Array[String]) {! // Connect to the Cassandra Cluster! val client: CassandraConnector = new CassandraConnector()! val cassandraNode = if(args.length > 0) args(0) else "127.0.0.1"! client.connect(cassandraNode)! client.execute("CREATE KEYSPACE IF NOT EXISTS streaming_test WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1 } ;")! client.execute("CREATE TABLE IF NOT EXISTS streaming_test.words (word text PRIMARY KE count int);")! // Create a StreamingContext with a SparkConf configuration! val sparkConf = new SparkConf()! .setAppName(“StreamingDemo”)! val ssc = new StreamingContext(sparkConf, Seconds(5))! ! // Create a DStream that will connect to serverIP:serverPort! val lines = ssc.socketTextStream("localhost", 9999)! ! client.execute("USE streaming_test;")! lines.foreachRDD(rdd => {! rdd.collect().foreach(line => {! if (line.length > 1) {! client.execute("INSERT INTO words (word, count)" + "VALUES ('" + line + "', 1); }! println("Line from RDD: " + line)! })! })! ssc.start()! }! } (1) Spark Streaming - Storing to C* Use Spark-C* connector Replace by a RabbitMQ or Kafka stream.
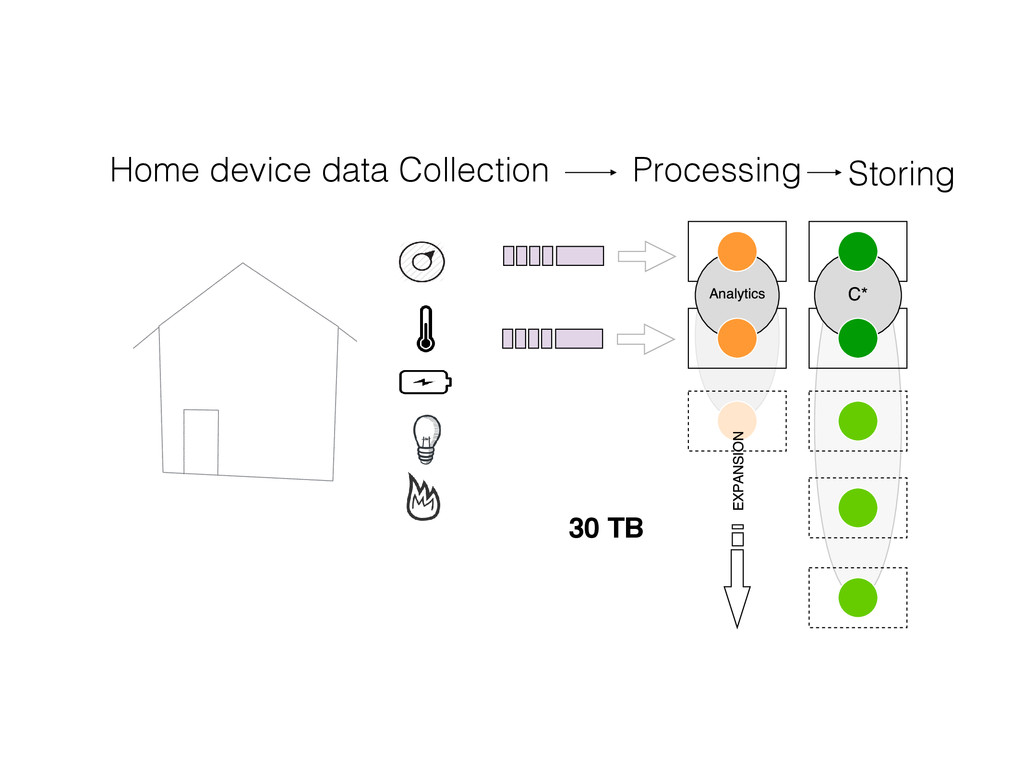
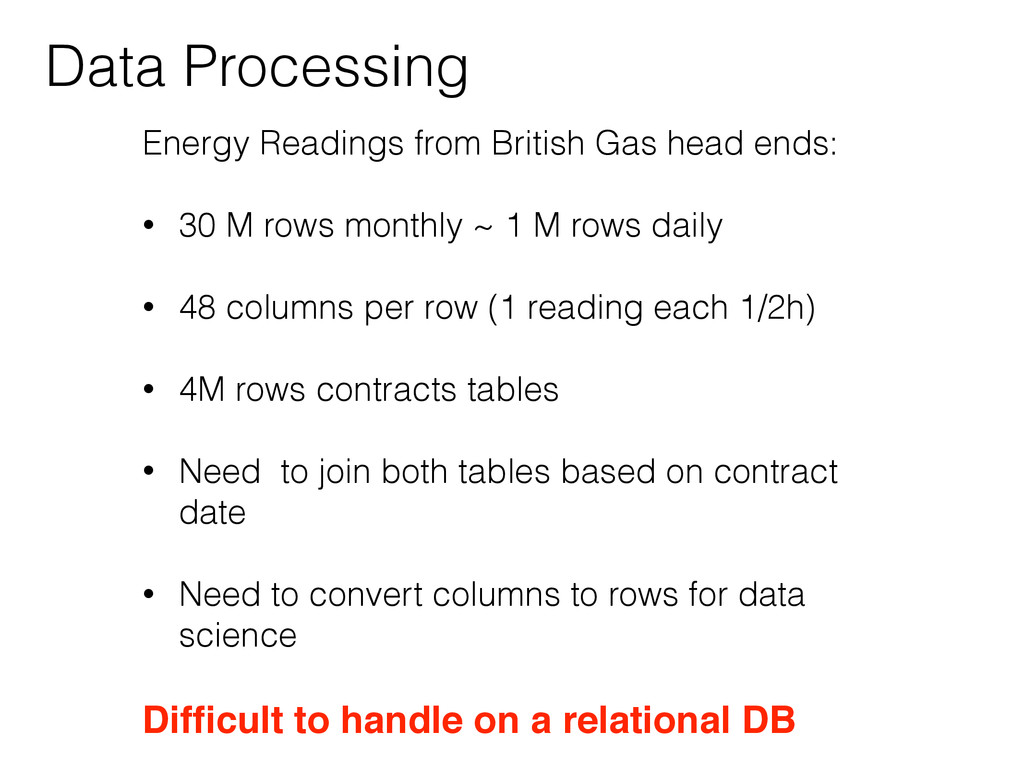
• 30 M rows monthly ~ 1 M rows daily ! • 48 columns per row (1 reading each 1/2h) ! • 4M rows contracts tables ! • Need to join both tables based on contract date ! • Need to convert columns to rows for data science ! Difficult to handle on a relational DB
(0 to 47).map(i => f"t${i/2}%02d${30*(i%2)}%02d") // Create se column names! val row = data._2._1.head! val contracts = data._2._2! val readDate = row.get[Date]("reading_date")! val current_contract = contracts.filter(c => c.get[Date]("move_in_date").before(readDate)) .sortBy(_.get[Date]("move_in_date"))! .reverse! .head! ! ! ! halfHourlyColumnNames.map(col => (! row.get[String]("mpxn"),! new SimpleDateFormat("yyyy-MM").format(readDate),! "elec",! new SimpleDateFormat("yyyy-MM-dd hhmm").parse(new SimpleDateFormat("yyyy-MM-dd ").format(readDate) + col.drop(1)),! row.get[Option[Double]](col).getOrElse(0.0),! current_contract.get[String]("business_partner"),! current_contract.get[String]("contract_account"),! current_contract.get[String]("premise"),! current_contract.get[String]("postcode_gis")! )! )! } (2) Transformations and Joins Get the right Create a row for
R and C# ! • Fridge energy calculation algorithm • -> 1000 loc in C# ! • Spark allows us to reduce from 1000 to 400 loc ! • We translate R and C# to Java / Scala ! • Would be great if Scala was the language of choice for Data scientists
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![object TransformReadings {! def main(args: Array[String]) {! val cassandraHost =](https://files.speakerdeck.com/presentations/b678d97040e10132e593723ed83df33f/slide_22.jpg){kind=link}
![def transformRow (data: (String, (Iterable[CassandraRow],Iterable[CassandraRow]))) = {! val halfHourlyColumnNames =](https://files.speakerdeck.com/presentations/b678d97040e10132e593723ed83df33f/slide_23.jpg){kind=link}
{kind=link}
![def main(args: Array[String]) = {! val sparkConf = new SparkConf().{…}!](https://files.speakerdeck.com/presentations/b678d97040e10132e593723ed83df33f/slide_25.jpg){kind=link}
{kind=link}