transferring, or exchanging products, services, and/or information via computer networks, including the Internet.” In Overview of electronic commerce by Efraim Turban and David King (2011). 3
customer engagement and click-through rate. • Using target marketing activities and recommendations systems. • Mainly three approaches for building recommendation systems [CMS97]: 4 Collaborative filtering Recommend products to a user based on what similar users brought. Content-based filtering Recommend products that are similar to those that an user brought in the past. Hybrid recommender systems Recommendations are based on a combination of Collaborative filtering and Content-based filtering.
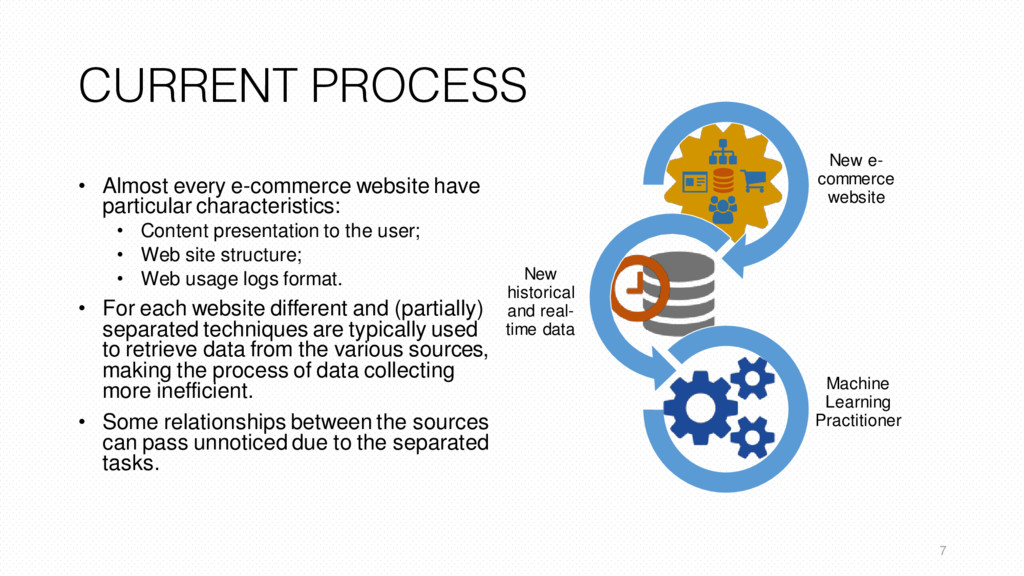
Machine Learning Practitioner • Almost every e-commerce website have particular characteristics: • Content presentation to the user; • Web site structure; • Web usage logs format. • For each website different and (partially) separated techniques are typically used to retrieve data from the various sources, making the process of data collecting more inefficient. • Some relationships between the sources can pass unnoticed due to the separated tasks. 7 CURRENT PROCESS
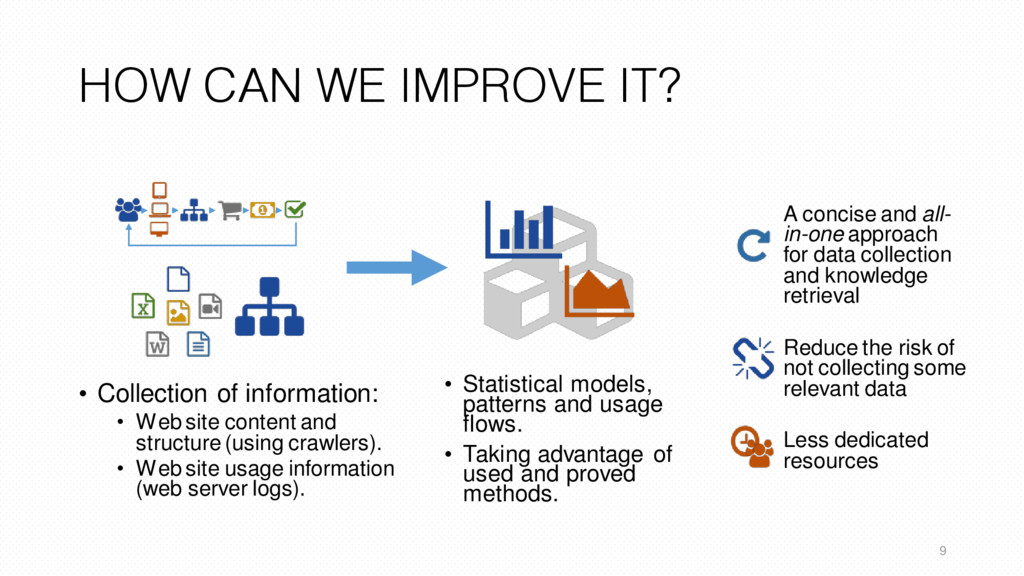
in-one approach for data collection and knowledge retrieval Reduce the risk of not collecting some relevant data Less dedicated resources • Collection of information: • Web site content and structure (using crawlers). • Web site usage information (web server logs). • Statistical models, patterns and usage flows. • Taking advantage of used and proved methods.
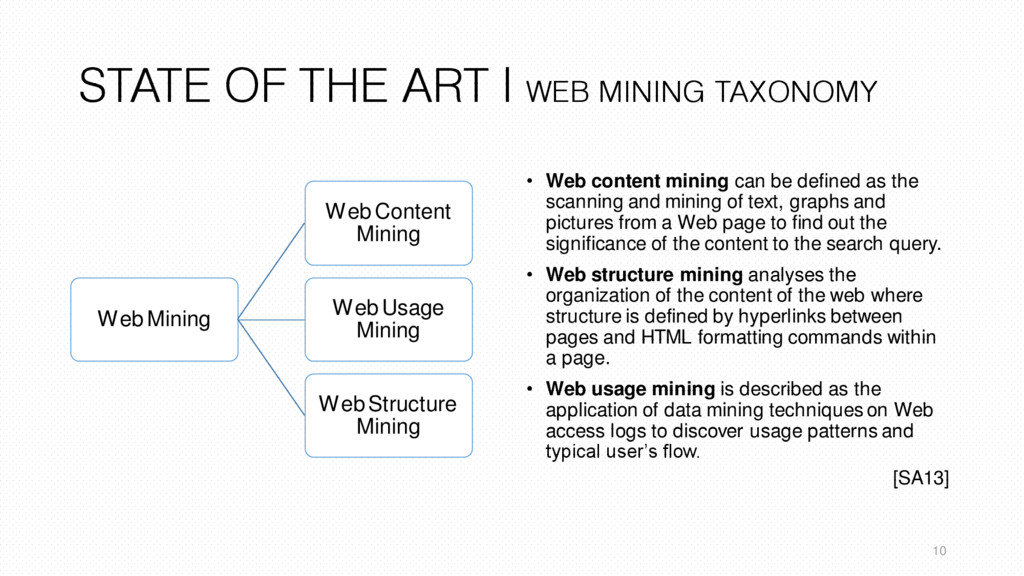
content mining can be defined as the scanning and mining of text, graphs and pictures from a Web page to find out the significance of the content to the search query. • Web structure mining analyses the organization of the content of the web where structure is defined by hyperlinks between pages and HTML formatting commands within a page. • Web usage mining is described as the application of data mining techniques on Web access logs to discover usage patterns and typical user’s flow. 10 [SA13] Web Mining Web Content Mining Web Usage Mining Web Structure Mining
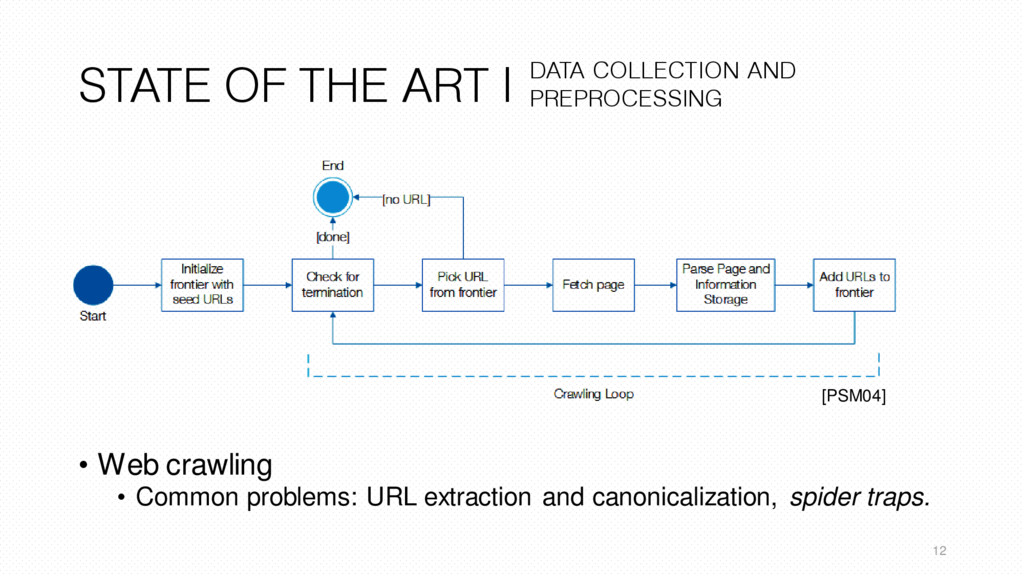
Problems: incompletion, redundancy, ambiguity and noise (i.e. web bots). • Solutions: user and session identification and path completion. 13 DATA COLLECTION AND PREPROCESSING [LF10]
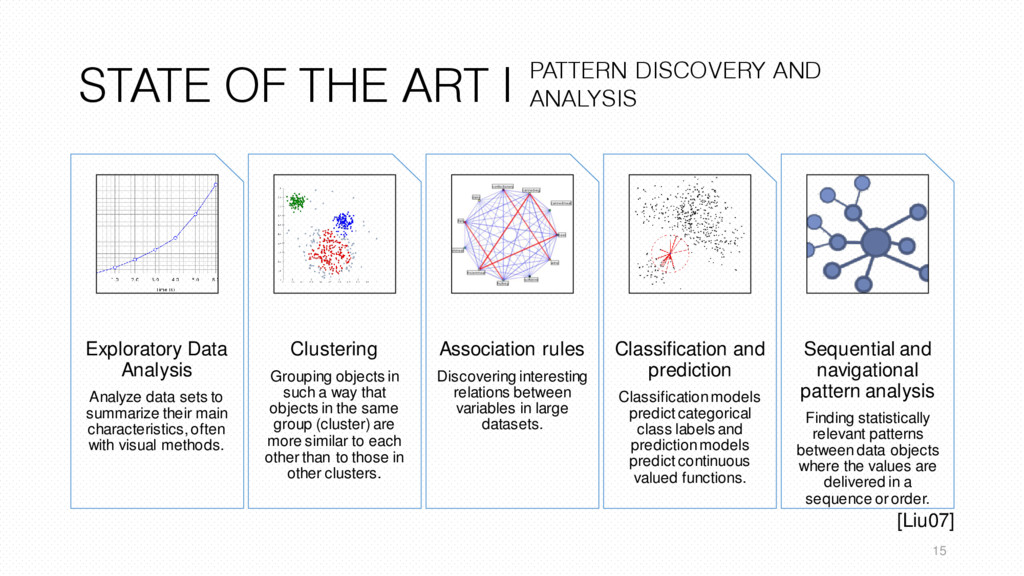
sets to summarize their main characteristics, often with visual methods. Clustering Grouping objects in such a way that objects in the same group (cluster) are more similar to each other than to those in other clusters. Association rules Discovering interesting relations between variables in large datasets. Classification and prediction Classification models predict categorical class labels and prediction models predict continuous valued functions. Sequential and navigational pattern analysis Finding statistically relevant patterns between data objects where the values are delivered in a sequence or order. 15 PATTERN DISCOVERY AND ANALYSIS [Liu07]
profiles • Each keyword can represent a topic of interest. • Weights are attribute in order to represent the importance. • Common problem: Polysemy (words with similar meaning) • Semantic Networks • Weighted semantic network in which each node represents a concept. • Solves the polysemy problem of keyword-based profiles. Sports Keywords Ball Soccer … Weight 0,45 0,72 … Technology Keywords PC Mouse … Weight 0,64 0,33 … Music Keywords Rock Guitar … Weight 0,54 0,32 … 16 Example of a user profile based on keywords representation [GSCM07].
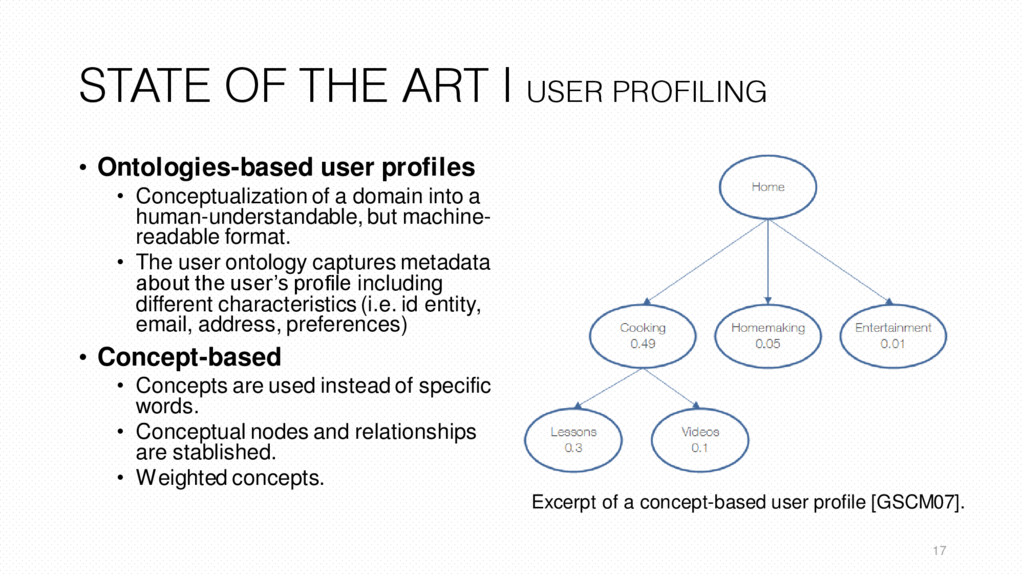
profiles • Conceptualization of a domain into a human-understandable, but machine- readable format. • The user ontology captures metadata about the user’s profile including different characteristics (i.e. id entity, email, address, preferences) • Concept-based • Concepts are used instead of specific words. • Conceptual nodes and relationships are stablished. • Weighted concepts. 17 Excerpt of a concept-based user profile [GSCM07].
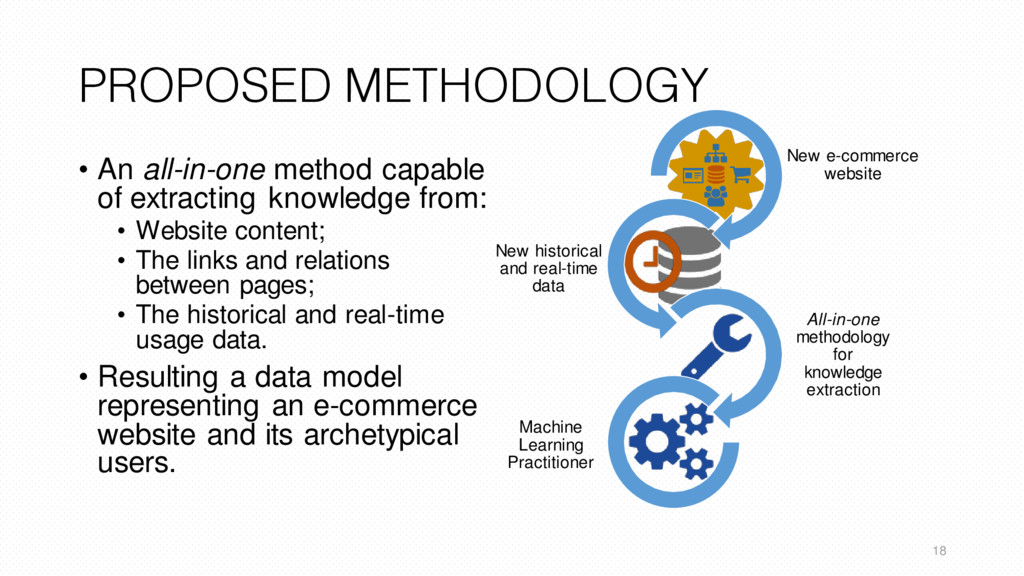
knowledge from: • Website content; • The links and relations between pages; • The historical and real-time usage data. • Resulting a data model representing an e-commerce website and its archetypical users. New e-commerce website New historical and real-time data All-in-one methodology for knowledge extraction Machine Learning Practitioner
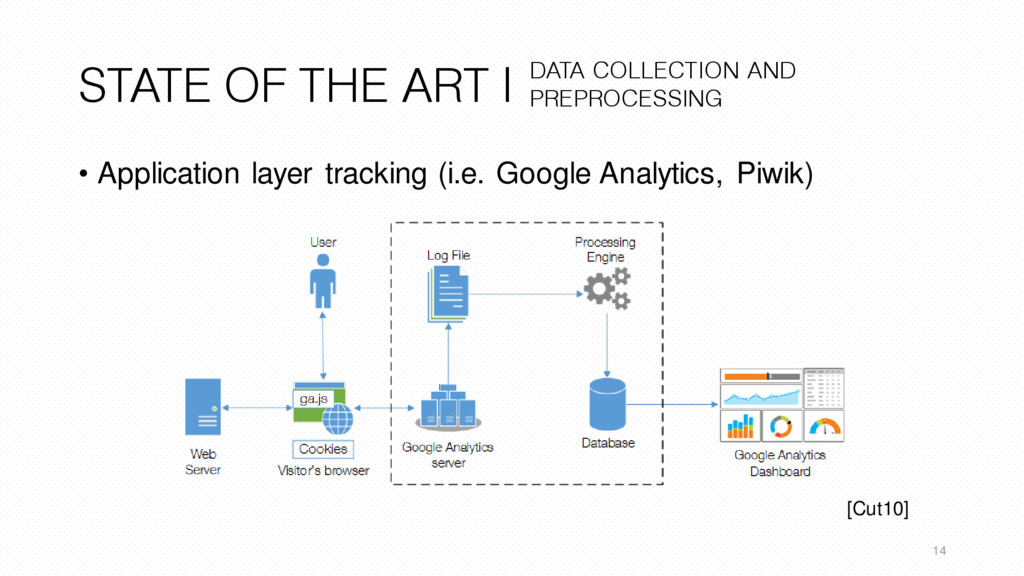
of concept tool. • Using proper and representative data (real or similar to the data generated by an e-commerce web site). • Reducing the time collecting data about an e-commerce website using an concise and all-in-one process. • Get a faster overview about the user typical behavior without resorting to real-time application tracking (application layer) 19
approaches and problems/solutions). • Development of a crawler prototype and lookup of several server log samples. • 12/02/2016 – 20/03/2016 (1 months) • Exploratory development of key features and techniques. • Crawling and other data collection techniques, pattern discovery techniques, user profile representations. • 18/03/2016 – 24/04/2016 (1.5 months) • Implement selected features and techniques as a proof of concept tool. • 11/04/2016 – 23/05/2016 (2 months) • Test and improvement. • Experimental evaluation. • 23/05/2016 – 24/06/2016 (1 month) • Dissertation write up. • 24/06/2016 – 25/07/2016 (1 month) • Dissertation delivery and presentation. 20
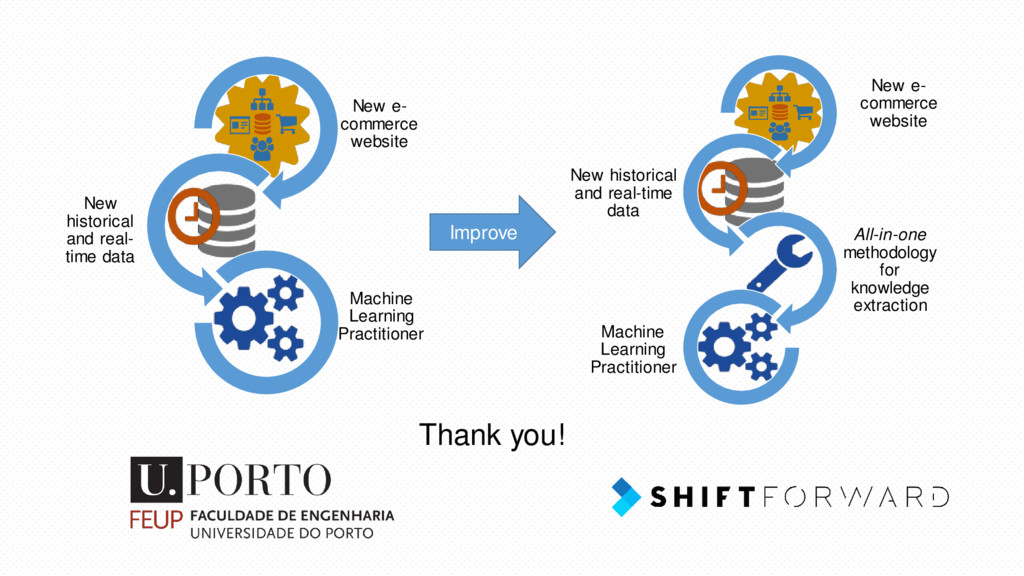
time data Machine Learning Practitioner New e- commerce website New historical and real-time data All-in-one methodology for knowledge extraction Machine Learning Practitioner Improve
Crawling the Web. Web Dynamics, pages 153-177, 2004. • [GSCM07] Susan Gauch, Mirco Speretta, Aravind Chandramouli, and Alessandro Micarelli. User Profiles for Personalized Information Access. The Adaptive Web, 4321:54-89, 2007. • [Liu07] Bing Liu. Web data mining: exploring hyperlinks, contents, and usage data. Springer Science & Business Media, 2007. • [Cut10] Justin Cutroni. Google Analytics, volume 1. O’Reilly Media, Inc., First edition, 2010. • [CMS97] R Cooley, B Mobasher, and J Srivastava. Web mining: information and pattern discovery on the World Wide Web. In IEEE International Conference on Tools with Artificial Intelligence, pages 558–567, 1997. • [LF10] Li Mei and Feng Cheng. Overview of Web mining technology and its application in e-commerce. 2010 2nd International Conference on Computer Engineering and Technology, 7:277–280, 2010. • [SA13] Ahmad Siddiqui and Sultan Aljahdali. Web Mining Techniques in E-Commerce Applications. International Journal of Computer Applications, 69(8):39–43, may 2013. 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![STATE OF THE ART | WEB MINING PROCESS 11 [LF10]](https://files.speakerdeck.com/presentations/afa3d4cf46374180b8f62950a60d6c56/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![REFERENCES • [PMS04] Gautam Pant, Padmini Srinivasan, and Filippo Menczer.](https://files.speakerdeck.com/presentations/afa3d4cf46374180b8f62950a60d6c56/slide_21.jpg){kind=link}