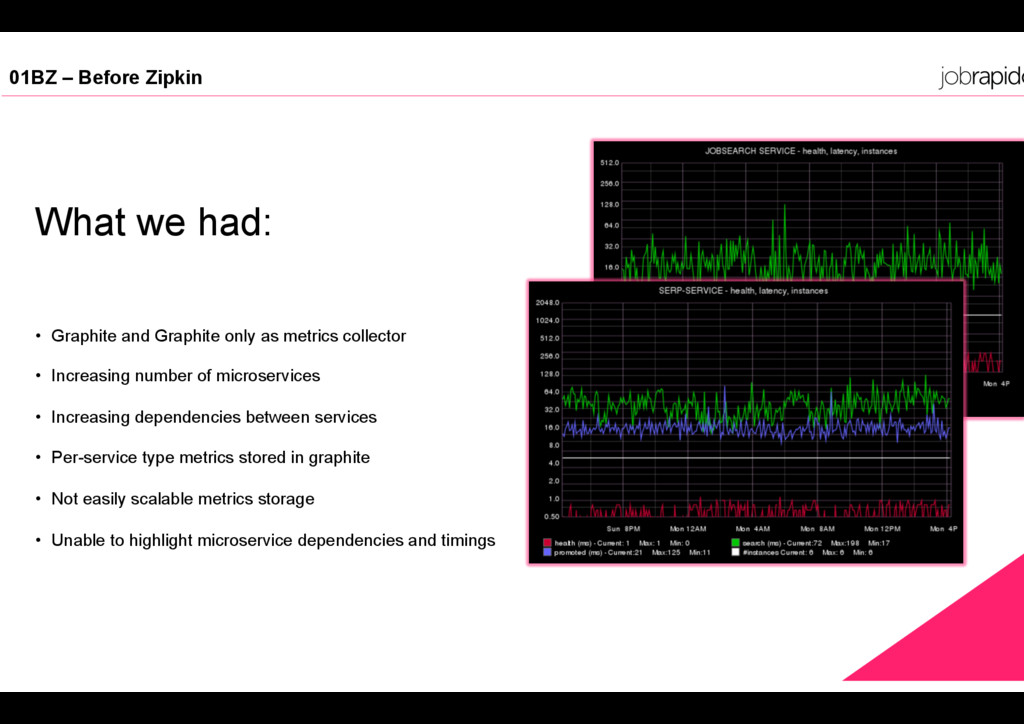
collector • Increasing number of microservices • Increasing dependencies between services • Per-service type metrics stored in graphite • Not easily scalable metrics storage • Unable to highlight microservice dependencies and timings Main Title 01BZ – Before Zipkin
collection system • An easy way to trace microservices interactions • A UI to render all microservices involved in a single search request • An easy way to analyze interaction in order to • Lifecycle of a search request • Find bottlenecks • Full execution time overview per request Main Title 01BZ – Before Zipkin
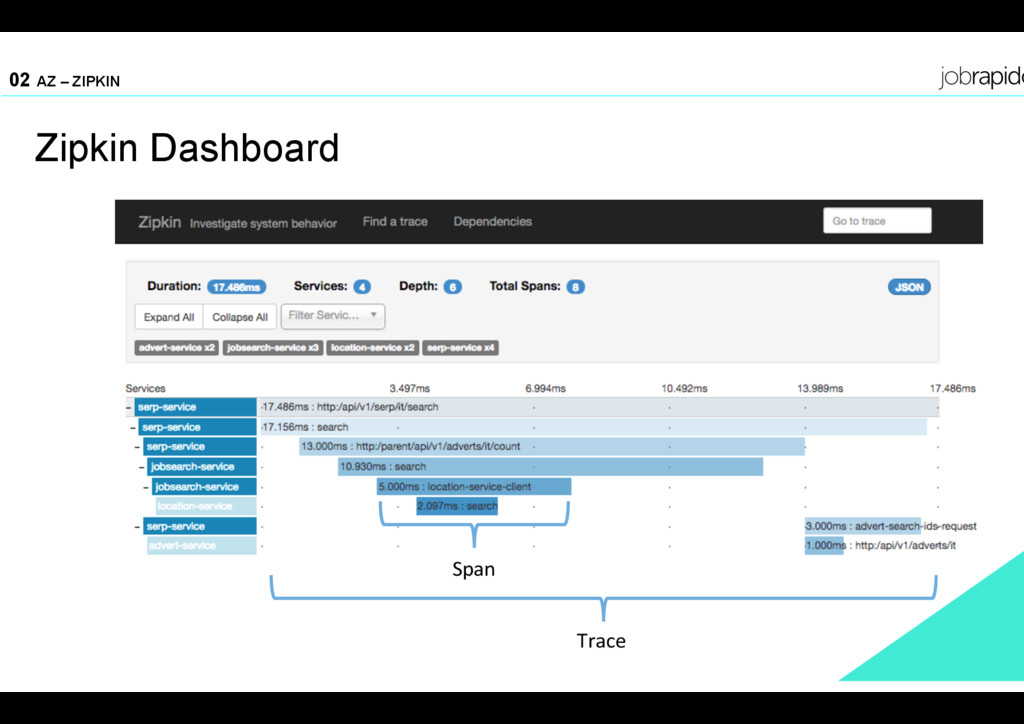
timing data needed to troubleshoot latency problems in microservice architectures. It manages both the collection and lookup of this data. Zipkin’s design is based on the Google Dapper. (http://zipkin.io/) Main Title 02 AZ – ZIPKIN Why zipkin • Native support for elasticsearch • Seamless integration in our Spring Boot microservices with Spring Cloud Sleuth • Inspired by a lot of experiences shared by other adopters during craft conf 2016
• Painless infrastructure configuration (Thanks DevOps team J ) • Tech support • All good “Elastic” features ( REST api, distributed, fault tolerant, scalable ) • Custom dashboards with Kibana
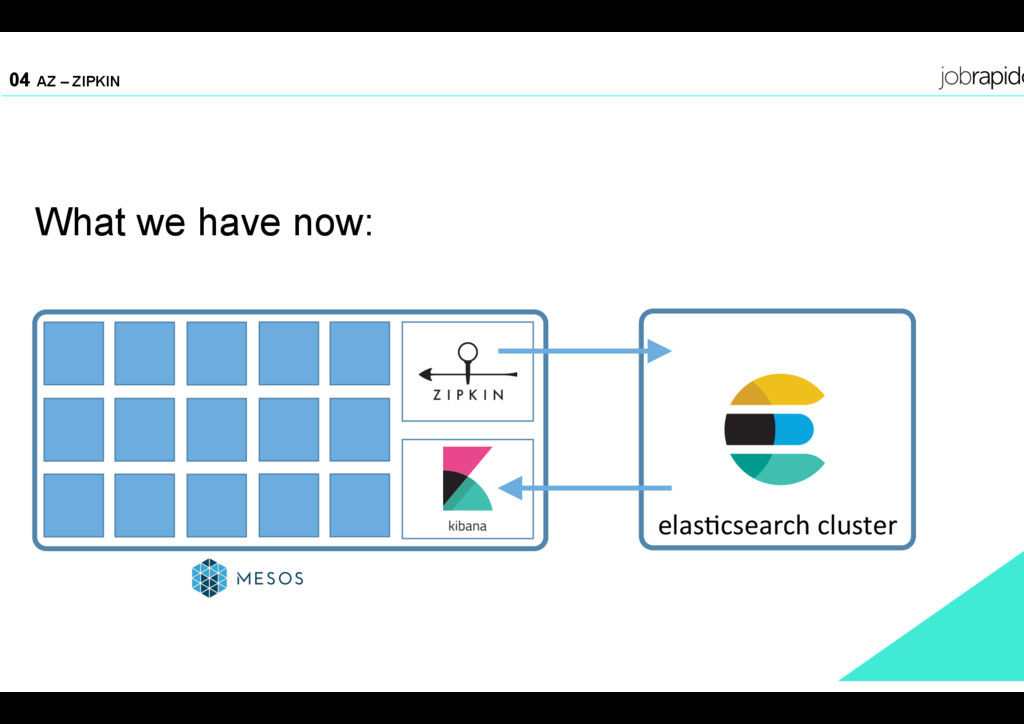
• Zipkin as a service in a mesos marathon cluster • Dedicated elasticsearch cluster for all tracing related document • A lot of tools to find and profile our services • Graphite as complementary tool
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}