Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
線形回帰② 正則化と過学習
Search
K_DM
October 10, 2021
620
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
線形回帰② 正則化と過学習
リッジ回帰とラッソ回帰について。
動画の説明もアップロードしました→
https://youtu.be/rhGYOBrxPXA
K_DM
October 10, 2021
More Decks by K_DM
See All by K_DM
主成分分析(PCA)の仕組み
k_study
0
220
X-meansの仕組み
k_study
0
2.2k
勾配ブースティングの仕組み
k_study
0
140
k-meansクラスタリングの仕組み
k_study
0
290
決定木を使った回帰の仕組み
k_study
0
240
アンサンブル学習① ランダムフォレストの仕組み
k_study
0
120
決定木に含まれるパラメタによる事前剪定と事後剪定
k_study
0
740
外れ値とHuber(フーバー)損失
k_study
0
1.2k
木構造1~決定木の仕組み(分類)
k_study
0
190
Featured
See All Featured
Site-Speed That Sticks
csswizardry
13
1.3k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Context Engineering - Making Every Token Count
addyosmani
9
1k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
AI: The stuff that nobody shows you
jnunemaker
PRO
8
830
Building Adaptive Systems
keathley
44
3.1k
Music & Morning Musume
bryan
47
7.3k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
190
Tell your own story through comics
letsgokoyo
1
1k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Transcript
,ͷษڧνϟϯωϧ
今回の内容 •前回のおさらい •最小二乗法では不十分な理由 •過学習とは •リッジ回帰とラッソ回帰 •幾何学的な視点から、なぜラッソ回帰は係数を0にしがちなのか確認 正則化と過学習について説明します
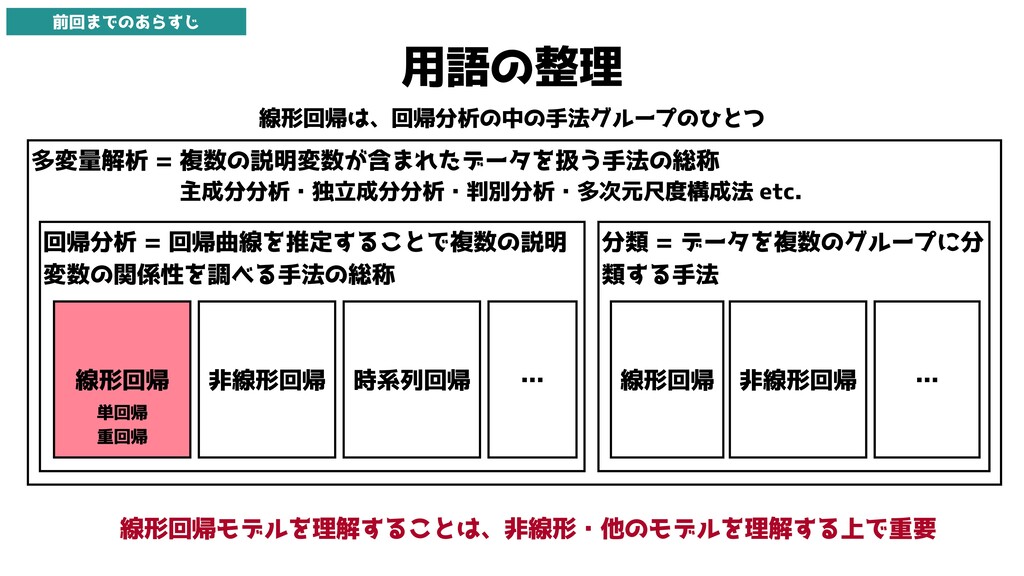
用語の整理 線形回帰は、回帰分析の中の手法グループのひとつ 多変量解析 = 複数の説明変数が含まれたデータを扱う手法の総称 回帰分析 = 回帰曲線を推定することで複数の説明 変数の関係性を調べる手法の総称 主成分分析・独立成分分析・判別分析・多次元尺度構成法
etc. 線形回帰 分類 = データを複数のグループに分 類する手法 非線形回帰 時系列回帰 線形回帰 非線形回帰 … … 線形回帰モデルを理解することは、非線形・他のモデルを理解する上で重要 単回帰 重回帰 前回までのあらすじ
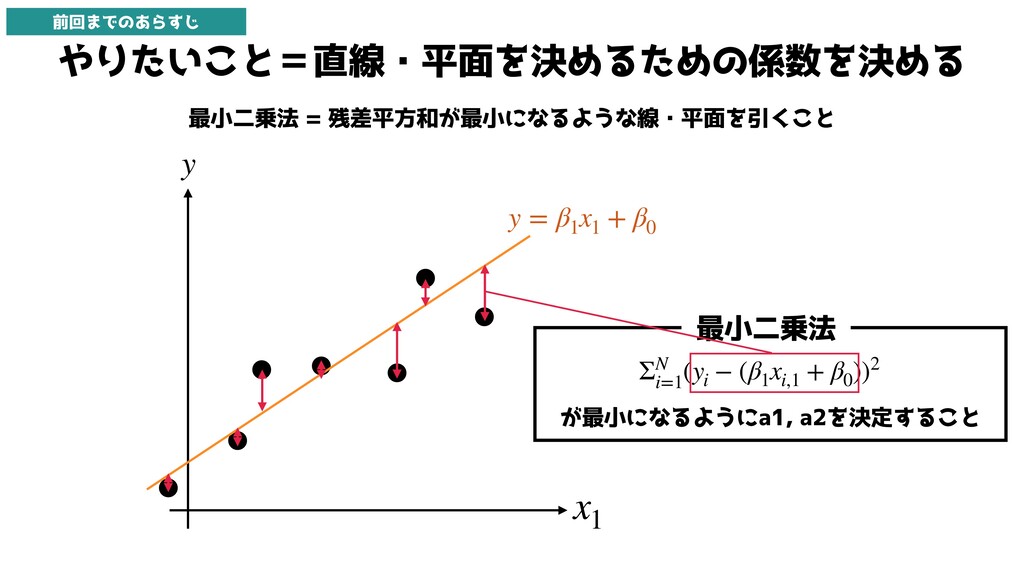
やりたいこと=直線・平面を決めるための係数を決める 最小二乗法 = 残差平方和が最小になるような線・平面を引くこと y x1 y = β1 x1
+ β0 ΣN i=1 (yi − (β1 xi,1 + β0 ))2 が最小になるようにa1, a2を決定すること 最小二乗法 前回までのあらすじ
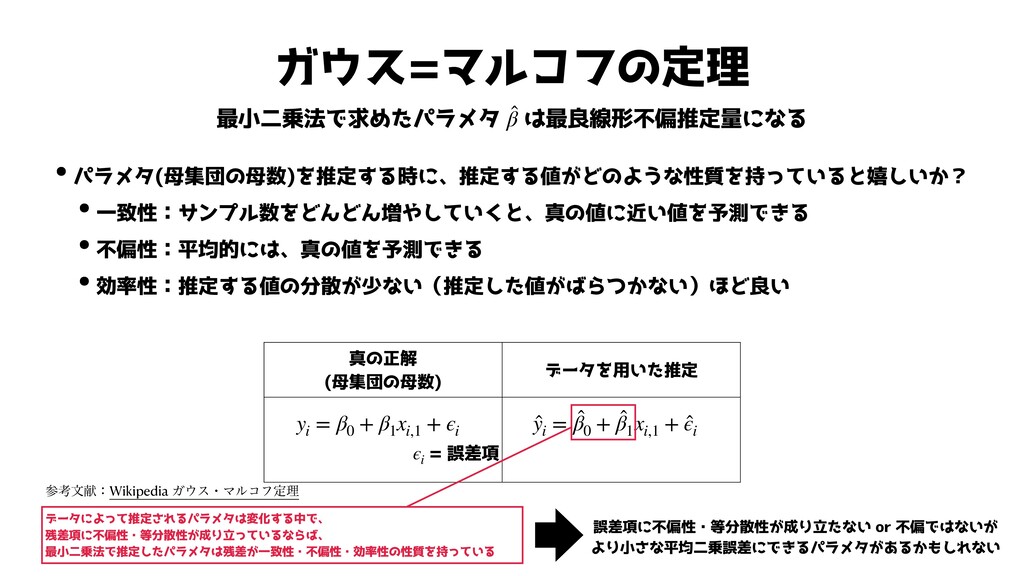
ガウス=マルコフの定理 最小二乗法で求めたパラメタ は最良線形不偏推定量になる ̂ β •パラメタ(母集団の母数)を推定する時に、推定する値がどのような性質を持っていると嬉しいか? •一致性:サンプル数をどんどん増やしていくと、真の値に近い値を予測できる •不偏性:平均的には、真の値を予測できる •効率性:推定する値の分散が少ない(推定した値がばらつかない)ほど良い 真の正解
(母集団の母数) データを用いた推定 yi = β0 + β1 xi,1 + ϵi ̂ yi = ̂ β0 + ̂ β1 xi,1 + ̂ ϵi = 誤差項 ϵi データによって推定されるパラメタは変化する中で、 残差項に不偏性・等分散性が成り立っているならば、 最小二乗法で推定したパラメタは残差が一致性・不偏性・効率性の性質を持っている 誤差項に不偏性・等分散性が成り立たない or 不偏ではないが より小さな平均二乗誤差にできるパラメタがあるかもしれない ࢀߟจݙɿWikipedia ΨεɾϚϧίϑఆཧ
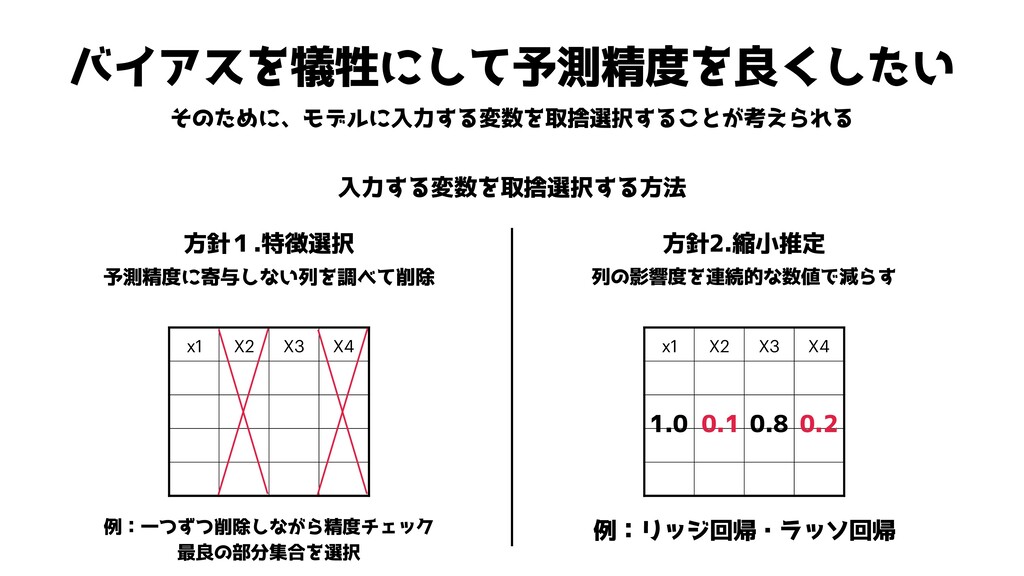
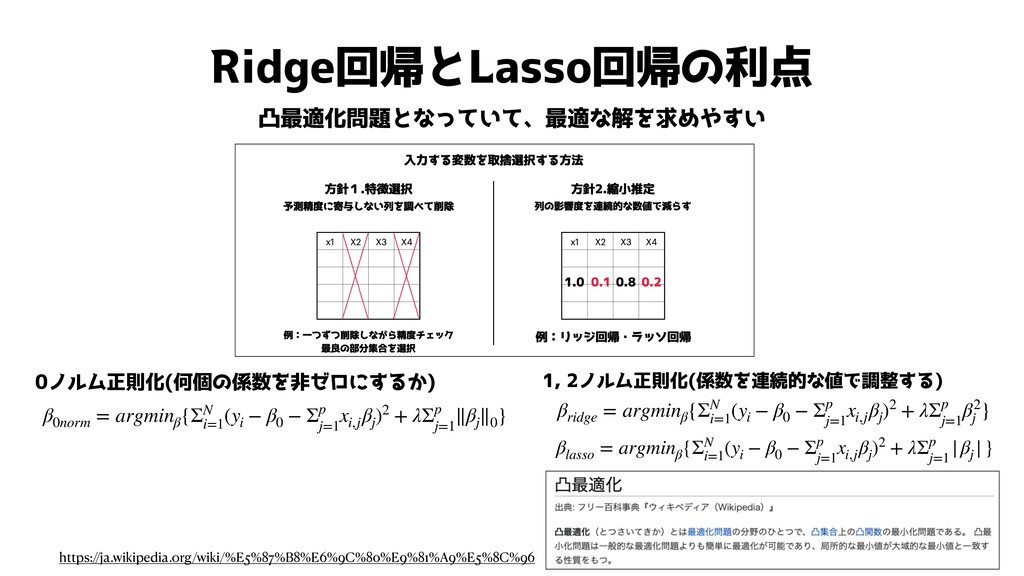
バイアスを犠牲にして予測精度を良くしたい 入力する変数を取捨選択する方法 そのために、モデルに入力する変数を取捨選択することが考えられる x1 X2 X3 X4 方針1.特徴選択 方針2.縮小推定 x1
X2 X3 X4 予測精度に寄与しない列を調べて削除 列の影響度を連続的な数値で減らす 1.0 0.1 0.8 0.2 例:一つずつ削除しながら精度チェック 最良の部分集合を選択 例:リッジ回帰・ラッソ回帰
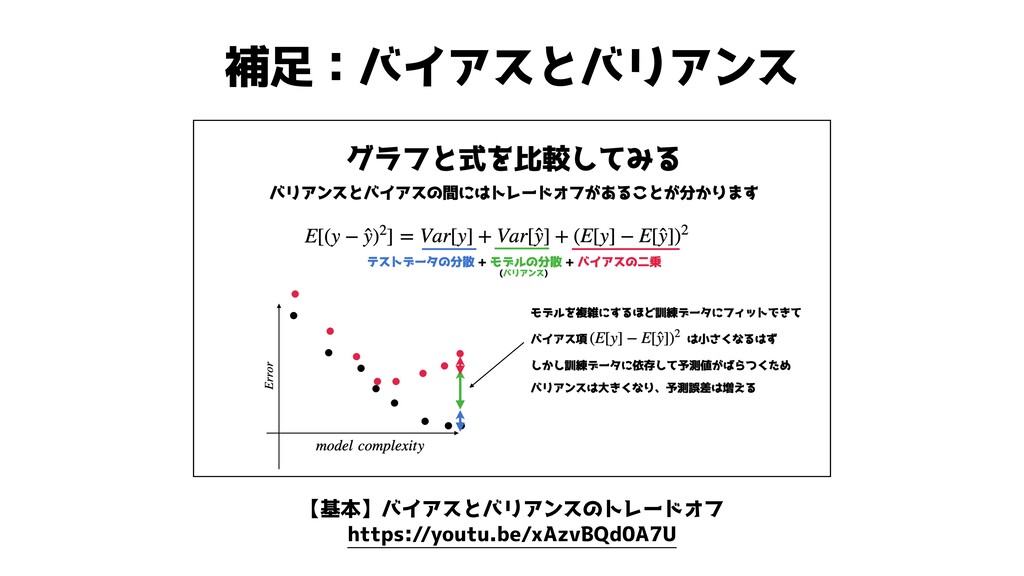
補足:バイアスとバリアンス 【基本】バイアスとバリアンスのトレードオフ https://youtu.be/xAzvBQd0A7U
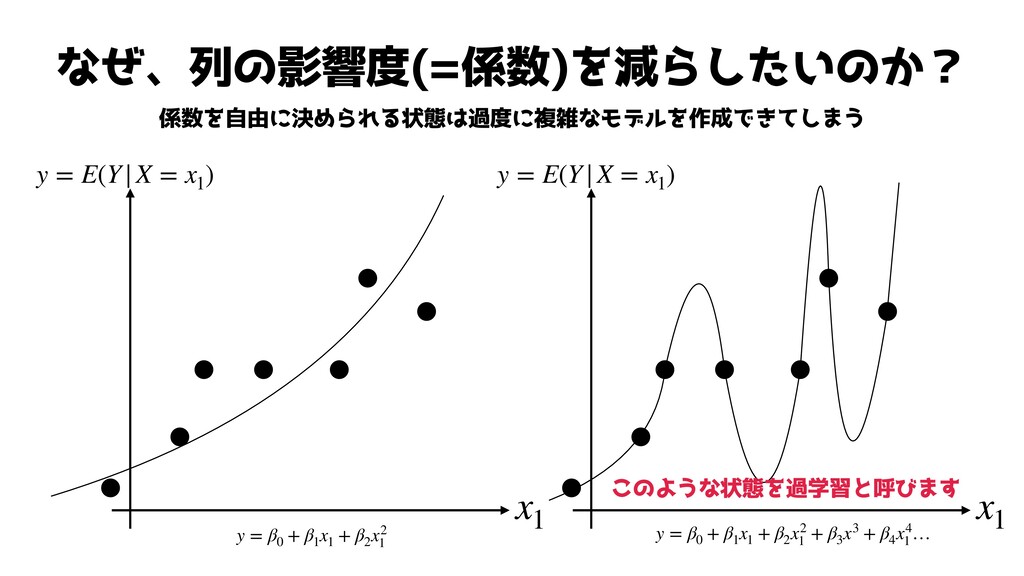
なぜ、列の影響度(=係数)を減らしたいのか? 係数を自由に決められる状態は過度に複雑なモデルを作成できてしまう y = E(Y|X = x1 ) x1 y
= E(Y|X = x1 ) x1 y = β0 + β1 x1 + β2 x2 1 y = β0 + β1 x1 + β2 x2 1 + β3 x3 + β4 x4 1 … このような状態を過学習と呼びます
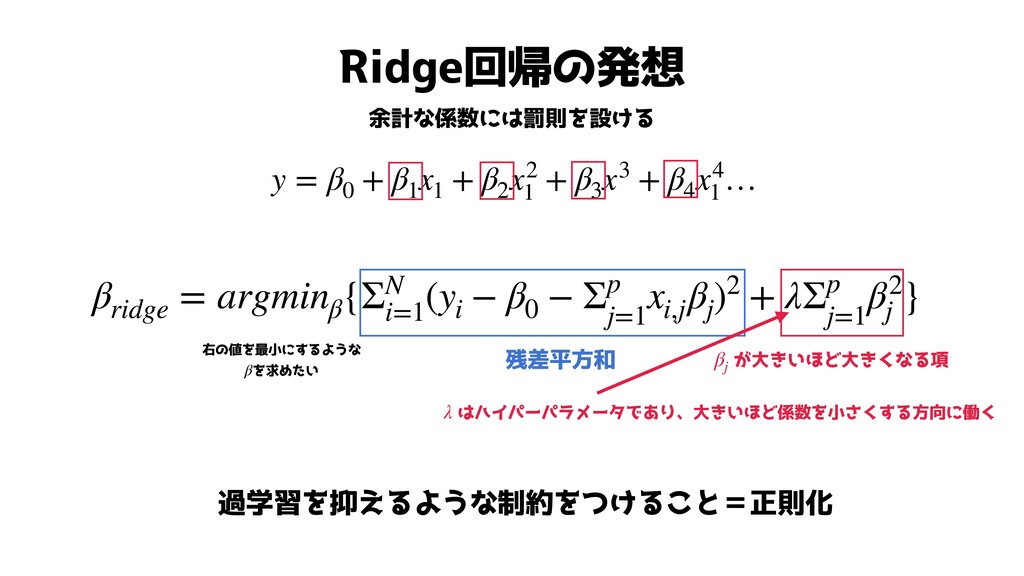
Ridge回帰の発想 余計な係数には罰則を設ける y = β0 + β1 x1 + β2
x2 1 + β3 x3 + β4 x4 1 … βridge = argminβ {ΣN i=1 (yi − β0 − Σp j=1 xi,j βj )2 + λΣp j=1 β2 j } が大きいほど大きくなる項 βj 残差平方和 右の値を最小にするような を求めたい β はハイパーパラメータであり、大きいほど係数を小さくする方向に働く λ 過学習を抑えるような制約をつけること=正則化
Ridge回帰の発想 余計な係数には罰則を設ける βridge = argminβ {ΣN i=1 (yi − β0
− Σp j=1 xi,j βj )2 + λΣp j=1 β2 j } が大きいほど大きくなる項 βj 残差平方和 右の値を最小にするような を求めたい β はハイパーパラメータであり、大きいほど係数を小さくする方向に働く λ ग़యɿ https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html
Ridge回帰を使う場合は変数を正規化する 係数は変数の大きさに依存しているため βridge = argminβ {ΣN i=1 (yi − β0
− Σp j=1 xi,j βj )2 + λΣp j=1 β2 j } が大きいほど大きくなる項 βj 残差平方和 右の値を最小にするような を求めたい β 変数x係数の項があるから、係数の大きさが変数の大きさに依存している →平均0・分散1に近い形に変換すべき ग़యɿ https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html
Lasso回帰の発想 余計な係数には罰則を設ける y = β0 + β1 x1 + β2
x2 1 + β3 x3 + β4 x4 1 … βlasso = argminβ {ΣN i=1 (yi − β0 − Σp j=1 xi,j βj )2 + λΣp j=1 |βj |} が大きいほど大きくなる項 βj 残差平方和 右の値を最小にするような を求めたい β
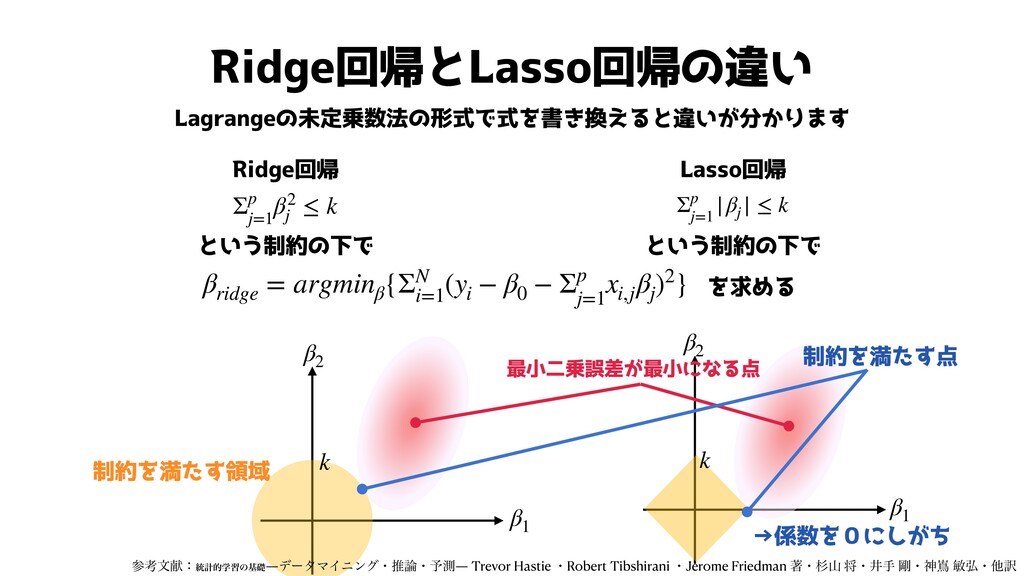
Ridge回帰とLasso回帰の違い 係数を二乗するかしないか βlasso = argminβ {ΣN i=1 (yi − β0
− Σp j=1 xi,j βj )2 + λΣp j=1 |βj |} が大きいほど大きくなる項 βj 残差平方和 右の値を最小にするような を求めたい β βridge = argminβ {ΣN i=1 (yi − β0 − Σp j=1 xi,j βj )2 + λΣp j=1 β2 j } 右の値を最小にするような を求めたい β ここだけ違う
Ridge回帰とLasso回帰の違い Lagrangeの未定乗数法の形式で式を書き換えると違いが分かります βridge = argminβ {ΣN i=1 (yi − β0
− Σp j=1 xi,j βj )2} Σp j=1 β2 j ≤ k Σp j=1 |βj | ≤ k Lasso回帰 Ridge回帰 という制約の下で という制約の下で を求める β1 β2 制約を満たす領域 最小二乗誤差が最小になる点 β1 β2 制約を満たす点 k k ࢀߟจݙɿ౷ܭతֶशͷجૅ―σʔλϚΠχϯάɾਪɾ༧ଌ― Trevor Hastie ɾRobert Tibshirani ɾJerome Friedman ஶɾਿࢁ কɾҪख ߶ɾਆቇ හ߂ɾଞ༁ →係数を0にしがち
Ridge回帰とLasso回帰の利点 凸最適化問題となっていて、最適な解を求めやすい β0norm = argminβ {ΣN i=1 (yi − β0
− Σp j=1 xi,j βj )2 + λΣp j=1 ∥βj ∥0 } βlasso = argminβ {ΣN i=1 (yi − β0 − Σp j=1 xi,j βj )2 + λΣp j=1 |βj |} βridge = argminβ {ΣN i=1 (yi − β0 − Σp j=1 xi,j βj )2 + λΣp j=1 β2 j } 0ノルム正則化(何個の係数を非ゼロにするか) 1, 2ノルム正則化(係数を連続的な値で調整する) https://ja.wikipedia.org/wiki/%E5%87%B8%E6%9C%80%E9%81%A9%E5%8C%96
まとめ 正則化と過学習について説明しました •線形回帰の係数に制約をつけない場合、過度に複雑なモデルを作成できてしまい、そ のような状態を過学習と呼ぶ •過学習を抑えるために制約をつけることを正則化と呼ぶ •正則化の方法として特徴選択(0-ノルム正則化)、ラッソ回帰(1-ノルム正則化)、リッ ジ回帰(2-ノルム正則化)を紹介しました •リッジ回帰とラッソ回帰はあらかじめ変数を正規化する必要がある •ラッソ回帰は係数を0にする働きある
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}