指定する。 // MapReduce(命令的) db.animals.mapReduce( function map() { if (this.family === "Sharks") emit(this.family, 1); }, function reduce(k, v) { return Array.sum(v); } ); 宣言的(Declarative)— What 「何が欲しいか」だけを伝える。どう取 るかはDBが決める。 -- SQL(宣言的) SELECT family, COUNT(*) FROM animals WHERE family = 'Sharks' GROUP BY family; 同じ結果を、より簡潔に記述できる。 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
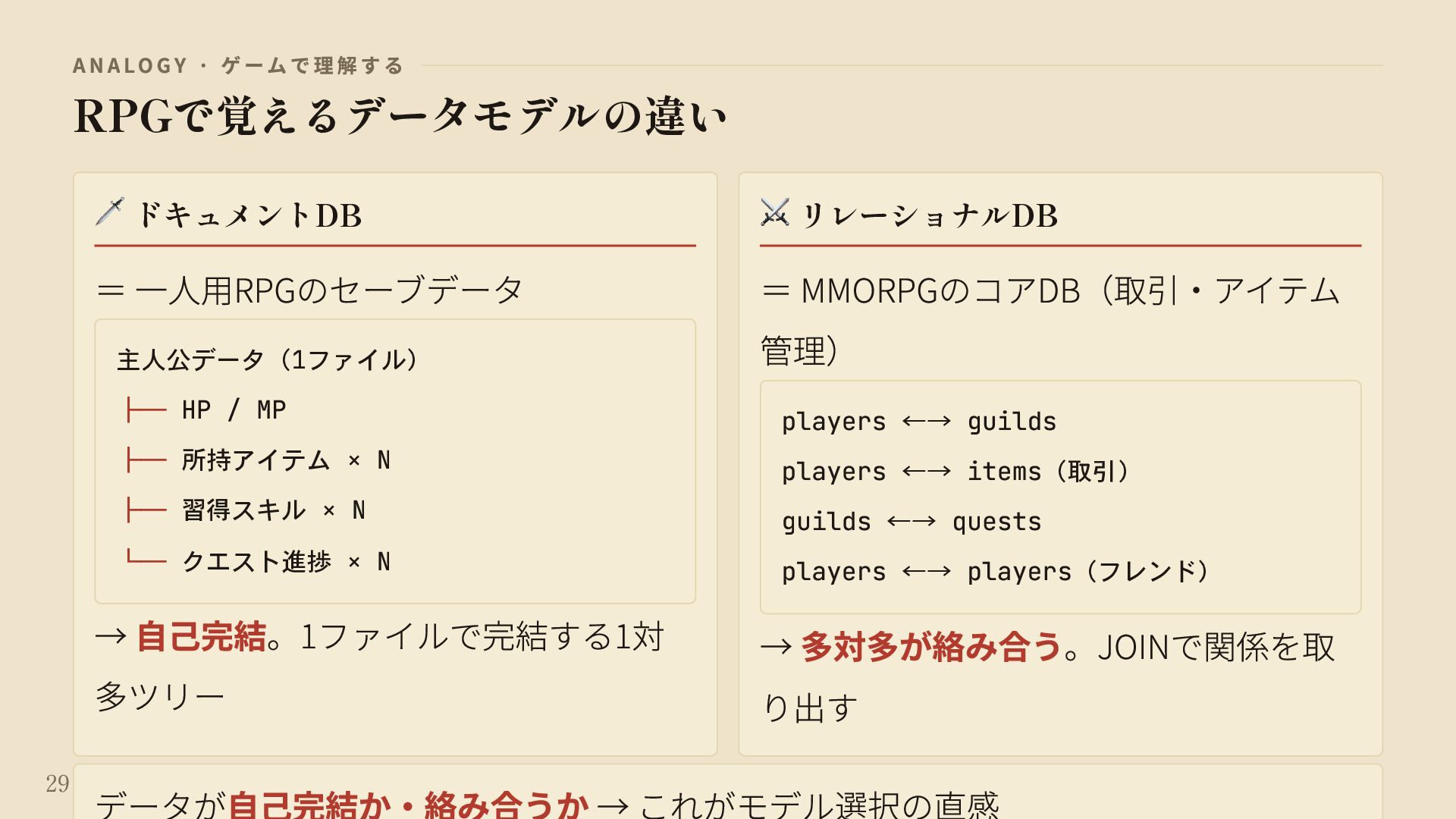{kind=link}
{kind=link}
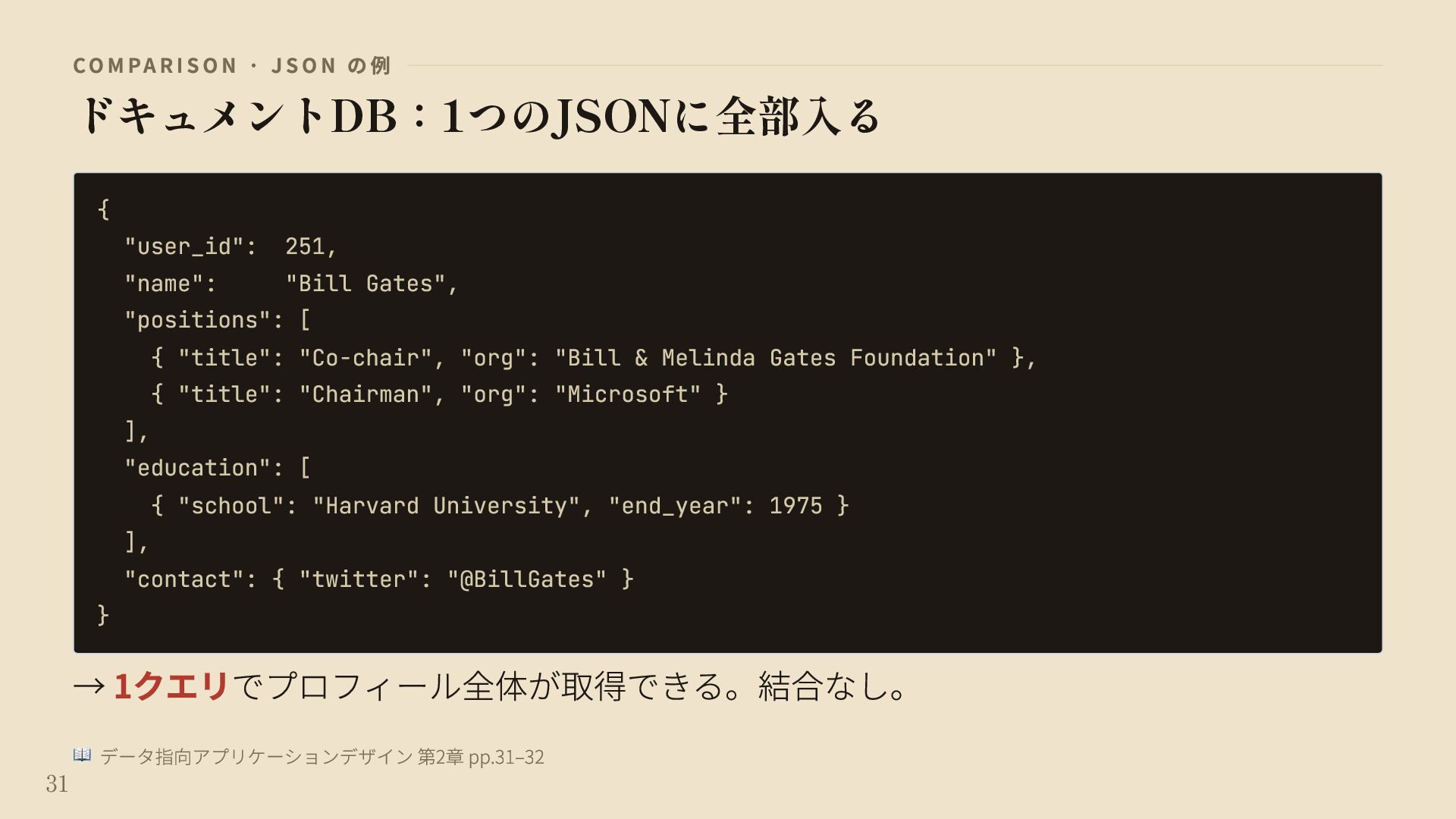{kind=link}
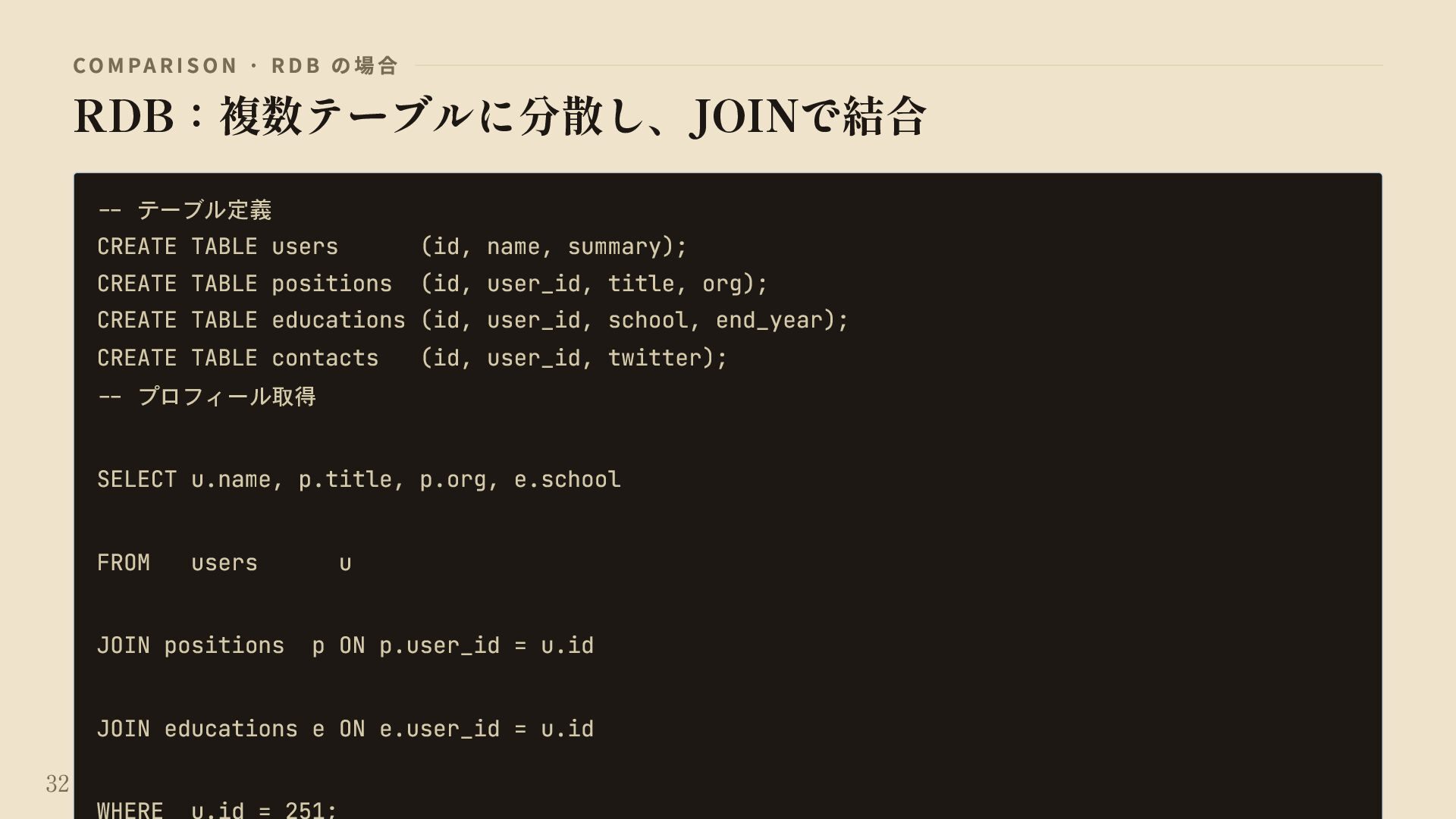{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
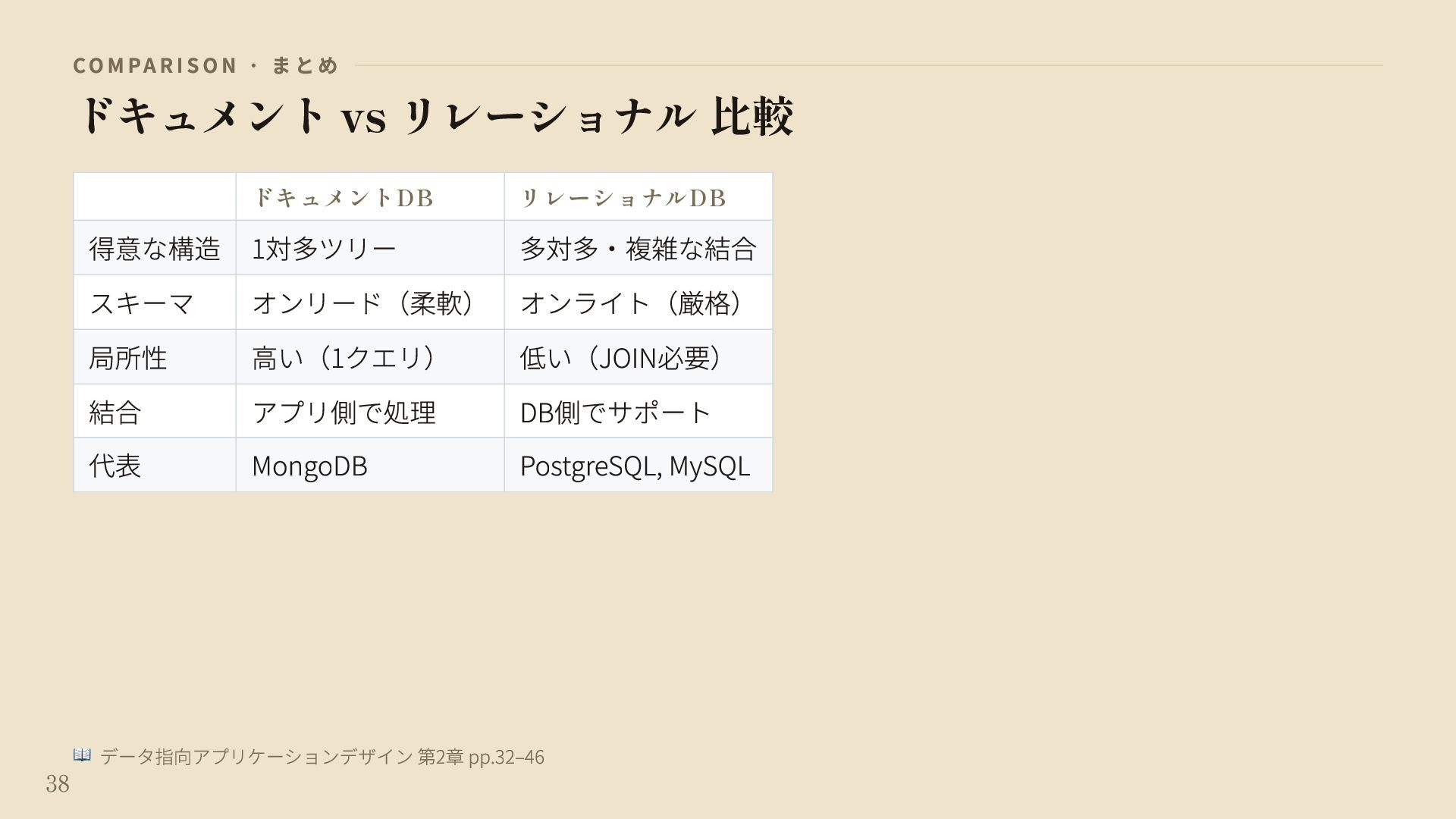{kind=link}
{kind=link}
{kind=link}
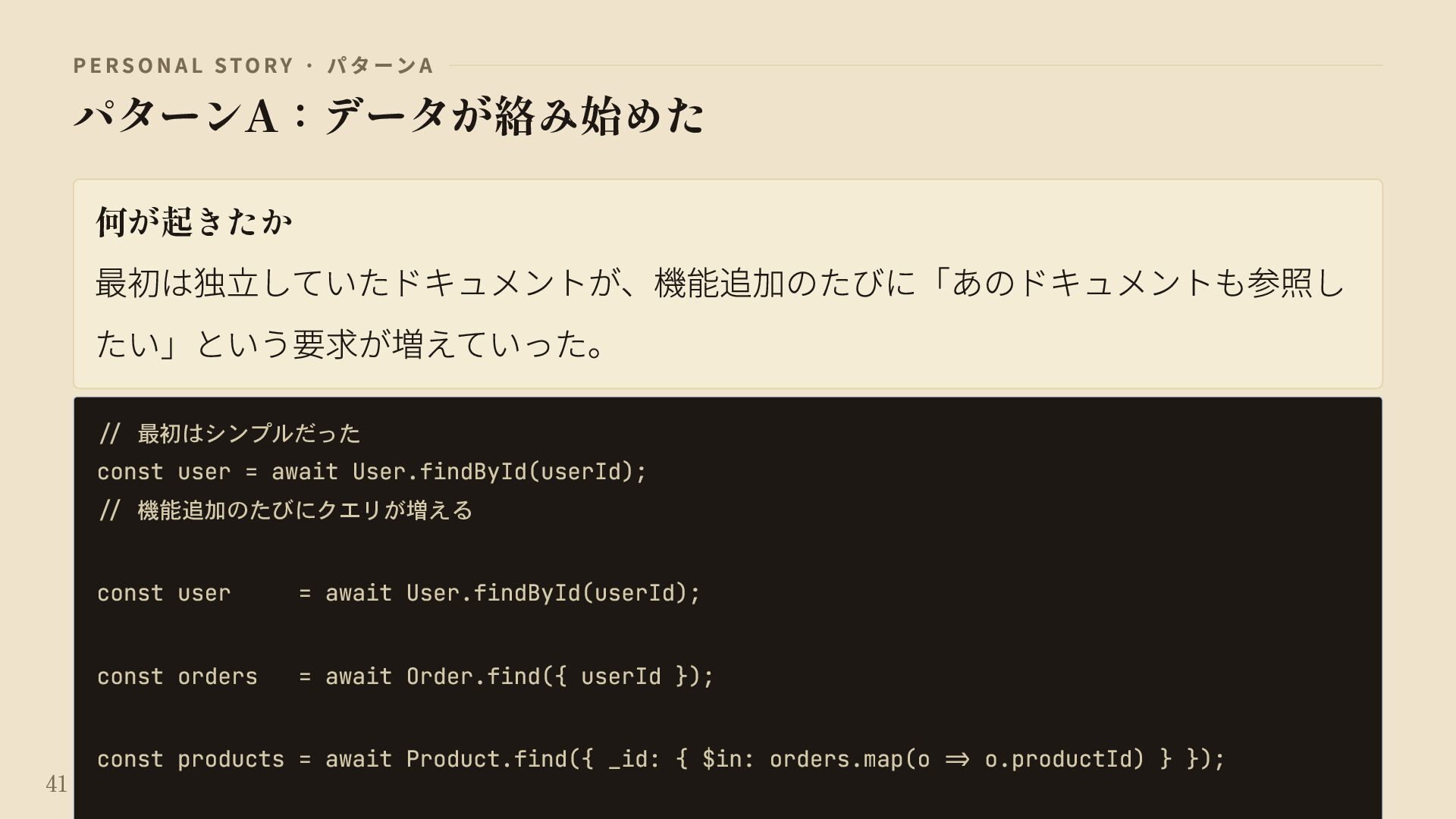{kind=link}
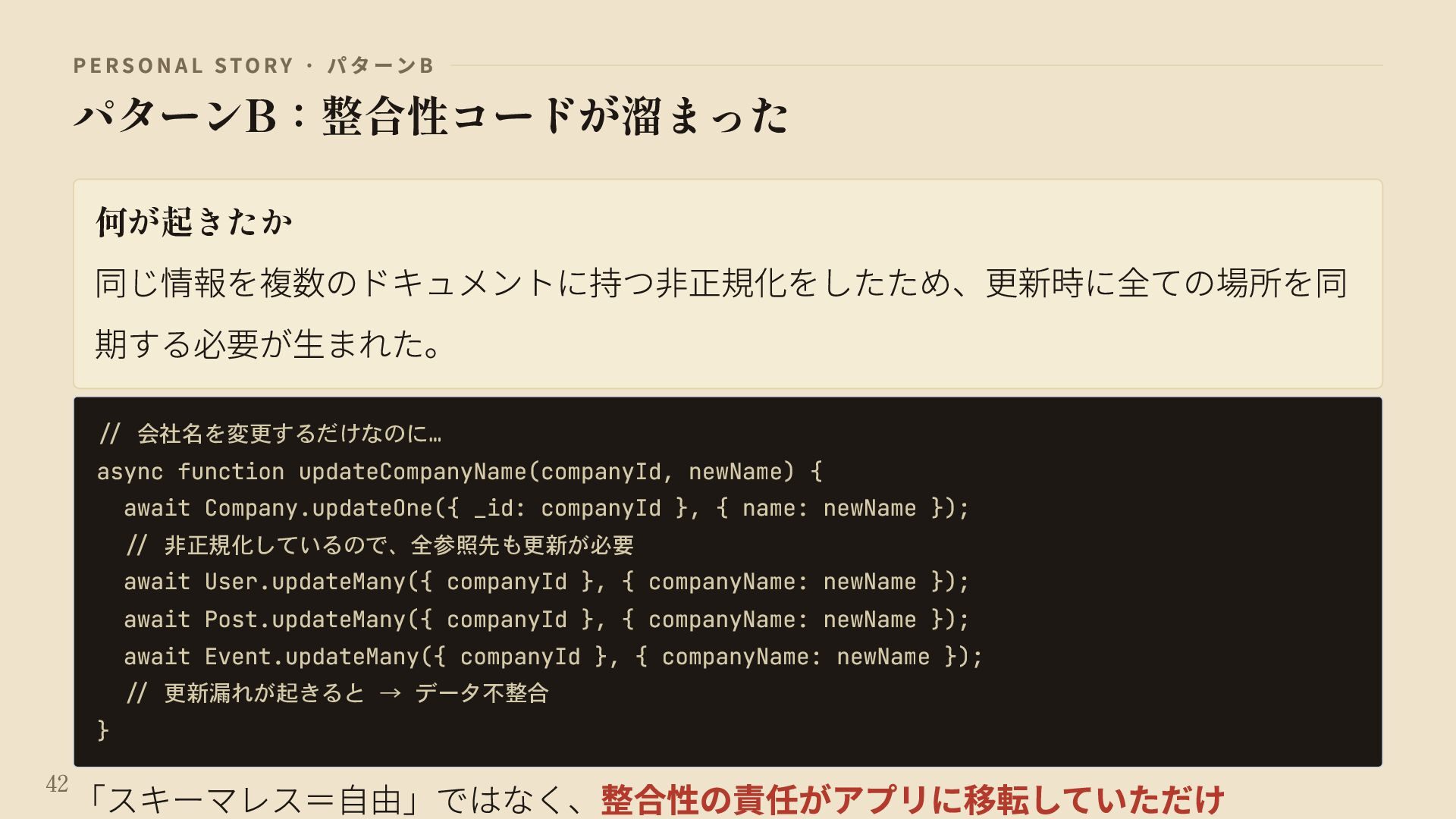{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
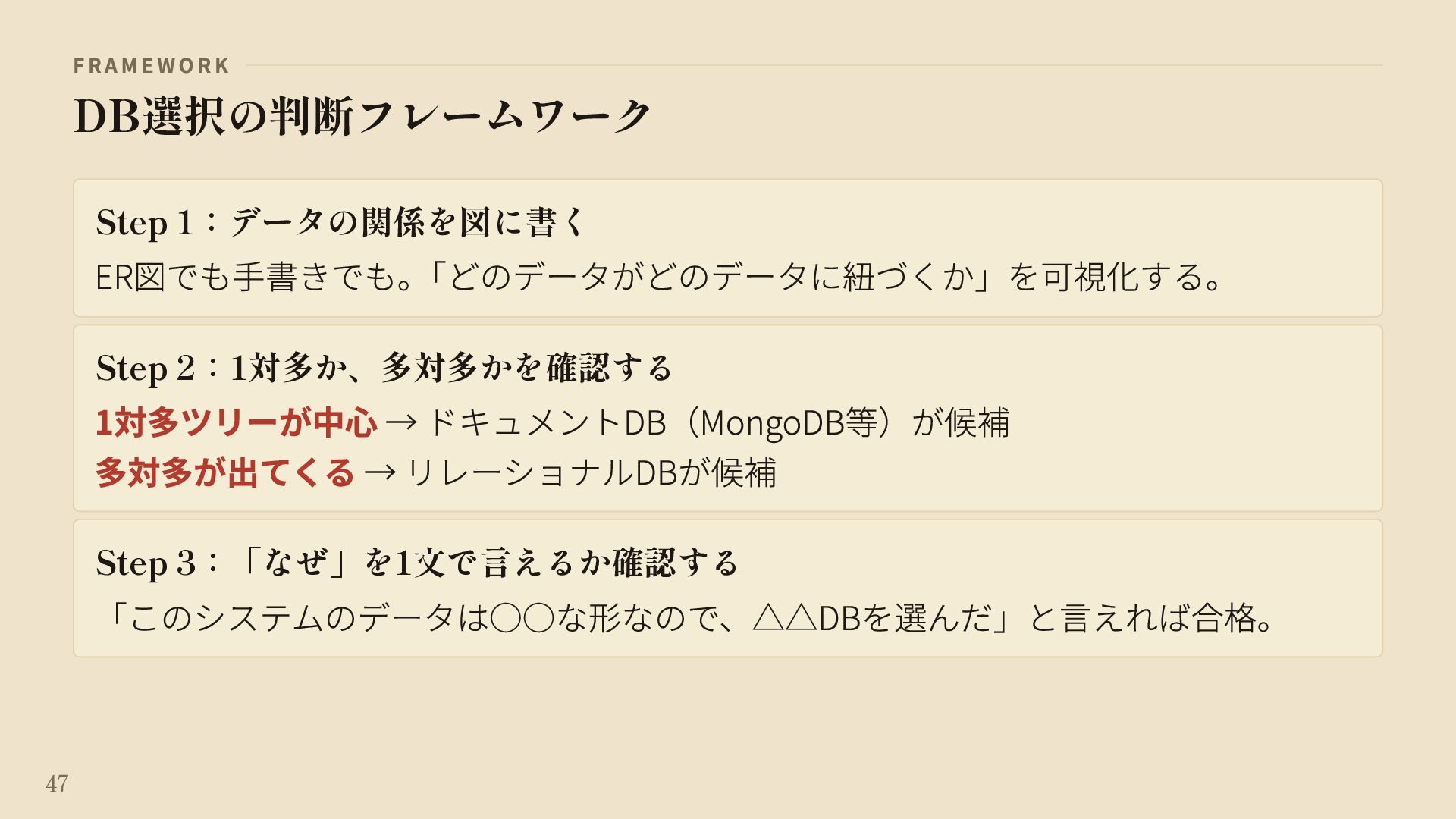{kind=link}
{kind=link}
{kind=link}
{kind=link}
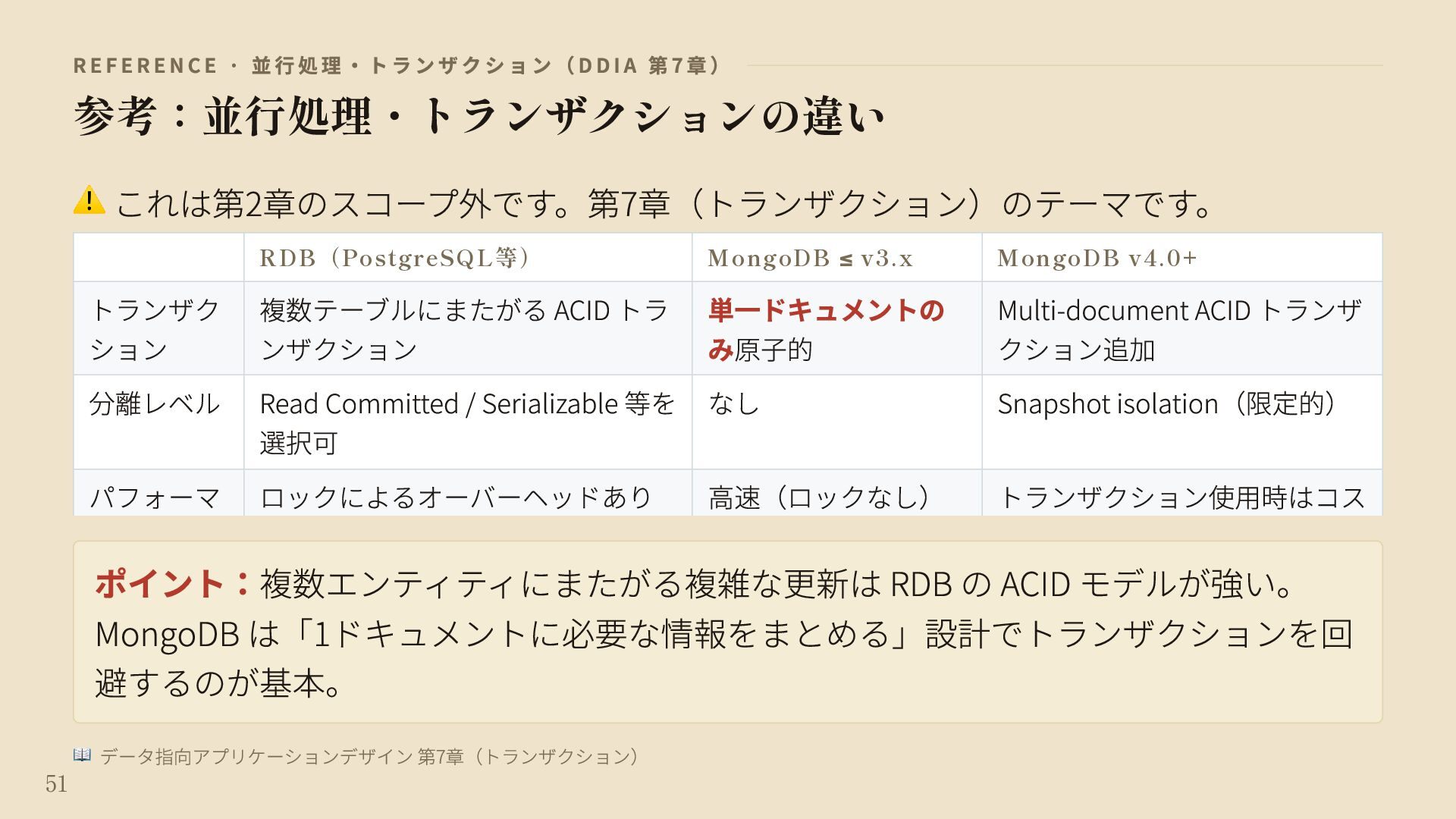{kind=link}
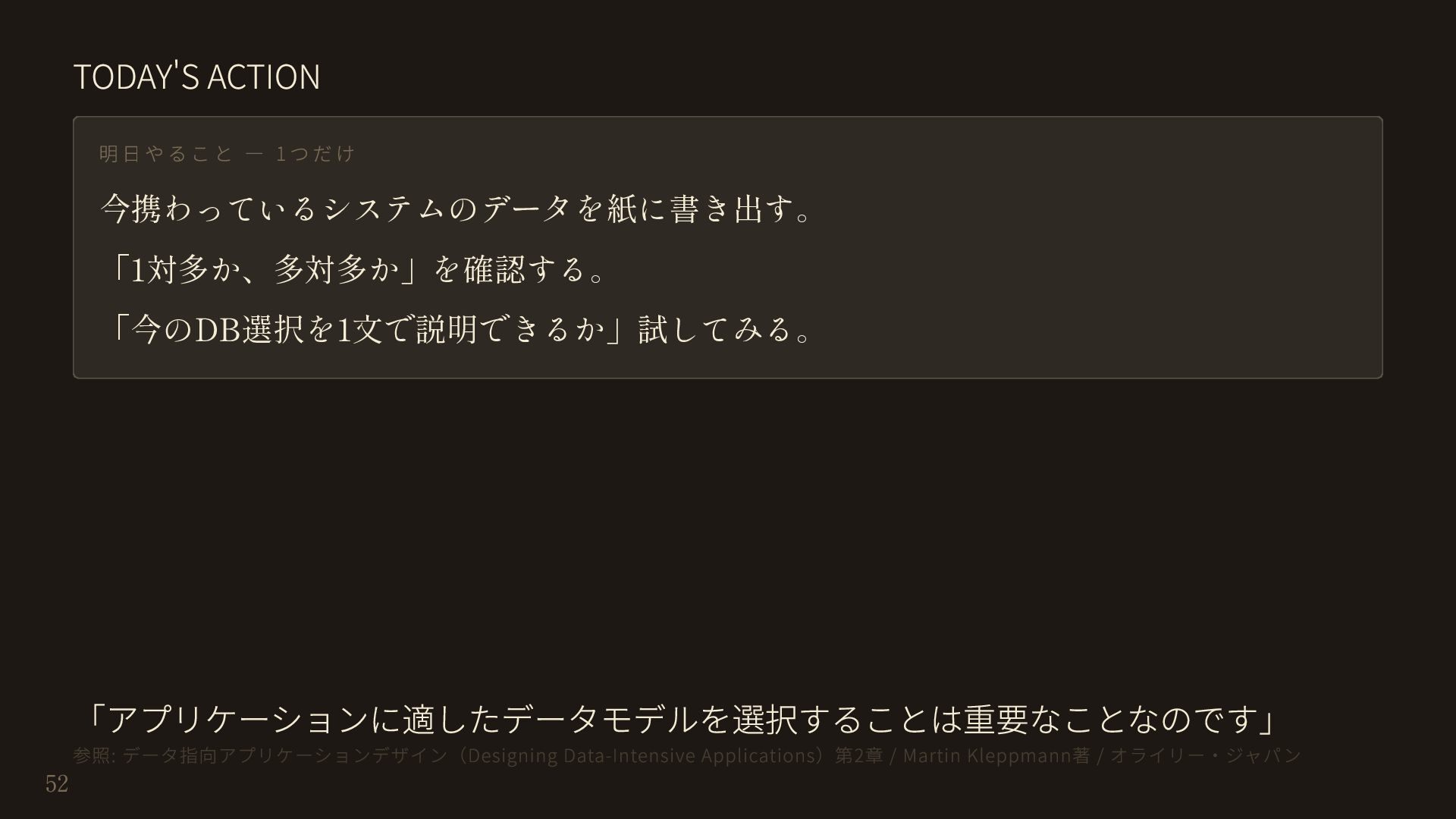{kind=link}