Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
深層生成モデルによるメディア生成
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Hirokazu Kameoka
February 07, 2020
Research
2.5k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
深層生成モデルによるメディア生成
筑波大学
社会工学ファシリテーター育成プログラム「メディア生成AI」
講義資料(修正版)
Hirokazu Kameoka
February 07, 2020
Other Decks in Research
See All in Research
SLAMはどこまで解決されたのか?
tomonom
0
770
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
240
typst の使い方:言語学を研究する学生のために
gitomochang
0
510
「車1割削減、渋滞半減、公共交通2倍」を 熊本から岡山へ@RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
1
1.3k
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4k
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
580
Using our influence and power for patient safety
helenbevan
0
370
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
110
LLM Compute Infrastructure Overview
karakurist
2
1.5k
羽田新ルート運用6年の検証
1manken
0
170
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
690
Featured
See All Featured
Producing Creativity
orderedlist
PRO
348
40k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
63
55k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
Statistics for Hackers
jakevdp
799
230k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
330
Transcript
深層生成モデルによる メディア(画像・音声)生成 亀岡弘和 日本電信電話株式会社 NTTコミュニケーション科学基礎研究所
[email protected]
筑波大学大学院システム情報工学研究科社会工学専攻 社会工学ファシリテーター育成プログラム「メディア生成AI」 2020年 1/17(金)
14:00‐18:00, 1/24(金) 14:00‐18:00, 2/7(金) 14:00‐18:00
自己紹介 亀岡弘和(かめおかひろかず) 略歴: 2007 東京大学大学院情報理工学系研究科 システム情報学専攻 博士課程修了 2007 日本電信電話株式会社入社 NTTコミュニケーション科学基礎研究所配属
2011 東京大学大学院情報理工学系研究科 システム情報学専攻 客員准教授 2015 NTTコミュニケーション科学基礎研究所 特別研究員 2016 国立情報学研究所 客員准教授 2019 筑波大学大学院システム情報工学研究科 客員准教授 専門: 音声・音楽などの音響信号を対象とした信号処理や機械学習 計算論的聴覚情景分析,音源分離,音声合成・変換など
本講義の目的と目標 深層学習(AI)研究に触れる 深層学習(AI)の研究の面白さや凄さを体感する 特に深層生成モデルと呼ぶ近年発展が著しい分野を扱う 温故知新(故きを温ねて新しきを知る) 深層生成モデルと古典的な確率モデルの関連を理解する
古典的な確率モデルがベースにする普遍的な考え方を学ぶ 信号処理の基礎を学ぶ プログラミングに触れる 簡単なプログラミングの演習を通して,信号やデータの扱いに 慣れ,確率モデルを用いた各種処理を実装する
深層生成モデル (Deep Generative Models) 深層学習×生成モデル=深層生成モデル ニューラルネットワークの能力を活かして極めてリアルな データ(画像や音声など)の生成を可能にする確率モデル 代表例
自己回帰生成ネットワーク (AutoregressiveGenerativeNetwork) 変分自己符号化器 (VariationalAutoEncoder) フローベース生成モデル (Flow‐based Generative Model) 敵対的生成ネットワーク (GenerativeAdversarialNetwork)
VAEによるランダム顔画像生成 [Kingma+2014] 画像サンプルは下記サイトより https://github.com/podgorskiy/VAE 学習データ 学習した確率モデルからランダム生成した画像
Crossmodal Voice/Face Synthesis [Kameoka+2018] VAEによる声からの顔予測と顔からの声質予測 入力音声のみから 話者の顔を予測する 入力音声の声質を、 入力顔画像に合わせて変換する 音声・画像サンプルは下記サイトより
http://www.kecl.ntt.co.jp/people/kameoka.hirokazu/Demos/crossmodal‐vc/index.html
テキスト音声合成(テキストのみから音声を生成)のサンプル 音声波形のランダム生成 WaveNet (AGN) による音声波形生成 [van den Oord+2016] 音声サンプルは下記サイトより https://deepmind.com/blog/article/wavenet‐generative‐model‐raw‐audio
DNN音声合成 [Zen+2013] WaveNet 英語音声で学習した WaveNetより生成した波形 ピアノ曲で学習した WaveNetより生成した波形
Flowによるランダム顔画像生成 [Kingma+2018] 画像サンプルは下記サイトより https://openai.com/blog/glow/ Glowと呼ぶ方式による生成例
GANによるランダム顔画像生成 [Goodfellow+2014, Karras+2019] 画像サンプルは下記サイトより無限に生成可能 https://thispersondoesnotexist.com/ NVIDIAが開発したStyleGANと呼ぶ方式による生成例
本講義の目的と目標 深層学習(AI)研究に触れる 深層学習(AI)の研究の面白さや凄さを体感する 特に深層生成モデルと呼ぶ近年発展が著しい分野を扱う 温故知新(故きを温ねて新しきを知る) 深層生成モデルと古典的な確率モデルの関連を理解する
古典的な確率モデルがベースにする普遍的な考え方を学ぶ 信号処理の基礎を学ぶ プログラミングに触れる 簡単なプログラミングの演習を通して,信号やデータの扱いに 慣れ,確率モデルを用いた各種処理を実装する
講義内容 深層生成モデルの実応用例の紹介 深層生成モデルと古典的な確率モデルの関連 自己回帰生成ネット (AGN) vs 自己回帰モデル (AutoRegressive model)
変分自己符号化器 (VAE) vs 主成分分析 (Principal Component Analysis ) フローベース生成モデル (Flow) vs 独立成分分析 (Independent Component Analysis ) 古典的確率モデルのおさらい ARモデル(=線形予測分析),PCA,ICA プログラミング演習 ニューラルネットワークの基礎 深層生成モデルのアイディアの解説 AGN (WaveNet),VAE,Flow,敵対的生成ネット (GAN)
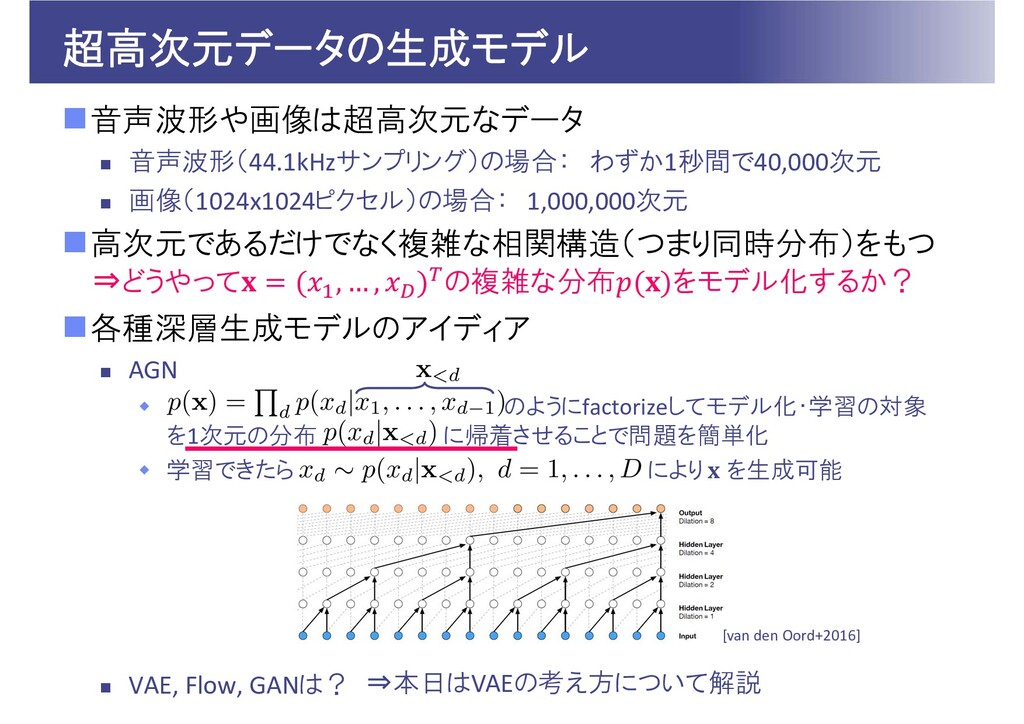
超高次元データの生成モデル 音声波形や画像は超高次元なデータ 音声波形(44.1kHzサンプリング)の場合: わずか1秒間で40,000次元 画像(1024x1024ピクセル)の場合: 1,000,000次元 高次元であるだけでなく複雑な相関構造(つまり同時分布)をもつ 各種深層生成モデルのアイディア
AGN VAE Flow GAN ⇒どうやって , … , の複雑な分布 をモデル化するか? 本講義でそれぞれの考え方を解説
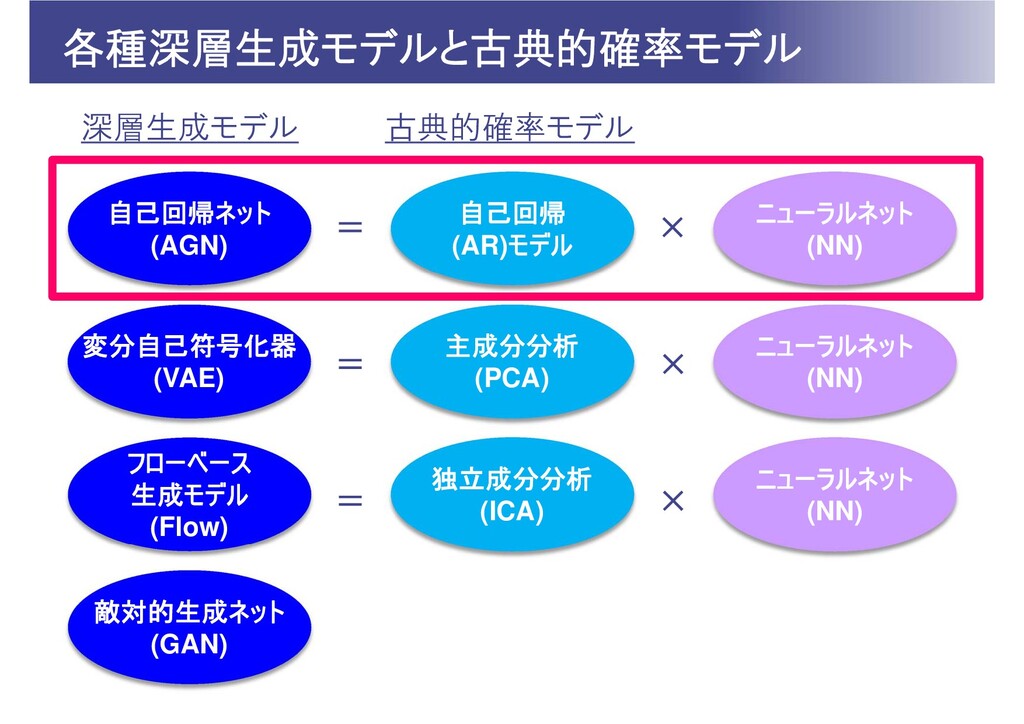
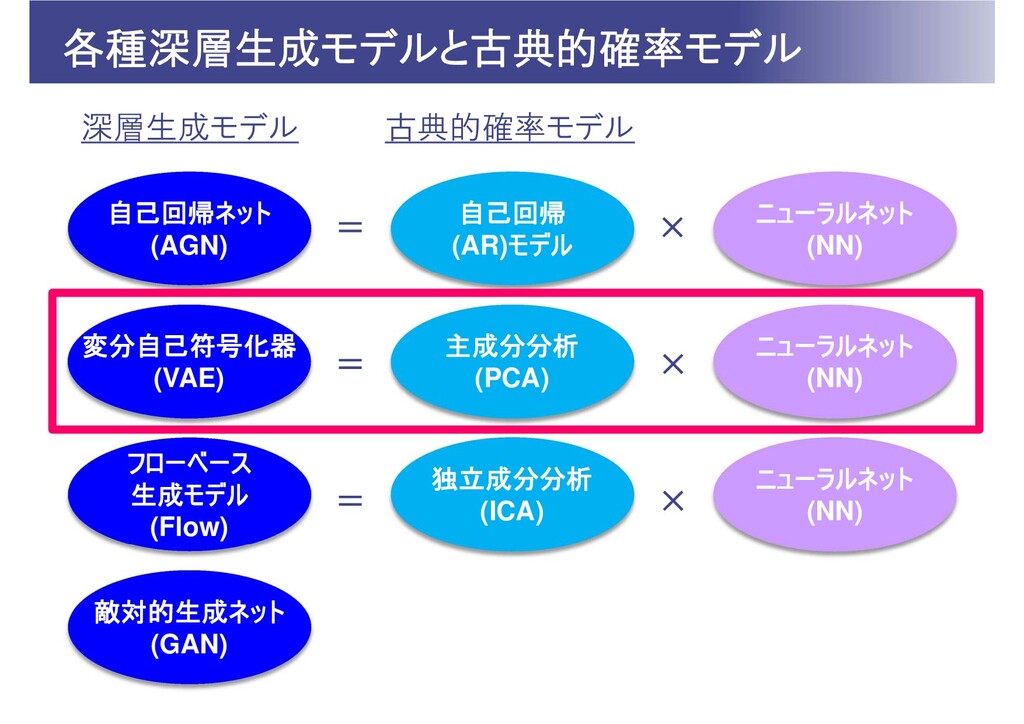
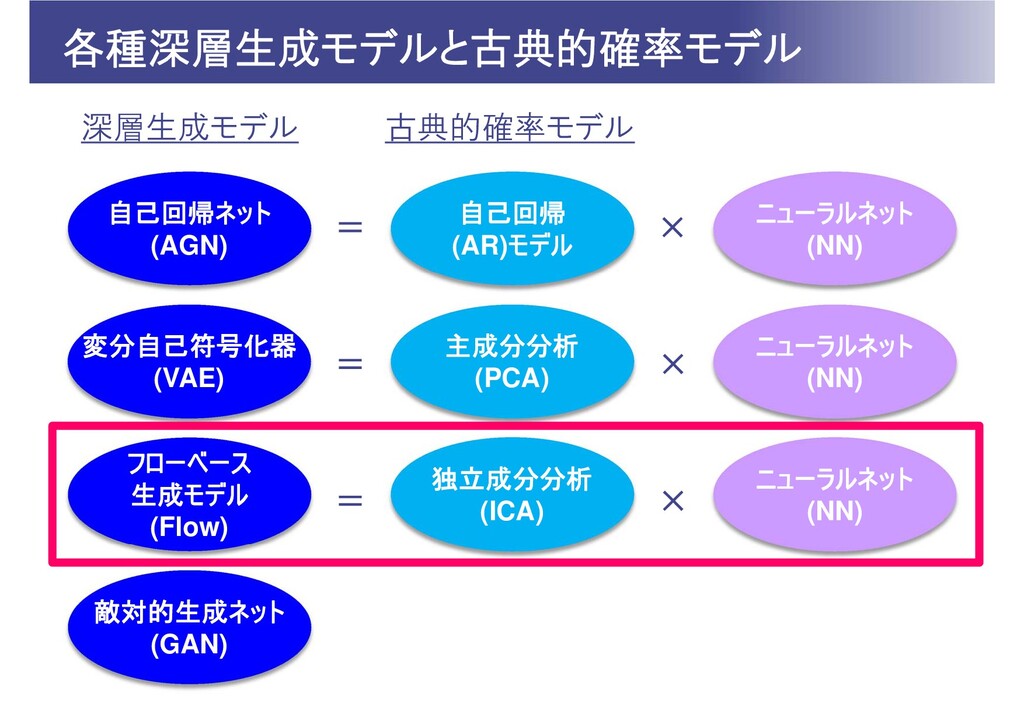
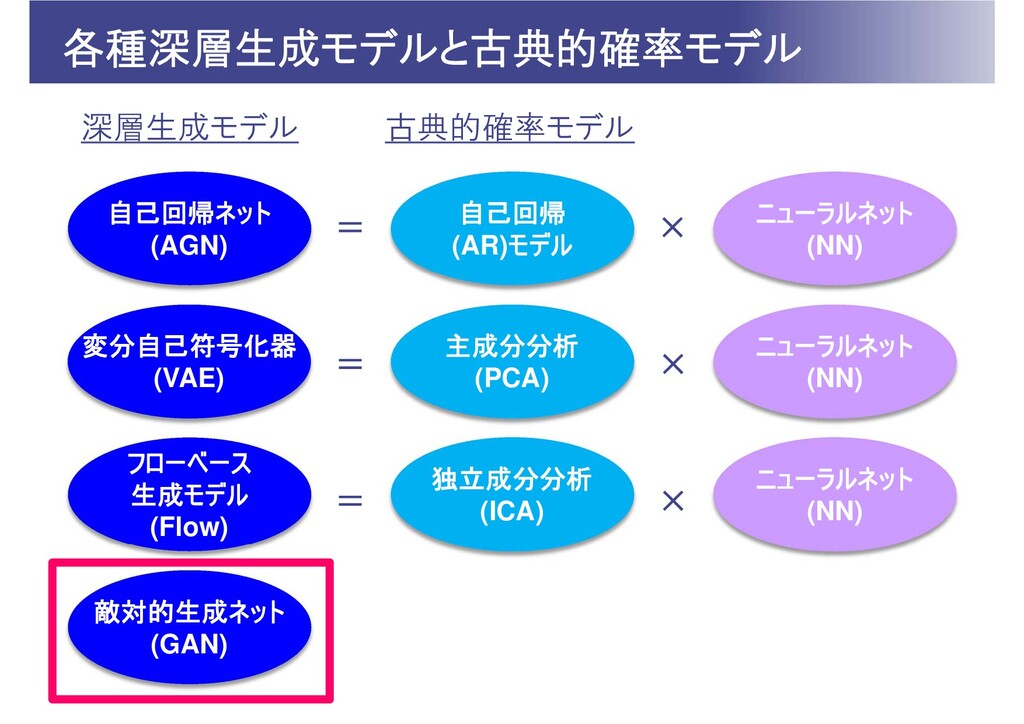
各種深層生成モデルと古典的確率モデル 敵対的生成ネット (GAN) 自己回帰ネット (AGN) 自己回帰 (AR)モデル ニューラルネット (NN) 変分自己符号化器
(VAE) 主成分分析 (PCA) ニューラルネット (NN) フローベース 生成モデル (Flow) 独立成分分析 (ICA) ニューラルネット (NN) 深層生成モデル 古典的確率モデル
ニューラルネットワークの基礎 自己回帰(AutoRegressive)モデル 線形予測分析
線形予測分析 (LinearPrediction) ARモデルを用いた音声信号の分析法 音声情報処理研究の歴史の幕開けとなった信号処理技術 (統計的手法を取り入れた初めての音声研究として有名) 音声分析合成(ボコーダ) 音声音響符号化
音声認識のための音声特徴量 音声強調(残響除去、ブラインド音声分離) などへの応用 日本発の技術としても知られる Levinson‐Durbin‐板倉アルゴリズム、偏自己相関(PARCOR)、線ス ペクトル対(Line Spectrum Pair) の発明や板倉齋藤距離 の発見など、板倉文忠氏(名古屋大学名誉教授)の 電電公社時代の活躍が世界的に有名
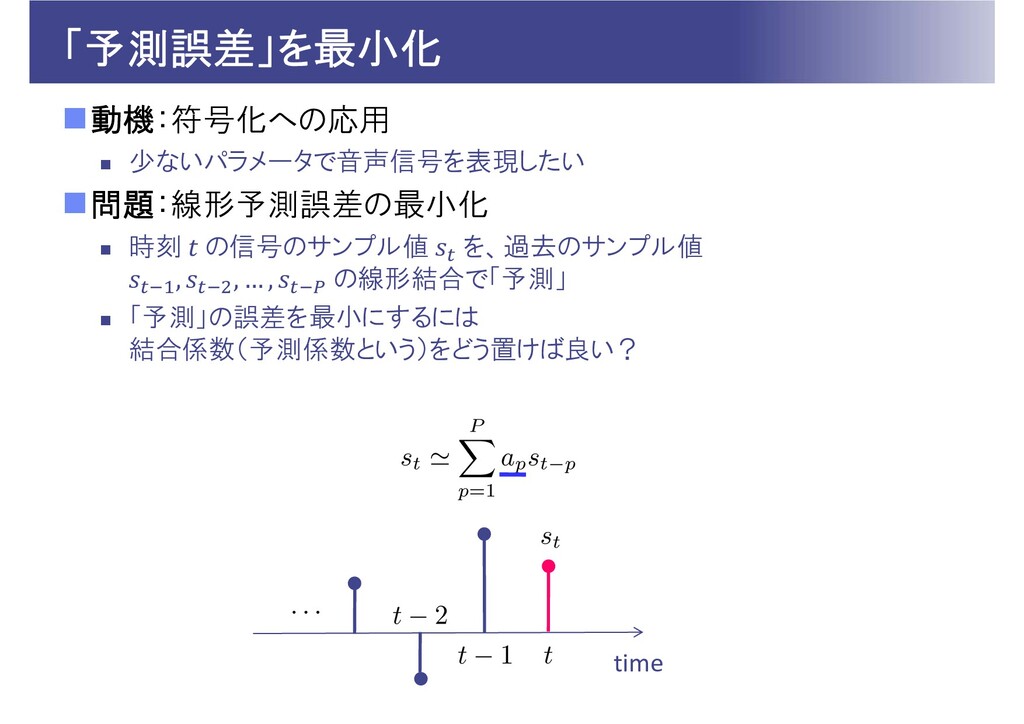
「予測誤差」を最小化 動機:符号化への応用 少ないパラメータで音声信号を表現したい 問題:線形予測誤差の最小化 時刻 の信号のサンプル値 を、過去のサンプル値 ,
, … , の線形結合で「予測」 「予測」の誤差を最小にするには 結合係数(予測係数という)をどう置けば良い? time
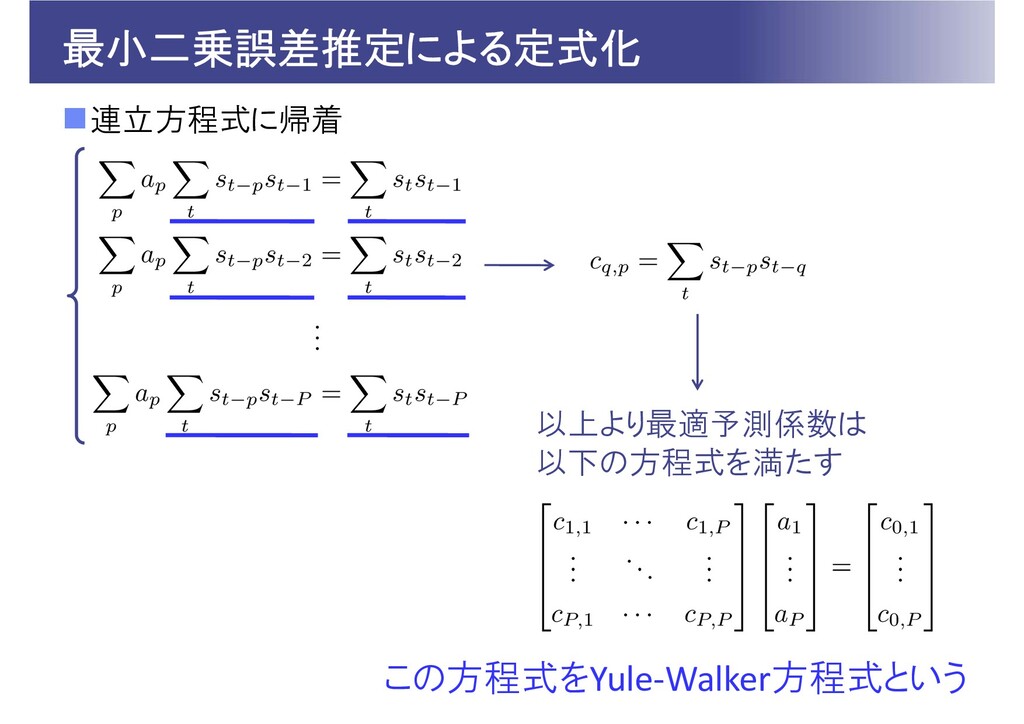
最小二乗誤差推定による定式化 問題:すべての で となる を求めたい 目的関数 最小解では を満たすため・・・
最小二乗誤差推定による定式化 連立方程式に帰着 以上より最適予測係数は 以下の方程式を満たす この方程式をYule‐Walker方程式という
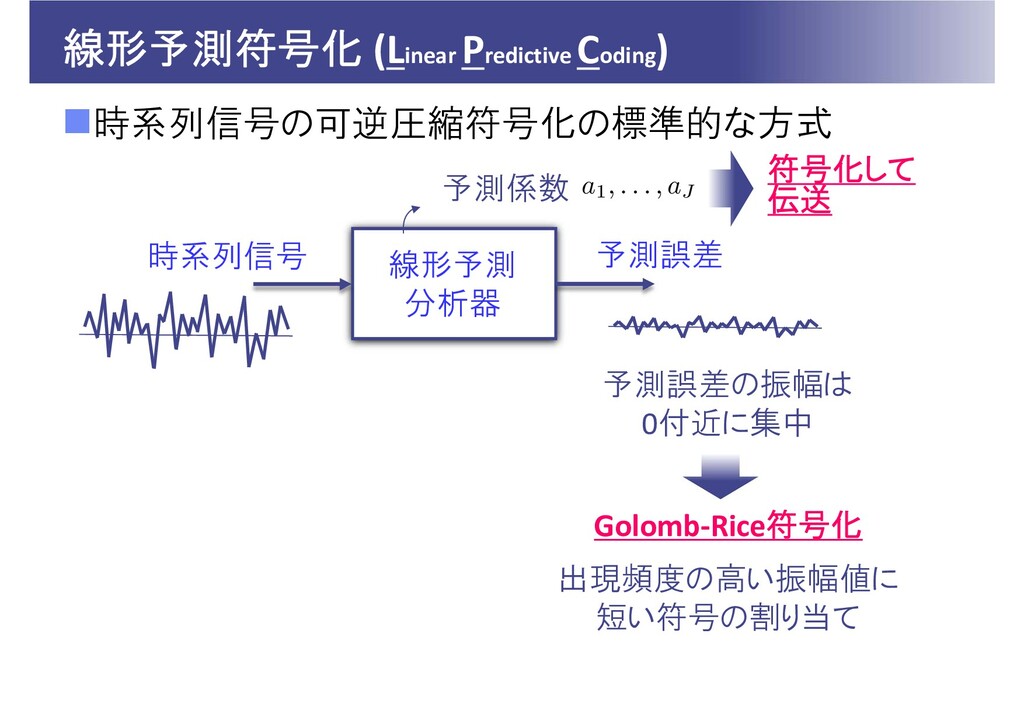
線形予測符号化 (Linear Predictive Coding) 時系列信号の可逆圧縮符号化の標準的な方式 時系列信号 予測係数 予測誤差 Golomb‐Rice符号化 符号化して
伝送 線形予測 分析器 出現頻度の高い振幅値に 短い符号の割り当て 予測誤差の振幅は 0付近に集中
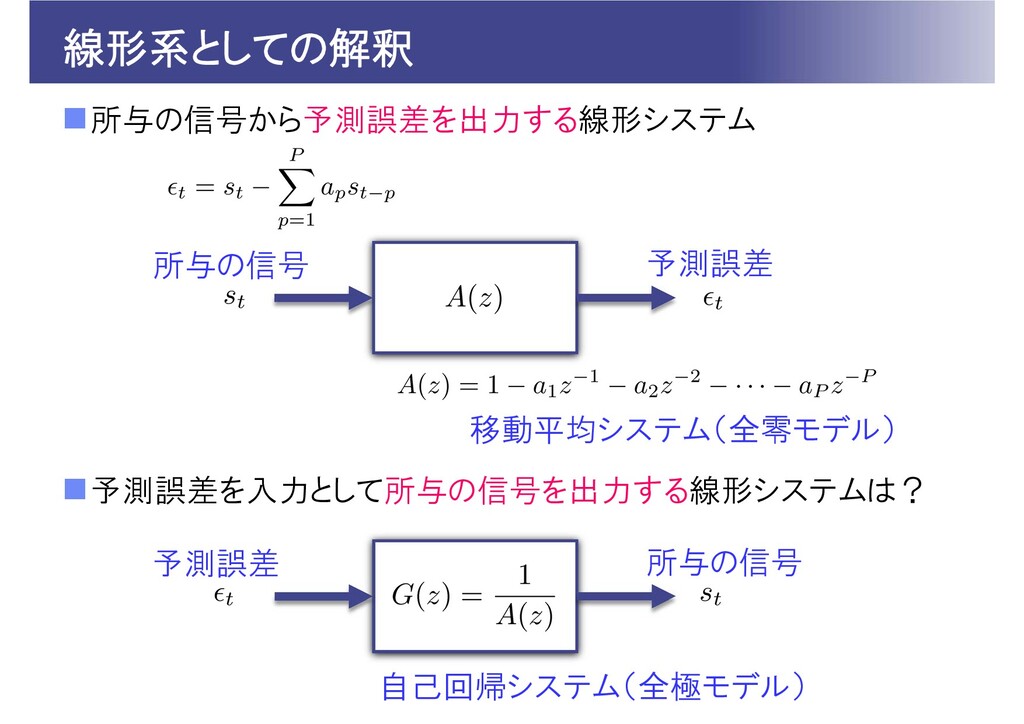
線形系としての解釈 所与の信号から予測誤差を出力する線形システム 予測誤差を入力として所与の信号を出力する線形システムは? 所与の信号 予測誤差 移動平均システム(全零モデル) 予測誤差 所与の信号 自己回帰システム(全極モデル)
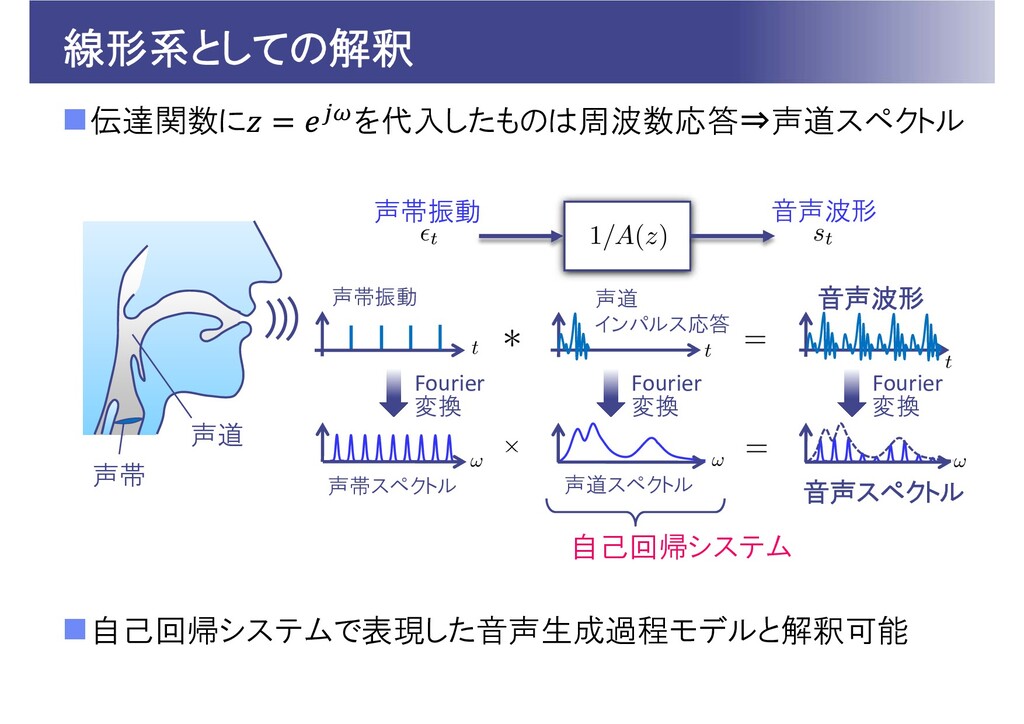
線形系としての解釈 伝達関数に を代入したものは周波数応答⇒声道スペクトル 自己回帰システムで表現した音声生成過程モデルと解釈可能 音声波形 声道 インパルス応答 声帯振動 Fourier 変換
Fourier 変換 Fourier 変換 声帯スペクトル 声道スペクトル 音声スペクトル 声帯振動 音声波形 自己回帰システム 声帯 声道
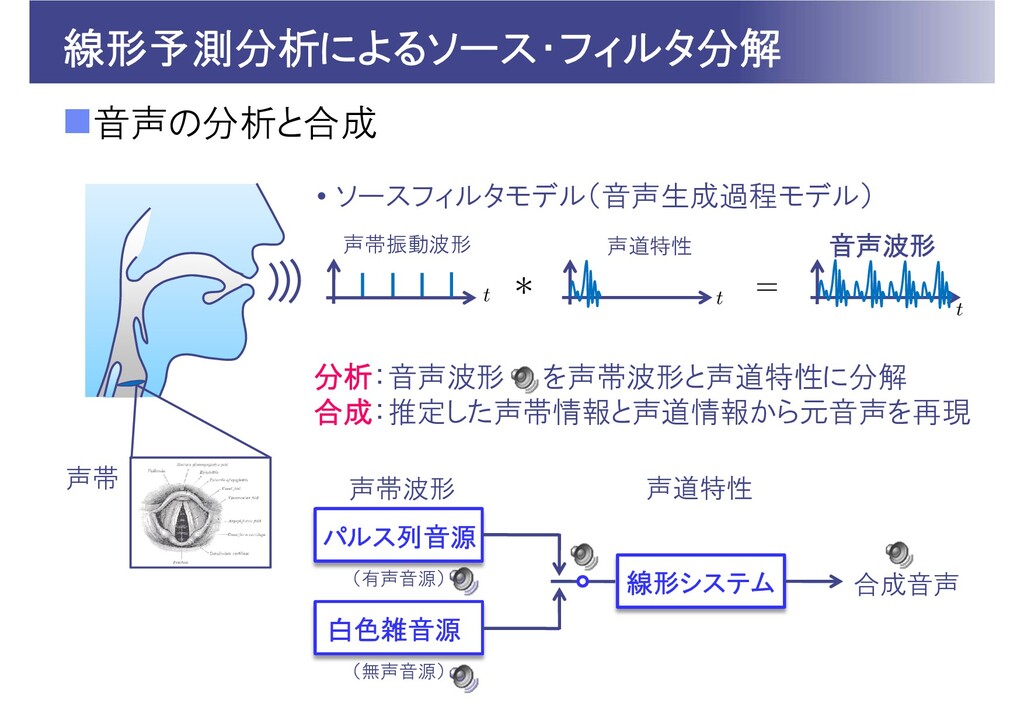
線形予測分析によるソース・フィルタ分解 音声の分析と合成 声帯 音声波形 声道特性 声帯振動波形 • ソースフィルタモデル(音声生成過程モデル) パルス列音源 白色雑音源
声帯波形 線形システム 合成音声 声道特性 (有声音源) (無声音源) 分析:音声波形 を声帯波形と声道特性に分解 合成:推定した声帯情報と声道情報から元音声を再現
WaveNet(ニューラルボコーダ)の登場 [van den Oord+2016] 線形方式から非線形方式へ 線形予測分析 ニューラルネットの導入 ⇔
where 過去サンプルの線形結合 (モデルとしての表現力は限定的) ガウス分布 where , … , , を入力として の分布を出力するニューラルネット を表す
WaveNet [van den Oord+2016] 最近DeepMindにより発表された高品質音声合成方式 アイディアのポイント 波形のサンプルごとの自己回帰型生成モデル 量子化された離散振幅値の条件付確率分布を畳み込みニューラルネット
(ConvolutionalNeuralNetwork)でモデル化
WaveNet [van den Oord+2016] 振幅の量子化 ( ‐law符号化) 条件付分布のモデル化 Causal
Conv Gated CNN Residual Net Dilated Conv WaveNetは高品質 だが を もとに1サンプルずつ 逐次生成するため、 波形生成に時間が かかるのが難点 振幅を256個の離散値に量子化 ( 層目) 時刻 より前の 個の振幅値系列 , ⋯ , s , s を入力 の離散分布 (256次元)を出力
WaveNet [van den Oord+2016] 下記ページよりWaveNetの音声サンプルを聴くことが可能 https://deepmind.com/blog/article/wavenet‐generative‐model‐raw‐audio
各種深層生成モデルと古典的確率モデル 敵対的生成ネット (GAN) 自己回帰ネット (AGN) 自己回帰 (AR)モデル ニューラルネット (NN) 変分自己符号化器
(VAE) 主成分分析 (PCA) ニューラルネット (NN) フローベース 生成モデル (Flow) 独立成分分析 (ICA) ニューラルネット (NN) 深層生成モデル 古典的確率モデル
超高次元データの生成モデル 音声波形や画像は超高次元なデータ 音声波形(44.1kHzサンプリング)の場合: わずか1秒間で40,000次元 画像(1024x1024ピクセル)の場合: 1,000,000次元 高次元であるだけでなく複雑な相関構造(つまり同時分布)をもつ 各種深層生成モデルのアイディア
AGN のようにfactorizeしてモデル化・学習の対象 を1次元の分布 に帰着させることで問題を簡単化 学習できたら により を生成可能 VAE, Flow, GANは? ⇒どうやって , … , の複雑な分布 をモデル化するか? [van den Oord+2016] ⇒本日はVAEの考え方について解説
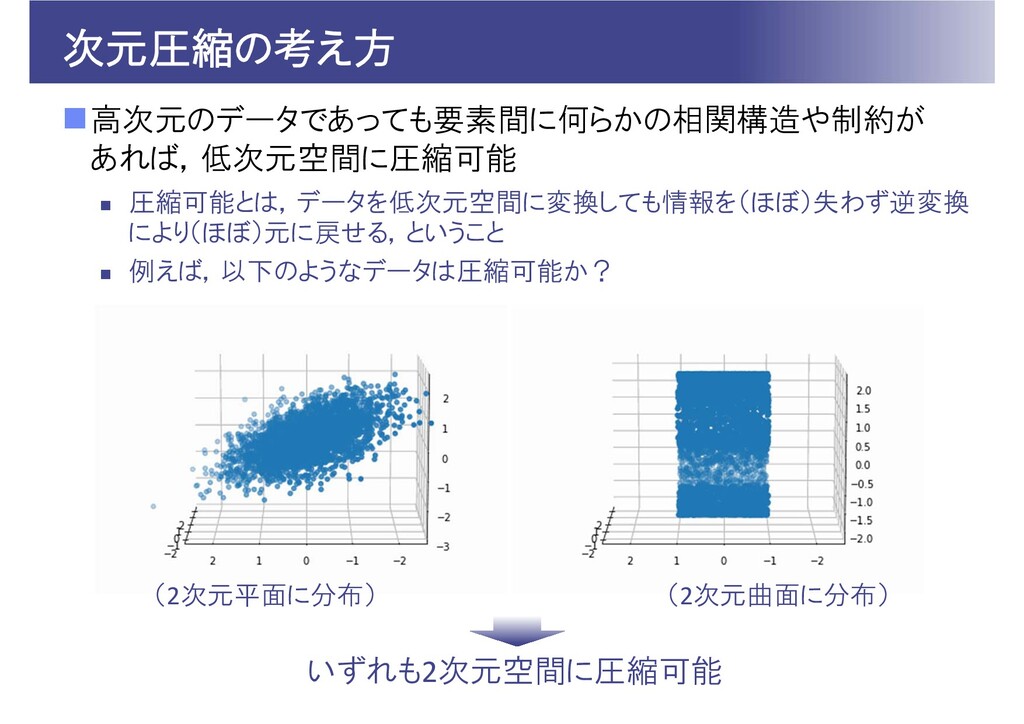
次元圧縮の考え方 高次元のデータであっても要素間に何らかの相関構造や制約が あれば,低次元空間に圧縮可能 圧縮可能とは,データを低次元空間に変換しても情報を(ほぼ)失わず逆変換 により(ほぼ)元に戻せる,ということ 例えば,以下のようなデータは圧縮可能か? いずれも2次元空間に圧縮可能 (2次元平面に分布)
(2次元曲面に分布)
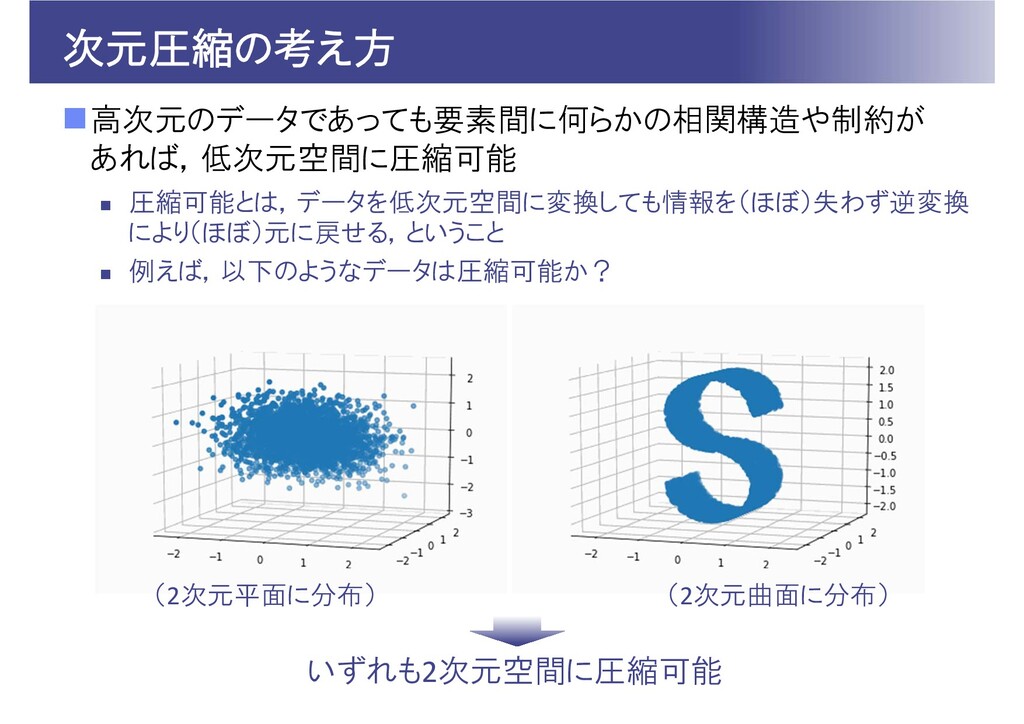
次元圧縮の考え方 高次元のデータであっても要素間に何らかの相関構造や制約が あれば,低次元空間に圧縮可能 圧縮可能とは,データを低次元空間に変換しても情報を(ほぼ)失わず逆変換 により(ほぼ)元に戻せる,ということ 例えば,以下のようなデータは圧縮可能か? いずれも2次元空間に圧縮可能 (2次元平面に分布)
(2次元曲面に分布)
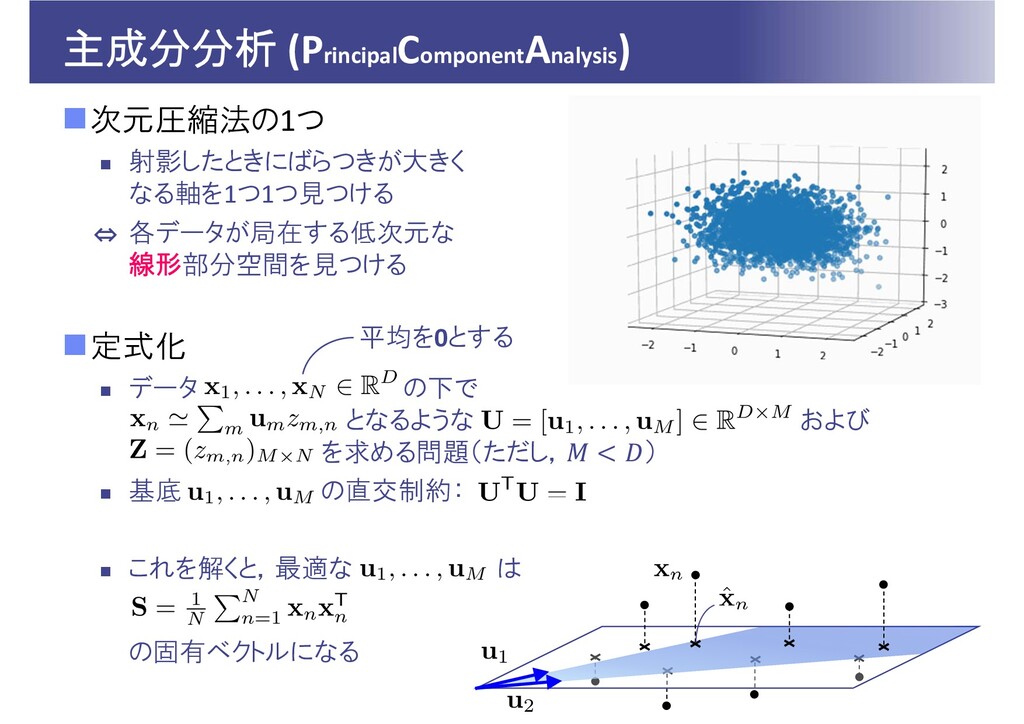
次元圧縮法の1つ 射影したときにばらつきが大きく なる軸を1つ1つ見つける 各データが局在する低次元な 線形部分空間を見つける 定式化 データ
の下で となるような および を求める問題(ただし, ) 基底 の直交制約: これを解くと,最適な は の固有ベクトルになる 主成分分析 (PrincipalComponentAnalysis) ⇔ 平均を0とする
主成分分析 (PrincipalComponentAnalysis) まず, これを に代入 (低次元空間への直交射影)
主成分分析 (PrincipalComponentAnalysis) の最適化問題 ノルム制約条件を考慮したラグランジュ関数 を に関して偏微分して0と置くと 固有値問題に帰着
PCAの生成モデル的解釈 データ の生成プロセス の最尤推定 低次元& 無相関 高次元& 相関あり がPCAに相当[Tipping1999]
潜在変数 空間
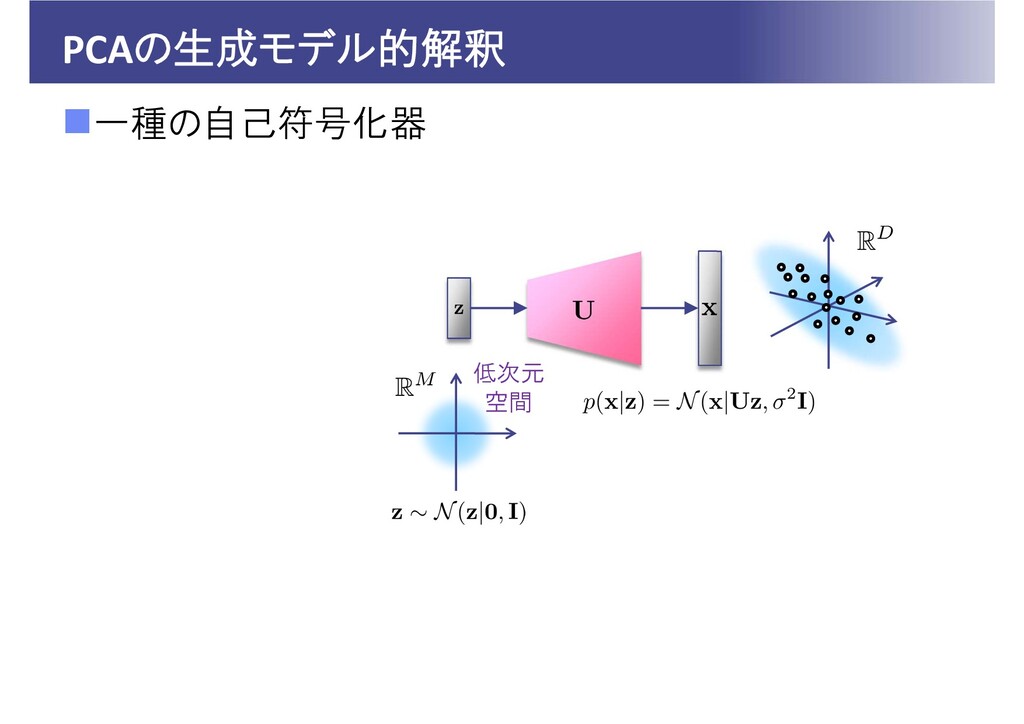
PCAの生成モデル的解釈 一種の自己符号化器 低次元 空間
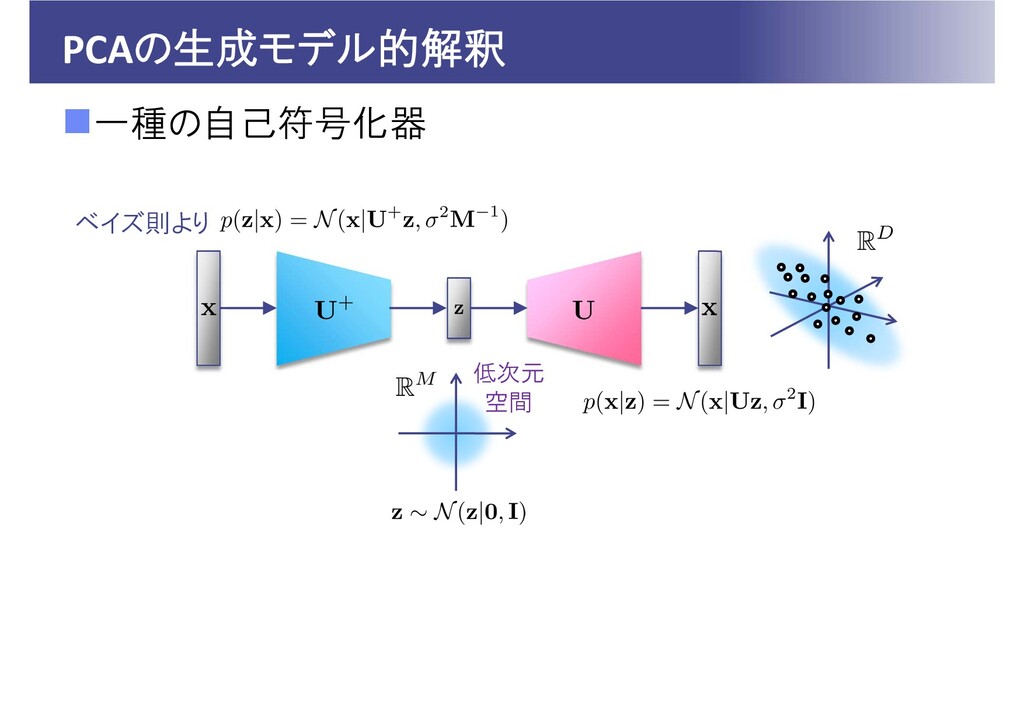
PCAの生成モデル的解釈 一種の自己符号化器 低次元 空間 ベイズ則より
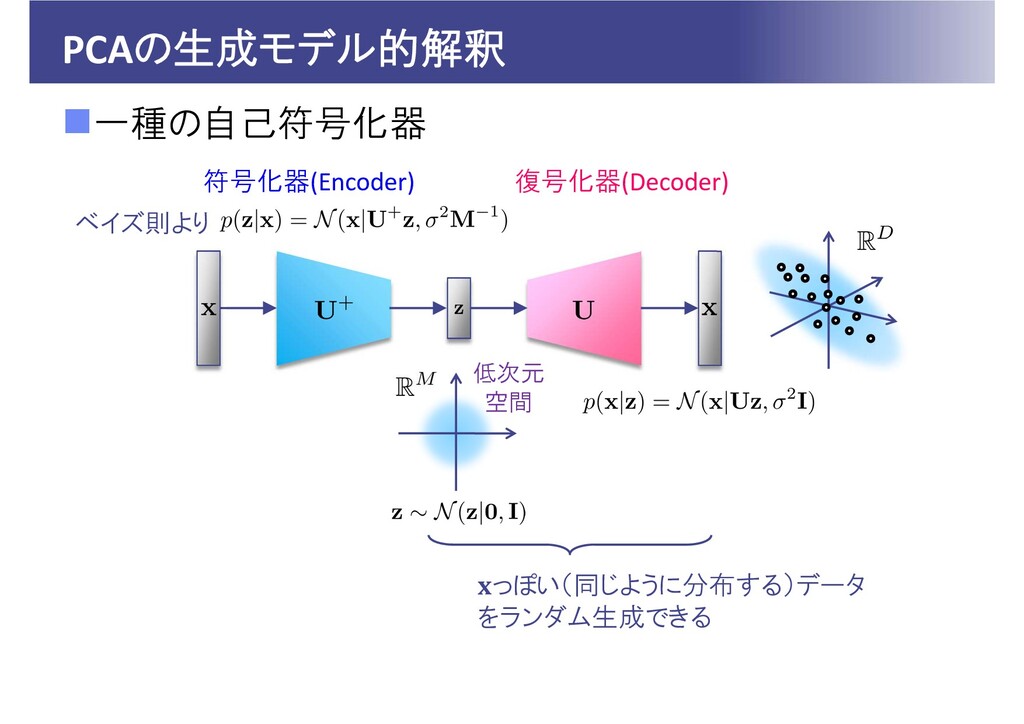
PCAの生成モデル的解釈 一種の自己符号化器 低次元 空間 符号化器(Encoder) 復号化器(Decoder) っぽい(同じように分布する)データ をランダム生成できる ベイズ則より
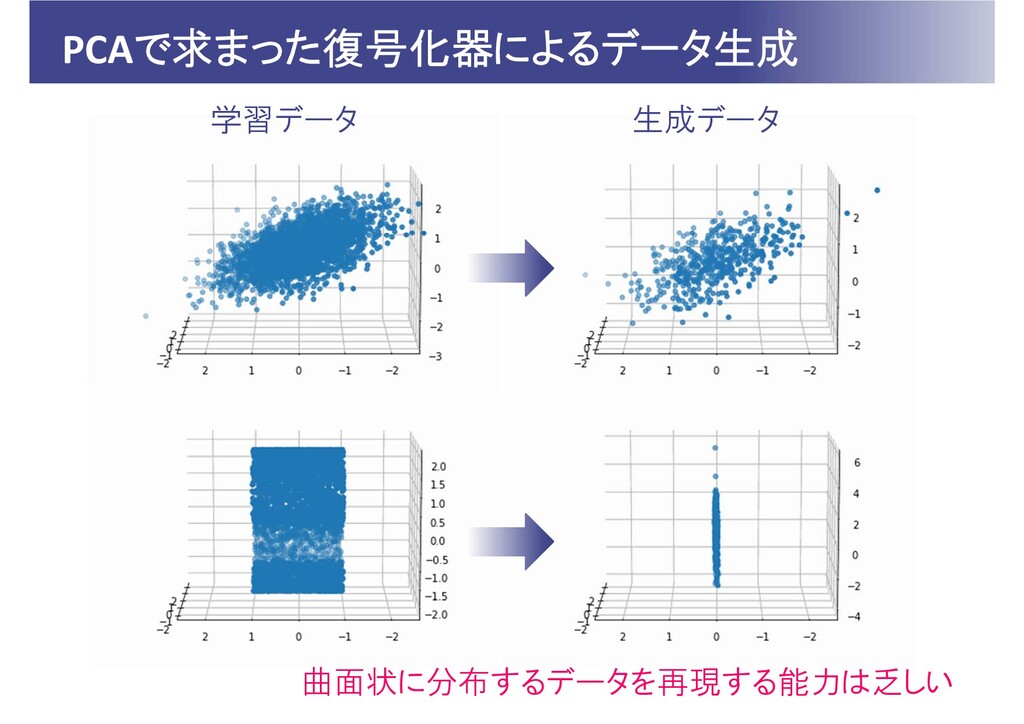
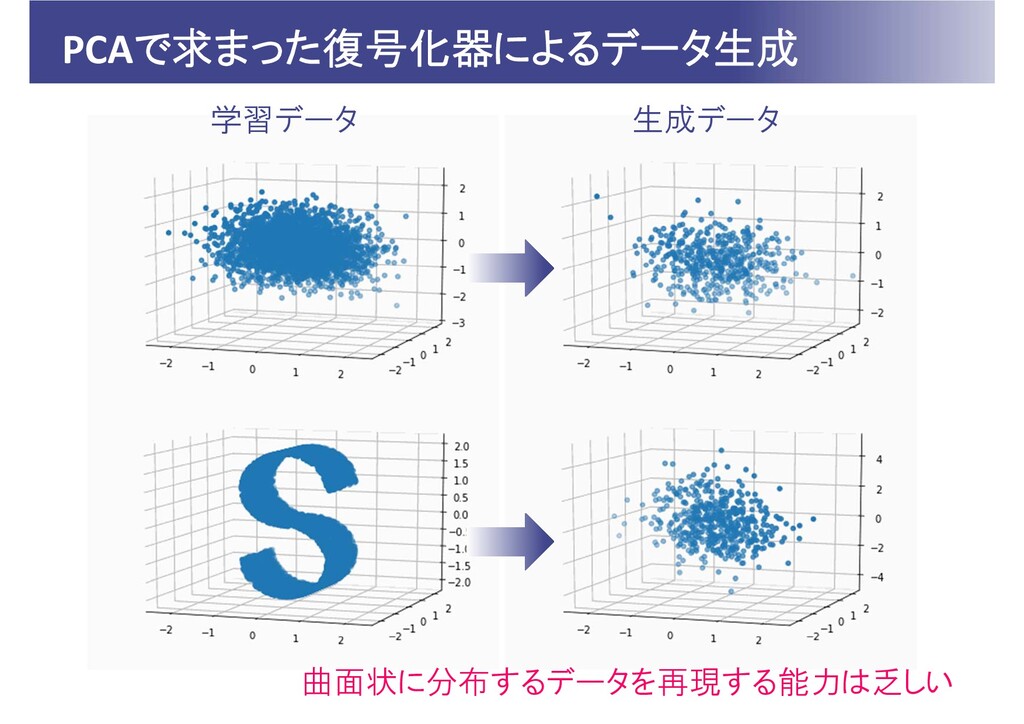
PCAで求まった復号化器によるデータ生成 学習データ 生成データ 曲面状に分布するデータを再現する能力は乏しい
PCAで求まった復号化器によるデータ生成 学習データ 生成データ 曲面状に分布するデータを再現する能力は乏しい
変分自己符号化器 (VariationalAutoEncoder) [Kingma+2014] NNを用いたPCAの非線形拡張 低次元 空間 復号化器(Decoder) ここがNN ( と
の非線形な 関係を表現可能) はどうなる?? ベイズ則より 分母計算が困難
変分自己符号化器 (VariationalAutoEncoder) [Kingma+2014] NNを用いたPCAの非線形拡張 低次元 空間 符号化器(Encoder) 復号化器(Decoder) ここがNN (
と の非線形な 関係を表現可能) を近似する NNを導入
変分自己符号化器 (VariationalAutoEncoder) [Kingma+2014] NNを用いたPCAの非線形拡張 低次元 空間 符号化器(Encoder) 復号化器(Decoder) ここがNN (
と の非線形な 関係を表現可能) を近似する NNを導入 両NNが無矛盾 となるように学習
VAEの定式化 から導かれる事後分布 を で近似する Kullback‐Leibler (KL)ダイバージェンス最小化問題として定式化 VAE学習ロス
VAEの学習 学習ロス: 第一項 第二項 ※ は学習データによるサンプル平均を表す ガウス分布同士のKLダイバージェンス に関する期待値計算
は によって具体形が 決まる の非線形関数になっており,期待値は 解析的に得られない のサンプリングによる モンテカルロ近似は? パラメータ がサンプリング元の分布に含まれる ためこれでは に関する勾配が計算できない に関して微分可能!
変数変換トリック ⇔ を利用すると, パラメータ をサンプリング元の分布 から[ ]の中に移すことができた のサンプリングによるモンテカルロ近似 ⇒
に関して微分可能! のとき と の誤差に相当 (つまり自己符号化器として解釈可能)
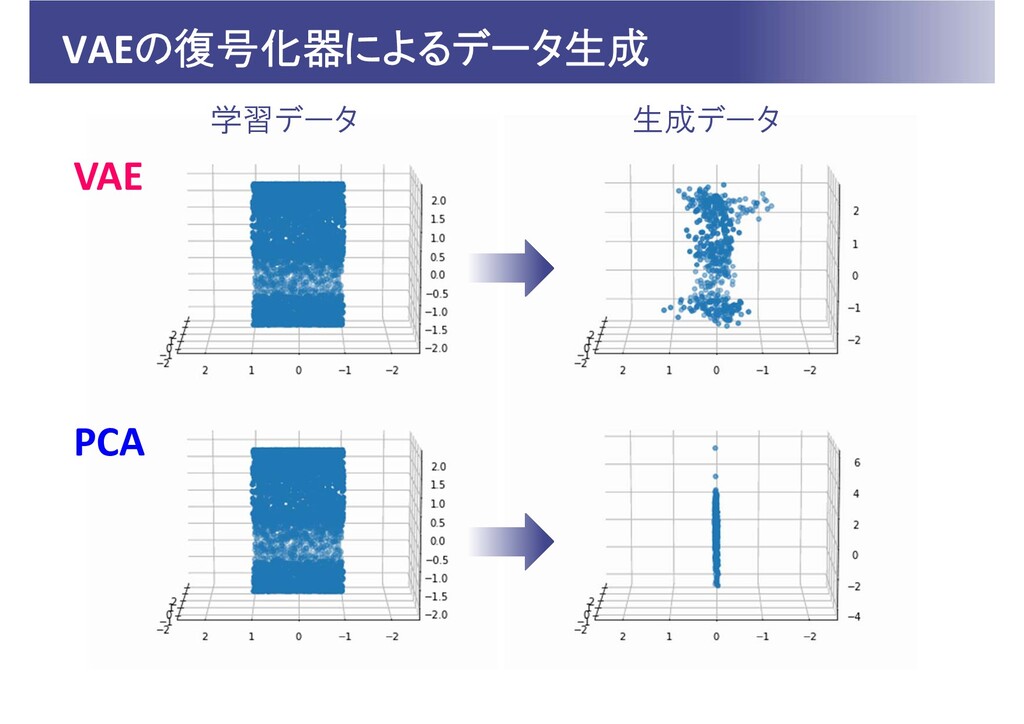
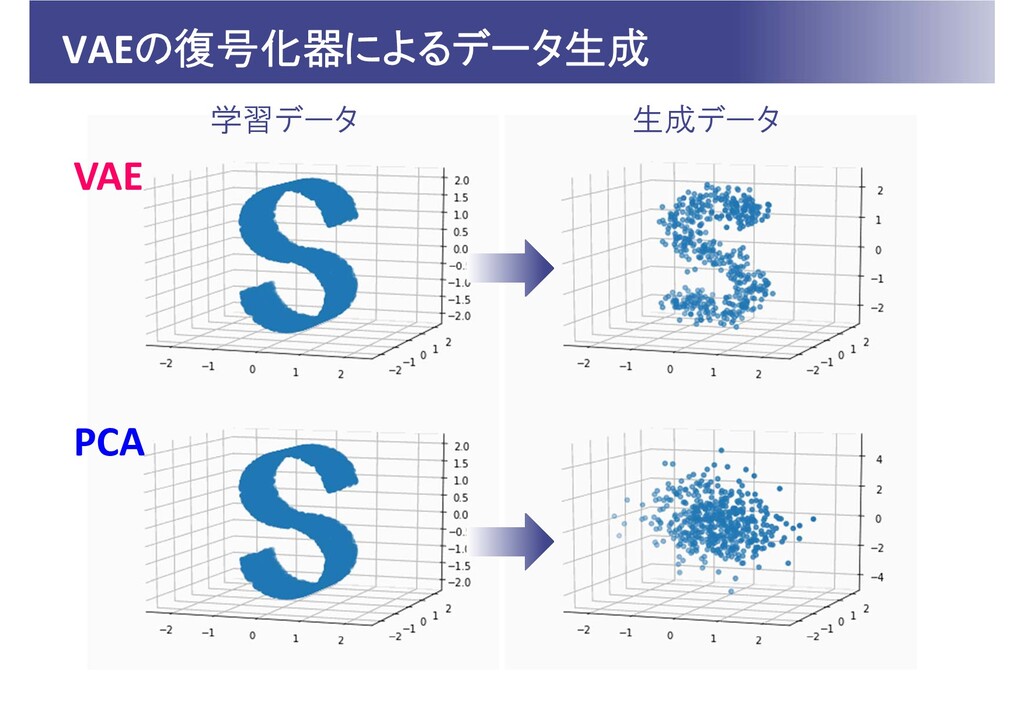
VAEの復号化器によるデータ生成 学習データ 生成データ VAE PCA
VAEの復号化器によるデータ生成 学習データ 生成データ VAE PCA
Crossmodal Voice/Face Synthesis [Kameoka+2018] Time Time 言語情報 容貌特徴 できるだけ一致 させる
声質特徴 抽出器 Channel 入力音声 変換音声 言語情報 抽出器 容貌特徴 抽出器 音声 合成器 入力顔画像 顔画像 生成器 声質特徴 音声変換器 顔画像 予測器 5つのNNを同時学習 言語抽出器 容貌特徴抽出器 音声合成器 声質特徴抽出器 顔画像生成器 : 入力音声の発話内容に相当する情報 を抽出 : 入力顔画像の容貌に相当する情報 を抽出 : 発話内容 と画像特徴 から音声 を生成 : 音声 の声質特徴に相当する情報 ̂を抽出 : 声質特徴 ̂から顔画像 を生成
各種深層生成モデルと古典的確率モデル 敵対的生成ネット (GAN) 自己回帰ネット (AGN) 自己回帰 (AR)モデル ニューラルネット (NN) 変分自己符号化器
(VAE) 主成分分析 (PCA) ニューラルネット (NN) フローベース 生成モデル (Flow) 独立成分分析 (ICA) ニューラルネット (NN) 深層生成モデル 古典的確率モデル
超高次元データの生成モデル 音声波形や画像は超高次元なデータ 音声波形(44.1kHzサンプリング)の場合: わずか1秒間で40,000次元 画像(1024x1024ピクセル)の場合: 1,000,000次元 高次元であるだけでなく複雑な相関構造(つまり同時分布)をもつ 各種深層生成モデルのアイディア
AGN のようにfactorizeしてモデル化・学習の対象 を1次元の分布 に帰着させることで問題を簡単化 学習できたら により を生成可能 VAE 要素間に相関構造や制約がある高次元データは低次元空間に圧縮可能という考え方 符号化器 と復号化器 の をNNでモデル化し, となるように , を学習 学習できたら により を生成可能 Flow, GANは? ⇒どうやって , … , の複雑な分布 をモデル化するか? ⇒本日はFlow, GANの考え方について解説
ニューラルネットワークの基礎 独立成分分析 (Independent Component Analysis )
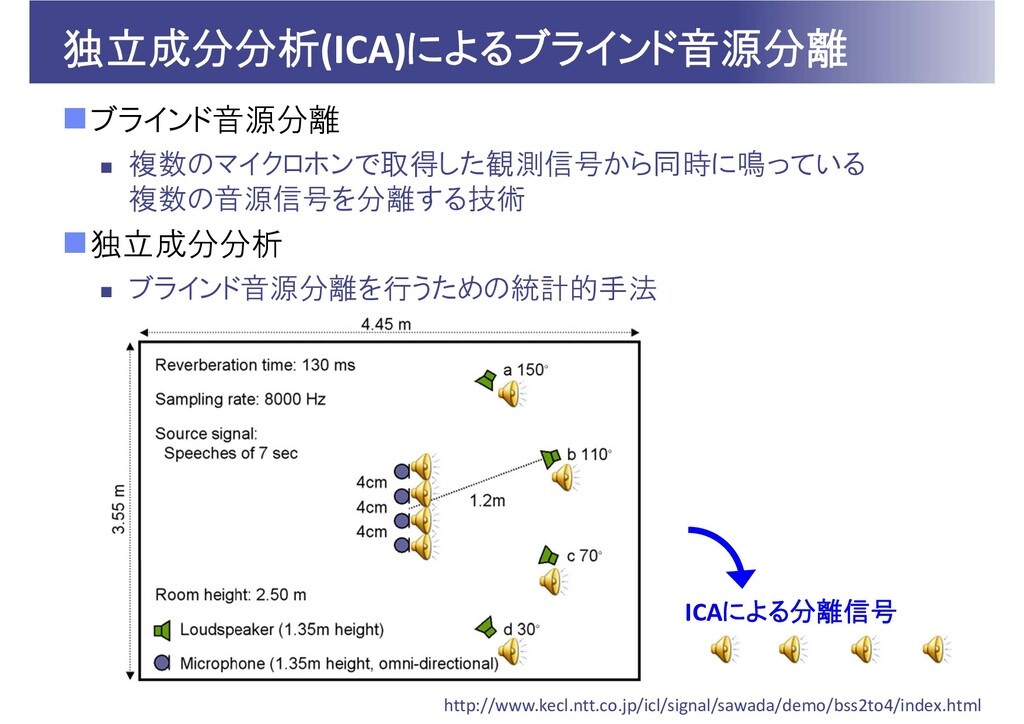
独立成分分析(ICA)によるブラインド音源分離 ブラインド音源分離 複数のマイクロホンで取得した観測信号から同時に鳴っている 複数の音源信号を分離する技術 独立成分分析 ブラインド音源分離を行うための統計的手法 ICAによる分離信号 http://www.kecl.ntt.co.jp/icl/signal/sawada/demo/bss2to4/index.html
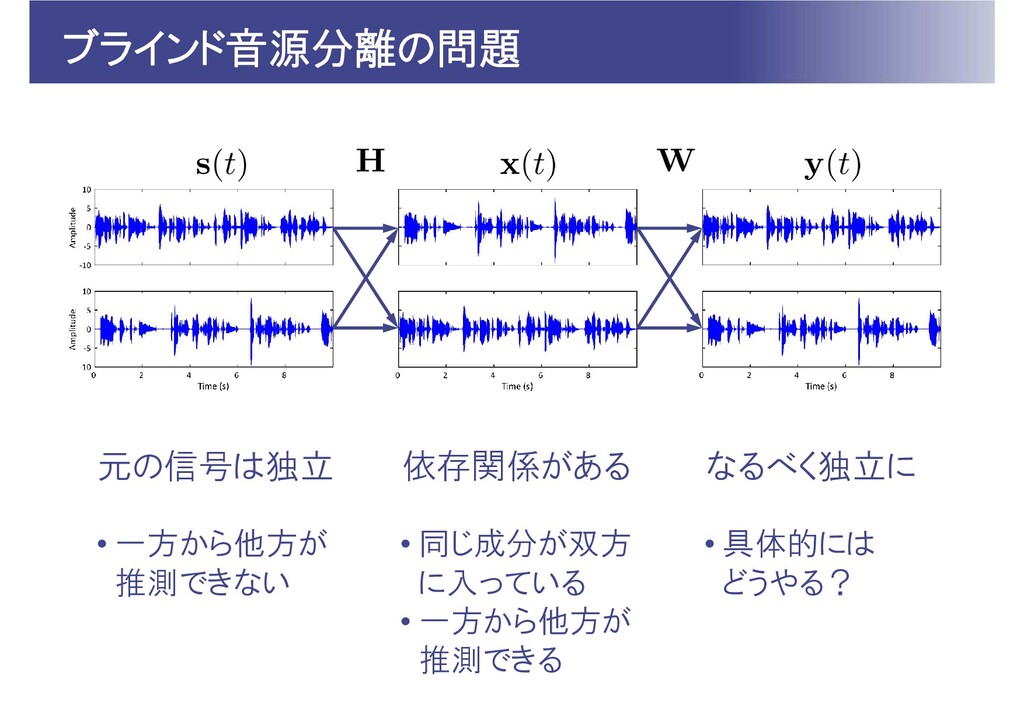
ブラインド音源分離の問題 元の信号は独立 依存関係がある なるべく独立に • 一方から他方が 推測できない • 同じ成分が双方 に入っている
• 一方から他方が 推測できる • 具体的には どうやる?
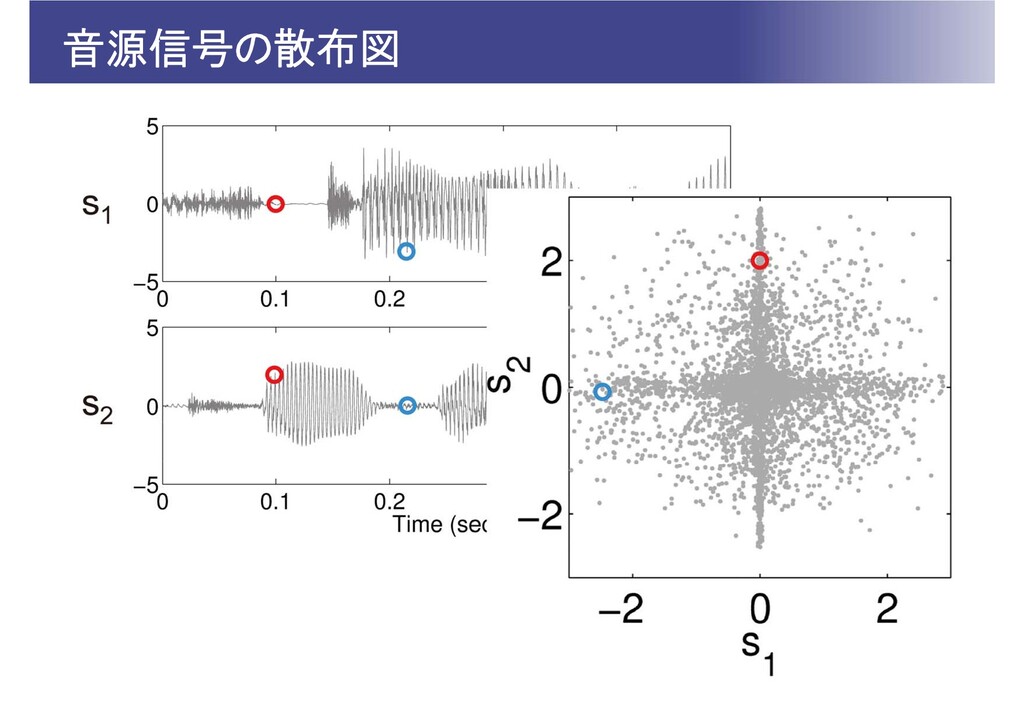
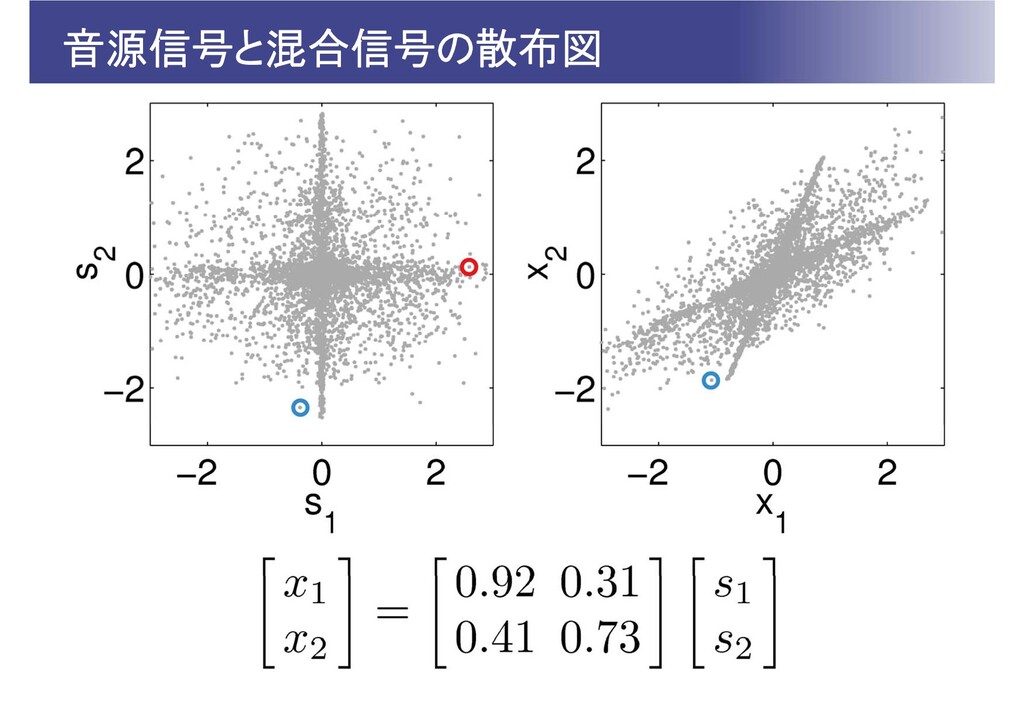
問題の定式化 個の音源信号 が混ざり合い, 個の観測信号 が得られたとする 分離行列 により分離信号 を生成する。
の推定は観測信号 のみから行う 分離信号 が互いに独立になるようにする
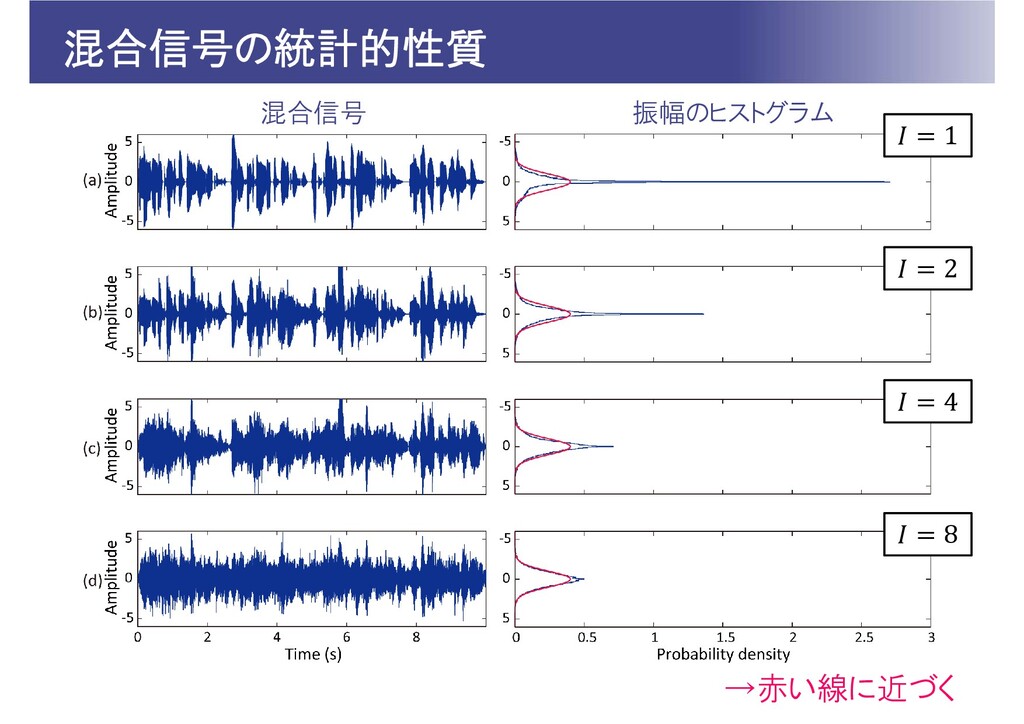
混合信号の統計的性質 1 2 4 8 →赤い線に近づく 振幅のヒストグラム 混合信号
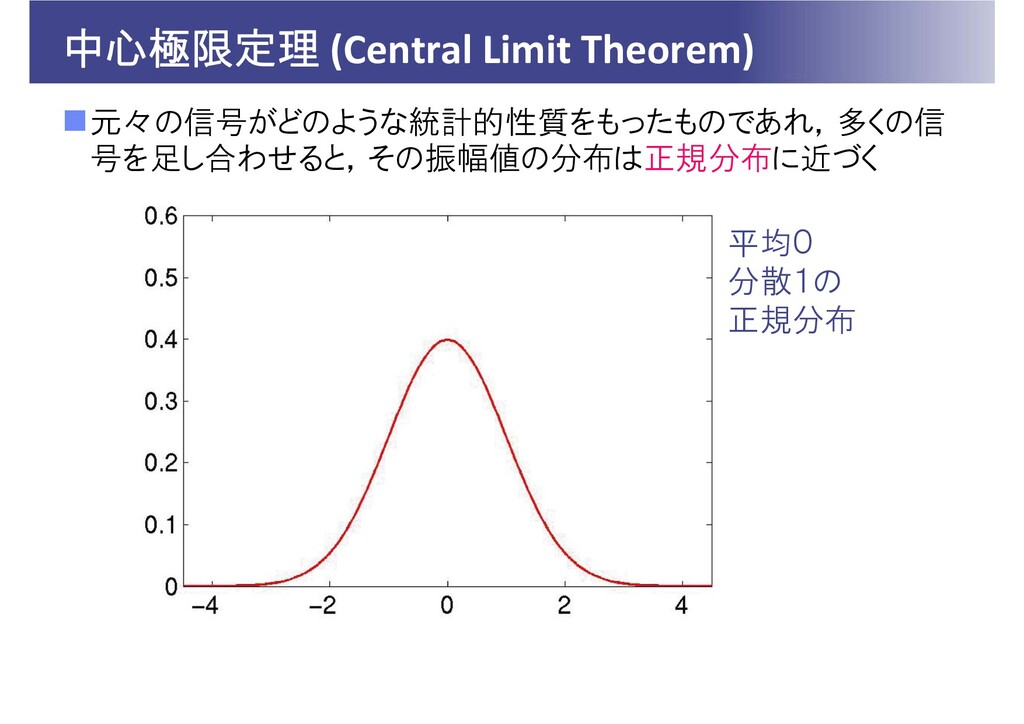
中心極限定理 (Central Limit Theorem) 元々の信号がどのような統計的性質をもったものであれ,多くの信 号を足し合わせると,その振幅値の分布は正規分布に近づく 平均0 分散1の 正規分布
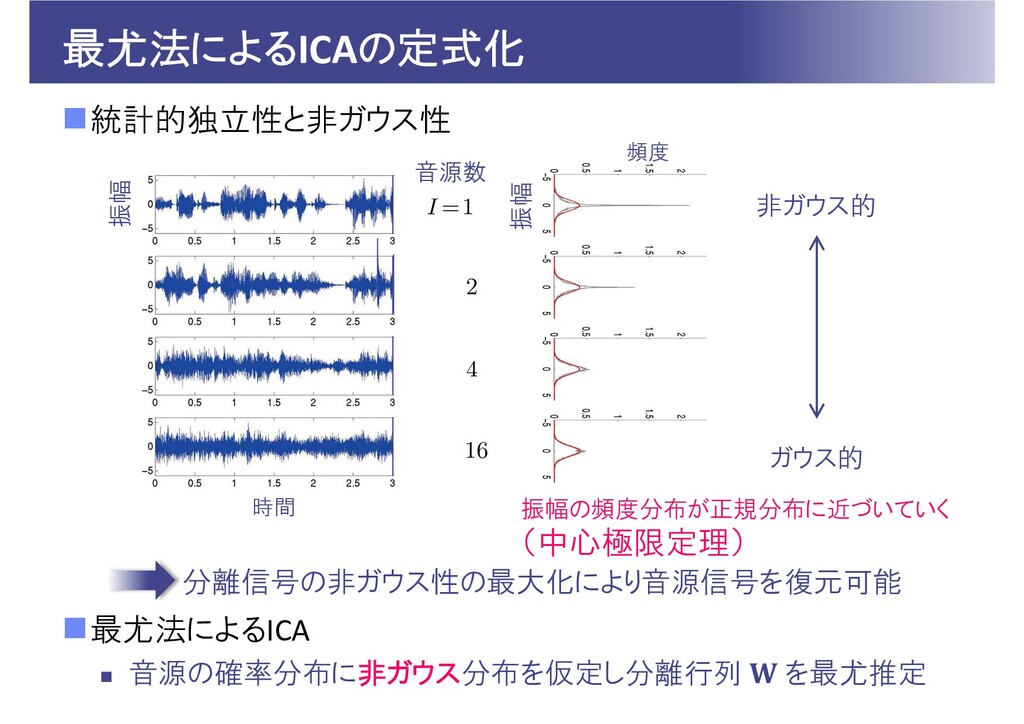
最尤法によるICAの定式化 統計的独立性と非ガウス性 最尤法によるICA 音源の確率分布に非ガウス分布を仮定し分離行列 を最尤推定 音源数 振幅 頻度 振幅
振幅の頻度分布が正規分布に近づいていく (中心極限定理) 非ガウス的 ガウス的 時間 分離信号の非ガウス性の最大化により音源信号を復元可能
最尤法によるICAの定式化 分離行列 を推定 観測信号 の確率密度関数( の尤度関数) 確率密度関数の変数変換 音源信号の独立性と非Gauss性を仮定
:Laplace分布など
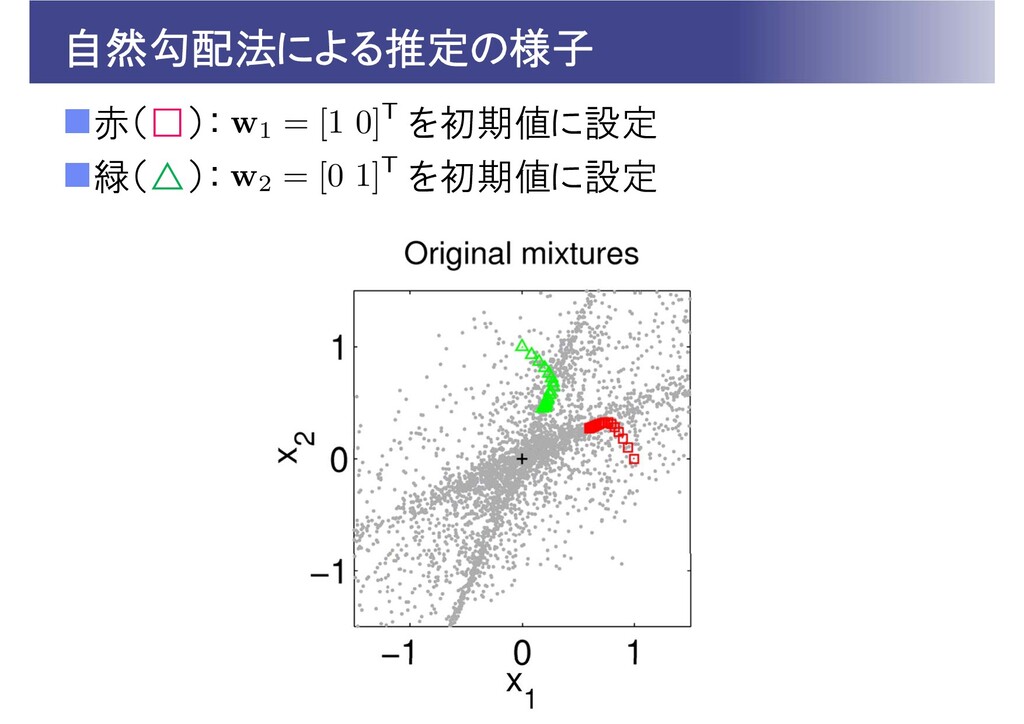
ICAのパラメータ推定アルゴリズム 通常の勾配法 更新則 毎ステップ逆行列計算が必要 自然勾配法 [Amari+1996] の実質的な変化分
のノルム制約下で最急降下方向を求める 逆行列計算が不要 ( はステップサイズ)
音源信号の散布図
音源信号と混合信号の散布図
自然勾配法による推定の様子 赤(□): を初期値に設定 緑(△): を初期値に設定
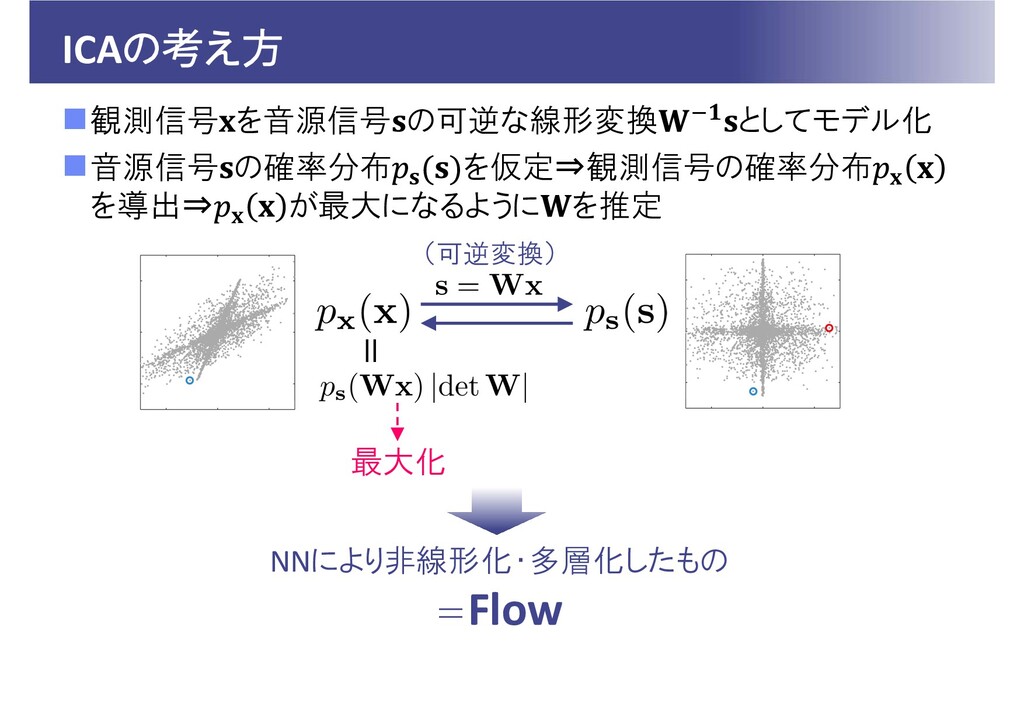
ICAの考え方 観測信号 を音源信号 の可逆な線形変換 としてモデル化 音源信号 の確率分布 を仮定⇒観測信号の確率分布 を導出⇒ が最大になるように
を推定 (可逆変換) 最大化 NNにより非線形化・多層化したもの =Flow
ニューラルネットワークの基礎 Flow
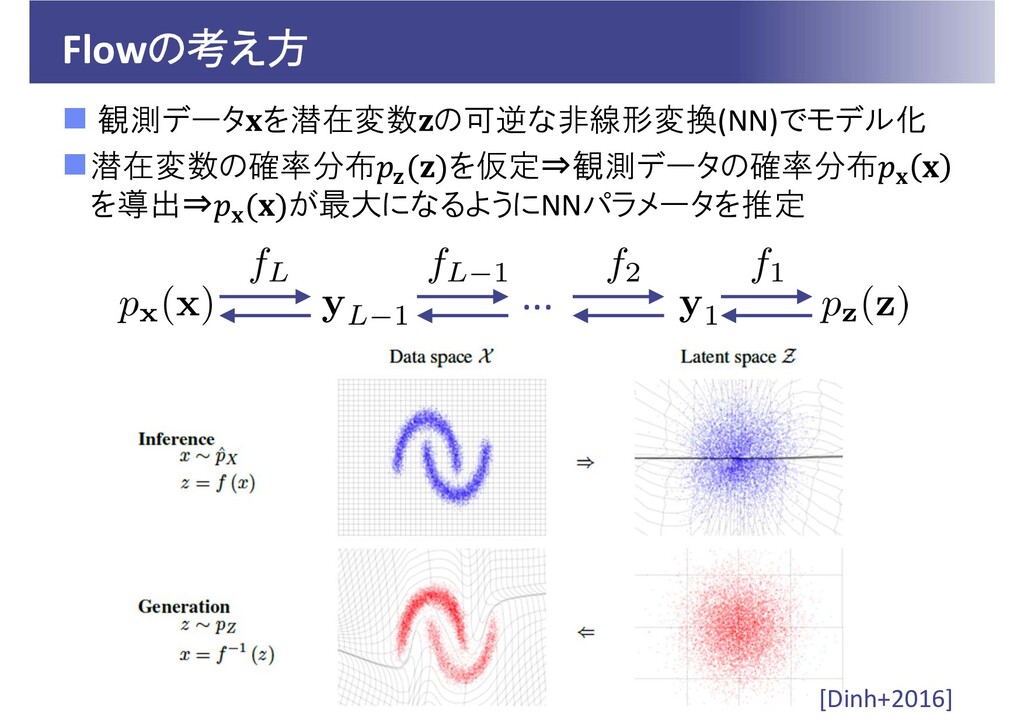
Flowの考え方 観測データ を潜在変数 の可逆な非線形変換(NN)でモデル化 潜在変数の確率分布 を仮定⇒観測データの確率分布 を導出⇒ が最大になるようにNNパラメータを推定 ...
[Dinh+2016]
Flowの考え方 観測データ を潜在変数 の可逆な非線形変換(NN)でモデル化 潜在変数の確率分布 を仮定⇒観測データの確率分布 を導出⇒ が最大になるようにNNパラメータを推定 ...
のとき より, ヤコビ行列 (Jacobian) の分布 が,変換関数 と の分布 を用いて表される ⇒
Flowのイメージ https://blog.evjang.com/2018/01/nf1.html
Flowの考え方 観測データ を潜在変数 の可逆な非線形変換(NN)でモデル化 潜在変数の確率分布 を仮定⇒観測データの確率分布 を導出⇒ が最大になるようにNNパラメータを推定
変数変換を多数回行い(既知の単純な)確率分布を変形して いくことで複雑な分布形を表現 が最大に なるように (の中のパラメータ)を学習 学習できたら で を生成可能 ... 学習では ,生成では を利用
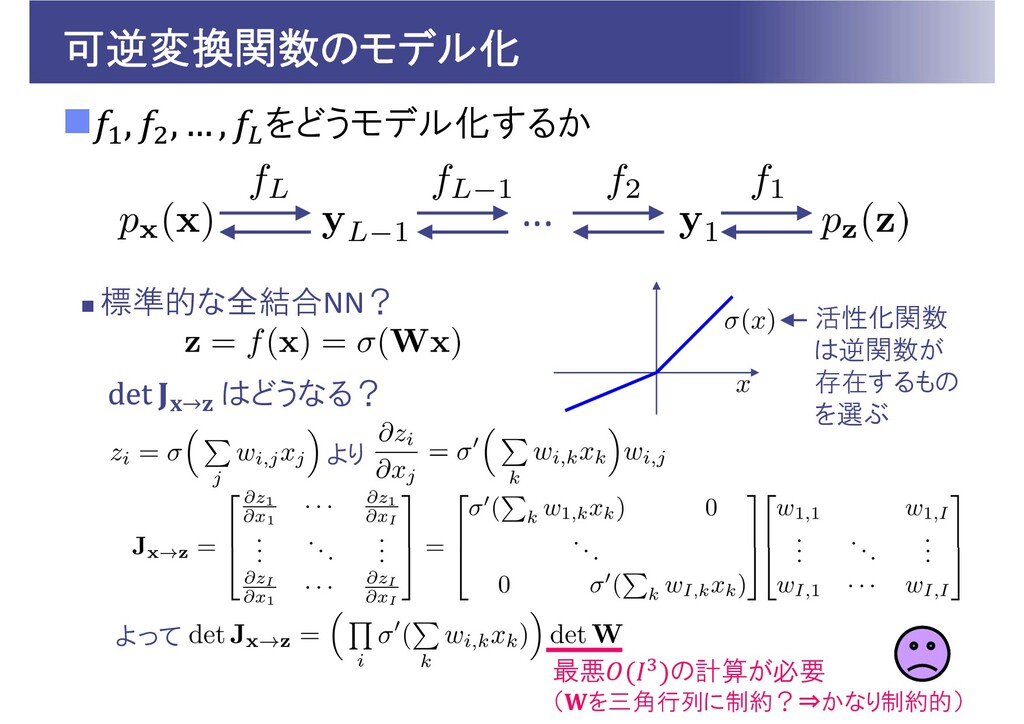
可逆変換関数のモデル化 をどうモデル化するか 標準的な全結合NN? ... 活性化関数 は逆関数が 存在するもの を選ぶ
→ はどうなる? より よって 最悪 の計算が必要 ( を三角行列に制約?⇒かなり制約的)
可逆変換関数のモデル化 をどうモデル化するか Nonlinear Independent Components Estimation (NICE) [Dinh+2014]
Additive coupling layer Random permutation layer ⇒要素を置換(置換行列を乗じる) Scaling layer ⇒対角行列を乗じる ... : where where : ⇒ split copy non‐ linear
可逆変換関数のモデル化 をどうモデル化するか Real‐valued non‐volume preserving (R‐NVP) flow [Dinh+2016]
R‐NVP transformation layer Glow [Kingma+2018] はNICEとR‐NVPの拡張 ... split : : ⇒ copy non‐ linear
可逆変換関数のモデル化 をどうモデル化するか Masked Autoregressive Flow (MAF) [Papamakarios+2017] ...
→ : ヤコビ行列: 尤度関数の評価 は並列計算可能 : for 1, … , : 生成に逐次計算が必要
可逆変換関数のモデル化 をどうモデル化するか Inverse Autoregressive Flow (IAF) [Kingma+2017] ...
ヤコビ行列: 尤度関数の評価に逐次計算が必要 生成は並列計算可能 * : → :
Flowの考え方(再掲) 観測データ を潜在変数 の可逆な非線形変換(NN)でモデル化 潜在変数の確率分布 を仮定⇒観測データの確率分布 を導出⇒ が最大になるようにNNパラメータを推定
変数変換を多数回行い(既知の単純な)確率分布を変形して いくことで複雑な分布形を表現 が最大に なるように (の中のパラメータ)を学習 学習できたら で を生成可能 ... 学習では ,生成では を利用
各種深層生成モデルと古典的確率モデル 敵対的生成ネット (GAN) 自己回帰ネット (AGN) 自己回帰 (AR)モデル ニューラルネット (NN) 変分自己符号化器
(VAE) 主成分分析 (PCA) ニューラルネット (NN) フローベース 生成モデル (Flow) 独立成分分析 (ICA) ニューラルネット (NN) 深層生成モデル 古典的確率モデル
Generative Adversarial Network (GAN) [Goodfellow+2014] 分布形を仮定することなく学習サンプルの分布に従う擬似サンプル を生成する生成器を学習する枠組 実サンプルか生成器 が生成した擬似サンプルかを識別する識 別器
をだますように を学習 もだまされないように学習 は識別スコアを小さく したい 識別境界を越えたい は識別スコアを 大きくしたい 敵対ロス ( から見た識別スコア) ⇒音声合成への応用も [Kaneko+2016][Saito+2016]
Generative Adversarial Network (GAN) [Goodfellow+2014] 分布フィッティングとしての解釈 がどういう時に敵対ロスは最大になるか? よって
のみにとってのロスは と のJensen‐Shanon (JS) ダイバージェンス
GANの考え方 確率分布のモデル化を回避しようという考え方 尤度関数を用いない学習法 ⇒生成器 と識別器 を敵対的に学習 学習が進むと に従うサンプルを生成する生成器が得られる 学習できたら は
により生成可能
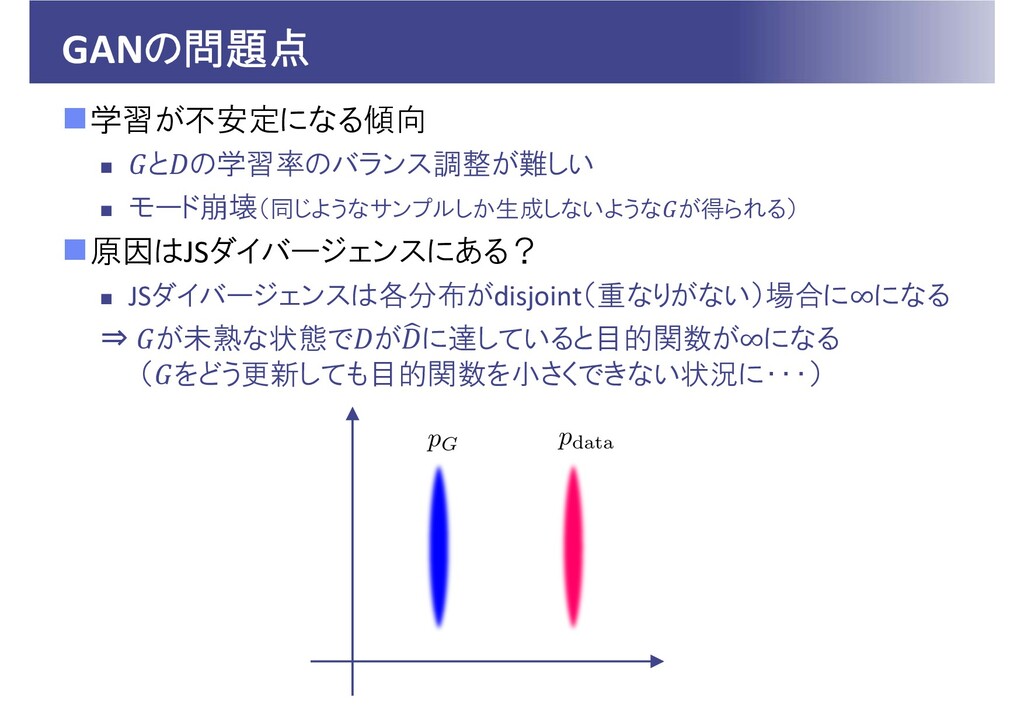
GANの問題点 学習が不安定になる傾向 と の学習率のバランス調整が難しい モード崩壊(同じようなサンプルしか生成しないような が得られる) 原因はJSダイバージェンスにある?
JSダイバージェンスは各分布がdisjoint(重なりがない)場合に∞になる ⇒ が未熟な状態で が に達していると目的関数が∞になる ( をどう更新しても目的関数を小さくできない状況に・・・)
Wasserstein GAN [Arjovsky+2017] Wasserstein距離で と の近さを測ることで前記問題を解決 Wasserstein距離の定義 のイメージ
ヒストグラム とヒストグラム の近さを測る規準 ヒストグラムを各地点に堆積した石と解釈し、 のように堆積した石 を運んで のような地形にする際にかかる最小の「労力」 ※ 1の場合は「Earth Mover’s Distance (EMD)」と呼ぶ A B
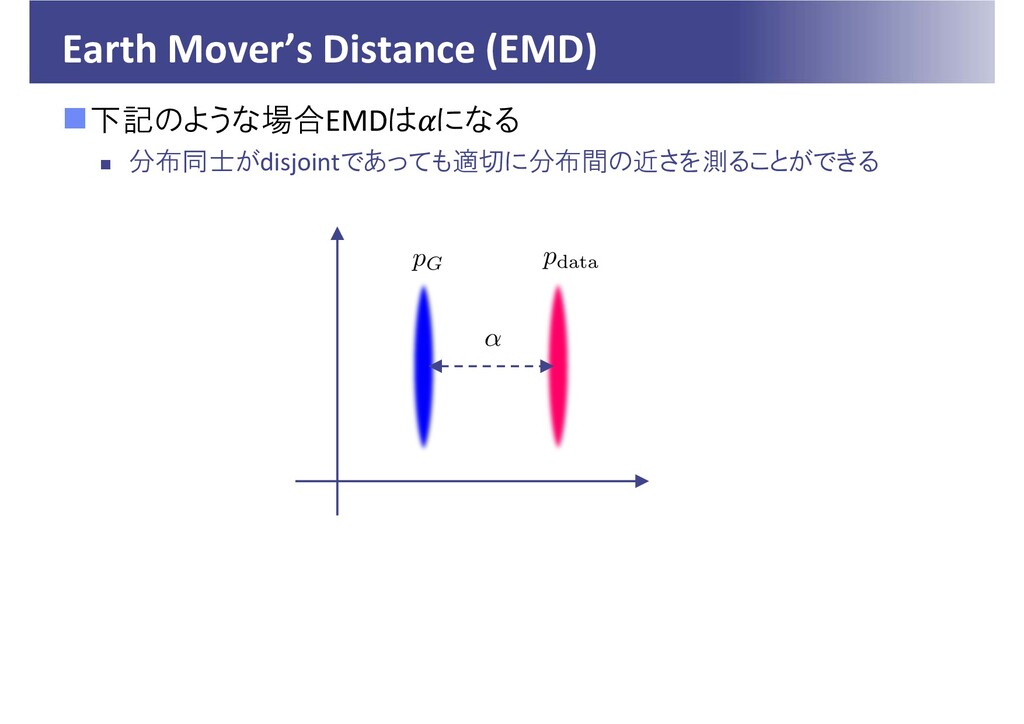
Earth Mover’s Distance (EMD) 下記のような場合EMDは になる 分布同士がdisjointであっても適切に分布間の近さを測ることができる
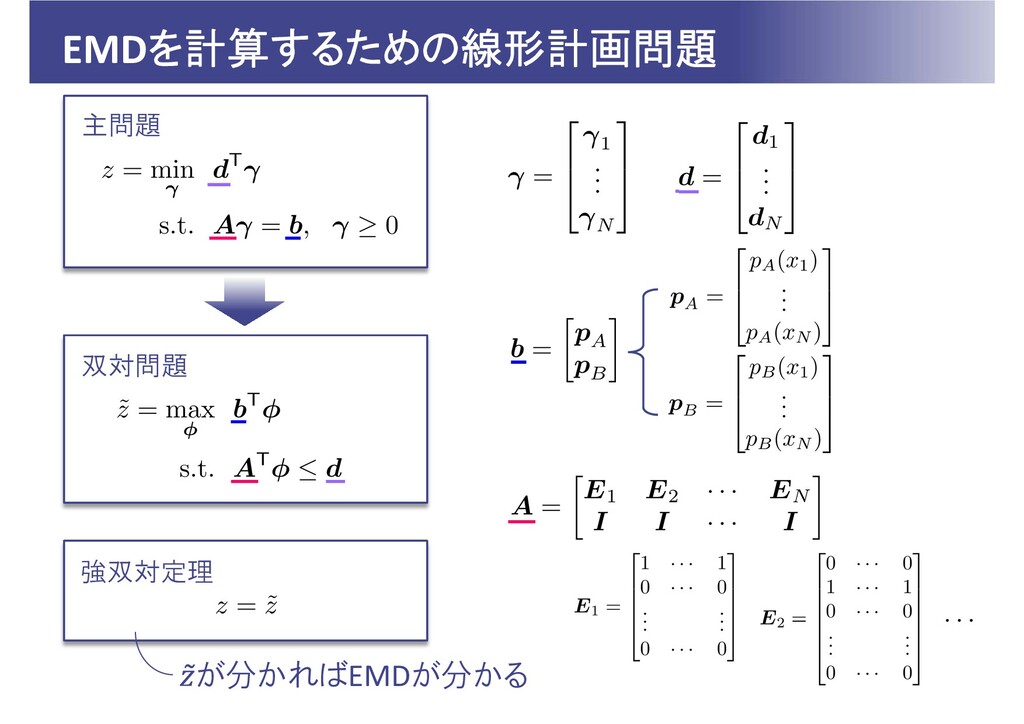
Earth Mover’s Distance (EMD) EMDの計算自体が最適化問題(最小輸送問題) 地点 から地点 に運ぶ石の量: ,
(労力)= (石の量) (運ぶ距離)と定義すると、 ヒストグラム とヒストグラム のEMDは以下となる と が離散的な場合、線形計画問題の形式で書ける ただし 地点 に運ばれる石の総量 地点 から運ばれる石の総量
EMDを計算するための線形計画問題 が分かればEMDが分かる 主問題 双対問題 強双対定理
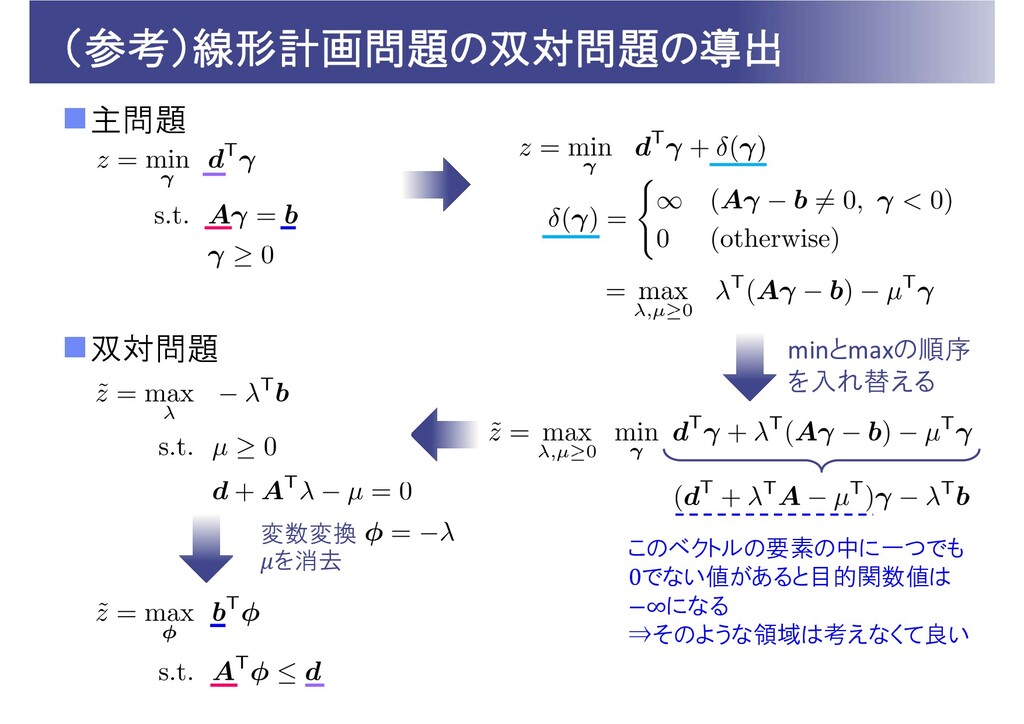
(参考)線形計画問題の双対問題の導出 主問題 双対問題 このベクトルの要素の中に一つでも 0でない値があると目的関数値は ∞になる ⇒そのような領域は考えなくて良い minとmaxの順序 を入れ替える 変数変換
を消去
EMDを計算するための線形計画問題 と置くと 不等式制約 は と書けるので 双対問題(再掲) A B も
も非負値なので、 も もできるだけ大きくしたい (しかし制約がある)
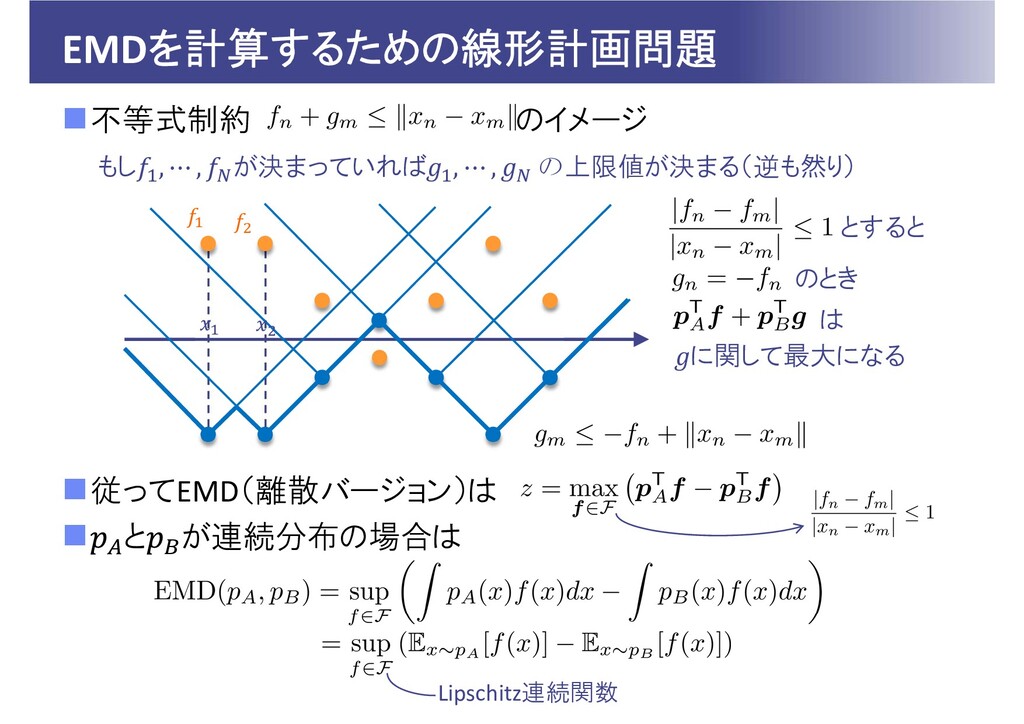
EMDを計算するための線形計画問題 不等式制約 のイメージ 従ってEMD(離散バージョン)は と が連続分布の場合は もし , ⋯
, が決まっていれば , ⋯ , の上限値が決まる(逆も然り) のとき とすると は に関して最大になる Lipschitz連続関数
Wasserstein GAN の学習アルゴリズム と のEMDを最小化する を求める最適化問題 と をニューラルネットワークで表現
それぞれのパラメータ および を学習 がLipschitz連続となるようにするためのアイディア Weight Clipping [Arjovsky+2017] Gradient Penalty [Gulrajani+2017] Spectral Normalization [Miyato+2018] GANと同様minmax問題 (敵対的学習)になっている
各種生成モデルのアイディアのまとめ AGN を学習 学習できたら により を生成可能 VAE
符号化器 と復号化器 の をNNでモデル化し, となるように , を学習 学習できたら により を生成可能 Flow が最大になるように , … , (NNパラメータ)を学習 学習できたら で を生成可能 GAN 生成器 ( )と識別器 ( )を敵対的に学習 学習できたら は ~ , により生成可能
本講義の目的と目標 深層学習(AI)研究に触れる 深層学習(AI)の研究の面白さや凄さを体感する 特に深層生成モデルと呼ぶ近年発展が著しい分野を扱う 温故知新(故きを温ねて新しきを知る) 深層生成モデルと古典的な確率モデルの関連を理解する
古典的な確率モデルがベースにする普遍的な考え方を学ぶ 信号処理の基礎を学ぶ プログラミングに触れる 簡単なプログラミングの演習を通して,信号やデータの扱いに 慣れ,確率モデルを用いた各種処理を実装する
![深層生成モデルによる メディア(画像・音声)生成 亀岡弘和 日本電信電話株式会社 NTTコミュニケーション科学基礎研究所 [email protected] 筑波大学大学院システム情報工学研究科社会工学専攻 社会工学ファシリテーター育成プログラム「メディア生成AI」 2020年 1/17(金)](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![VAEによるランダム顔画像生成 [Kingma+2014] 画像サンプルは下記サイトより https://github.com/podgorskiy/VAE 学習データ 学習した確率モデルからランダム生成した画像](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_4.jpg){kind=link}
![Crossmodal Voice/Face Synthesis [Kameoka+2018] VAEによる声からの顔予測と顔からの声質予測 入力音声のみから 話者の顔を予測する 入力音声の声質を、 入力顔画像に合わせて変換する 音声・画像サンプルは下記サイトより](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_5.jpg){kind=link}
![テキスト音声合成(テキストのみから音声を生成)のサンプル 音声波形のランダム生成 WaveNet (AGN) による音声波形生成 [van den Oord+2016] 音声サンプルは下記サイトより https://deepmind.com/blog/article/wavenet‐generative‐model‐raw‐audio](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_6.jpg){kind=link}
![Flowによるランダム顔画像生成 [Kingma+2018] 画像サンプルは下記サイトより https://openai.com/blog/glow/ Glowと呼ぶ方式による生成例](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_7.jpg){kind=link}
![GANによるランダム顔画像生成 [Goodfellow+2014, Karras+2019] 画像サンプルは下記サイトより無限に生成可能 https://thispersondoesnotexist.com/ NVIDIAが開発したStyleGANと呼ぶ方式による生成例](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![WaveNet(ニューラルボコーダ)の登場 [van den Oord+2016] 線形方式から非線形方式へ 線形予測分析 ニューラルネットの導入 ⇔](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_22.jpg){kind=link}
![WaveNet [van den Oord+2016] 最近DeepMindにより発表された高品質音声合成方式 アイディアのポイント 波形のサンプルごとの自己回帰型生成モデル 量子化された離散振幅値の条件付確率分布を畳み込みニューラルネット](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_23.jpg){kind=link}
![WaveNet [van den Oord+2016] 振幅の量子化 ( ‐law符号化) 条件付分布のモデル化 Causal](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_24.jpg){kind=link}
![WaveNet [van den Oord+2016] 下記ページよりWaveNetの音声サンプルを聴くことが可能 https://deepmind.com/blog/article/wavenet‐generative‐model‐raw‐audio](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PCAの生成モデル的解釈 データ の生成プロセス の最尤推定 低次元& 無相関 高次元& 相関あり がPCAに相当[Tipping1999]](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![変分自己符号化器 (VariationalAutoEncoder) [Kingma+2014] NNを用いたPCAの非線形拡張 低次元 空間 復号化器(Decoder) ここがNN ( と](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_39.jpg){kind=link}
![変分自己符号化器 (VariationalAutoEncoder) [Kingma+2014] NNを用いたPCAの非線形拡張 低次元 空間 符号化器(Encoder) 復号化器(Decoder) ここがNN (](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_40.jpg){kind=link}
![変分自己符号化器 (VariationalAutoEncoder) [Kingma+2014] NNを用いたPCAの非線形拡張 低次元 空間 符号化器(Encoder) 復号化器(Decoder) ここがNN (](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
![変数変換トリック ⇔ を利用すると, パラメータ をサンプリング元の分布 から[ ]の中に移すことができた のサンプリングによるモンテカルロ近似 ⇒](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
![Crossmodal Voice/Face Synthesis [Kameoka+2018] Time Time 言語情報 容貌特徴 できるだけ一致 させる](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ICAのパラメータ推定アルゴリズム 通常の勾配法 更新則 毎ステップ逆行列計算が必要 自然勾配法 [Amari+1996] の実質的な変化分](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_58.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![可逆変換関数のモデル化 をどうモデル化するか Nonlinear Independent Components Estimation (NICE) [Dinh+2014]](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_69.jpg){kind=link}
![可逆変換関数のモデル化 をどうモデル化するか Real‐valued non‐volume preserving (R‐NVP) flow [Dinh+2016]](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_70.jpg){kind=link}
![可逆変換関数のモデル化 をどうモデル化するか Masked Autoregressive Flow (MAF) [Papamakarios+2017] ...](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_71.jpg){kind=link}
![可逆変換関数のモデル化 をどうモデル化するか Inverse Autoregressive Flow (IAF) [Kingma+2017] ...](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_72.jpg){kind=link}
{kind=link}
{kind=link}
![Generative Adversarial Network (GAN) [Goodfellow+2014] 分布形を仮定することなく学習サンプルの分布に従う擬似サンプル を生成する生成器を学習する枠組 実サンプルか生成器 が生成した擬似サンプルかを識別する識 別器](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_75.jpg){kind=link}
![Generative Adversarial Network (GAN) [Goodfellow+2014] 分布フィッティングとしての解釈 がどういう時に敵対ロスは最大になるか? よって](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_76.jpg){kind=link}
{kind=link}
{kind=link}
![Wasserstein GAN [Arjovsky+2017] Wasserstein距離で と の近さを測ることで前記問題を解決 Wasserstein距離の定義 のイメージ ](https://files.speakerdeck.com/presentations/0424cabb09c146948a2ac0494533f3af/slide_79.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}