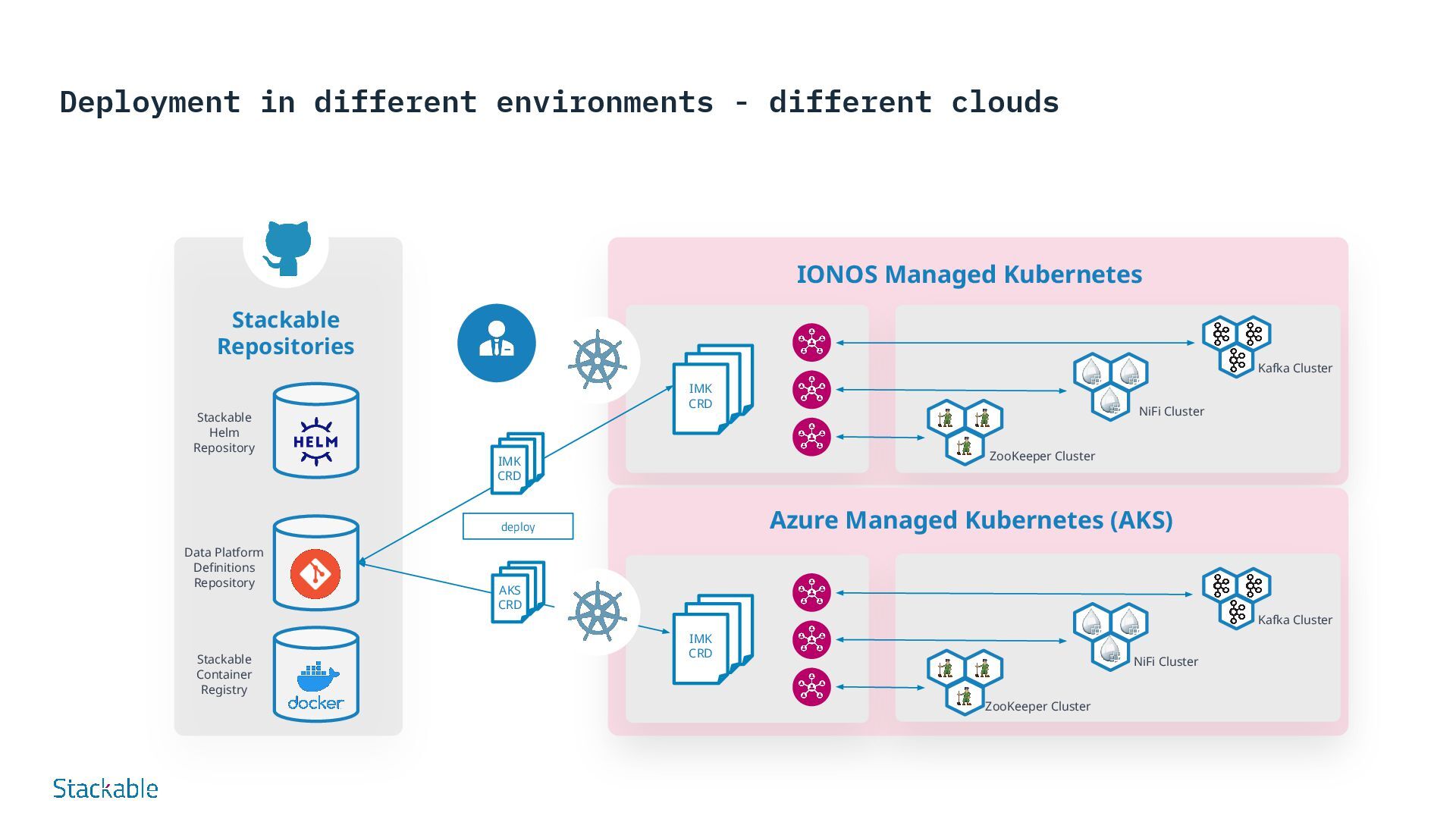
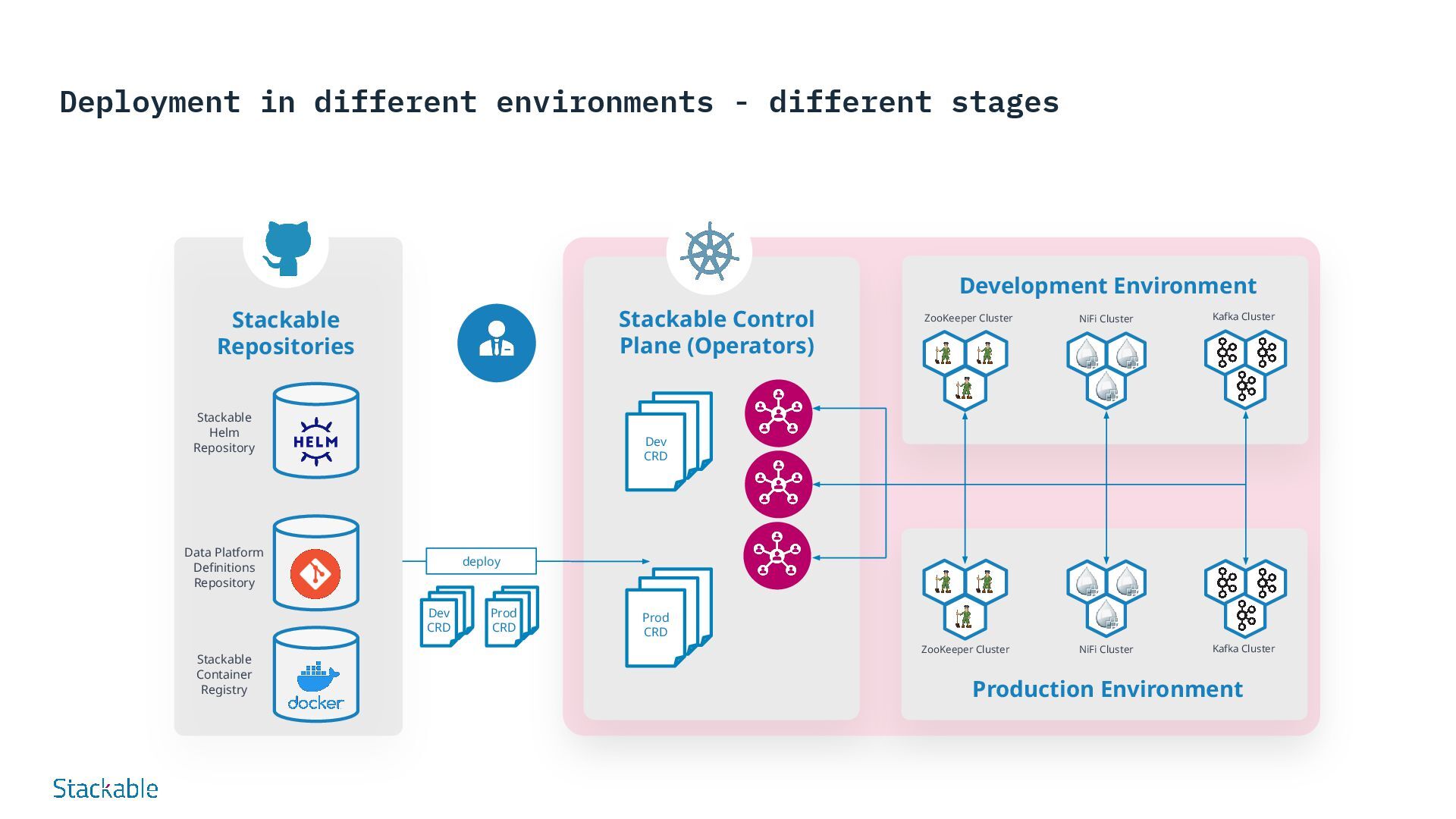
on Infrastructure-as-Code (IaC) Stackable data platforms are defined declaratively in order to specify configurations such as size, components and use cases. This enables automated, standardized and efficient deployment via GitOps. Advantages: Consistency Standardized environments, fewer errors Speed Faster deployment and updates Version control Comprehensible changes, simple rollbacks Collaboration Clearly defined configurations promote teamwork Security Integrated compliance and security checks
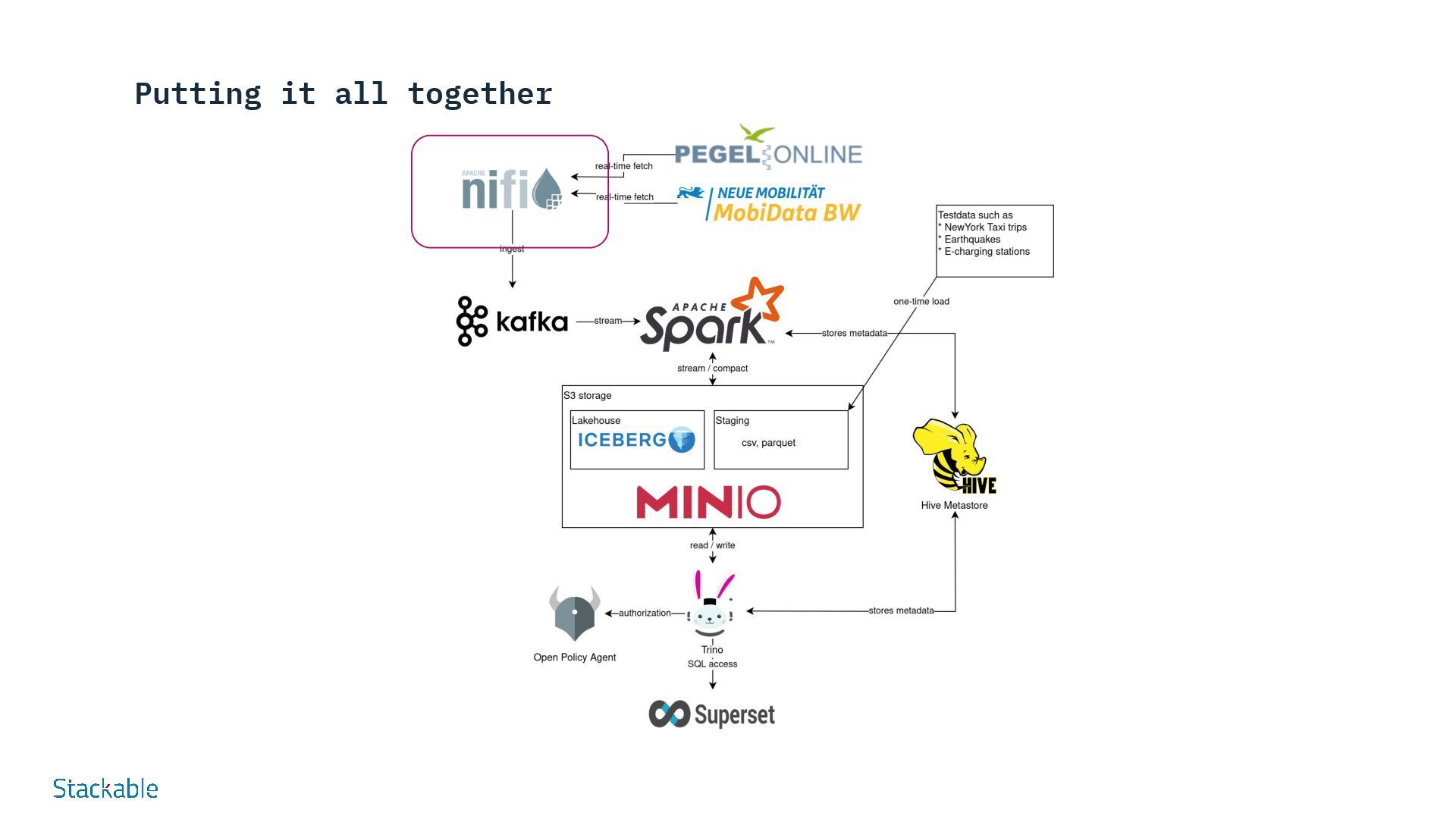
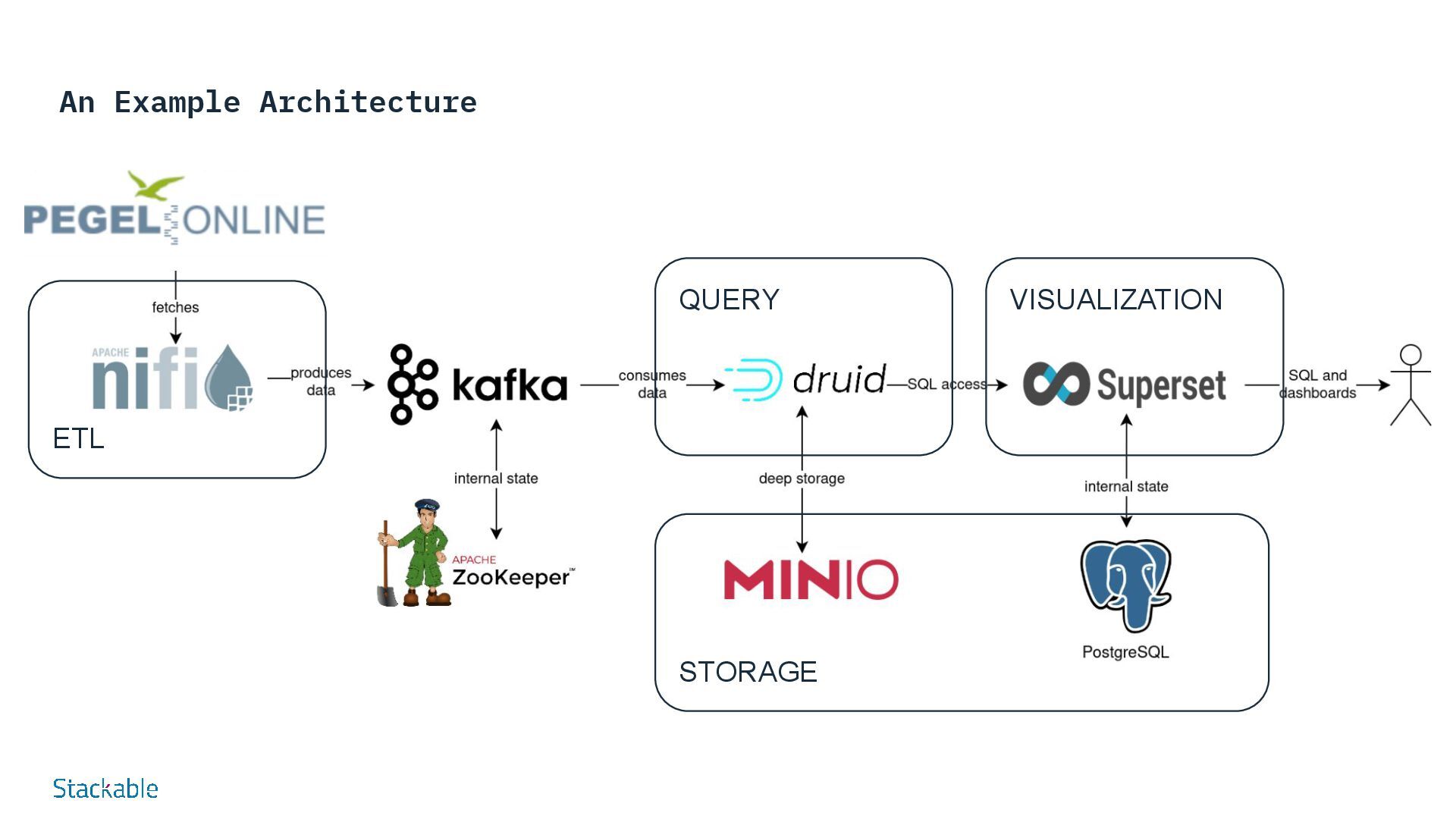
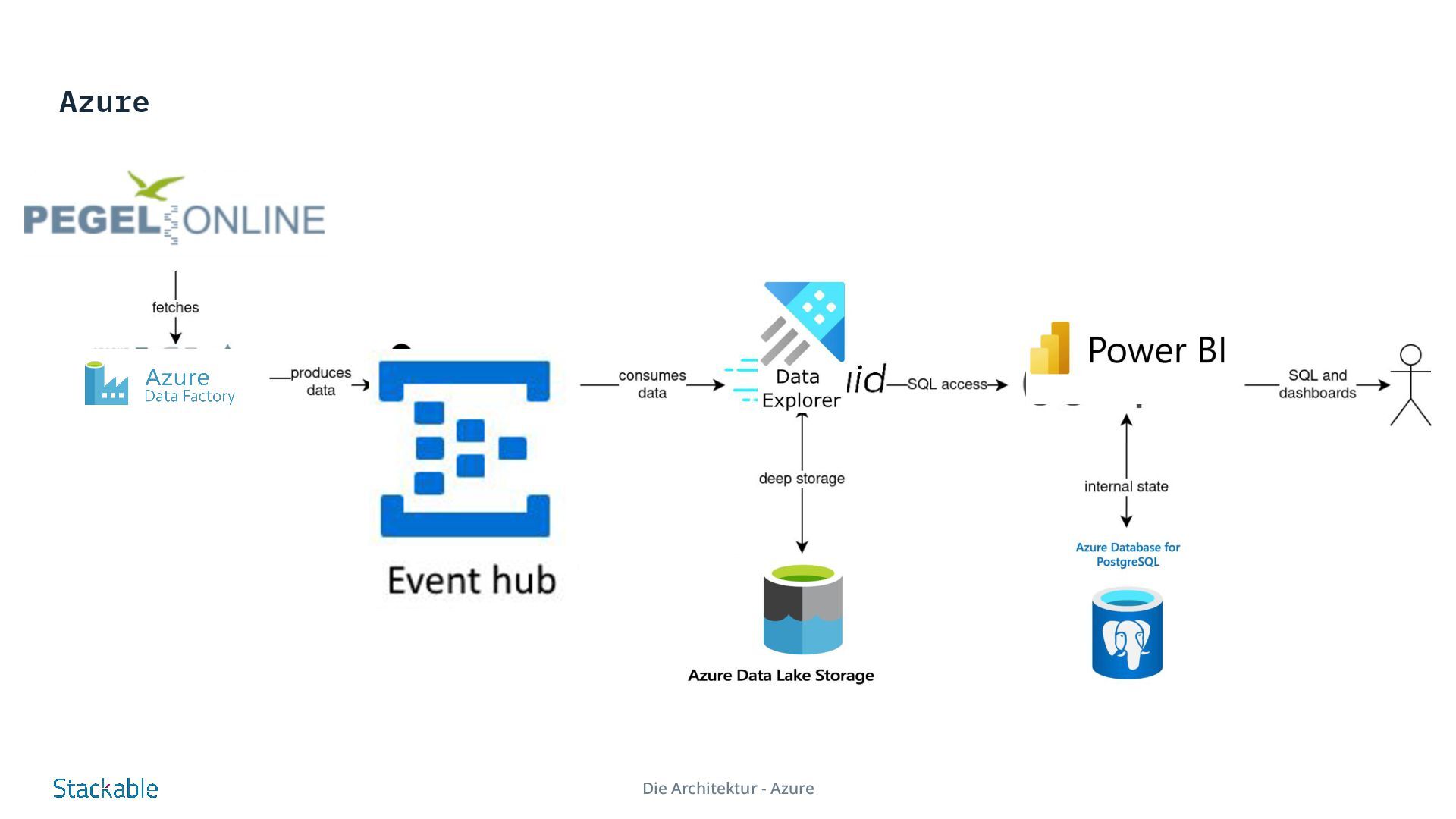
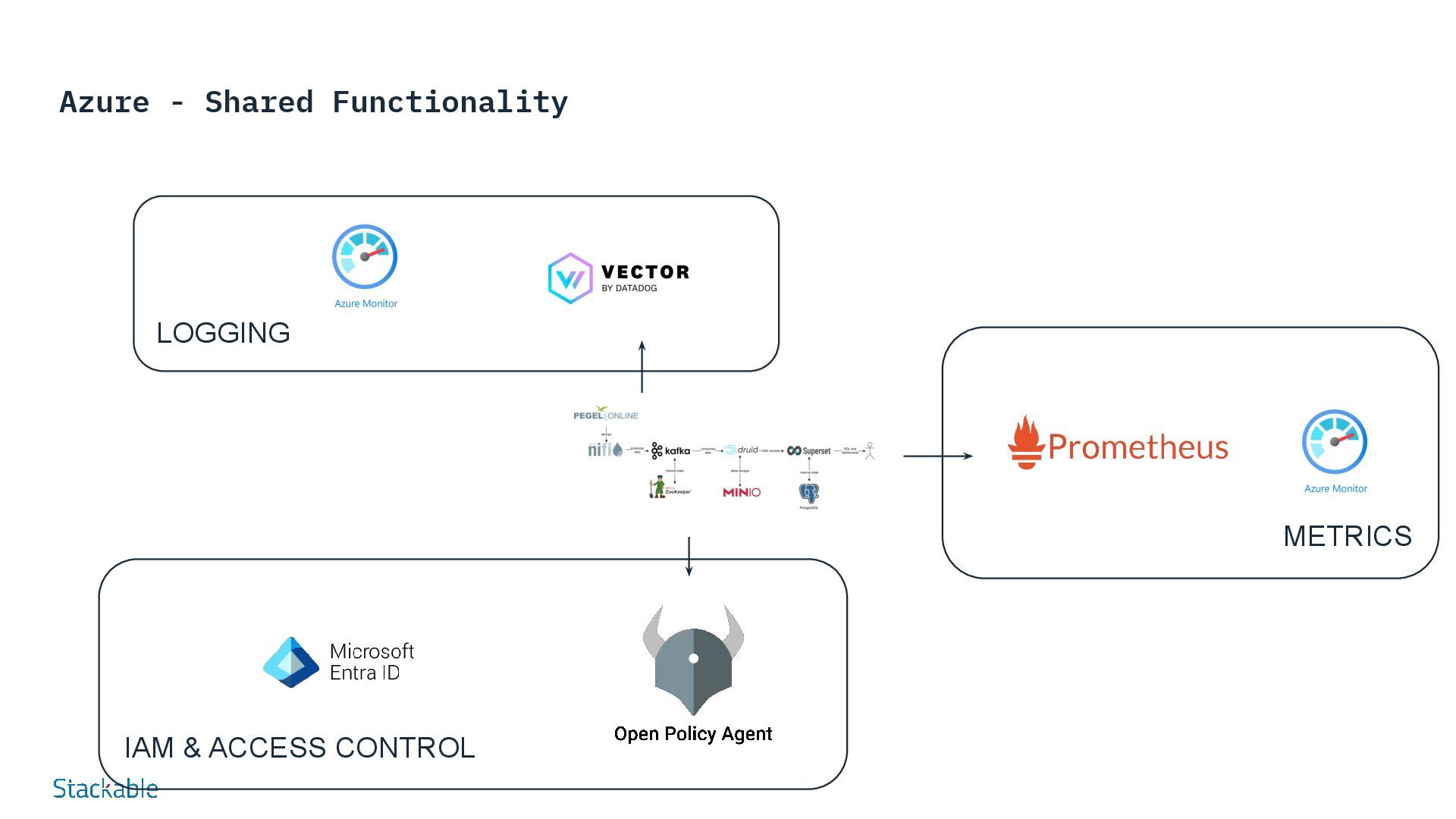
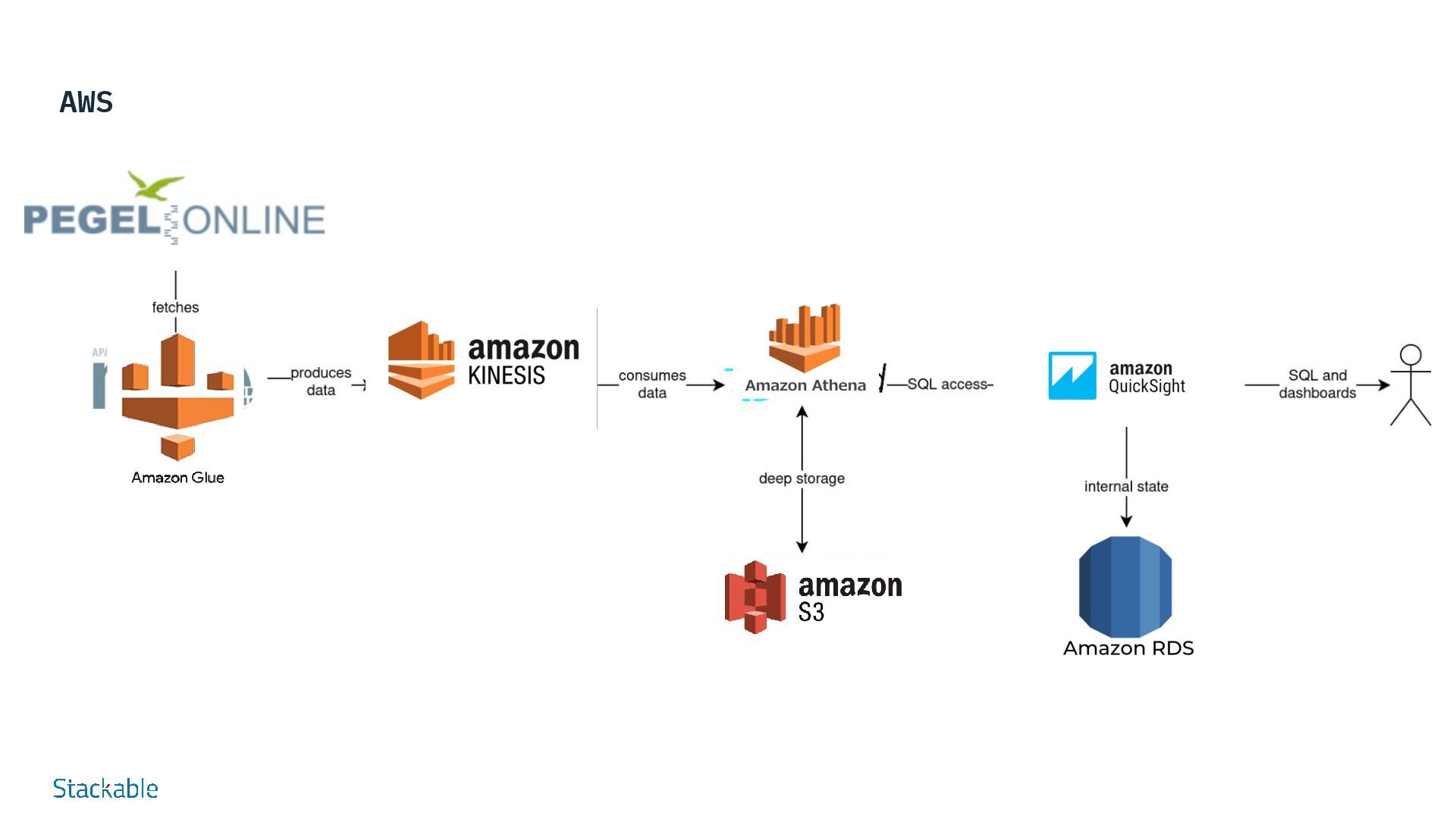
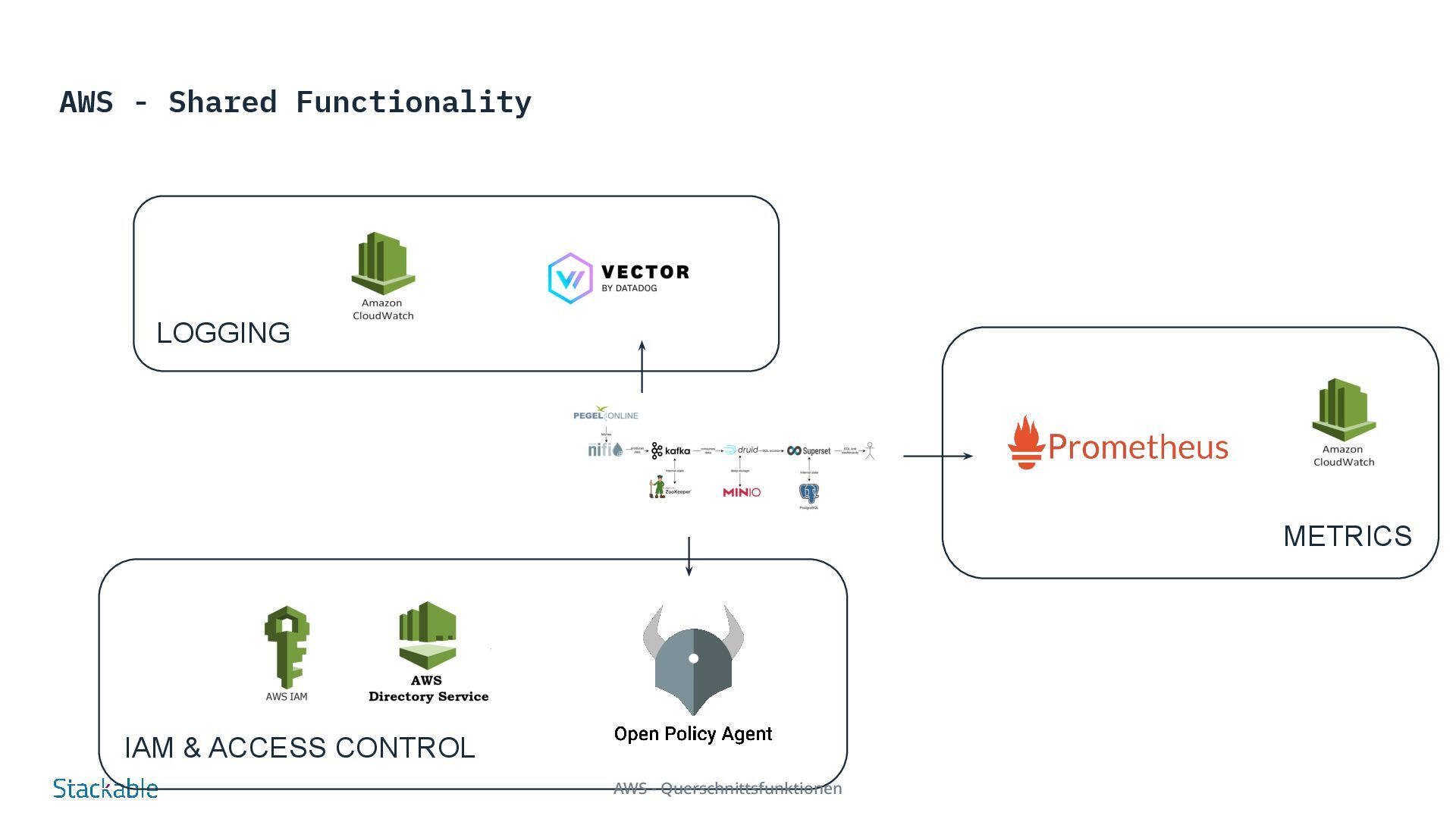
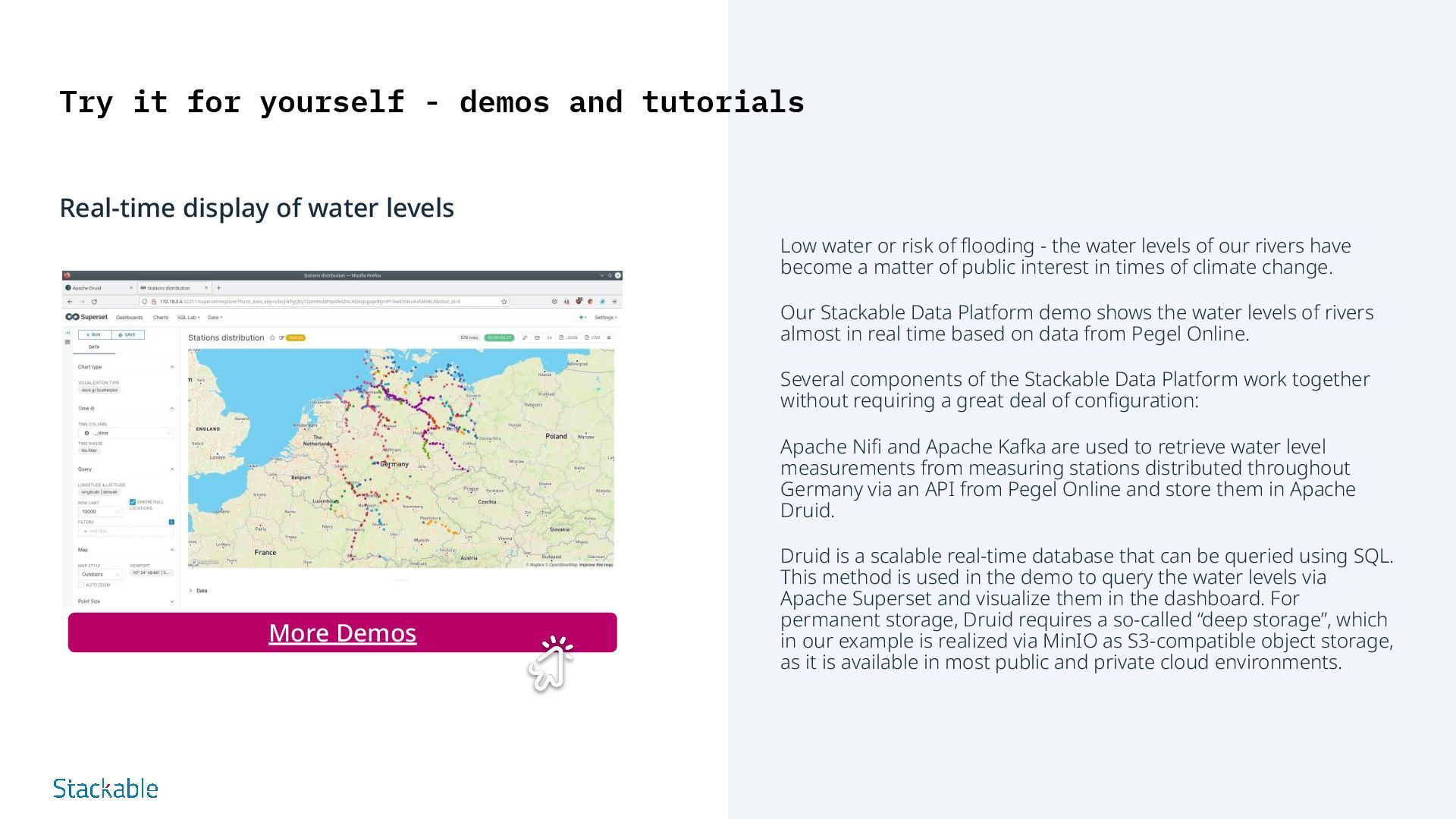
of our rivers have become a matter of public interest in times of climate change. Our Stackable Data Platform demo shows the water levels of rivers almost in real time based on data from Pegel Online. Several components of the Stackable Data Platform work together without requiring a great deal of configuration: Apache Nifi and Apache Kafka are used to retrieve water level measurements from measuring stations distributed throughout Germany via an API from Pegel Online and store them in Apache Druid. Druid is a scalable real-time database that can be queried using SQL. This method is used in the demo to query the water levels via Apache Superset and visualize them in the dashboard. For permanent storage, Druid requires a so-called “deep storage”, which in our example is realized via MinIO as S3-compatible object storage, as it is available in most public and private cloud environments. Try it for yourself - demos and tutorials Real-time display of water levels More Demos
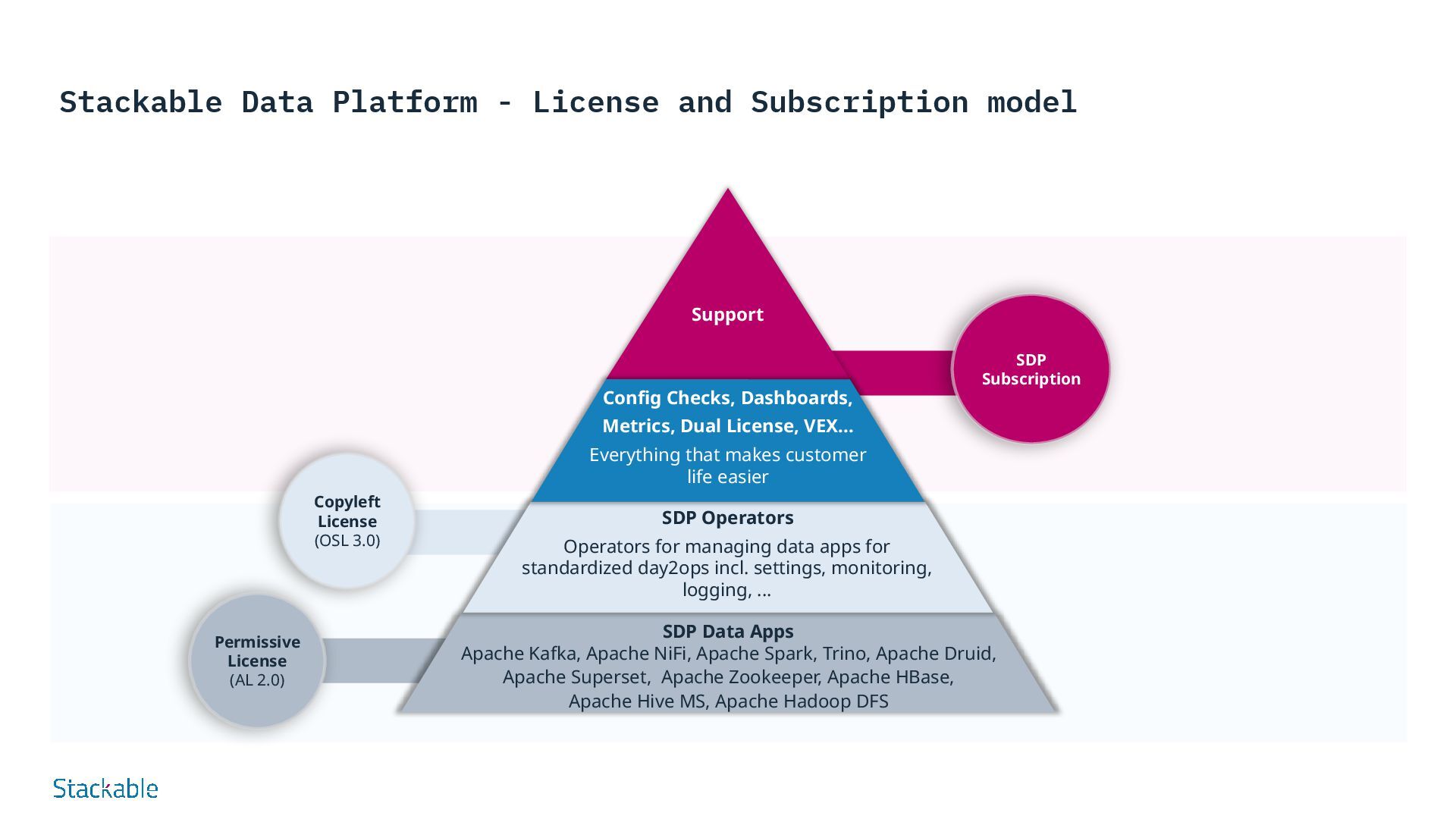
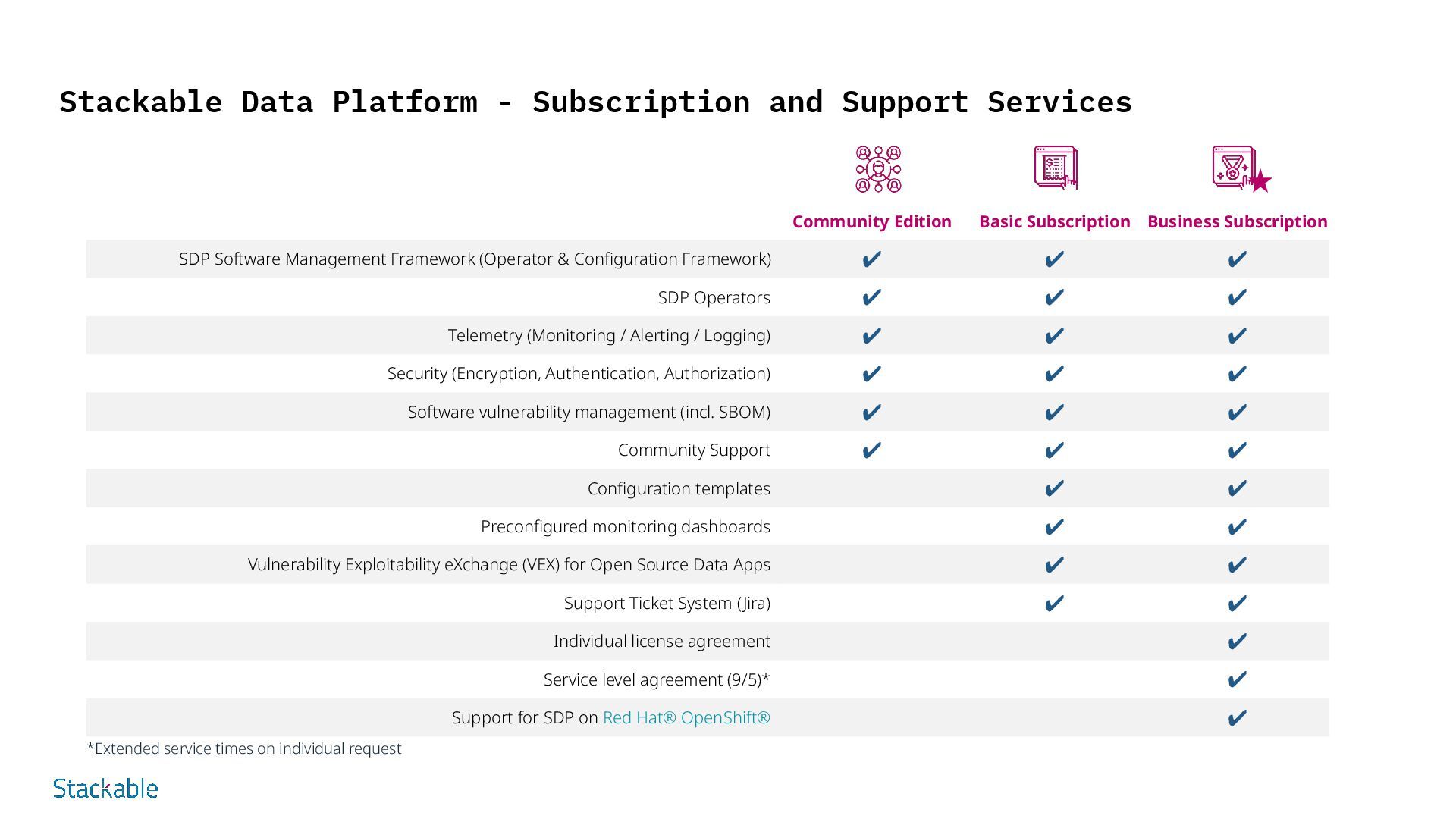
strategy requirements. SDP QuickStart Experienced Stackable consultants support the customer in live sessions. After an introduction to Kubernetes, initial installation options will be discussed and practical installation support will be offered. Finally, Stackable will support the customer with the next steps. The customer will then be able to use the SDP for initial deployment and/or further assessments. SDP QuickCheck Workshops are used to record, evaluate and analyze the current situation. Use cases are then collected and evaluated. The current situation and the use cases form the basis for an initial outline of the target architecture and implementation recommendations. As a result, the discussed solution approaches are provided as a rough concept including a functional reference architecture and a possible roadmap. SDP PoC Depending on the customer situation, a longer-term professional proof of concept is developed with the customer. Initial use cases are implemented with the help of Stackable consultants. The customer receives a detailed picture of Stackable as a new data platform. SDP Subscription An SDP subscription entitles the customer to Stackable support throughout the entire lifecycle of use. Different support models offer specific options to meet the customer's need for longer support: whether by informal email, 5/9 or even 24/7 helpdesk, all with or without SLAs, Stackable can cover most situations - even as a layer with a customer-owned multi-level support organization. starting at 10.000 EUR starting at 16.000 EUR starting at 11.000 EUR starting at 1.600 EUR
solutions for every industry Urban data platforms for smart cities https://stackable.tech/en/open-source-data-platform/ Data catalogue & metadata Highlights: Data integration & aggregation Open Source & cloud-first Urban Data Platforms
solutions for every industry Real-time Fraud Detection https://stackable.tech/en/financialservices/ Security By Design Highlights: Open Source & Support Private & Public Cloud Support Financial Services
solutions for every industry Performance monitoring for modern waste-to-energy solutions https://stackable.tech/en/data-platform-for-manufacturing-industry/ Batch Processing & Reporting Highlights: (Real-)Time Streaming Processing & Monitoring Self-Service-Analytics Manufacturing
solutions for every industry Gaia-X Data Spaces https://stackable.tech/en/gaia-x-dataspaces/ Identity and trust Highlights: Data exchange Orchestration of services Data Spaces
solutions for every industry Gaia-X Industrial Data Spaces https://stackable.tech/en/gaia-x-dataspaces/ Trustworthy supply chains Highlights: Digital twins Platform-based maintenance Data Spaces
solutions for every industry FAIR and Open Data https://stackable.tech/en/opendata/ Data access and interoperability Highlights: (Meta)data standardization Data Governance Open Data
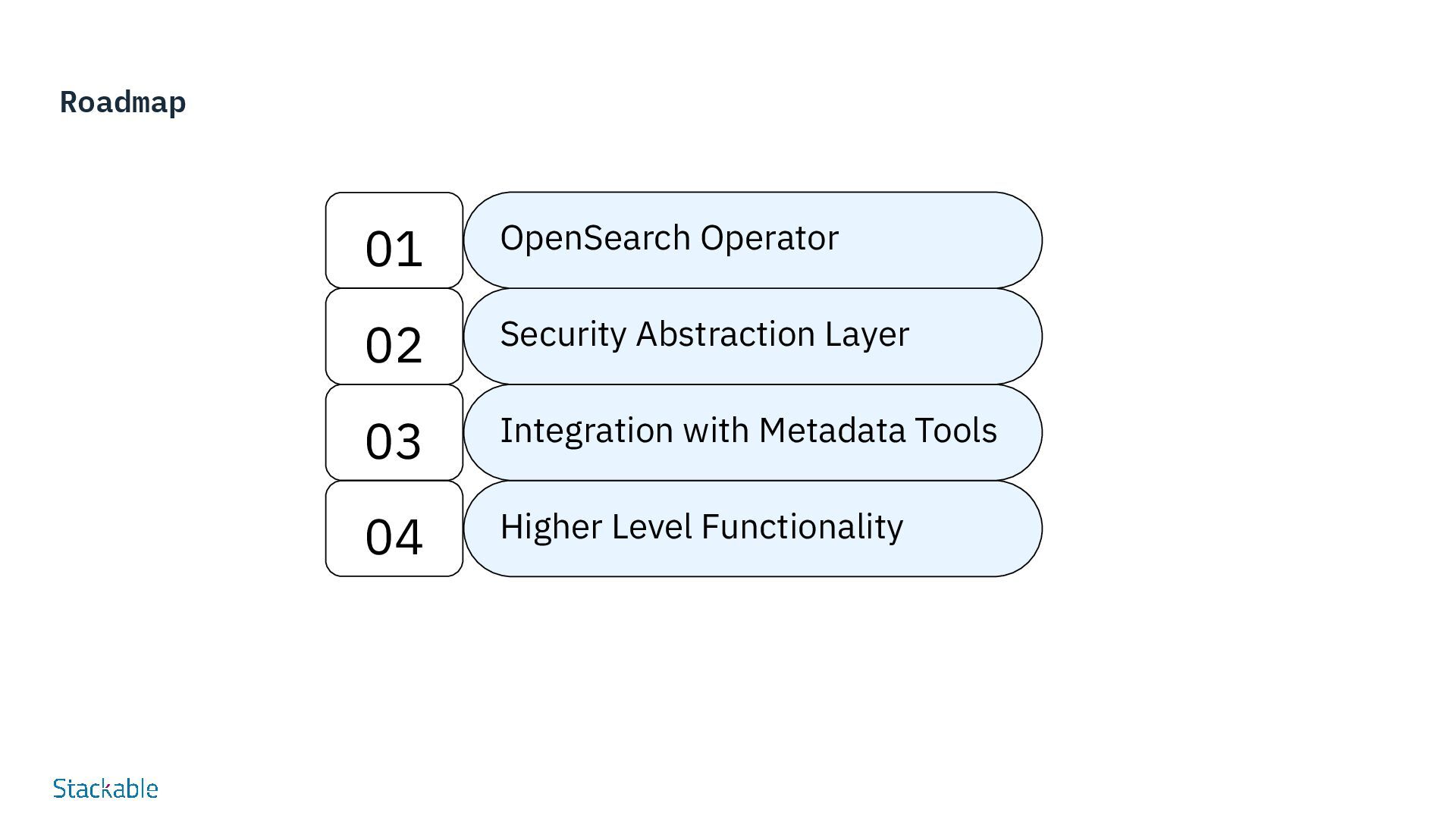
background, financial 2. Mission and Vision 3. Pains and challenges you address 4. Why Stackable and value prop. aligned on these challenges 5. Products pitch and details (how it works), and how do you solve these pains 6. Demo if you consider it add values to the pitch 7. Use cases 8. Case studies (references even anonymous) 9. Competition and differentiators, why you win 10. Roadmap 11. Go to market, partner ecosystem, oem, distribution/reseller 12. Pricing model (Preise nicht schreiben, aber sagen) 13. A bit of future directions for the company and product, what's next 14. Questions, questions, questions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Contact: Sönke Liebau [email protected] +49 4103 926 3100](https://files.speakerdeck.com/presentations/fb8b7ce3b4e74a8eb3d8d458dd70d1e6/slide_81.jpg){kind=link}