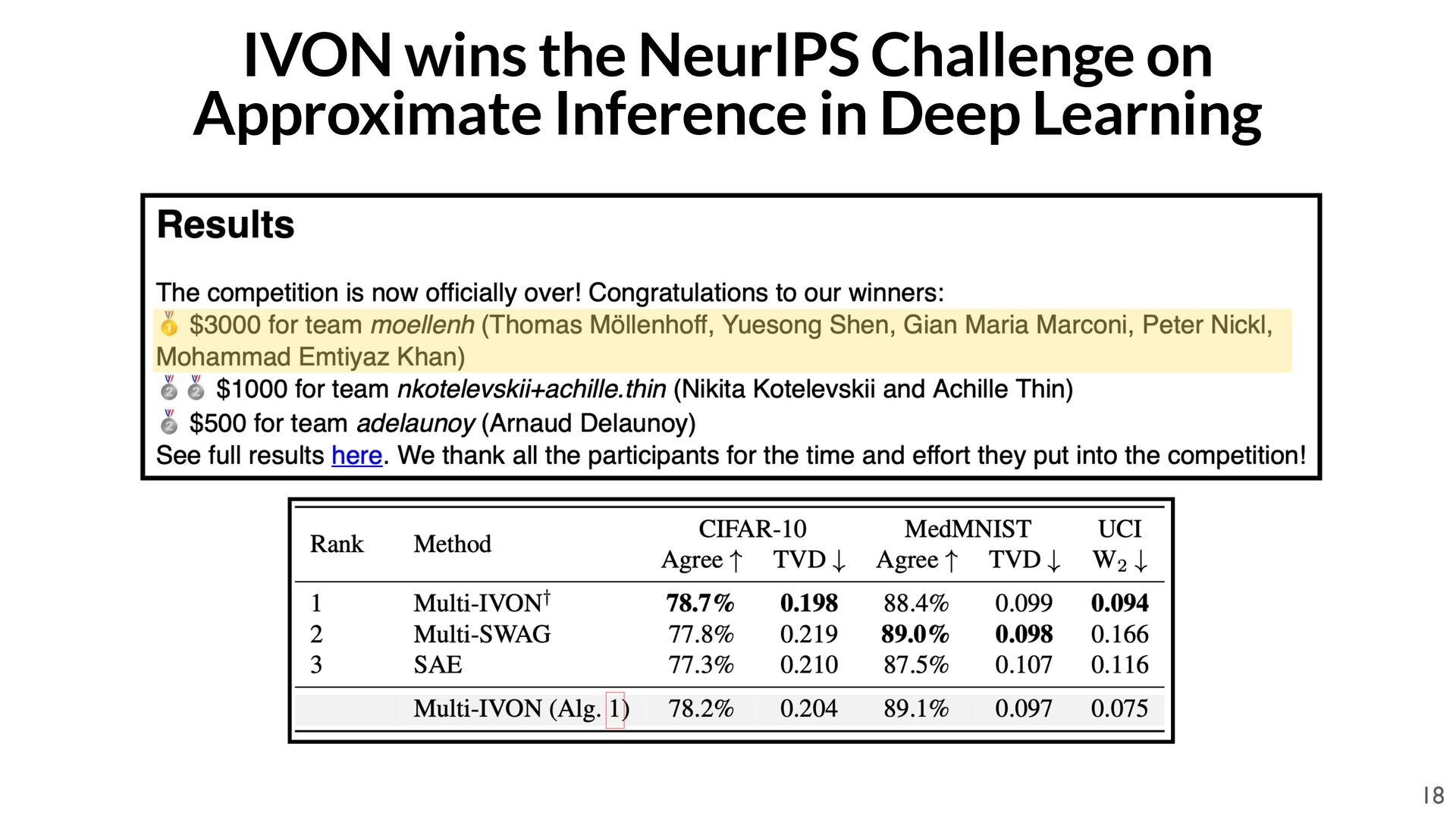
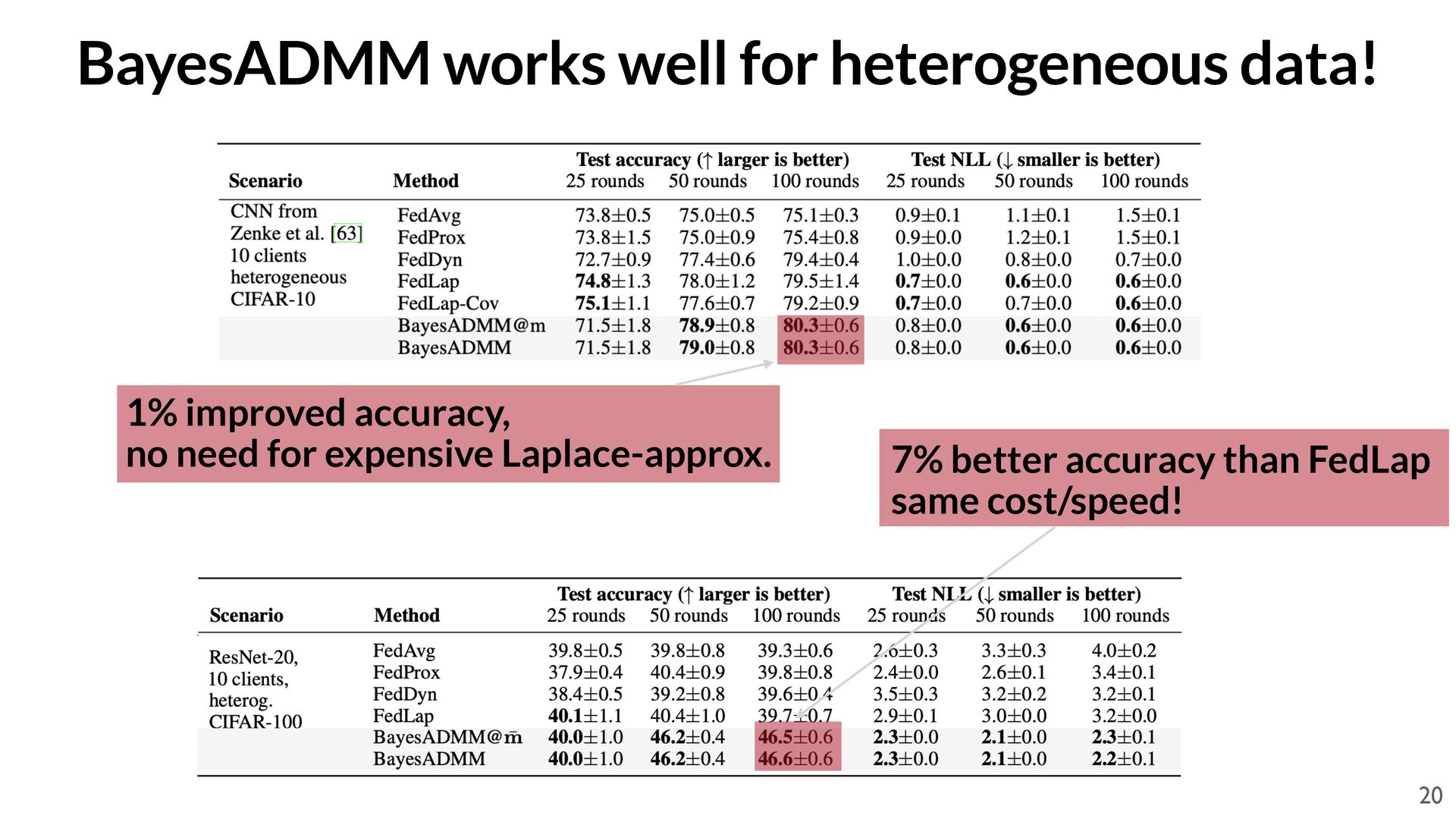
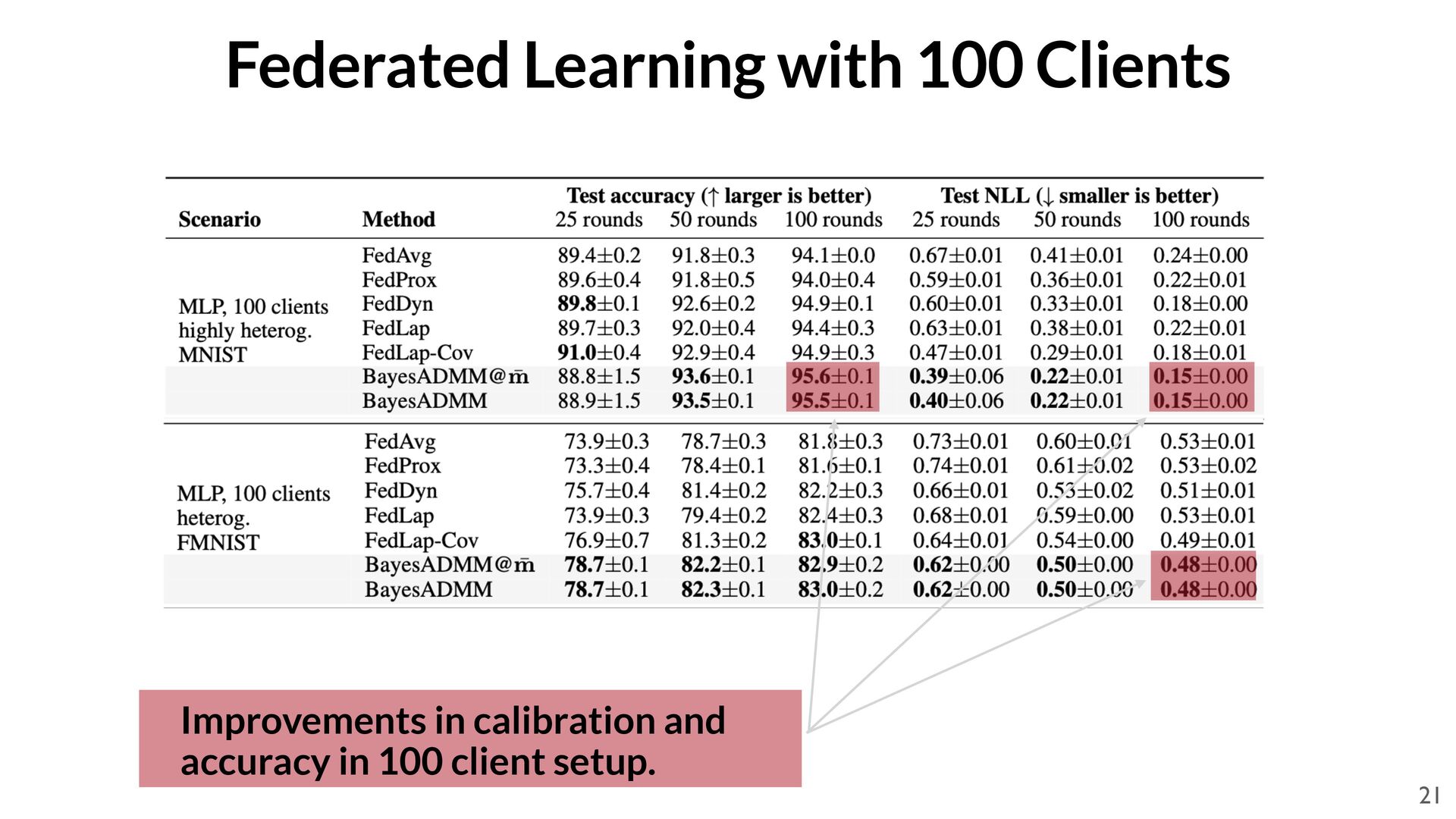
Möllenhoff Code available at: https://github.com/team-approx-bayes/bayes-admm 1. T. Möllenhoff*, S. Swaroop*, F. Doshi-Velez, M. E. Khan, Federated ADMM from Bayesian Duality, arXiv:2506.13150, 2025
across institutions • Perhaps we don’t want or cannot share all data • Specialized models which share their knowledge with each other • We may have highly heterogeneous data… • … or train on entirely different tasks (biology, math, physics, …) • What knowledge should the local models exchange with each other? • How should shared information be weighted? 3 This talk: Improving Federated ADMM via Bayes
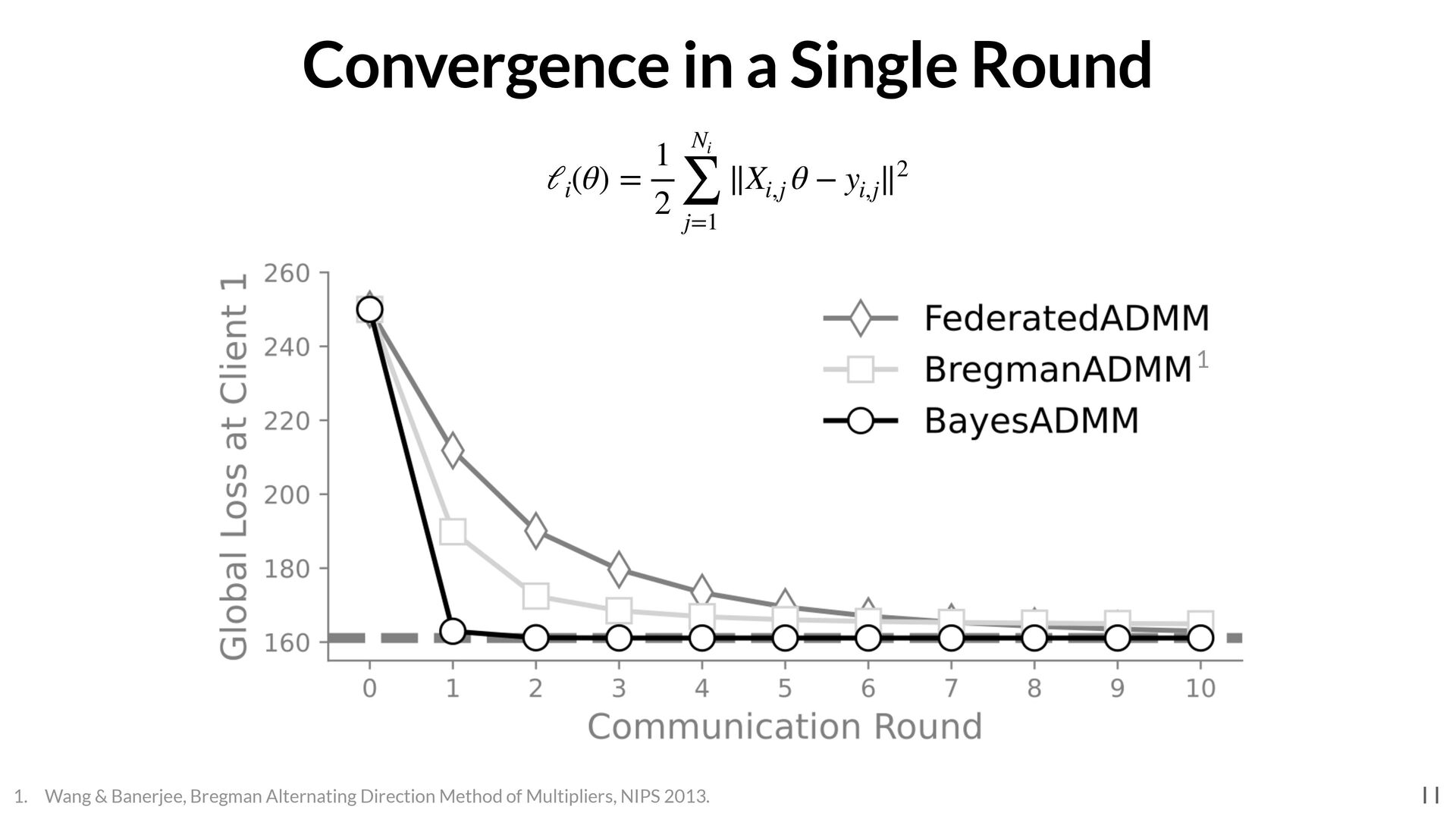
∑ i=1 ℓi (θ) 4 • K clients; each minimize a loss function to fi nd their local solution • What information should be exchanged between the clients? • Example: ℓi θi ℓi (θ) = 1 2 Ni ∑ j=1 (θ − xi,j )2 1, 2, 3 4, 6, 5, 5, 10 2 6 4? A: 4.5 this quantity is the posterior precision (inverse covariance). Ni = ∇2ℓi
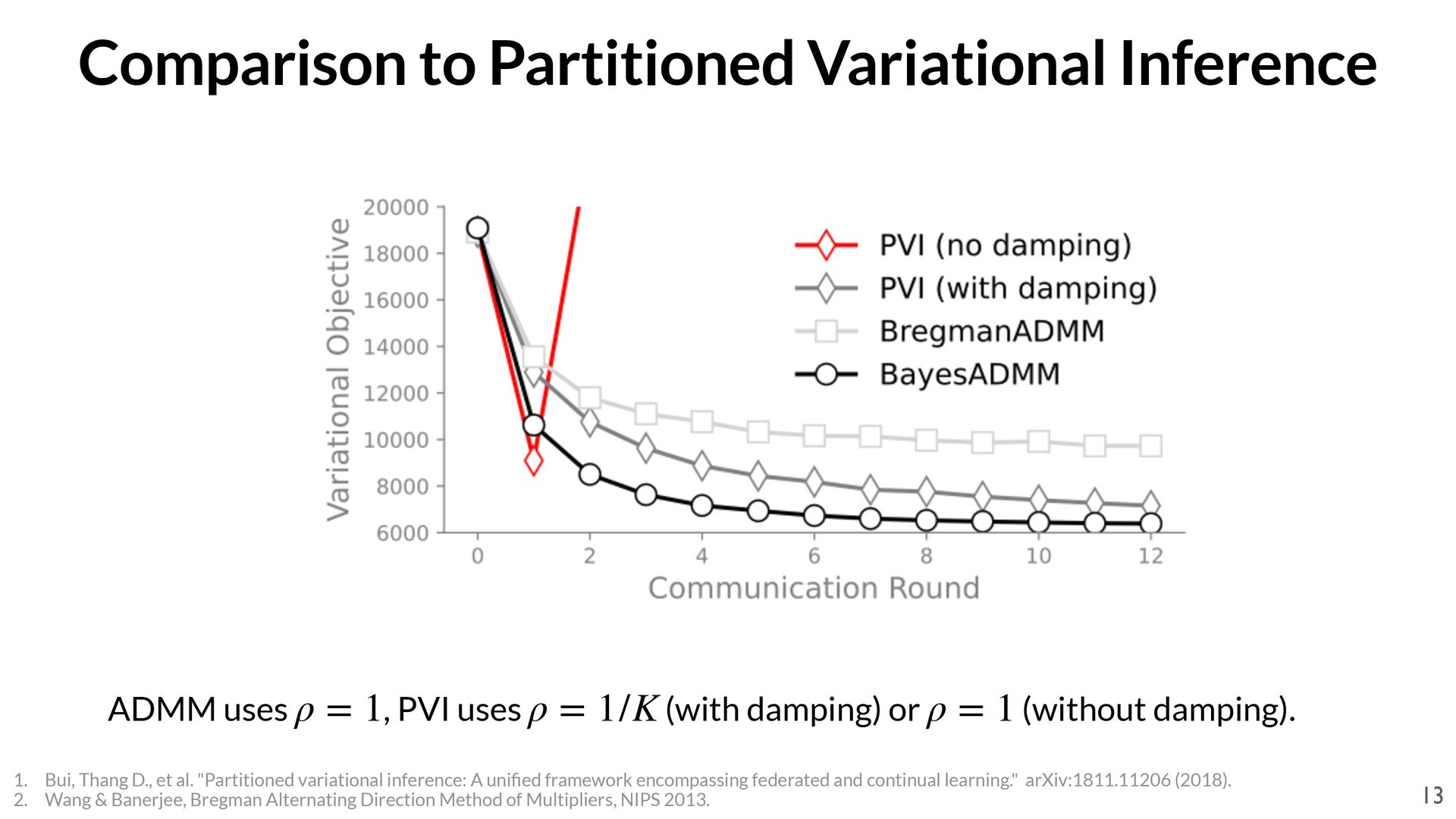
(with damping) or (without damping). ρ = 1 ρ = 1/K ρ = 1 1. Bui, Thang D., et al. "Partitioned variational inference: A uni fi ed framework encompassing federated and continual learning." arXiv:1811.11206 (2018). 2. Wang & Banerjee, Bregman Alternating Direction Method of Multipliers, NIPS 2013. 13
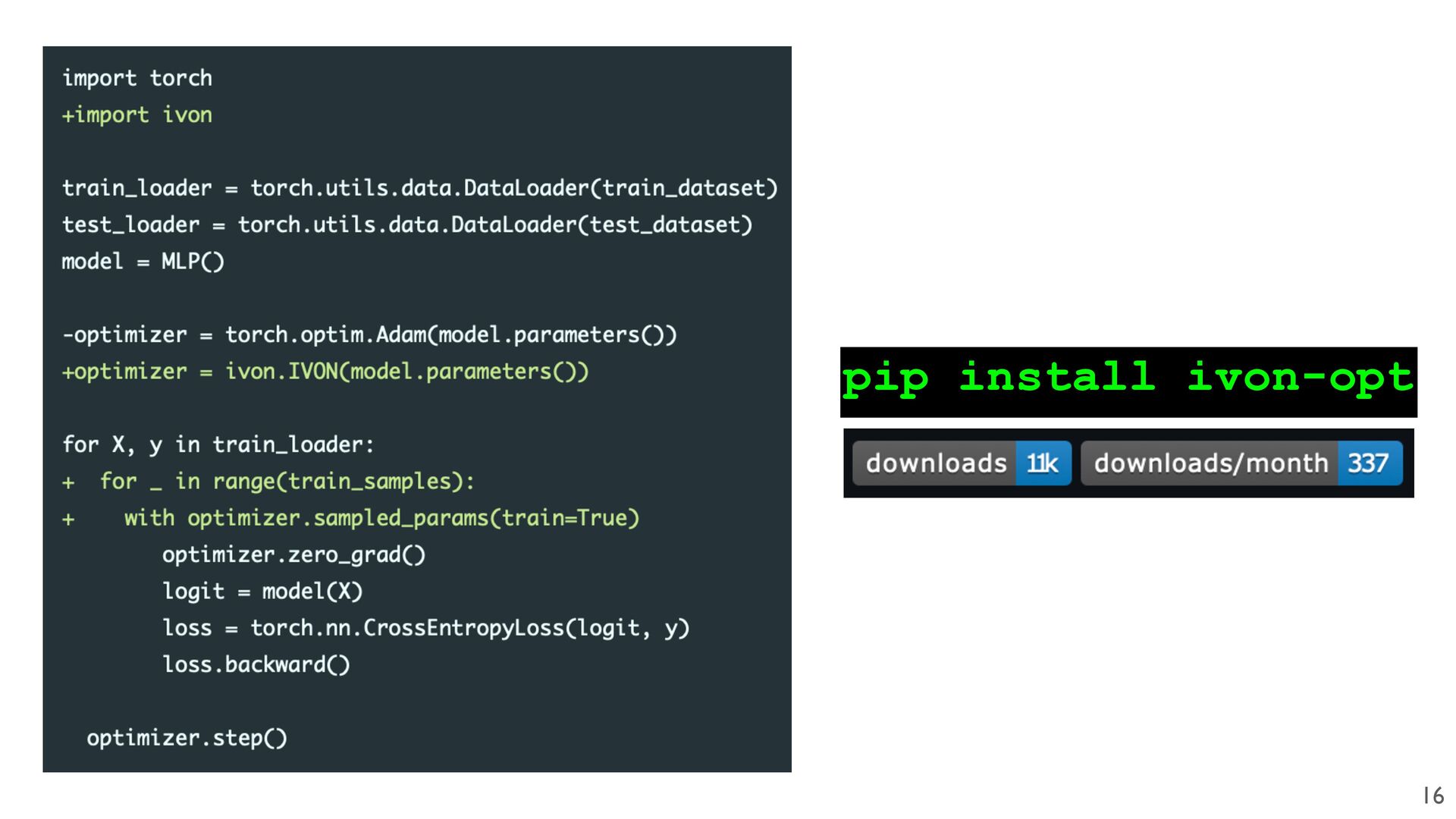
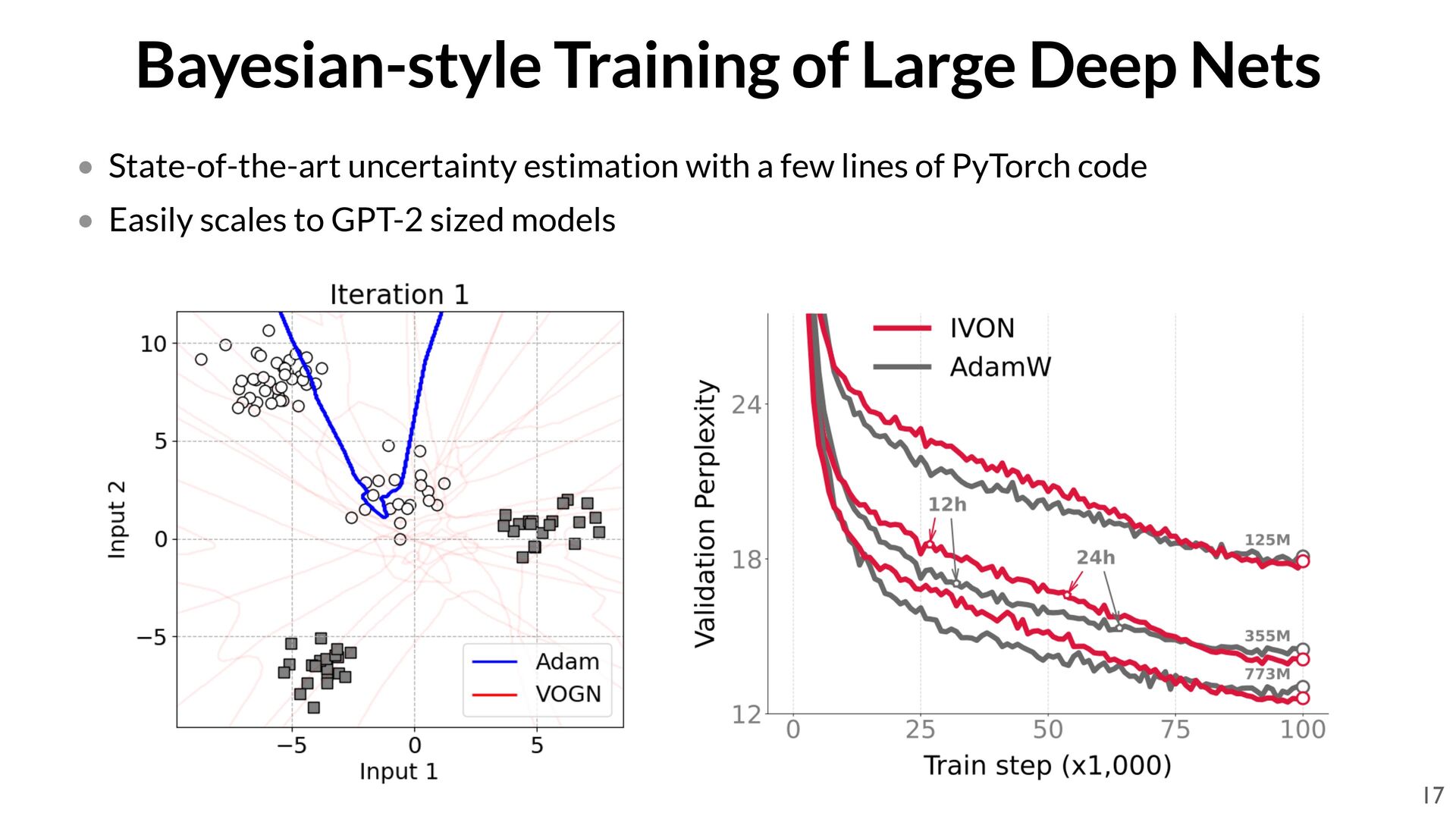
culty: fi rst step is a variational learning/inference problem • We restrict the family to Gaussians with diagonal covariance • We use the recent IVON (Improved Variational Online Newton) optimizer [1] • IVON is a scalable drop-in replacement for Adam/RMSprop which does mean- fi eld VI 1. Y. Shen*, N. Daheim*, …, T. Möllenhoff. Variational Learning is Effective for Large Deep Networks, ICML 2024 (Spotlight). 14
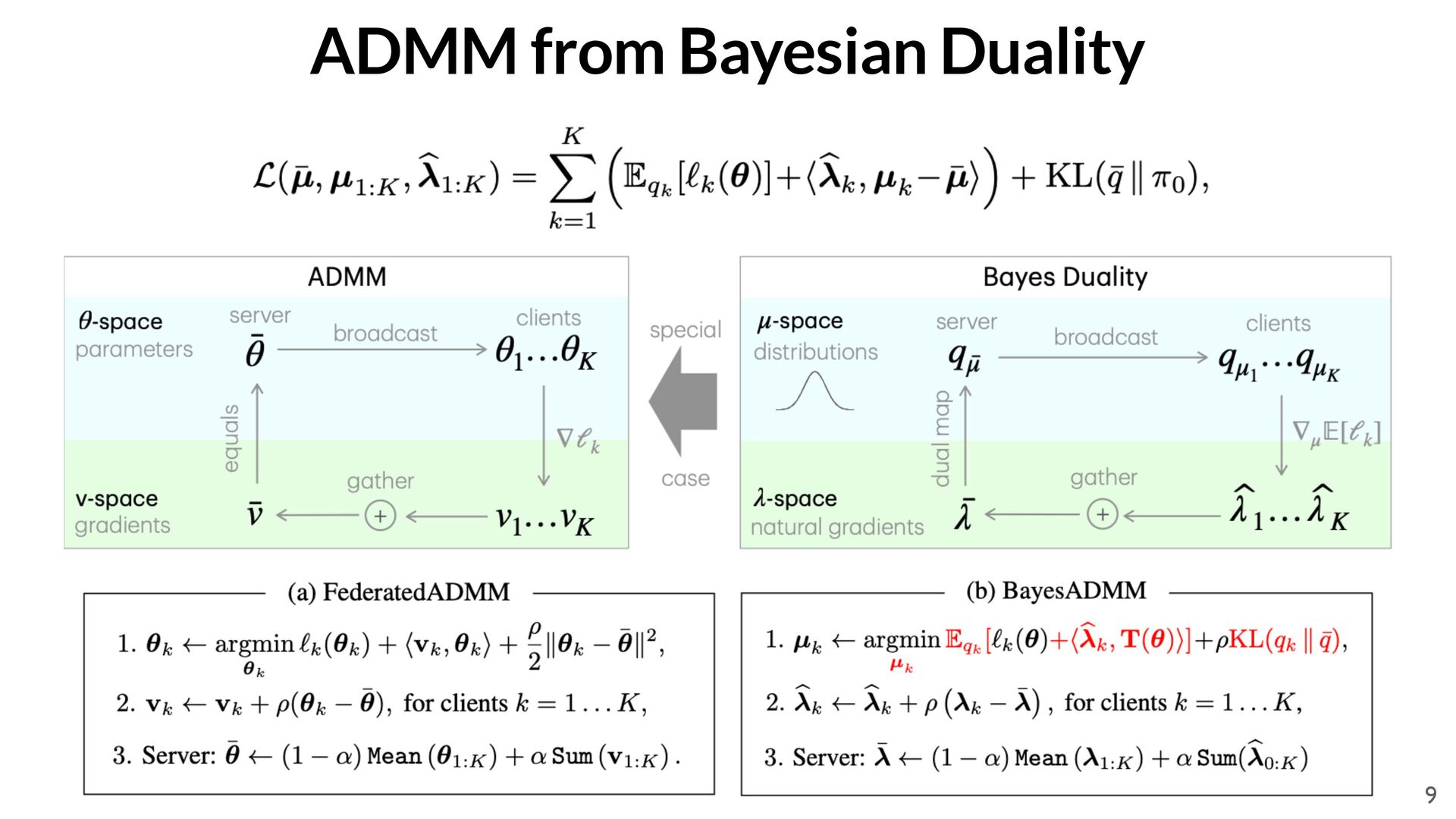
r`(✓) ˆ h ˆ g2 h (1 ⇢)h + ⇢ˆ h ✓ ✓ ↵(ˆ g + m)/( p h + ) <latexit sha1_base64="lMR1EEq84mMqe3ZqmU42lhTl4A0=">AAADlnicbVLbbtNAEN3YXEq4NKUvSLyMiKhspbk4KrcXVFEheKqCRNpK2SRabzZZq7u2tV5TIst/xNfwxt+wdl2C065l6ficmTkz4/VjESR6MPjTsOx79x883HnUfPzk6bPd1t7zsyRKFWVjGolIXfgkYSII2VgHWrCLWDEifcHO/cuTQj//wVQSROF3vY7ZVJJVGCwDSrSh5nuNX5gTna1yOMCCLTVRKrqCksMh8QXJATMhHKw508SFDJeemWILo2j2UyuZwRVnikFBFFGAk0AClkRzSkR2mjvy0FArSWZDF3KMm2V9fofnKsd0EemaS+XdlW7/popxwk1eS3e8LlY8coFDBwoElQk+LJ56450iYDZ0eLcKcmfDvmO+O3jBhJnTLbqUNQMJXcBExJwAODfdFl5lhpHdPjg1F76RXVOuvrp/kxxs7XTj6PWdU4dvarj5vNUe9AblgdvAq0AbVWc0b/3Gi4imkoWaCpIkE28Q62lGlA6oYHkTpwmLCb0kKzYxMCSSJdOsbCeH14ZZwDJS5g01lOz/GRmRSbKWvoks/nWyrRXkXdok1cv30ywI41SzkF4bLVMBOoLijsIiUIxqsTaAUBWYXoFyogjV5iY3zRK87ZFvg7Nhz3vbe/PtqH18VK1jB71Er5CDPPQOHaOvaITGiFr71gfrk3Viv7A/2p/tL9ehVqPK2Ue1Y4/+AgL8INo=</latexit> ˆ g ˆ r`(✓) where ✓ ⇠ N(m, 2) ˆ h ˆ g · (✓ m)/ 2 h (1 ⇢)h + ⇢ˆ h +⇢2(h ˆ h)2/(2(h + )) m m ↵(ˆ g + m)/(h + ) 2 1/(N(h + )) 1 2 3 4 5 1 2 3 4 5 τ min q(✓) E ✓⇠q h `(✓) + R(✓) i H(q) <latexit sha1_base64="zxzGAg831qqlwA1I9DetXeeD+WE=">AAAEvXichVNdbxJBFL1bUVv8KNVHXyaSGoiVgKnRNxu1WqMm9YO2SbdpZpcBNgy7sDtUcLPEv+mzf8MHz1ygKSLtbIZ758y55947M3g9HSSmWv3lrFzLXb9xc3Utf+v2nbvrhY17B0k0iH1V9yMdxUeeTJQOQlU3gdHqqBcr2fW0OvQ6r+3+4ZmKkyAKv5lRT510ZSsMmoEvDaDTwu/NR8LtBuFp6pq2MjITbr8/kA0xHo9dpXVpApfFY/Hl3Hfd/CwqFS4XkcaqkfVLCGeOSC/A5SwT4zkEwdK0PS/dzWaJhZsEXdHP3FdBSx8LUJZlnxcCPT7JLlYhnkzkfanTvazUL58WitVKlYdYdGpTp0jTsR9tOJJcalBEPg2oS4pCMvA1SUrwHVONqtQDdkIpsBhewPuKMsojdgCWAkMC7eC3hdXxFA2xtpoJR/vIojFjRAraxHzLih7YNquCn8D+wfzBWGtphpSVbYUjWA+Ka6z4CbihNhhXRXanzFktV0fargw16QV3E6C+HiO2T/9c5w12YmAd3hG0y8wWNDxen+EEQtg6KrCnPFMQ3HEDVrJVrBJOFSX0Ylh7+rae/CX9zTpLsKO4suXcIWcN+G4al96p5WroDjFjYBOm5RnOaLtscm8G3HdYa3yCvnI/yQJ/UuEsosRdtrjDhLboIzOs5ha07EnYEy3/XxmvvvbvG190Dp5WatuVZ5+3izsffk7e/yo9oIfIXaPntEN7tI9b8Z33TuQMnVHuZU7ldC6cUFec6X/mPs2N3Pe/N14VtQ==</latexit> M. E. Khan, H. Rue, The Bayesian Learning Rule, J. Mach. Learn. Res., 2023 λ′  = λ − ρF−1 λ ∇λ( 𝔼 q [ℓ + R] − H(q)) λ weighted by τ δ 2 ∥θ∥2 Unbiased estimator of (expected) diagonal Hessian Prompt/Context P(Next Word) Noisy weights!
Khan, Federated ADMM from Bayesian Duality, arXiv:2506.13150, 2025 Practical Deep Learning Implementation with IVON Required changes to FederatedADMM are highlighted in red.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}