Your Rails app is full of data that can (and should!) be turned into useful information with some simple machine learning techniques. We'll look at basic techniques that are both immediately applicable and the foundation for more advanced analysis -- starting with your Users table.
We will cover the basics of assigning users to categories, segmenting users by behavior, and simple recommendation algorithms. Come as a Rails dev, leave a data scientist.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Exercise 2: Code users.each do |user| ! if user[:current_login_ip].match(Resolv::IPv4::Regex)](https://files.speakerdeck.com/presentations/e0d68fd0b785013184ac42b7f74d85e8/slide_37.jpg){kind=link}
![Exercise 2: Code users.each do |user| ! json = conn.get("/json/#{user[:current_login_ip]}").body](https://files.speakerdeck.com/presentations/e0d68fd0b785013184ac42b7f74d85e8/slide_38.jpg){kind=link}
![Exercise 2: Code users.each do |user| ! demo.insert(user_id: user[:id], lat:](https://files.speakerdeck.com/presentations/e0d68fd0b785013184ac42b7f74d85e8/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
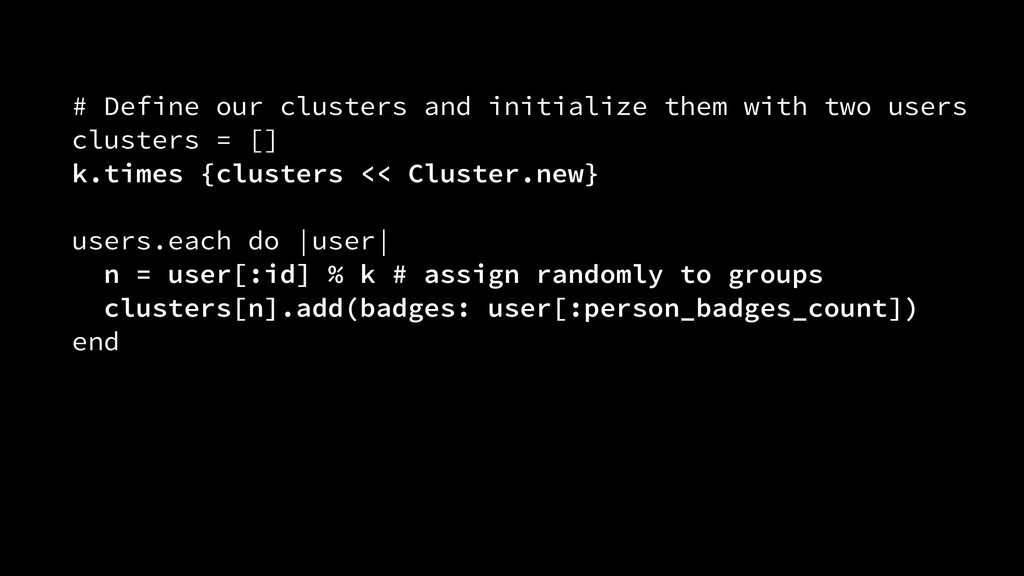{kind=link}
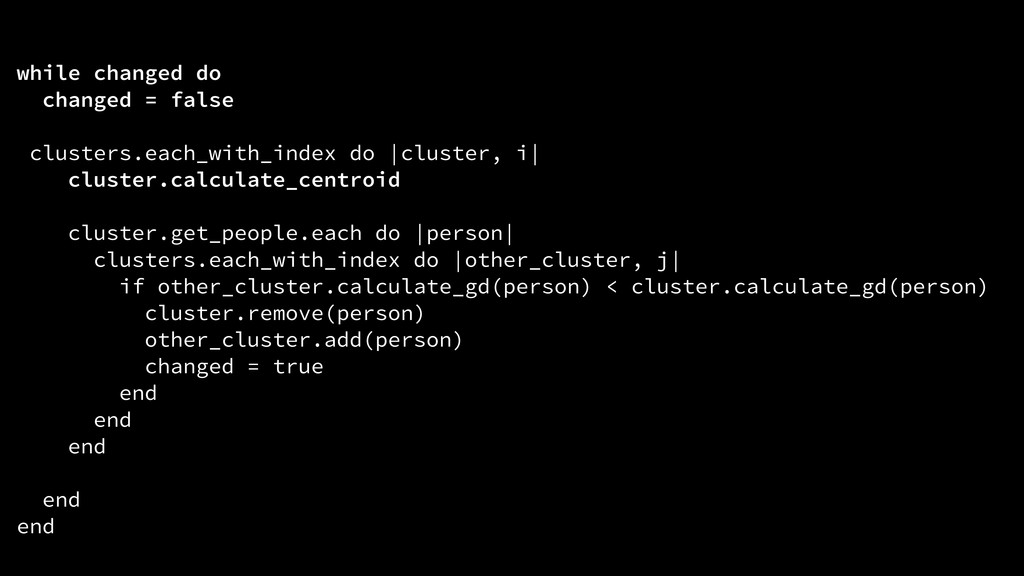{kind=link}
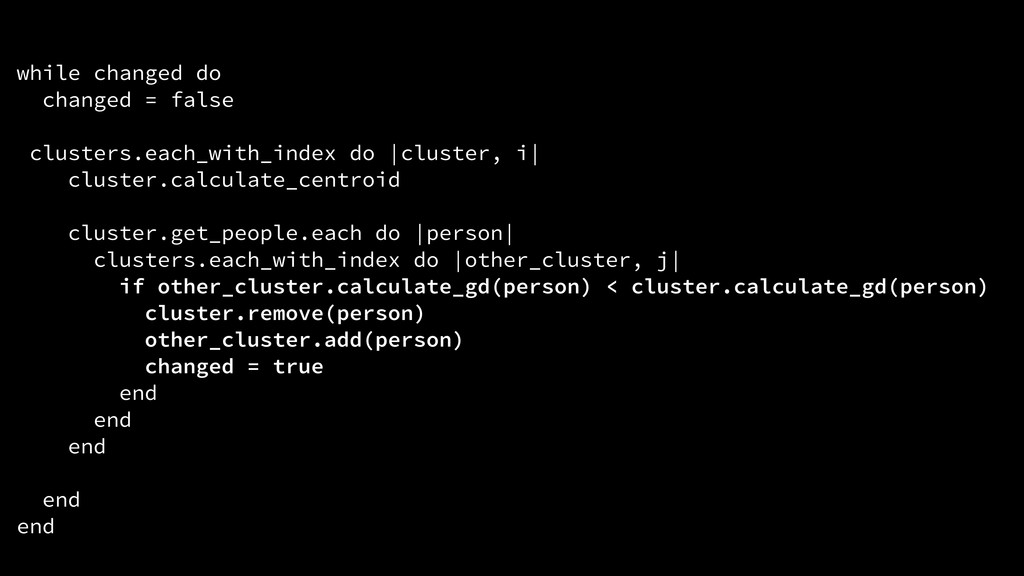{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
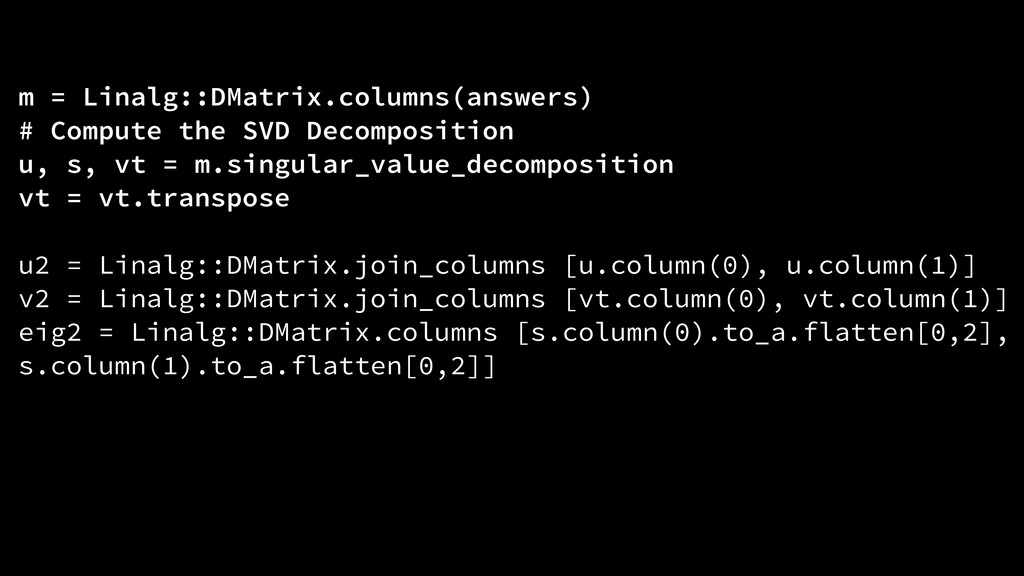{kind=link}
{kind=link}
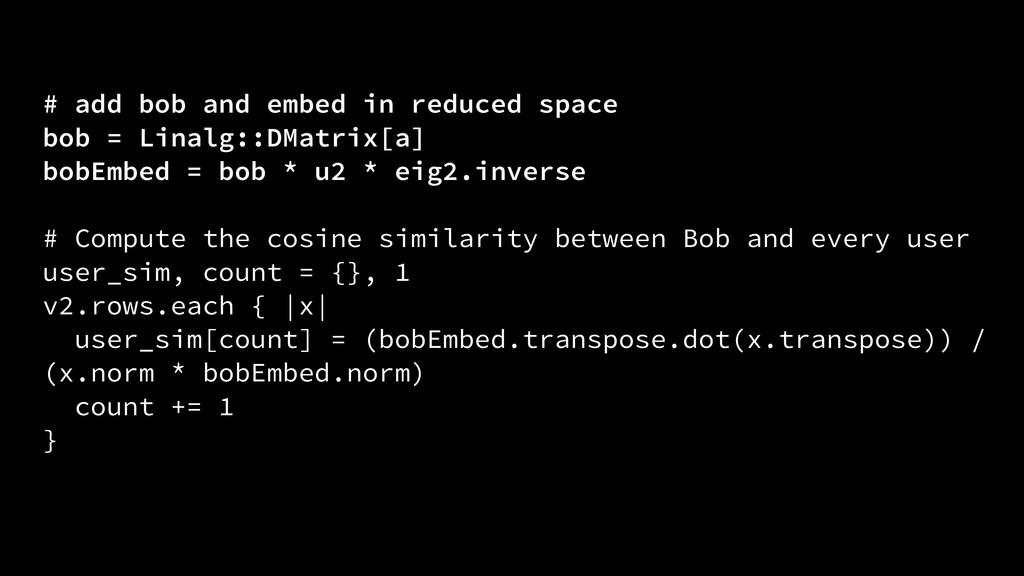{kind=link}
{kind=link}
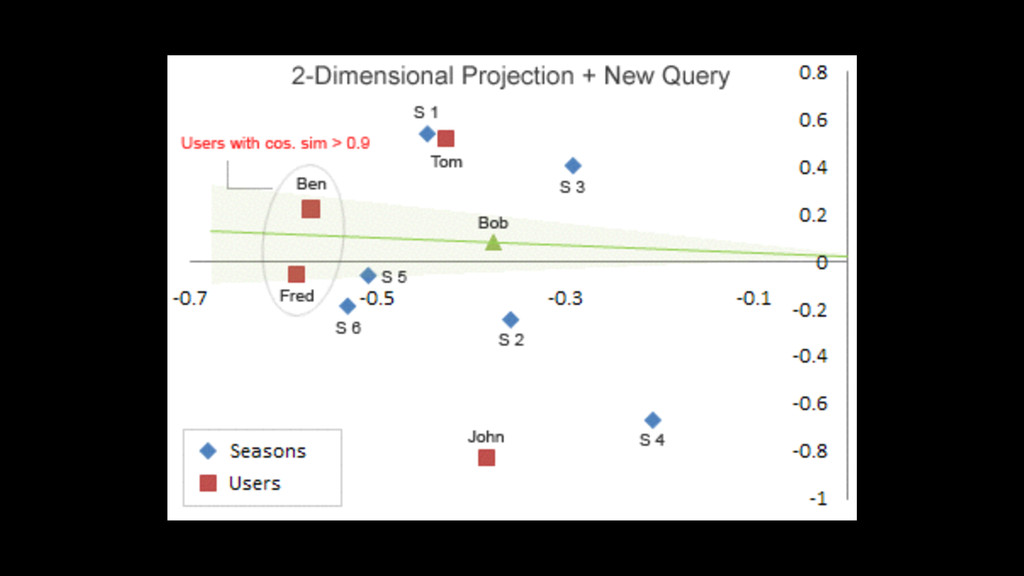{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contact • John Paul Ashenfelter • [email protected] • @johnashenfelter](https://files.speakerdeck.com/presentations/e0d68fd0b785013184ac42b7f74d85e8/slide_75.jpg){kind=link}
{kind=link}
{kind=link}
![John Paul Ashenfelter • [email protected] • @johnashenfelter](https://files.speakerdeck.com/presentations/e0d68fd0b785013184ac42b7f74d85e8/slide_78.jpg){kind=link}
{kind=link}
{kind=link}