◊ Část položek musí být v průběhu kalibrace vyřazena kvůli nedostatečným psychometrickým parametrům ◊ ◊ Tvůrci se ne vždy drží daných pokynů a směrnic ◊ ◊ Tvůrci nejsou schopni vymýšlet položky přesahující jejich vlastní schopnosti
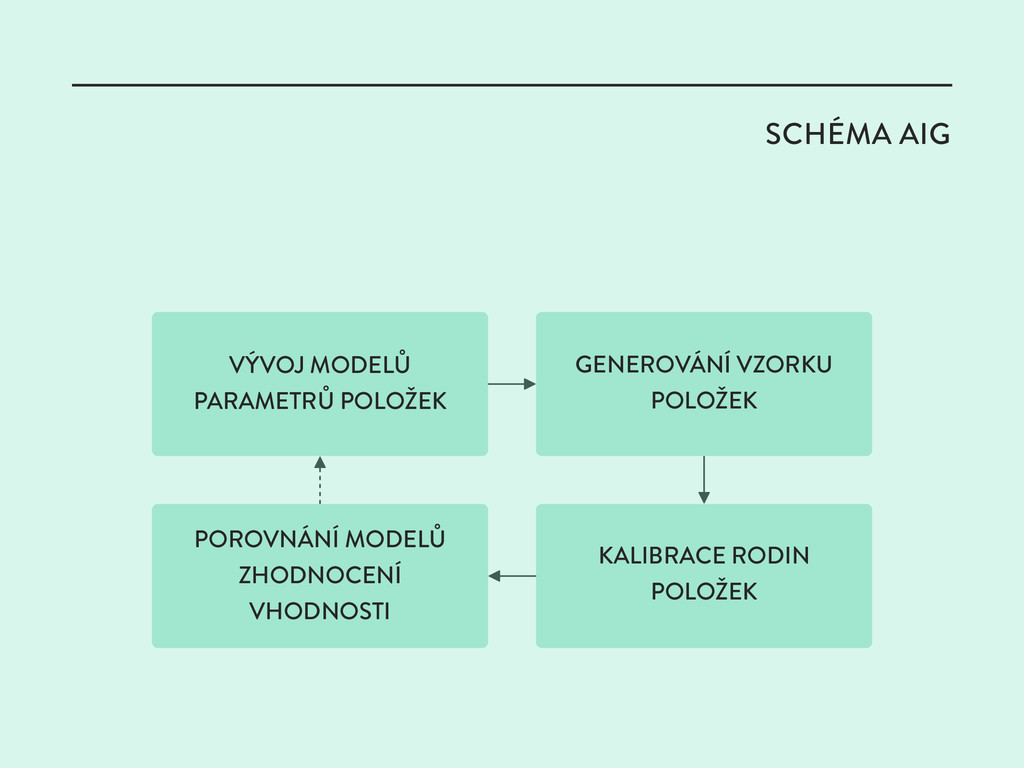
psychometriky se lze s těmito problémy vyrovnat. Automatické generování položek (AIG) Proces, kdy je z jediné šablony generováno více kalibrovaných položek.
elementů ◊ ◊ Elementy jsou algoritmicky variovány a vygenerují se nové položky ◊ ◊ Parametry položek jsou založeny na kombinaci použitých elementů (díky využití statistických modelů)
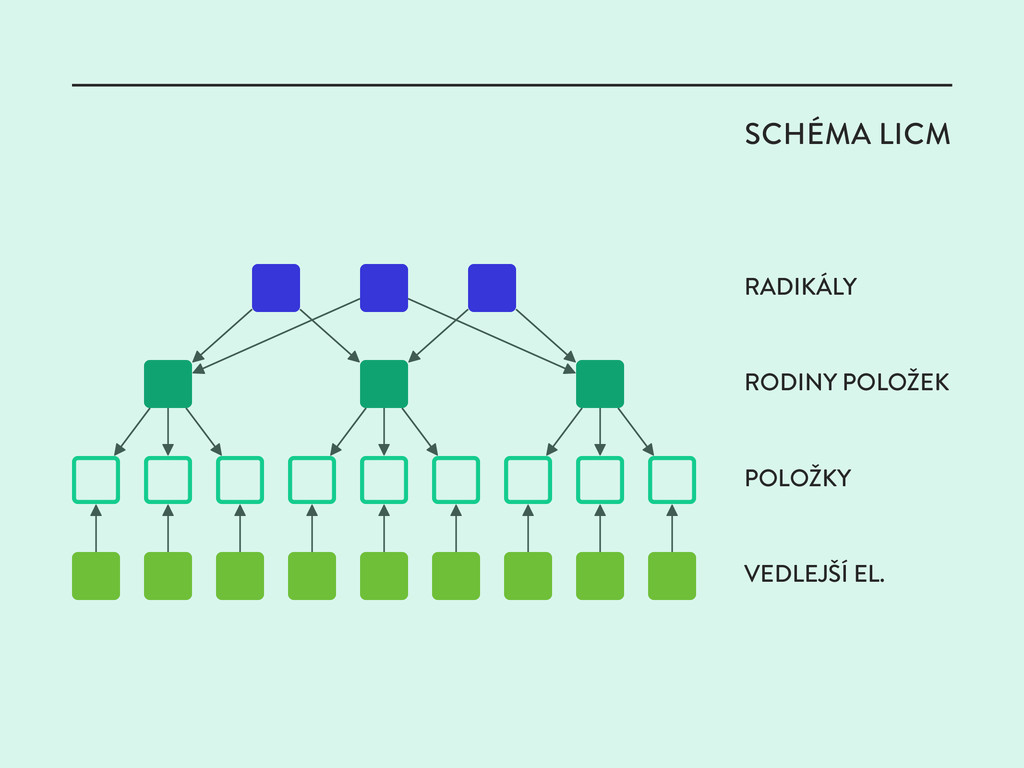
a souvisejícího kognitivního modelu ◊ ◊ Upřesnění formátu položky a popis jejích elementů ◊ ◊ Určit, které elementy položek je třeba z procesu tvorby vyřadit, aby se snížila interference těch kognitivních procesů, které nesouvisejí s měřeným konstruktem
položky ◊ ◊ Vedlejší elementy vytvářejí variace položek bez systematického účinku na jejich obtížnost Položky, které se neliší v radikálech, ale pouze ve vedlejších elementech, patří do jedné rodiny položek.
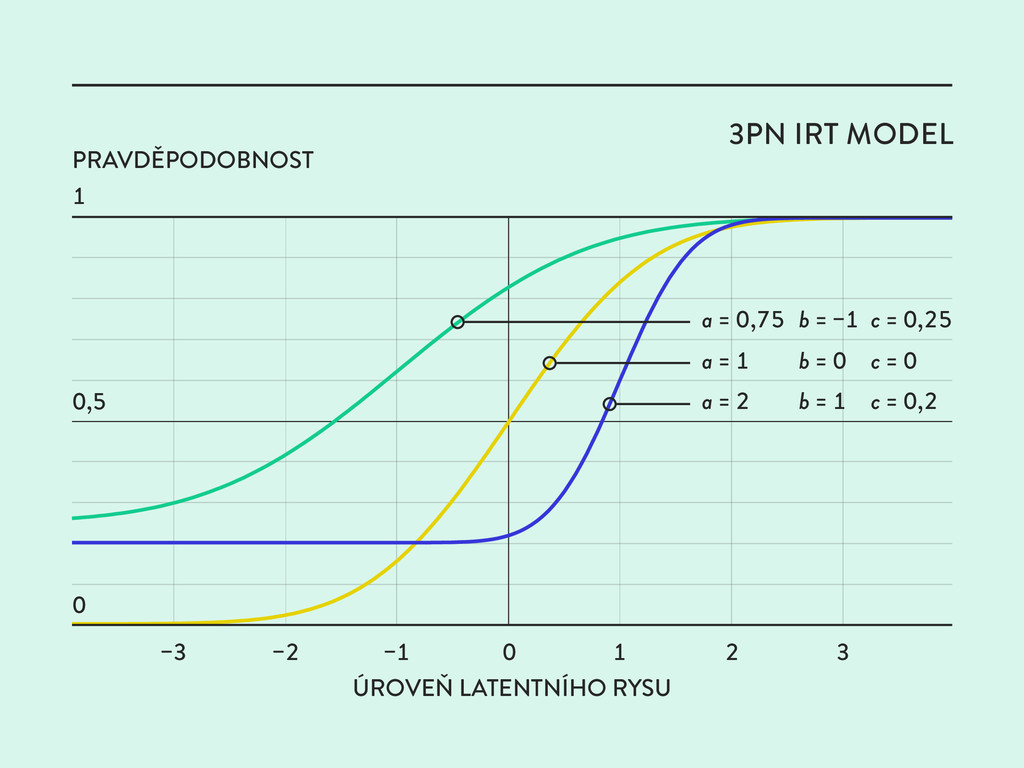
◊ Získáme odpovědi od respondentů ◊ ◊ Data využijeme ke kalibraci parametrů psychometrických modelů Základ modelů tvoří teorie odpovědi na položku (IRT).
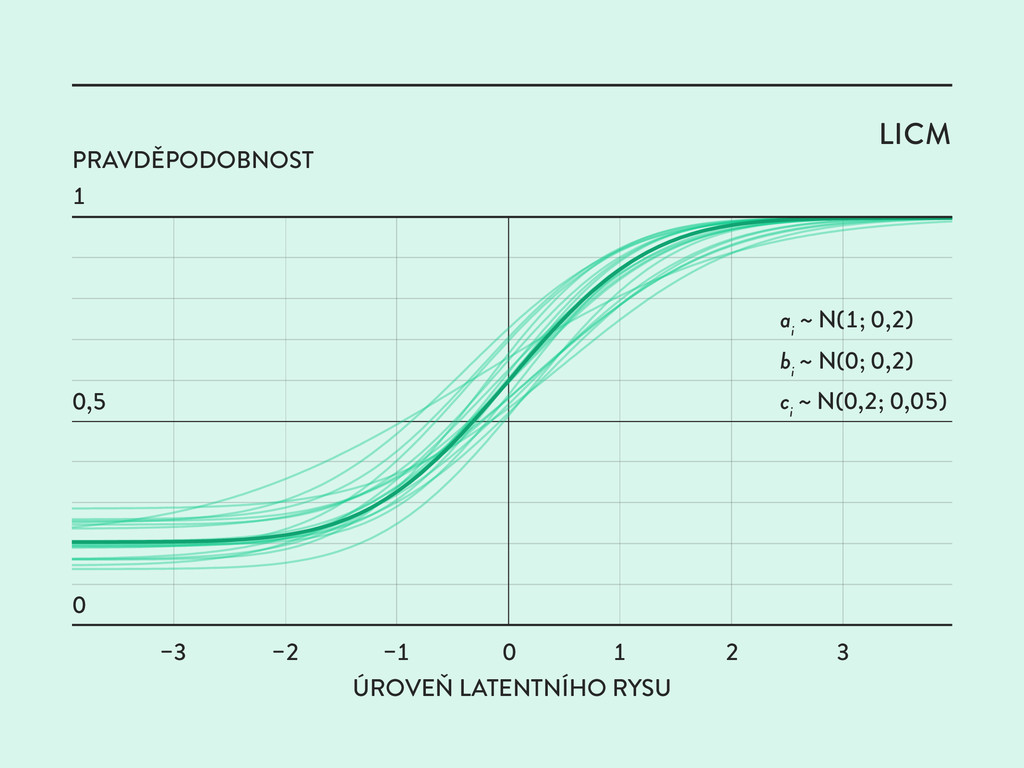
je parametr osob obvykle pokládán za náhodný, zatímco parametry položek za fixované. Pokud však předpokládáme, že položky jsou generovány jako instance šablony z určité rodiny položek, můžeme jejich parametry rovněž považovat za náhodné proměnné.
instancí z jedné rodiny položek a vysvětlit předpokládaný vliv radikálů na obtížnost položek. ◊ ◊ Radikály determinují průměr obtížnosti rodiny položek ◊ ◊ Vedlejší elementy určují kovarianční matici parametrů rodiny položek
Používat předem vygenerované a kalibrované položky ◊ ◊ Generovat položky z předem kalibrovaných rodin ◊ ◊ Generovat položky pouze za využití radikálů Design kalibrace nutno navrhnout optimálně, aby byly potřebné co nejmenší zdroje, a zároveň byly odhady parametrů co nejpřesnější.
rodin a velikost vzorku položek z každé rodiny? Je lepší generovat jako vzorek více položek z jedné rodiny a snížit počet respondentů na položku, nebo naopak? ◊ ◊ Jak ovlivňuje odhad radikálů jejich zastoupení v jednotlivých rodinách položek? ◊ ◊ Jaký je vliv variability parametrů rodin položek a přesnosti jejich odhadu na odhad úrovně latentního rysu?
Practice. New York: Taylor & Francis. Geerlings, H., Glas, C. A., & van der Linden, W. J. (2011). Modeling rule- based item generation. Psychometrika, 76(2), 337–359. De Boeck, P. (2008). Random item IRT models. Psychometrika, 73(4), 533–559.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}