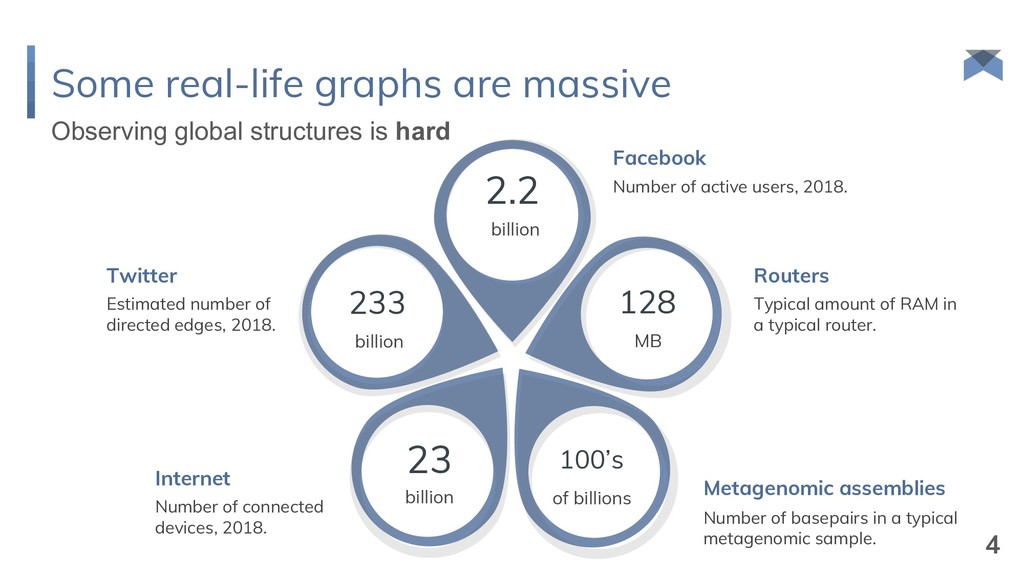
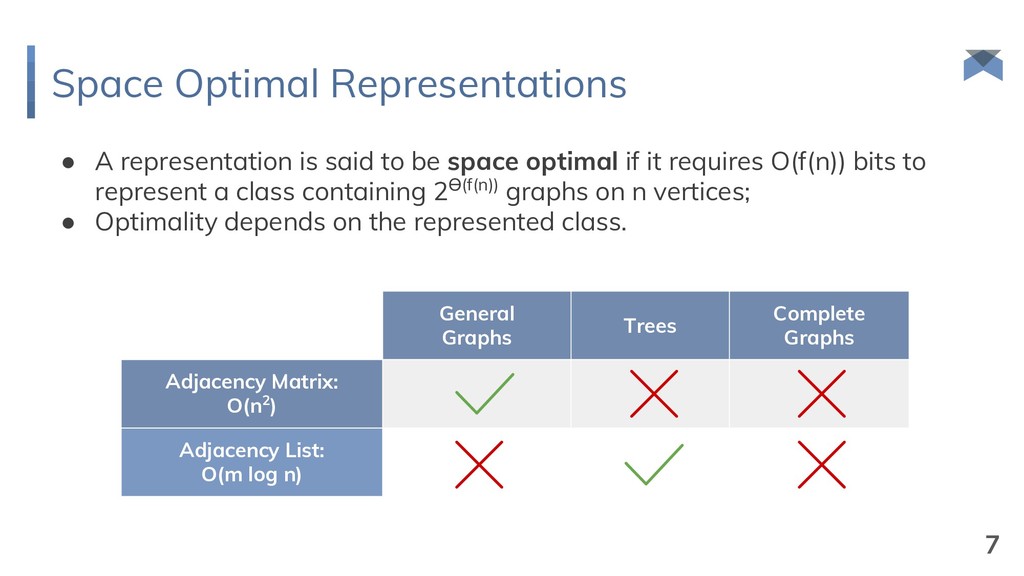
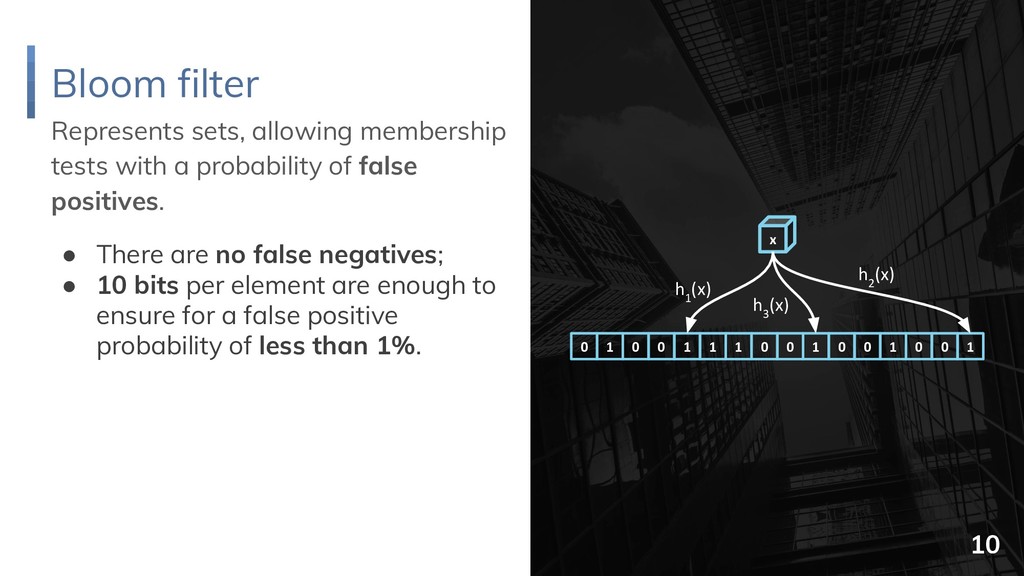
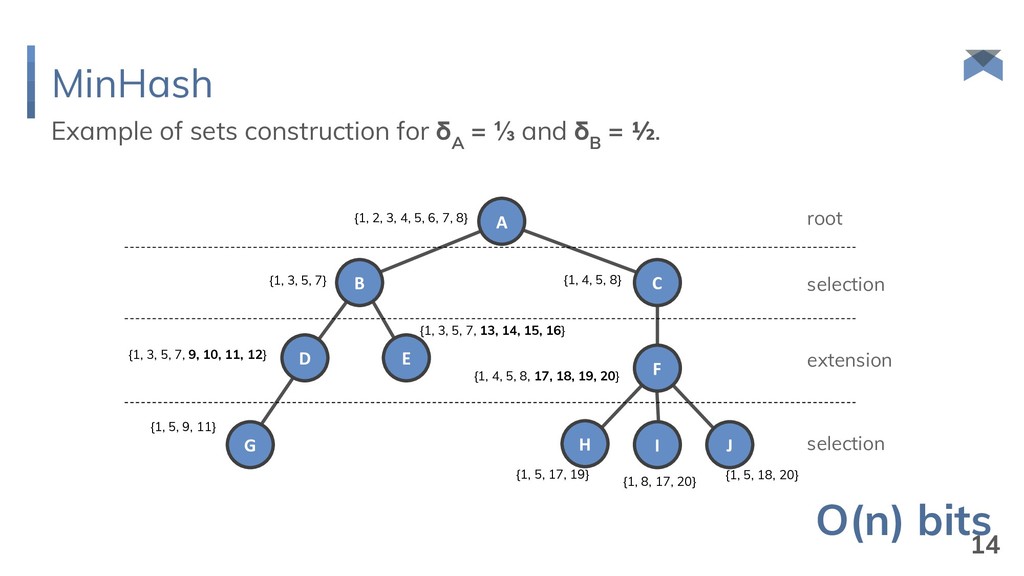
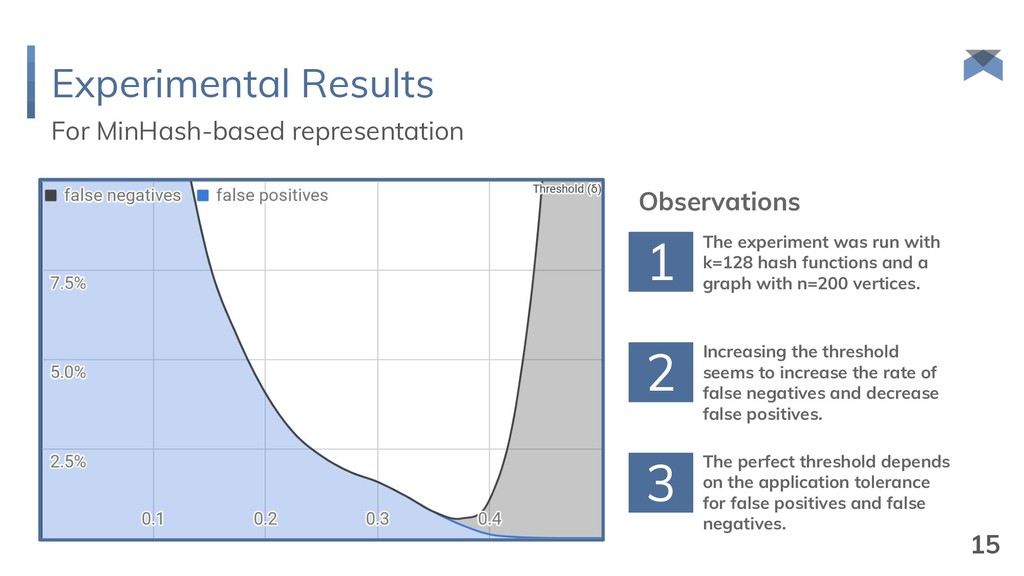
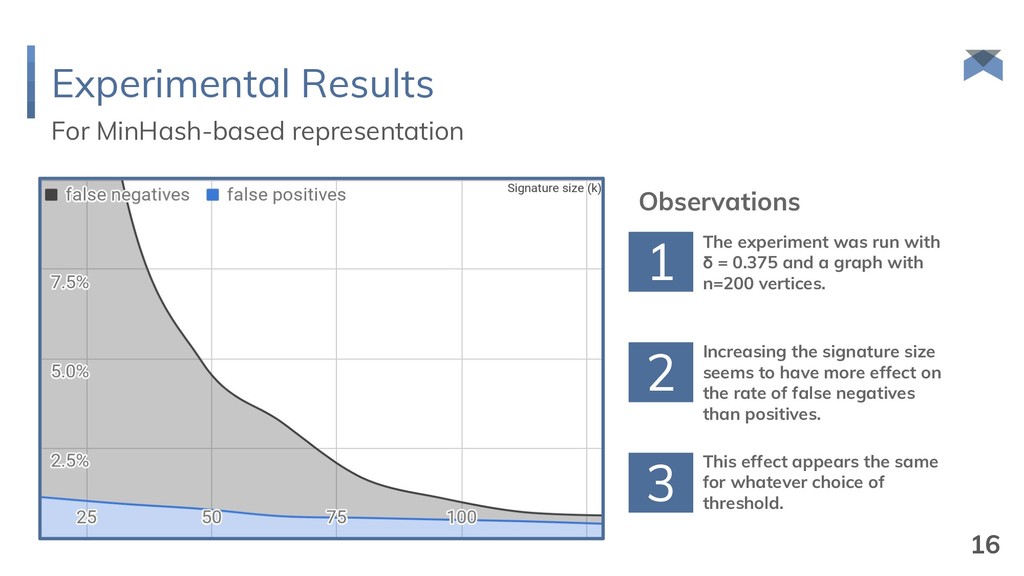
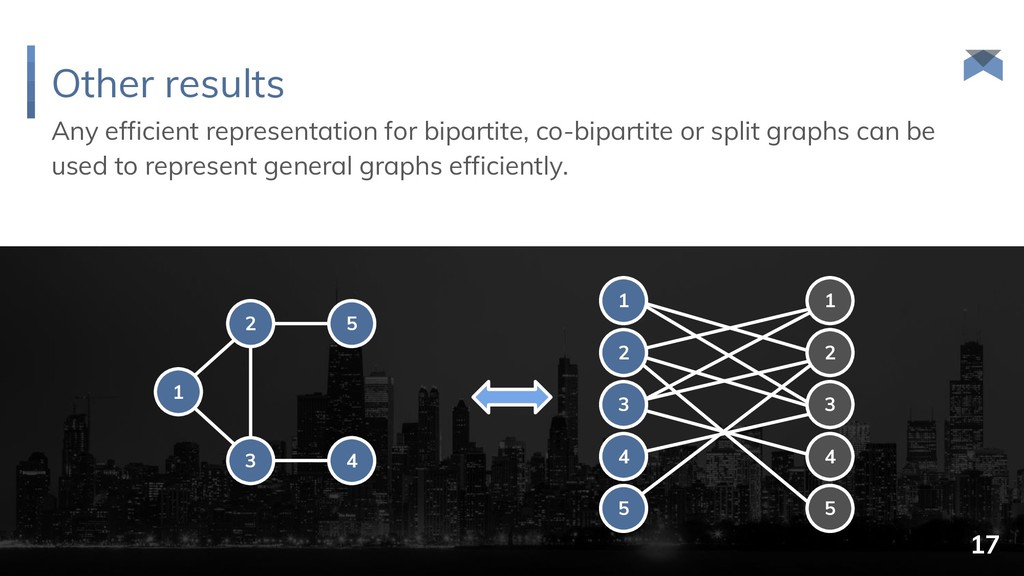
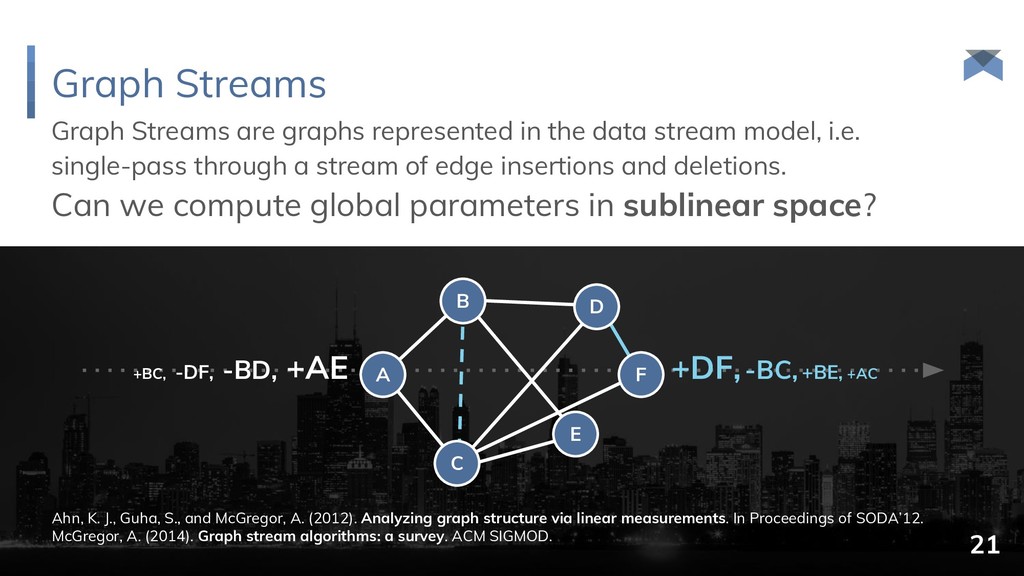
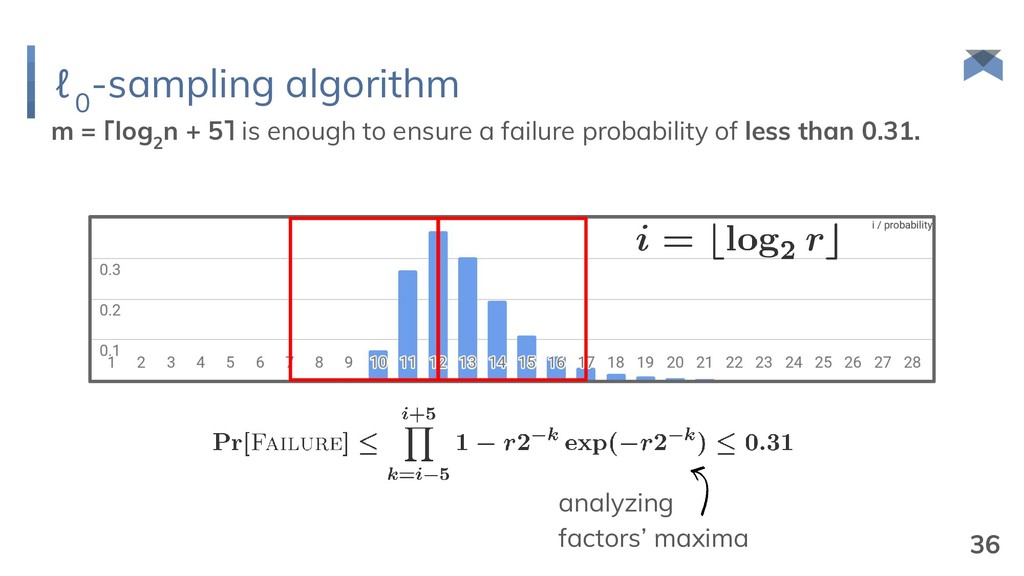
and δ B = ½. {1, 2, 3, 4, 5, 6, 7, 8} {1, 3, 5, 7} {1, 4, 5, 8} {1, 3, 5, 7, 9, 10, 11, 12} {1, 3, 5, 7, 13, 14, 15, 16} {1, 4, 5, 8, 17, 18, 19, 20} {1, 5, 9, 11} root selection extension selection {1, 5, 17, 19} {1, 8, 17, 20} {1, 5, 18, 20} O(n) bits 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
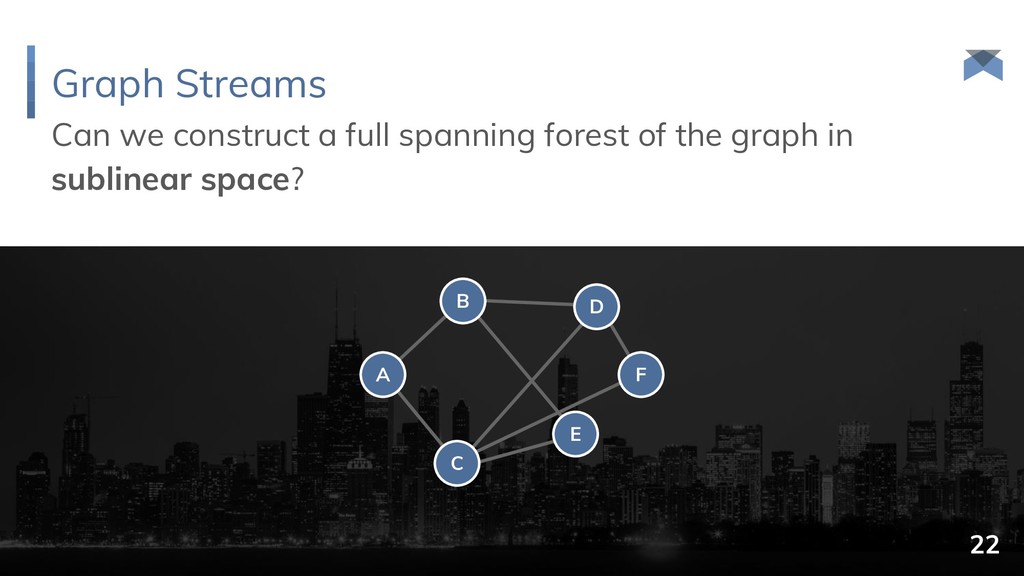{kind=link}
{kind=link}
{kind=link}
{kind=link}
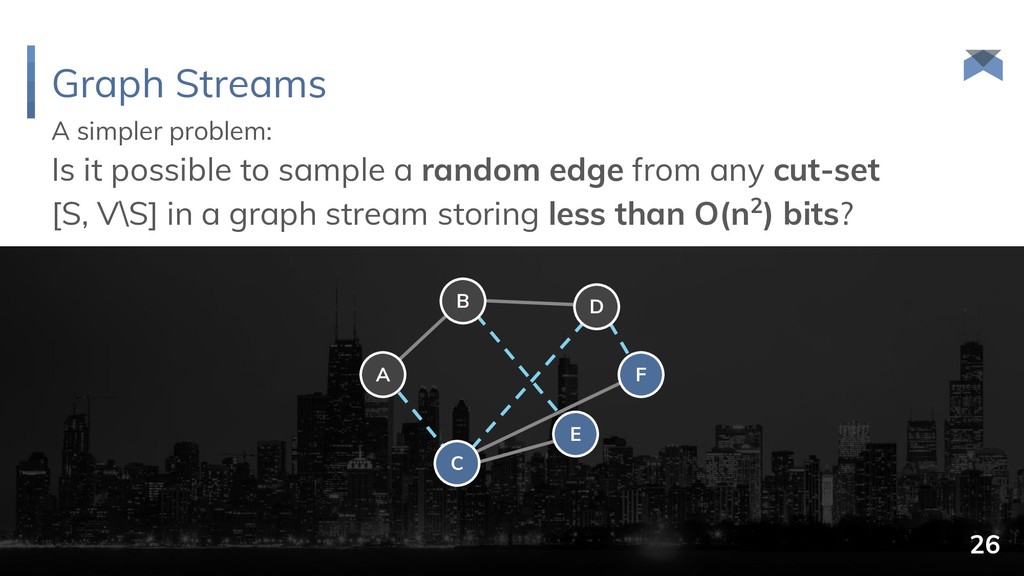{kind=link}
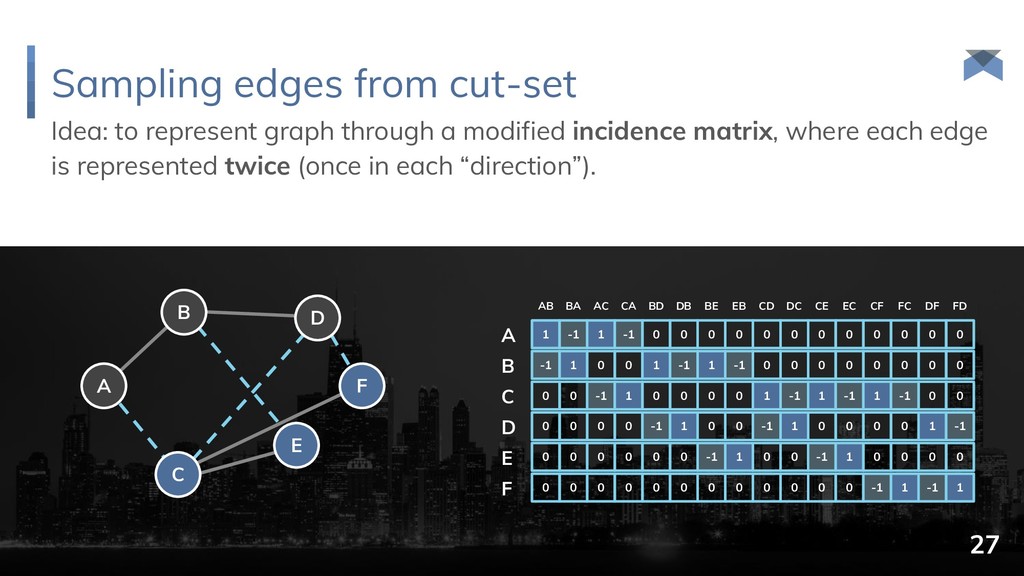{kind=link}
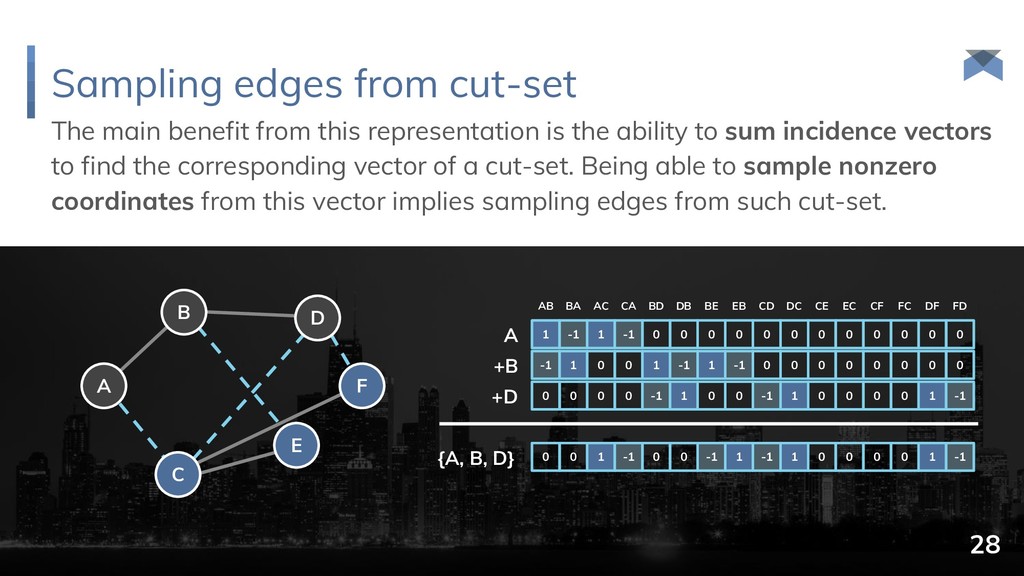{kind=link}
{kind=link}
{kind=link}
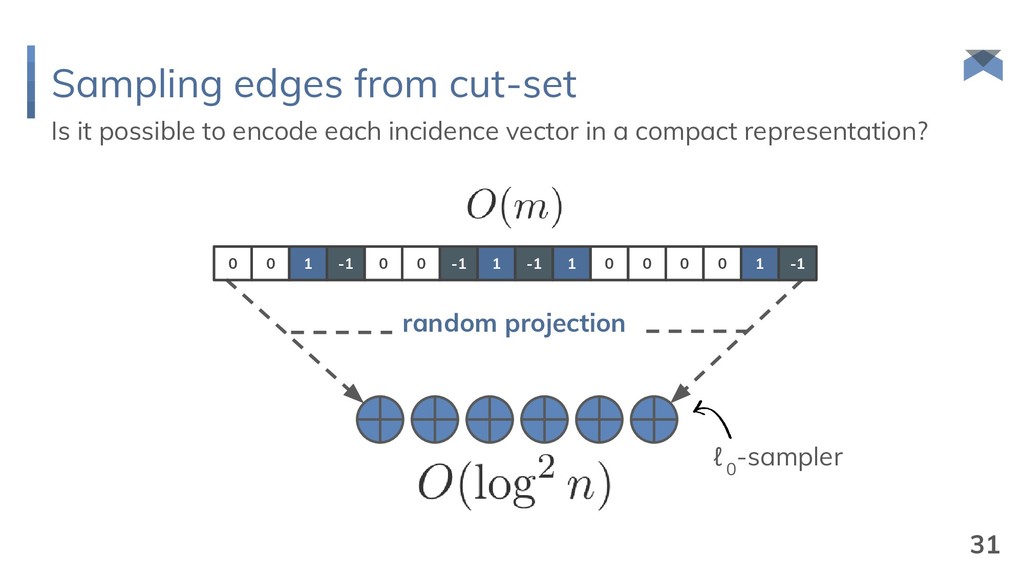{kind=link}
{kind=link}
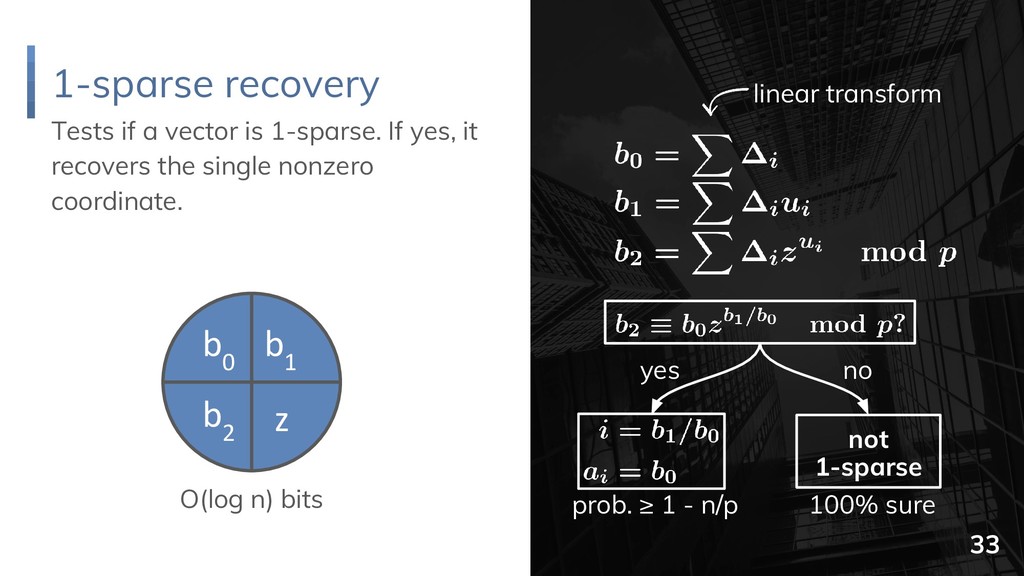{kind=link}
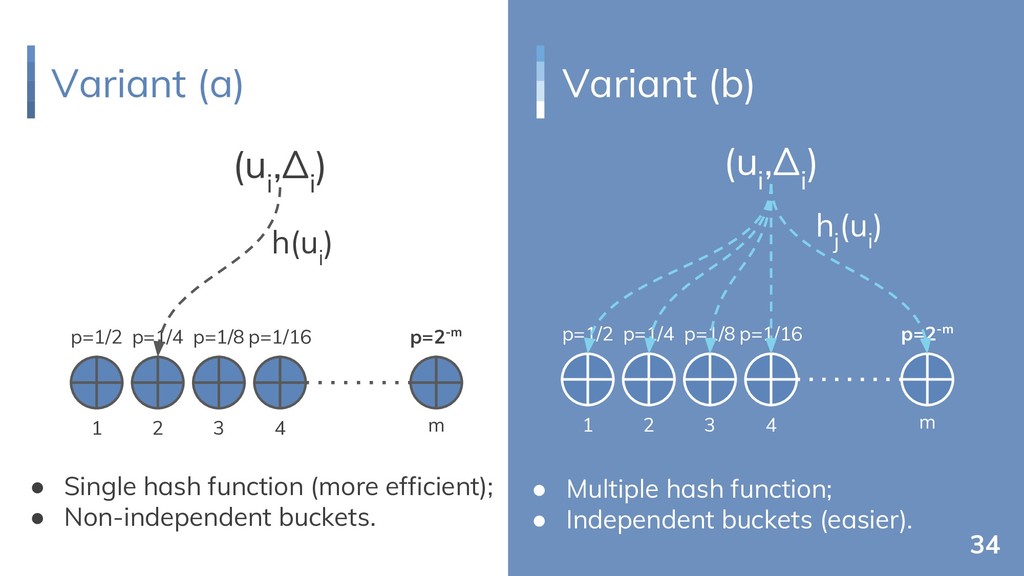{kind=link}
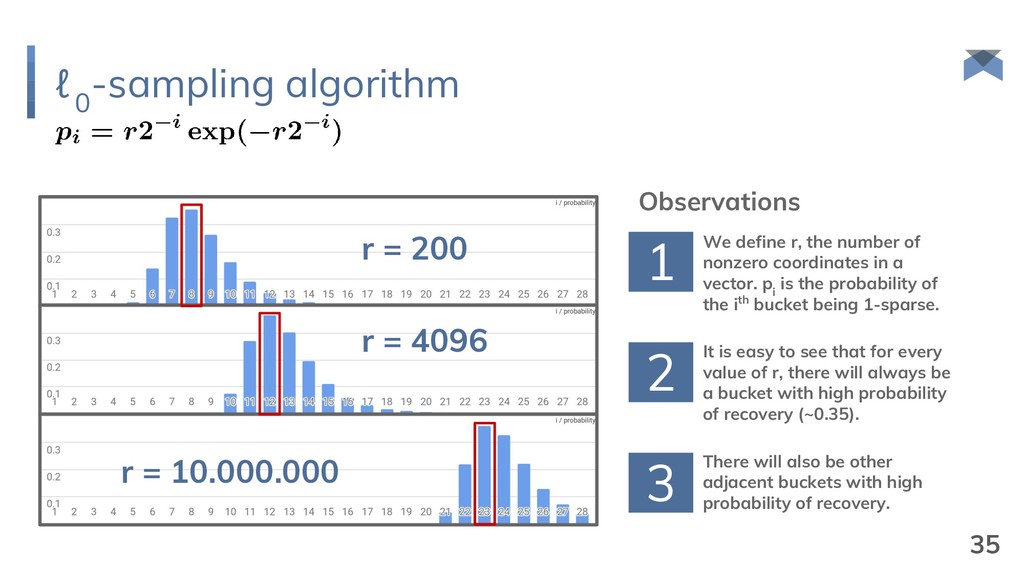{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}