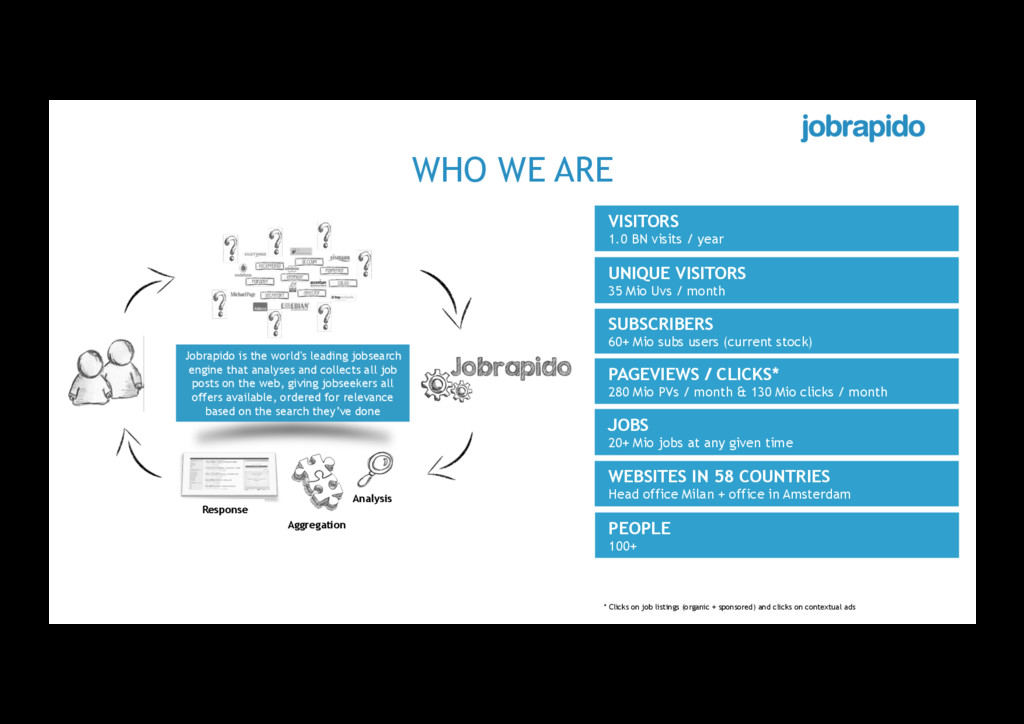
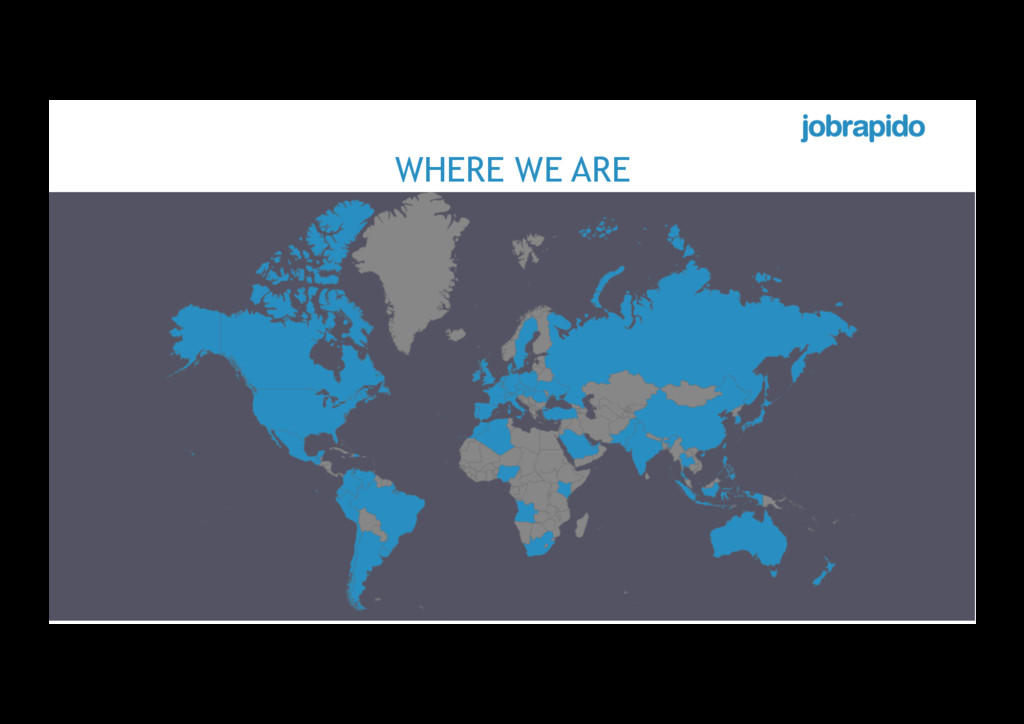
Amsterdam Jobrapido is the world's leading jobsearch engine that analyses and collects all job posts on the web, giving jobseekers all offers available, ordered for relevance based on the search they’ve done Analysis Aggregation Response * Clicks on job listings (organic + sponsored) and clicks on contextual ads WHO WE ARE UNIQUE VISITORS 35 Mio Uvs / month SUBSCRIBERS 60+ Mio subs users (current stock) PAGEVIEWS / CLICKS* 280 Mio PVs / month & 130 Mio clicks / month JOBS 20+ Mio jobs at any given time VISITORS 1.0 BN visits / year PEOPLE 100+
PICCINETTI ARNALDO DE MAIO FABIO ARCARI STEFANO FRIGERIO GIANLUCA TOMASINO MAGDA SWIERCZEK MICHELE PINTO VALENTINO MIAZZO FABIO RANFI LORENZO SANTI STEFANO ZANIN VALENTINA MISTRANGELO RAFFAELE SCOZZAFAVA ANDREA CHIAROT SHARATH PERAVALI ANDREA VAGHI GIUSEPPE LA TONA ARTURO GATTO LUIGI SAGGESE MARCELLO GRECO MAURIZIO BATTAGHINI ALBERTO BASOLI MARCO SIVIERO MICHELE PATERNITI PAOLO ZITELLI MARCO LOCATELLI ALINA CHELMUS FABIO PIZZATO GABRIELE TONINELLI ANTONELLA CIPRESSO FRANCESCO CARANTE
2012 2013 2014 2015 Apr 2012 - Jobrapido joins DMGT Mar 2014 - Jobrapido joins STG May 2014 – 1st Elasticsearch spike live on ao.jobrapido.com Jul 2014 – All Jobrapido websites moved to Elasticsearch Jul 2013 – Jobrapido websites migrated to Java Mar 2015 – Full-text relevance on all our websites Dec 2014 – Locations moved to Elasticsearch May 2015 – Dynamic sitemaps live Jun 2006 – Jobrapido founded Jan 2011 – Jobrapido counts 50 employees Dec 2009 – Jobrapido goes US and AU Jun 2011 – New Jobrapido HQ in Milan Dec 2007 – Jobrapido in Latin America (AR, CL and MX) Nov 2008 –Jobrapido goes France Dec 2006 – Jobrapido covers IT, UK, DE, AT, CH and ES Jun 2010 – Jobrapido goes Asia and Africa Sep 2010 – Jobrapido serves 50 countries Jul 2008 – Jobrapido reaches 3M unique visitors Aug 2009 – Jobrapido reaches 10M unique visitors Dec 2013 – Search&Match team established Dec 2015 – Jobrapido Jobsearch API Oct 2015 – Jobrapido counts 100 employees
limited to CPC and publish date • Debug and troubleshooting nearly impossible • Exact match was the only option • Slow reindex time (up to 10 days) • Custom and inaccurate language analysis • No high availability • Hard to scale 10
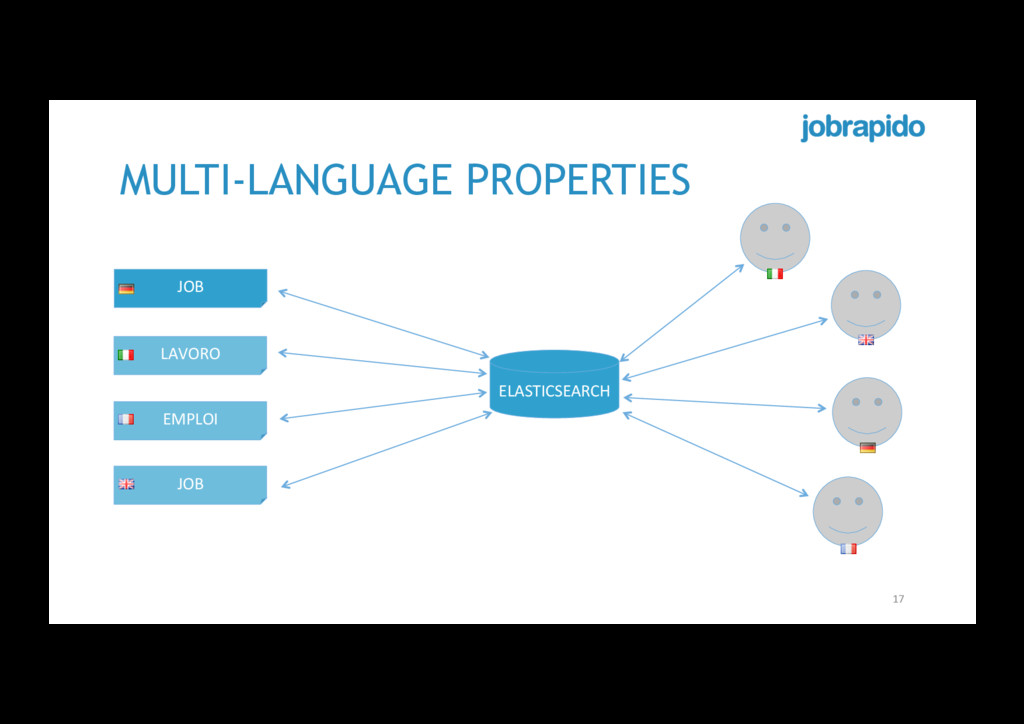
with filter (organic vs. sponsored jobs) • Each index implements country and language-specific analysers • A country may support more than one language • e.g., Canada, Switzerland, etc. 14 IT CH FR UK DE US IT.JOBRAPIDO.COM CH.JOBRAPIDO.COM DE.JOBRAPIDO.COM UK.JOBRAPIDO.COM FR.JOBRAPIDO.COM US.JOBRAPIDO.COM
SHINGLE HTML STRIP CHAR FILTER STANDARD LOWERCASE, GERMAN STOPWORDS, GERMAN STEMMER TOKENIZER FILTER HTML STRIP STANDARD STANDARD, LOWERCASE, GERMAN STOPWORDS HTML STRIP STANDARD POSSESSIVE, LOWERCASE, ENGLISH STOPWORDS, ENGLISH STEMMER HTML STRIP STANDARD ELISION, LOWERCASE, FRENCH STOPWORDS, FRENCH STEMMER HTML STRIP STANDARD ELISION, LOWERCASE, ITALIAN STOPWORDS, ITALIAN STEMMER HTML STRIP STANDARD LOWERCASE, GERMAN STOPWORDS, GERMAN STEMMER, SHINGLE
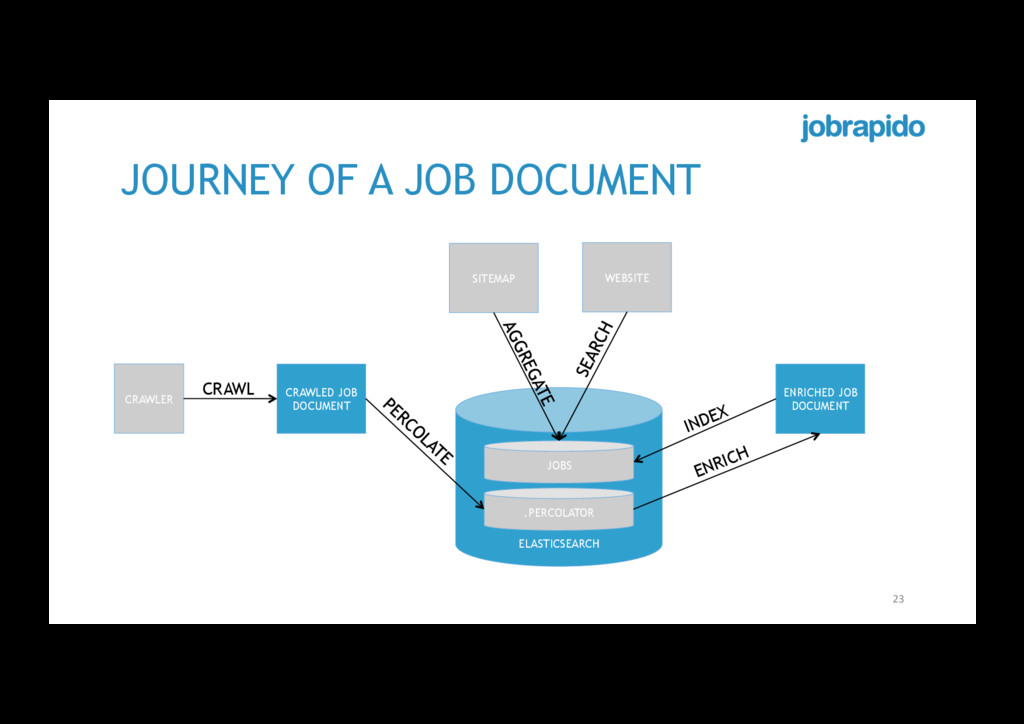
cannot easily find in structured documents • Only few websites explicitly show job titles and industry • What if we build a taxonomy of job titles/industry represented by queries? • That would allow enriching documents at index time by means of percolators 21
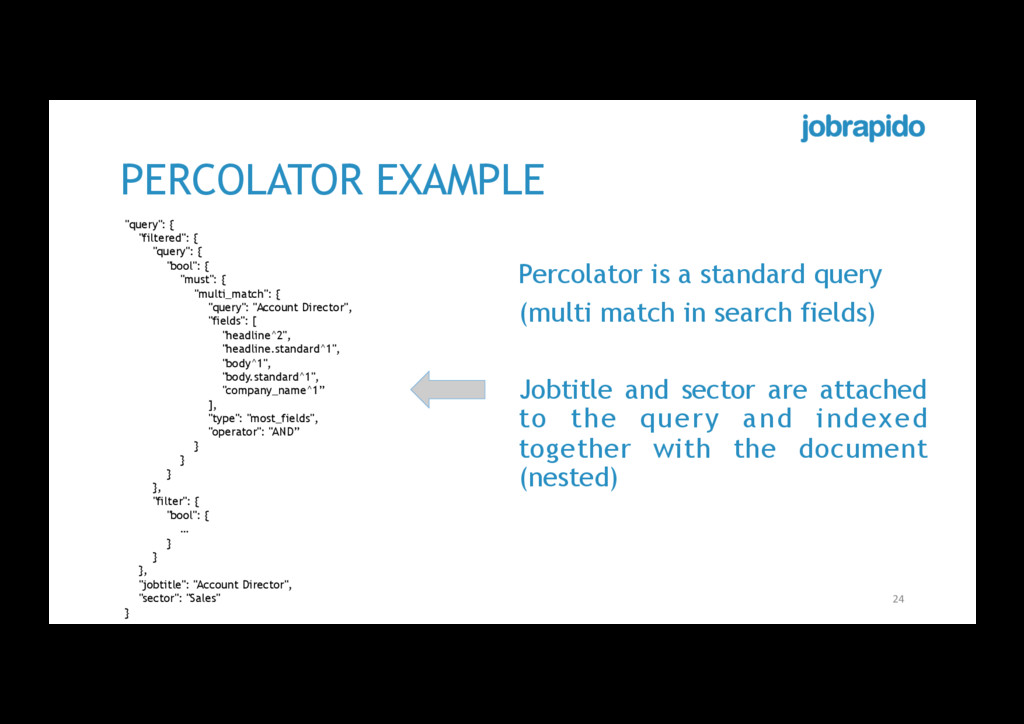
"bool": { "must": { "multi_match": { "query": "Account Director", "fields": [ "headline^2", "headline.standard^1", "body^1", "body.standard^1", "company_name^1” ], "type": "most_fields", "operator": "AND” } } } }, "filter": { "bool": { … } } }, "jobtitle": "Account Director", "sector": "Sales" } Percolator is a standard query (multi match in search fields) Jobtitle and sector are attached to the query and indexed together with the document (nested)
classification based on keywords (+) • Aggregate by industry and sub-aggregate by location (+) • Slower reindex time (-) • Reindex all 10x slower • Aggregations are heavy (-) • Caching required • Inaccurate since the population is dynamic • Try to be consistent with your queries • e.g., percolators do not support min_score, whereas queries do 25
classification based on keywords (+) • Aggregate by industry and sub-aggregate by location (+) • Slower reindex time (-) • Reindex all 10x slower • Aggregations are heavy (-) • Caching required • Inaccurate since the population is dynamic • Try to be consistent with your queries • e.g., percolators do not support min_score, whereas queries do 26
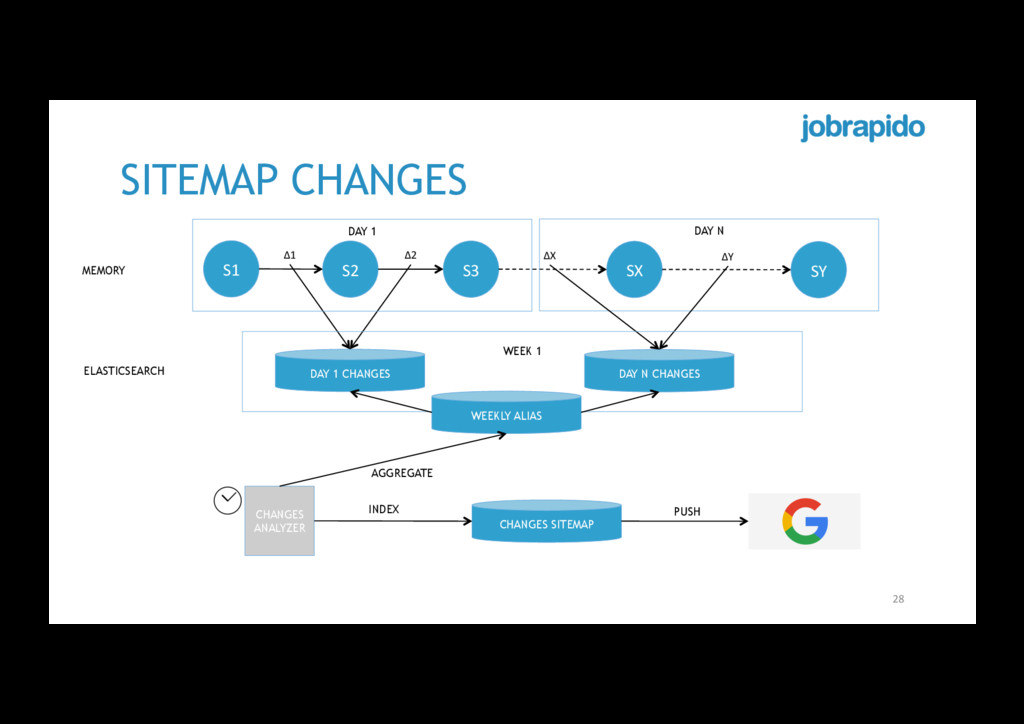
lifecycle cause link churn • Sitemaps are heavy • Tons of jobtitle and locations • Google periodically crawls sitemaps • Google allows pushing sitemap changes • We do not want to push unstable changes 27
S3 SY Δ1 Δ2 ΔX ΔY MEMORY DAY N DAY 1 CHANGES DAY N CHANGES DAY 1 ELASTICSEARCH WEEK 1 WEEKLY ALIAS CHANGES ANALYZER AGGREGATE CHANGES SITEMAP PUSH INDEX
there is no max_doc_count filter • A small and separate use-case allowed us to test ES 2.0 • ES 2.0 provides pipeline aggregations (experimental) • Pipeline aggregations work on the outputs produced from other aggregations rather than from document sets • After the pipeline aggregation we query back the changes index to get only the documents we need 29
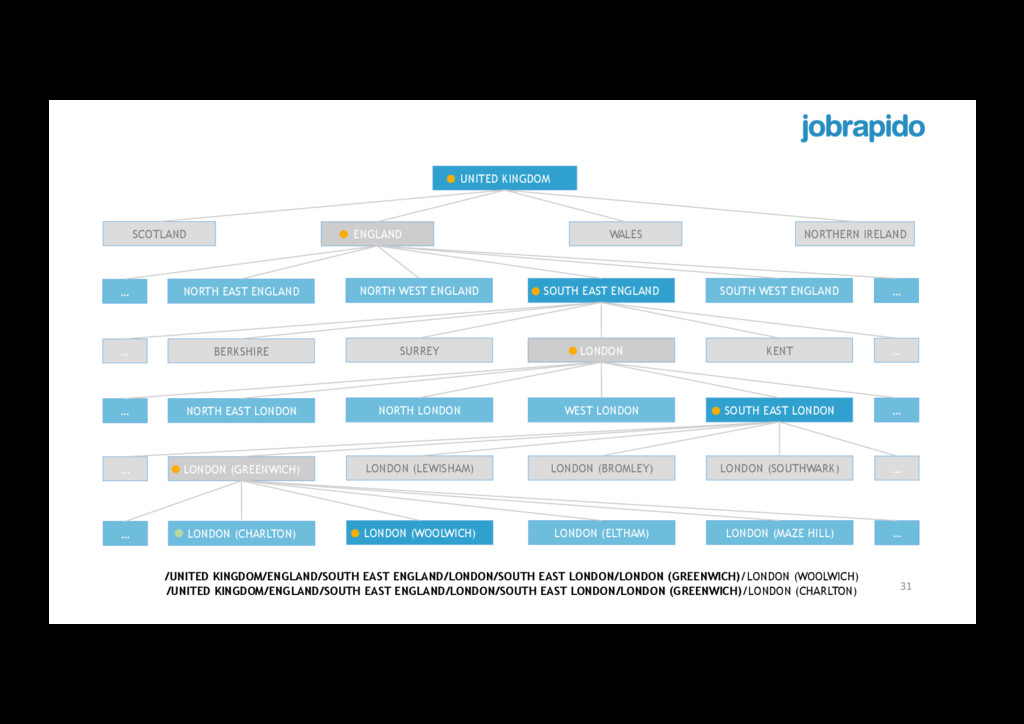
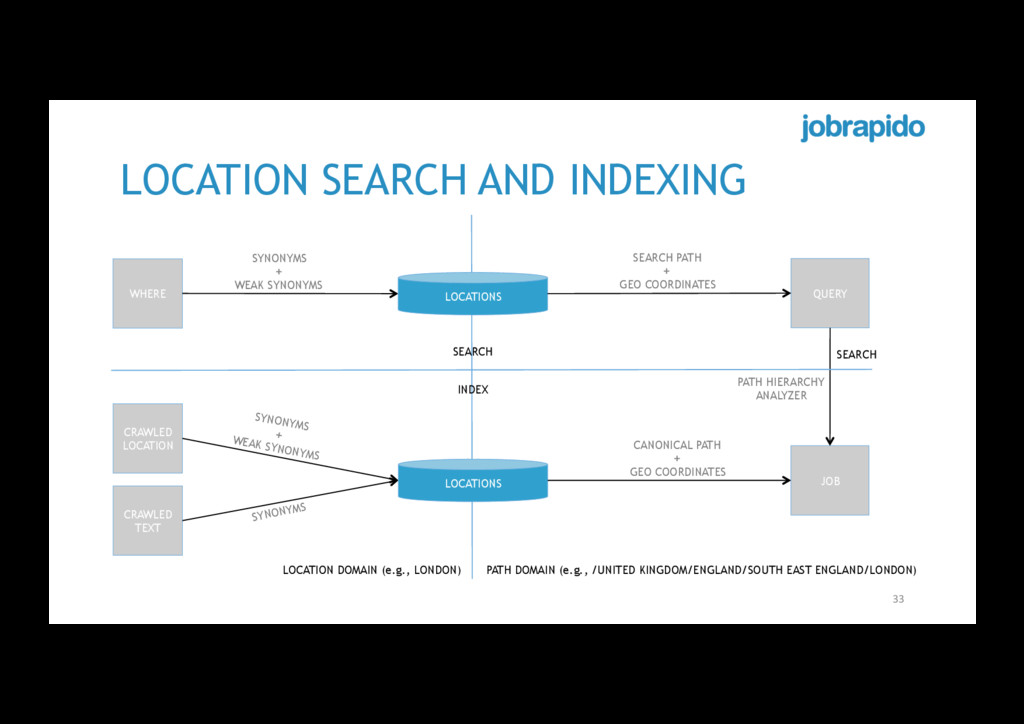
EAST ENGLAND NORTH WEST ENGLAND SOUTH EAST ENGLAND SOUTH WEST ENGLAND … … BERKSHIRE SURREY LONDON KENT … … NORTH EAST LONDON NORTH LONDON WEST LONDON SOUTH EAST LONDON … … LONDON (GREENWICH) LONDON (LEWISHAM) LONDON (BROMLEY) LONDON (SOUTHWARK) … … LONDON (CHARLTON) LONDON (WOOLWICH) LONDON (ELTHAM) LONDON (MAZE HILL) … … /UNITED KINGDOM/ENGLAND/SOUTH EAST ENGLAND/LONDON/SOUTH EAST LONDON/LONDON (GREENWICH)/LONDON (WOOLWICH) /UNITED KINGDOM/ENGLAND/SOUTH EAST ENGLAND/LONDON/SOUTH EAST LONDON/LONDON (GREENWICH)/LONDON (CHARLTON)
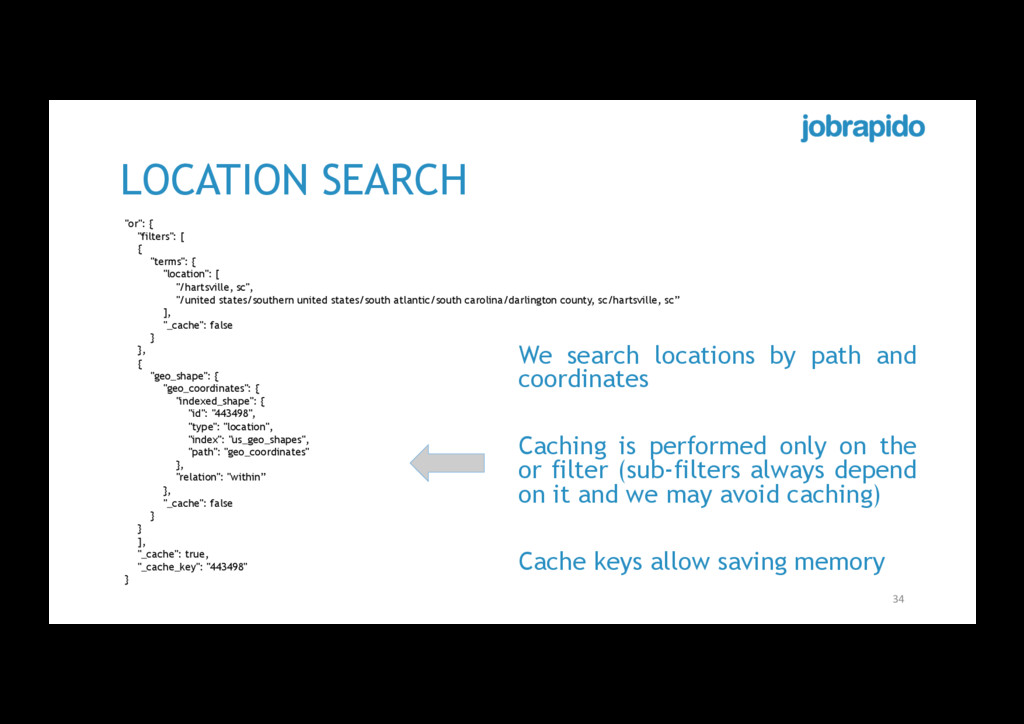
{ "location": [ "/hartsville, sc", "/united states/southern united states/south atlantic/south carolina/darlington county, sc/hartsville, sc” ], "_cache": false } }, { "geo_shape": { "geo_coordinates": { "indexed_shape": { "id": "443498", "type": "location", "index": "us_geo_shapes", "path": "geo_coordinates" }, "relation": "within” }, "_cache": false } } ], "_cache": true, "_cache_key": "443498" } We search locations by path and coordinates Caching is performed only on the or filter (sub-filters always depend on it and we may avoid caching) Cache keys allow saving memory
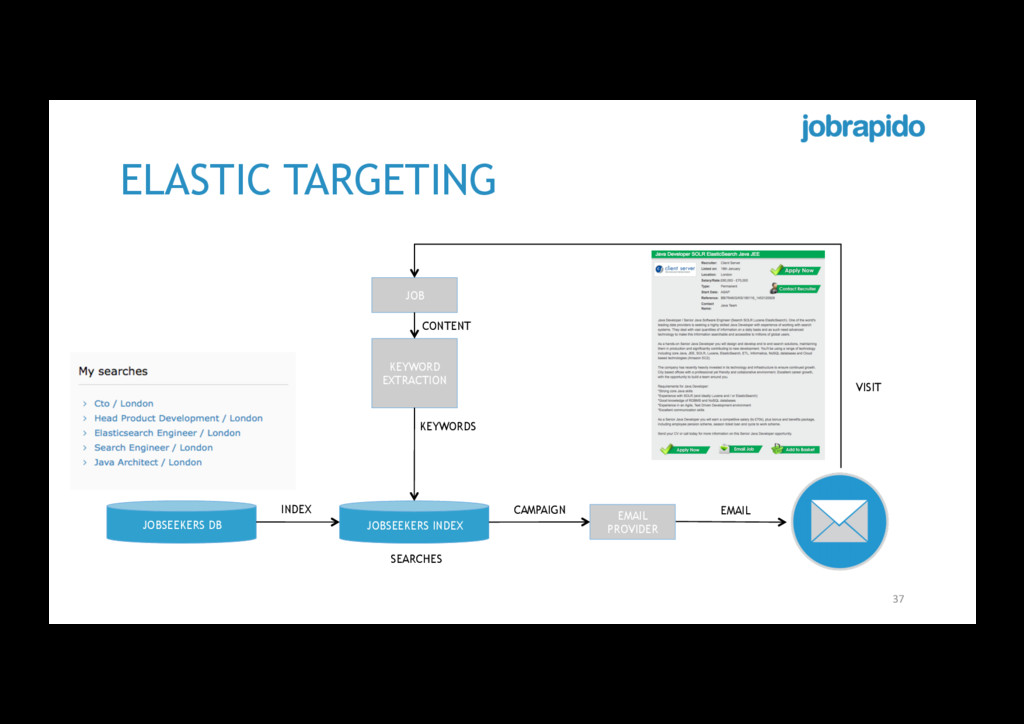
get • Applications (CVs) • Traffic • How do we provide qualified candidates on demand? • We should notify only relevant jobseekers • Interested • Active • No pressure • We want to maximize the chance of delivering the right candidate 36
keywords on the jobseeker’s saved searches • Apply same mapping of the pure search scenario (be consistent with the user search experience) • Synonyms • Apply synonyms to increase matching rate • Fuzziness • Users often misspell words (and sometimes advertisers do) • Aggregation • Give more weight to jobseekers with more than one search matching • First test with Elasticsearch 2.1.1 38
Percolations and aggregations allow for document enrichment and dynamic sitemap creation • Pipeline aggregations ease push of significant sitemap changes to Google • Path hierarchies to cleverly represent location structure • We search not only jobs but also jobseekers • Index and search like a pro J • Documentation: https://www.elastic.co/guide/index.html • Training: thanks Luca and Karel J • Book: Elasticsearch – The Definitive Guide • Support: Jobrapido is a proud platinum customer (production and development advice) – thanks Antonio J • Thanks to Michele Solazzo and Kiratech for their commercial support 39
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}