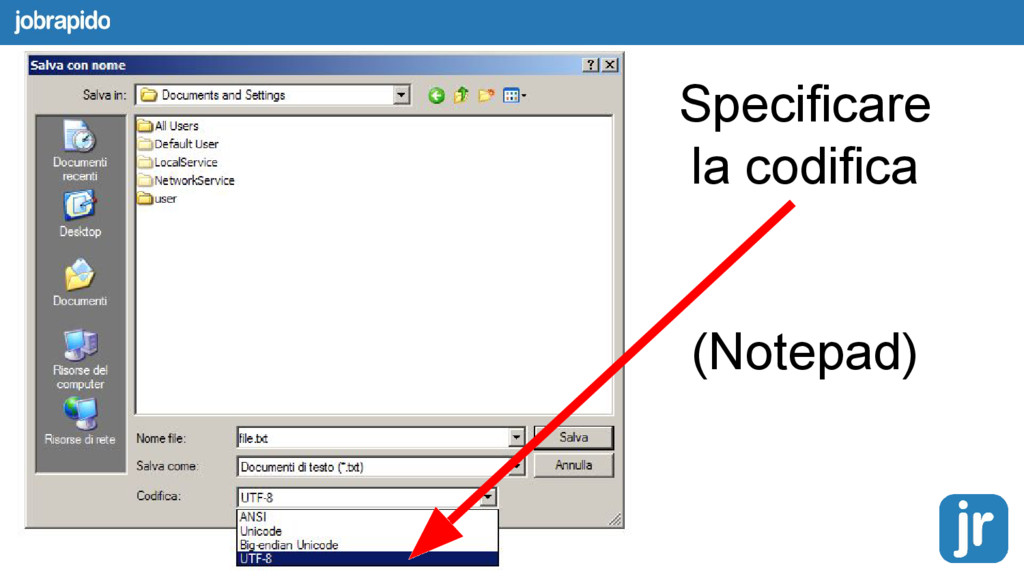
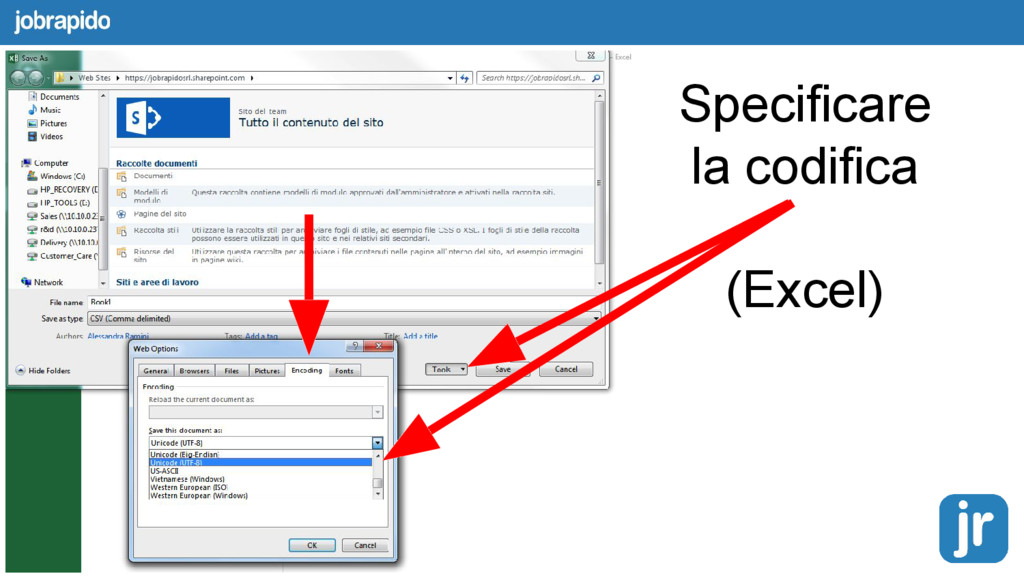
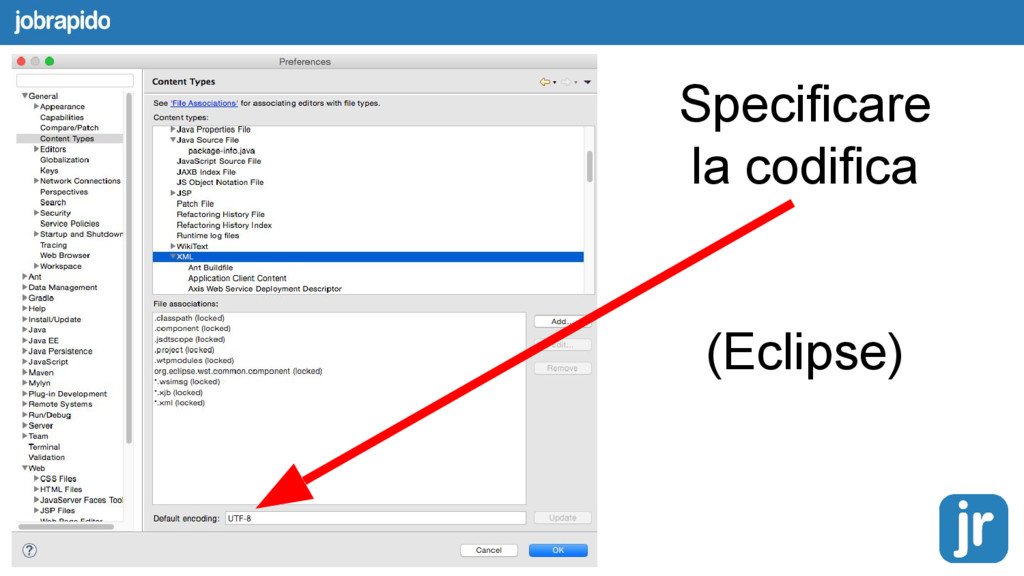
Filippo;Piazza Duomo;328-923212;1980-02-04 Luisa;Piazza Cordusio;02-123456;1979-03-12 Name,Address,Birthdate Francesco,Via Torino,1977-01-01 Filippo,Piazza Duomo,1980-02-04 Luisa,Piazza Cordusio,1979-03-12 Name,Address,Birthdate Arsène,50 rue de Varenne,1977-01-01 Adélaïde,134 rue du Fbg. St-Honoré,1980-02-04 Bénédicte,rue de la Paix,1979-03-12 Name,Address,Birthdate Ars?ne,50 rue de Varenne,1977-01-01 Ad?la?de,134 rue du Fbg. St-Honor?,1980-02-04 B?n?dicte,rue de la Paix,1979-03-12 Name,Address,Birthdate Ирина,ул. Донская,1977-01-01 Андрей,Проспект вернадского,1980-02-04 Виктория,Невский проспект,1979-03-12 Name,Address,Birthdate ?????,??. ???????,1977-01-01 ??????,???????? ???????????,1980-02-04 ????????,??????? ????????,1979-03-12
{kind=link}
{kind=link}
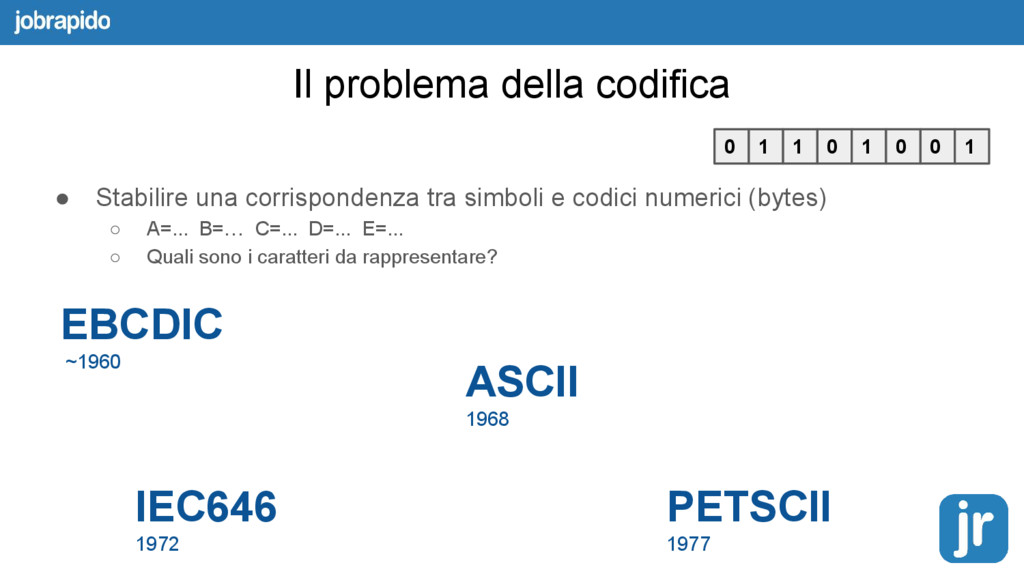{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
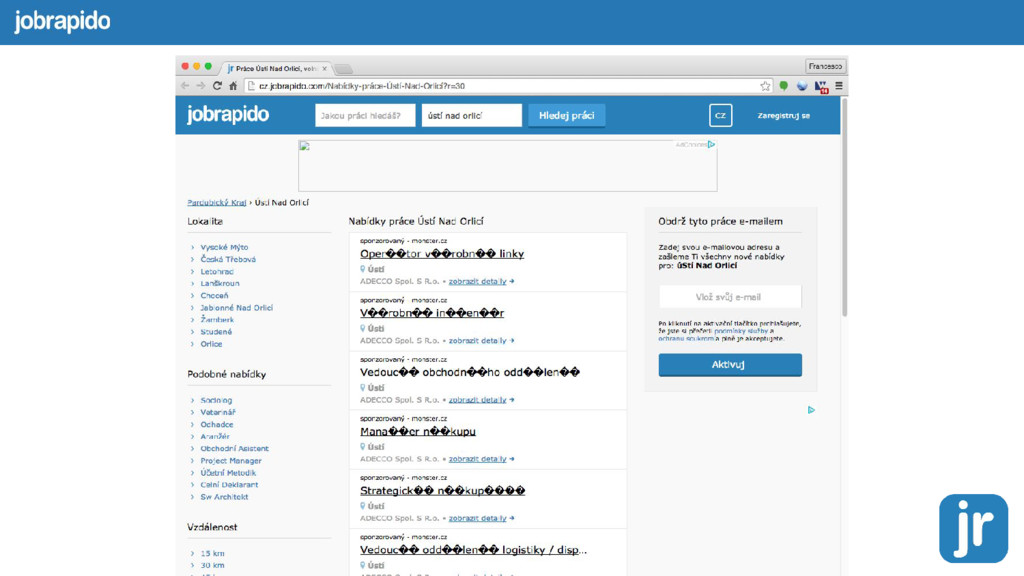{kind=link}
{kind=link}
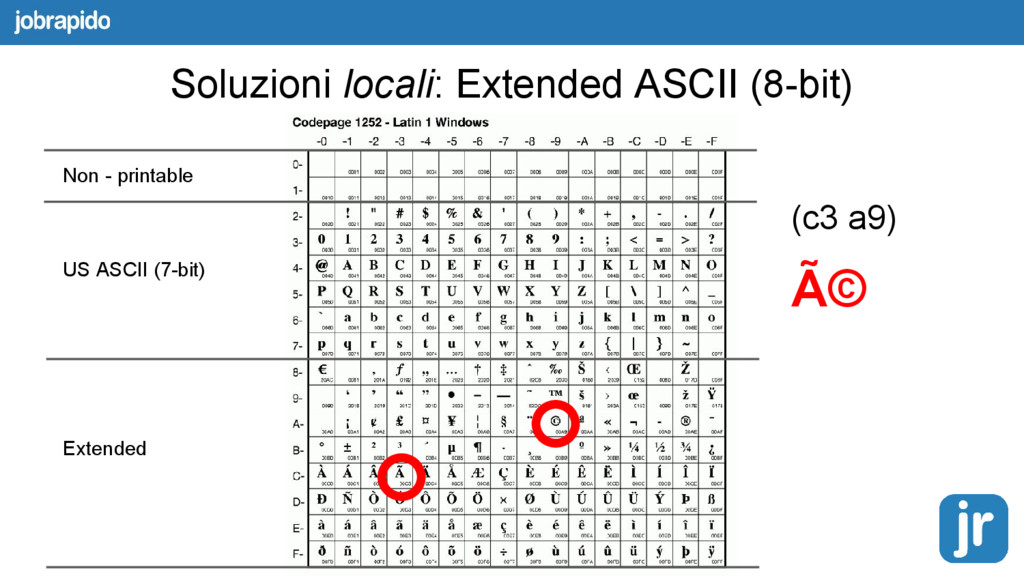{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}