Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
主成分分析(PCA)の仕組み
Search
K_DM
January 15, 2022
Education
220
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
主成分分析(PCA)の仕組み
K_DM
January 15, 2022
More Decks by K_DM
See All by K_DM
X-meansの仕組み
k_study
0
2.2k
勾配ブースティングの仕組み
k_study
0
140
k-meansクラスタリングの仕組み
k_study
0
290
決定木を使った回帰の仕組み
k_study
0
240
アンサンブル学習① ランダムフォレストの仕組み
k_study
0
120
決定木に含まれるパラメタによる事前剪定と事後剪定
k_study
0
740
線形回帰② 正則化と過学習
k_study
0
620
外れ値とHuber(フーバー)損失
k_study
0
1.2k
木構造1~決定木の仕組み(分類)
k_study
0
190
Other Decks in Education
See All in Education
データマネジメント試験対策教材1〜データマネジメント基礎〜
yoshimura_datam
1
470
Beyond the Prompt: Programming as a Pathway to Statistical Thinking
minecr
0
250
Info Session MSc Computer Science & MSc Applied Informatics
signer
PRO
0
300
アラムコSTEAMチャレンジ 実践報告書
codeforeveryone
0
180
Case Studies - Lecture 12 - Information Visualisation (4019538FNR)
signer
PRO
0
180
0526
cbtlibrary
0
200
「答えを出す」より「わかる」をつくる
kzkmaeda
1
230
【デザイナー就活講座】 デザイナー就活市場・企業探し・ポートフォリオのポイント
koheihasebe
0
280
Portable & Reproducible Research Environments in the Age of AI Agents
denkiwakame
0
500
2026年度春学期 統計学 第10回 分布の推測とは - 標本調査,度数分布と確率分布 (2026. 6. 4)
akiraasano
PRO
0
150
Πλουτοκρατία: Η Τυραννία του Μαμμωνά και η Μεταανθρώπινη Δουλεία
amethyst1
0
270
現場最前線から教えるデータサイエンス1 -ITベンダーにおけるデータサイエンティスト-
hidetoshikawaguchi
0
140
Featured
See All Featured
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
290
Automating Front-end Workflow
addyosmani
1370
210k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Designing for Timeless Needs
cassininazir
1
380
So, you think you're a good person
axbom
PRO
2
2.1k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
30 Presentation Tips
portentint
PRO
1
350
Fireside Chat
paigeccino
42
4k
Test your architecture with Archunit
thirion
1
2.3k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
Transcript
次元削減1 次元削減1 主成分分析 主成分分析 作成者:K (リンク)
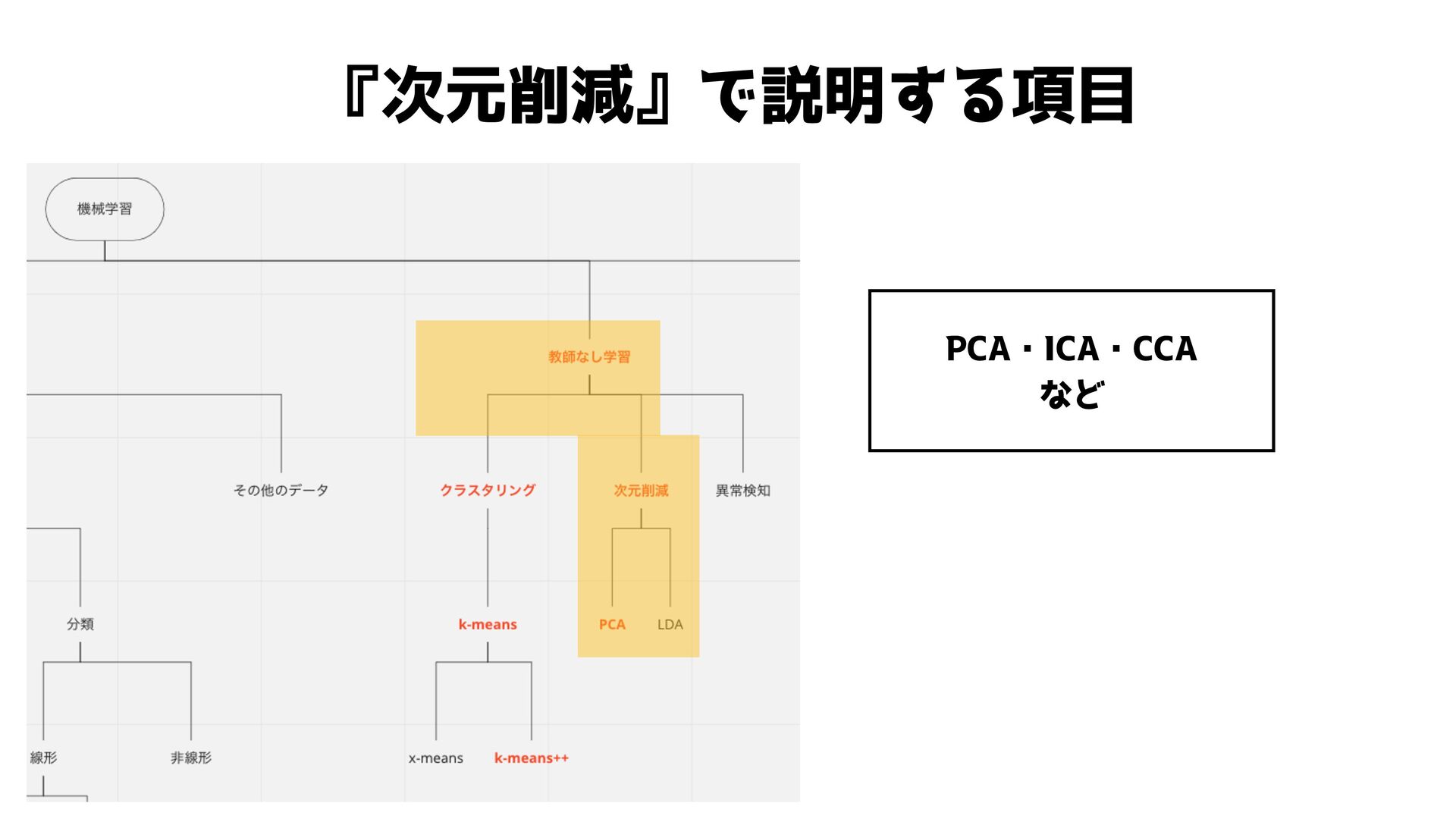
『次元削減』で説明する項目 PCA・ICA・CCA など
今回の内容 •「教師なし学習」のおさらい •「次元削減」とは •主成分分析 •アルゴリズム •実験 •まとめ PCA(主成分分析)について説明します
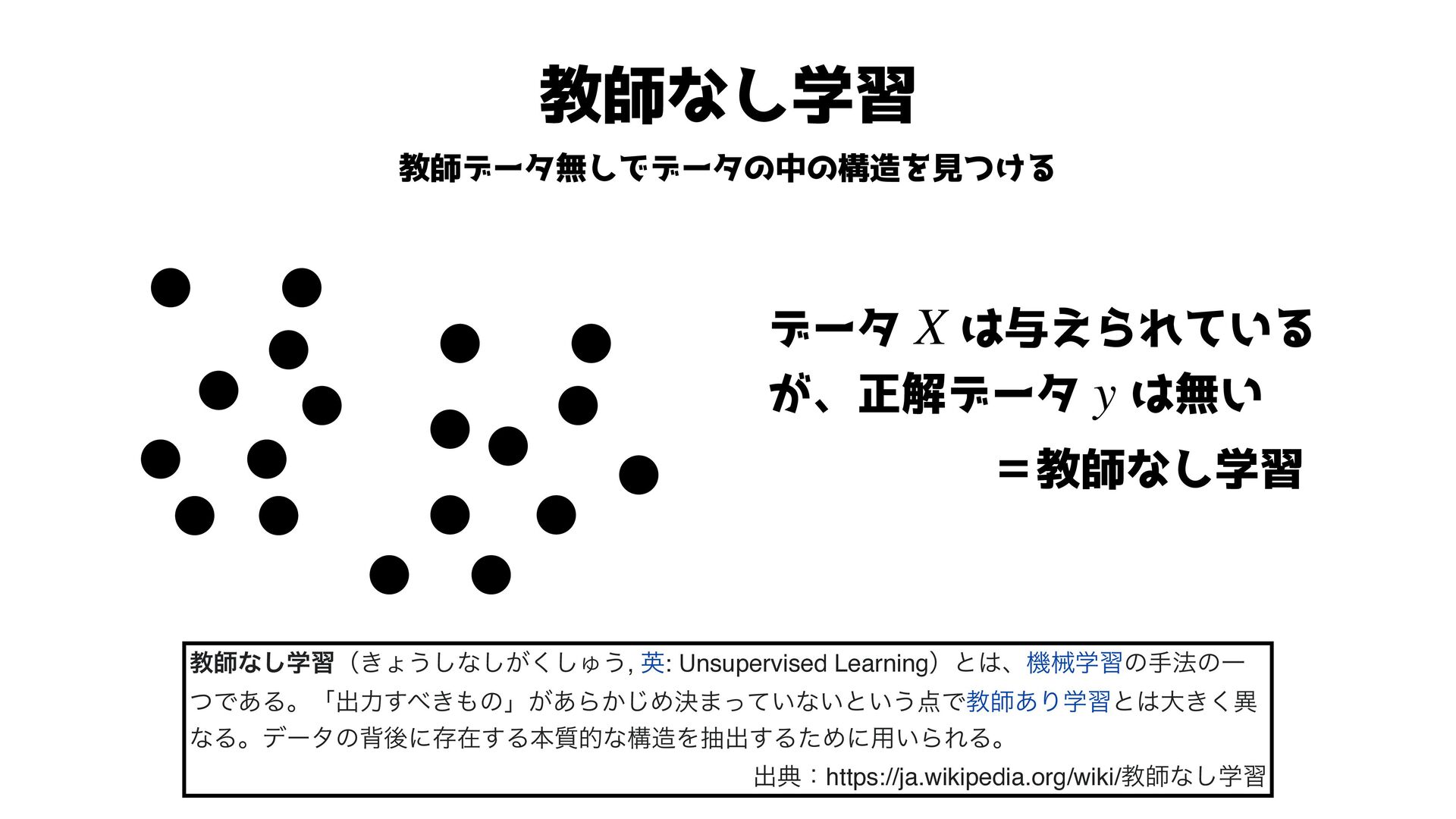
教師なし学習 教師データ無しでデータの中の構造を見つける データ は与えられている が、正解データ は無い =教師なし学習 X y ڭࢣͳֶ͠शʢ͖ΐ͏͠ͳ͕͘͠͠Ύ͏,
ӳ: Unsupervised Learningʣͱɺػցֶशͷख๏ͷҰ ͭͰ͋Δɻʮग़ྗ͖͢ͷʯ͕͋Β͔͡Ίܾ·͍ͬͯͳ͍ͱ͍͏Ͱڭࢣ͋Γֶशͱେ͖͘ҟ ͳΔɻσʔλͷഎޙʹଘࡏ͢Δຊ࣭తͳߏΛநग़͢ΔͨΊʹ༻͍ΒΕΔɻ ग़యɿhttps://ja.wikipedia.org/wiki/ڭࢣͳֶ͠श
次元削減とは たくさんある特徴をより少ない数値で表現する 例:ボディマス指数 BMI = 体重[kg] / (身長[m]) × (身長[m])
→体重と身長というデータをBMIと呼ばれる一つの数値で表している
次元削減とは たくさんある特徴をより少ない数値で表現する 例:ボディマス指数 BMI = 体重[kg] / (身長[m]) × (身長[m])
→体重と身長というデータをBMIと呼ばれる一つの数値で表している 手元にあるデータに対して、いい感じに次元削減して データを表現する方法はないだろうか? ㅟ ㅟ ㅟ ㅟ
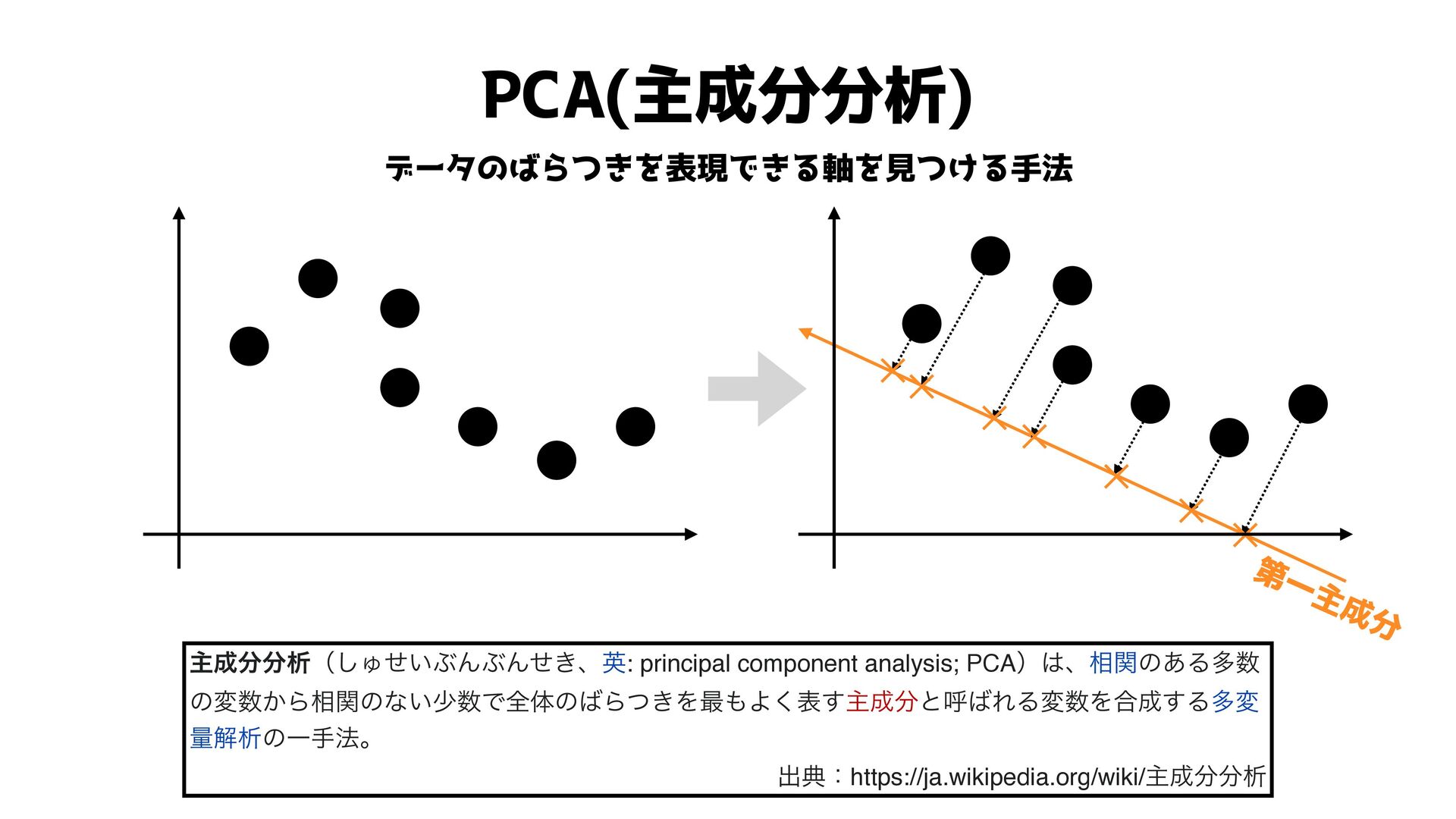
PCA(主成分分析) データのばらつきを表現できる軸を見つける手法 ओੳʢ͠Ύ͍ͤͿΜͿΜ͖ͤɺӳ: principal component analysis; PCAʣɺ૬ؔͷ͋Δଟ ͷม͔Β૬ؔͷͳ͍গͰશମͷΒ͖ͭΛ࠷Α͘ද͢ओͱݺΕΔมΛ߹͢Δଟม ྔղੳͷҰख๏ɻ ग़యɿhttps://ja.wikipedia.org/wiki/ओੳ
✕✕ ✕ ✕ ✕ ✕ ✕ 第一主成分
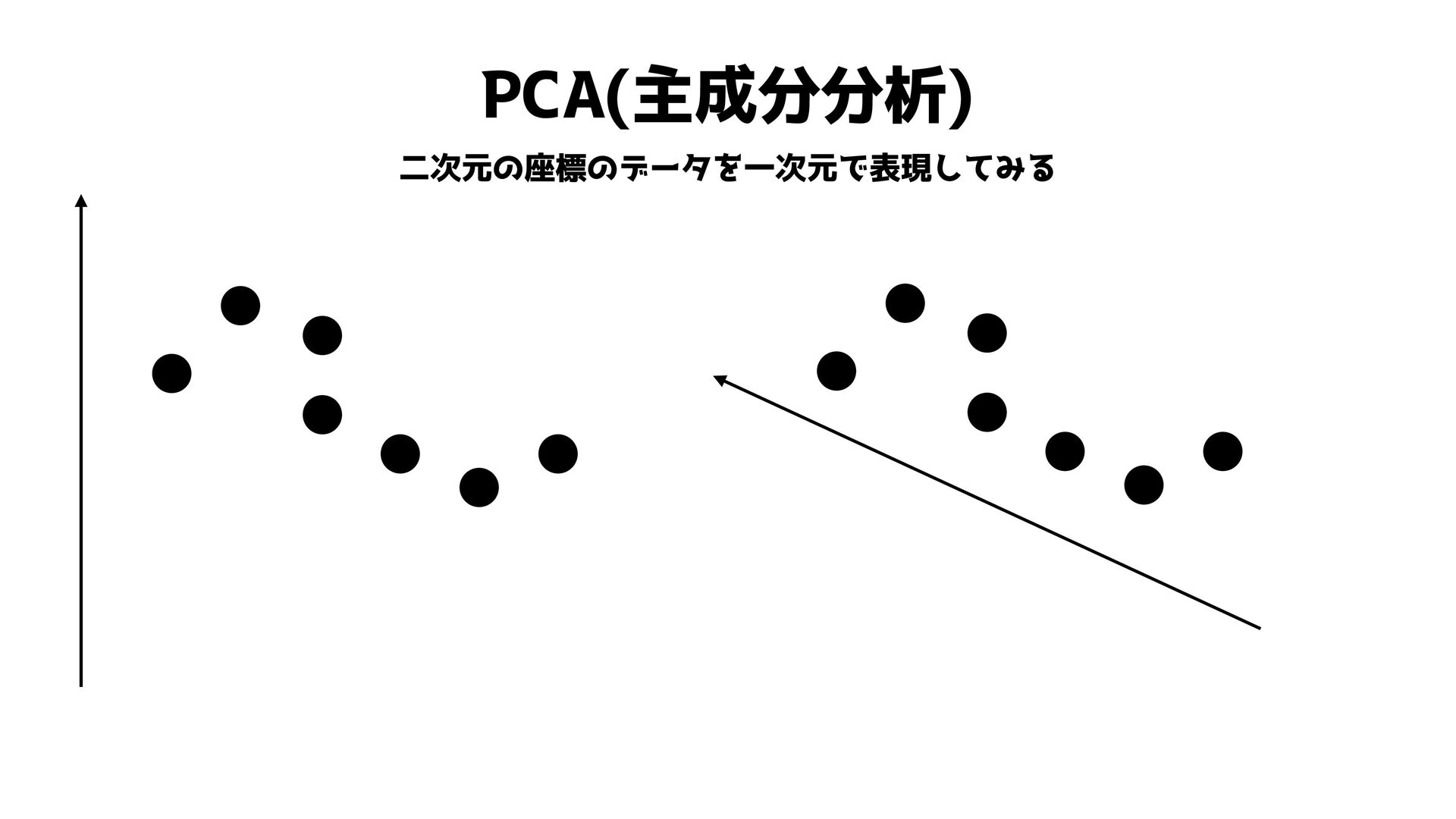
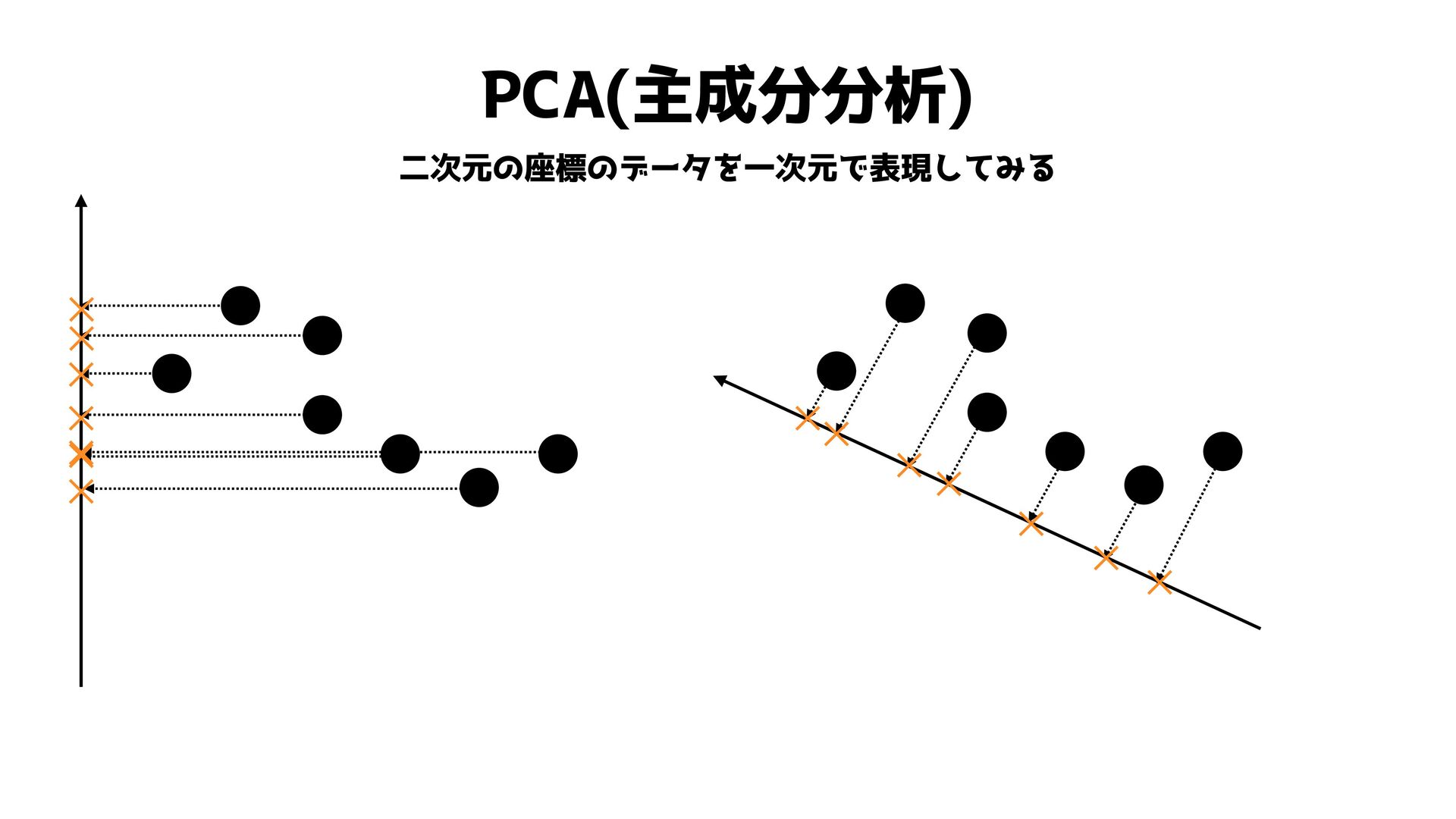
PCA(主成分分析) 二次元の座標のデータを一次元で表現してみる
PCA(主成分分析) 二次元の座標のデータを一次元で表現してみる ✕✕ ✕ ✕ ✕ ✕ ✕ ✕ ✕
✕ ✕ ✕ ✕ ✕
PCA(主成分分析) 二次元の座標のデータを一次元で表現してみる ✕✕ ✕ ✕ ✕ ✕ ✕ ✕ ✕
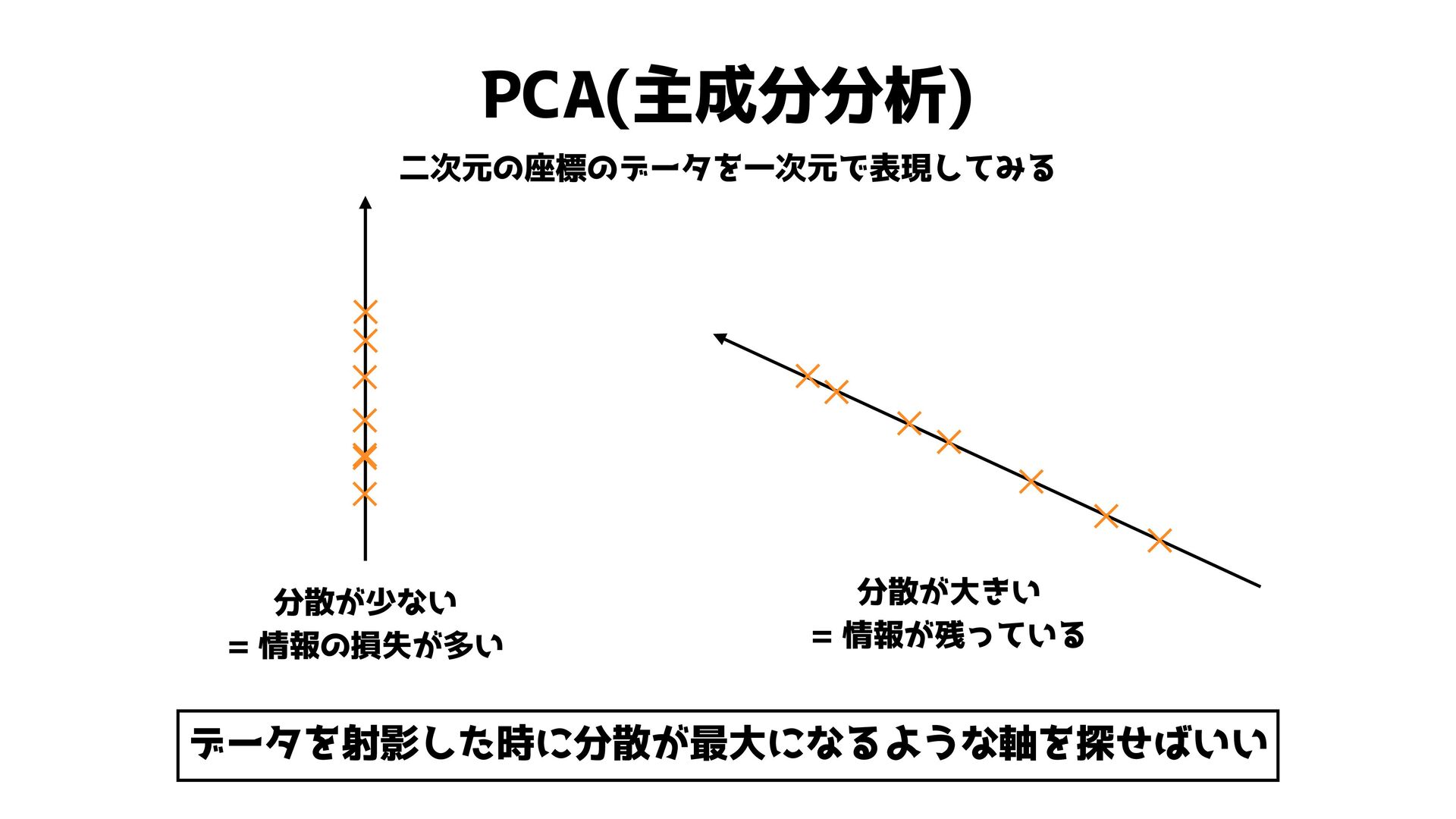
✕ ✕ ✕ ✕ ✕ 分散が少ない = 情報の損失が多い 分散が大きい = 情報が残っている データを射影した時に分散が最大になるような軸を探せばいい
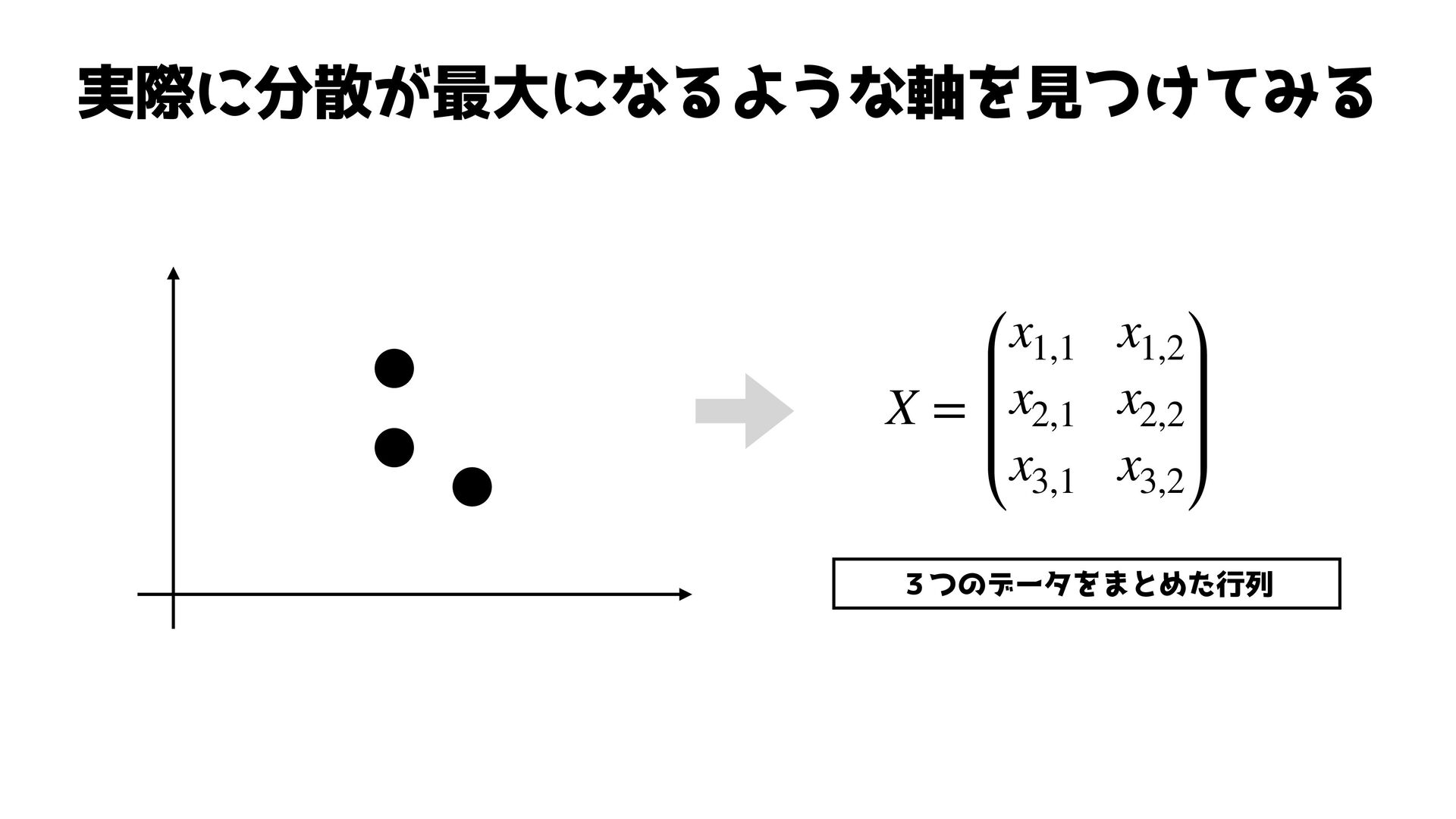
実際に分散が最大になるような軸を見つけてみる 3つのデータをまとめた行列 X = x1,1 x1,2 x2,1 x2,2 x3,1 x3,2
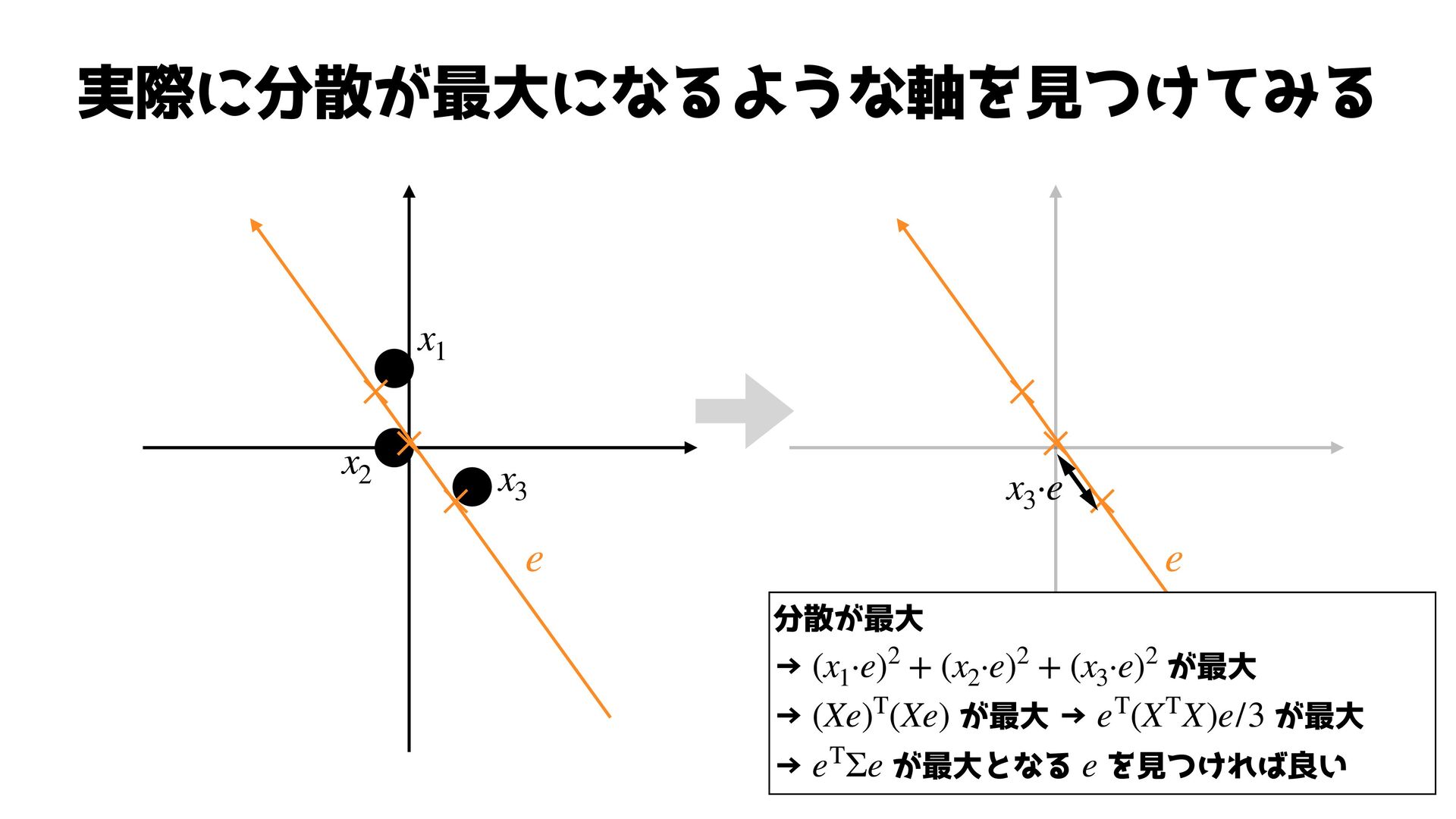
実際に分散が最大になるような軸を見つけてみる ✕ ✕ ✕ ✕ ✕ ✕ e e x1
x2 x3 x3 ·e 分散が最大 → が最大 → が最大 → が最大 → が最大となる を見つければ良い (x1 ·e)2 + (x2 ·e)2 + (x3 ·e)2 (Xe)T(Xe) eT(XTX)e/3 eTΣe e
実際に分散が最大になるような軸を見つけてみる ✕ ✕ ✕ e x3 ·e 分散が最大 → が最大
→ が最大 → が最大 → が最大となる を見つければ良い (x1 ·e)2 + (x2 ·e)2 + (x3 ·e)2 (Xe)T(Xe) eT(XTX)/3 eTΣe e の直線であり という制約をつける ↓ 「制約がある中で分散の式を最大にする」 という問題になる。 ↓ ラグランジュの未定乗数法で解ける! e = αx + βy α2 + β2 = 1
ラグランジュの未定乗数法を適用する L(ex , ey , λ) = eTΣe − λ(α2
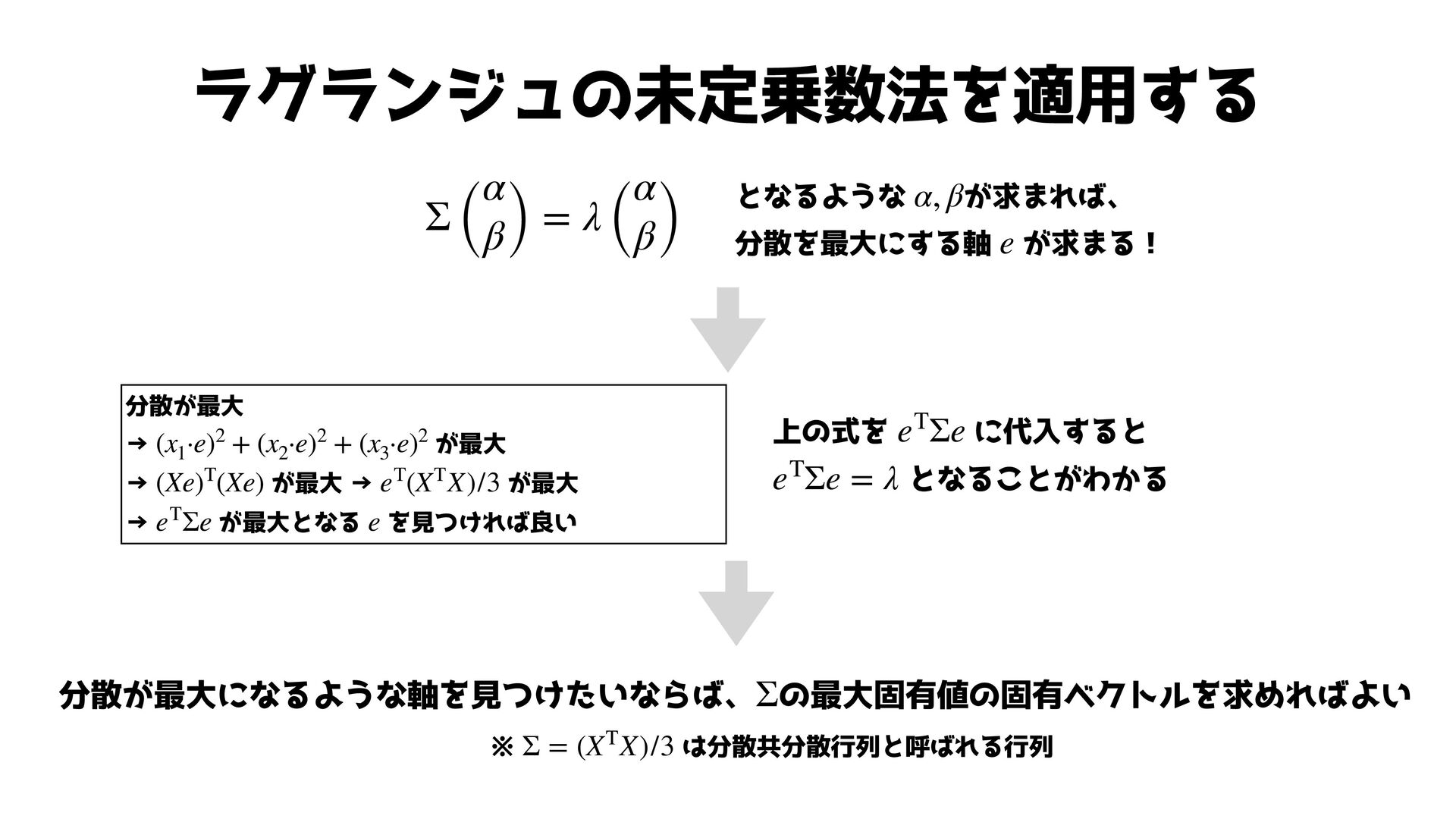
+ β2 − 1) ∂L(ex , ey , λ) ∂α = (1 0) Σ ( α β) + (α β) ΣT ( 1 0) − 2λα = 0 ∂L(ex , ey , λ) ∂β = (0 1) Σ ( α β) + (α β) ΣT ( 0 1) − 2λβ = 0 Σ ( α β) = λ ( α β) となるような が求まれば、 分散を最大にする軸 が求まる! α, β e
ラグランジュの未定乗数法を適用する Σ ( α β) = λ ( α β)
となるような が求まれば、 分散を最大にする軸 が求まる! α, β e 分散が最大になるような軸を見つけたいならば、 の最大固有値の固有ベクトルを求めればよい Σ ※ は分散共分散行列と呼ばれる行列 Σ = (XTX)/3 分散が最大 → が最大 → が最大 → が最大 → が最大となる を見つければ良い (x1 ·e)2 + (x2 ·e)2 + (x3 ·e)2 (Xe)T(Xe) eT(XTX)/3 eTΣe e 上の式を に代入すると となることがわかる eTΣe eTΣe = λ
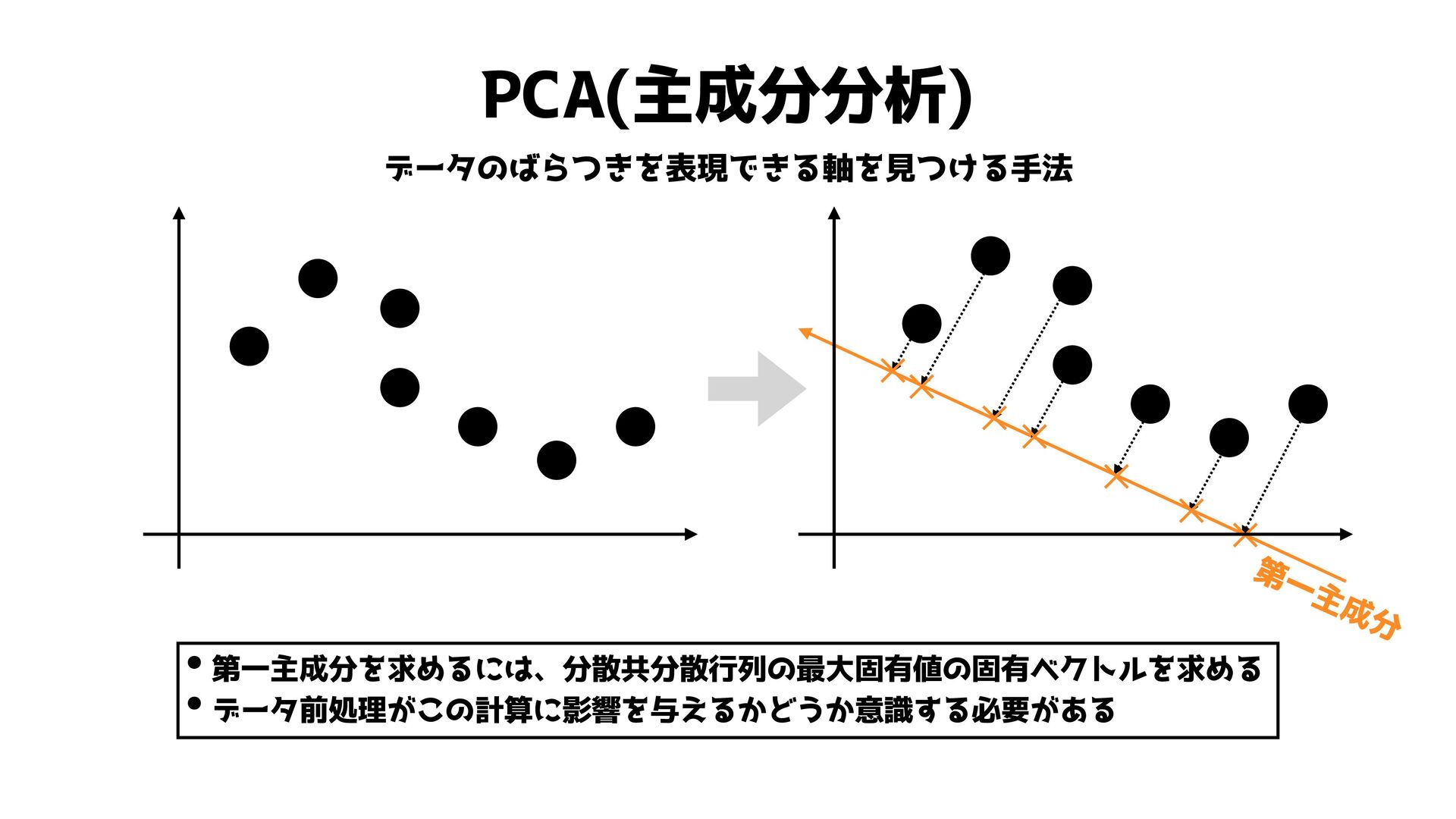
PCA(主成分分析) データのばらつきを表現できる軸を見つける手法 ✕✕ ✕ ✕ ✕ ✕ ✕ 第一主成分 •第一主成分を求めるには、分散共分散行列の最大固有値の固有ベクトルを求める
•データ前処理がこの計算に影響を与えるかどうか意識する必要がある
実験!
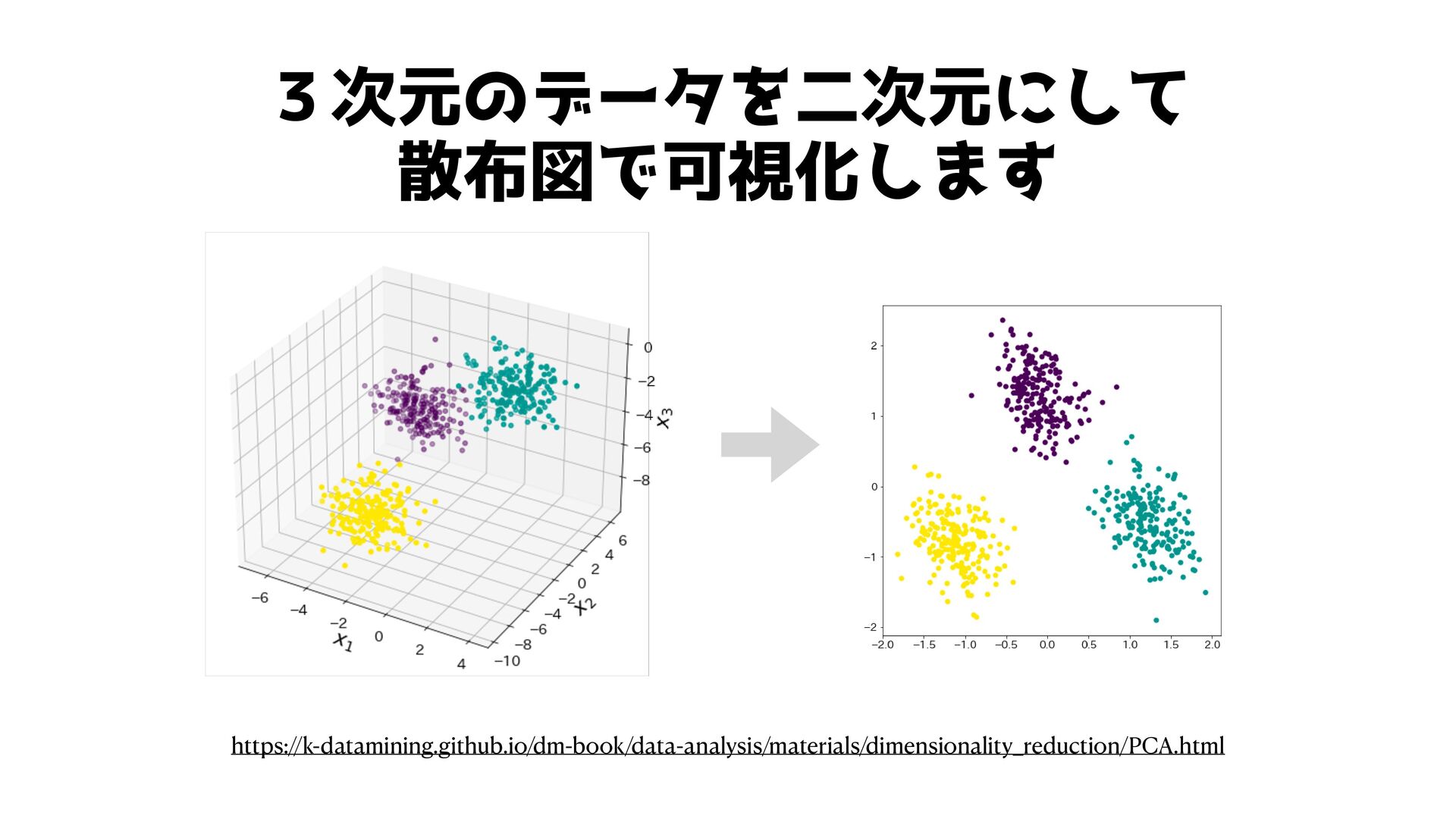
3次元のデータを二次元にして 散布図で可視化します https://k-datamining.github.io/dm-book/data-analysis/materials/dimensionality_reduction/PCA.html
まとめ 主成分分析について説明しました •主成分分析(PCA)とは、次元削減をする教師なし学習手法のひとつ •主に高次元のデータを可視化する時に使うことができる •分散が最大になる方向が最も情報の損失が少ない方向 •分散共分散行列の固有ベクトルを求めることで、主成分方向が求まる •PCAで次元削減して可視化をする時は、データ前処理がPCAの計算にどのような影響 を与えるか考える
参考文献 •鈴木大慈, データ解析 第七回「主成分分析」http://ibis.t.u-tokyo.ac.jp/suzuki/ lecture/2015/dataanalysis/L7.pdf •sklearn.decomposition.PCA — scikit-learn 1.0.2 documentation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![次元削減とは たくさんある特徴をより少ない数値で表現する 例:ボディマス指数 BMI = 体重[kg] / (身長[m]) × (身長[m])](https://files.speakerdeck.com/presentations/c29ea12be61448dd8373110e198b5254/slide_4.jpg){kind=link}
![次元削減とは たくさんある特徴をより少ない数値で表現する 例:ボディマス指数 BMI = 体重[kg] / (身長[m]) × (身長[m])](https://files.speakerdeck.com/presentations/c29ea12be61448dd8373110e198b5254/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}