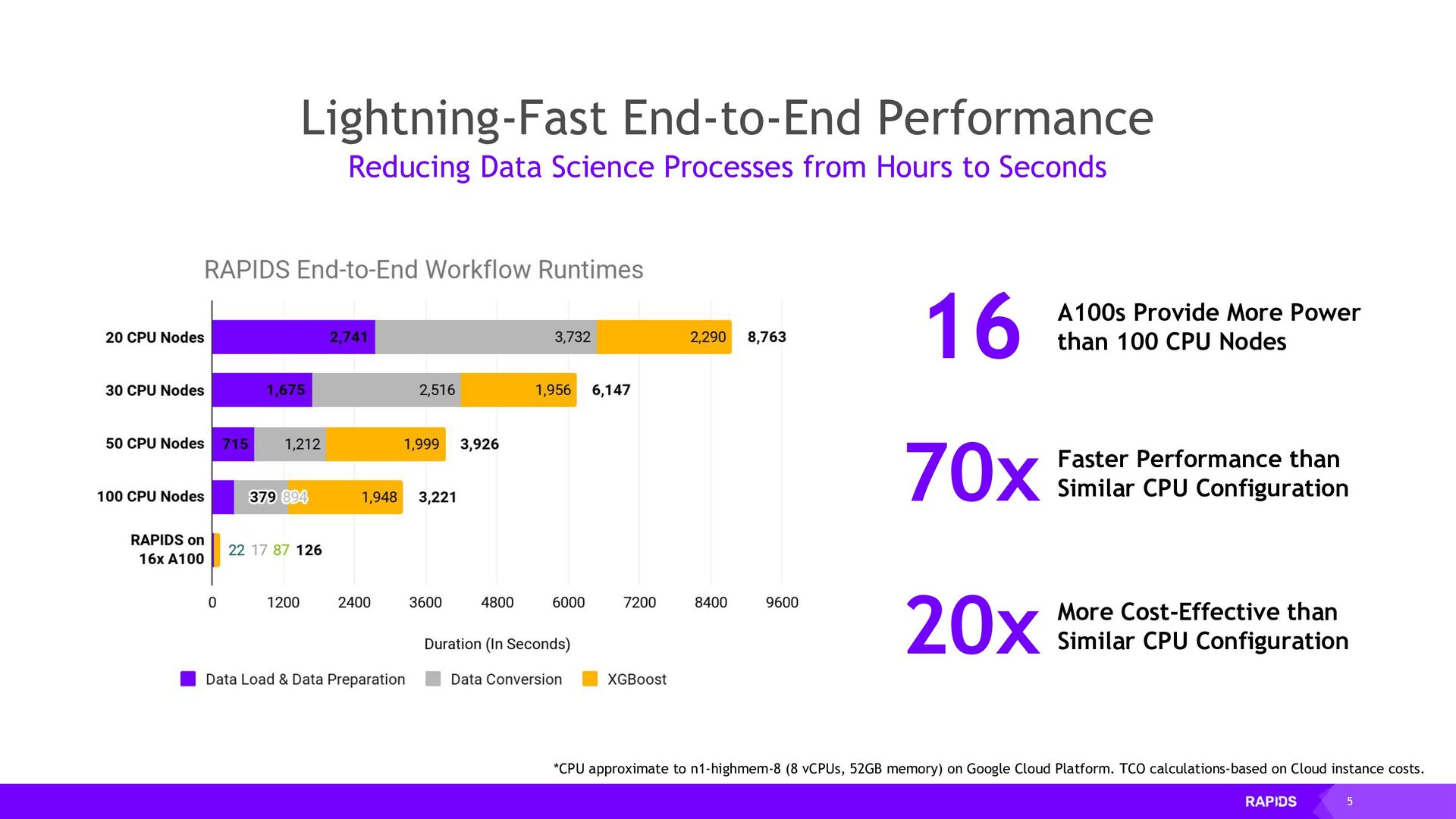
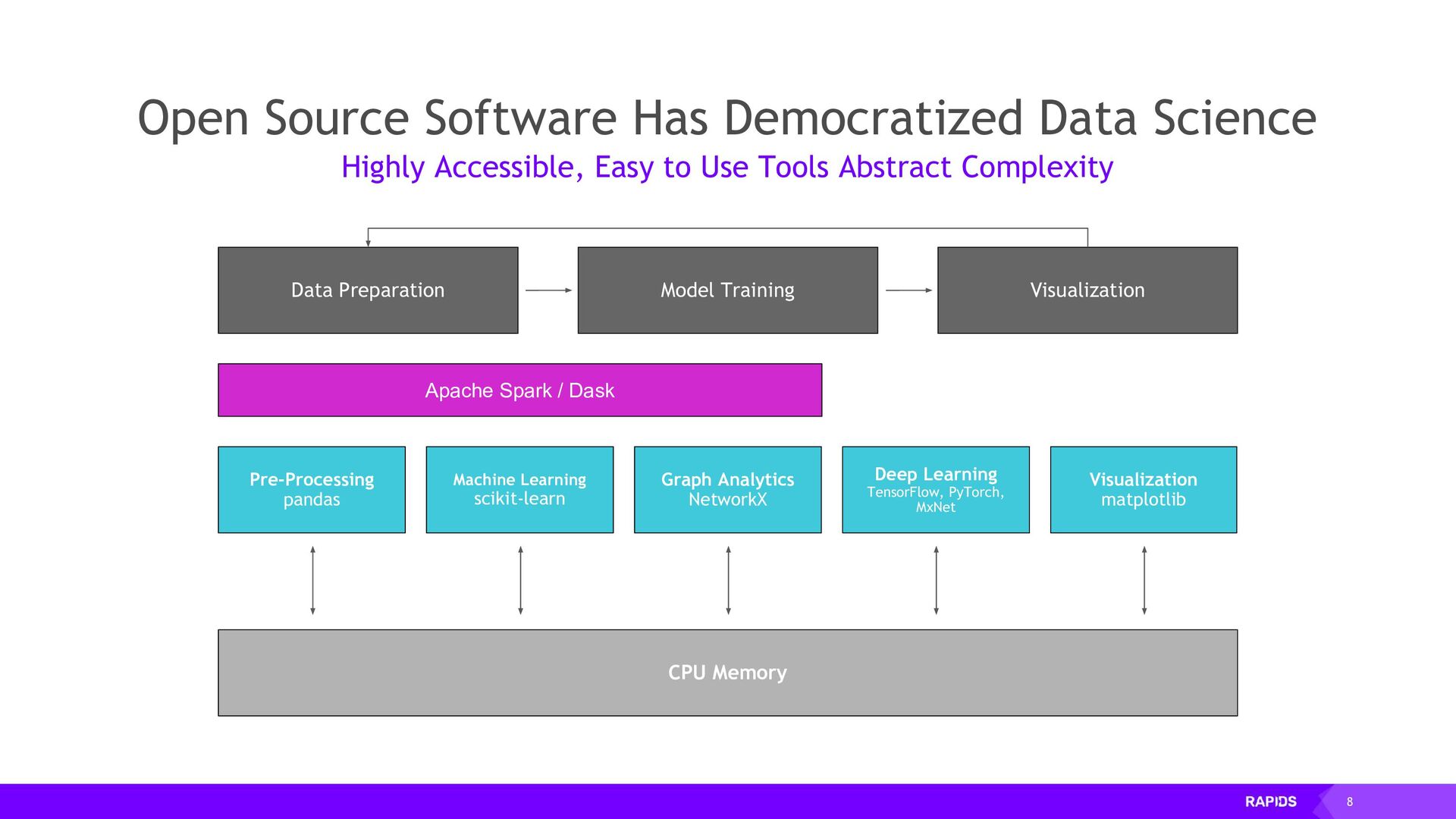
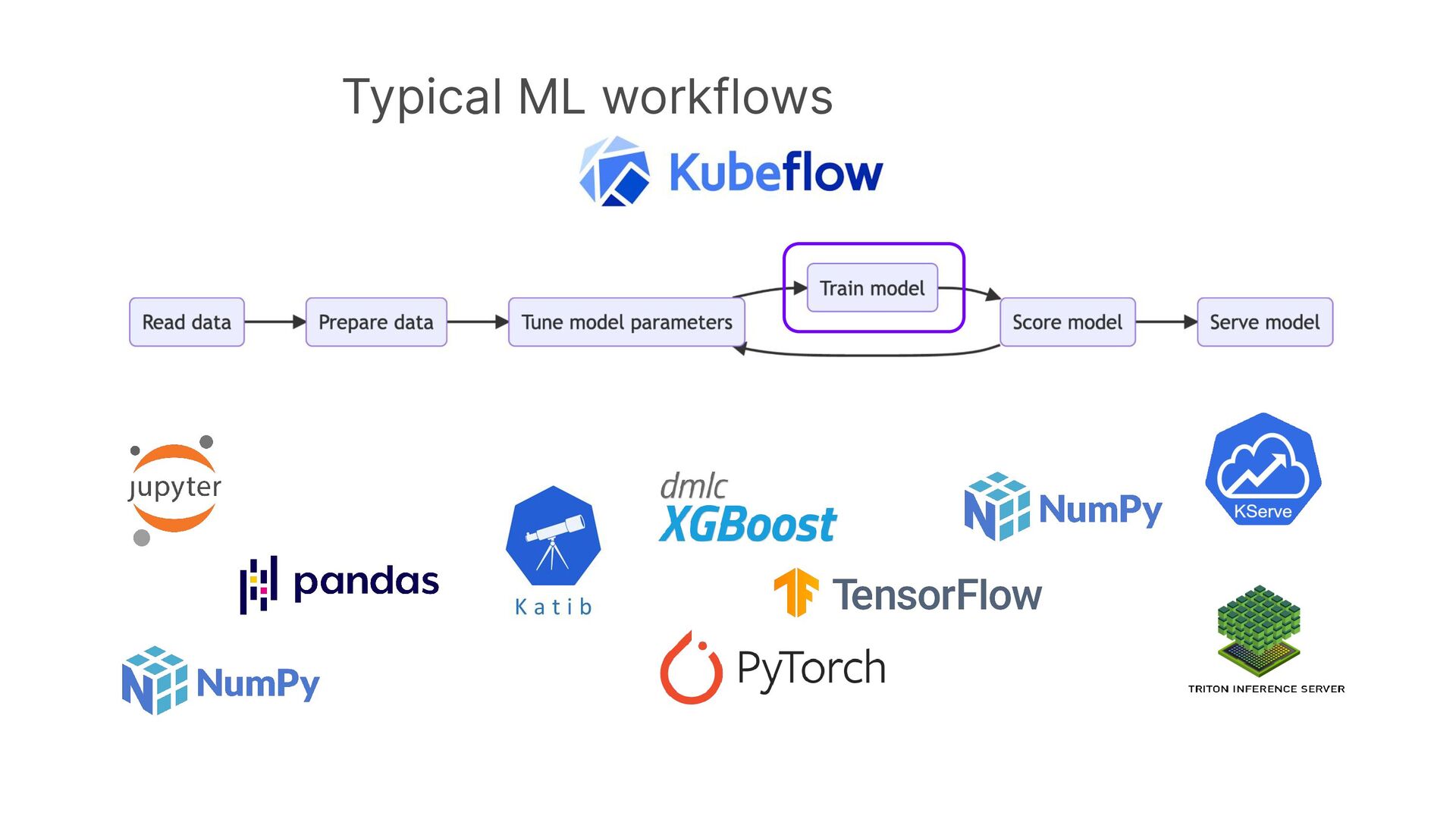
The RAPIDS suite of open source software libraries gives you the freedom to execute end-to-end data science and analytics pipelines entirely on GPUs with minimal code changes and no new tools to learn.
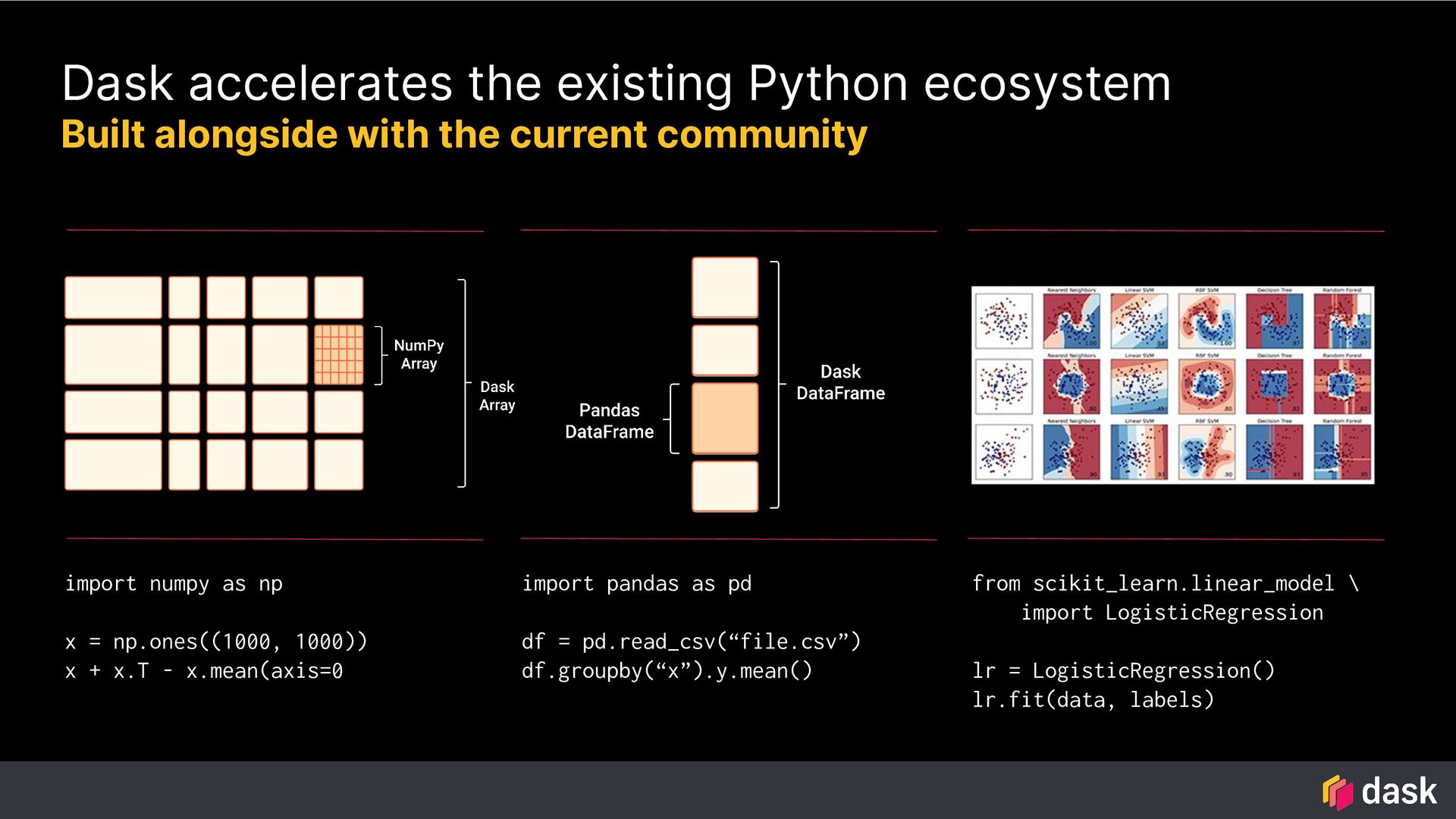
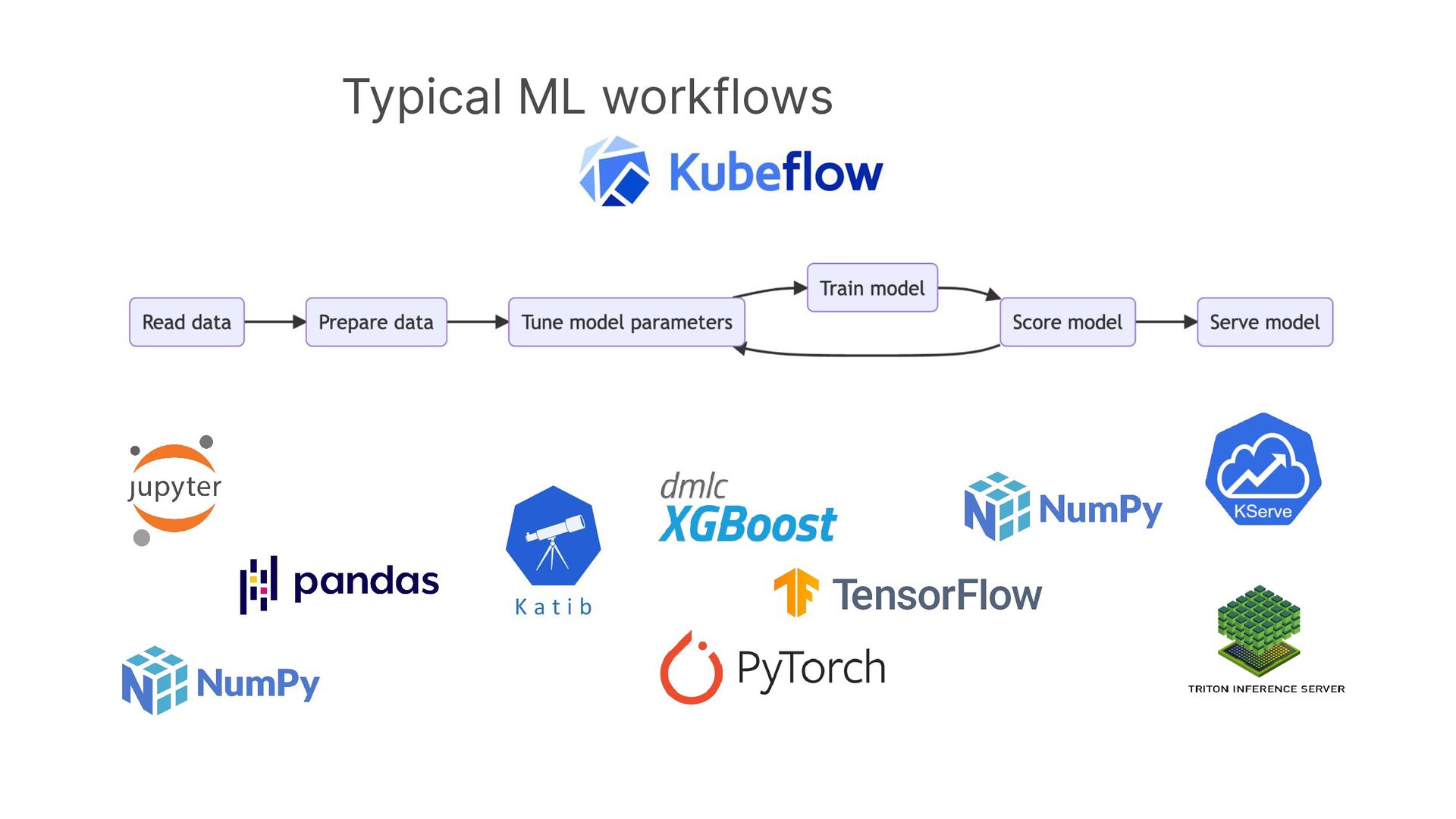
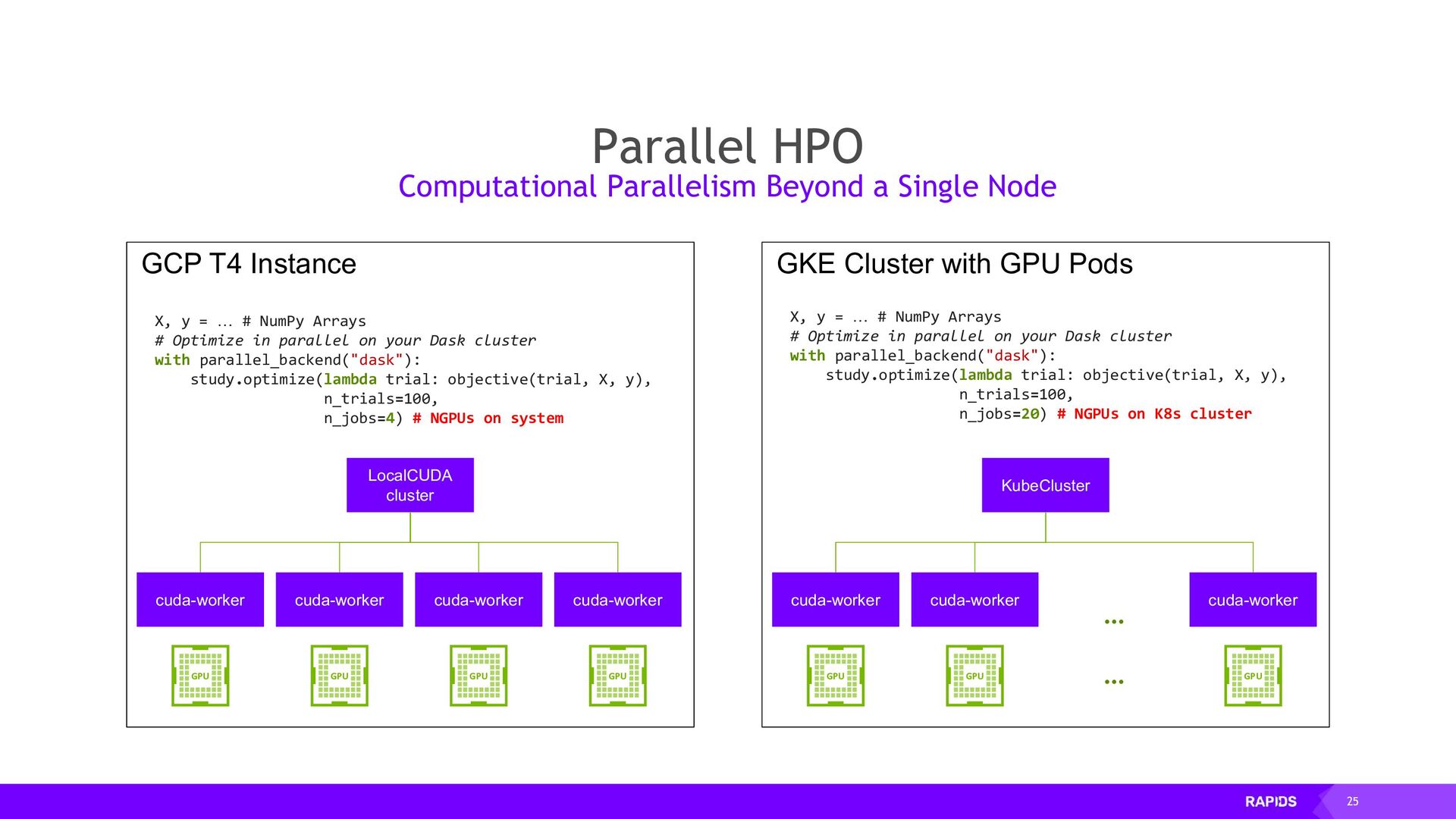
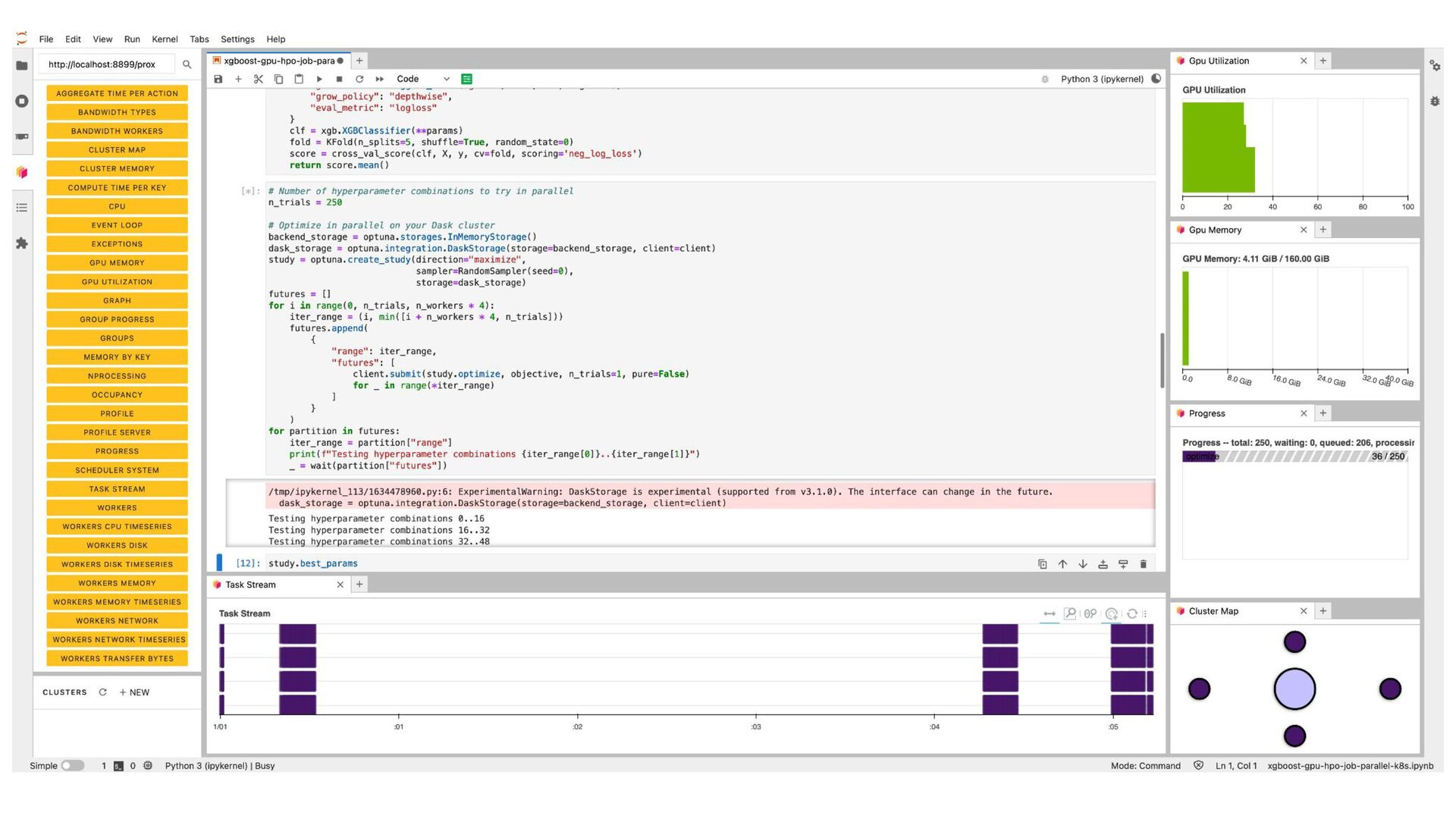
Dask provides advanced parallelism for Python by breaking functions into a task graph that can be evaluated by a task scheduler that has many workers.
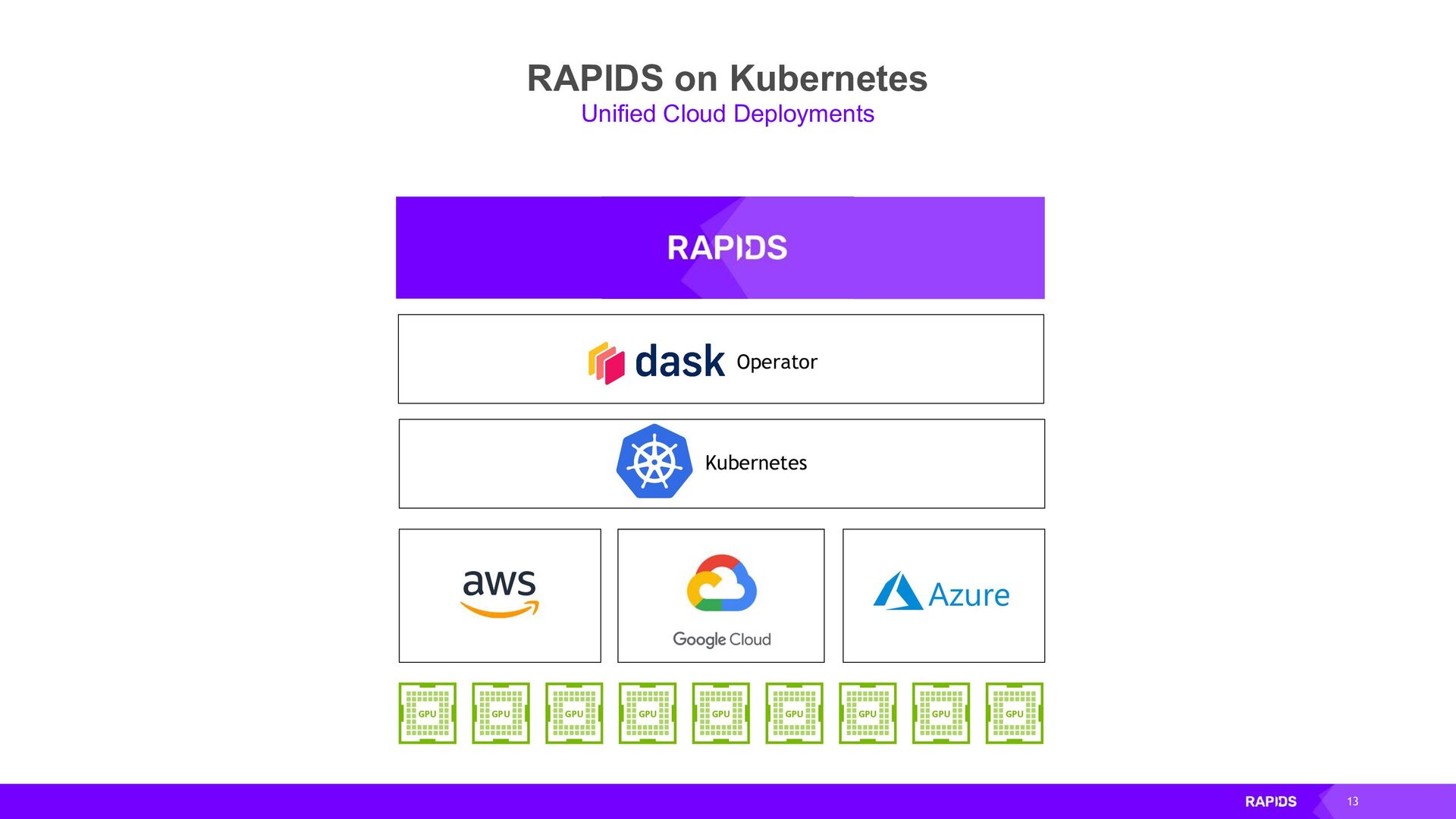
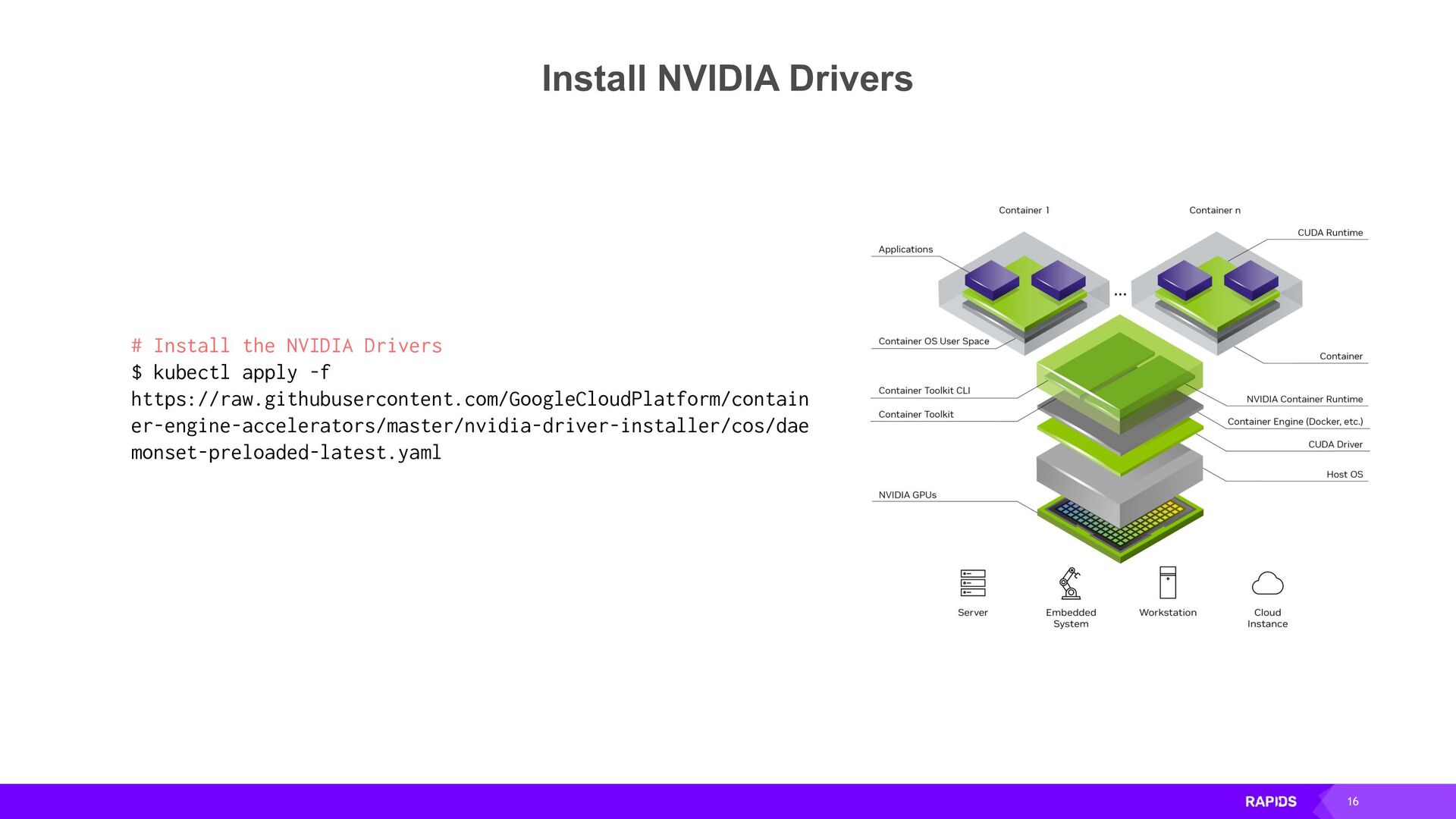
By using Dask to scale out RAPIDS workloads on Kubernetes you can accelerate your workloads across many GPUs on many machines. In this talk we will discuss how to install and configure Dask on your Kubernetes cluster and use it to run accelerated GPU workloads on your cluster.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU Jacob Tomlinson [email protected] @_jacobtomlinson](https://files.speakerdeck.com/presentations/696b4e479bd34cb09e4e51172c124e99/slide_30.jpg){kind=link}