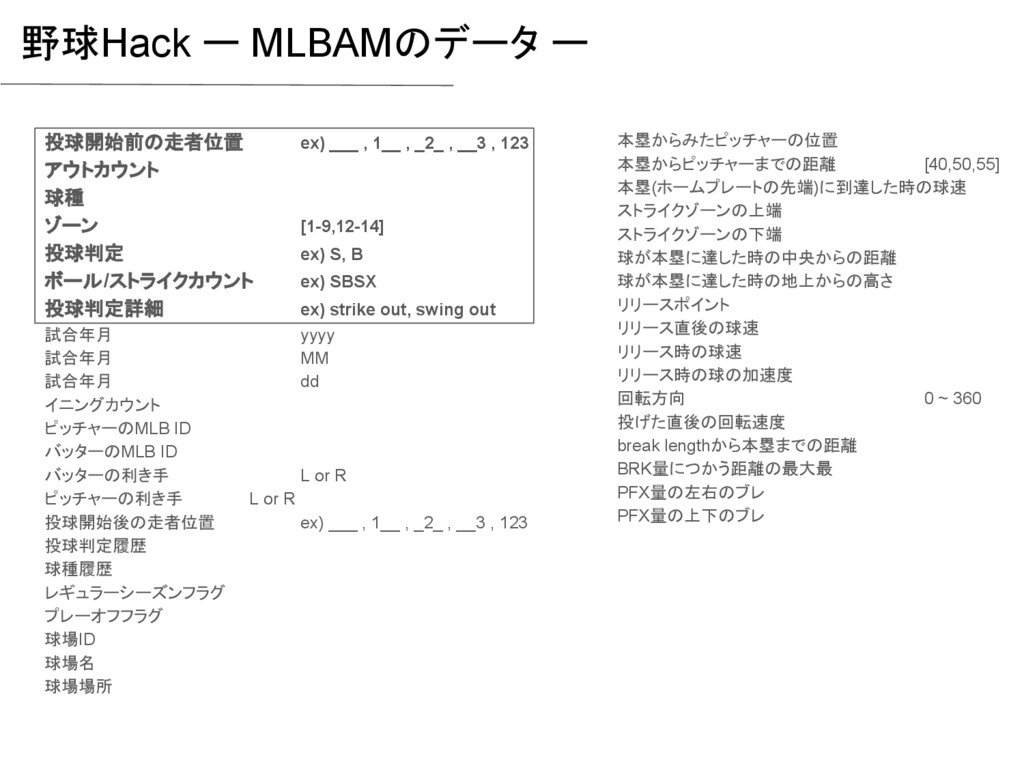
_2_ , __3 , 123 アウトカウント 球種 ゾーン [1-9,12-14] 投球判定 ex) S, B ボール/ストライクカウント ex) SBSX 投球判定詳細 ex) strike out, swing out 試合年月 yyyy 試合年月 MM 試合年月 dd イニングカウント ピッチャーのMLB ID バッターのMLB ID バッターの利き手 L or R ピッチャーの利き手 L or R 投球開始後の走者位置 ex) ___ , 1__ , _2_ , __3 , 123 投球判定履歴 球種履歴 レギュラーシーズンフラグ プレーオフフラグ 球場ID 球場名 球場場所 本塁からみたピッチャーの位置 本塁からピッチャーまでの距離 [40,50,55] 本塁(ホームプレートの先端)に到達した時の球速 ストライクゾーンの上端 ストライクゾーンの下端 球が本塁に達した時の中央からの距離 球が本塁に達した時の地上からの高さ リリースポイント リリース直後の球速 リリース時の球速 リリース時の球の加速度 回転方向 0 ~ 360 投げた直後の回転速度 break lengthから本塁までの距離 BRK量につかう距離の最大最 PFX量の左右のブレ PFX量の上下のブレ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}