Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Machine Learning Environment Made by Rancher
Search
@ジュジュ
March 02, 2019
Programming
1.2k
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Machine Learning Environment Made by Rancher
@ジュジュ
March 02, 2019
More Decks by @ジュジュ
See All by @ジュジュ
チーム分割においていかれたアラートをチームで責任を持てる形に再設計した
juju62q
0
210
ボトムアップでSLOを導入 2年半運用して分かった失敗と変化
juju62q
2
1.2k
Firecracker Snapshottingを調べてみた
juju62q
1
650
SLOを活用した技術的改善
juju62q
10
15k
IAM Role for Pods and Instance Meta Data Service
juju62q
1
1.7k
telepresence handson
juju62q
2
5.4k
Wanna Use Vitess in Orientation
juju62q
6
1.4k
machine learning with rancher and K8s on prem
juju62q
5
490
docker-handson-for-researcher
juju62q
3
360
Other Decks in Programming
See All in Programming
ITヒヤリハットを整理してみた ~ライフサイクルと原因から考える再発防止策~
koukimiura
1
110
数百円から始めるRuby電子工作
tarosay
0
100
Laravel Boostに学ぶ、AIにPHPを書かせる技術 〜OSSの実装から蒸留するエージェント制御の王道〜
kentaroutakeda
3
520
えっ!!コードを読まずに開発を!?
hananouchi
0
230
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
180
GitHubCopilotCLIのスラッシュコマンドを自作してみる
htkym
0
100
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
390
Terraform標準の組織で AWS CDKをどう使うか
mu7889yoon
1
350
FDEが実現するAI駆動経営の現在地
gonta
2
200
PHP初心者セッション2026 〜生成AIでは見えない裏側を知る:今だからLAMPを通して仕組みを学ぶ〜
kashioka
0
650
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
全PRの83%がAIレビューだけでマージできるようになった開発組織はその後どうなったか
athug
0
300
Featured
See All Featured
The Language of Interfaces
destraynor
162
27k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
From π to Pie charts
rasagy
0
240
The Spectacular Lies of Maps
axbom
PRO
1
870
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Rails Girls Zürich Keynote
gr2m
96
14k
Technical Leadership for Architectural Decision Making
baasie
3
440
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Building AI with AI
inesmontani
PRO
1
1.1k
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
sira's awesome portfolio website redesign presentation
elsirapls
0
310
Transcript
Rancherでつくる NoOps機械学習基盤 株式会社キスモ 岡野 兼也
2 2 会社概要 2 社名 株式会社キスモ (KYSMO inc.) 本社 愛知県名古屋市千種区不老町1番
名古屋大学インキュベーション施設 (名古屋大学公認ベンチャー) 代表者 代表取締役 三野稜太 設立 2017年5月9日 スタッフ数 12人 事業内容 Explainable AI(XAI)の導入支援 企業理念:働くをアップデートする。 代表取締役 三野 稜太 取締役 大越 拓実 取締役 鈴木 雄也
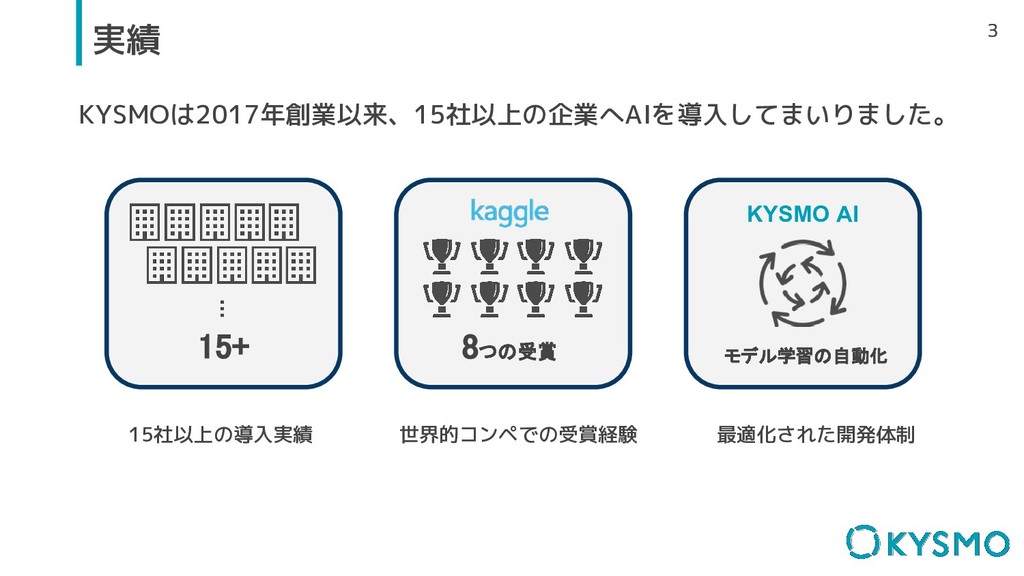
3 3 実績 KYSMO AI … 15+ 8つの受賞 モデル学習の自動化 KYSMOは2017年創業以来、15社以上の企業へAIを導入してまいりました。
15社以上の導入実績 世界的コンペでの受賞経験 最適化された開発体制
4 $ whoami name: - 岡野兼也 - @ジュジュ belonging: -
株式会社キスモ - 名古屋大学 interest: - CloudNative - SRE - Container dream: - 働かないこと hobbies: - 登山 - キャンプ
5 お話しすること 1. 理想的な機械学習基盤とRancher導入前のキスモでの現実 2. 現在キスモで利用されている機械学習基盤 3. なぜコンテナを使うのか 4. なぜKubernetes
& Rancherを使うのか 5. 機械学習基盤が与えた効果
6 お話しすること 1. 理想的な機械学習基盤とRancher導入前のキスモでの現実 2. 現在キスモで利用されている機械学習基盤 3. なぜコンテナを使うのか 4. なぜKubernetes
& Rancherを使うのか 5. 機械学習基盤が与えた効果
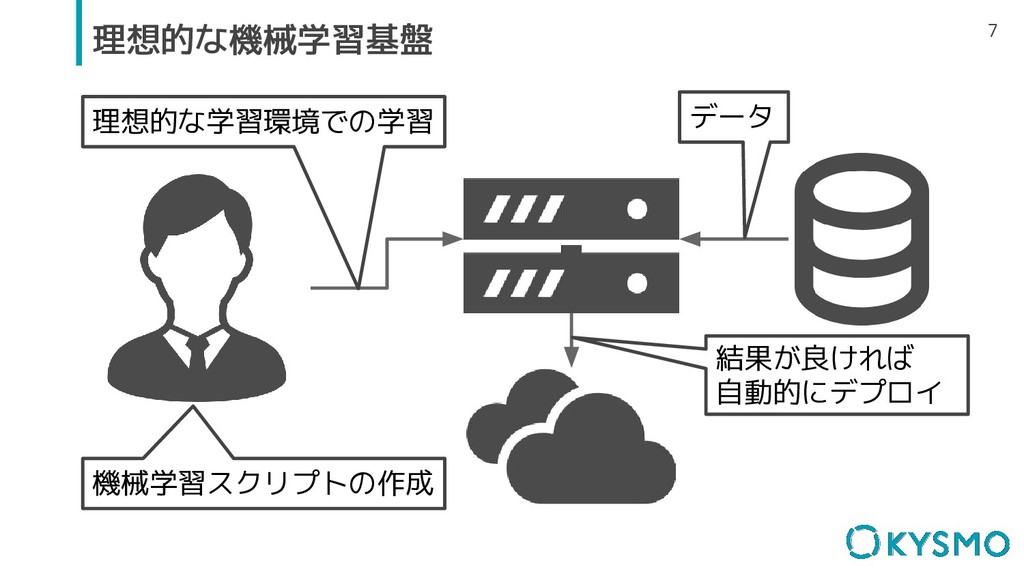
7 理想的な機械学習基盤 機械学習スクリプトの作成 理想的な学習環境での学習 データ 結果が良ければ 自動的にデプロイ
8 理想的な機械学習基盤 データサイエンスだけを意識すればいい世界
9 キスモの昔の機械学習環境 SSHでのLOGIN
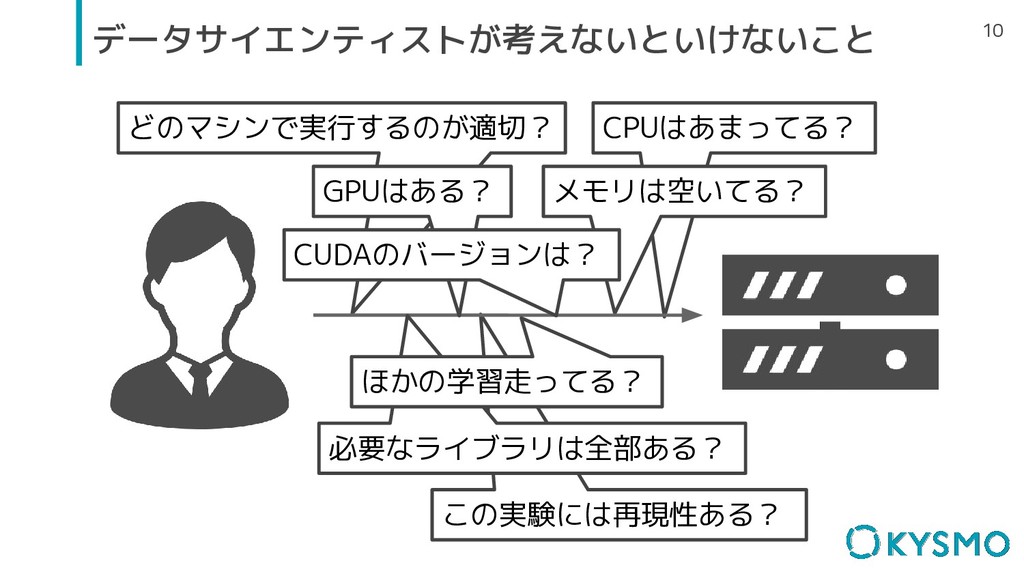
この実験には再現性ある? どのマシンで実行するのが適切? CPUはあまってる? メモリは空いてる? 10 データサイエンティストが考えないといけないこと 必要なライブラリは全部ある? GPUはある? CUDAのバージョンは? ほかの学習走ってる?
11 インフラ的にもつらい ▫ 環境が継ぎ足されるので現状把握が難しい - インフラエンジニアだけがOSイメージを管理するとボトルネックになる ▫ インフラが変化に弱い - 用途に合わせていちいち環境ごとつくる?
- そもそもCUDAのバージョン管理は人類には困難 ▫ 複数のマシンで同一の環境を担保しにくい - 作業ノードのみでパッケージの追加をしてしまう ▫ メンテしようにもどのマシンがどうなっているかログインしないと わからない
12 とにかくやらないといけないことが多い 適切な管理がなされない &
13 お話しすること 1. 理想的な機械学習基盤とRancher導入前のキスモでの現実 2. 現在キスモで利用されている機械学習基盤 3. なぜコンテナを使うのか 4. なぜKubernetes
& Rancherを使うのか 5. 機械学習基盤が与えた効果
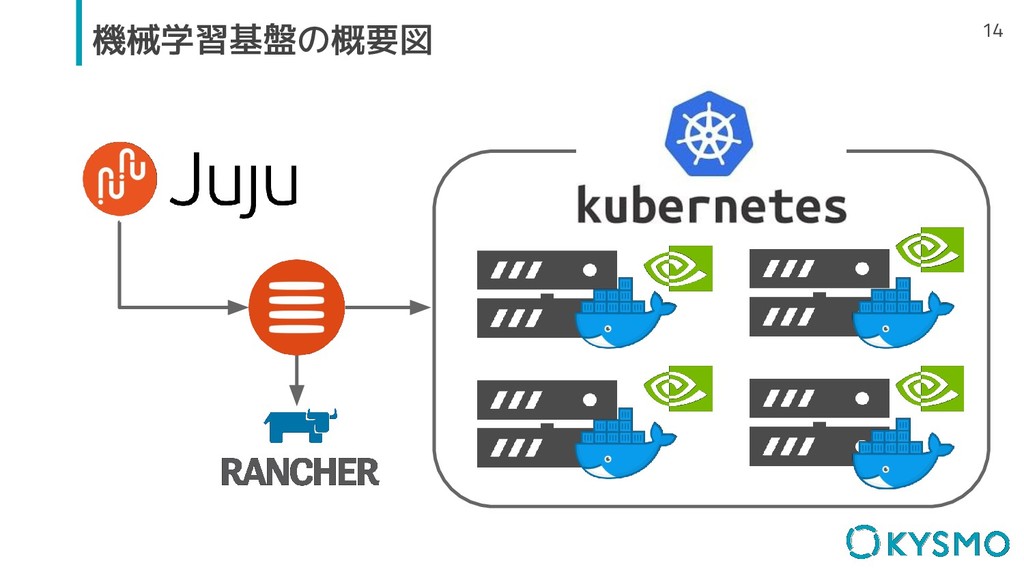
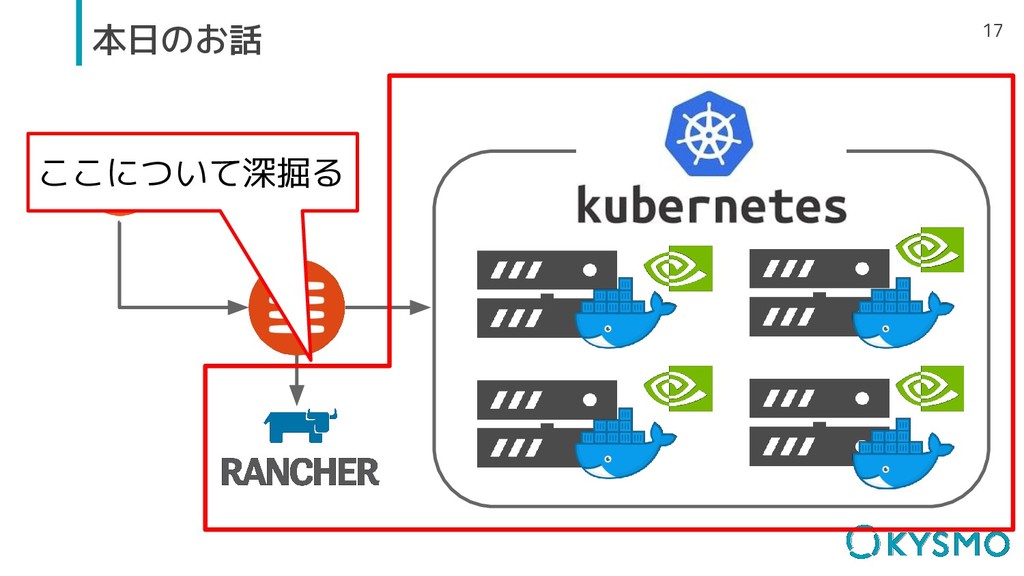
14 機械学習基盤の概要図
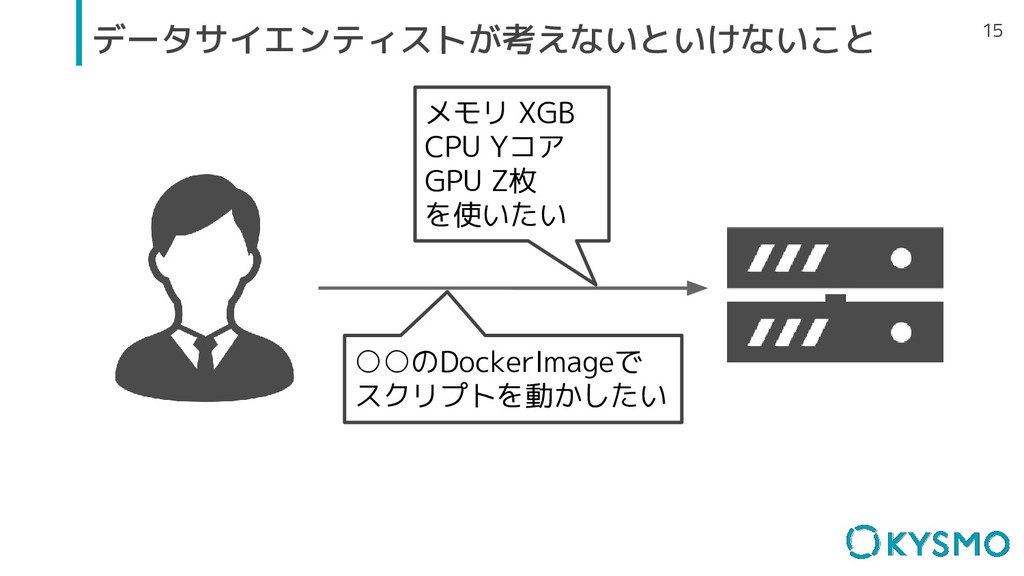
15 データサイエンティストが考えないといけないこと メモリ XGB CPU Yコア GPU Z枚 を使いたい ◦◦のDockerImageで
スクリプトを動かしたい
16 インフラの作業 ▫ データサイエンティストと一緒にDocker Imageの管理 ▫ 最小限のミドルウェアをJujuを利用して管理 - Docker -
nvidia-docker - nvidiaデバイスドライバー ▫ マシンを物理的にネットワーク接続
17 本日のお話 ここについて深掘る
18 お話しすること 1. 理想的な機械学習基盤とRancher導入前のキスモでの現実 2. 現在キスモで利用されている機械学習基盤 3. なぜコンテナを使うのか 4. なぜKubernetes
& Rancherを使うのか 5. 機械学習基盤が与えた効果
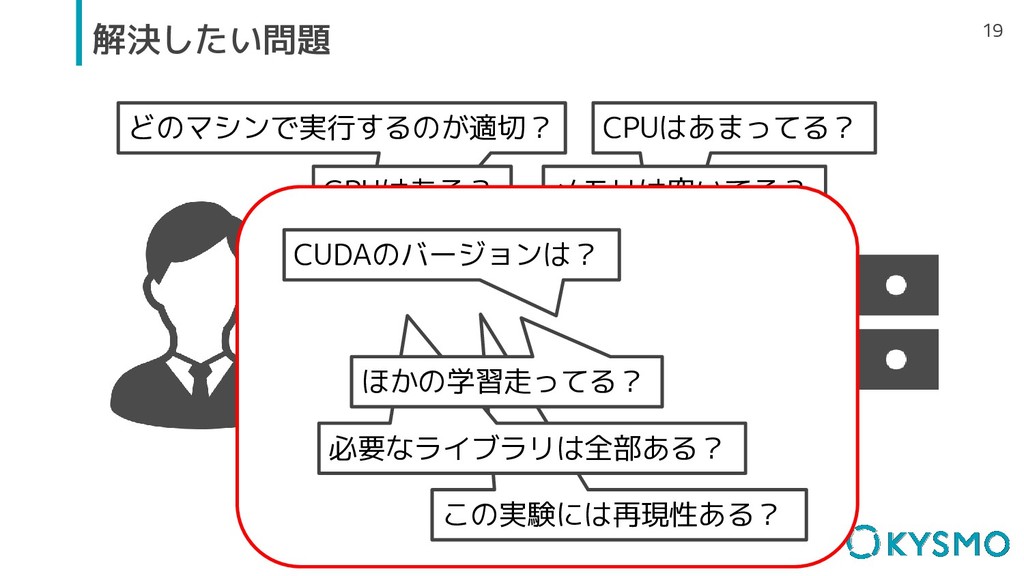
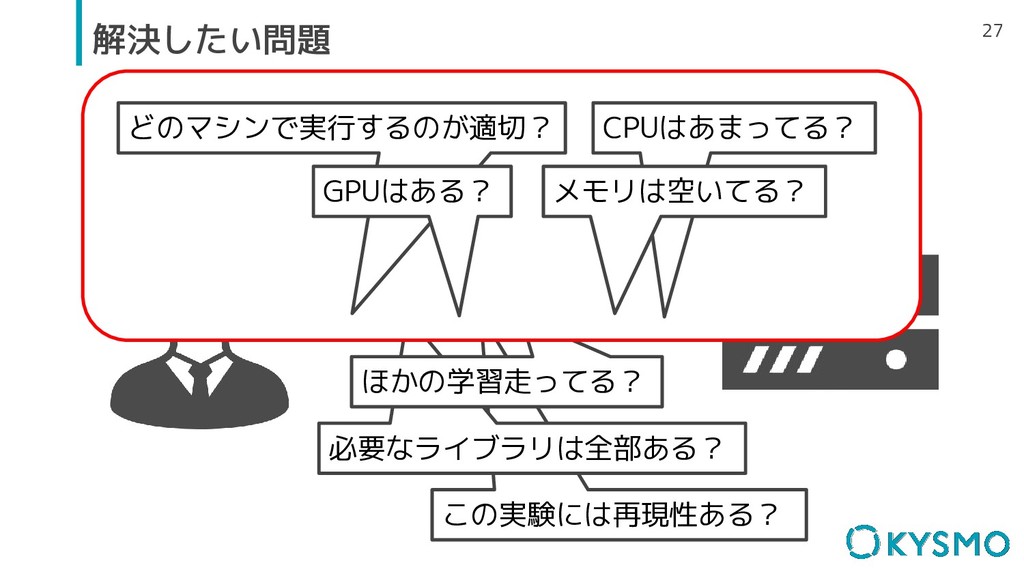
どのマシンで実行するのが適切? CPUはあまってる? メモリは空いてる? 19 解決したい問題 GPUはある? この実験には再現性ある? 必要なライブラリは全部ある? CUDAのバージョンは? ほかの学習走ってる?
20 解決したい問題 ▫ 環境が継ぎ足されるので現状把握が難しい - インフラエンジニアだけがOSイメージを管理するとボトルネックになる ▫ インフラが変化に弱い - 用途に合わせていちいち環境ごとつくる?
- そもそもCUDAのバージョン管理は人類には困難 ▫ 複数のマシンで同一の環境を担保しにくい - 作業ノードのみでパッケージの追加をしてしまう ▫ メンテしようにもどのマシンがどうなっているかログインしないと わからない
21 機械学習を取り巻く環境 ▫ 機械学習分野は非常に開発が盛んである - 同一のフレームワークを使っていても優れたものがすぐに開発される ▫ 機械学習フレームワーク毎に特徴がある - データの特徴に合わせて、必要な時に必要なものを使いたい
変化に強い基盤づくりが必要不可欠
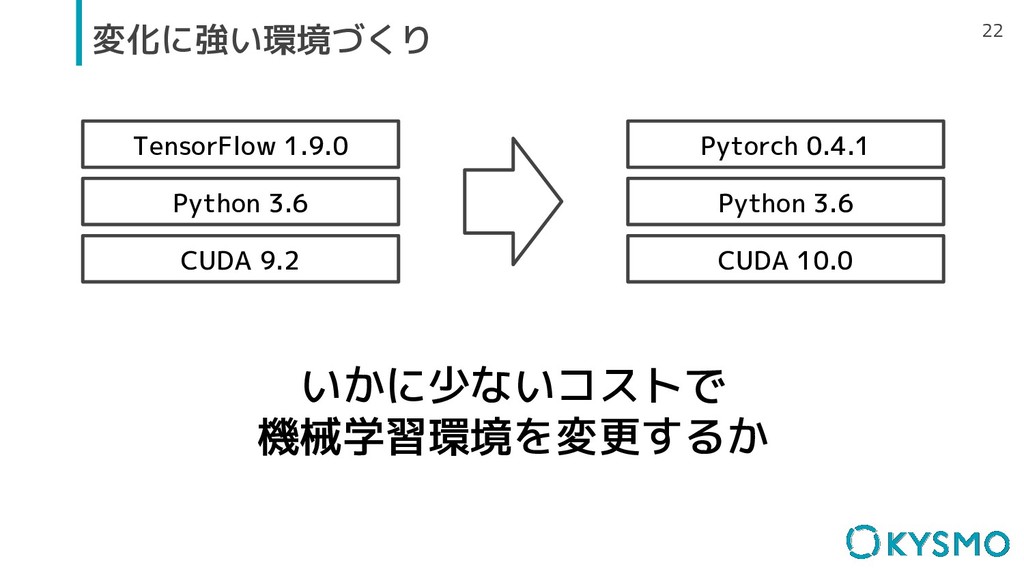
22 変化に強い環境づくり CUDA 9.2 Python 3.6 TensorFlow 1.9.0 CUDA 10.0
Python 3.6 Pytorch 0.4.1 いかに少ないコストで 機械学習環境を変更するか
23 Docker ▫ 必要なパッケージを必要な分だけコンテナに詰め込める ▫ 環境を変えたい場合はコンテナごと取り換えればよい ▫ nvidia-dockerを使うことでGPUも利用可能
24 ▫ DockerfileにはCUDAや必要なライブラリのバージョンが コードとして書かれる - コードになることで実行前に確認が容易 - イメージの変更も容易なことが多い ▫ Imageとしてpushすることで環境の冪等性が保証できる
- 実験環境が容易に再現できる ▫ Nvidiaの作成したDockerImageを元にすると簡単に作業可能 環境を保存するDockerfileを書いておく
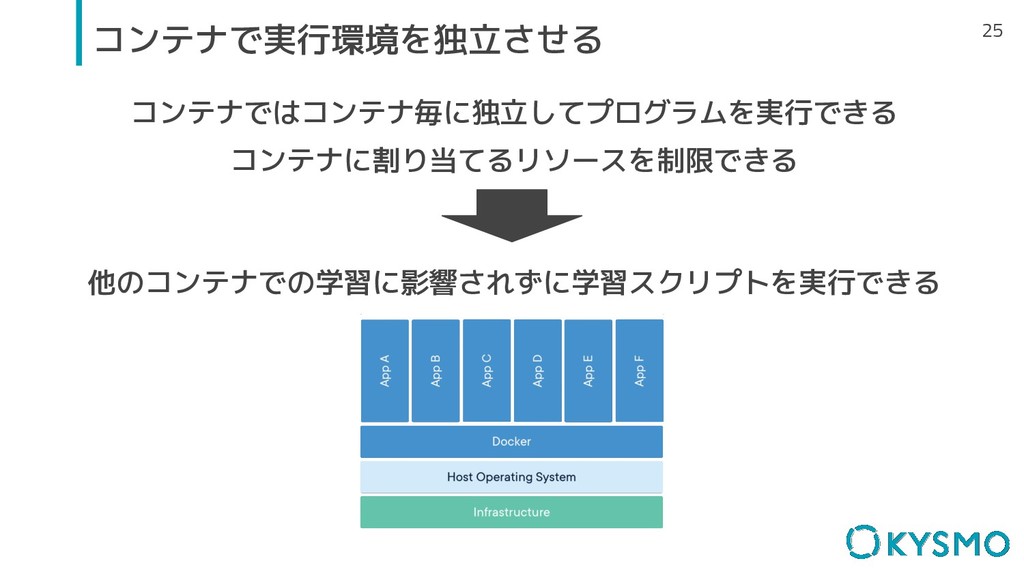
25 コンテナで実行環境を独立させる コンテナではコンテナ毎に独立してプログラムを実行できる コンテナに割り当てるリソースを制限できる 他のコンテナでの学習に影響されずに学習スクリプトを実行できる
26 お話しすること 1. 理想的な機械学習基盤とRancher導入前のキスモでの現実 2. 現在キスモで利用されている機械学習基盤 3. なぜコンテナを使うのか 4. なぜKubernetes
& Rancherを使うのか 5. 機械学習基盤が与えた効果
この実験には再現性ある? 27 解決したい問題 必要なライブラリは全部ある? CUDAのバージョンは? ほかの学習走ってる? どのマシンで実行するのが適切? CPUはあまってる? メモリは空いてる? GPUはある?
28 解決したい問題 ▫ 環境が継ぎ足されるので現状把握が難しい - インフラエンジニアだけがOSイメージを管理するとボトルネックになる ▫ インフラが変化に弱い - 用途に合わせていちいち環境ごとつくる?
- そもそもCUDAのバージョン管理は人類には困難 ▫ 複数のマシンで同一の環境を担保しにくい - 作業ノードのみでパッケージの追加をしてしまう ▫ メンテしようにもどのマシンがどうなっているかログインしないと わからない
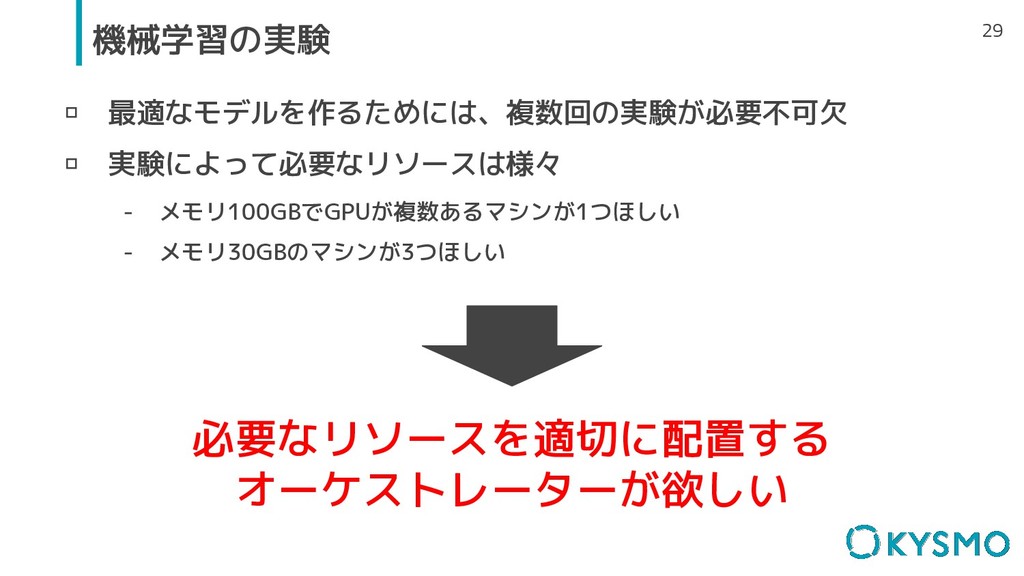
29 機械学習の実験 ▫ 最適なモデルを作るためには、複数回の実験が必要不可欠 ▫ 実験によって必要なリソースは様々 - メモリ100GBでGPUが複数あるマシンが1つほしい - メモリ30GBのマシンが3つほしい
必要なリソースを適切に配置する オーケストレーターが欲しい
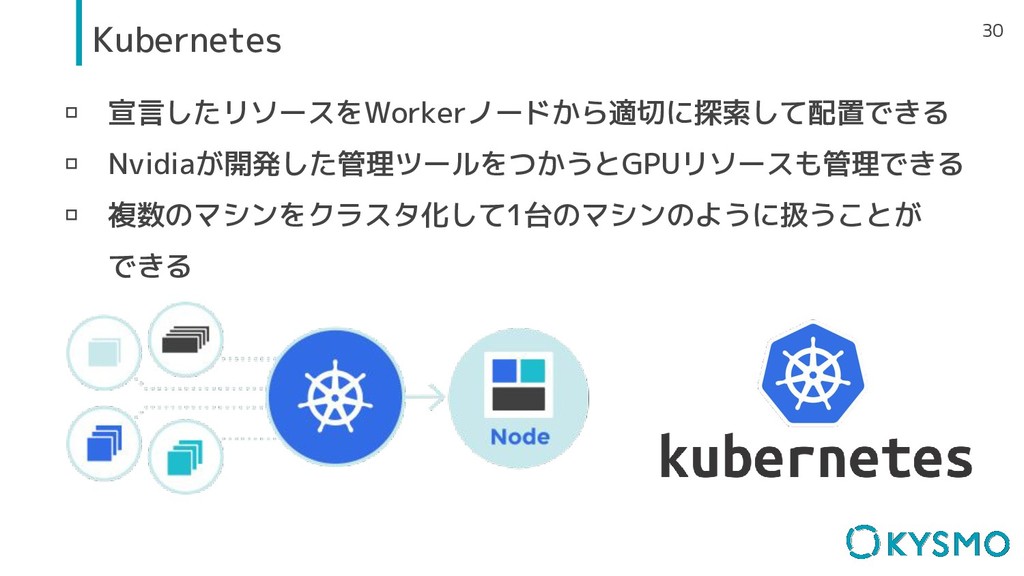
30 Kubernetes ▫ 宣言したリソースをWorkerノードから適切に探索して配置できる ▫ Nvidiaが開発した管理ツールをつかうとGPUリソースも管理できる ▫ 複数のマシンをクラスタ化して1台のマシンのように扱うことが できる
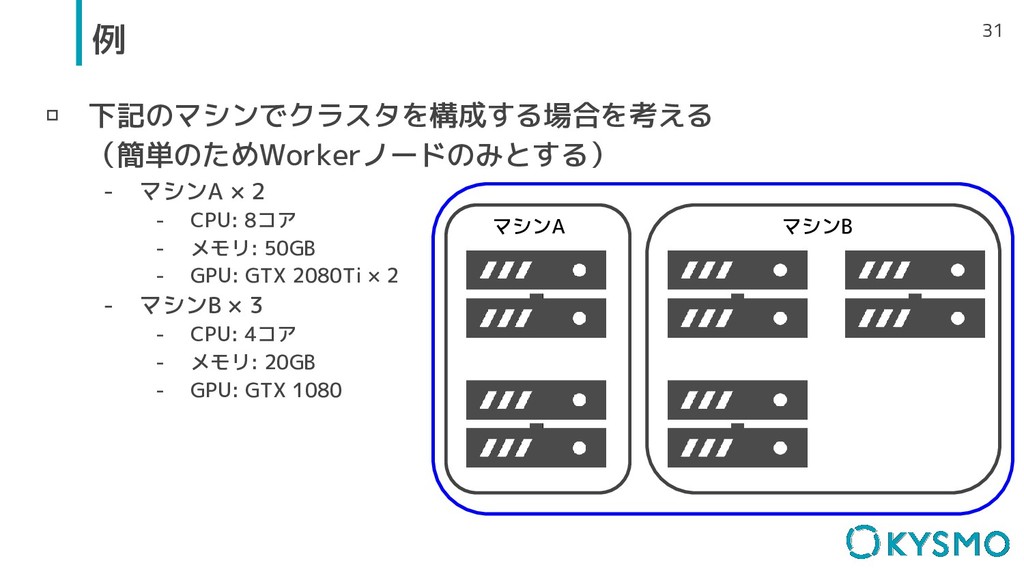
▫ 下記のマシンでクラスタを構成する場合を考える (簡単のためWorkerノードのみとする) - マシンA × 2 - CPU: 8コア
- メモリ: 50GB - GPU: GTX 2080Ti × 2 - マシンB × 3 - CPU: 4コア - メモリ: 20GB - GPU: GTX 1080 31 例 マシンA マシンB
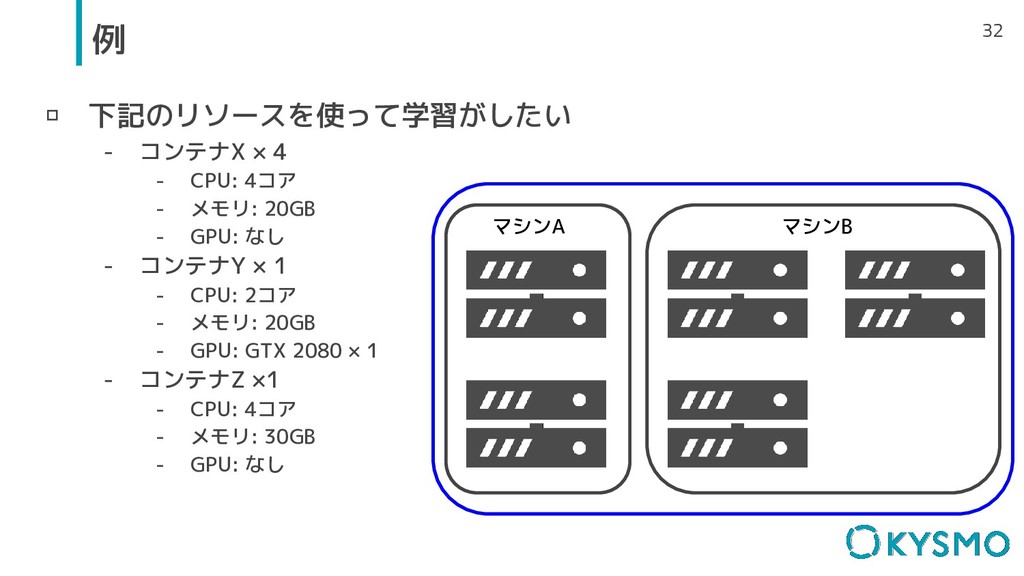
▫ 下記のリソースを使って学習がしたい - コンテナX × 4 - CPU: 4コア -
メモリ: 20GB - GPU: なし - コンテナY × 1 - CPU: 2コア - メモリ: 20GB - GPU: GTX 2080 × 1 - コンテナZ ×1 - CPU: 4コア - メモリ: 30GB - GPU: なし 32 例 マシンA マシンB
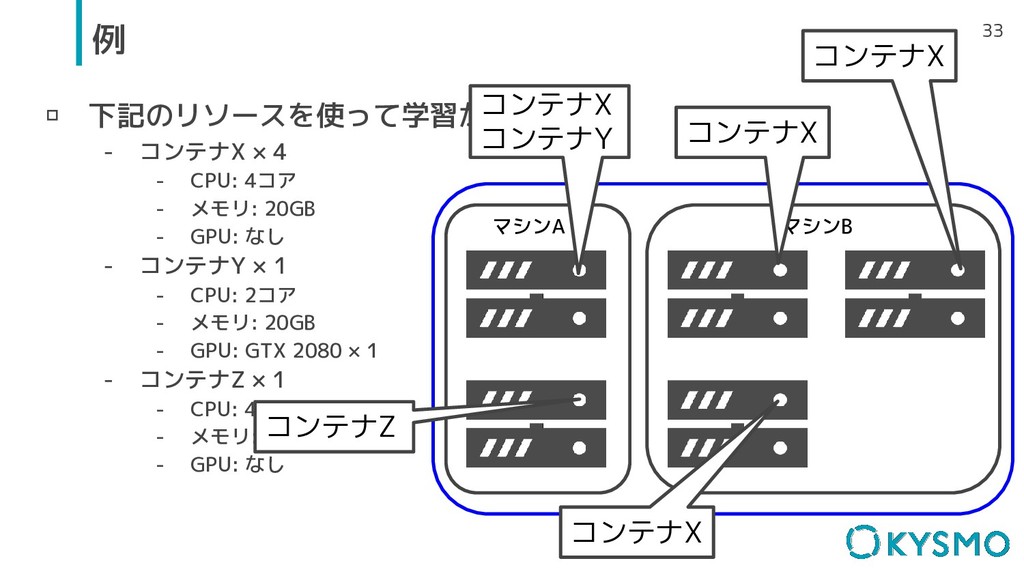
▫ 下記のリソースを使って学習がしたい - コンテナX × 4 - CPU: 4コア -
メモリ: 20GB - GPU: なし - コンテナY × 1 - CPU: 2コア - メモリ: 20GB - GPU: GTX 2080 × 1 - コンテナZ × 1 - CPU: 4コア - メモリ: 30GB - GPU: なし 33 例 マシンA マシンB コンテナX コンテナY コンテナX コンテナZ コンテナX コンテナX
34 必要なリソースのみ考えればいい世界
35 とはいえ… ▫ Kubernetesの学習コストをデータサイエンティストに課すのは うれしくない ▫ もっと直感的にKubernetesを使いたい GUIがあると初めて触るときの イメージが付きやすいのでは?
36 Rancher ▫ GUIで穴埋めをすればコンテナをKubernetesに展開できる - 必ずしもkubectlコマンド等の利用方法を覚えなくとも使える ▫ 運用面でモニタリングツールとしても便利 ▫ 権限の管理もある程度できる
37 使い方 ▫ GPUにはラベルを振って、 指定できるようにする ▫ 慣れてきた人にはkubectlをラップした CLIツールを使ってもらう - インタラクティブにして変更があっても
覚えることなく利用できるようにしている ▫ データは共有ストレージに配置
38 お話しすること 1. 理想的な機械学習基盤とRancher導入前のキスモでの現実 2. 現在キスモで利用されている機械学習基盤 3. なぜコンテナを使うのか 4. なぜKubernetes
& Rancherを使うのか 5. 機械学習基盤が与えた効果
39 機械学習基盤が与えた効果 ▫ データサイエンティスト - 機械学習を行う際に意識すべきことが少なくなった - 最新のライブラリを柔軟に取り入れることが可能になった - リソースを柔軟に切り分けることができるようになった
▫ インフラエンジニア - 環境がコード化され、変化にかかるコストが著しく低下した - メンテナンスでは、必要に応じてノードを切り離せるようになった - 全体の管理を一括でやりやすくなった - 楽しい
40 ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}