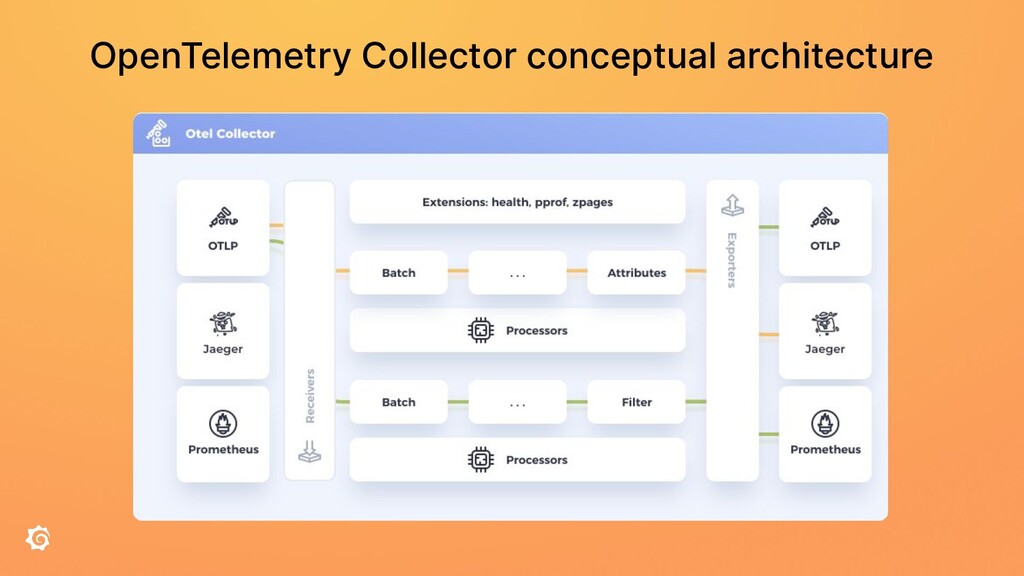
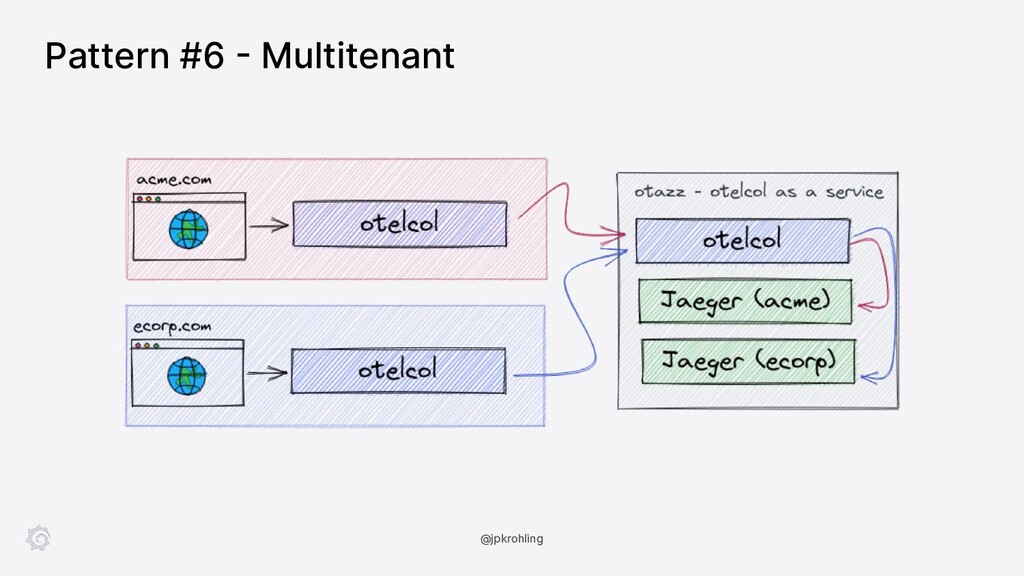
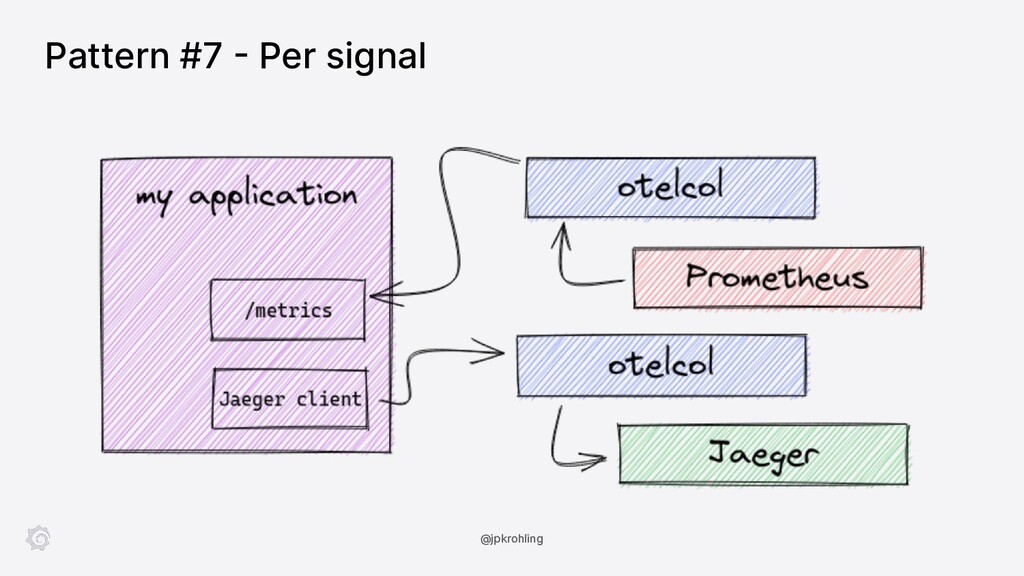
The OpenTelemetry Collector is a highly versatile software, able to process not only traces but also metrics and logs. It can be deployed in a variety of ways, with features like authentication, routing, load balancing, tail-based sampling, and so on. The tooling around the collector is also extensive, with extra modules and distributions as part of the “contrib” package as well as a CLI tool allowing you to build your own distribution, possibly with your custom components.
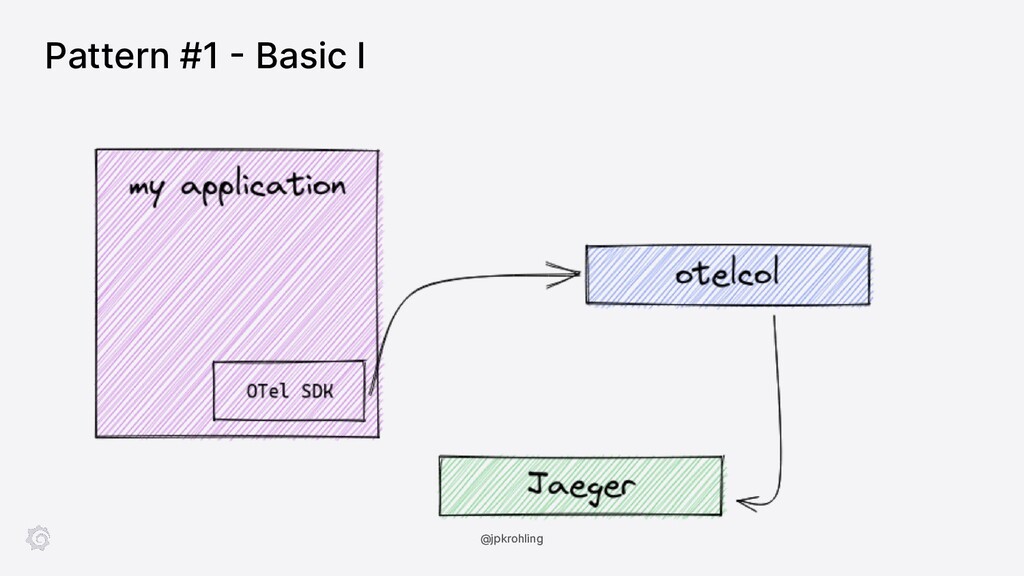
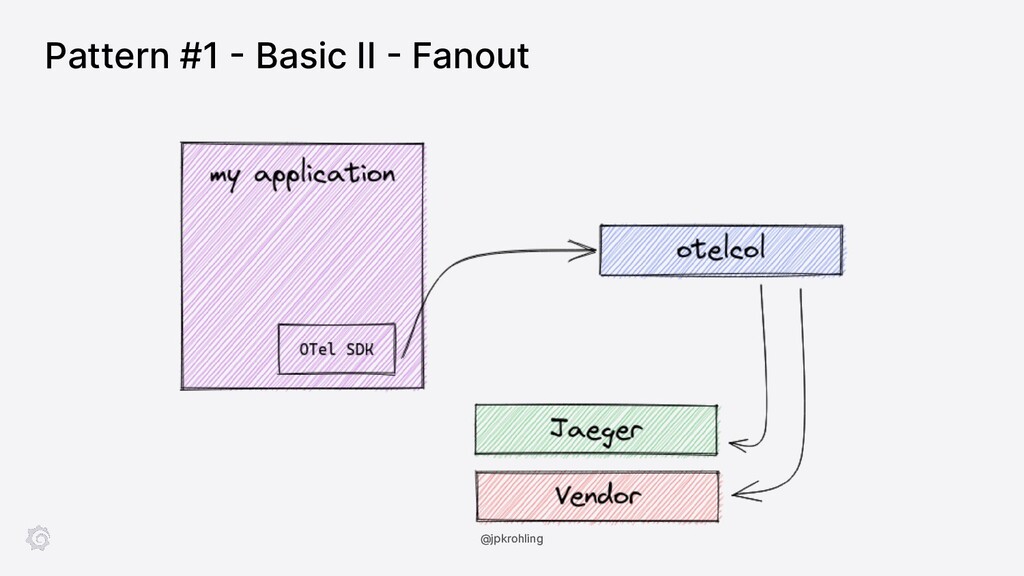
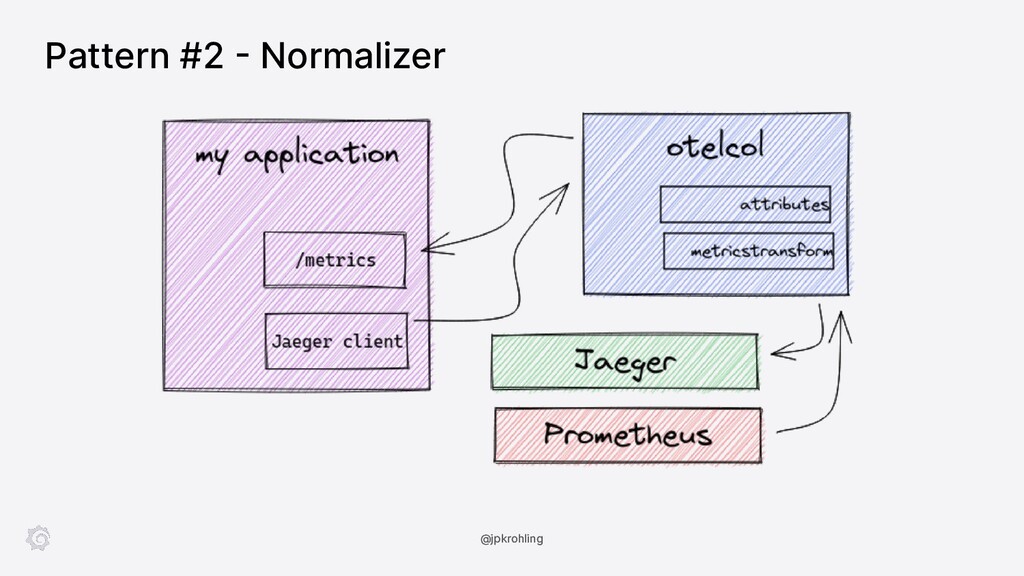
In this session, Juraci Paixão Kröhling introduces the OpenTelemetry Collector showing how you can deploy it in a variety of scenarios, from the classic “agent/collector on Kubernetes” up to scalable tail-based sampling. In the second part, we’ll see how a component can be built from scratch and integrated into our own distribution.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
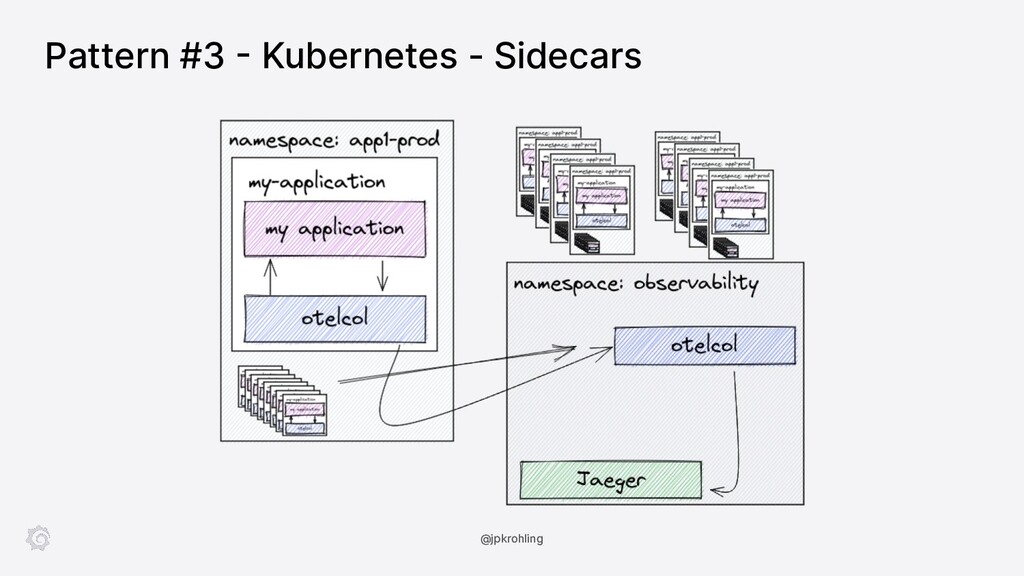{kind=link}
{kind=link}
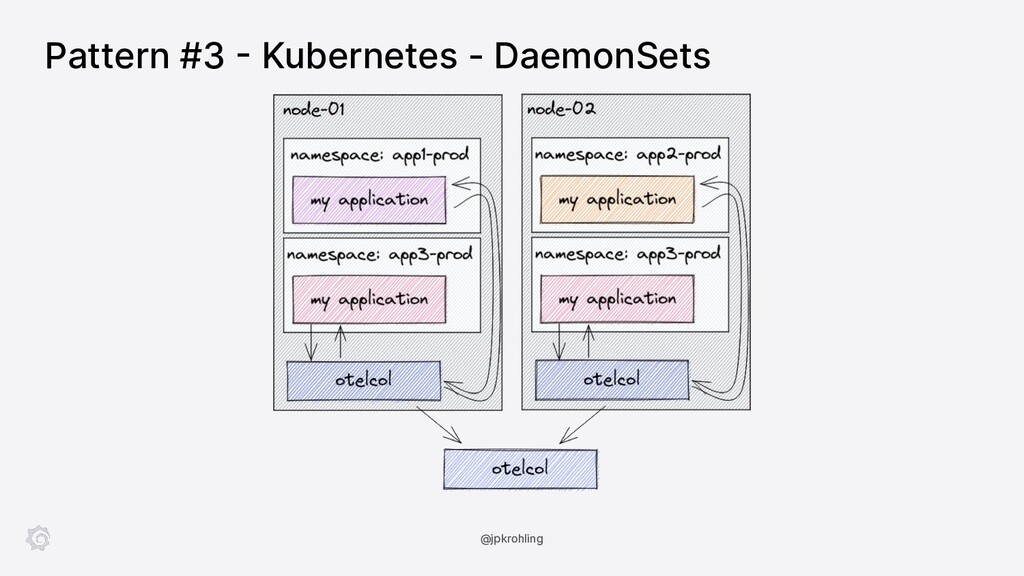{kind=link}
{kind=link}
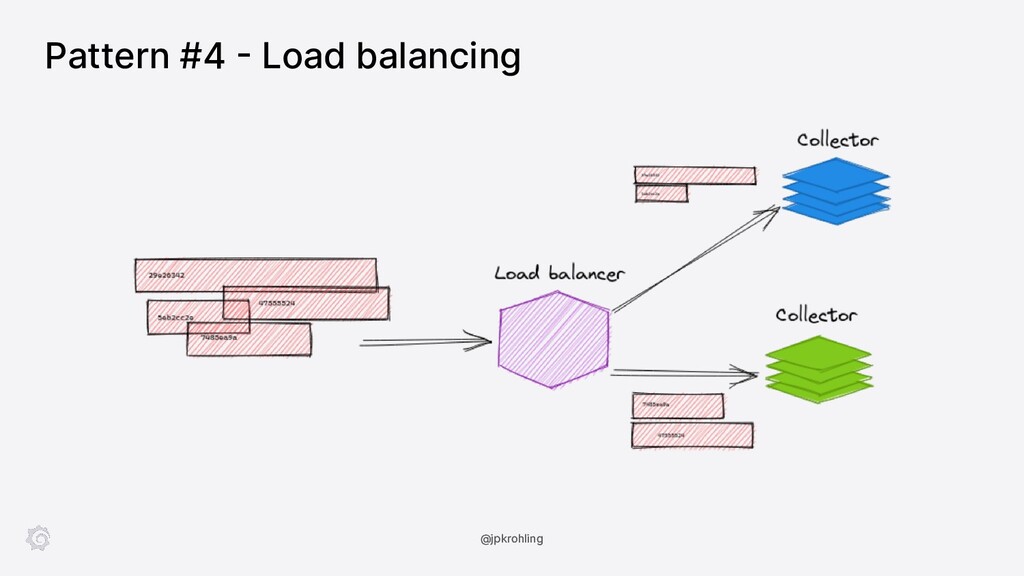{kind=link}
{kind=link}
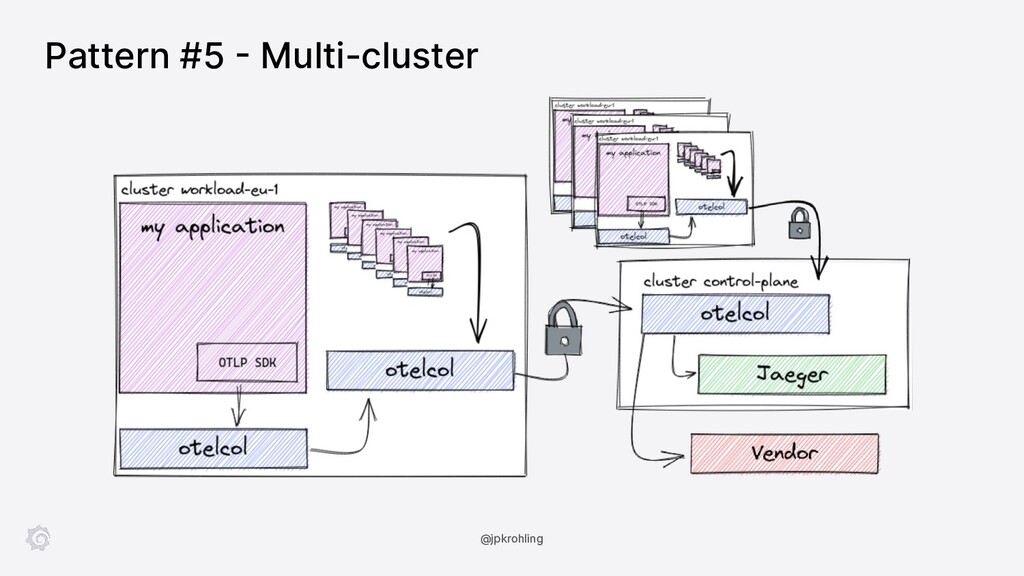{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}