Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
勾配ブースティングの仕組み
Search
K_DM
January 06, 2022
Education
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
勾配ブースティングの仕組み
勾配ブースティングの仕組みについて概要を説明したスライドです。
動画:
https://youtu.be/ZgssfFWQbZ8
K_DM
January 06, 2022
More Decks by K_DM
See All by K_DM
主成分分析(PCA)の仕組み
k_study
0
220
X-meansの仕組み
k_study
0
2.2k
k-meansクラスタリングの仕組み
k_study
0
290
決定木を使った回帰の仕組み
k_study
0
240
アンサンブル学習① ランダムフォレストの仕組み
k_study
0
120
決定木に含まれるパラメタによる事前剪定と事後剪定
k_study
0
740
線形回帰② 正則化と過学習
k_study
0
620
外れ値とHuber(フーバー)損失
k_study
0
1.2k
木構造1~決定木の仕組み(分類)
k_study
0
190
Other Decks in Education
See All in Education
コミュニティを通じた_キャリア設計のススメ_20260424.pdf
masakiokuda
0
360
Human-AI Interaction - Lecture 11 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
1.1k
「答えを出す」より「わかる」をつくる
kzkmaeda
1
230
教育現場から見た Ruby on Rails
yasslab
PRO
0
210
[2026前期火5] 論理学(京都大学文学部 前期 第14回)「計算は、証明ではない——ハルシネーションを三層ハーモニーで診る」
yatabe
0
110
モブ社員がモブエンジニアを名乗って得られたこと_20260413
masakiokuda
4
560
Πλουτοκρατία: Η Τυραννία του Μαμμωνά και η Μεταανθρώπινη Δουλεία
amethyst1
0
270
[2026前期火5] 論理学(京都大学文学部 前期 第12回)「証明を走らせる:カリー・ハワード対応」
yatabe
0
210
AIには考えられないことを考えられる人になるために
iqbocchi
1
200
Stardy 会社紹介資料
stardy
0
3k
[2026前期火5] 論理学(京都大学文学部 前期 第3回)「形式言語と四つのキーワード:メタ・構成・意味論・ハーモニー」
yatabe
0
600
データマネジメント試験対策教材1〜データマネジメント基礎〜
yoshimura_datam
1
470
Featured
See All Featured
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
900
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Product Roadmaps are Hard
iamctodd
55
12k
Everyday Curiosity
cassininazir
0
260
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Marketing to machines
jonoalderson
1
5.6k
The Limits of Empathy - UXLibs8
cassininazir
1
510
Transcript
アンサンブル4 アンサンブル4 勾配ブースティング 勾配ブースティング
アンサンブル学習とは 複数の予測モデルを組合せて、ロバスト性やより高い性能を目指す 複数モデルの予測値をまとめる方針 ブースティング(Boosting) •バギング •ランダムフォレスト •ExtraTrees •Stacking •AdaBoost •GradientBoosting
•XGBoost 複数の予測モデルの平均や多数決を取り、 最終的な予測を行う 予測モデルの誤差に注目して 少しずつモデルを改善して行く 勾配ブースティング(Gradient Boosting) 前回までのおさらい
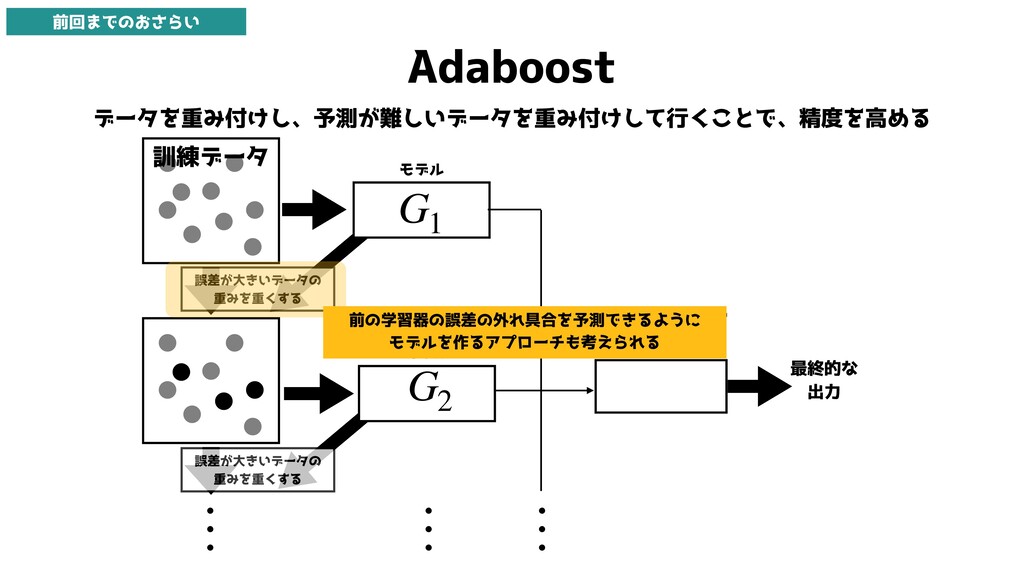
Adaboost データを重み付けし、予測が難しいデータを重み付けして行くことで、精度を高める … • • • • • • •
• • モデル 各モデルの出力を 受け取り集約 最終的な 出力 G1 • • • • • • • • • … G2 誤差が大きいデータの 重みを重くする モデル … 誤差が大きいデータの 重みを重くする 訓練データ 前回までのおさらい 前の学習器の誤差の外れ具合を予測できるように モデルを作るアプローチも考えられる
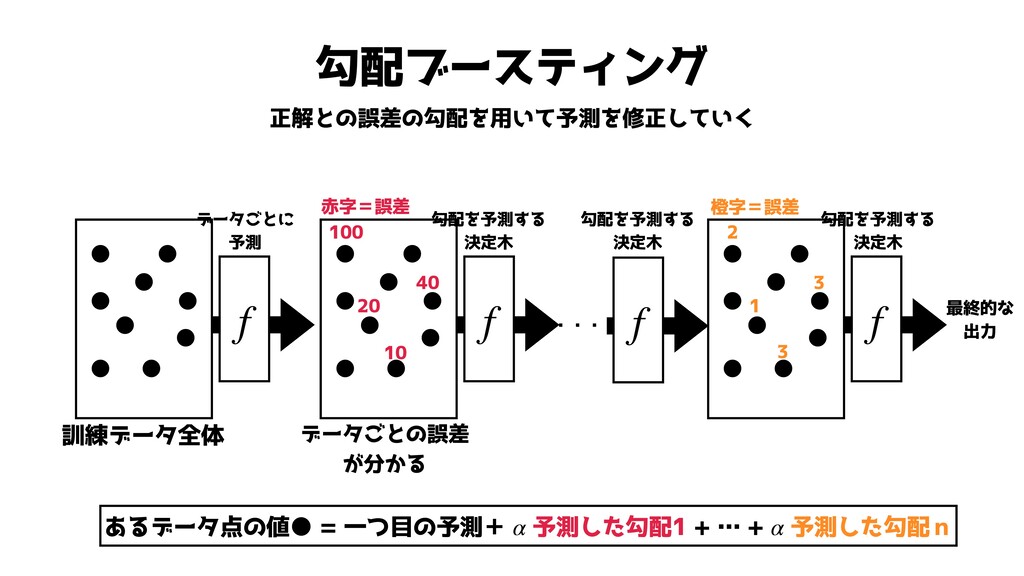
勾配ブースティング 正解との誤差の勾配を用いて予測を修正していく 訓練データ全体 ・・・ 最終的な 出力 • • • •
• • • • • f • • • • • • • • • f • • • • • • • • • f f 100 20 10 40 データごとの誤差 が分かる 勾配を予測する 決定木 勾配を予測する 決定木 勾配を予測する 決定木 2 1 3 3 データごとに 予測 赤字=誤差 あるデータ点の値• = 一つ目の予測+ 予測した勾配1 + … + 予測した勾配n α α 橙字=誤差
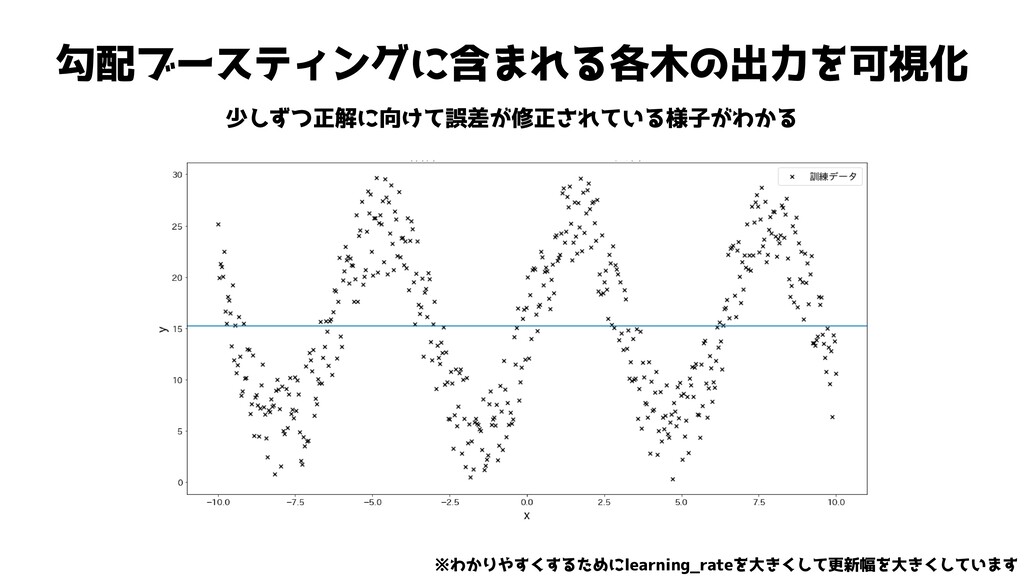
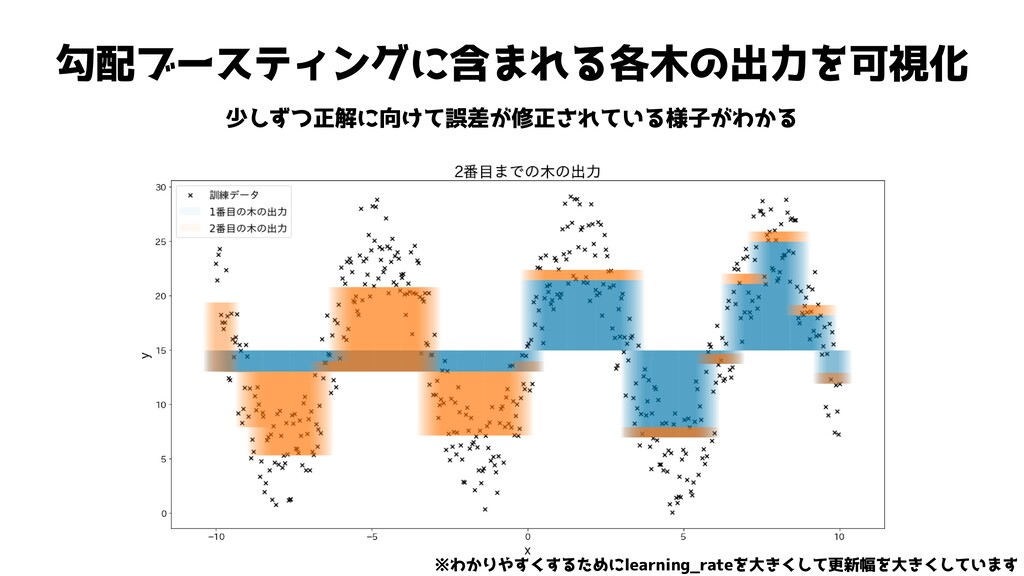
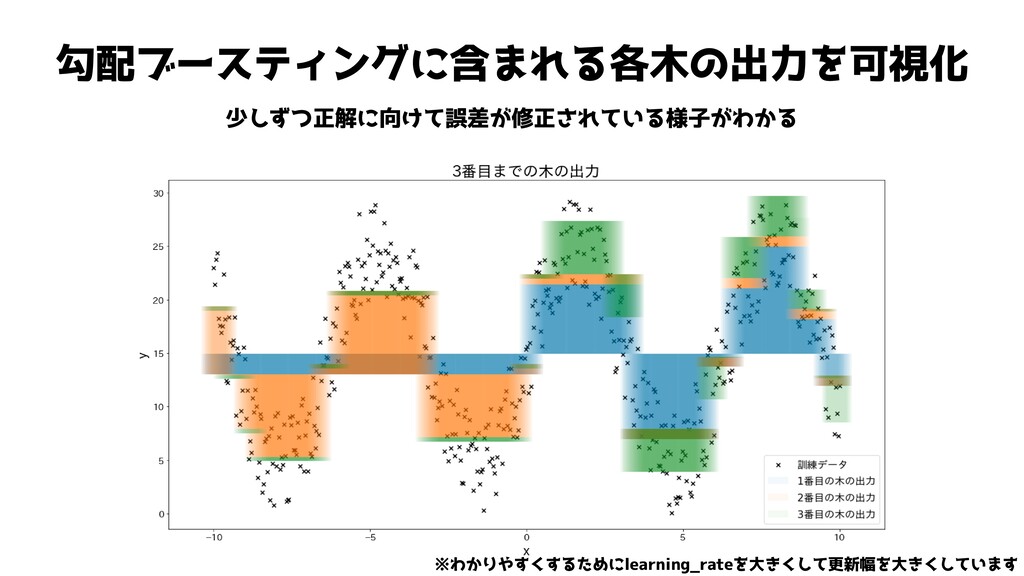
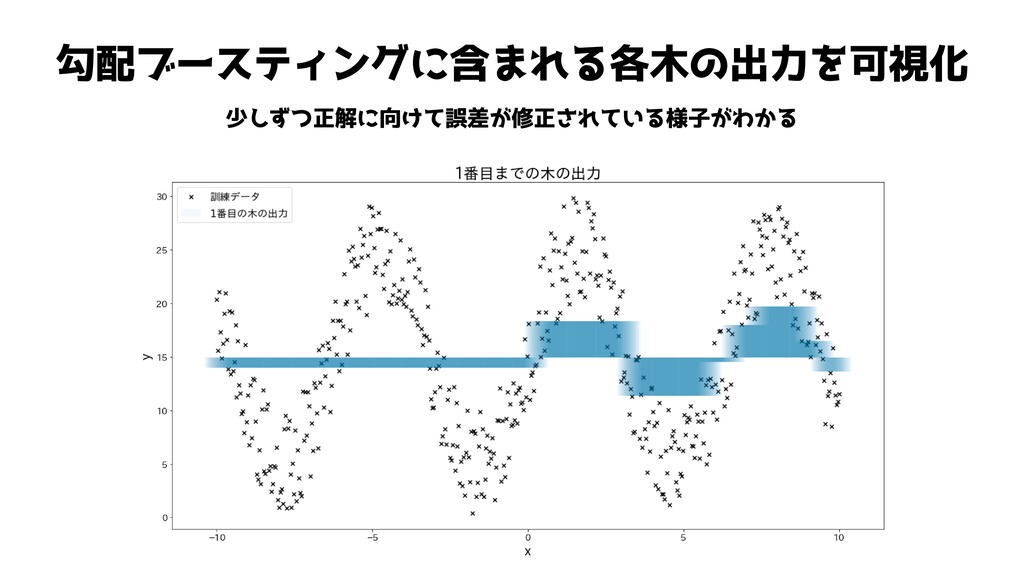
勾配ブースティングに含まれる各木の出力を可視化 少しずつ正解に向けて誤差が修正されている様子がわかる ※わかりやすくするためにlearning_rateを大きくして更新幅を大きくしています
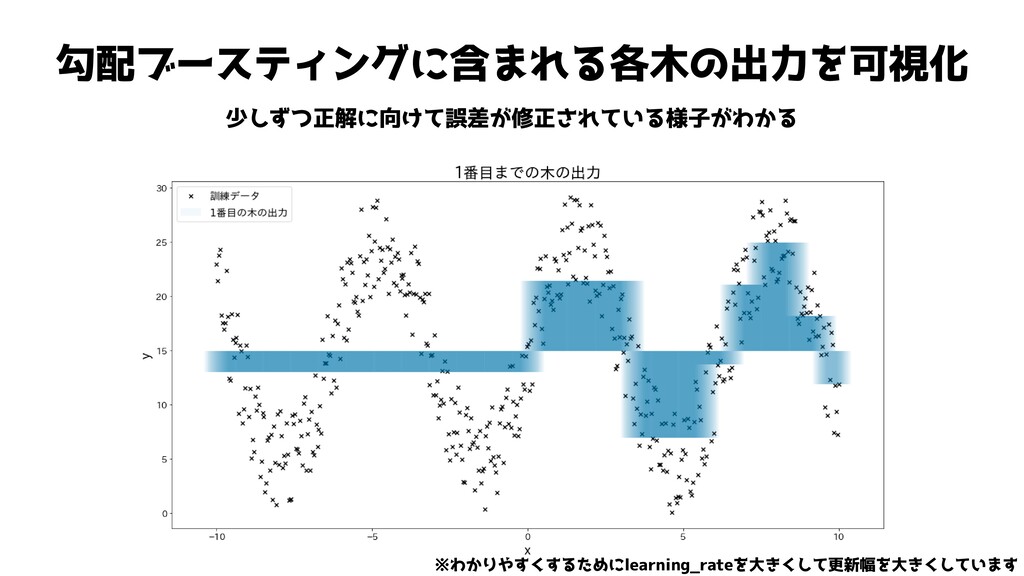
勾配ブースティングに含まれる各木の出力を可視化 少しずつ正解に向けて誤差が修正されている様子がわかる ※わかりやすくするためにlearning_rateを大きくして更新幅を大きくしています
勾配ブースティングに含まれる各木の出力を可視化 少しずつ正解に向けて誤差が修正されている様子がわかる ※わかりやすくするためにlearning_rateを大きくして更新幅を大きくしています
勾配ブースティングに含まれる各木の出力を可視化 少しずつ正解に向けて誤差が修正されている様子がわかる ※わかりやすくするためにlearning_rateを大きくして更新幅を大きくしています
アルゴリズム① 1. いくつかモデルを作成し、その中から損失が最小のモデルを選択する 2. 以下のステップを 回繰り返す( ) 2-1. 各データについて、以下の値を計算する
fo (x) = argminγ ΣN i=1 L(yi , γ) M m = 1,2,…, M rim = − [ ∂L(yi , f(xi )) ∂f(xi ) ]f=fm−1 1 2 (yn − fm (x)))2 → yn − fm (x) 損失を偏微分 参考文献:Trevor Hastie ・Robert Tibshirani ・Jerome Friedman 著・杉山 将・井手 剛・神嶌 敏弘・栗田 多喜夫・前田 英作監訳・井尻 善久・井手 剛・岩田 具治・金森 敬文・兼村 厚範・烏山 昌幸・河原 吉伸・木村 昭悟・小 西 嘉典・酒井 智弥・鈴木 大慈・竹内 一郎・玉木 徹・出口 大輔・冨岡 亮太・波部 斉・前田 新一・持橋 大地・山田 誠訳 ”統計的学習の基礎: データマイニング・推論・予測”. 共立出版, 2014.
アルゴリズム② 2-2. を予測できるような回帰木を作成する 2-3. 終端領域 について となるような を求める
2-4. としてモデルを更新する rim Rjm (j = 1,…, Jm ) γjm = argminγ Σxi ∈Rjm L(yi , fm−1 (xi ) + γ) γjm fm (x) = fm−1 (x) + ΣJm j=1 γjm I(x ∈ Rjm ) 参考文献:Trevor Hastie ・Robert Tibshirani ・Jerome Friedman 著・杉山 将・井手 剛・神嶌 敏弘・栗田 多喜夫・前田 英作監訳・井尻 善久・井手 剛・岩田 具治・金森 敬文・兼村 厚範・烏山 昌幸・河原 吉伸・木村 昭悟・小 西 嘉典・酒井 智弥・鈴木 大慈・竹内 一郎・玉木 徹・出口 大輔・冨岡 亮太・波部 斉・前田 新一・持橋 大地・山田 誠訳 ”統計的学習の基礎: データマイニング・推論・予測”. 共立出版, 2014. 番目までの モデルの出力 m − 1 番目に加える微調整 m 可視化した回帰木
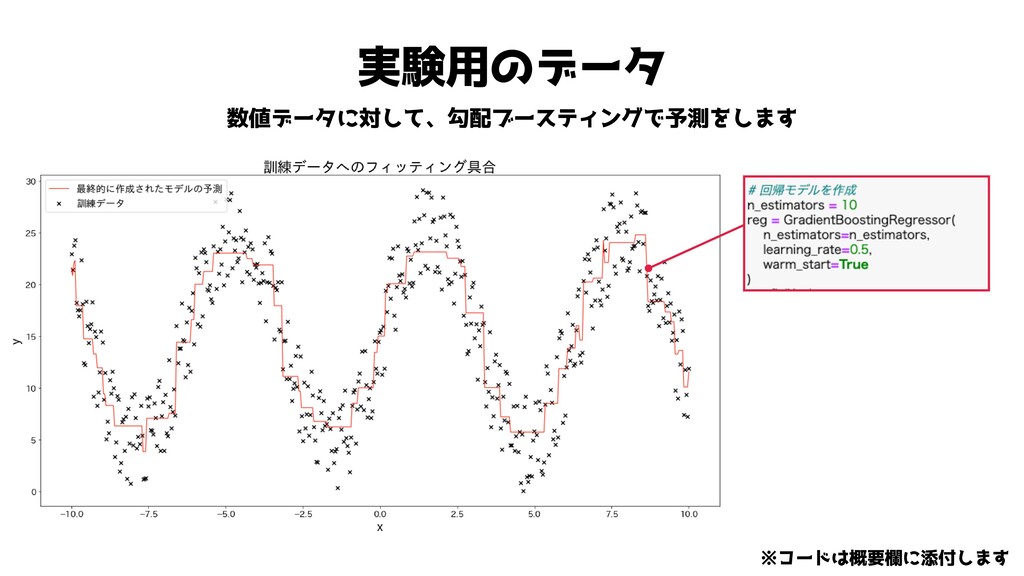
実験! じ っ け ん
実験用のデータ 数値データに対して、勾配ブースティングで予測をします ※コードは概要欄に添付します
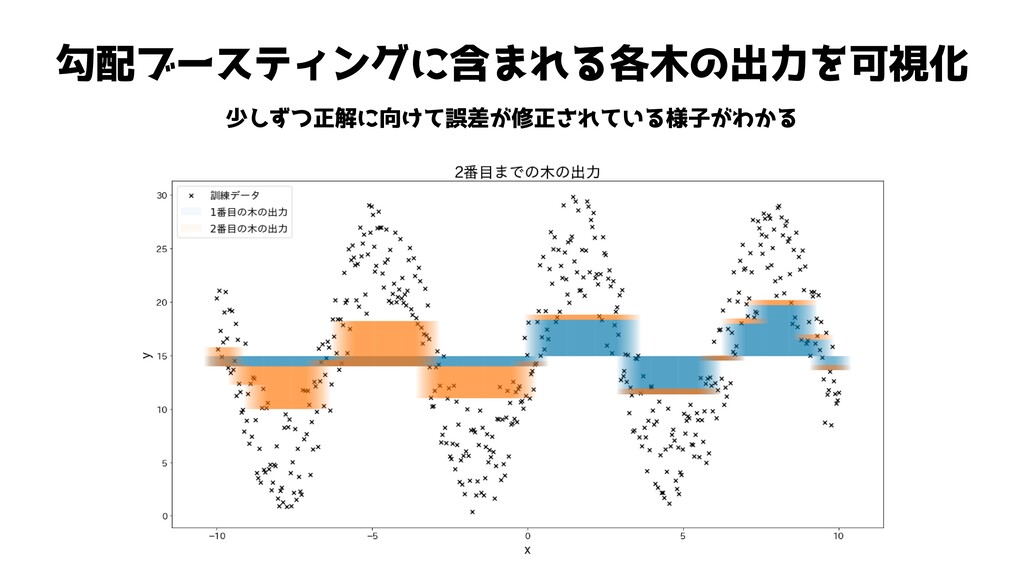
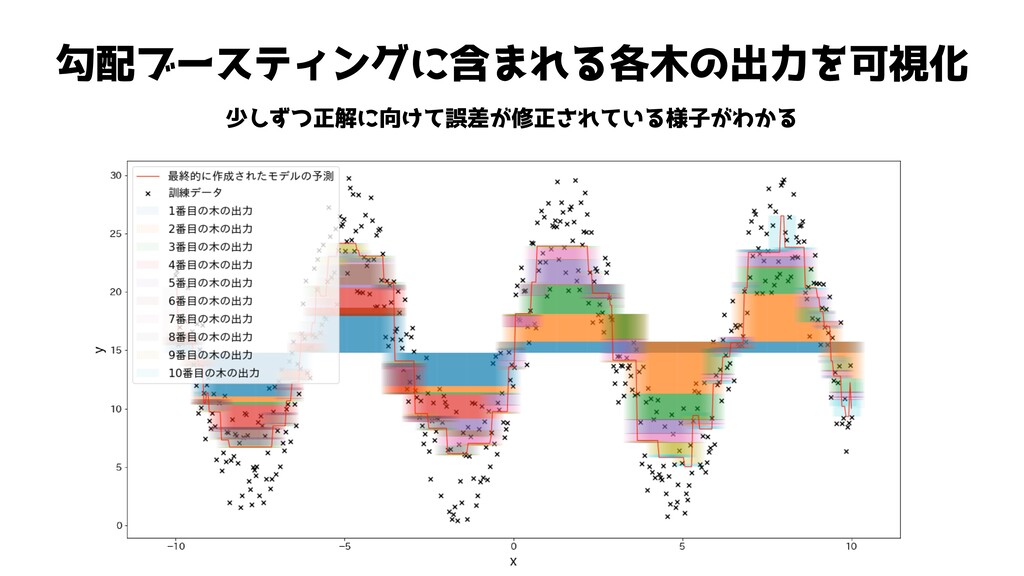
勾配ブースティングに含まれる各木の出力を可視化 少しずつ正解に向けて誤差が修正されている様子がわかる
勾配ブースティングに含まれる各木の出力を可視化 少しずつ正解に向けて誤差が修正されている様子がわかる
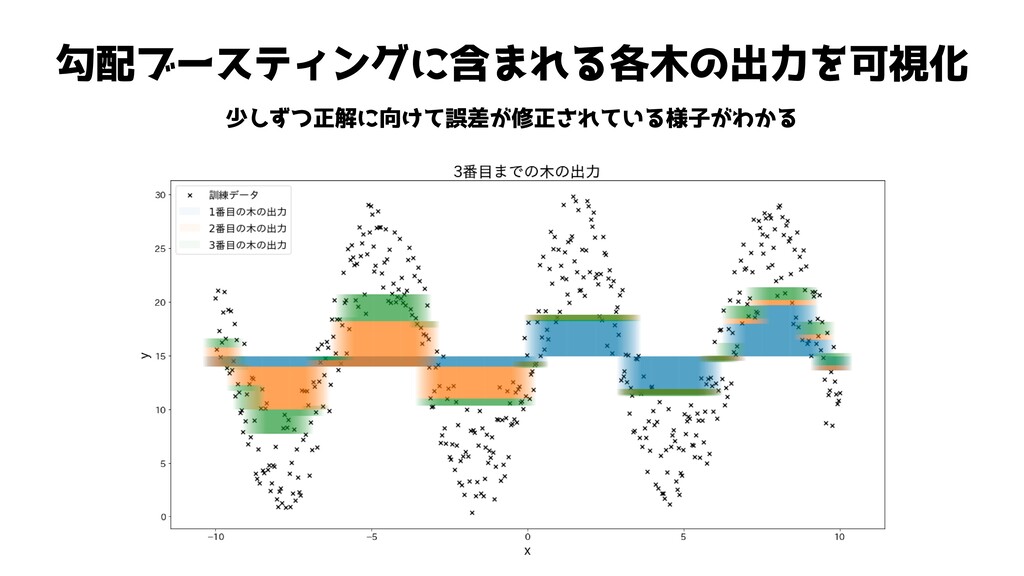
勾配ブースティングに含まれる各木の出力を可視化 少しずつ正解に向けて誤差が修正されている様子がわかる
勾配ブースティングに含まれる各木の出力を可視化 少しずつ正解に向けて誤差が修正されている様子がわかる
各パラメタの影響 え い き ょ う
n_estimators 基本的にはデフォルトの設定で十分によい性能になる 一定の基準を超えると頭打ちになる
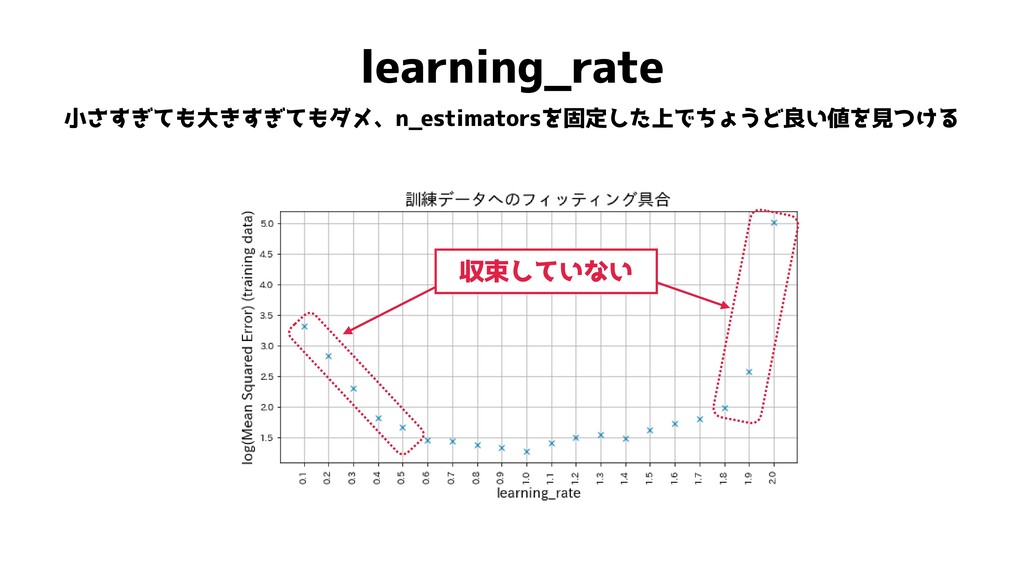
learning_rate 小さすぎても大きすぎてもダメ、n_estimatorsを固定した上でちょうど良い値を見つける 収束していない
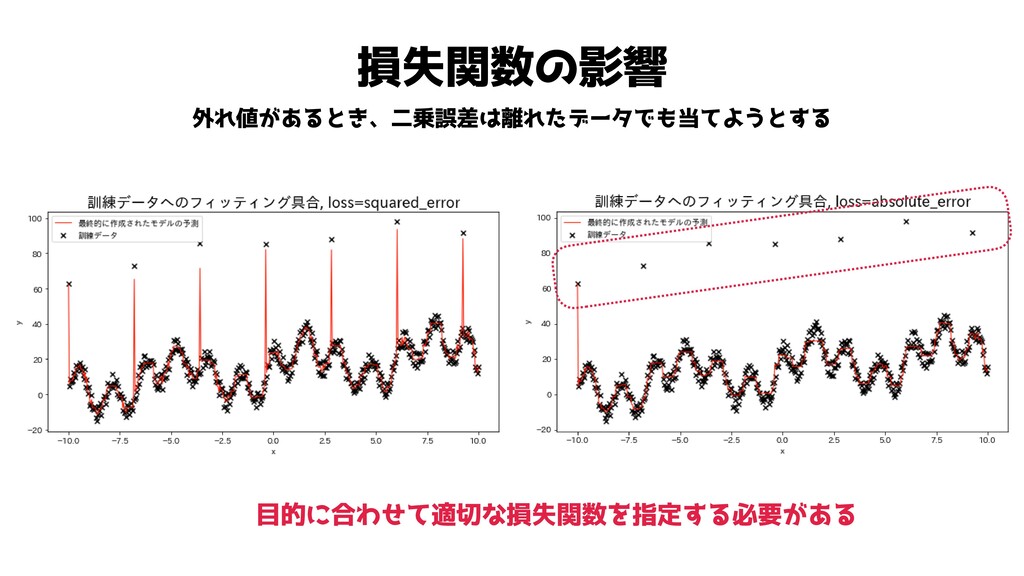
損失関数の影響 外れ値があるとき、二乗誤差は離れたデータでも当てようとする 目的に合わせて適切な損失関数を指定する必要がある
まとめ 勾配ブースティングの仕組みを説明しました •勾配ブースティング木 = 勾配降下法 + ブースティング + 決定木学習 •はじめに決めるべき重要なパラメタは
•n_estimators •loss •パラメタ調整する必要があるのは •max_depth •learning_rate •他、木に関係するパラメタなど
参考文献 •sklearn.tree.DecisionTreeRegressor •1.11. Ensemble methods •https://github.com/scikit-learn/scikit-learn/blob/main/sklearn/ ensemble/_gb_losses.py •Trevor Hastie ・Robert
Tibshirani ・Jerome Friedman 著・杉山 将・井手 剛・ 神嶌 敏弘・栗田 多喜夫・前田 英作監訳・井尻 善久・井手 剛・岩田 具治・金森 敬 文・兼村 厚範・烏山 昌幸・河原 吉伸・木村 昭悟・小西 嘉典・酒井 智弥・鈴木 大 慈・竹内 一郎・玉木 徹・出口 大輔・冨岡 亮太・波部 斉・前田 新一・持橋 大地・山 田 誠訳 ”統計的学習の基礎: データマイニング・推論・予測”. 共立出版, 2014.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}