➢ Tech Lead WordBox & Founder DevHack ➢ Consultant and advisor on software architecture, cloud computing and software development. ➢ Experience in several languages and platforms. (C, C#, Java, NodeJS, android, GCP, Firebase, Python, Go, DS, ML). ➢ Google Developer Expert (GDE) in Firebase & GCP & Kotlin & ML ➢ BS in System Engineering and a MS in Software Engineering. ➢ @jggomezt ➢ youtube.com/devhack
the business. ❖ Find faults and points for improvement. ❖ It processes a lot of data in a short time. ❖ Use the best tools to obtain, process and store data. ❖ Automate processes to obtain, process and store data.
insights to make the best decisions quickly ❖ Create new services faster. ❖ Create new attributes. ❖ Improve our data and its structure. ❖ Changing technology for data lakes.
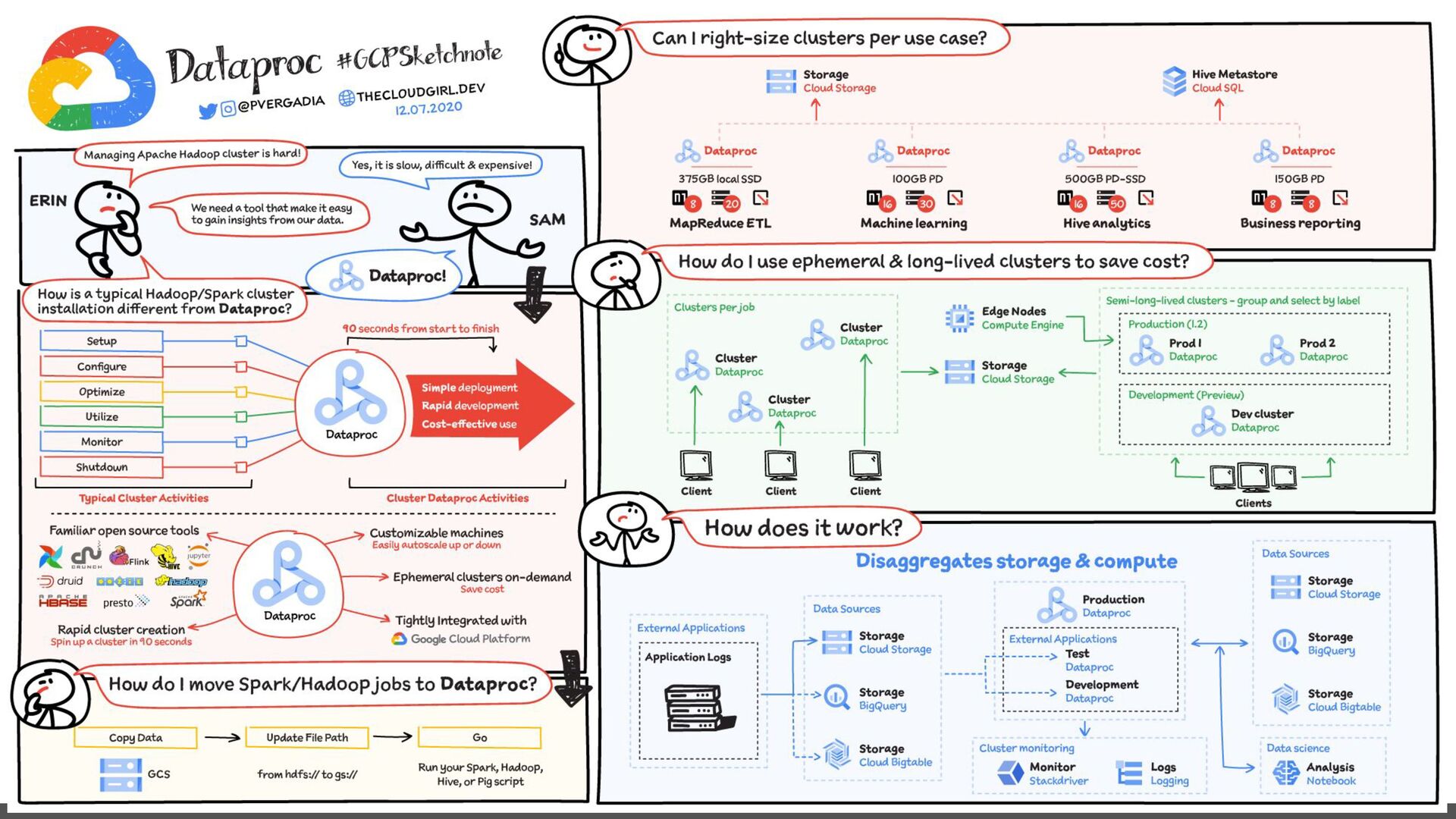
Scripts and executing in our PC. ❖ Scripts and executing in Colab or Jupyter. ❖ Scripts and executing in a Super Virtual Machine ❖ Scripts and executing in a Cluster. ❖ Using advanced tools.
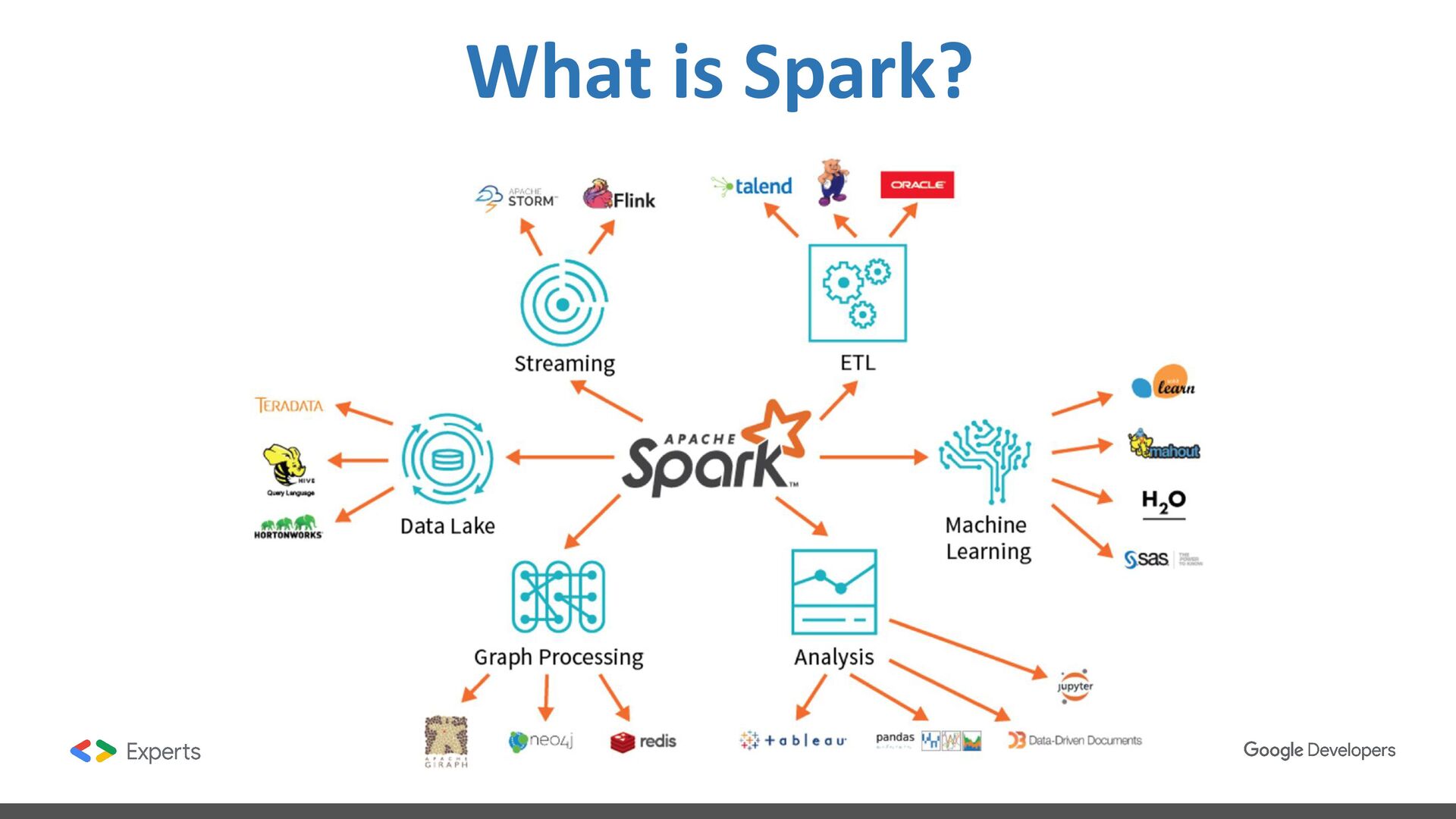
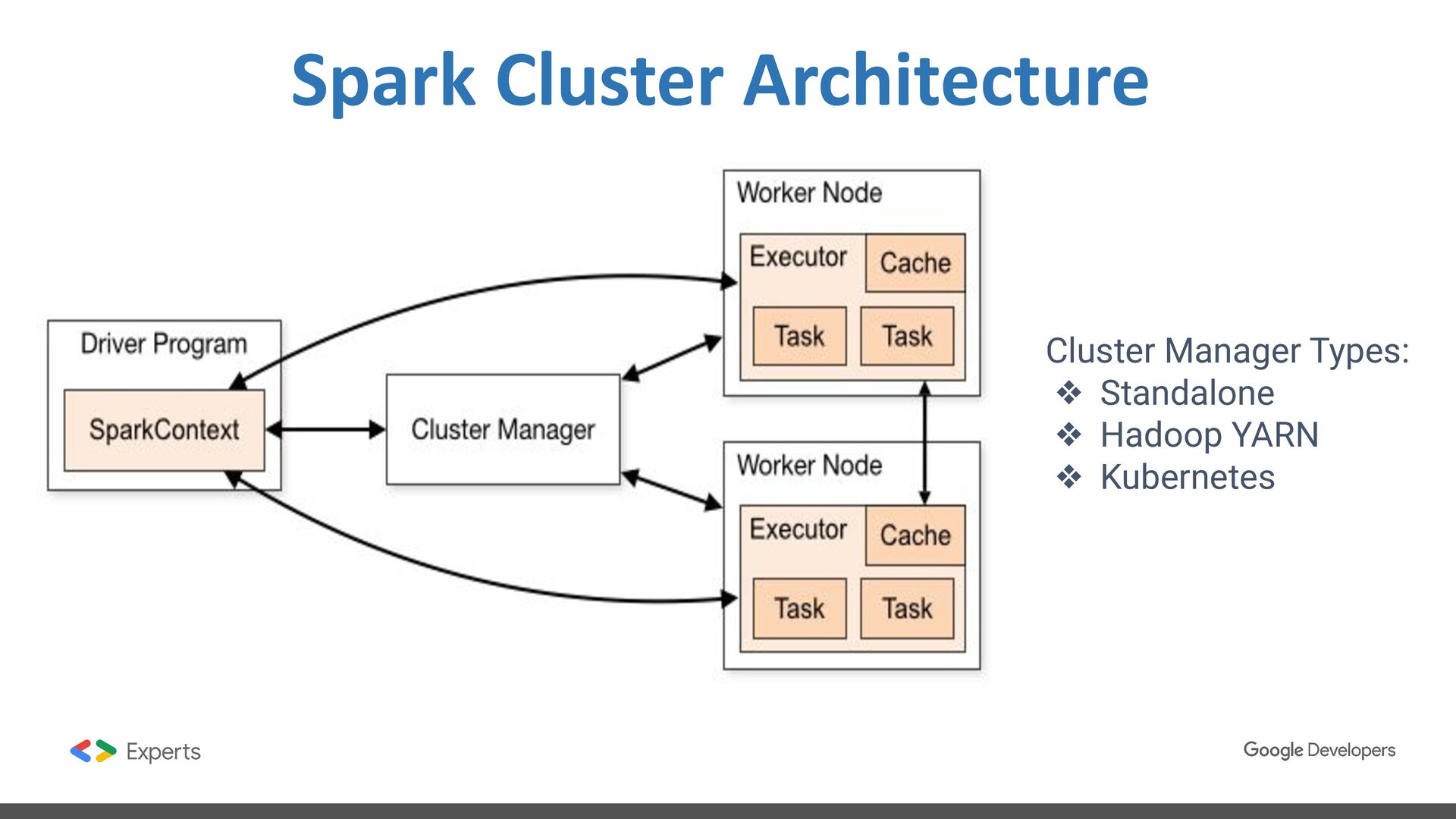
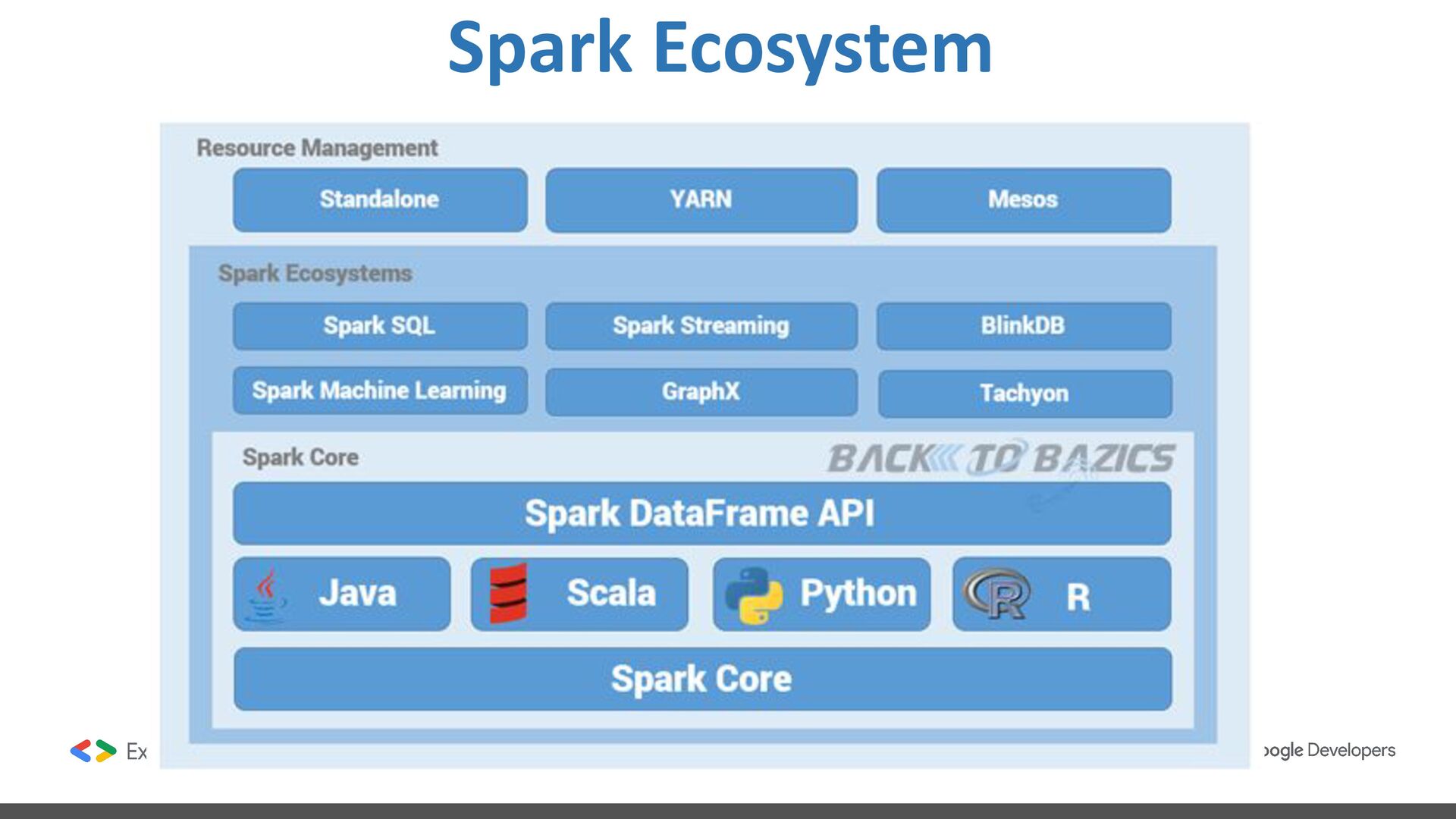
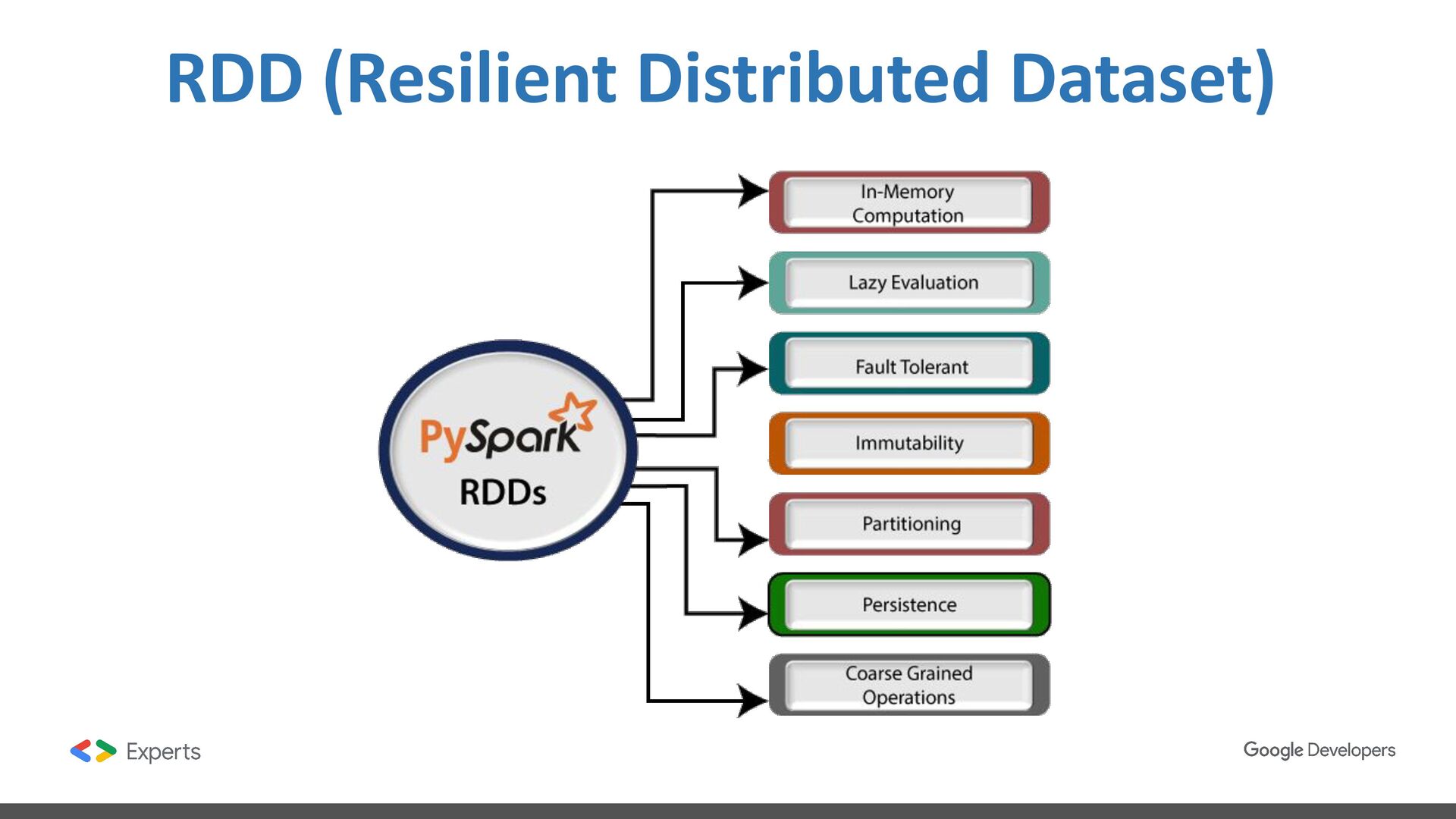
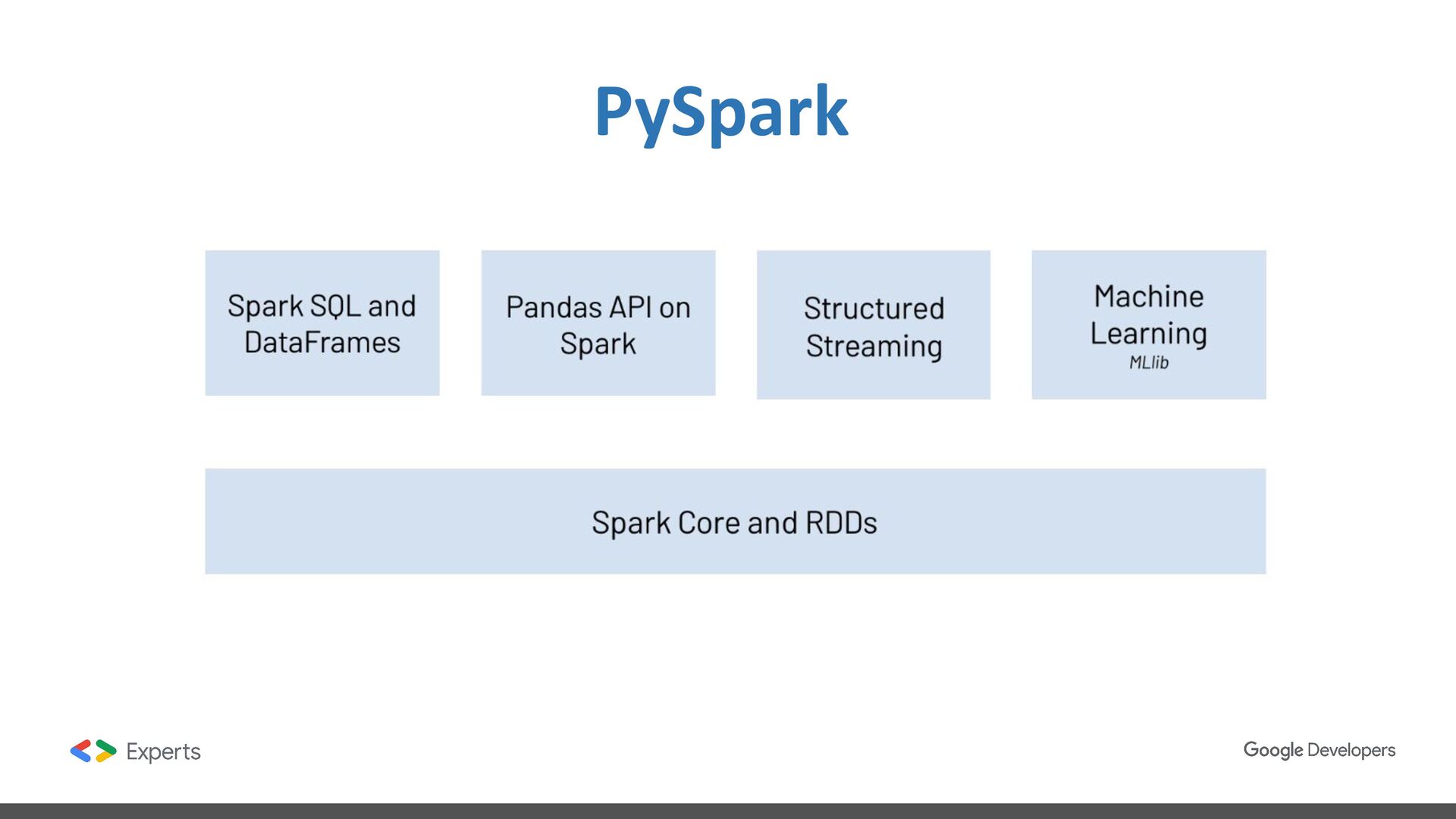
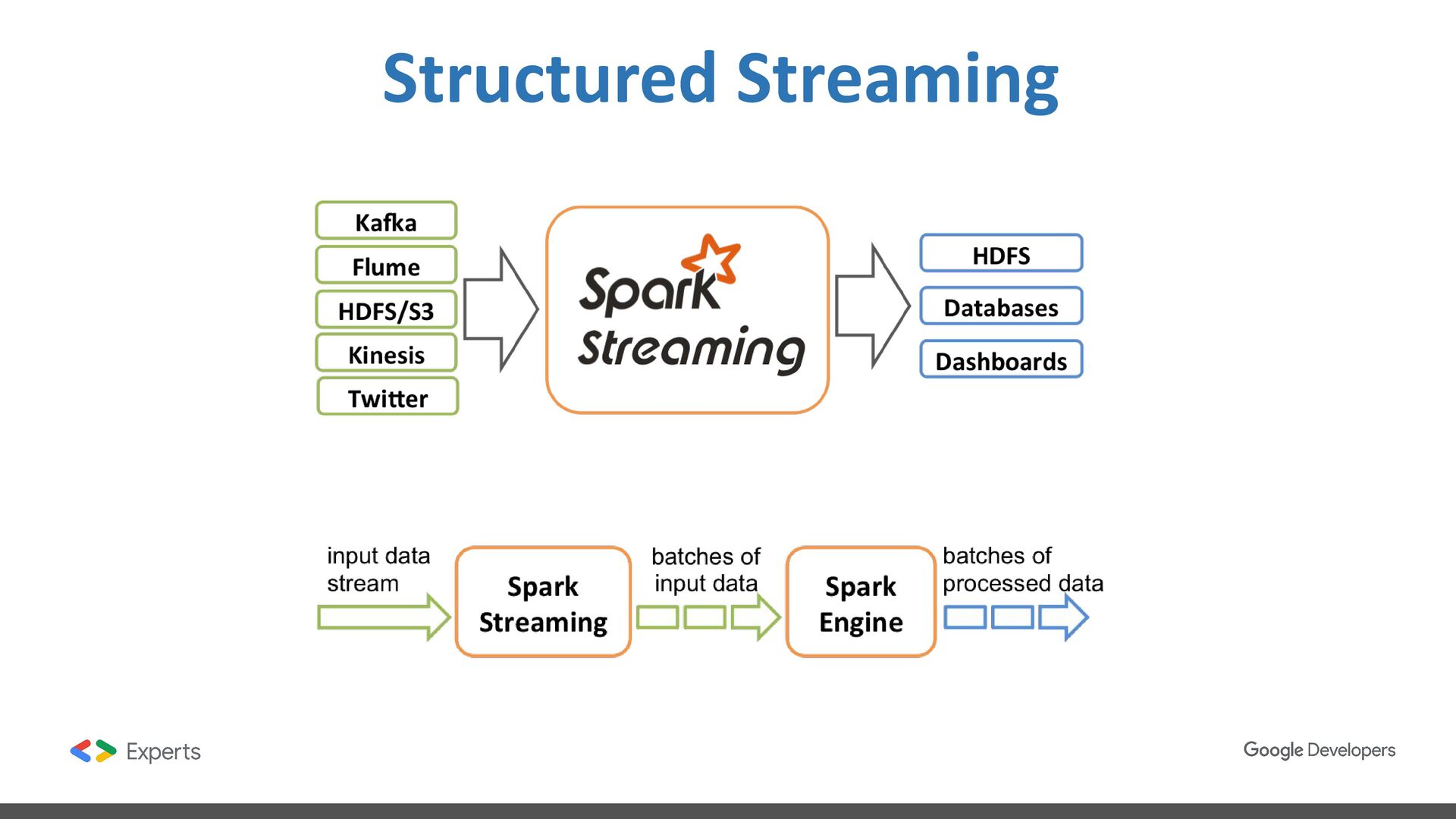
data science, and machine learning on single-node machines or clusters. ❖ Framework for processing data distributed in multiple nodes. ❖ Framework with high level components for developing jobs. ❖ Batch and streaming data processing. ❖ SQL Analytics. ❖ Data Science at scale. ❖ Machine learning.
query structured data inside Spark programs, using either SQL or a familiar DataFrame API ❖ DataFrames and SQL provide a common way to access a variety of data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC. You can even join data across these sources.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}