I joined NVIDIA in 2019 and I was brand new to GPU development. In that time, I’ve gotten to grips with the fundamentals of writing accelerated code in Python. I was amazed to discover that I didn’t need to learn C++ and I didn’t need new development tools. Writing GPU code in Python is easier today than ever, and in this tutorial, I will share what I’ve learned and how you can get started with accelerating your code.
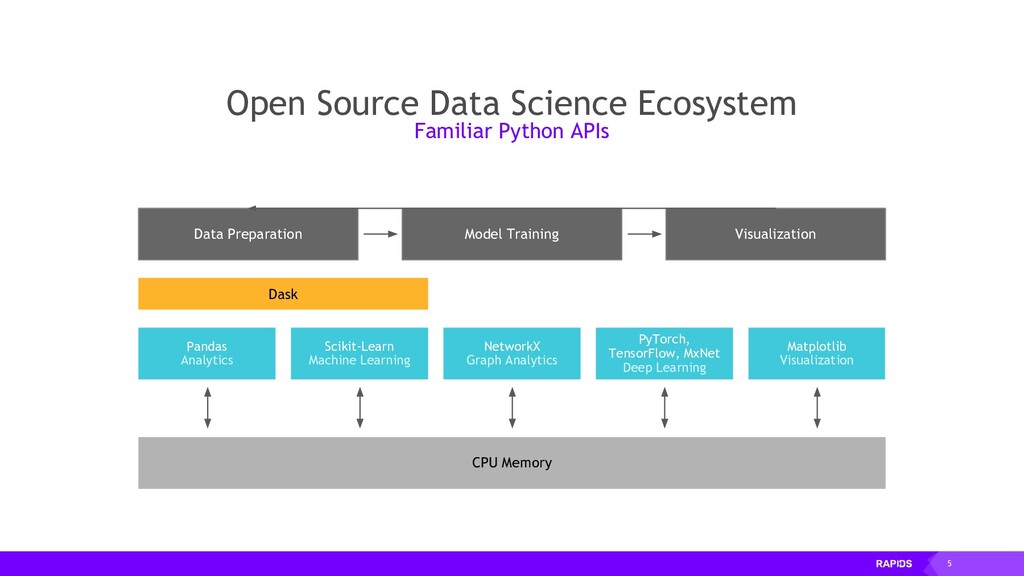
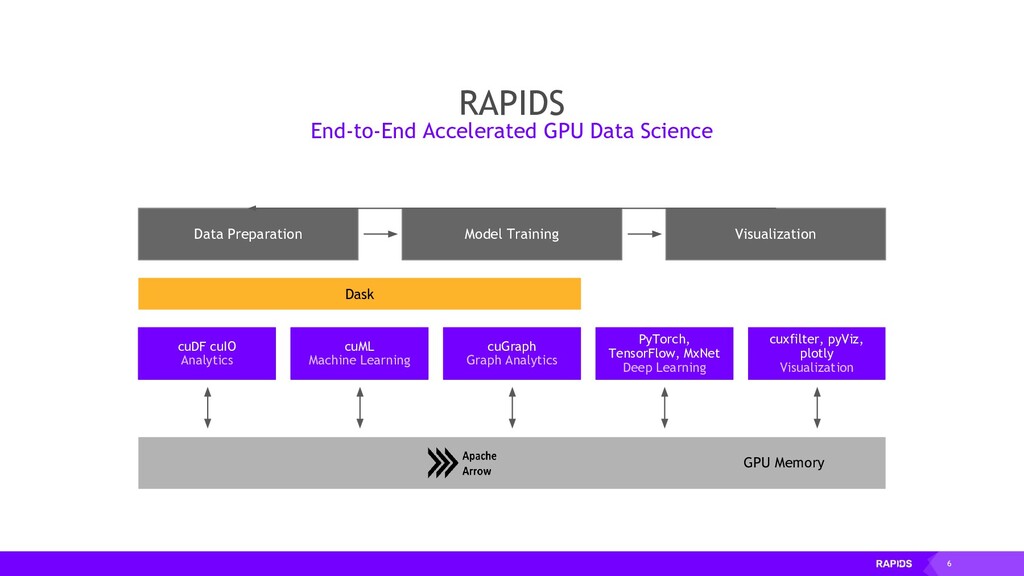
Once we’ve written a bit of GPU code we will look at some open source Python libraries that are part of the RAPIDS suite of tools. These libraries follow familiar APIs from the PyData ecosystem for working with Dataframes, ND-Arrays and doing statistics and machine learning, but under the hood they’ve been rewritten to run on NVIDIA GPUs giving large performance gains.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
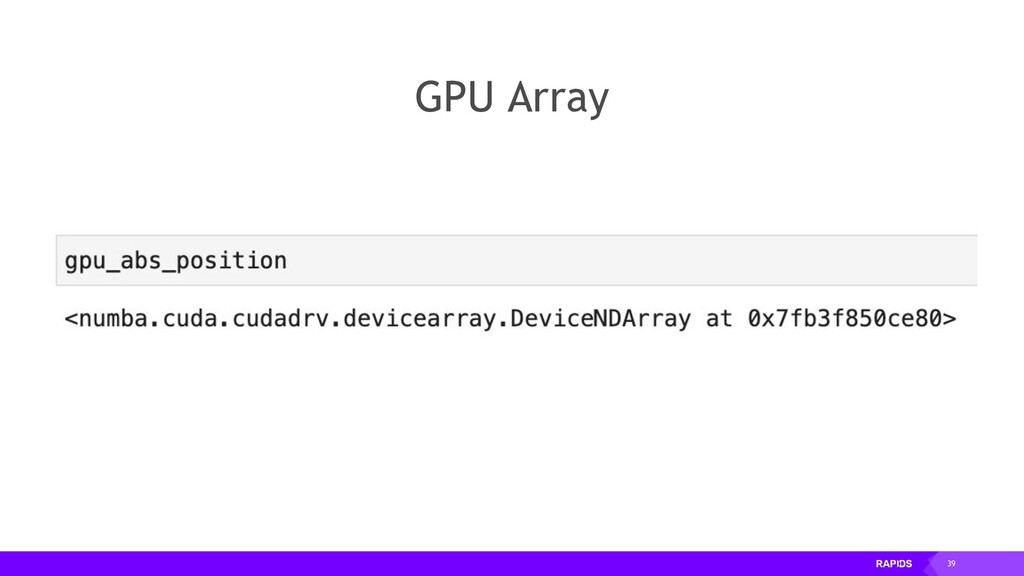{kind=link}
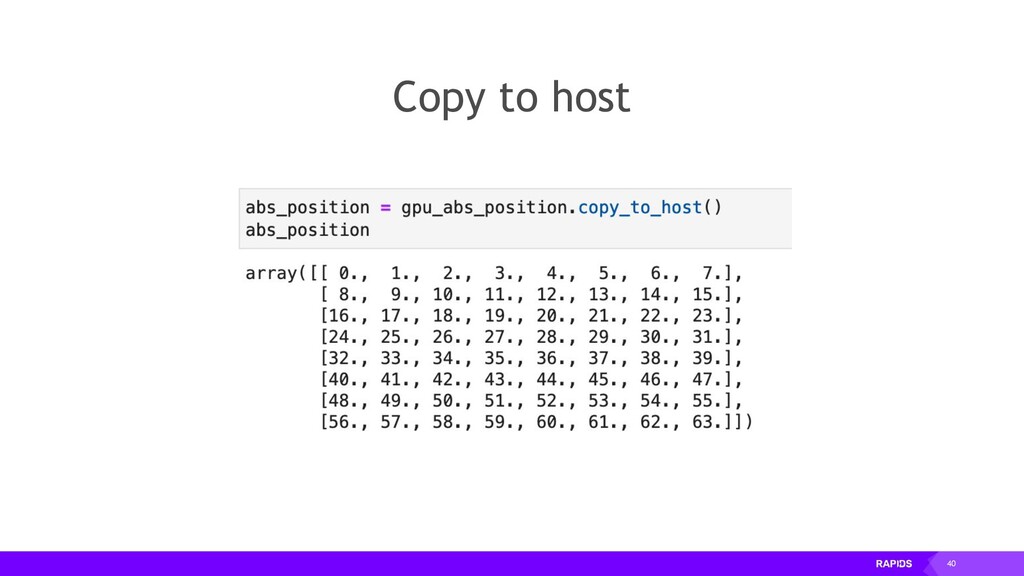{kind=link}
{kind=link}
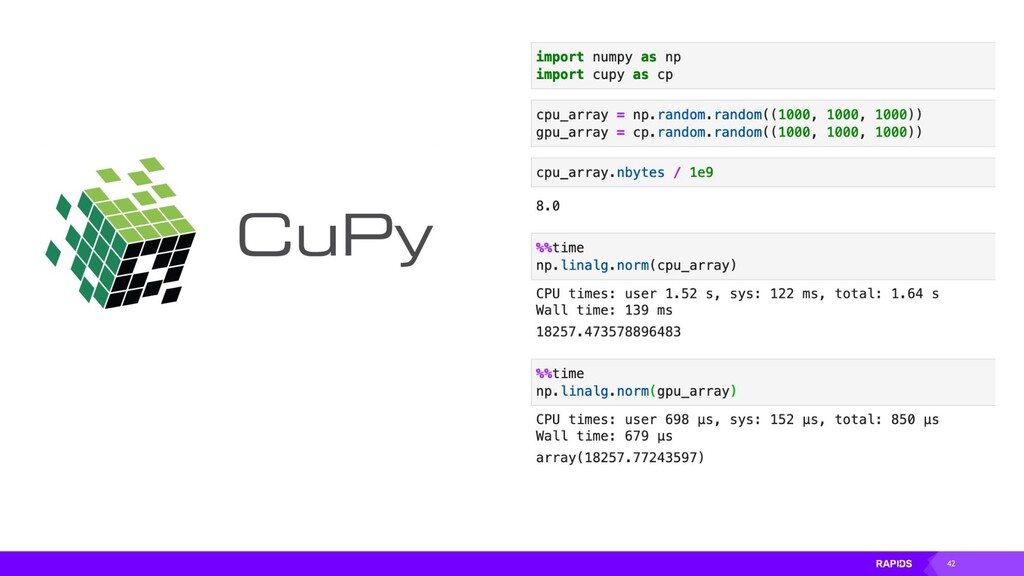{kind=link}
{kind=link}
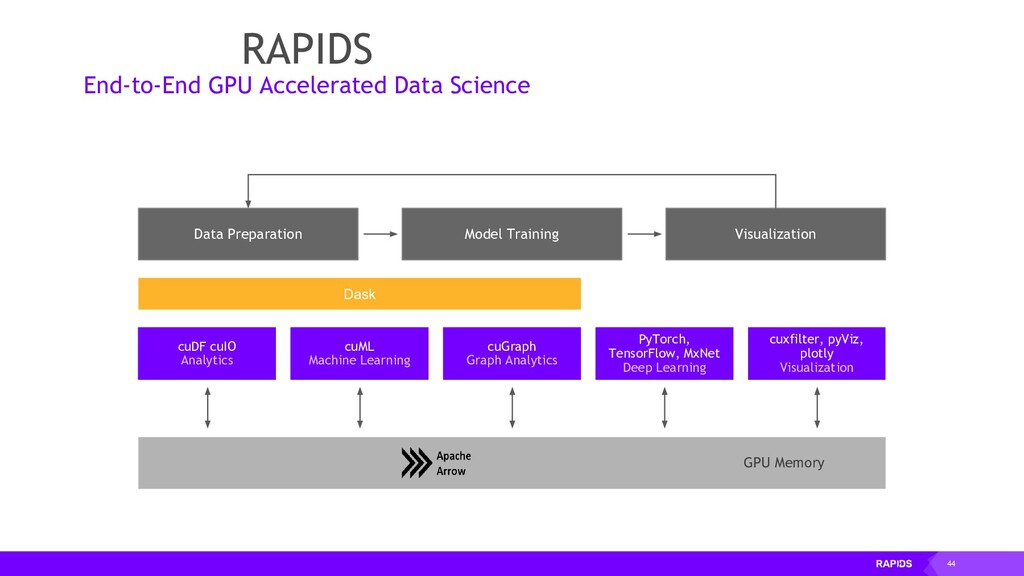{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}