全日本コンピュータビジョン勉強会(2022/08/07)で発表した"DoubleField: Bridging the Neural Surface and Radiance Fields for High-Fidelity Human Reconstruction and Rendering"の紹介資料です。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
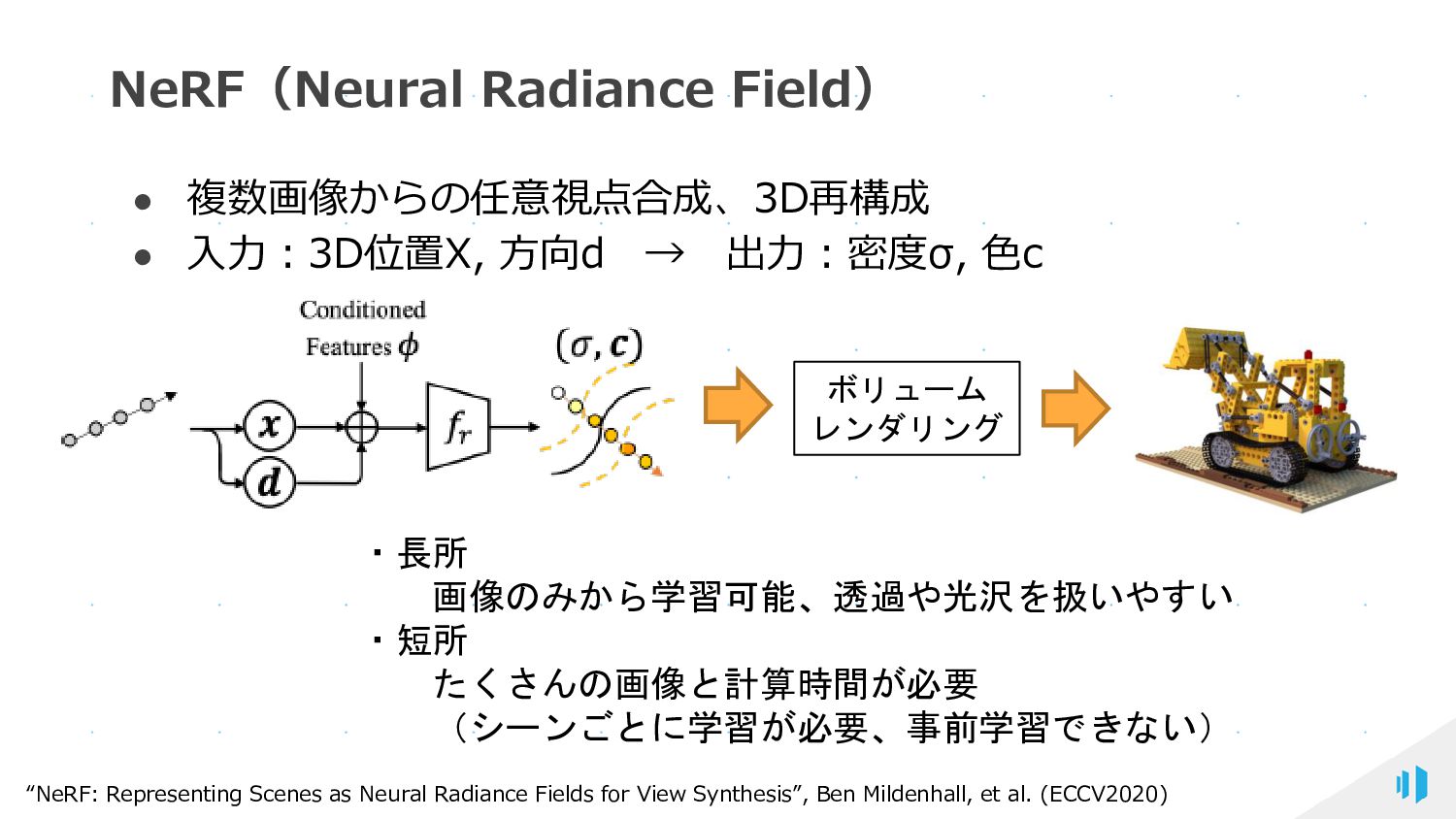{kind=link}
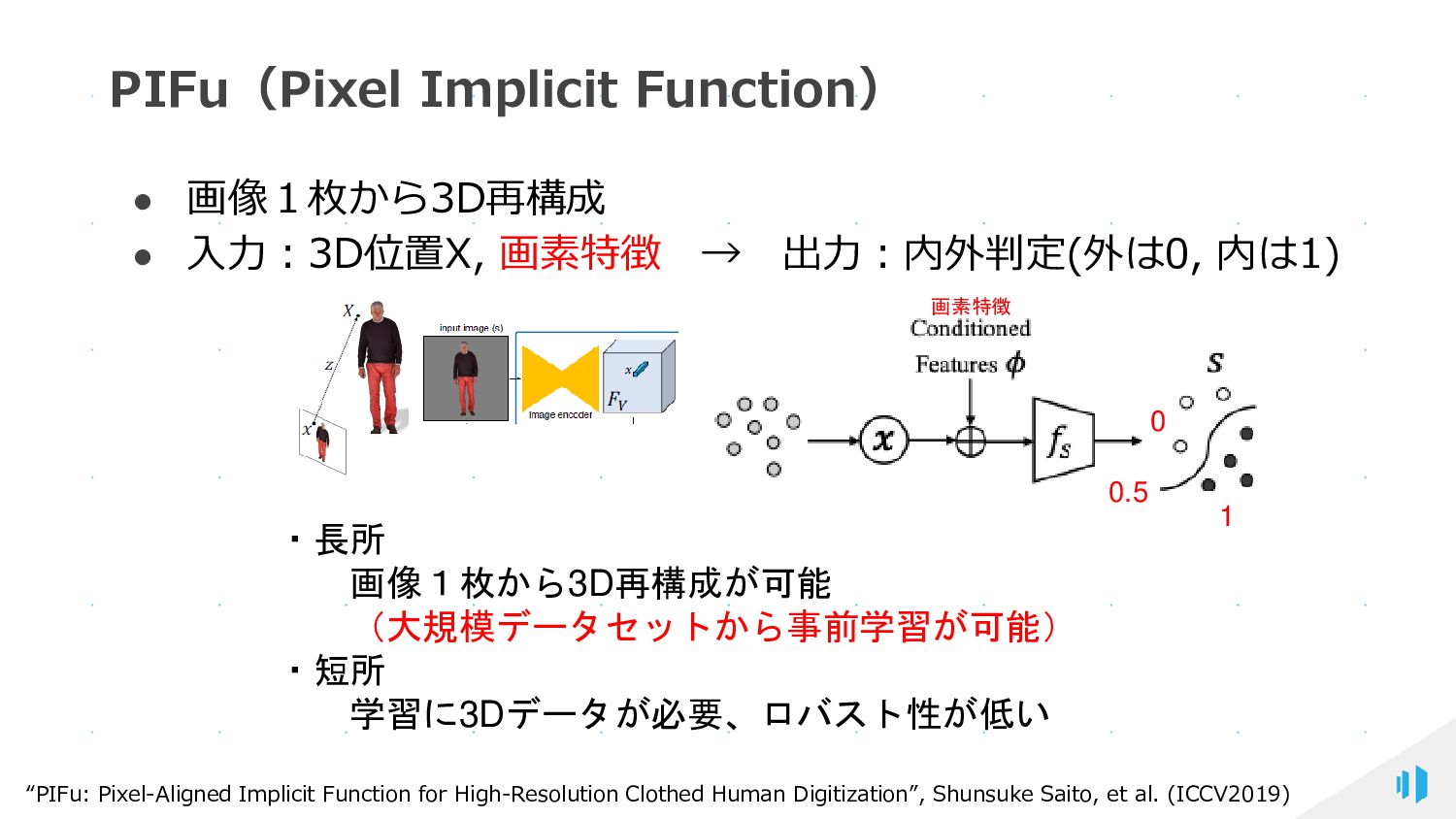{kind=link}
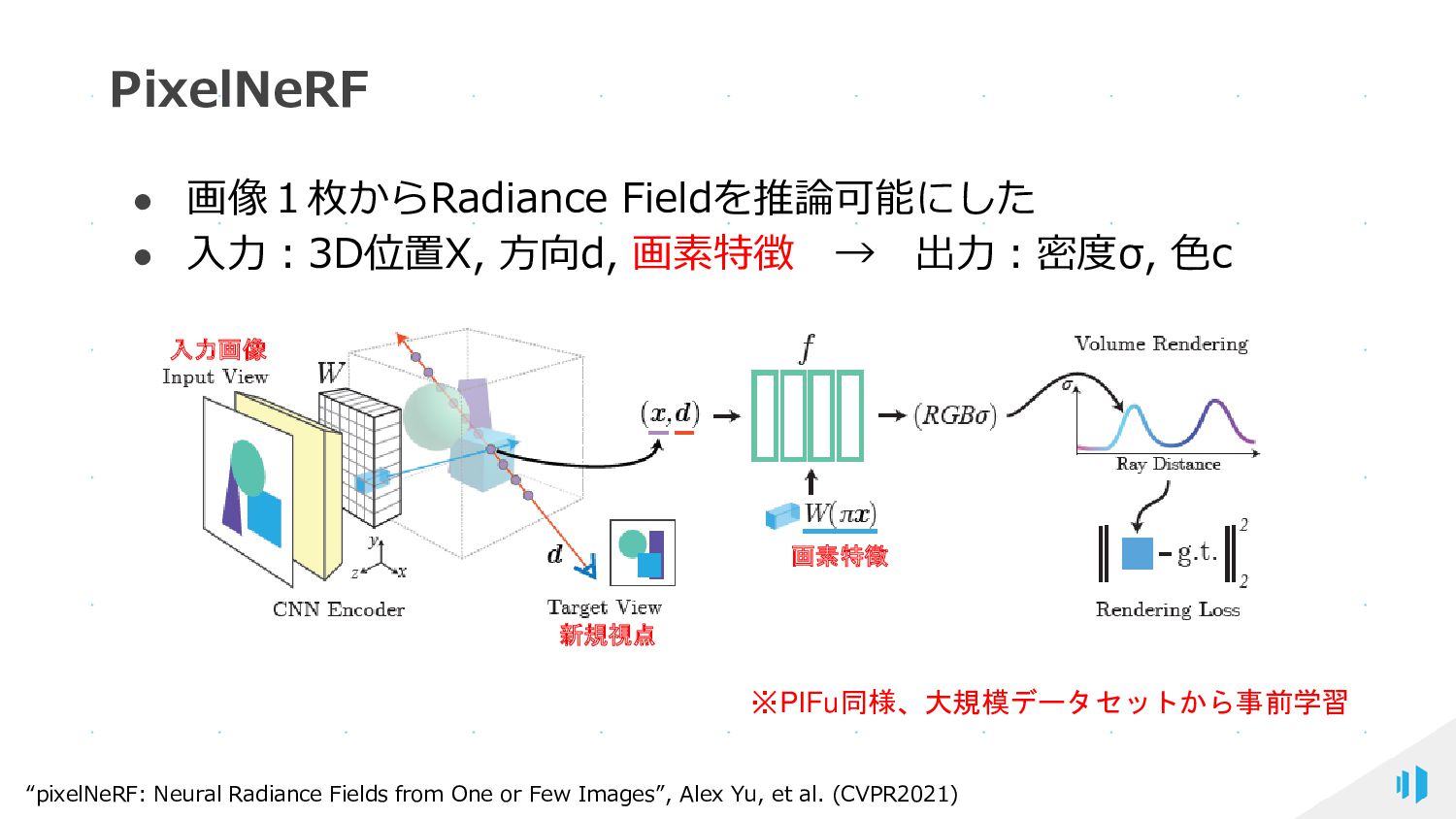{kind=link}
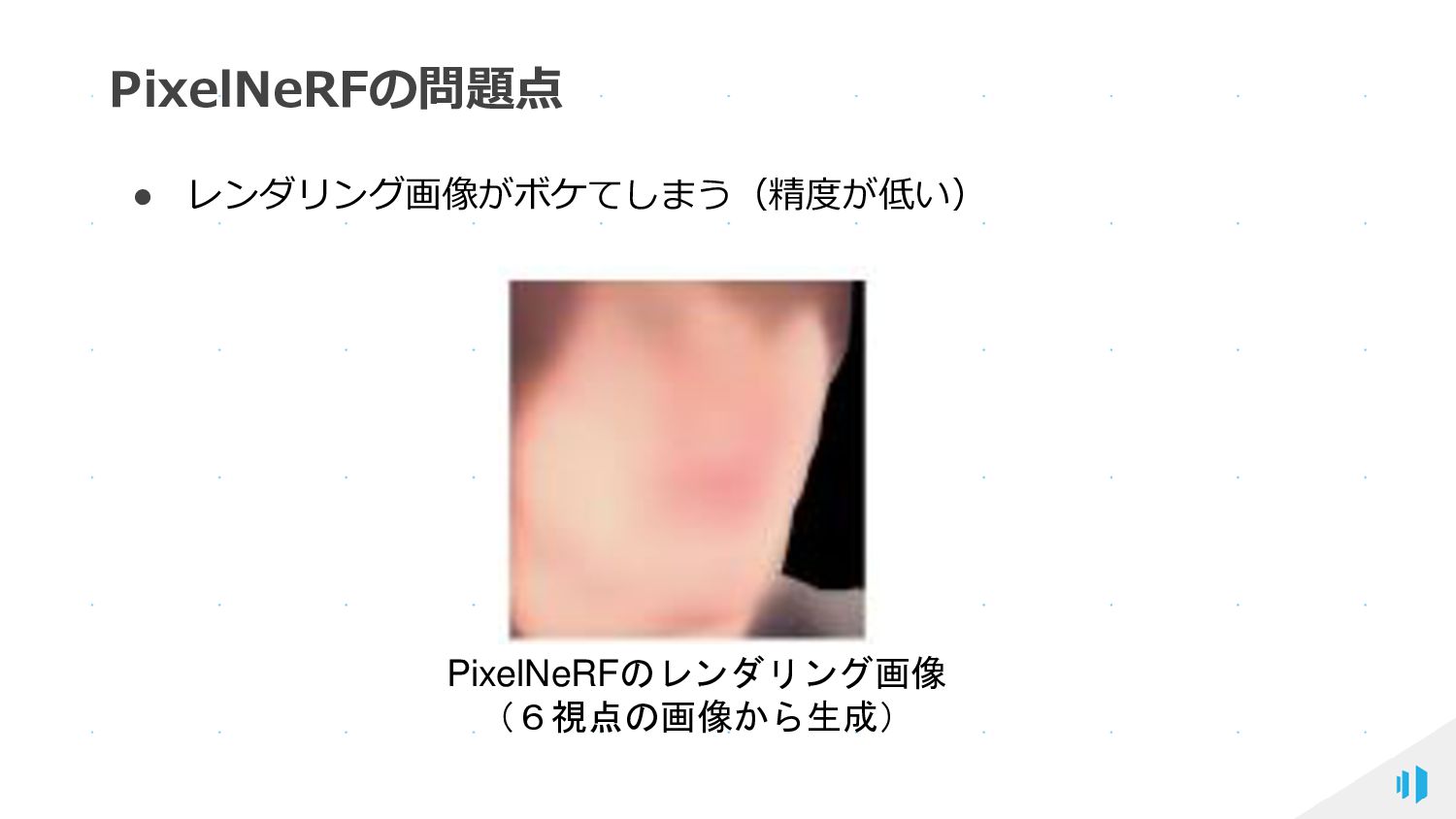{kind=link}
{kind=link}
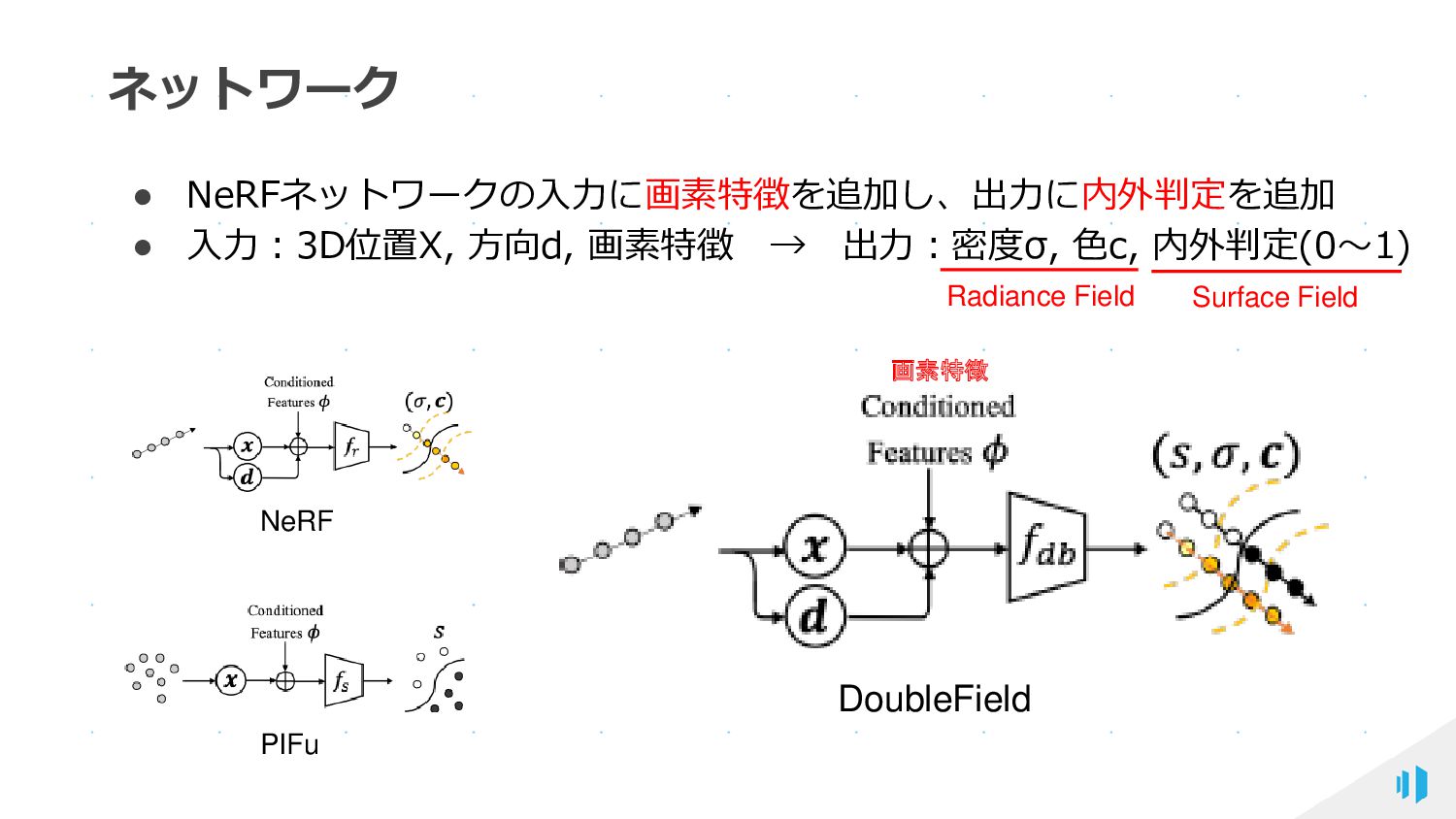{kind=link}
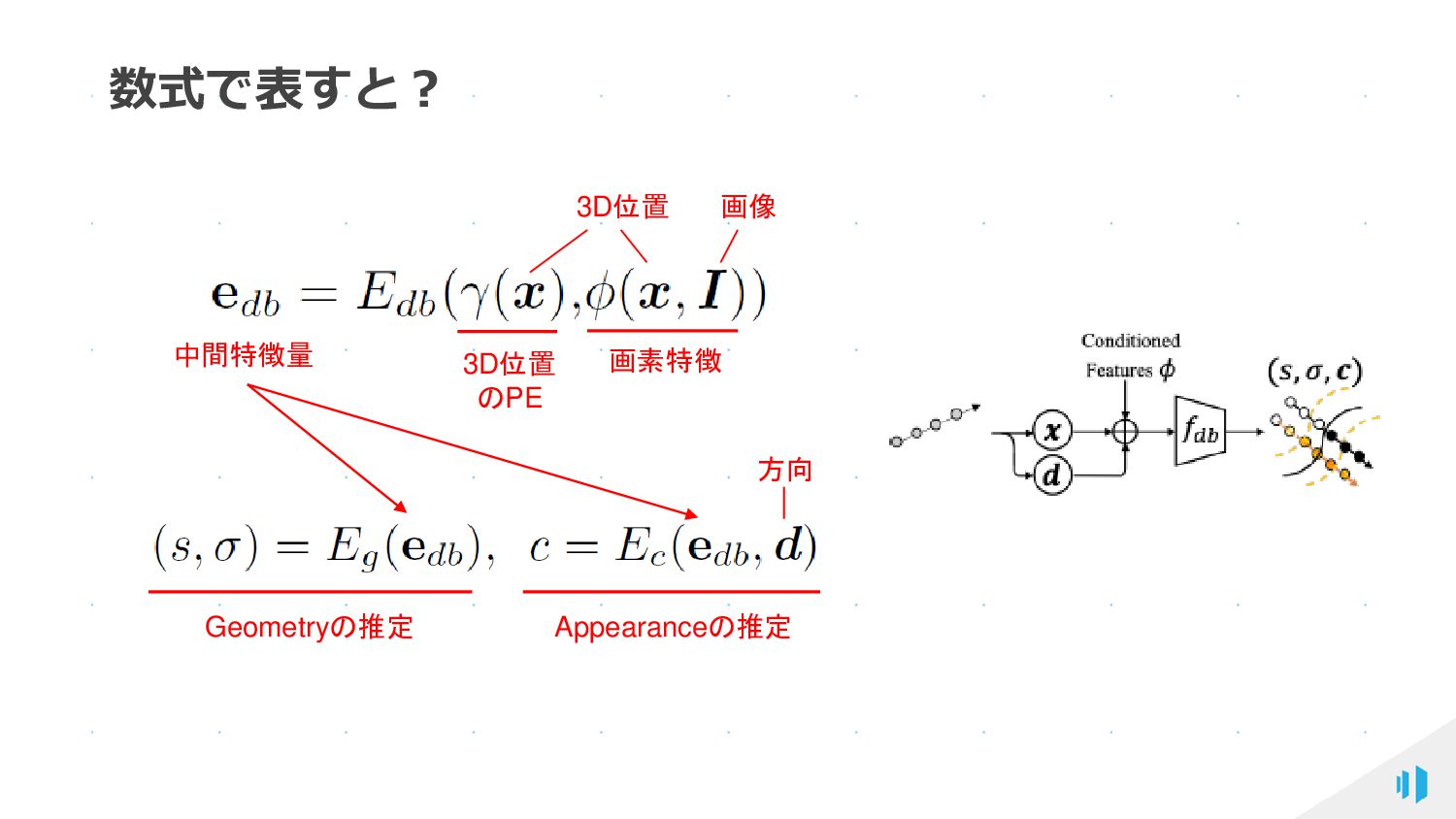{kind=link}
{kind=link}
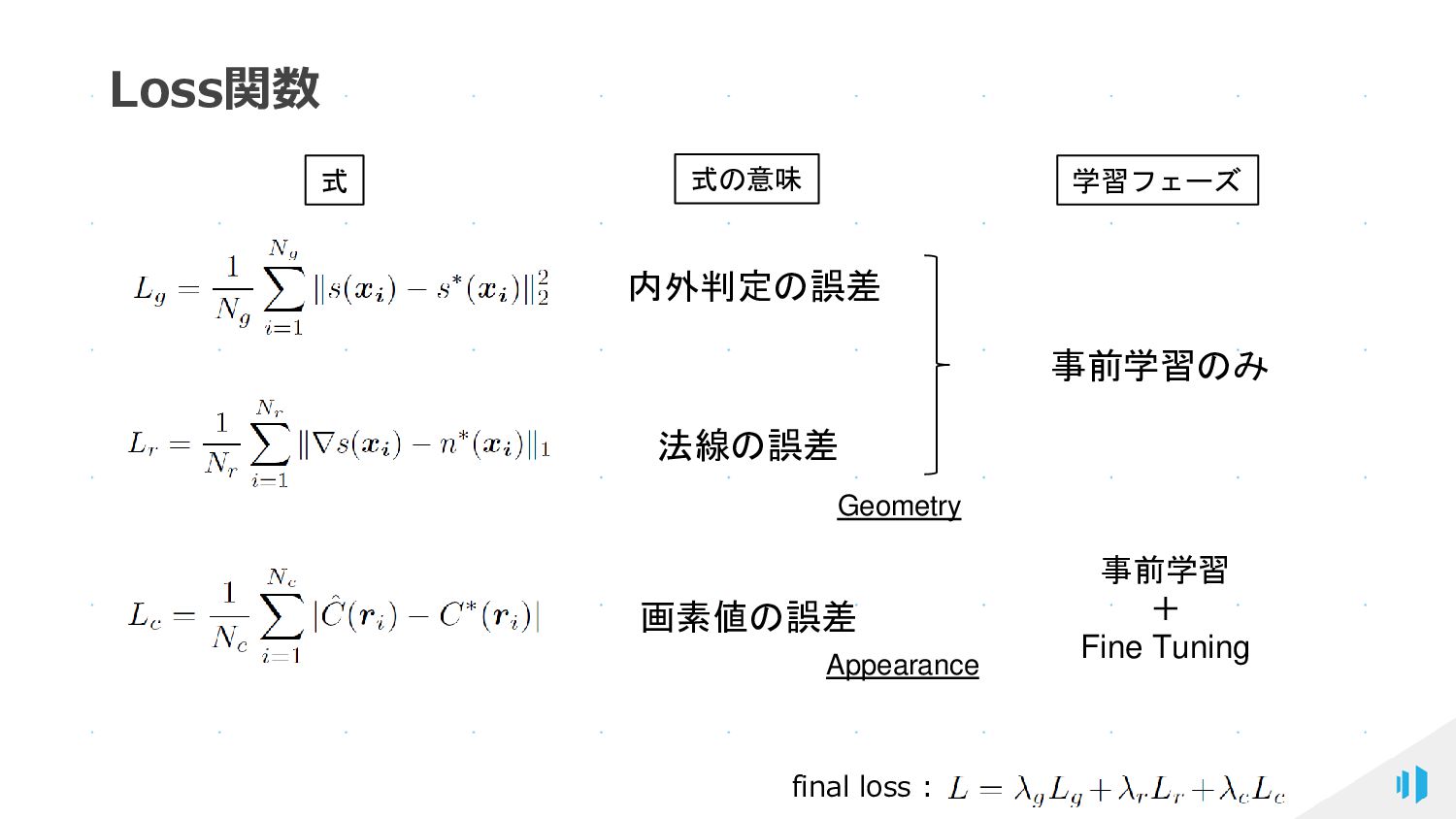{kind=link}
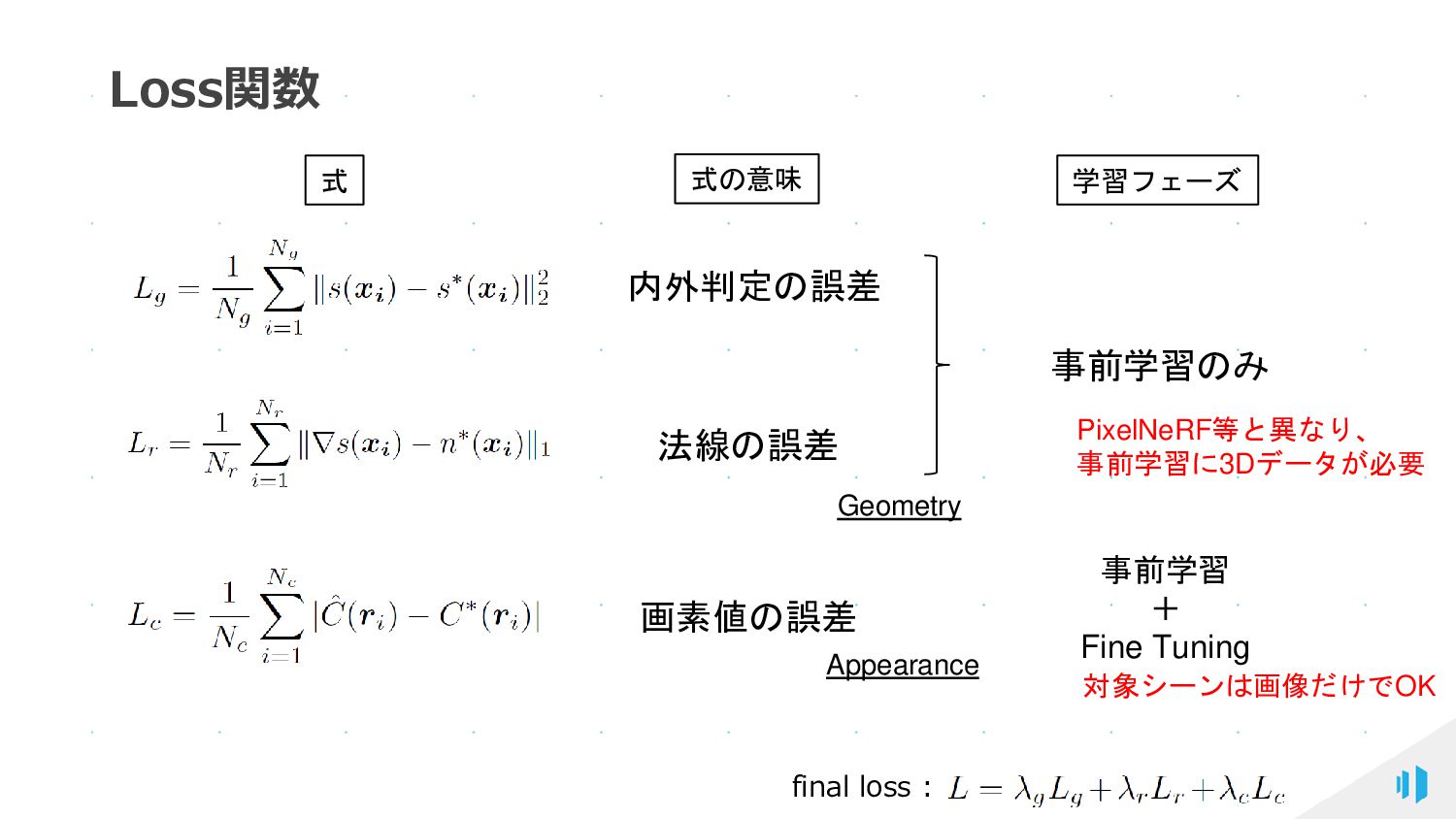{kind=link}
{kind=link}
{kind=link}
{kind=link}
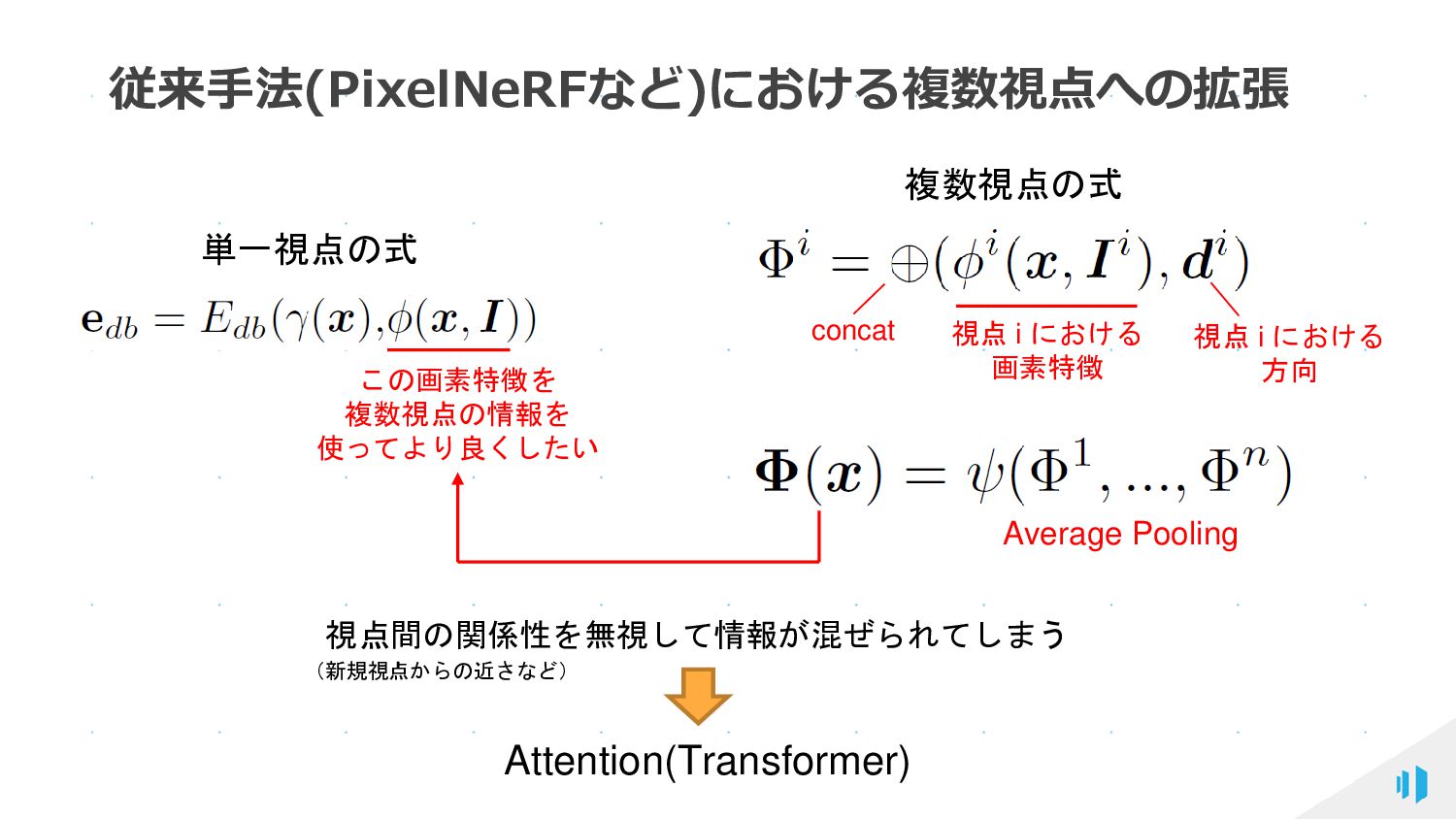{kind=link}
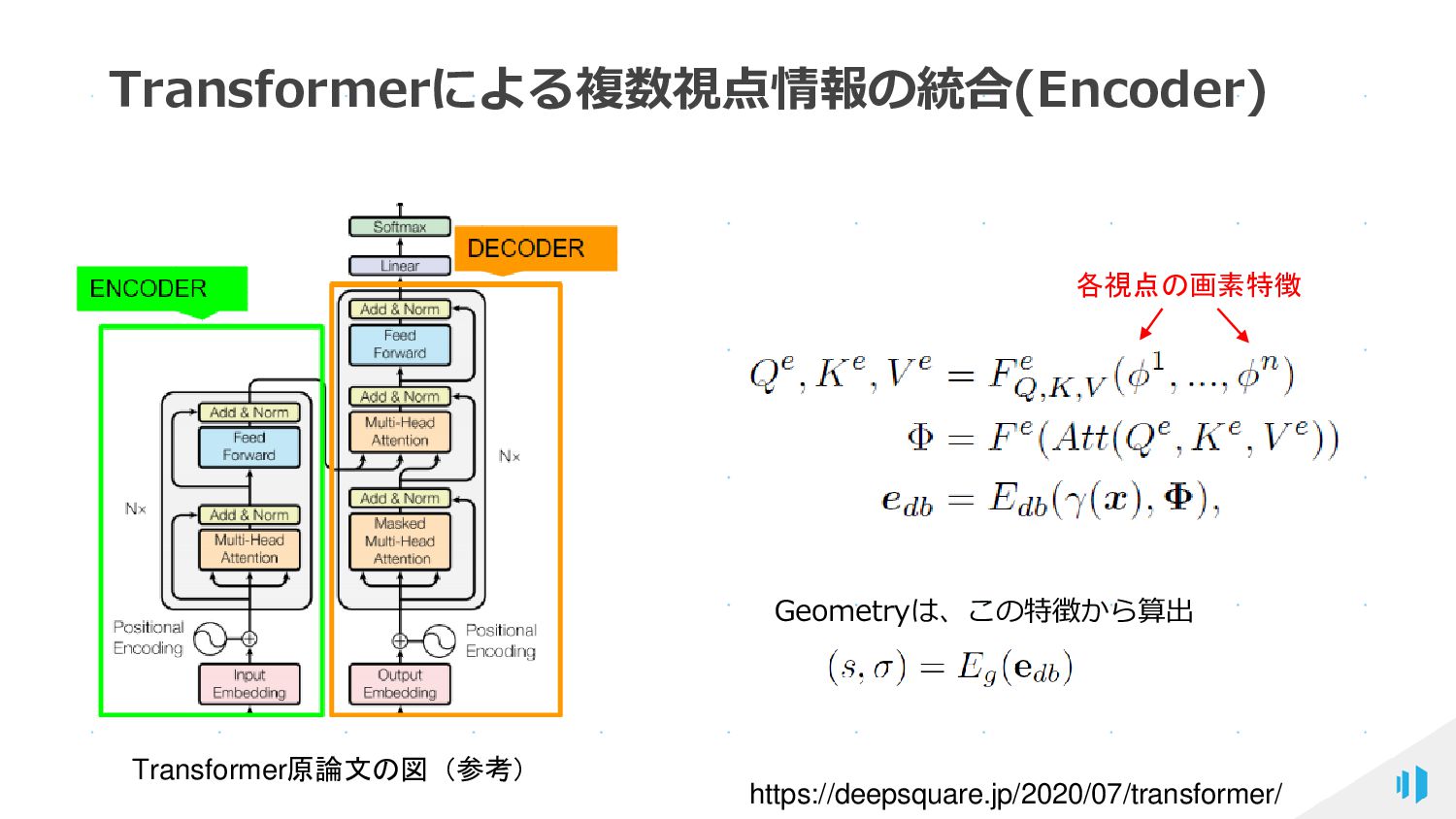{kind=link}
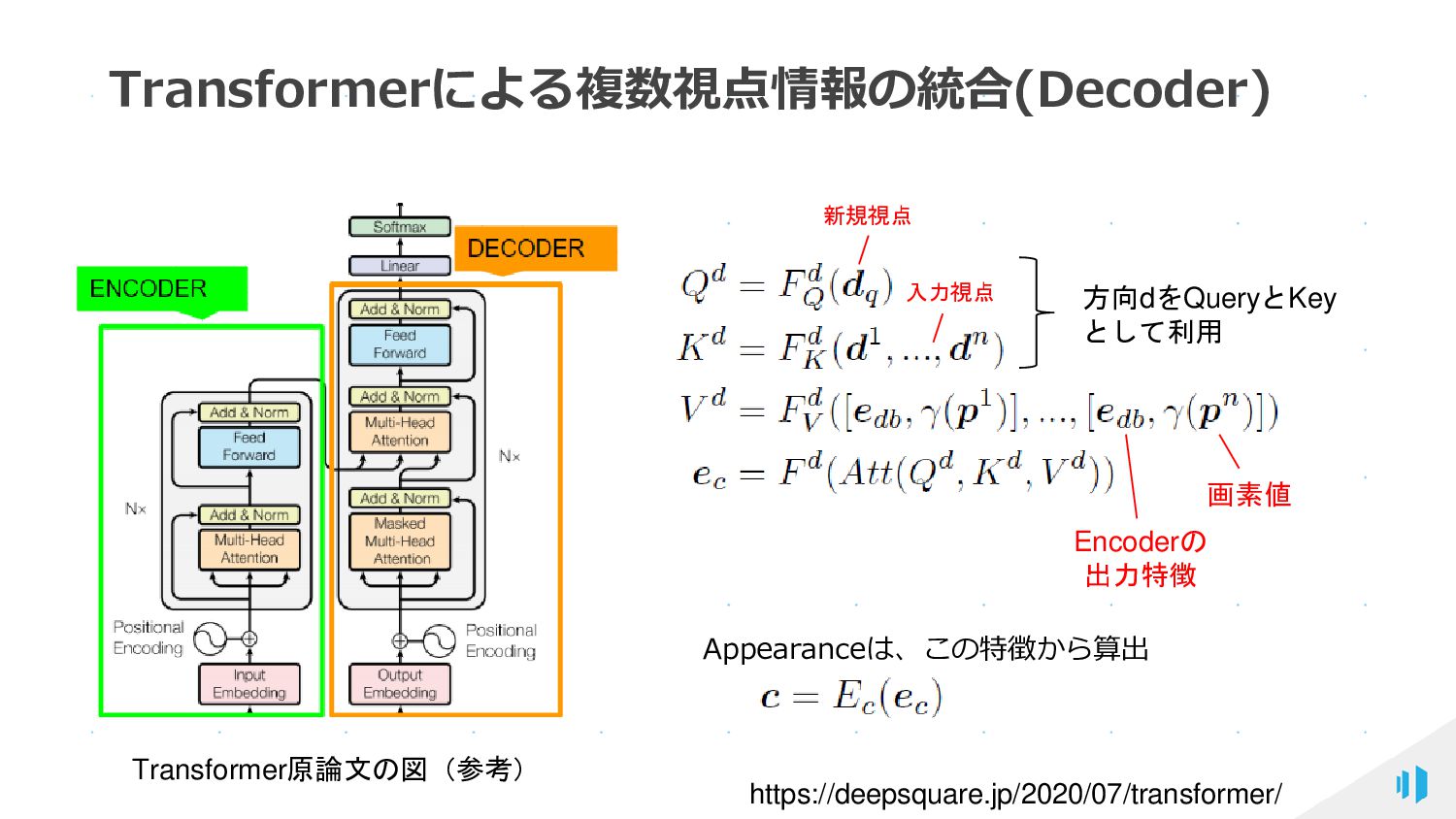{kind=link}
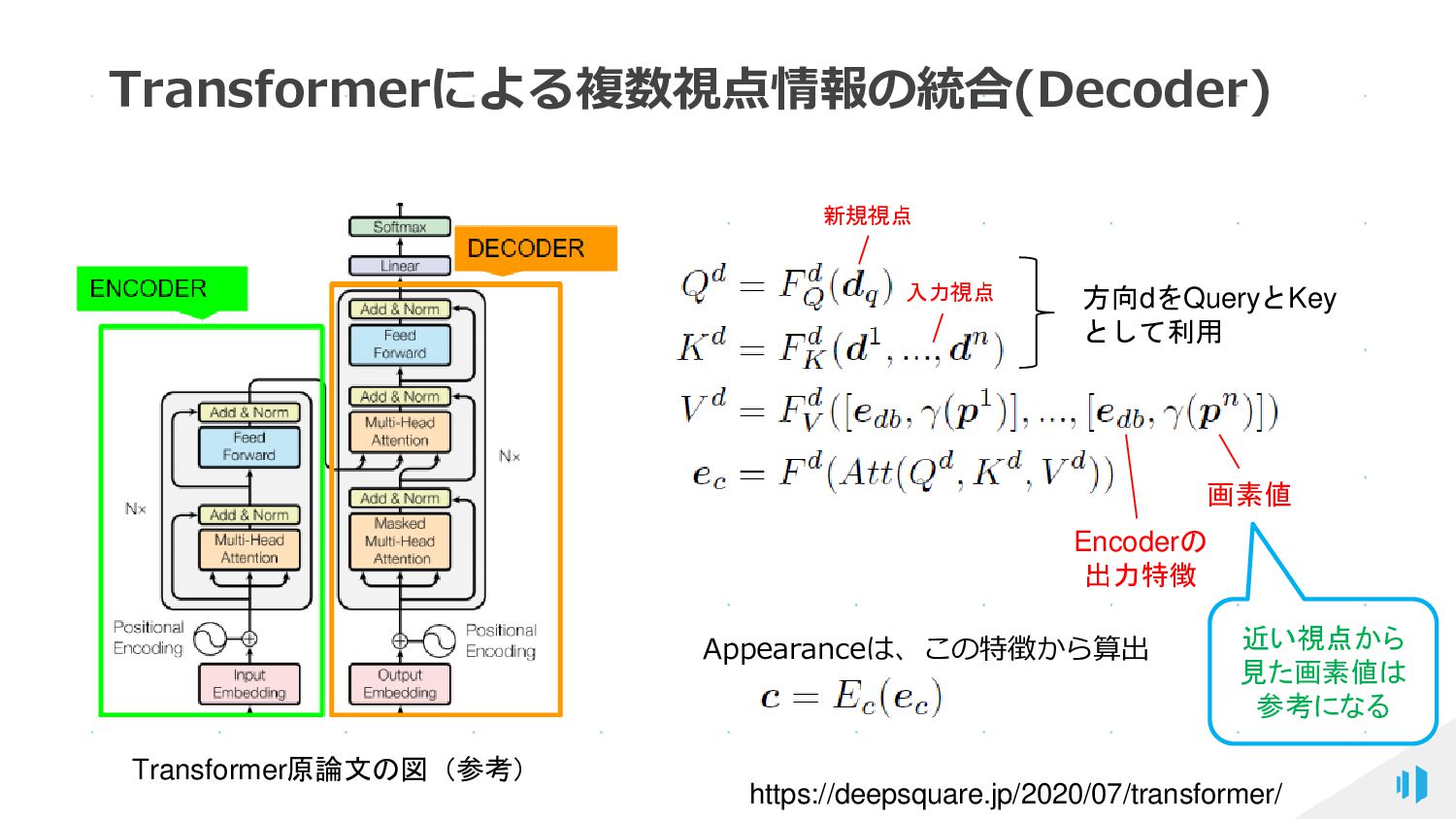{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![客観評価(3D再構成) ほぼ全ての項目について、”Our Method”が最も良い結果 FineTuning なし FineTuning あり 単位は[cm]](https://files.speakerdeck.com/presentations/26b76cc046494b5aab7cdbae4b93d46e/slide_28.jpg){kind=link}
{kind=link}
{kind=link}