• Initial Pilot Service: Winter 2003 • Initial Production Service: Fall 2004 • As of March 2013: • Over 120,000 Class & Project sites • Over 220,000 My Workspaces • Reference: http://ctoolsstatus.blogspot.com/ • CTIR – CTools Infrastructure Rationalization Project (a FY12 Priority IT Project for U-M)
virtual vs. physical infrastructure • Implications of shared infrastructure decisions • Cost-savings a significant factor to many institutions in decision-making processes today • Different services have different requirements (resource, performance, etc.)
legacy IT central organizations • New support model of stratified technical teams • Technical Perspective • Create a standardized and sustainable infrastructure following U-M (ITS) strategic direction • Retire at-risk hardware and software • Migrate to new data centers • Cross-train technical staff to eliminate single points of knowledge • Document all infrastructure and procedures • Better position for unknown capacity needs in near future • Untangling unknown and undocumented dependencies
performance or increasing risk • Implement using shared infrastructure on organizational standards (hardware & software) • File resources required to be on shared file systems (NFS) • Migrate database storage to high performance SAN-based solution • Capacity • Address immediate capacity issues at database server layer and plan for unknown growth rate • Horizontal vs. vertical scaling
What if outage is delayed or postponed or takes longer than expected? • What if users experience problems after update? • Communications planning • T-9 months: Email to selected campus groups; Special email setup to service requests • T-4 months: CTools/Sakai MOTD on Gateway • T-3 months: Re-occurring Email, Facebook, Yammer, UM Web pages posts, plus ITS news article • T-2 weeks: One more email, continued social media presence, campus paper news brief • T-30 minutes: Global Alert Message to active sessions. • T+1 day: all clear email announcement; new gateway
staff resources for testing/validating new environments • Investment in automated functional testing • Review new service architecture designs for usability, security from developer perspective
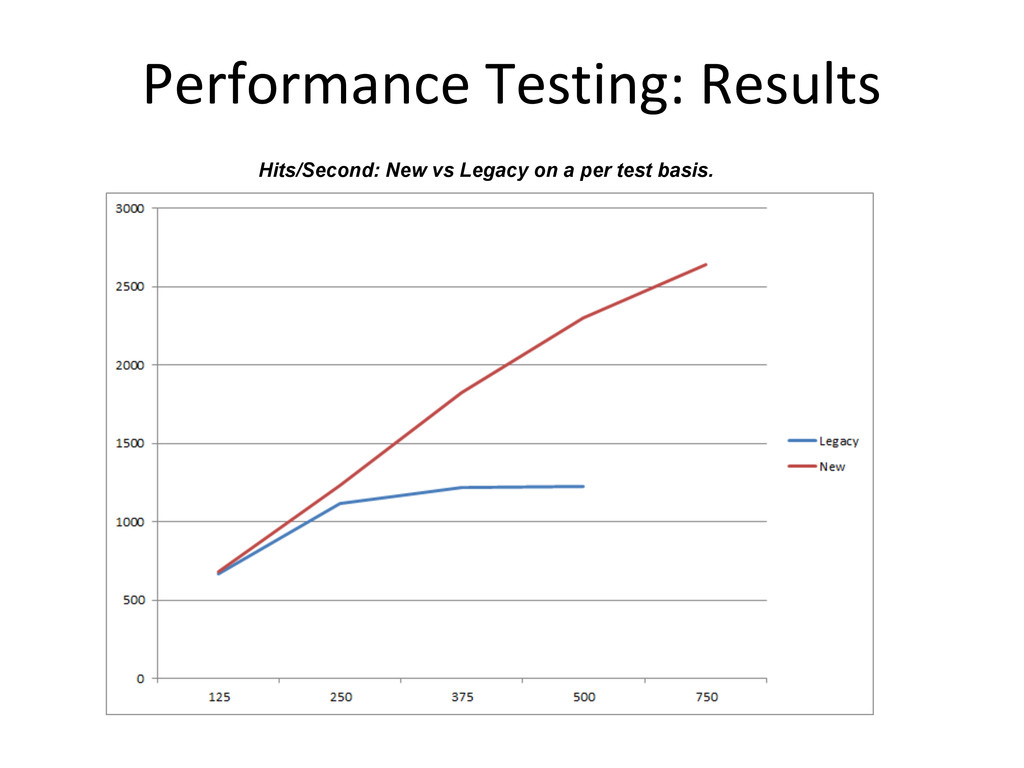
Load test environment equivalent production • Dedicated load tester from 2007-2009, 2012- • Data roughly equivalent, but diverging with time • Goals: • Correctly size flexible infrastructure • Certify combinations of hardware & software configuration
upper limits • Multiples of base load test • System capacity increased 120% • Significant database CPU capacity increased 5 times • New bottleneck at application tier • Virtualization: flexible application tier. • Added nodes, not CPUs/node • Reduced risk for users in case of server failure
challenges within infrastructure, rather than application, support model • Provided basis for communication in resolving production incidents in Fall and Winter terms.
scenarios of varying size, impact, recovery difficulty • Scaled back due to time and resource constraints • End result: Single scenario (loss of primary data center) tested • Exposed some conflicting architecture assumptions, some contrived environmentals • BUT… a successful and well-documented test!
Freeze – June 2012 • Deployment: June 30 – July 1, 2012 • Start time – 12:15am EDT 06/30/2012 • Progressed smoothly overall • Slow rebuild of Site Search indexes introduced delays • Decision to leave it running overnight and reconvene Sunday morning (07/01/2012) • Largely coincidental timing of index rebuild at 11:59:60pm aka: Java “leap second” bug ☹ • Rebooted all application servers Sunday morning to resolve issue • Service restored by early Sunday afternoon (within scheduled window)
• Met stated goals of project • Major achievement for organizational/institutional direction for shared services • Some tasks slipped out of scope of project • “CTools is different” – doesn’t fit the same availability and reliability requirements as some other services. • Stratified support model requires significantly more communication and engagement
handle the load • Usage profile significantly different from load testing profile • Earlier load testing configuration validation informed quick decision to change production application configuration to resolve • Winter 2013 “bleed over” • February: Observed curious performance issue in CTLOAD during a Gradebook-related production incident • March: Observed and reproducible performance degradation in production service during load testing • March-April: Long problem investigation eventually identified shared infrastructure component (firewall device) as the cause of the degraded performance • May: Near-term solution implemented to have backend app/db communication bypass firewall device
2013 – low load again ☺ • All legacy hardware has been decommissioned • Preparing for next application release • Learned a lot about shared infrastructure and support model (benefits and challenges)
DRBC testing was a successful milestone • QA processes refined • Open collaboration across infrastructure teams • Communication: start early and communicate often • Organizational culture disconnects • No clearly defined SLA/SLE w/ performance metrics; affected architecture decision-making • Resource contention (staff availability)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}