Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ロジスティック回帰の実装
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
kaise
March 30, 2025
Programming
120
0
Share
ロジスティック回帰の実装
線形回帰の知識を前提とし,ロジスティック回帰を実装できるまでの理論,数学,実装方法をまとめた.
kaise
March 30, 2025
More Decks by kaise
See All by kaise
線形回帰の実装
kai_ds04
0
230
Other Decks in Programming
See All in Programming
PHPのバージョンアップ時にも役立ったAST(2026年版)
matsuo_atsushi
0
290
Kubernetes上でAgentを動かすための最新動向と押さえるべき概念まとめ
sotamaki0421
3
440
Java 21/25 Virtual Threads 소개
debop
0
340
How Swift's Type System Guides AI Agents
koher
0
190
PHP で mp3 プレイヤーを実装しよう
m3m0r7
PRO
0
180
KagglerがMixSeekを触ってみた
morim
0
370
飯MCP
yusukebe
0
490
仕様漏れ実装漏れをなくすトレーサビリティAI基盤のご紹介
orgachem
PRO
9
5.1k
今年もTECHSCOREブログを書き続けます!
hiraoku101
0
230
まかせられるPM・まかせられないPM / DevTech GUILD Meetup
yusukemukoyama
0
110
[PHPerKaigi 2026]PHPerKaigi2025の企画CodeGolfが最高すぎて社内で内製して半年運営して得た内製と運営の知見
ikezoemakoto
0
340
AIと共にエンジニアとPMの “二刀流”を実現する
naruogram
0
130
Featured
See All Featured
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
200
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
110
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
55k
Building Applications with DynamoDB
mza
96
7k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
330
Believing is Seeing
oripsolob
1
110
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
710
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
260
Agile that works and the tools we love
rasmusluckow
331
21k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.7k
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
120
Transcript
武蔵野大学データサイエンス学科 B3 高橋快成 Github: Takahashi-Kaisei X:@kai_ds04 ロジスティック回帰の実装 ~ scikit-learnを0から作ろうProject 第8回勉強会(2024/12/13)~
最終更新(2025/3/30)
目次 • はじめに • ロジスティック回帰の気持ち • ロジスティック回帰の理論 • 実装 •
付録 2024/12/13 2
目次 • はじめに • ロジスティック回帰とは • 前提知識 • ロジスティック回帰の気持ち •
ロジスティック回帰の理論 • 実装 • 付録 2024/12/13 3 はじめに
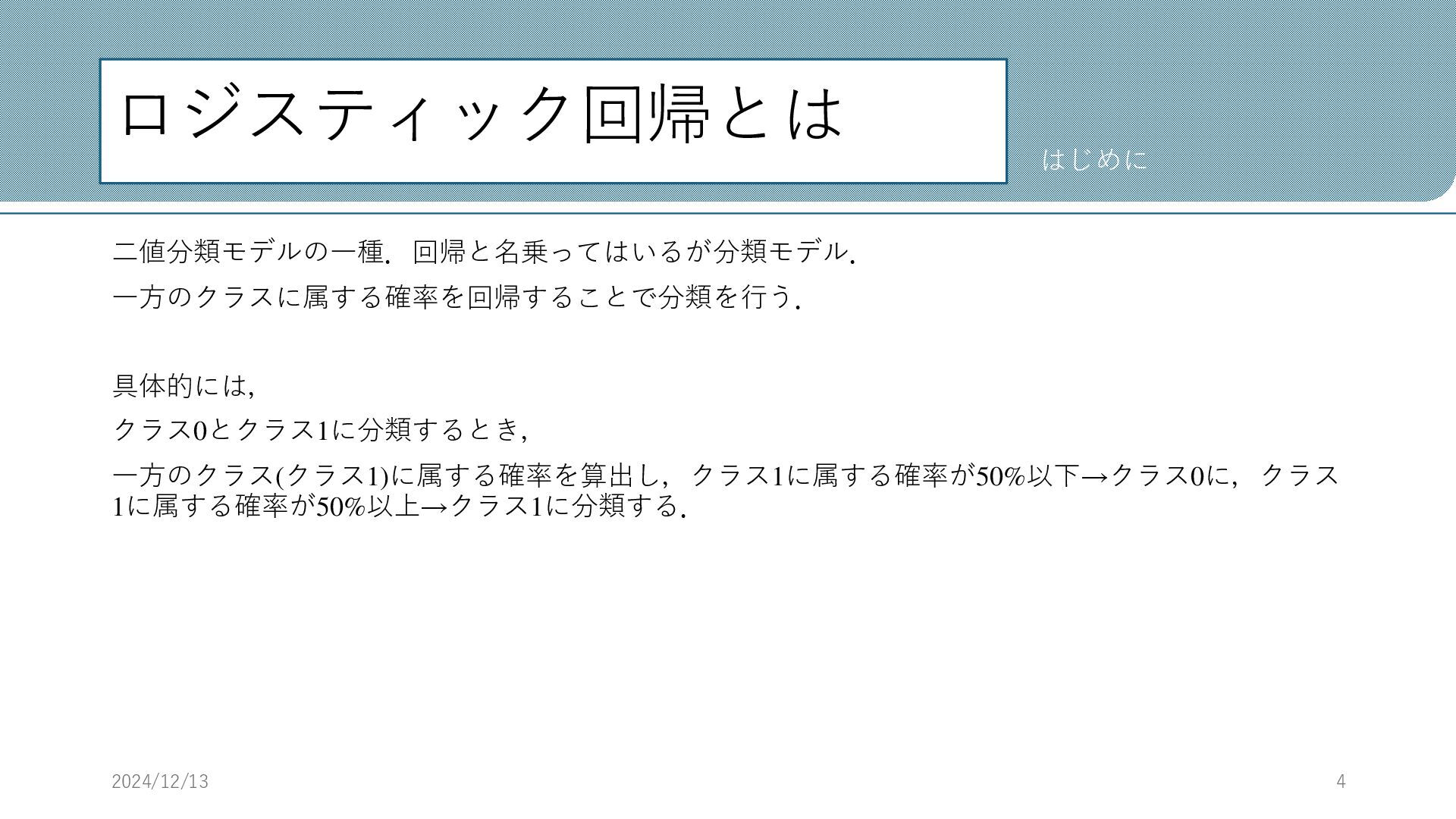
ロジスティック回帰とは 二値分類モデルの一種.回帰と名乗ってはいるが分類モデル. 一方のクラスに属する確率を回帰することで分類を行う. 具体的には, クラス0とクラス1に分類するとき, 一方のクラス(クラス1)に属する確率を算出し,クラス1に属する確率が50%以下→クラス0に,クラス 1に属する確率が50%以上→クラス1に分類する. 2024/12/13 4 はじめに
前提知識 ロジスティック回帰を学ぶにあたり,前提知識となる線形回帰について復習する. 線形回帰(単回帰,重回帰): 1つ,または複数の説明変数から,1つの連続値を予測するモデル. m:次元数 x∈ ℝ𝑚:説明変数 y∈ ℝ:目的変数 w∈
ℝ𝑚:パラメータ 2024/12/13 5 はじめに ො 𝑦 = 𝒘𝑇𝒙
前提知識 ො 𝑦 = 𝒘𝑇𝒙は何者だろうか. それにあたり,単回帰を確認する. それはただの一次関数. b:バイアス項 2024/12/13 6
はじめに ො 𝑦 = 𝑤𝑥 + 𝑏
前提知識 線 形 回 帰 の 実 装 では,重回帰だとどうなるのか. それは単回帰をひたすら足すような式になる.
これを,内積を使って整理すると以下のようになる. この資料では, 𝒘𝑇𝒙をよく使う. 詳しくは線形回帰の実装 2024/12/13 7 はじめに ො 𝑦 = 𝑤0 𝑥0 +𝑤1 𝑥1 +𝑤2 𝑥2 + ⋯ + 𝑤𝑚 𝑥𝑚 ※ 𝑥0 =1 ො 𝑦 = 𝑖=0 𝑚 𝑤𝑖 𝑥𝑖 = 𝒘𝑇𝒙
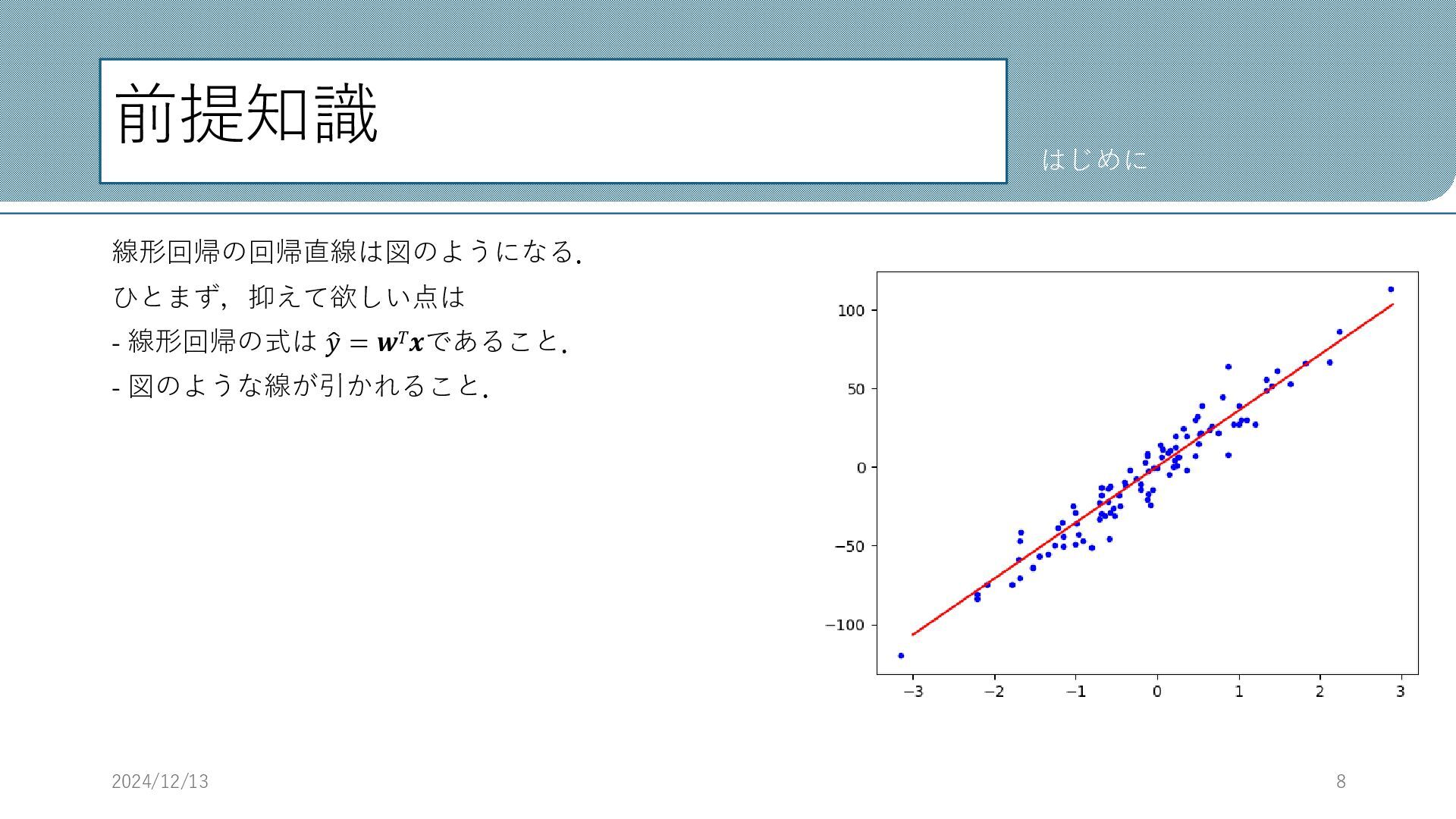
前提知識 線形回帰の回帰直線は図のようになる. ひとまず,抑えて欲しい点は - 線形回帰の式は ො 𝑦 = 𝒘𝑇𝒙であること. -
図のような線が引かれること. 2024/12/13 8 はじめに
前提知識 ロジスティック回帰と線形回帰の違い ロジスティック回帰は,一方のクラスに属する確率を回帰する. 確率を回帰するという点が線形回帰との大きな違いである. (逆に言えば,線形回帰は,確率を回帰していない.) 2024/12/13 9 はじめに
目次 • はじめに • ロジスティック回帰の気持ち • 線形回帰の対象のデータ • ロジスティック回帰の対象のデータ •
シグモイド関数に線形回帰を適用 • パラメータの最適化 • ロジスティック回帰の理論 • 実装 • 付録 2024/12/13 10 ロジスティック回帰の気持ち
ロジスティック回帰の気持ち 線形回帰→ロジスティック回帰への一連の流れを,数式なしで図で理解する. 基盤となる線形回帰が,ロジスティック回帰とどう関わっているのか. ロジスティック回帰はどのように作られているのか. 目標 ロジスティック回帰の気持ちを汲み取ること!!! 2024/12/13 11 ロジスティック回帰の気持ち
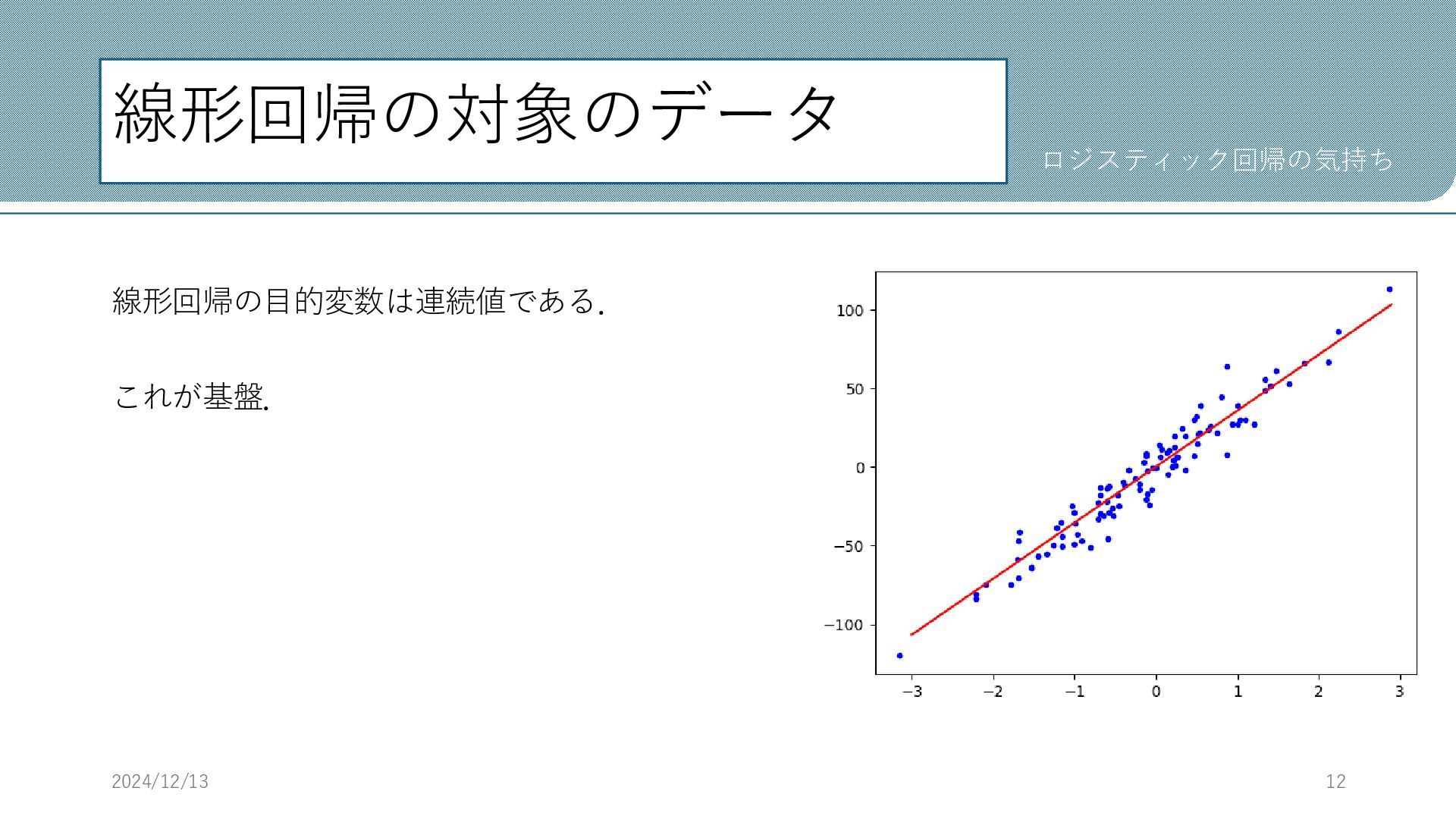
線形回帰の対象のデータ 線形回帰の目的変数は連続値である. これが基盤. 2024/12/13 12 ロジスティック回帰の気持ち
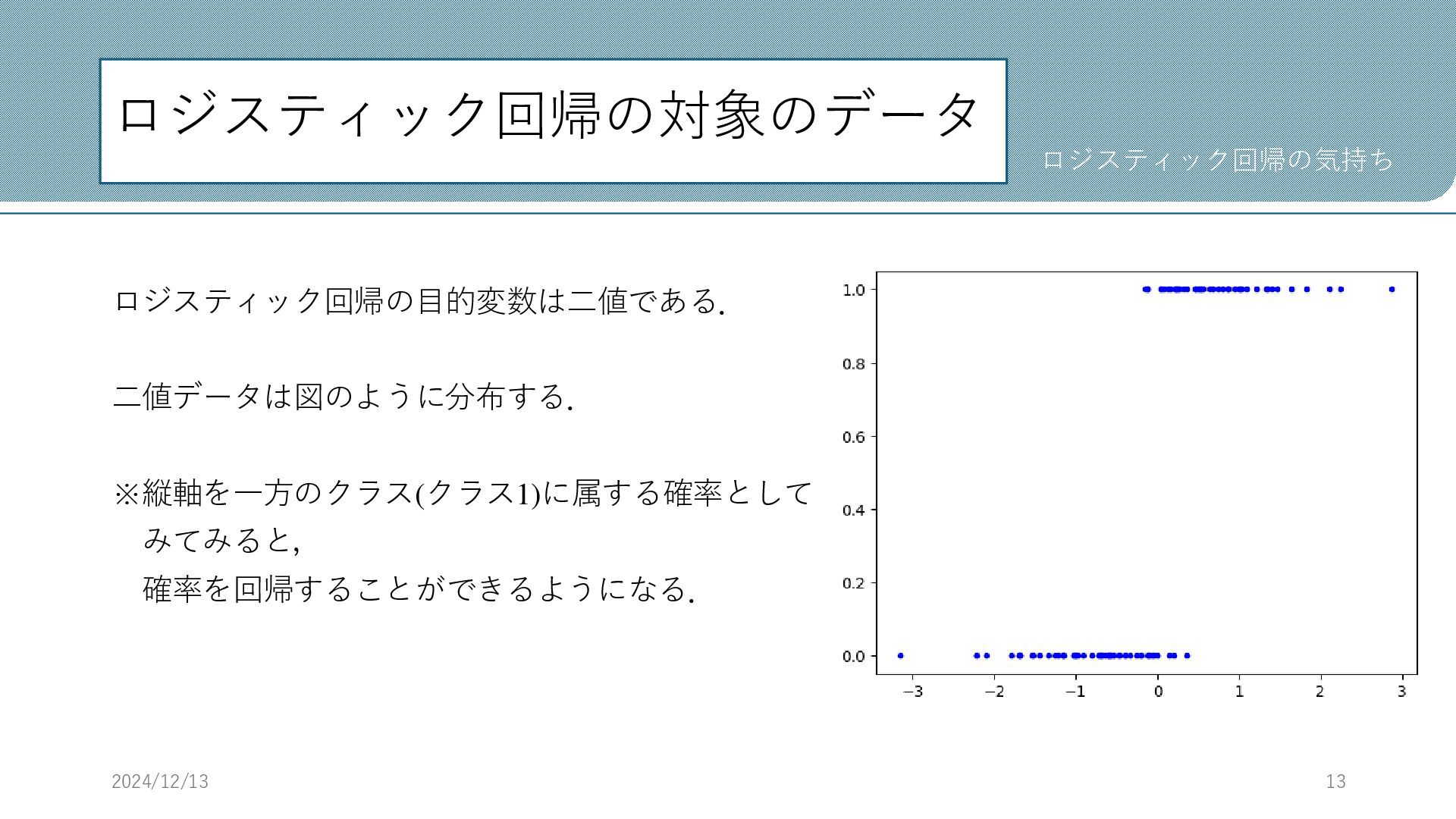
ロジスティック回帰の対象のデータ ロジスティック回帰の目的変数は二値である. 二値データは図のように分布する. ※縦軸を一方のクラス(クラス1)に属する確率として みてみると, 確率を回帰することができるようになる. 2024/12/13 13 ロジスティック回帰の気持ち
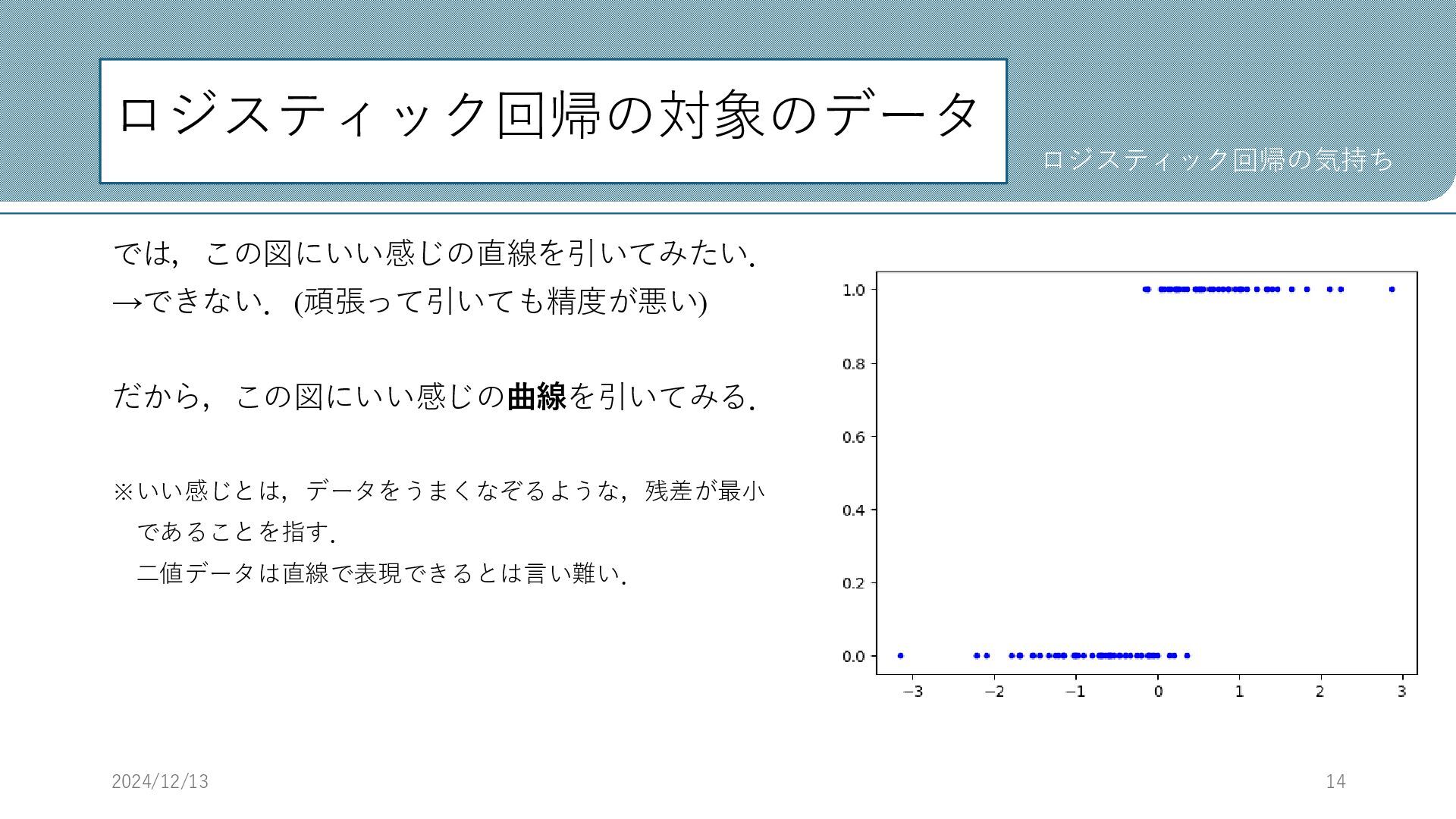
ロジスティック回帰の対象のデータ では,この図にいい感じの直線を引いてみたい. →できない.(頑張って引いても精度が悪い) だから,この図にいい感じの曲線を引いてみる. ※いい感じとは,データをうまくなぞるような,残差が最小 であることを指す. 二値データは直線で表現できるとは言い難い. 2024/12/13 14 ロジスティック回帰の気持ち
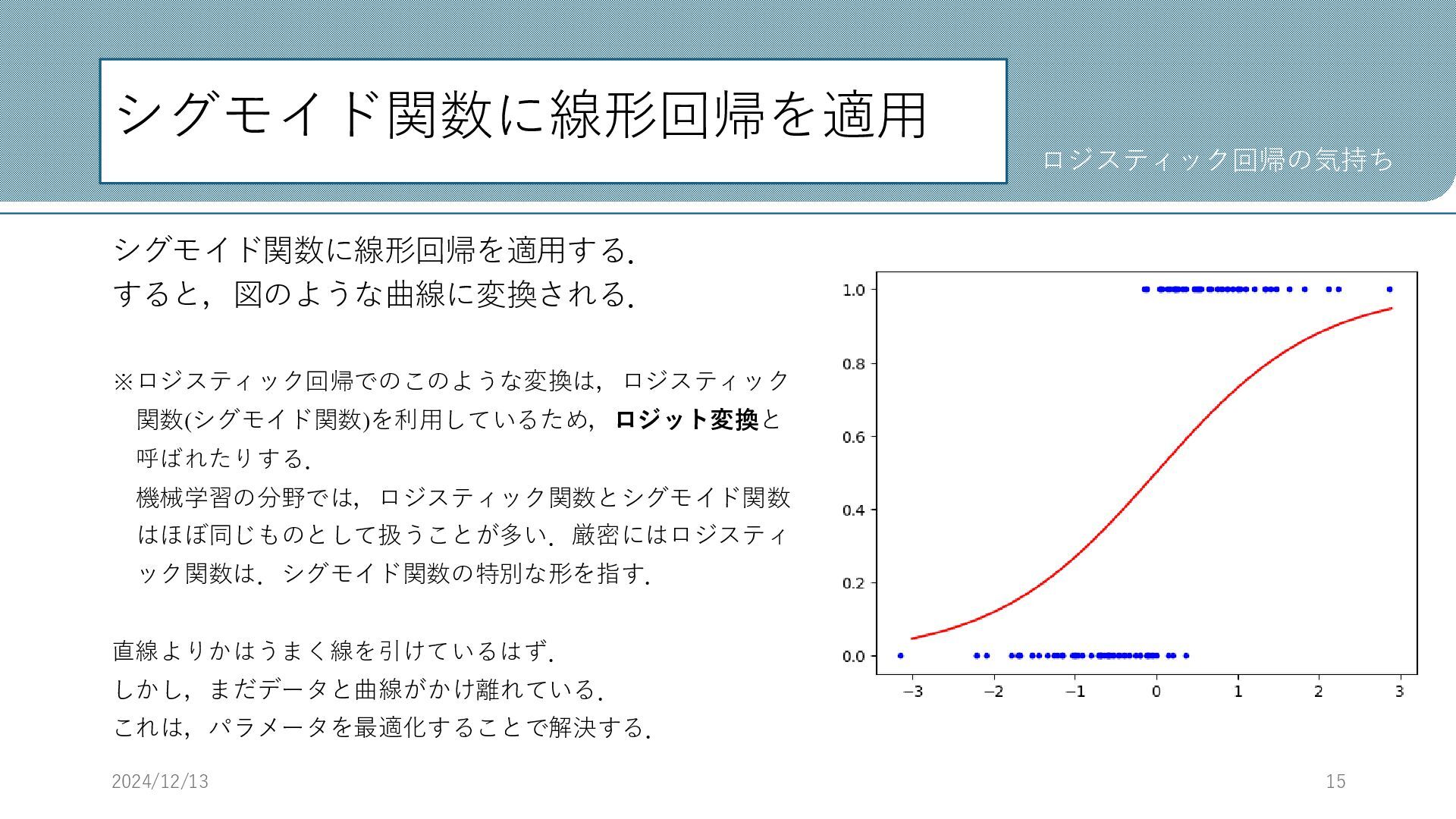
シグモイド関数に線形回帰を適用 シグモイド関数に線形回帰を適用する. すると,図のような曲線に変換される. ※ロジスティック回帰でのこのような変換は,ロジスティック 関数(シグモイド関数)を利用しているため,ロジット変換と 呼ばれたりする. 機械学習の分野では,ロジスティック関数とシグモイド関数 はほぼ同じものとして扱うことが多い.厳密にはロジスティ ック関数は.シグモイド関数の特別な形を指す. 直線よりかはうまく線を引けているはず.
しかし,まだデータと曲線がかけ離れている. これは,パラメータを最適化することで解決する. 2024/12/13 15 ロジスティック回帰の気持ち
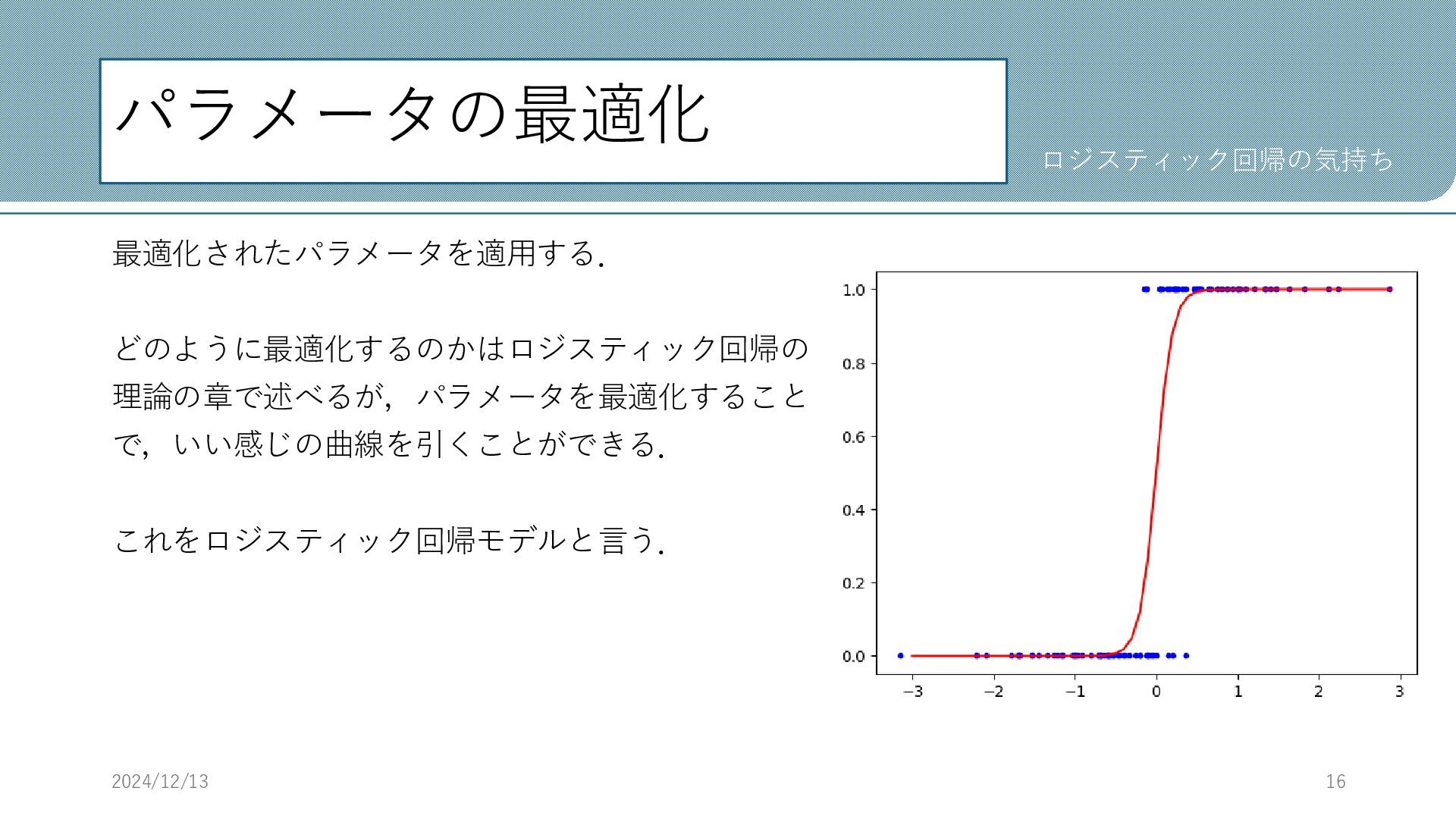
パラメータの最適化 最適化されたパラメータを適用する. どのように最適化するのかはロジスティック回帰の 理論の章で述べるが,パラメータを最適化すること で,いい感じの曲線を引くことができる. これをロジスティック回帰モデルと言う. 2024/12/13 16 ロジスティック回帰の気持ち
まとめ • 線形回帰の目的変数を確認した. • 二値分類の目的変数を確認した. • シグモイド関数に線形回帰を適用した. • パラメータを最適化した. 2024/12/13
17 ロジスティック回帰の気持ち
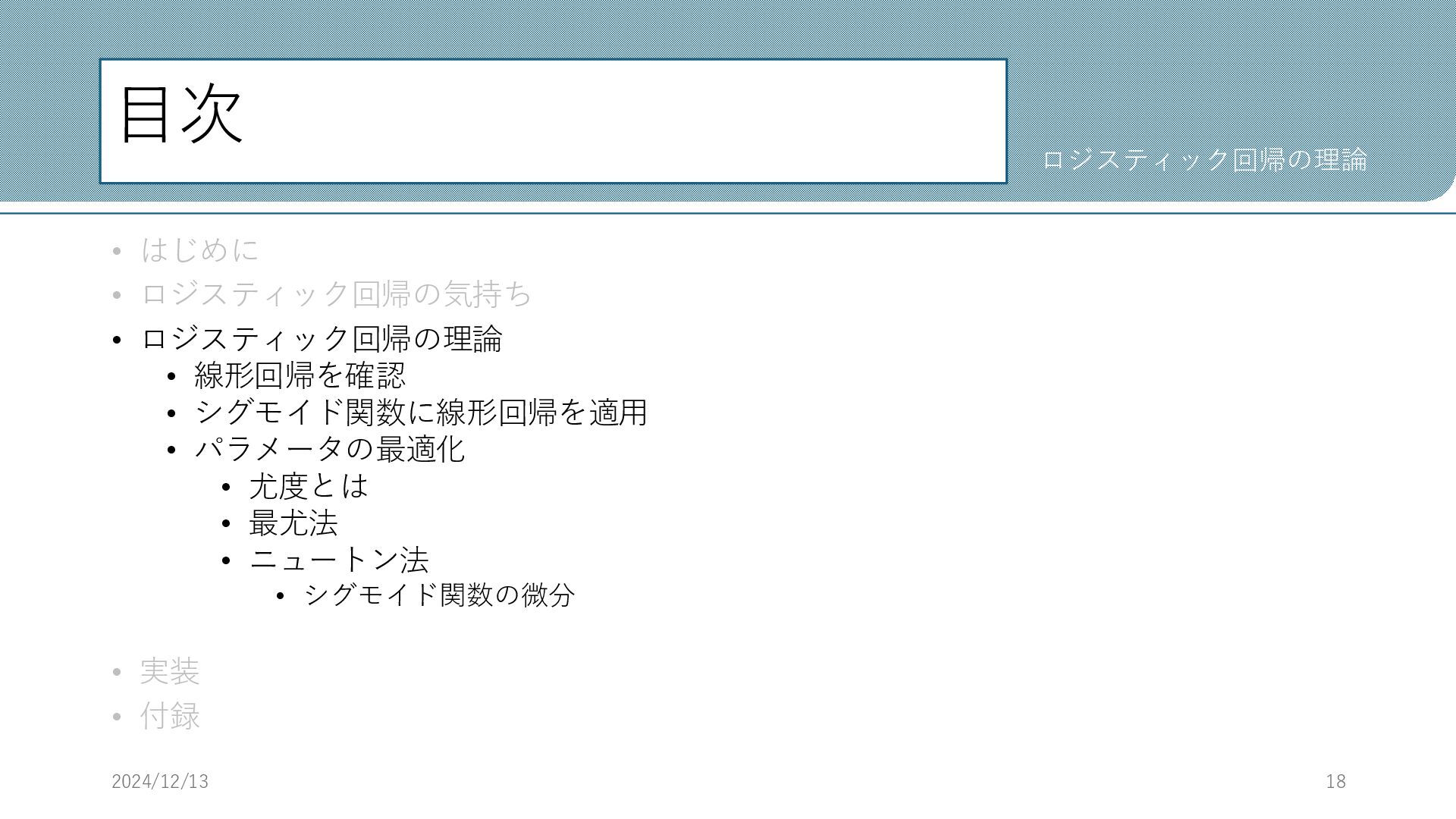
目次 • はじめに • ロジスティック回帰の気持ち • ロジスティック回帰の理論 • 線形回帰を確認 •
シグモイド関数に線形回帰を適用 • パラメータの最適化 • 尤度とは • 最尤法 • ニュートン法 • シグモイド関数の微分 • 実装 • 付録 2024/12/13 18 ロジスティック回帰の理論
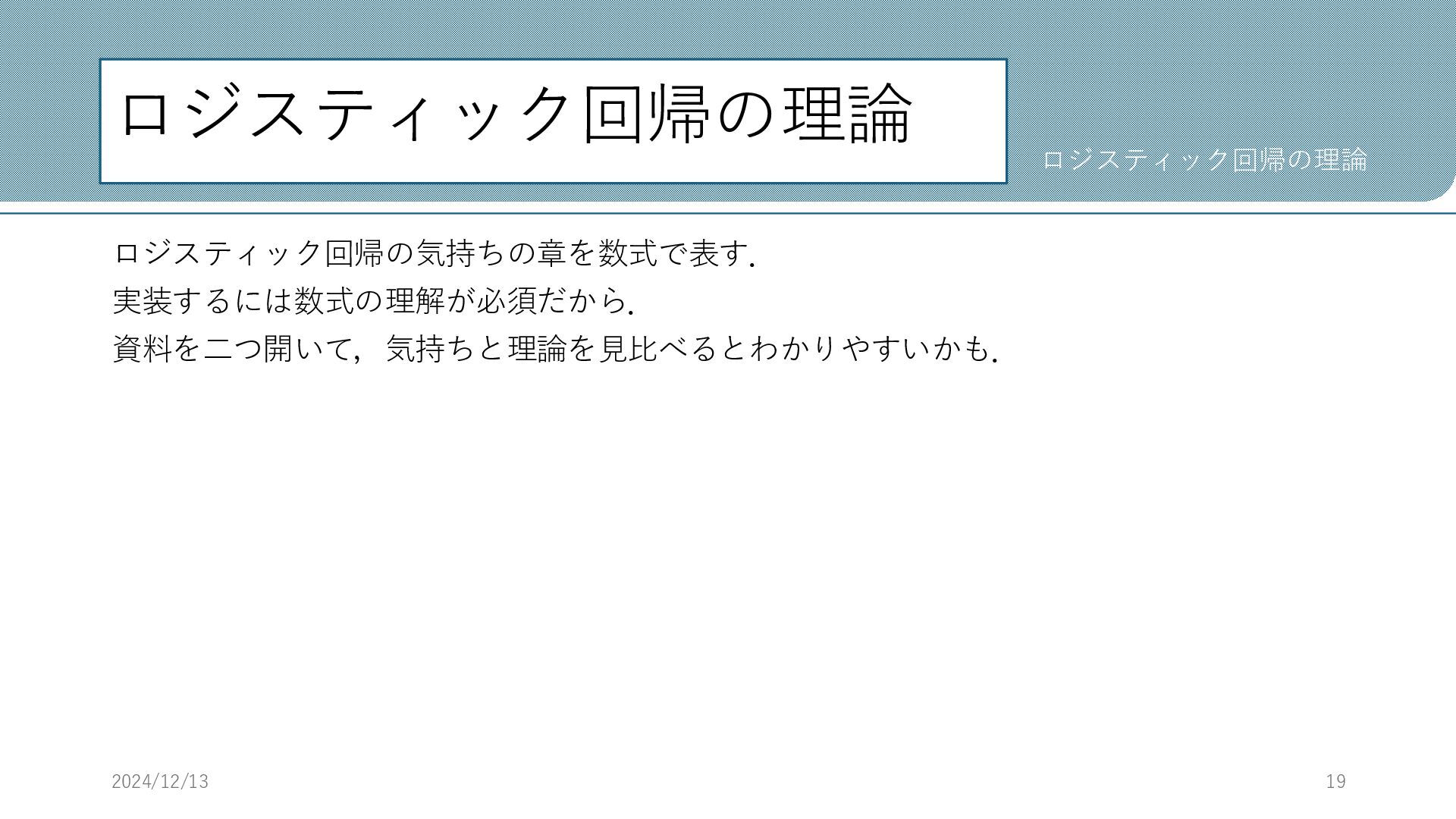
ロジスティック回帰の理論 ロジスティック回帰の気持ちの章を数式で表す. 実装するには数式の理解が必須だから. 資料を二つ開いて,気持ちと理論を見比べるとわかりやすいかも. 2024/12/13 19 ロジスティック回帰の理論
線形回帰を確認 まず,ロジスティック回帰の基盤となる,線形回帰の式を用意する. ※ 今回はバイアス項なしで実装するので,暗黙的に𝒘𝑇𝒙 = 𝑤1 𝑥1+𝑤2 𝑥2 + ⋯
+ 𝑤𝑚 𝑥𝑚 となっている. m:次元数 x∈ ℝ𝑚:説明変数 y∈ ℝ:目的変数 w∈ ℝ𝑚:パラメータ 2024/12/13 20 ロジスティック回帰の理論 ො 𝑦 = 𝒘𝑇𝒙
シグモイド関数に線形回帰を適用 シグモイド関数は以下 このシグモイド関数に線形回帰を適用する. 2024/12/13 21 ロジスティック回帰の理論 𝜎(𝑥) = 1 1
+ 𝑒−𝑥 ො 𝑦 = 𝜎(𝒘𝑇𝒙) = 1 1 + 𝑒−𝒘𝑇𝒙
パラメータの最適化 次に,最適なパラメータを求める.パラメータを最適化すると,いい感じの曲線が引ける. パラメータを最適化するために,パラメータの最適度合いを定量化する必要がある . 尤度が最大になるようなパラメータを,最適なパラメータとする. すなわち,最適度合いを尤度で表すということ. でもそういえば… 線形回帰では,パラメータの最適度合いを二乗和誤差という損失関数で表していた. すなわち,二乗和誤差を最小化するという方針で定量化できた. だから,ロジスティック回帰でも二乗和誤差を使用するのかというと,そうではない.
尤度を最大化するという方針で定量化する. 2024/12/13 22 ロジスティック回帰の理論
パラメータの最適化 表にするとこう では,この二つは違うのか? →背景にある気持ちは同じ.どちらも「尤度を最大にしたい」という背景がある. だから本当はこう 線形回帰は尤度を最大化する過程で 二乗和誤差が出てきただけ. 尤度を次のスライドで説明する. 2024/12/13 23
ロジスティック回帰の理論 モデル 最適度合いの関数 方針 線形回帰 二乗和誤差 最小化 ロジスティック回帰 尤度 最大化 モデル 最適度合いの関数 方針 線形回帰 尤度 最大化 ロジスティック回帰 尤度 最大化
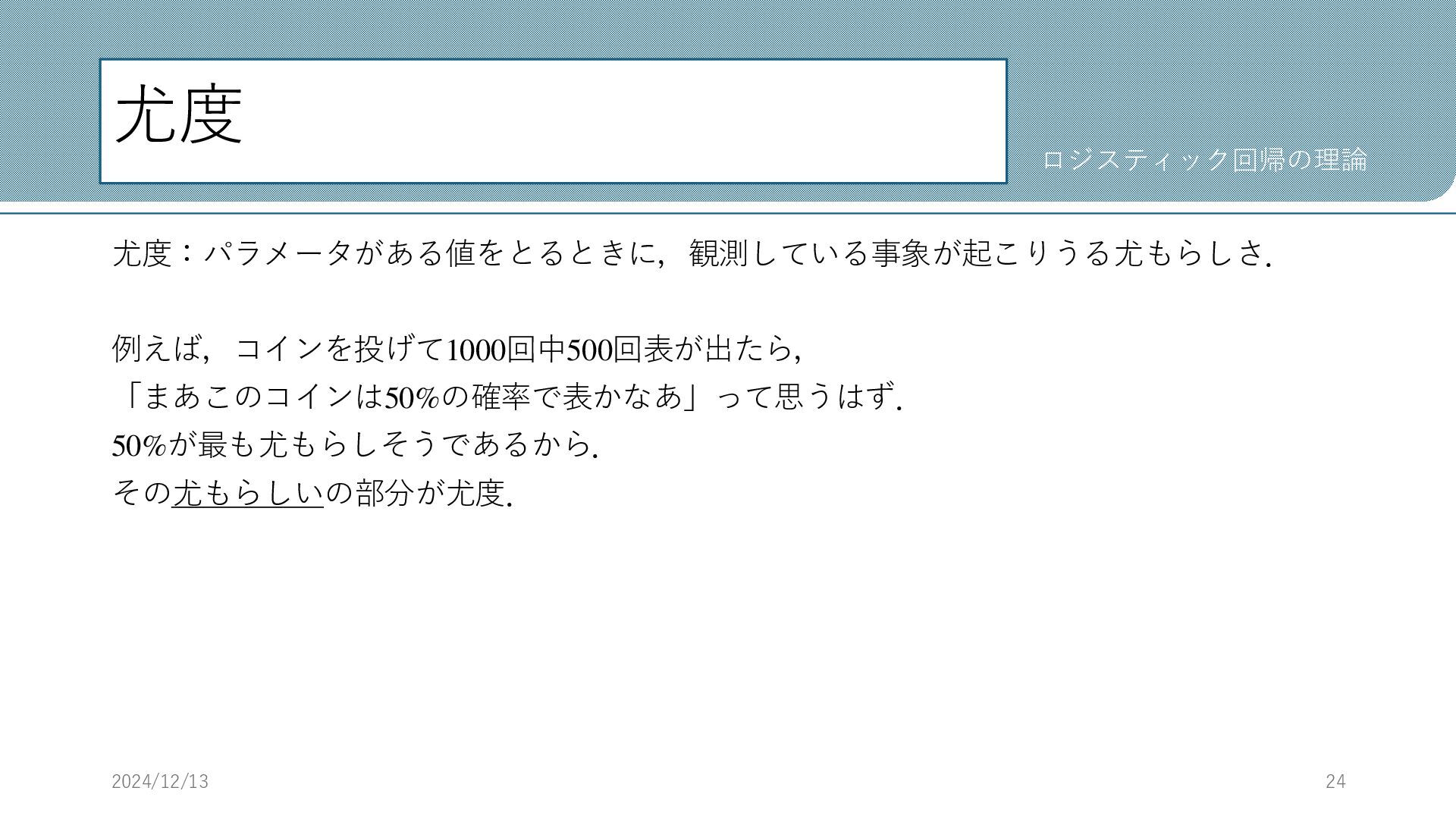
尤度 尤度:パラメータがある値をとるときに,観測している事象が起こりうる尤もらしさ. 例えば,コインを投げて1000回中500回表が出たら, 「まあこのコインは50%の確率で表かなあ」って思うはず. 50%が最も尤もらしそうであるから. その尤もらしいの部分が尤度. 2024/12/13 24 ロジスティック回帰の理論
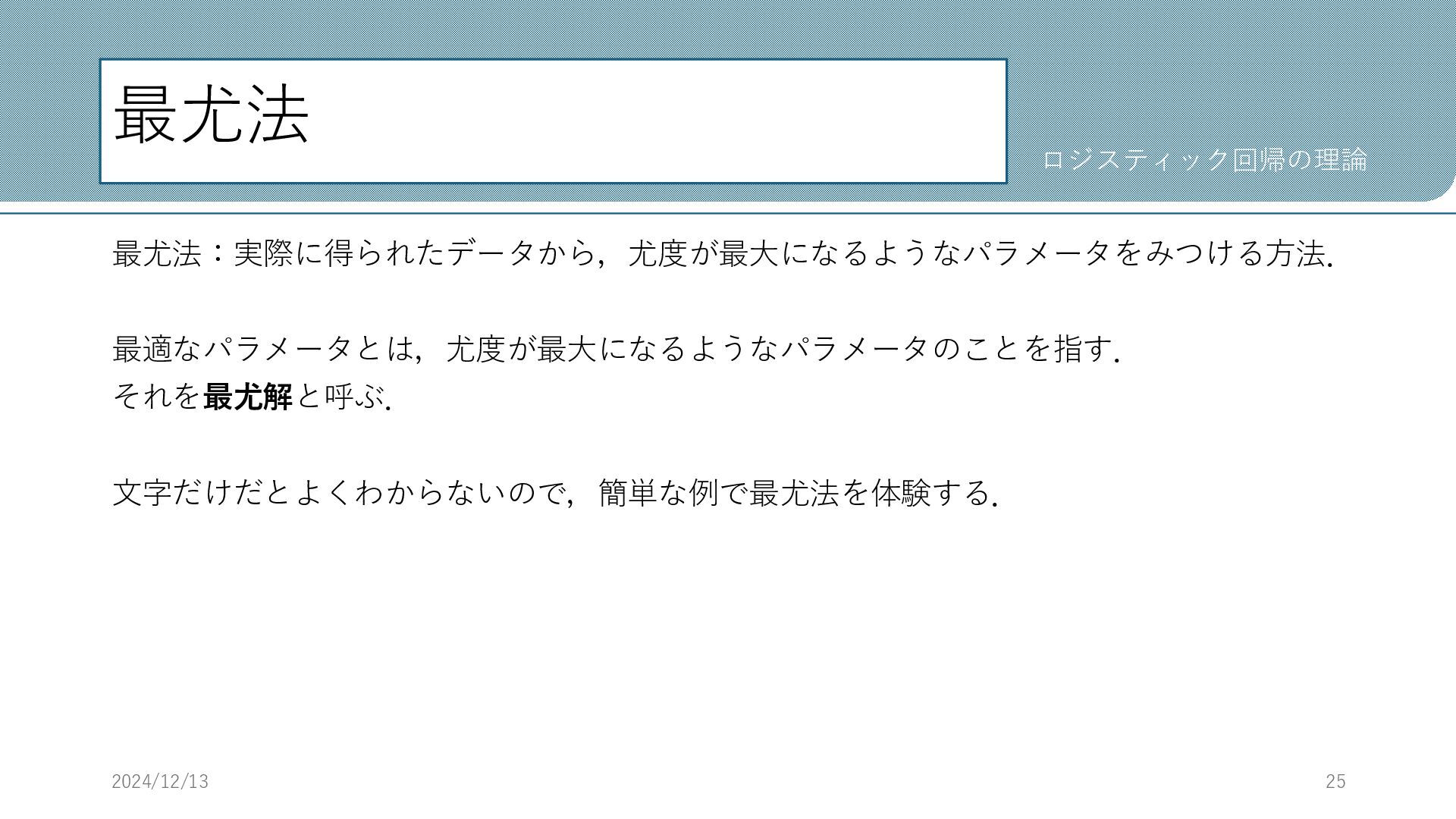
最尤法 最尤法:実際に得られたデータから,尤度が最大になるようなパラメータをみつける方法. 最適なパラメータとは,尤度が最大になるようなパラメータのことを指す. それを最尤解と呼ぶ. 文字だけだとよくわからないので,簡単な例で最尤法を体験する. 2024/12/13 25 ロジスティック回帰の理論
最尤法(コイン投げの例) 一旦ロジスティック回帰から離れ,コイン投げの例を通して最尤法を体験する. コインのパラメータ(表が出る確率)を求める. パラメータを𝜃とする. コインを何回か投げ,その結果から最尤法で𝜃の値を求める. 尤度を求めるための式.尤度方程式は以下.これに当てはめて求めてみる. (あるパラメータ𝜃のときの確率密度の積) 𝐿 𝜃 =
ෑ 𝑖=1 𝑛 𝑓(𝑥𝑖 ; 𝜃) 2024/12/13 26 ロジスティック回帰の理論
最尤法(コイン投げの例) 問:10回コインを投げた結果,表が6回,裏が4回でた. このコインの表が出る確率𝜃を求めよ. 観測値が得られたときのパラメータの尤もらしさを尤度𝐿(𝜃)とする. (尤度が最大のときの𝜃が,最尤解である.) 次スライドにこの式の説明を示す. 2024/12/13 27 ロジスティック回帰の理論 𝐿
𝜃 = ෑ 𝑖=1 𝑛 𝜃𝐾𝑖(1 − 𝜃)1−𝐾𝑖
最尤法(コイン投げの例) 問:10回コインを投げた結果,表が6回,裏が4回でた. このコインの表が出る確率𝜃を求めよ. 尤度𝐿 𝜃 表が出ることを「成功した」と解釈する. n:試行回数 𝜃:パラメータ(表が出る確率) K𝑖 ∈
{0, 1}:成功フラグ,成功(表)=1,失敗(裏)=0 (ベルヌーイ分布の確率質量関数そのものを当てはめている.) 2024/12/13 28 ロジスティック回帰の理論 𝐿 𝜃 = ෑ 𝑖=1 𝑛 𝜃𝐾𝑖(1 − 𝜃)1−𝐾𝑖
最尤法(コイン投げの例) 問:10回コインを投げた結果,表が6回,裏が4回でた. このコインの表が出る確率𝜃を求めよ. 各試行について分解してみる. 10回の試行をまとめると以下のようになる. 𝑘:成功数(表が出た回数) 2024/12/13 29 ロジスティック回帰の理論 𝐾1
= 表 , 𝐾2 = 表 , 𝐾3 = 表 , 𝐾4 = 表 , 𝐾5 = 表 , 𝐾6 = 表 , 𝐾7 = 表 , 裏, 𝐾8 = 裏, 𝐾9 = 裏, 𝐾10 = 裏 𝐿 𝜃 = 𝜃 × 𝜃 × 𝜃 × 𝜃 × 𝜃 × 𝜃 × 1 − 𝜃 × 1 − 𝜃 × 1 − 𝜃 × (1 − 𝜃) 𝐿 𝜃 = 𝜃𝑘 1 − 𝜃 𝑛−𝑘 = 𝜃6 (1 − 𝜃)4
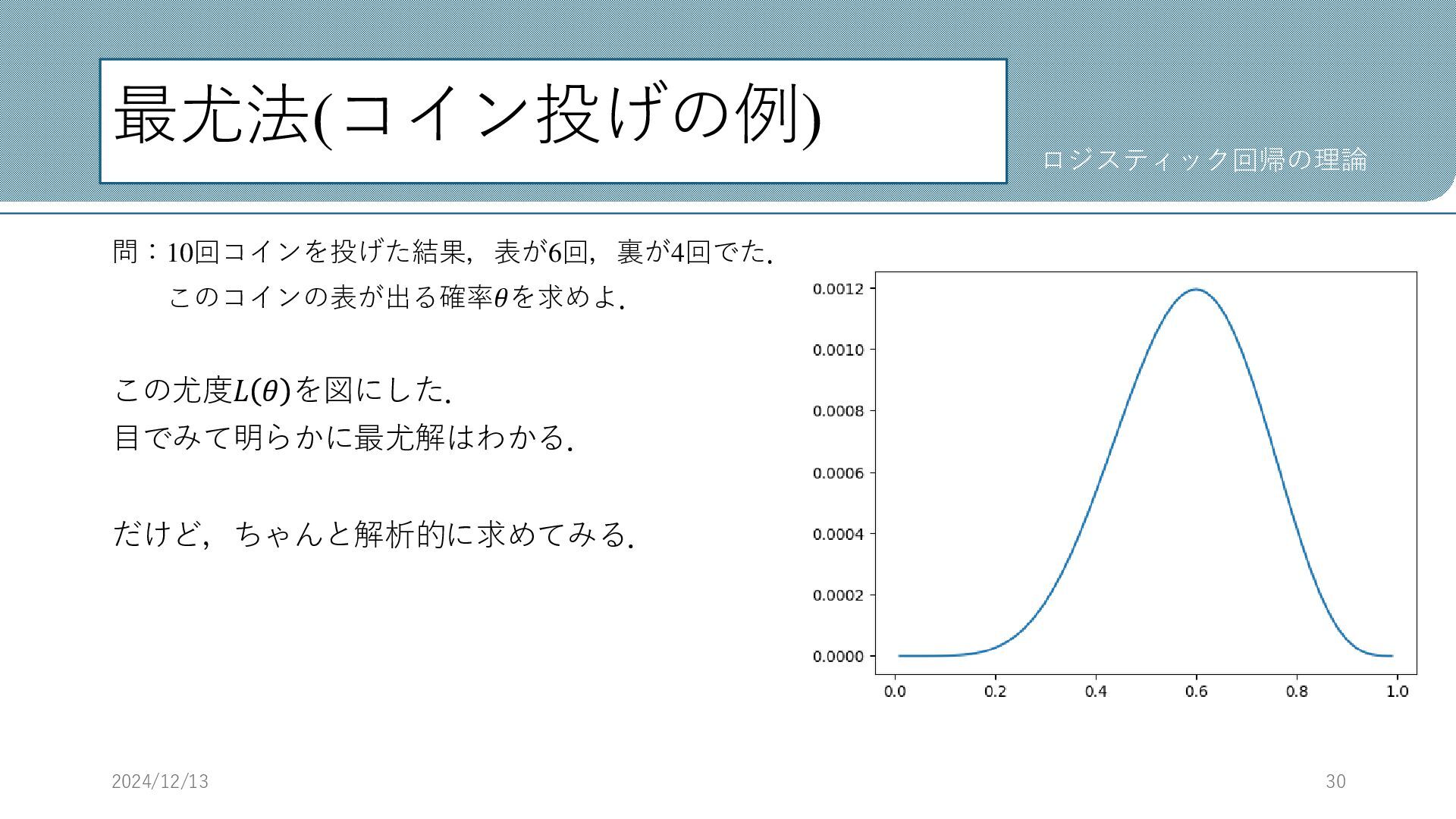
最尤法(コイン投げの例) 問:10回コインを投げた結果,表が6回,裏が4回でた. このコインの表が出る確率𝜃を求めよ. この尤度𝐿 𝜃 を図にした. 目でみて明らかに最尤解はわかる. だけど,ちゃんと解析的に求めてみる. 2024/12/13 30
ロジスティック回帰の理論
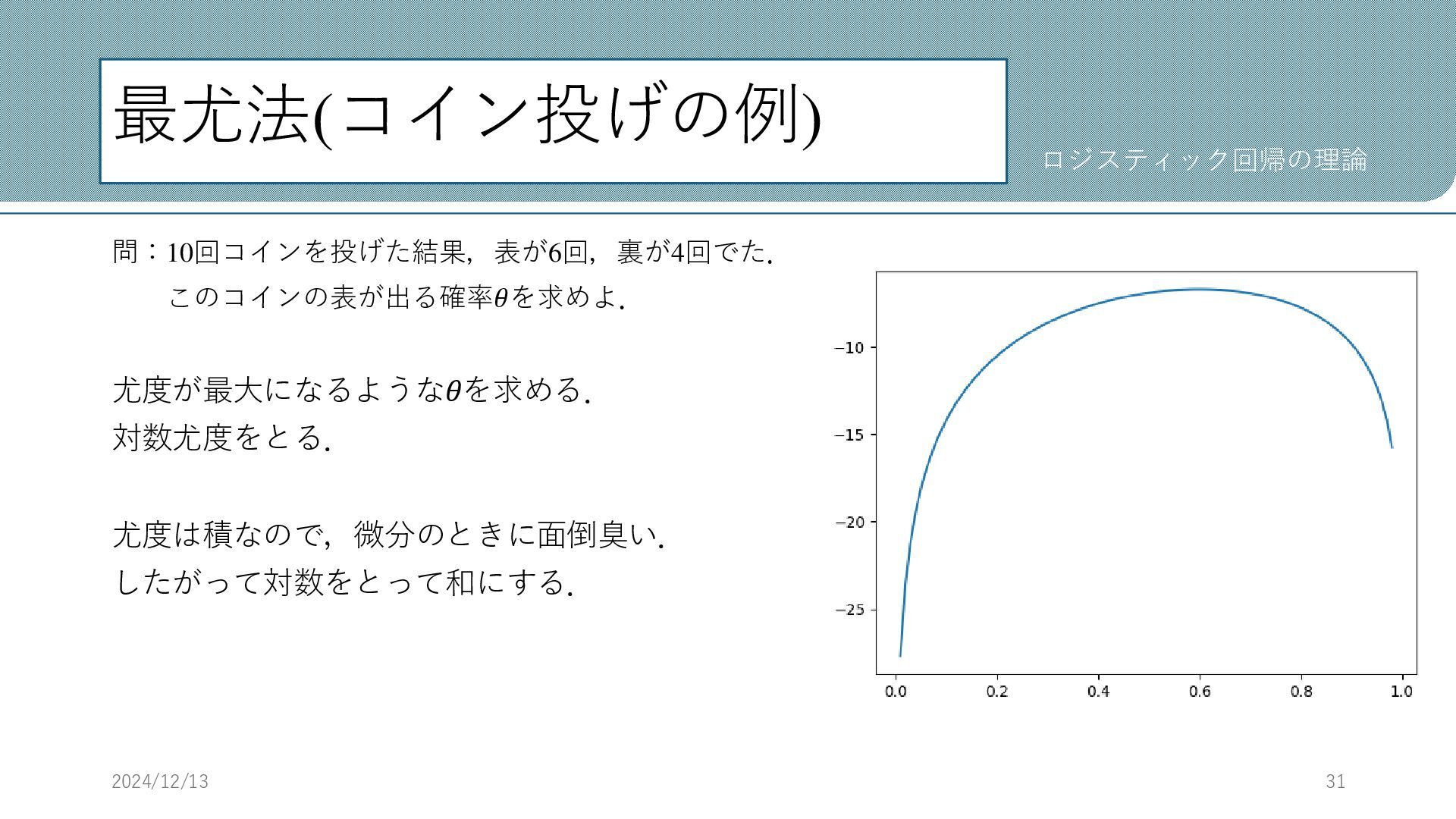
最尤法(コイン投げの例) 問:10回コインを投げた結果,表が6回,裏が4回でた. このコインの表が出る確率𝜃を求めよ. 尤度が最大になるような𝜃を求める. 対数尤度をとる. 尤度は積なので,微分のときに面倒臭い. したがって対数をとって和にする. 2024/12/13 31 ロジスティック回帰の理論
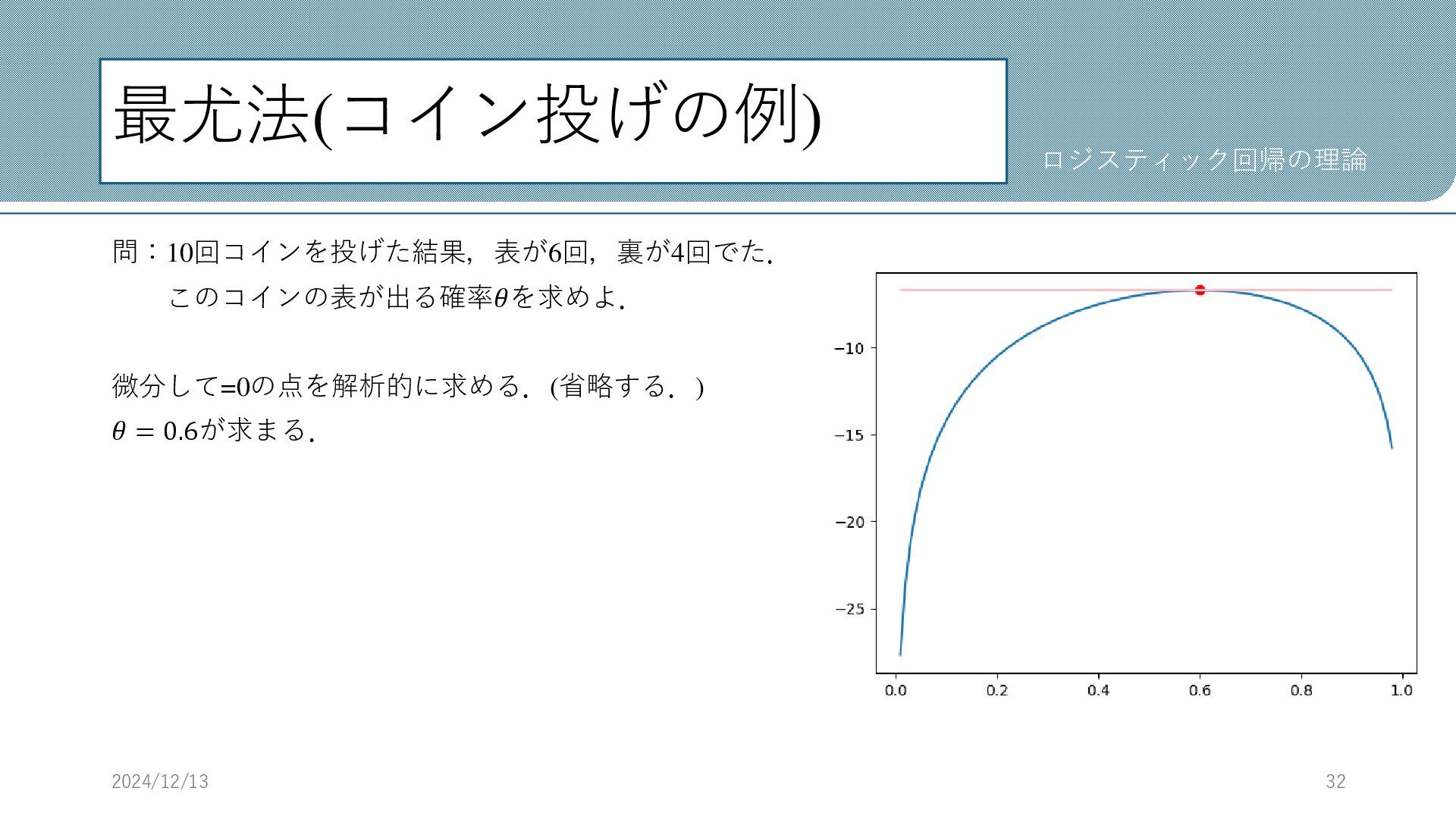
最尤法(コイン投げの例) 問:10回コインを投げた結果,表が6回,裏が4回でた. このコインの表が出る確率𝜃を求めよ. 微分して=0の点を解析的に求める.(省略する.) 𝜃 = 0.6が求まる. 2024/12/13 32 ロジスティック回帰の理論
最尤法(コイン投げの例) コイン投げの例のまとめ. - 尤度を立てる. - 対数尤度をとる. - 対数尤度を微分して=0になる𝜃を求める. ロジスティック回帰でも同じことを目指す. 2024/12/13
33 ロジスティック回帰の理論
最尤法(ロジスティック回帰) 念頭に置いておくが,最尤解(尤度が最大になるパラメータ)が欲しいというのは変わらない.だ から最尤法を使う. ロジスティック回帰での尤度は以下.単純に確率の積になっている. これは,コイン投げの例と同じ. コイン投げのパラメータ𝜃は確率だし, ො 𝑦も確率.(一方のクラスに属する確率) どちらも二値だから同じような式になる.(どちらもベルヌーイ分布にしたがっている) 2024/12/13
34 ロジスティック回帰の理論 𝐿 𝒘 = ෑ 𝑖=1 𝑛 ො 𝑦𝑖 𝑦 𝑖 1 − ො 𝑦𝑖 1−𝑦𝑖 ො 𝑦𝑖 = 𝜎(𝒘𝑇𝒙𝑖 )
最尤法(ロジスティック回帰) 負の対数尤度をとる.(負の対数尤度を取り最小化問題とすることで,損失関数として捉えるため.) 損失関数はよく𝐸 𝒘 とおくので,それにならう. あとは, 𝐸 𝒘 を微分して= 0になる𝒘を求めれば良い.
つまり,∇𝐸 𝒘 = 0を解けば良いということになる.(ベクトルの微分は∇と書く.) しかしこれは解析的に解けない.(方程式の変形だけで解けないということ.ちなみにコイン投げは解析的に解けた.) よって,数値的に解く.(※解析的に解けない問題を,近似的に解を求める方法で解くということ.) 具体的には,(今回は)ニュートン法という方法で解く. 2024/12/13 35 ロジスティック回帰の理論 𝐸 𝒘 = −log𝐿 𝒘 = − σ 𝑖=1 𝑛 (𝑦𝑖 log𝜎 𝒘𝑇𝒙𝒊 + 1 − 𝑦𝑖 log 1 − 𝜎 𝒘𝑇𝒙𝒊 )
最尤法(ロジスティック回帰) 最尤法(ロジスティック回帰)のまとめ 最尤解を求めたい. - 損失関数を微分して= 0になるときのパラメータが最尤解である. - しかしその方程式は解析的に解けない. - 数値的に解く方法を使おう.
- ニュートン法で数値的に解く. 2024/12/13 36 ロジスティック回帰の理論
目次 … • パラメータの最適化 • 尤度とは • 最尤法 • ニュートン法
• ニュートン法とは • 𝑥 − 1 2でのニュートン法 • ロジスティック回帰でのニュートン法 • シグモイド関数の微分 • 勾配:∇𝐸 𝒘 • ヘッセ行列:𝐻 … 2024/12/13 37 ロジスティック回帰の理論
ニュートン法 ニュートン法は,f 𝑥 = 0を数値的に解くための手法の一種. (このようなアルゴリズムは多数存在する.) 収束までの必要な更新回数が少ないという特徴がある. ∇𝐸 𝒘 =
0をニュートン法で数値的に解いていく. 2024/12/13 38 ロジスティック回帰の理論
ニュートン法 ニュートン法の更新式は以下. この式に適当な初期値,𝑥を決めて更新していく. (視覚的なイメージはP41にあるのでそれをみてほしい.) 2024/12/13 39 ロジスティック回帰の理論 𝑥𝑛𝑒𝑤 = 𝑥𝑜𝑙𝑑
− 𝑓(𝑥𝑜𝑙𝑑) 𝑓′(𝑥𝑜𝑙𝑑)
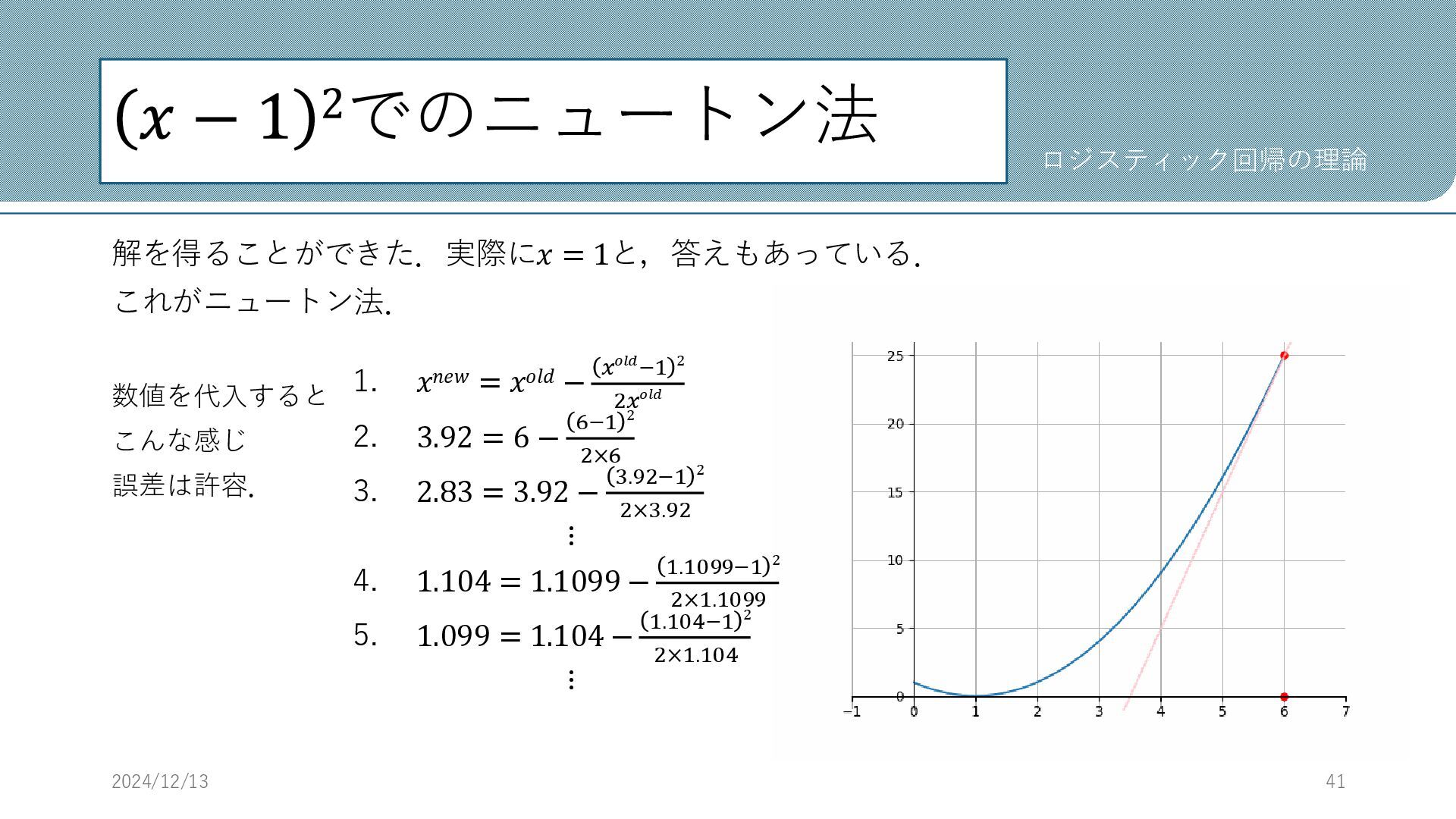
𝑥 − 1 2でのニュートン法 最尤法をコイン投げで説明したように,ニュートン法でも,ロジスティック回帰以外の例 を用いて体験してもらう. 𝑥 − 1 2
= 0を数値的に解いてニュートン法を体験する. ニュートン法の式, 𝑥𝑛𝑒𝑤 = 𝑥𝑜𝑙𝑑 − 𝑓(𝑥𝑜𝑙𝑑) 𝑓′(𝑥𝑜𝑙𝑑) に 𝑥 − 1 2を代入する. これで準備は完了. あとは適当な初期値(𝑥の値)を決めて,更新していくだけ. 適当に初期値𝑥=6から始める. 2024/12/13 40 ロジスティック回帰の理論 𝑥𝑛𝑒𝑤 = 𝑥𝑜𝑙𝑑 − 𝑥𝑜𝑙𝑑 − 1 2 2𝑥𝑜𝑙𝑑
𝑥 − 1 2でのニュートン法 解を得ることができた.実際に𝑥 = 1と,答えもあっている. これがニュートン法. 数値を代入すると こんな感じ
誤差は許容. 2024/12/13 41 ロジスティック回帰の理論 1. 𝑥𝑛𝑒𝑤 = 𝑥𝑜𝑙𝑑 − 𝑥𝑜𝑙𝑑−1 2 2𝑥𝑜𝑙𝑑 2. 3.92 = 6 − 6−1 2 2×6 3. 2.83 = 3.92 − 3.92−1 2 2×3.92 ⋮ 4. 1.104 = 1.1099 − 1.1099−1 2 2×1.1099 5. 1.099 = 1.104 − 1.104−1 2 2×1.104 ⋮
ロジスティック回帰でのニュートン法 ニュートン法のイメージがつかめたところで, ロジスティック回帰の場合は.ニュートン法の更新式に何を代入すれば良いかをみていく. ニュートン法は𝑓(𝑥)=0を解くアルゴリズムであり,𝑓(𝑥)を代入することで解く. 今回の場合,それは∇𝐸 𝒘 である. ∇𝐸 𝒘 を目的関数として代入する.代入した結果,出来上がった更新式が以下.
∇𝐸 𝒘 を微分したものは, 𝐸 𝒘 の二階微分なのでヘッセ行列𝐻で表すことができる. 2024/12/13 42 ロジスティック回帰の理論 𝒘𝑛𝑒𝑤 = 𝒘𝑜𝑙𝑑 − ∇𝐸 𝒘𝑜𝑙𝑑 ∇𝐸 𝒘𝑜𝑙𝑑 ′ =𝒘𝑜𝑙𝑑 − ∇𝐸 𝒘𝑜𝑙𝑑 𝐻 = 𝒘𝑜𝑙𝑑 − 𝐻−1∇𝐸 𝒘𝑜𝑙𝑑
ロジスティック回帰でのニュートン法 ここまできたらラストスパート. 最後は∇𝐸 𝒘 と𝐻の具体的な式を求めて,ニュートン法の更新式に代入するだけ. 次は, - シグモイド関数の微分 - 勾配:∇𝐸
𝒘 - ヘッセ行列:𝐻 を順番に求めていく. 2024/12/13 43 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 シグモイド関数の微分を求める. シグモイド関数:𝜎 𝑥 = 1 1+𝑒−𝑥 = 1 +
𝑒−𝑥 −1 𝑡 = (1 + 𝑒−𝑥)とする. 𝑑 𝑑𝑥 𝜎 𝑥 = 𝑑 𝑑𝑡 𝑡−1 𝑑𝑡 𝑑𝑥 𝑡 = −𝑡−2 𝑑𝑡 𝑑𝑥 1 + 𝑒−𝑥 −1 = − 1 + 𝑒−𝑥 −2 ⋅ −𝑒−𝑥 = 𝑒−𝑥 1+𝑒−𝑥 2 = 𝑒−𝑥 1+𝑒−𝑥 1 1+𝑒−𝑥 = (1+𝑒−𝑥 1+𝑒−𝑥 − 1 1+𝑒−𝑥 ) 1 1+𝑒−𝑥 = (1 − 𝜎 𝑥 )𝜎 𝑥 2024/12/13 44 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 勾配:∇𝐸(𝒘)を求める. ∇𝐸 𝒘 = − 𝑖=1 𝑛 𝑦𝑖
∇ log𝜎 𝒘𝑇𝒙𝒊 + (1 − 𝑦𝑖 ∇ log 1 − 𝜎 𝒘𝑇𝒙𝒊 ] 対数の微分より = − 𝑖=1 𝑛 [𝑦𝑖 1 𝜎 𝒘𝑇𝒙𝒊 ∇𝜎 𝒘𝑇𝒙𝒊 + (1 − 𝑦𝑖 ) 1 1 − 𝜎 𝒘𝑇𝒙𝒊 ∇(1 − 𝜎 𝒘𝑇𝒙𝒊 )] シグモイド関数の微分より = − 𝑖=1 𝑛 𝑦𝑖 1 − 𝜎 𝒘𝑇𝒙𝒊 𝒙𝑖 + (1 − 𝑦𝑖 (−𝜎 𝒘𝑇𝒙𝒊 )𝒙𝑖 ] = − 𝑖=1 𝑛 [𝑦𝑖 − 𝑦𝑖 𝜎 𝒘𝑇𝒙𝒊 − 𝜎 𝒘𝑇𝒙𝒊 + 𝑦𝑖 𝜎 𝒘𝑇𝒙𝒊 ]𝒙𝑖 = − 𝑖=1 𝑛 𝑦𝑖 − 𝜎 𝒘𝑇𝒙𝒊 𝒙𝑖 = 𝑖=1 𝑛 (𝜎 𝒘𝑇𝒙𝒊 − 𝑦𝑖 )𝒙𝑖 2024/12/13 45 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 𝜎 𝒘𝑇𝒙𝒊 =ො 𝑦𝑖 なのでො 𝑦𝑖 − 𝑦𝑖 と表すことができる.
ො 𝑦𝑖 − 𝑦𝑖 はスカラーで,𝒙𝑖 は𝑚次元の列ベクトルである. したがって, σ𝑖=1 𝑛 (ො 𝑦𝑖 − 𝑦𝑖 )𝒙𝑖 は, ((予測された確率) – (実際の確率)) × 説明変数 を全てのデータについての和をとるという意味になっている. ※(実際の確率)は,クラス1であるか否かなので,0.0か1.0のどちらか. 2024/12/13 46 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 行列を使用すると, σ𝑖=1 𝑛 (ො 𝑦𝑖 − 𝑦𝑖 )𝒙𝑖 のΣを外すことができる.
𝑖=1 𝑛 ( ො 𝑦𝑖 − 𝑦𝑖 )𝒙𝑖 = ො 𝑦1 − 𝑦1 𝑥11 + ො 𝑦2 − 𝑦2 𝑥21 + ⋯ + ො 𝑦𝑛 − 𝑦𝑛 𝑥𝑛1 ො 𝑦1 − 𝑦1 𝑥12 + ො 𝑦2 − 𝑦2 𝑥22 + ⋯ + ො 𝑦𝑛 − 𝑦𝑛 𝑥𝑛2 ⋮ ො 𝑦1 − 𝑦1 𝑥1𝑚 + ො 𝑦2 − 𝑦2 𝑥2𝑚 + ⋯ + ො 𝑦𝑛 − 𝑦𝑛 𝑥𝑛𝑚 これを行列でまとめると,以下になる. ∇𝐸 𝒘 = 𝑋𝑇(ෝ 𝒚 − 𝒚) これで∇𝐸 𝒘 が求められた. 2024/12/13 47 ロジスティック回帰の理論
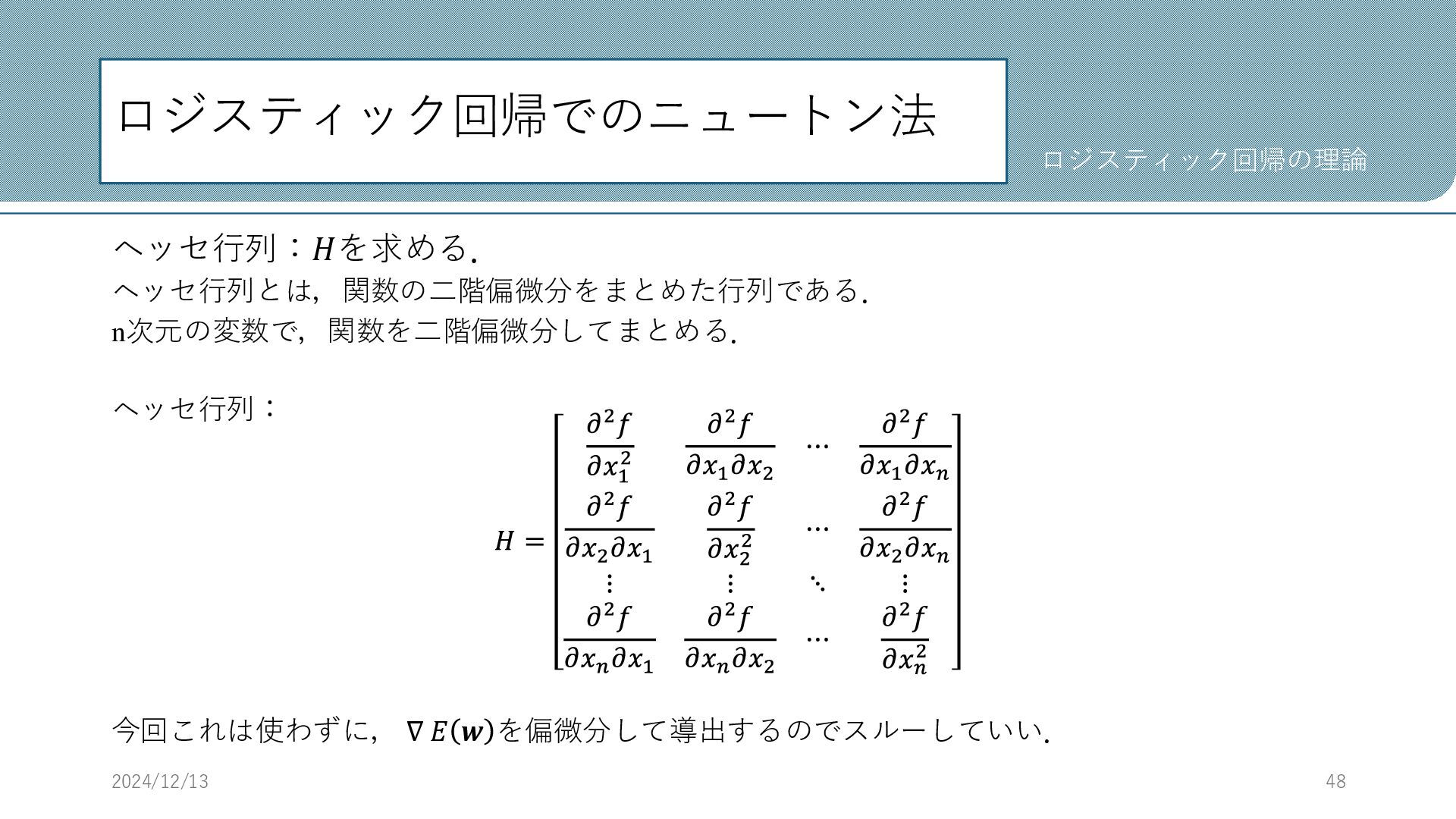
ロジスティック回帰でのニュートン法 ヘッセ行列:𝐻を求める. ヘッセ行列とは,関数の二階偏微分をまとめた行列である. n次元の変数で,関数を二階偏微分してまとめる. ヘッセ行列: 𝐻 = 𝜕2𝑓 𝜕𝑥1 2
𝜕2𝑓 𝜕𝑥1 𝜕𝑥2 ⋯ 𝜕2𝑓 𝜕𝑥1 𝜕𝑥𝑛 𝜕2𝑓 𝜕𝑥2 𝜕𝑥1 𝜕2𝑓 𝜕𝑥2 2 ⋯ 𝜕2𝑓 𝜕𝑥2 𝜕𝑥𝑛 ⋮ ⋮ ⋱ ⋮ 𝜕2𝑓 𝜕𝑥𝑛 𝜕𝑥1 𝜕2𝑓 𝜕𝑥𝑛 𝜕𝑥2 ⋯ 𝜕2𝑓 𝜕𝑥𝑛 2 今回これは使わずに, ∇ 𝐸 𝒘 を偏微分して導出するのでスルーしていい. 2024/12/13 48 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 ロジスティック回帰におけるヘッセ行列を導出する. (∇ 𝐸 𝒘 を偏微分するので,𝐸 𝒘 の二階微分として,∇2𝐸 𝒘 ともかける.)
∇𝐸 𝒘 = 𝑋𝑇(ෝ 𝒚 − 𝒚)なので, 𝐻 = ∇2𝐸 𝒘 = 𝜕 𝜕𝒘 𝐸 𝒘 = 𝜕 𝜕𝒘 {𝑋𝑇(ෝ 𝒚 − 𝒚)} = 𝜕 𝜕𝒘 (𝑋𝑇ෝ 𝒚 − 𝑋𝑇𝒚) 𝑋𝑇𝒚は𝒘に関係ないので, 𝜕 𝜕𝒘 (−𝑋T𝒚) =0になる. したがって, = 𝜕 𝜕𝒘 𝑋𝑇ෝ 𝒚 2024/12/13 49 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 問題は 𝜕 𝜕𝒘 𝑋𝑇ෝ 𝒚のみとなった. 連鎖律より, 𝜕 𝜕𝒘 𝑋𝑇ෝ
𝒚 = 𝜕 𝜕ෝ 𝒚 𝑋𝑇ෝ 𝒚 𝜕ෝ 𝒚 𝜕𝒘 𝜕 𝜕ෝ 𝒚 𝑋𝑇ෝ 𝒚と, 𝜕ෝ 𝒚 𝜕𝒘 に分けて計算できるようになった.(順番に求めればいい.) 注意したいのは,どちらもベクトルをベクトルで微分する形になっていること. 𝑋𝑇ෝ 𝒚 ∈ ℝ𝑚 ෝ 𝒚 ∈ ℝ𝑛 𝒘 ∈ ℝ𝑚 ベクトルをベクトルで微分すると行列になる. 2024/12/13 50 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 ベクトルをベクトルで微分すると行列になる. これを,ヤコビ行列と言う. ヤコビ行列をしっかり定義する. 𝒂 ∈ ℝ𝑚 𝒃 ∈ ℝ𝑛
とする. 𝜕𝒂 𝜕𝒃 = 𝜕𝑎1 𝜕𝑏1 𝜕𝑎1 𝜕𝑏2 ⋯ 𝜕𝑎1 𝜕𝑏𝑛 𝜕𝑎2 𝜕𝑏1 𝜕𝑎2 𝜕𝑏2 ⋯ 𝜕𝑎2 𝜕𝑏𝑛 ⋮ ⋮ ⋱ ⋮ 𝜕𝑎𝑚 𝜕𝑏1 𝜕𝑎𝑚 𝜕𝑏2 ⋯ 𝜕𝑎𝑚 𝜕𝑏𝑛 𝜕𝒂 𝜕𝒃 ∈ ℝm×𝑛とする. この定義から, 𝜕 𝜕ෝ 𝒚 𝑋𝑇ෝ 𝒚 ∈ ℝm×𝑛, 𝜕ෝ 𝒚 𝜕𝒘 ∈ ℝ𝑛×mになることがわかる. 2024/12/13 51 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 𝜕 𝜕ෝ 𝒚 𝑋𝑇ෝ 𝒚と𝜕ෝ 𝒚 𝜕𝒘 を計算していく. 𝜕
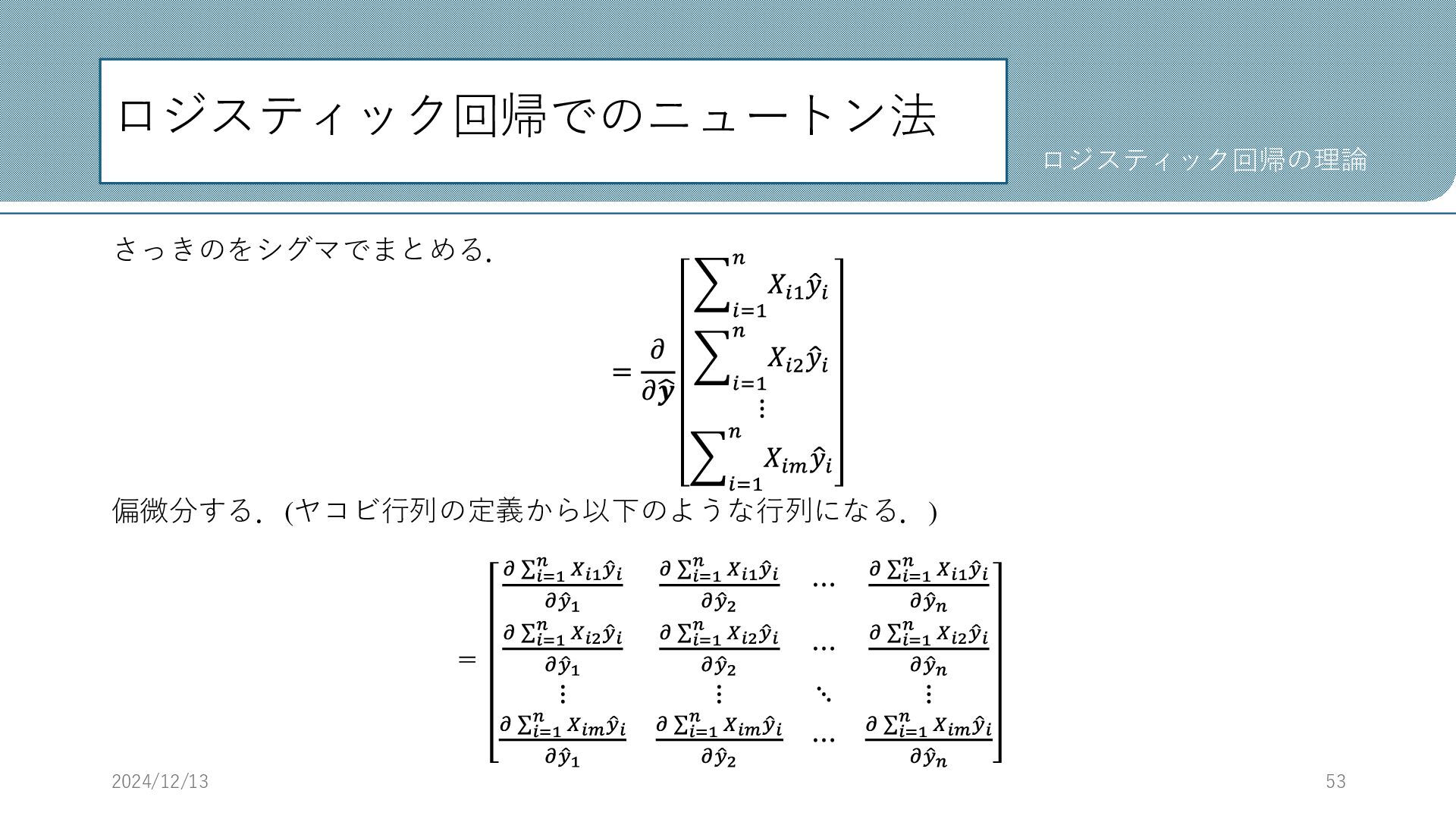
𝜕ෝ 𝒚 𝑋𝑇ෝ 𝒚を計算する. 𝜕 𝜕ෝ 𝒚 𝑋𝑇ෝ 𝒚 = 𝜕 𝜕ෝ 𝒚 𝑋11 𝑋21 ⋯ 𝑋𝑛1 𝑋12 𝑋22 ⋯ 𝑋𝑛2 ⋮ ⋮ ⋱ ⋮ 𝑋1𝑚 𝑋2𝑚 ⋯ 𝑋𝑛𝑚 ො 𝑦1 ො 𝑦2 ⋮ ො 𝑦𝑛 行列とベクトルの積を計算. = 𝜕 𝜕ෝ 𝒚 𝑋11 ො 𝑦1 + 𝑋21 ො 𝑦2 + ⋯ + 𝑋𝑛1 ො 𝑦𝑛 𝑋12 ො 𝑦1 + 𝑋22 ො 𝑦2 + ⋯ + 𝑋𝑛2 ො 𝑦𝑛 ⋮ 𝑋1𝑚 ො 𝑦1 + 𝑋2𝑚 ො 𝑦2 + ⋯ + 𝑋𝑛𝑚 ො 𝑦𝑛 2024/12/13 52 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 さっきのをシグマでまとめる. = 𝜕 𝜕ෝ 𝒚 𝑖=1 𝑛 𝑋𝑖1
ො 𝑦𝑖 𝑖=1 𝑛 𝑋𝑖2 ො 𝑦𝑖 ⋮ 𝑖=1 𝑛 𝑋𝑖𝑚 ො 𝑦𝑖 偏微分する.(ヤコビ行列の定義から以下のような行列になる.) = 𝜕 σ𝑖=1 𝑛 𝑋𝑖1 ො 𝑦𝑖 𝜕 ො 𝑦1 𝜕 σ𝑖=1 𝑛 𝑋𝑖1 ො 𝑦𝑖 𝜕 ො 𝑦2 ⋯ 𝜕 σ𝑖=1 𝑛 𝑋𝑖1 ො 𝑦𝑖 𝜕 ො 𝑦𝑛 𝜕 σ𝑖=1 𝑛 𝑋𝑖2 ො 𝑦𝑖 𝜕 ො 𝑦1 𝜕 σ𝑖=1 𝑛 𝑋𝑖2 ො 𝑦𝑖 𝜕 ො 𝑦2 ⋯ 𝜕 σ𝑖=1 𝑛 𝑋𝑖2 ො 𝑦𝑖 𝜕 ො 𝑦𝑛 ⋮ ⋮ ⋱ ⋮ 𝜕 σ𝑖=1 𝑛 𝑋𝑖𝑚 ො 𝑦𝑖 𝜕 ො 𝑦1 𝜕 σ𝑖=1 𝑛 𝑋𝑖𝑚 ො 𝑦𝑖 𝜕 ො 𝑦2 ⋯ 𝜕 σ𝑖=1 𝑛 𝑋𝑖𝑚 ො 𝑦𝑖 𝜕 ො 𝑦𝑛 2024/12/13 53 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 𝜕 σ𝑖=1 𝑛 𝑋𝑖1 ො 𝑦𝑖 𝜕 ො 𝑦1
𝜕 σ𝑖=1 𝑛 𝑋𝑖1 ො 𝑦𝑖 𝜕 ො 𝑦2 ⋯ 𝜕 σ𝑖=1 𝑛 𝑋𝑖1 ො 𝑦𝑖 𝜕 ො 𝑦𝑛 𝜕 σ𝑖=1 𝑛 𝑋𝑖2 ො 𝑦𝑖 𝜕 ො 𝑦1 𝜕 σ𝑖=1 𝑛 𝑋𝑖2 ො 𝑦𝑖 𝜕 ො 𝑦2 ⋯ 𝜕 σ𝑖=1 𝑛 𝑋𝑖2 ො 𝑦𝑖 𝜕 ො 𝑦𝑛 ⋮ ⋮ ⋱ ⋮ 𝜕 σ𝑖=1 𝑛 𝑋𝑖𝑚 ො 𝑦𝑖 𝜕 ො 𝑦1 𝜕 σ𝑖=1 𝑛 𝑋𝑖𝑚 ො 𝑦𝑖 𝜕 ො 𝑦2 ⋯ 𝜕 σ𝑖=1 𝑛 𝑋𝑖𝑚 ො 𝑦𝑖 𝜕 ො 𝑦𝑛 の一行一列目だけ計算してみる. 他の要素についても同様の計算をすれば求められる. 𝜕 σ𝑖=1 𝑛 𝑋𝑖1 ො 𝑦𝑖 𝜕ො 𝑦1 = 𝜕 𝜕ො 𝑦1 𝑖=1 𝑛 𝑋𝑖1 ො 𝑦𝑖 = 𝜕 𝜕 ො 𝑦1 𝑋11 ො 𝑦1 + 𝑋21 ො 𝑦2 + ⋯ + 𝑋𝑛1 ො 𝑦𝑛 = 𝜕 𝜕 ො 𝑦1 𝑋11 ො 𝑦1 + 𝜕 𝜕 ො 𝑦1 𝑋21 ො 𝑦2 + ⋯ + 𝜕 𝜕 ො 𝑦1 𝑋𝑛1 ො 𝑦𝑛 = 𝑋11 + 0 + ⋯ + 0 = 𝑋11 2024/12/13 54 ロジスティック回帰の理論
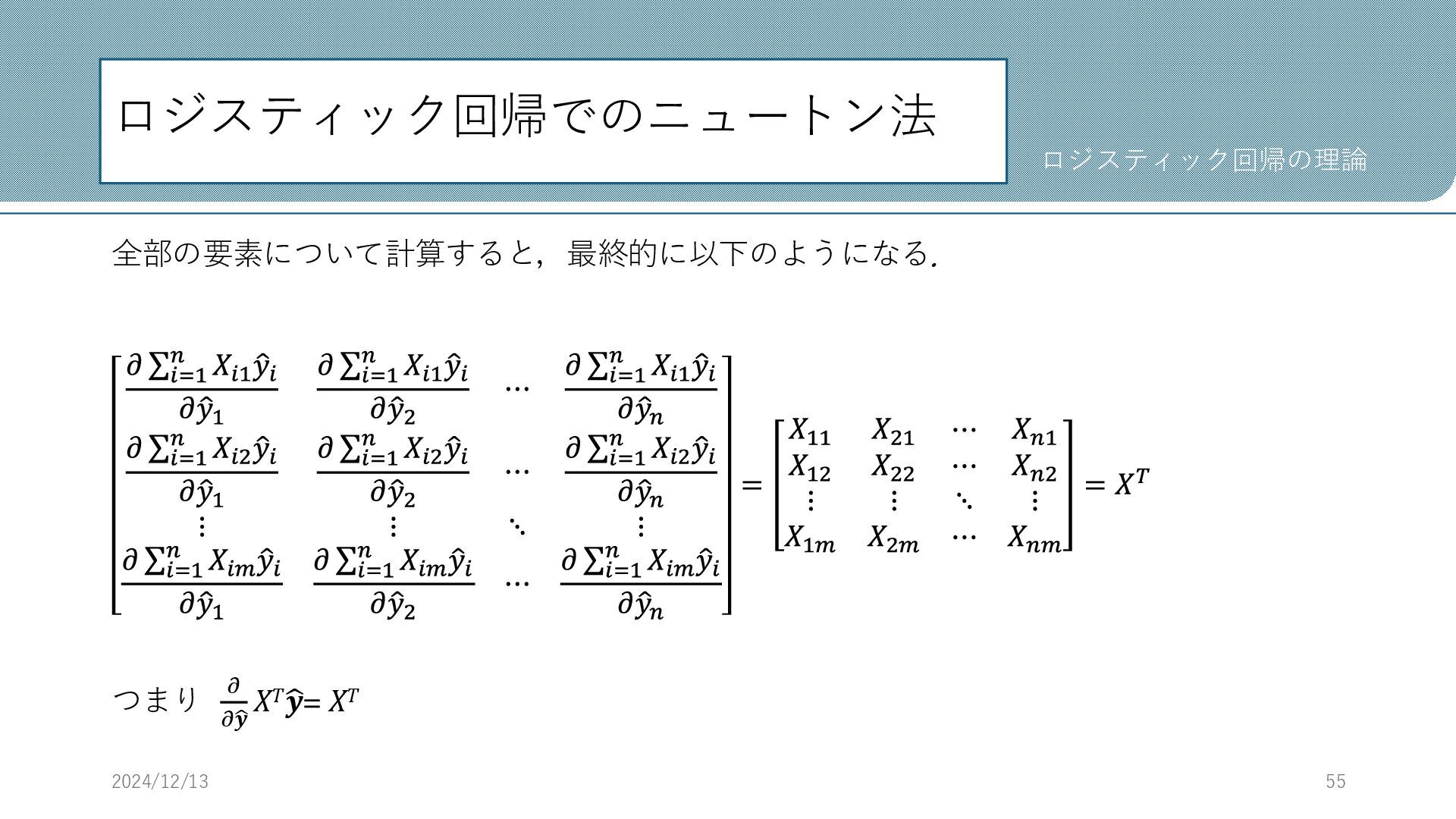
ロジスティック回帰でのニュートン法 全部の要素について計算すると,最終的に以下のようになる. 𝜕 σ𝑖=1 𝑛 𝑋𝑖1 ො 𝑦𝑖 𝜕ො 𝑦1
𝜕 σ𝑖=1 𝑛 𝑋𝑖1 ො 𝑦𝑖 𝜕ො 𝑦2 ⋯ 𝜕 σ𝑖=1 𝑛 𝑋𝑖1 ො 𝑦𝑖 𝜕ො 𝑦𝑛 𝜕 σ𝑖=1 𝑛 𝑋𝑖2 ො 𝑦𝑖 𝜕ො 𝑦1 𝜕 σ𝑖=1 𝑛 𝑋𝑖2 ො 𝑦𝑖 𝜕ො 𝑦2 ⋯ 𝜕 σ𝑖=1 𝑛 𝑋𝑖2 ො 𝑦𝑖 𝜕ො 𝑦𝑛 ⋮ ⋮ ⋱ ⋮ 𝜕 σ𝑖=1 𝑛 𝑋𝑖𝑚 ො 𝑦𝑖 𝜕ො 𝑦1 𝜕 σ𝑖=1 𝑛 𝑋𝑖𝑚 ො 𝑦𝑖 𝜕ො 𝑦2 ⋯ 𝜕 σ𝑖=1 𝑛 𝑋𝑖𝑚 ො 𝑦𝑖 𝜕ො 𝑦𝑛 = 𝑋11 𝑋21 ⋯ 𝑋𝑛1 𝑋12 𝑋22 ⋯ 𝑋𝑛2 ⋮ ⋮ ⋱ ⋮ 𝑋1𝑚 𝑋2𝑚 ⋯ 𝑋𝑛𝑚 = 𝑋𝑇 つまり 𝜕 𝜕ෝ 𝒚 𝑋𝑇ෝ 𝒚= 𝑋𝑇 2024/12/13 55 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 𝜕ෝ 𝒚 𝜕𝒘 を計算する. これは,一旦ヤコビ行列を展開したほうがわかりやすいと思うので,展開する. 𝜕ෝ 𝒚 𝜕𝒘 =
𝜕ො 𝑦1 𝜕𝑤1 𝜕ො 𝑦1 𝜕𝑤2 ⋯ 𝜕ො 𝑦1 𝜕𝑤𝑚 𝜕ො 𝑦2 𝜕𝑤1 𝜕ො 𝑦2 𝜕𝑤2 ⋯ 𝜕ො 𝑦2 𝜕𝑤𝑚 ⋮ ⋮ ⋱ ⋮ 𝜕ො 𝑦𝑛 𝜕𝑤1 𝜕ො 𝑦𝑛 𝜕𝑤2 ⋯ 𝜕ො 𝑦𝑛 𝜕𝑤𝑚 2024/12/13 56 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 𝜕 ො 𝑦1 𝜕𝑤1 𝜕 ො 𝑦1 𝜕𝑤2 ⋯
𝜕 ො 𝑦1 𝜕𝑤𝑚 𝜕 ො 𝑦2 𝜕𝑤1 𝜕 ො 𝑦2 𝜕𝑤2 ⋯ 𝜕 ො 𝑦2 𝜕𝑤𝑚 ⋮ ⋮ ⋱ ⋮ 𝜕 ො 𝑦𝑛 𝜕𝑤1 𝜕 ො 𝑦𝑛 𝜕𝑤2 ⋯ 𝜕 ො 𝑦𝑛 𝜕𝑤𝑚 の一行一列目だけ計算してみる. ො 𝑦1 = 𝜎(𝒘𝑇𝒙𝟏 ) 𝒙𝟏 = 𝑋11 𝑋12 ⋮ 𝑋1𝑚 = 𝑥11 𝑥12 ⋮ 𝑥1𝑚 ※この大文字小文字に特に意味はない. シグモイド関数の微分:(1 − 𝜎 𝑥 )𝜎 𝑥 から 2024/12/13 57 ロジスティック回帰の理論 𝜕ො 𝑦1 𝜕𝑤1 = 𝜕 𝜕𝑤1 𝜎 𝒘𝑇𝒙𝟏 = 𝜕 𝜕𝑤1 𝜎(𝑤1 𝑥11+𝑤2 𝑥12 + ⋯ + 𝑤𝑚 𝑥1𝑚 ) 𝜎の中の微分は𝑤1 の係数が出てくるので, = 𝜎 𝒘𝑇𝒙𝟏 1 − 𝜎 𝒘𝑇𝒙𝟏 𝑥11 = ො 𝑦1 (1 − ො 𝑦1 )𝑋11
ロジスティック回帰でのニュートン法 全部の要素について計算すると,最終的に以下のようになる. 𝜕ො 𝑦1 𝜕𝑤1 𝜕ො 𝑦1 𝜕𝑤2 ⋯ 𝜕ො
𝑦1 𝜕𝑤𝑚 𝜕ො 𝑦2 𝜕𝑤1 𝜕ො 𝑦2 𝜕𝑤2 ⋯ 𝜕ො 𝑦2 𝜕𝑤𝑚 ⋮ ⋮ ⋱ ⋮ 𝜕ො 𝑦𝑛 𝜕𝑤1 𝜕ො 𝑦𝑛 𝜕𝑤2 ⋯ 𝜕ො 𝑦𝑛 𝜕𝑤𝑚 = ො 𝑦1 (1 − ො 𝑦1 )𝑋11 ො 𝑦1 (1 − ො 𝑦1 )𝑋12 ⋯ ො 𝑦1 (1 − ො 𝑦1 )𝑋1𝑚 ො 𝑦2 (1 − ො 𝑦2 )𝑋21 ො 𝑦2 (1 − ො 𝑦2 )𝑋22 ⋯ ො 𝑦2 (1 − ො 𝑦2 )𝑋2𝑚 ⋮ ⋮ ⋱ ⋮ ො 𝑦𝑛 (1 − ො 𝑦𝑛 )𝑋𝑛1 ො 𝑦𝑛 (1 − ො 𝑦𝑛 )𝑋𝑛2 ⋯ ො 𝑦𝑛 (1 − ො 𝑦𝑛 )𝑋𝑛𝑚 実は,これはො 𝑦1 (1 − ො 𝑦1 ), ො 𝑦2 (1 − ො 𝑦2 ),…, ො 𝑦𝑛 (1 − ො 𝑦𝑛 )を対角成分にもつ対角行列と, 𝑋に分解できる. 2024/12/13 58 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 分解して整理すると以下のようになる. = ො 𝑦1 1 − ො 𝑦1 0
ො 𝑦2 1 − ො 𝑦2 ⋱ 0 ො 𝑦𝑛 1 − ො 𝑦𝑛 𝑋11 𝑋12 ⋯ 𝑋1𝑚 𝑋21 𝑋22 ⋯ 𝑋2𝑚 ⋮ ⋮ ⋱ ⋮ 𝑋𝑛1 𝑋𝑛2 ⋯ 𝑋𝑛𝑚 対角行列を𝑅と置くと. = 𝑅𝑋 つまり, 𝜕ෝ 𝒚 𝜕𝒘 = 𝑅𝑋 𝜕 𝜕ෝ 𝒚 𝑋𝑇ෝ 𝒚= 𝑋𝑇, 𝜕ෝ 𝒚 𝜕𝒘 = 𝑅𝑋 なので, 𝐻 = ∇2𝐸 𝒘 = 𝜕 𝜕𝒘 𝑋𝑇ෝ 𝒚 = 𝜕 𝜕ෝ 𝒚 𝑋𝑇ෝ 𝒚 𝜕ෝ 𝒚 𝜕𝒘 = 𝑋𝑇𝑅𝑋 𝐻 = 𝑋𝑇𝑅𝑋 これで𝐻が求められた. 2024/12/13 59 ロジスティック回帰の理論
ロジスティック回帰でのニュートン法 ∇𝐸 𝒘 と𝐻が求められたので,更新式に代入する. - 更新式 :𝒘𝑛𝑒𝑤 = 𝒘𝑜𝑙𝑑 −
𝐻−1∇𝐸 𝒘𝑜𝑙𝑑 - ∇𝐸 𝒘 = 𝑋𝑇(ෝ 𝒚 − 𝒚) - 𝐻 = 𝑋𝑇𝑅𝑋 以下の式変形は「逆行列を作る」「単位行列を作る」「結合法則」しか利用していないので補足はしない. 𝒘𝑛𝑒𝑤 = 𝒘𝑜𝑙𝑑 − 𝐻−1∇𝐸 𝒘𝑜𝑙𝑑 = 𝒘𝑜𝑙𝑑 − 𝑋𝑇𝑅𝑋 −1𝑋𝑇 ෝ 𝒚 − 𝒚 = (𝑋𝑇𝑅𝑋)−1𝑋𝑇𝑅𝑋𝒘𝑜𝑙𝑑 − 𝑋𝑅𝑋𝑇 −1𝑋𝑇𝑅𝑅−1 ෝ 𝒚 − 𝒚 = 𝑋𝑇𝑅𝑋 −1(𝑋𝑇𝑅)[𝑋𝒘𝑜𝑙𝑑 − 𝑅−1 ෝ 𝒚 − 𝒚 ] これがパラメータの更新式. これを元にパラメータを更新していくことで最適なパラメータが得られる. ※ 実装にあたっては,2行目の式で十分.4行目の形はIRLSというものと関係があるらしい. 2024/12/13 60 ロジスティック回帰の理論
目次 • はじめに • ロジスティック回帰の気持ち • ロジスティック回帰の理論 • 実装 •
付録 2024/12/13 61 実装
ライブラリのインポート コピペして使おう. import time import random import pandas as pd
import numpy as np from sklearn.datasets import make_classification from sklearn.linear_model import LogisticRegression import matplotlib.pyplot as plt import matplotlib.patches as patches 2024/12/13 62 実装
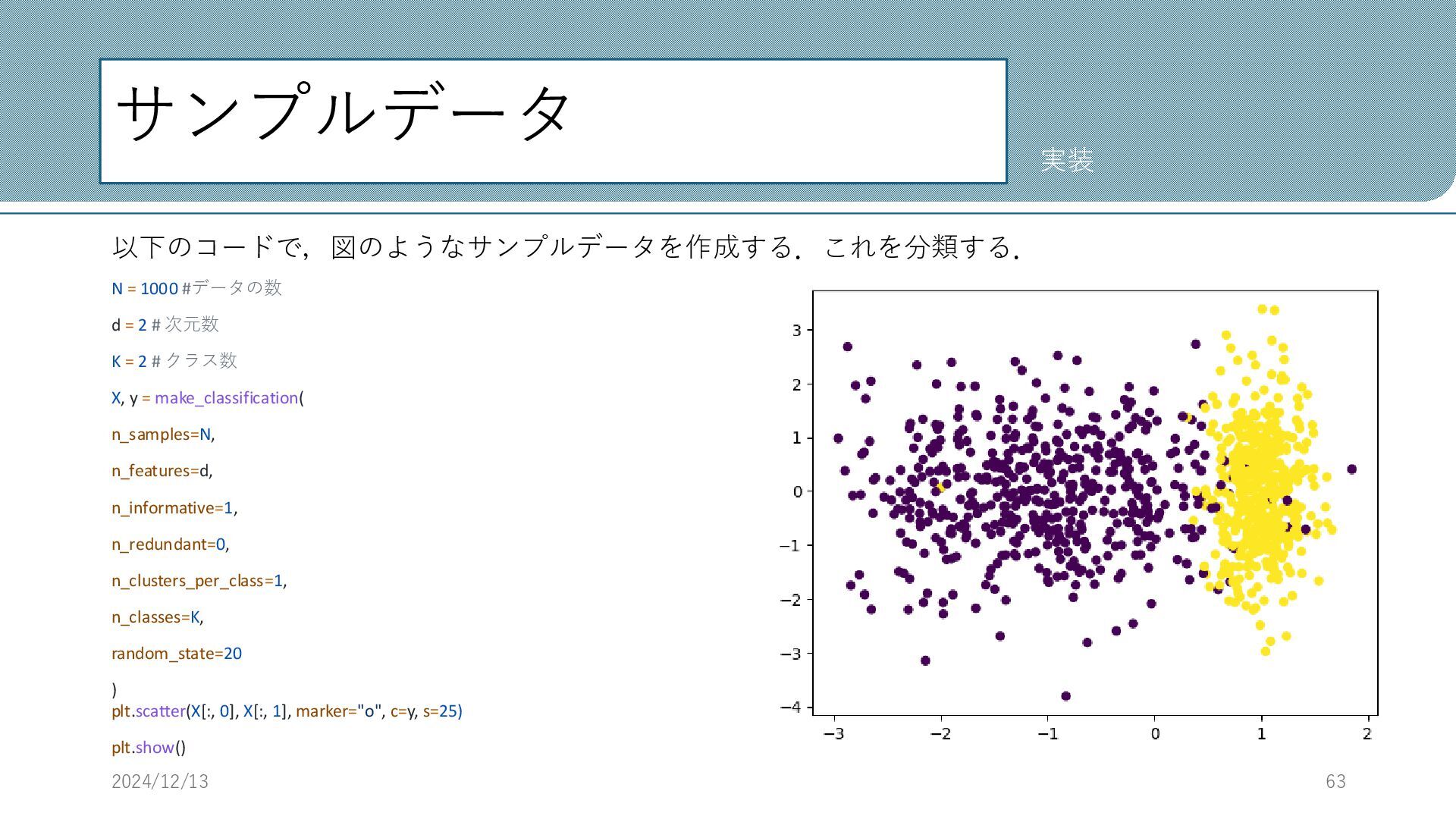
サンプルデータ 以下のコードで,図のようなサンプルデータを作成する.これを分類する. N = 1000 #データの数 d = 2 #
次元数 K = 2 # クラス数 X, y = make_classification( n_samples=N, n_features=d, n_informative=1, n_redundant=0, n_clusters_per_class=1, n_classes=K, random_state=20 ) plt.scatter(X[:, 0], X[:, 1], marker="o", c=y, s=25) plt.show() 2024/12/13 63 実装
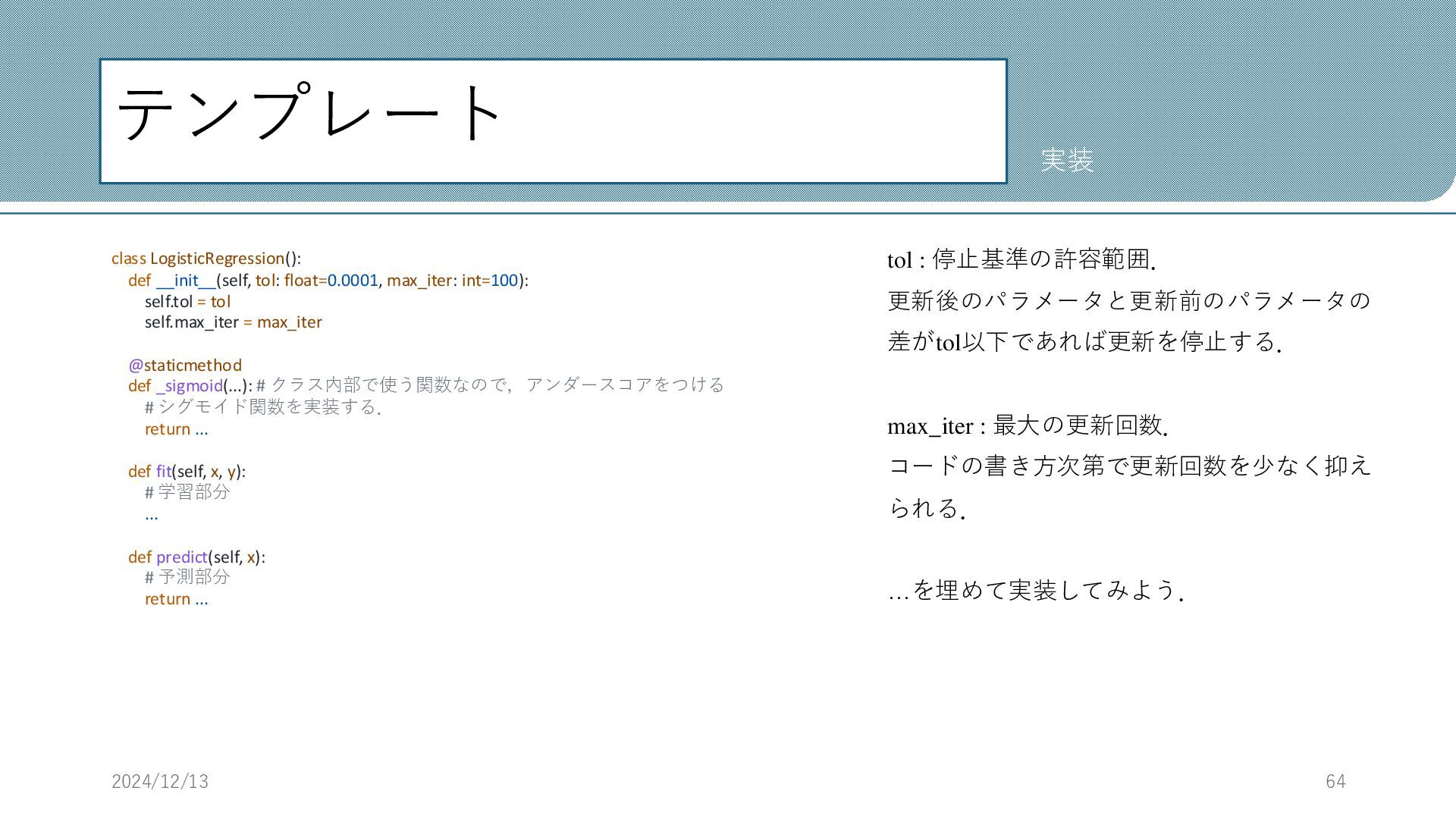
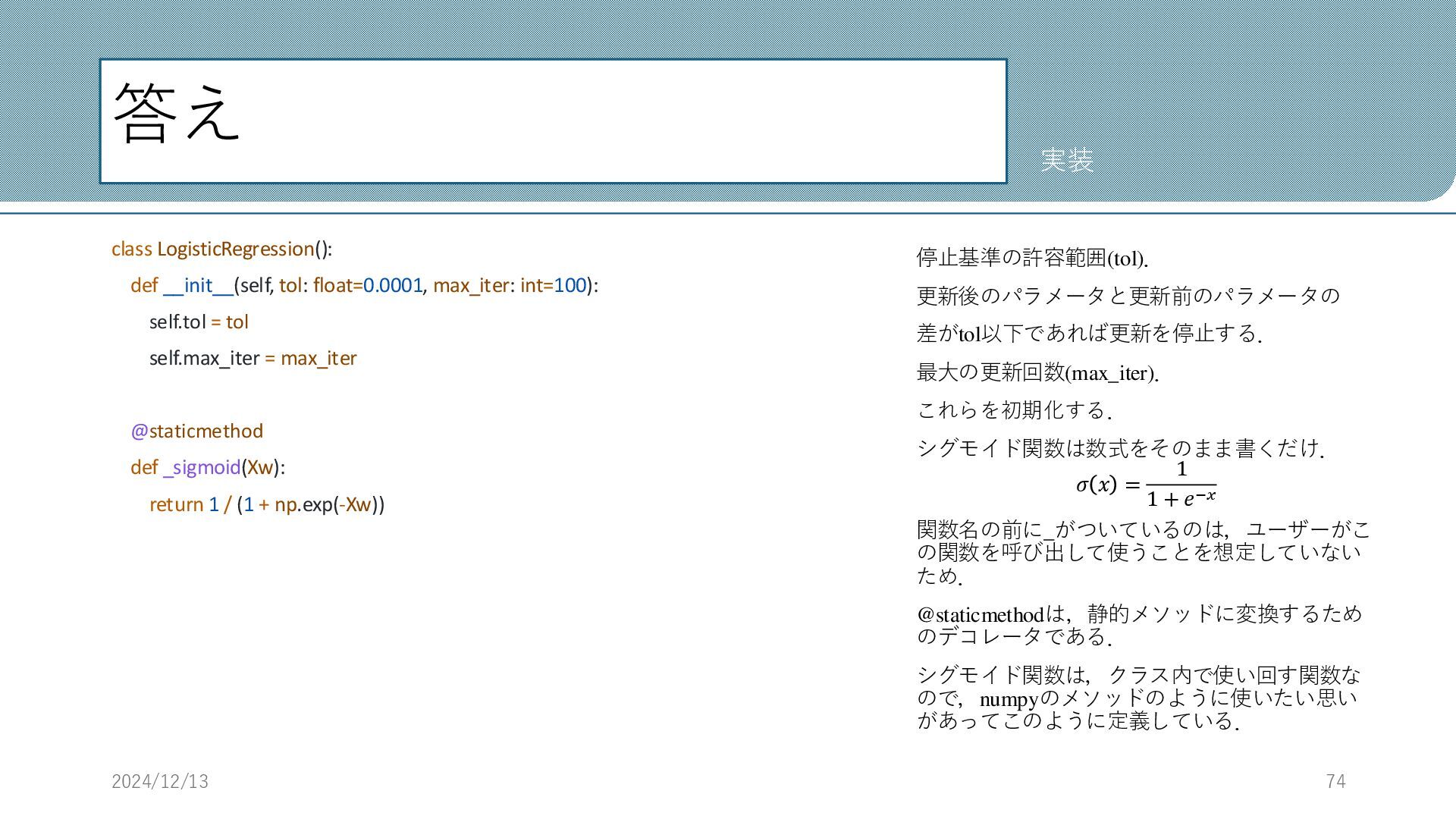
テンプレート tol : 停止基準の許容範囲. 更新後のパラメータと更新前のパラメータの 差がtol以下であれば更新を停止する. max_iter : 最大の更新回数. コードの書き方次第で更新回数を少なく抑え
られる. …を埋めて実装してみよう. 2024/12/13 64 実装 class LogisticRegression(): def __init__(self, tol: float=0.0001, max_iter: int=100): self.tol = tol self.max_iter = max_iter @staticmethod def _sigmoid(...): # クラス内部で使う関数なので,アンダースコアをつける # シグモイド関数を実装する. return ... def fit(self, x, y): # 学習部分 ... def predict(self, x): # 予測部分 return ...
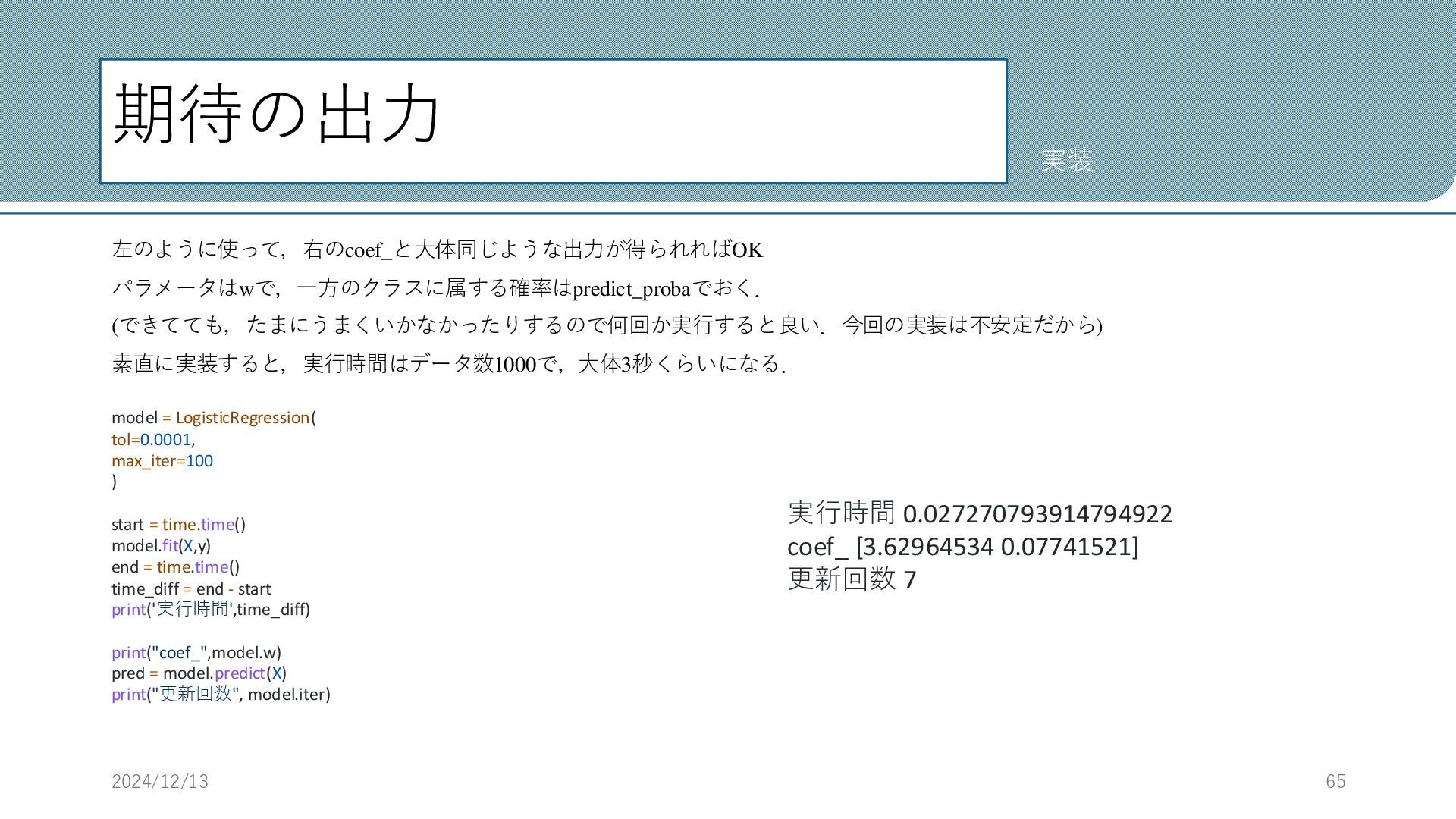
期待の出力 左のように使って,右のcoef_と大体同じような出力が得られればOK パラメータはwで,一方のクラスに属する確率はpredict_probaでおく. (できてても,たまにうまくいかなかったりするので何回か実行すると良い.今回の実装は不安定だから) 素直に実装すると,実行時間はデータ数1000で,大体3秒くらいになる. 2024/12/13 65 実装 model =
LogisticRegression( tol=0.0001, max_iter=100 ) start = time.time() model.fit(X,y) end = time.time() time_diff = end - start print('実行時間',time_diff) print("coef_",model.w) pred = model.predict(X) print("更新回数", model.iter) 実行時間 0.027270793914794922 coef_ [3.62964534 0.07741521] 更新回数 7
実装に必要な材料 シグモイド関数: 𝜎 𝑥 = 1 1 + 𝑒−𝑥 ここの𝑥は,説明変数が入るわけではないの
で注意.ただ変数として置いているだけ. 2024/12/13 66 実装 モデル: ො 𝑦 = 𝜎(𝒘𝑇𝒙) しかし, データ一つに対しての場合なので… 実際は行列にした𝑋と𝒘の内積を使う. ෝ 𝒚 = 𝜎(𝑋𝒘) 全データに対しての予測値ということ. 𝑛: データ数 𝑚: 次元数 𝒙 ∈ ℝ𝑚:説明変数 𝑋 ∈ ℝ𝑛×𝑚:説明変数(全てのデータ) 𝑦 ∈ ℝ:目的変数 𝐲 ∈ ℝ𝑛:目的変数(全てのデータ) 𝒘 ∈ ℝ𝑚:パラメータ
実装に必要な材料 学習 - パラメータや,必要な変数の初期化 - パラメータの初期化.(ランダムでOK) - 対角行列の初期化.(単位行列を作成して初期化すると良い.) - ∇𝐸
𝒘 = 0を表すのに,更新後のパラメータと更新前のパラメータとの差を利用する. その差が限りなく0に近くなっていれば収束判定,その基準はtol=0.0001で与えている. 収束判定のために,更新後のパラメータと更新前のパラメータとの差を格納するリストを初期化する. ここはnp.infで初期化すると良い.(絶対0にしたくないから.) リストと,tolを比べて,リストの要素全てがtolの値を下回ったら収束とすれば良い. - イテレーション数を初期化する.更新するごとに,+1をして更新回数を計測する. 2024/12/13 67 実装
実装に必要な材料 学習 - 更新式を回し,最適なパラメータを求める 𝒘𝑛𝑒𝑤 = 𝒘𝑜𝑙𝑑 − 𝑋𝑇𝑅𝑋 −1𝑋𝑇
ෝ 𝒚 − 𝒚 𝑅 = ො 𝑦1 1 − ො 𝑦1 ො 𝑦2 1 − ො 𝑦2 ⋱ ො 𝑦𝑛 1 − ො 𝑦𝑛 ෝ 𝒚 = 𝜎(𝑋𝒘) 2024/12/13 68 実装
実装に必要な材料 学習 - 以下の3つを更新する - 更新後のパラメータと更新前のパラメータとの差のリスト - イテレーション数(更新回数) - パラメータ
に戻って繰り返す. 収束判定は, - 更新後のパラメータと更新前のパラメータとの差のリストの全要素がtolを下回っている. or - イテレーション数(更新回数が),max_iterに達する. 2024/12/13 69 実装
実装に必要な材料 予測 - 一方のクラスに属する確率0.5を閾値に,クラスを分ける.(分類する) 2024/12/13 70 実装
ヒント+追加課題 頑張ろう!!!!!!!! 余裕のある人は実行時間が小さくするようにしてみよう. 想定されるコードの問題点は以下. - 逆行列を明示的に求めるのは安定性と早さに欠ける. - 対角行列を扱うのは時間がかかる. 2024/12/13 71
実装
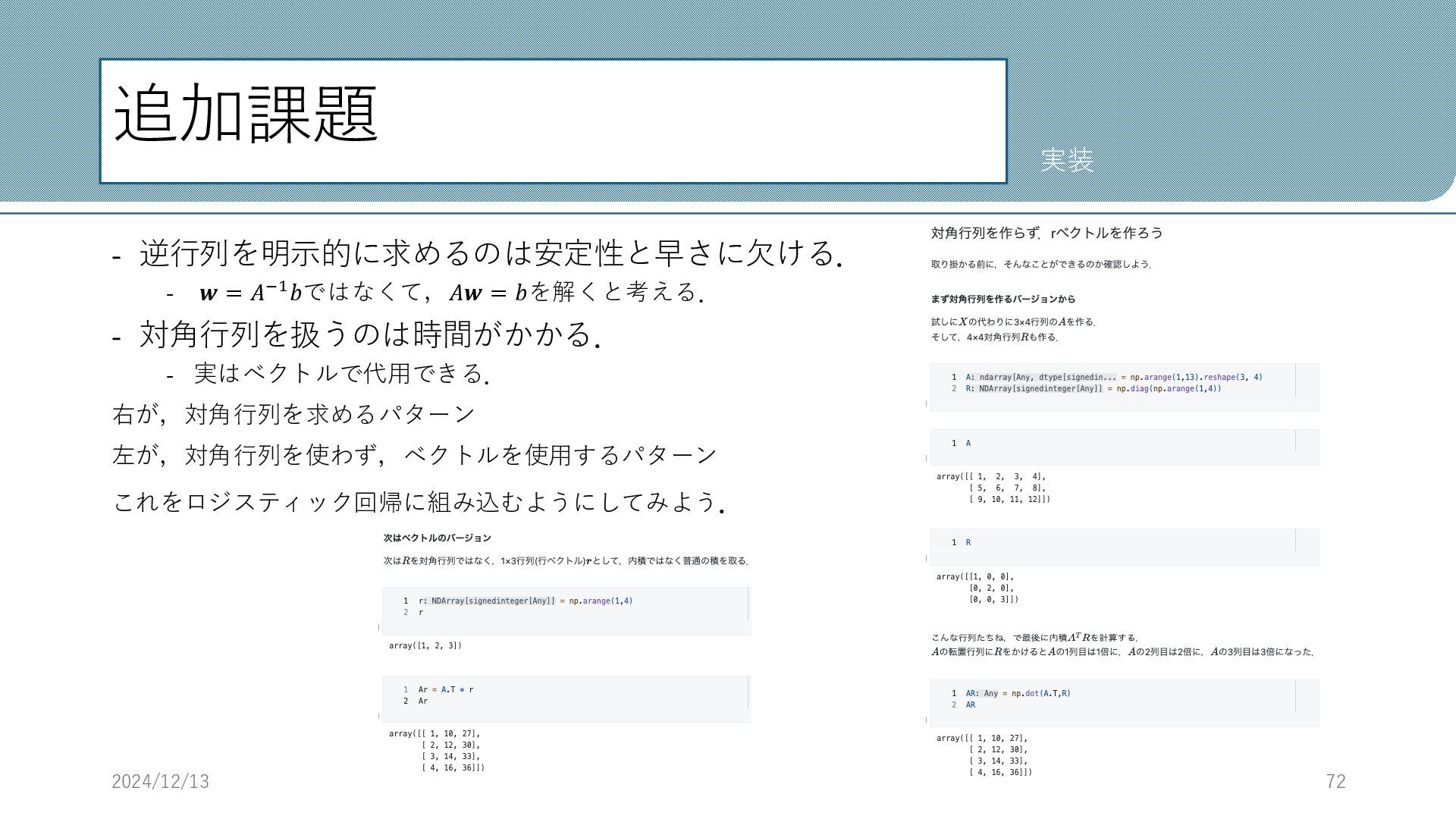
追加課題 - 逆行列を明示的に求めるのは安定性と早さに欠ける. - 𝒘 = 𝐴−1𝑏ではなくて,𝐴𝒘 = 𝑏を解くと考える. -
対角行列を扱うのは時間がかかる. - 実はベクトルで代用できる. 右が,対角行列を求めるパターン 左が,対角行列を使わず,ベクトルを使用するパターン これをロジスティック回帰に組み込むようにしてみよう. 2024/12/13 72 実装
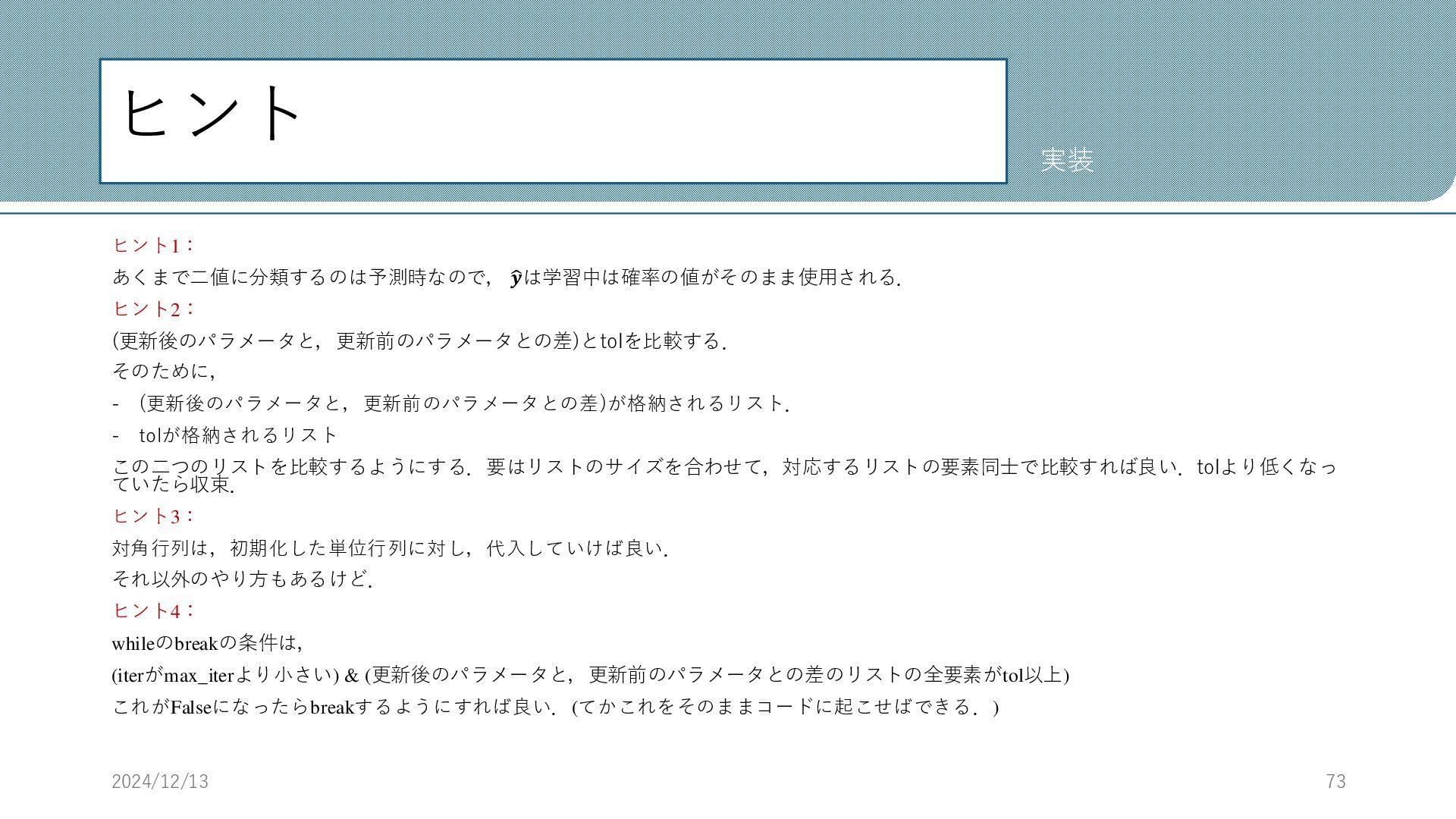
ヒント ヒント1: あくまで二値に分類するのは予測時なので, ෝ 𝒚は学習中は確率の値がそのまま使用される. ヒント2: (更新後のパラメータと,更新前のパラメータとの差)とtolを比較する. そのために, - (更新後のパラメータと,更新前のパラメータとの差)が格納されるリスト.
- tolが格納されるリスト この二つのリストを比較するようにする.要はリストのサイズを合わせて,対応するリストの要素同士で比較すれば良い.tolより低くなっ ていたら収束. ヒント3: 対角行列は,初期化した単位行列に対し,代入していけば良い. それ以外のやり方もあるけど. ヒント4: whileのbreakの条件は, (iterがmax_iterより小さい) & (更新後のパラメータと,更新前のパラメータとの差のリストの全要素がtol以上) これがFalseになったらbreakするようにすれば良い.(てかこれをそのままコードに起こせばできる.) 2024/12/13 73 実装
答え class LogisticRegression(): def __init__(self, tol: float=0.0001, max_iter: int=100): self.tol
= tol self.max_iter = max_iter @staticmethod def _sigmoid(Xw): return 1 / (1 + np.exp(-Xw)) 2024/12/13 74 実装 停止基準の許容範囲(tol). 更新後のパラメータと更新前のパラメータの 差がtol以下であれば更新を停止する. 最大の更新回数(max_iter). これらを初期化する. シグモイド関数は数式をそのまま書くだけ. 𝜎 𝑥 = 1 1 + 𝑒−𝑥 関数名の前に_がついているのは,ユーザーがこ の関数を呼び出して使うことを想定していない ため. @staticmethodは,静的メソッドに変換するため のデコレータである. シグモイド関数は,クラス内で使い回す関数な ので,numpyのメソッドのように使いたい思い があってこのように定義している.
答え def fit(self, x, y): self.w = np.random.randn(x.shape[1]) tol_vec =
np.full(x.shape[1],self.tol) diff = np.full(x.shape[1], np.inf) self.iter = 0 while np.any(diff > tol_vec) and (self.iter < self.max_iter): y_hat = self._sigmoid(x @ self.w) R = np.diag(y_hat * (1 - y_hat)) w_new = self.w - (np.linalg.pinv((x.T @ R) @ x) @ x.T @ (y_hat - y)) diff = w_new - self.w self.iter += 1 self.w = w_new 2024/12/13 75 実装 重み(w),停止基準のベクトル (tol_vec),重みの差分を保存する ためのベクトル(diff),更新回数 (iter)を初期化する. while文の条件は, 重みの差分が停止基準を下回る か,更新回数が最大更新回数を超 える. に設定する. 予測値を算出する.(y_hat) 対角行列を作る.(R) 更新式をそのまま書く. 𝒘𝑛𝑒𝑤 = 𝒘𝑜𝑙𝑑 − 𝑋𝑇𝑅𝑋 −1𝑋𝑇 ෝ 𝒚 − 𝒚 最後にdiff,iter,w を更新する.
答え def predict(self, x): y_hat_Xw = np.dot(x, self.w) y_pred =
self._sigmoid(y_hat_Xw) for _ in range(x.shape[0]): if y_pred[_] > 0.5: y_pred[_] = 1 elif y_pred[_] < 0.5: y_pred[_] = 0 return y_pred 2024/12/13 76 実装 予測値を算出する.(y_pred)この時点では確率. ここから0と1に分類する. 算出した予測値に対し,確率0.5より上であればクラス1に, 下であればクラス0に分類する.
追加課題の答え def fit(self, x, y): self.w = np.random.randn(x.shape[1]) tol_vec =
np.full(x.shape[1],self.tol) diff = np.full(x.shape[1], np.inf) self.iter = 0 while np.any(diff > tol_vec) and (self.iter < self.max_iter): y_hat = self._sigmoid(x @ self.w) R = np.diag(y_hat * (1 - y_hat)) # w_new = self.w - (np.linalg.pinv((x.T @ R) @ x) @ x.T @ (y_hat - y)) w_new = self.w - (np.linalg.solve(((x.T @ R) @ x), x.T @ (y_hat - y))) diff = w_new - self.w self.iter += 1 self.w = w_new 2024/12/13 77 実装 方程式を解く.という解釈で 実装すると,np.linalg.solveと いうメソッドを使って,明示 的に擬似逆行列を使わずに実 装できる. (実際にはsolveメソッドが臨 機応変に対応してくれるだ け.)
追加課題の答え def fit(self, x, y): self.w = np.random.randn(x.shape[1]) tol_vec =
np.full(x.shape[1],self.tol) diff = np.full(x.shape[1], np.inf) self.iter = 0 while np.any(diff > tol_vec) and (self.iter < self.max_iter): y_hat = self._sigmoid(x @ self.w) # R = np.diag(y_hat * (1 - y_hat)) r = y_hat * (1 - y_hat) # w_new = self.w - (np.linalg.solve(((x.T @ R) @ x), x.T @ (y_hat - y))) w_new = self.w - (np.linalg.solve(((x.T * r) @ x), x.T @ (y_hat - y))) diff = w_new - self.w self.iter += 1 self.w = w_new 2024/12/13 78 実装 対角行列をベクトルで代用す ると,行列演算が一個減るの で,大幅に実行時間を削減で きる. その代わり安定性に欠ける. (気がする.)
参考 • 加藤公一, 機械学習のエッセンス, SBクリエイティブ, (出版:2018/9/21) • C.M. ビショップ (著),
元田 浩 (監訳), 栗田 多喜夫 (監訳), 樋口 知之 (監訳), 松本 裕治 (監訳), 村田 昇 (監訳), パターン認識と機械学習 上, 丸善出版, (出版:2012/01/20) • からっぽのしょこ, 4.3.2-3:ロジスティック回帰の導出【PRMLのノート】, (参照:2025/3/29) • 高校数学の美しい物語, ヤコビ行列,ヤコビアンの定義と極座標の例, (参照:2025/3/29) • ウィキペディア, ヤコビ行列, (参照2025/3/29) • AnchorBlues(Yu Umegaki), 「ベクトルで微分・行列で微分」公式まとめ, (参照:2025/3/29) • 高校数学の美しい物語, ベクトルの微分, (参照2025/3/29) 2024/12/13 79 実装
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![答え def fit(self, x, y): self.w = np.random.randn(x.shape[1]) tol_vec =](https://files.speakerdeck.com/presentations/ebf4455fd4d94110a47e2eb42bad5ad4/slide_74.jpg){kind=link}
{kind=link}
![追加課題の答え def fit(self, x, y): self.w = np.random.randn(x.shape[1]) tol_vec =](https://files.speakerdeck.com/presentations/ebf4455fd4d94110a47e2eb42bad5ad4/slide_76.jpg){kind=link}
![追加課題の答え def fit(self, x, y): self.w = np.random.randn(x.shape[1]) tol_vec =](https://files.speakerdeck.com/presentations/ebf4455fd4d94110a47e2eb42bad5ad4/slide_77.jpg){kind=link}
{kind=link}