I will talk about how we built and maintained a WebSockets platform on AWS infra.
You can expect to have insights about,
How to build and evovle a WebSockets platform on AWS
How we made the platform more resilient to failures known and unknown
How we saved costs by using right strategy for auto-scaling and load balancing
How to monitor a WebSockets platform
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
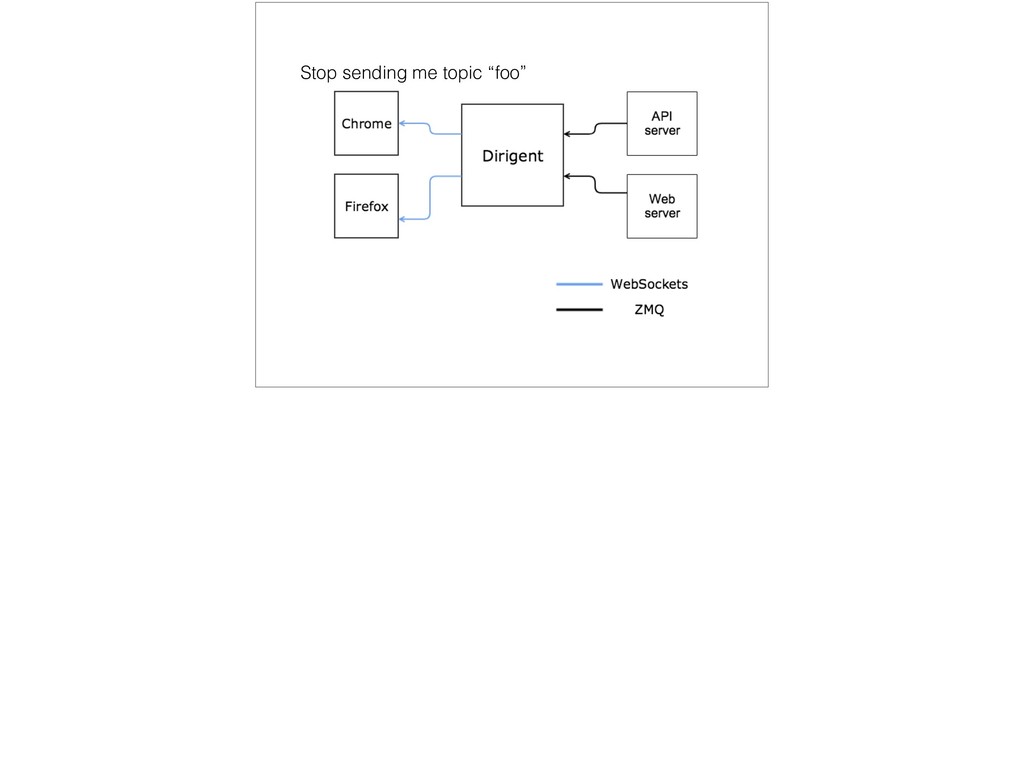{kind=link}
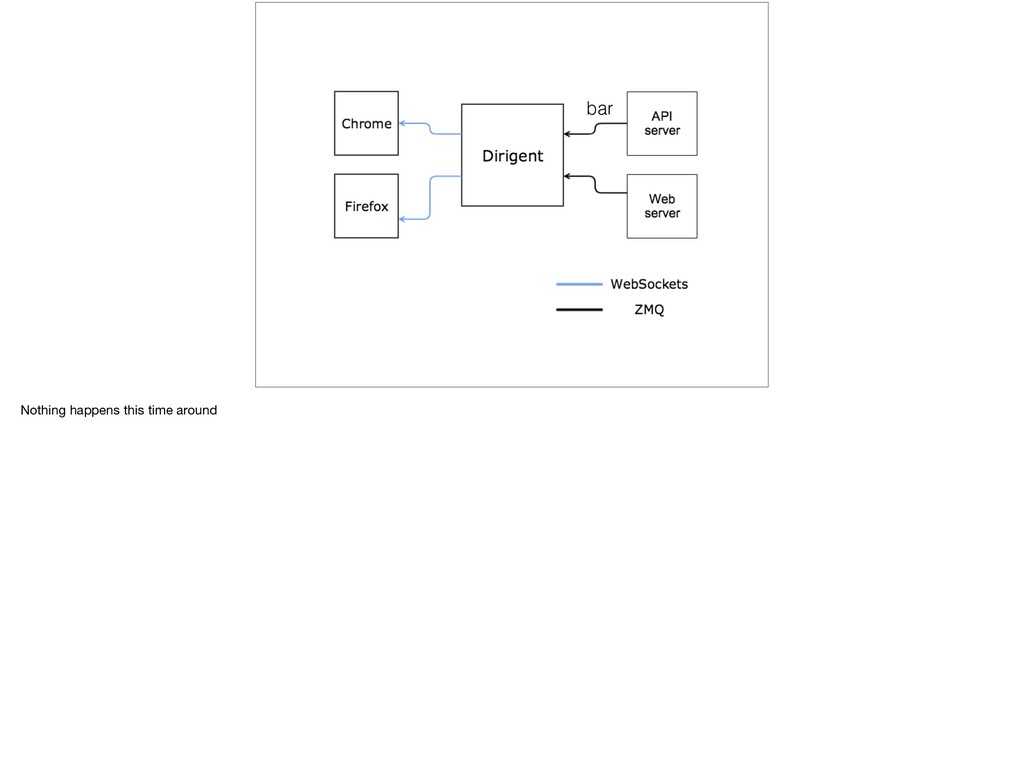{kind=link}
![bar Topics for different customers [“cust1.tickets”,”cust1.feed”] [“cust2.tickets”,”cust2.feed”] Nothing happens this](https://files.speakerdeck.com/presentations/4fe43542208d409db685587c6b786e72/slide_21.jpg){kind=link}
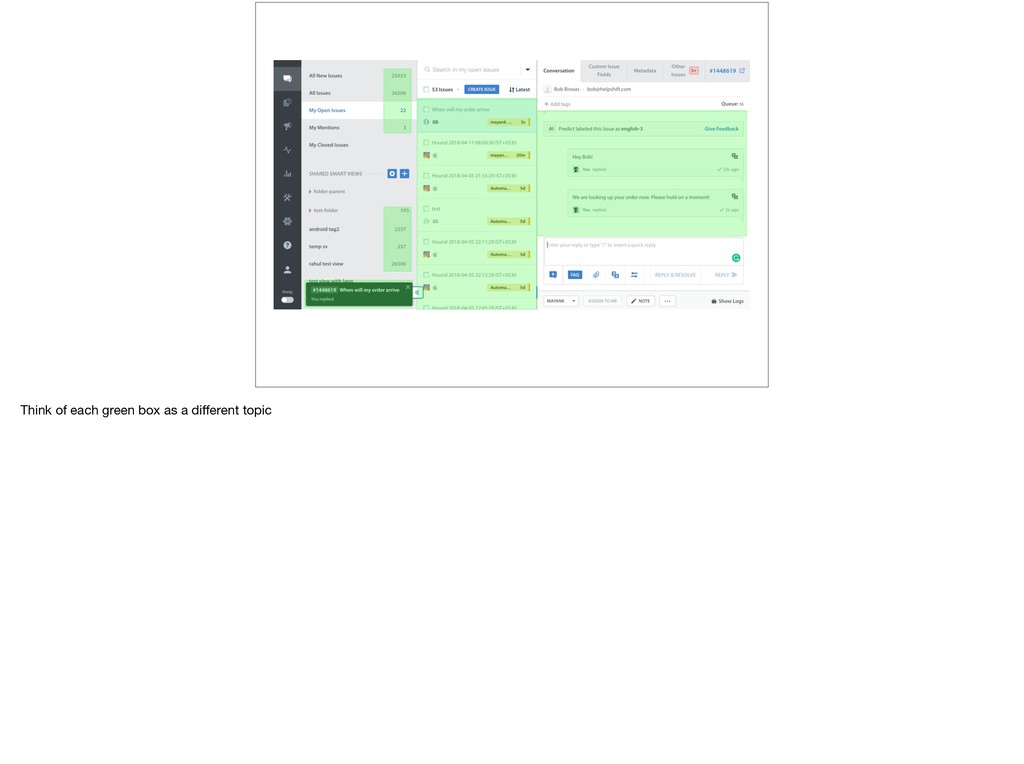{kind=link}
{kind=link}
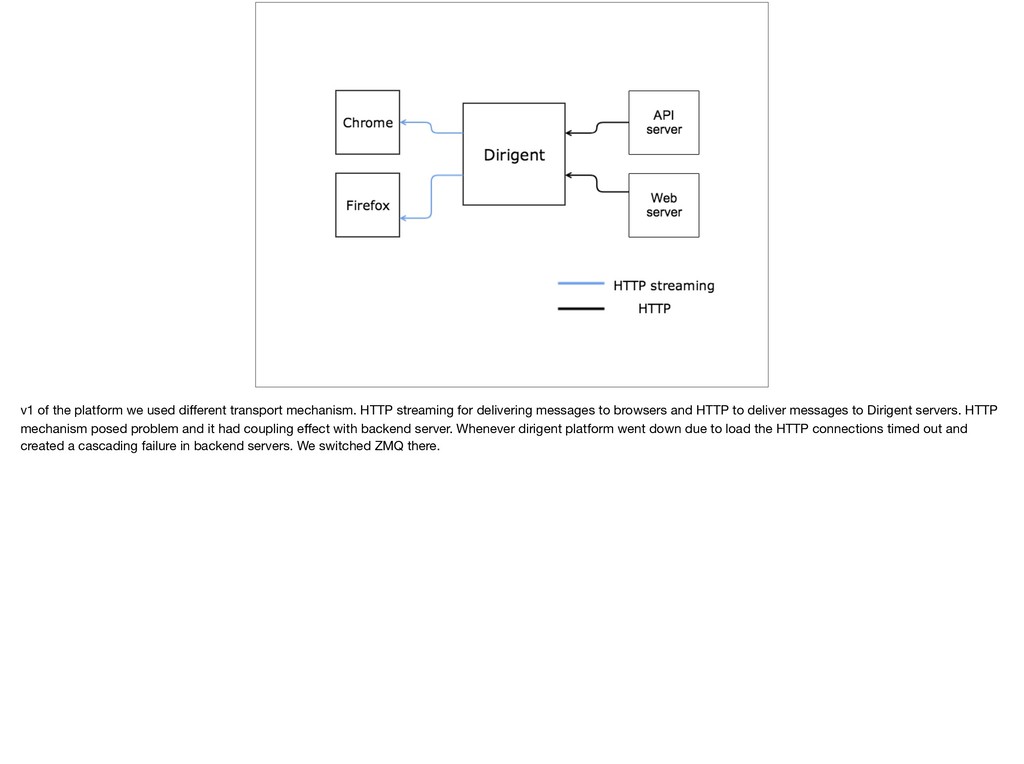{kind=link}
{kind=link}
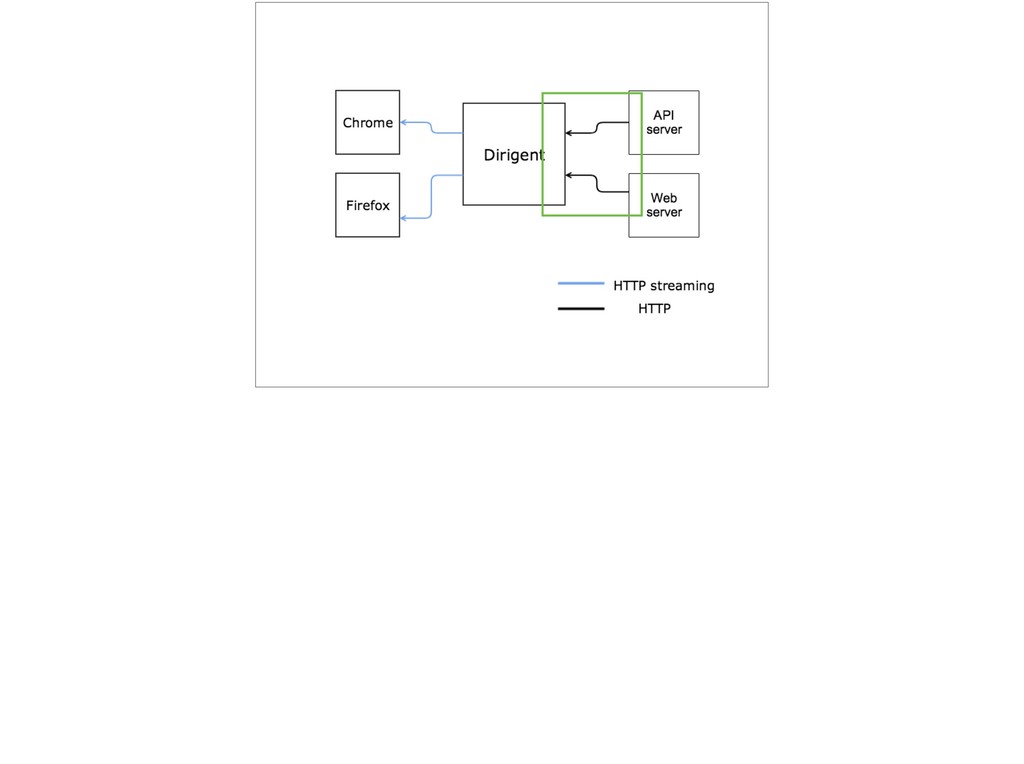{kind=link}
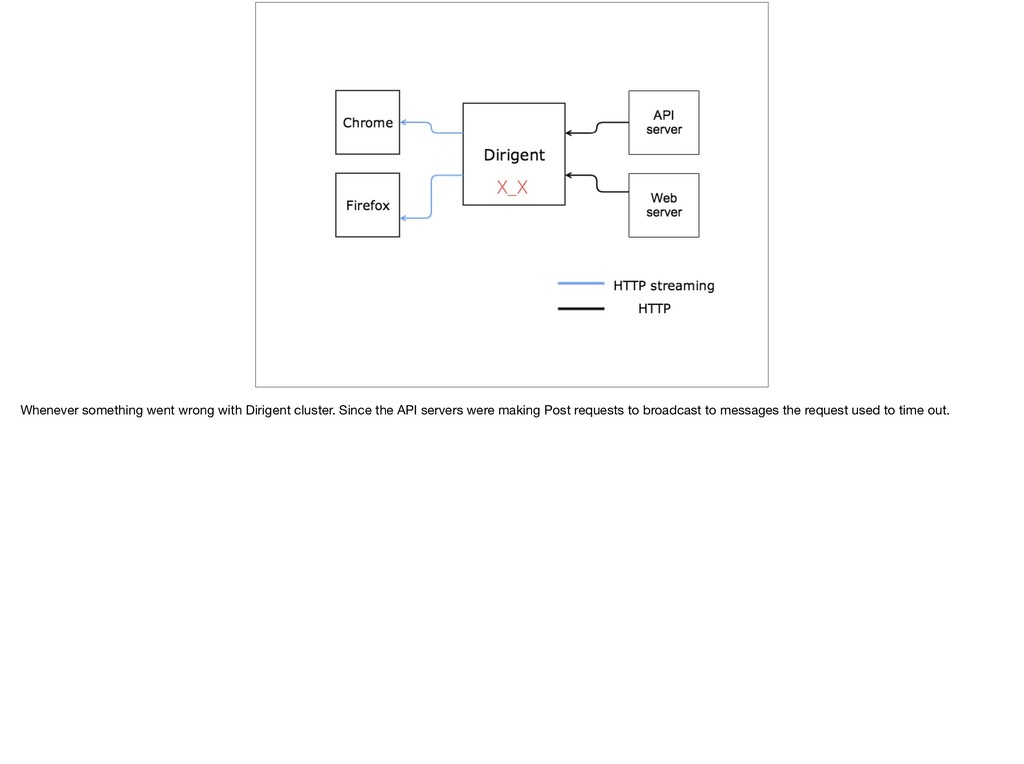{kind=link}
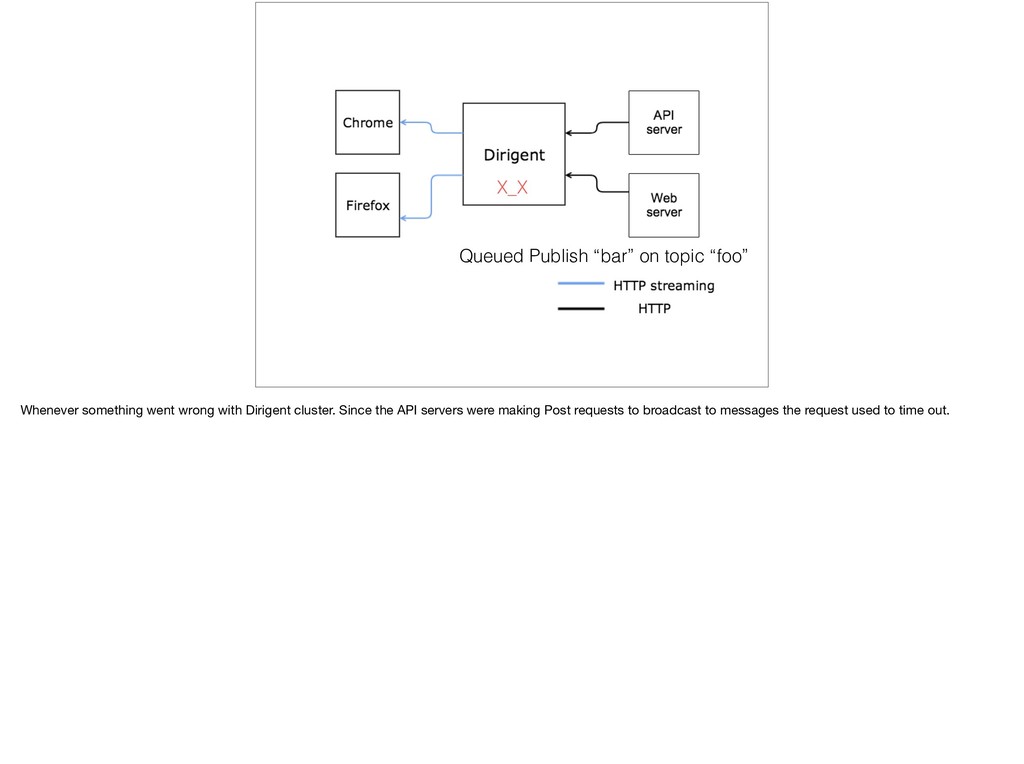{kind=link}
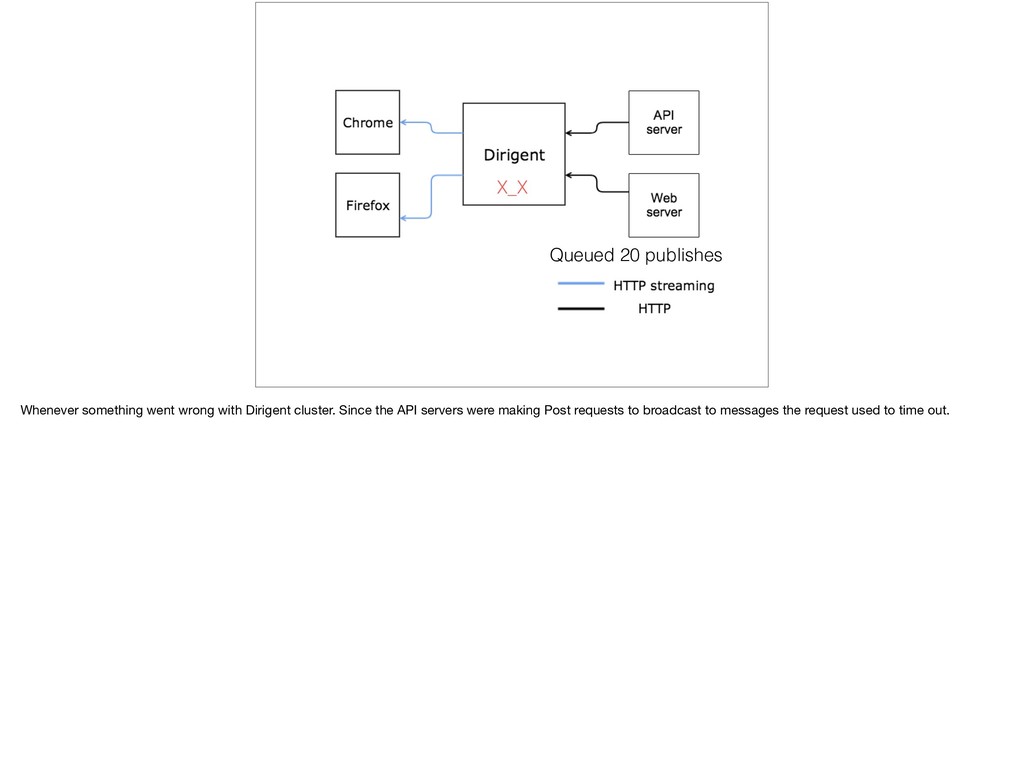{kind=link}
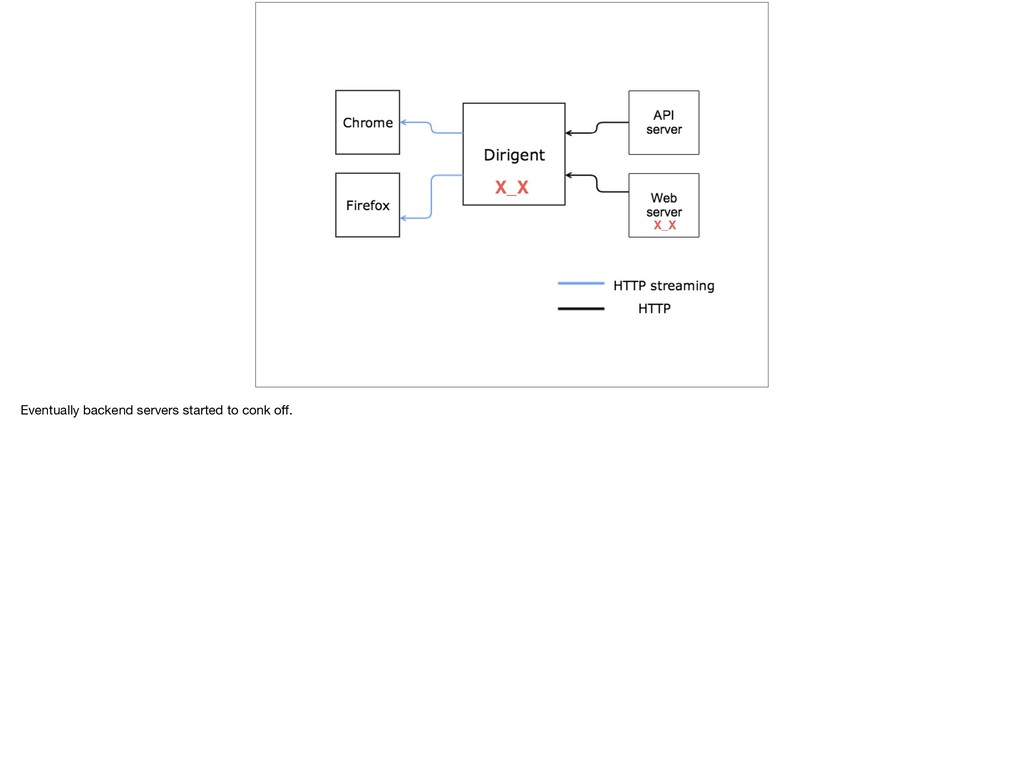{kind=link}
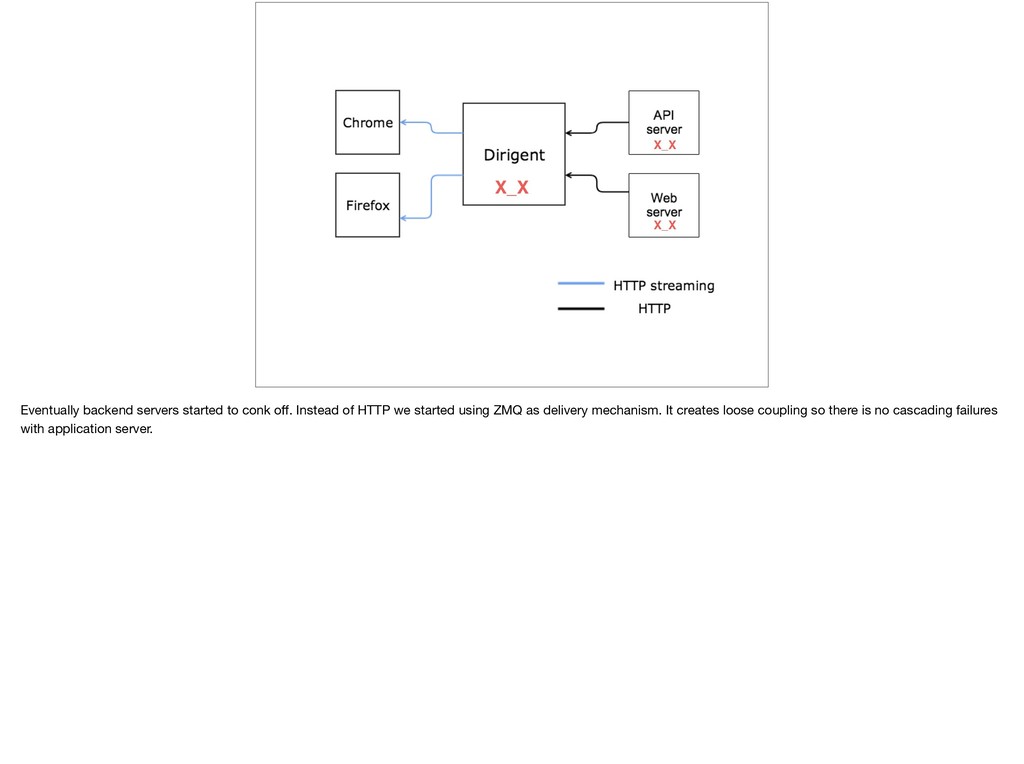{kind=link}
{kind=link}
{kind=link}
{kind=link}
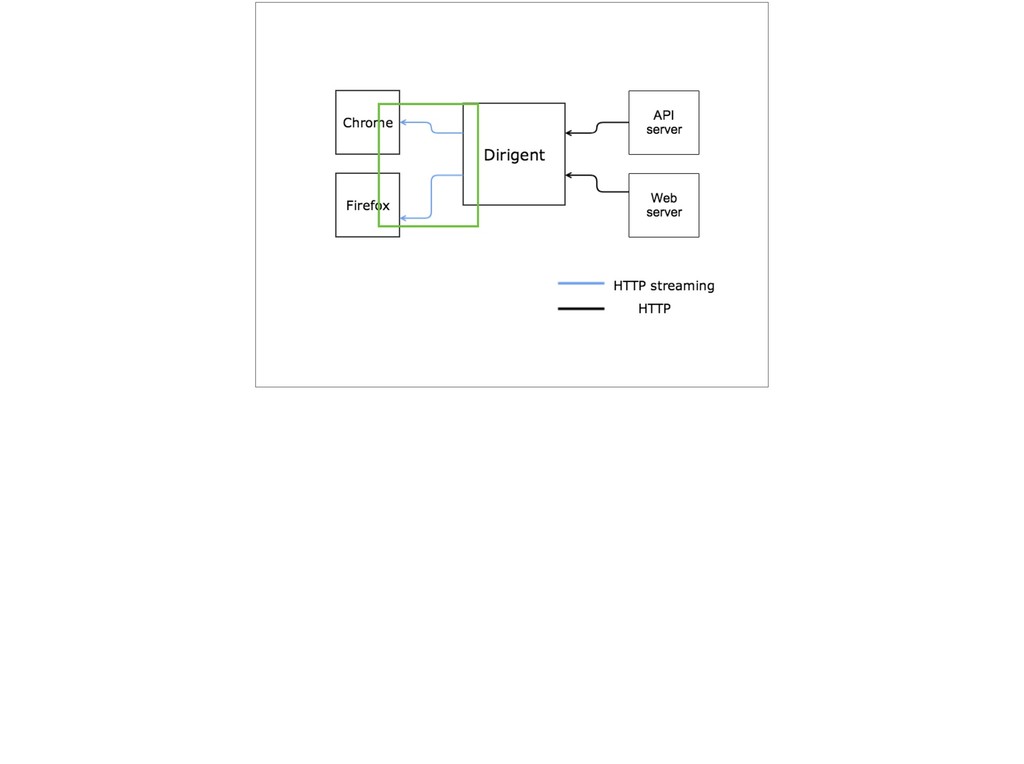{kind=link}
![[“cust1”] [“cust2”]](https://files.speakerdeck.com/presentations/4fe43542208d409db685587c6b786e72/slide_36.jpg){kind=link}
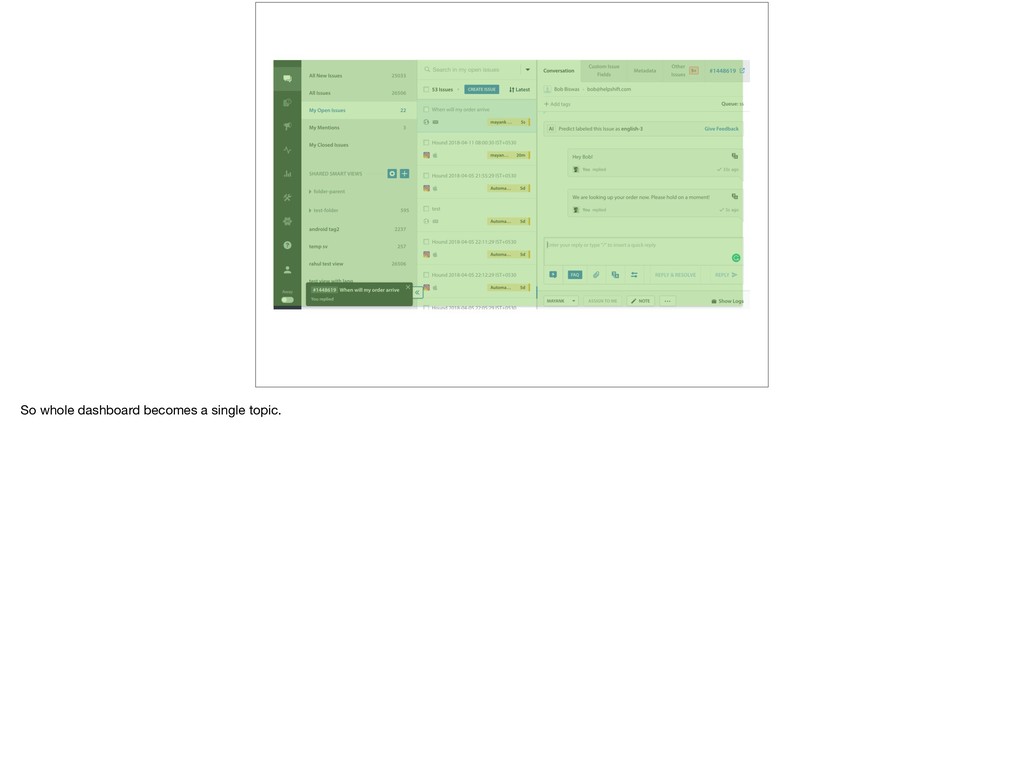{kind=link}
![[“cust1”] Cust 1 - Ticket 100 Looking at Ticket 1](https://files.speakerdeck.com/presentations/4fe43542208d409db685587c6b786e72/slide_38.jpg){kind=link}
![[“cust1”] Cust 1 - Ticket 101 Looking at Ticket 1](https://files.speakerdeck.com/presentations/4fe43542208d409db685587c6b786e72/slide_39.jpg){kind=link}
![[“cust1”] Cust 1 - Ticket 103 Looking at Ticket 1](https://files.speakerdeck.com/presentations/4fe43542208d409db685587c6b786e72/slide_40.jpg){kind=link}
![[“cust1”] Cust 1 - Ticket 500 Looking at Ticket 1](https://files.speakerdeck.com/presentations/4fe43542208d409db685587c6b786e72/slide_41.jpg){kind=link}
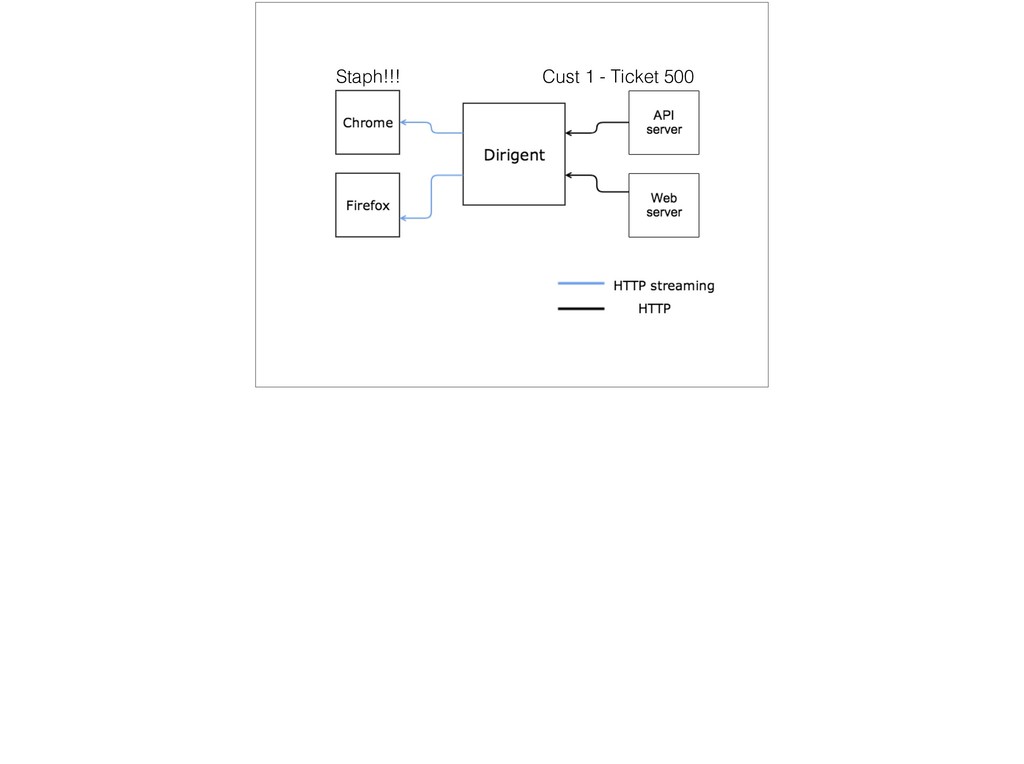{kind=link}
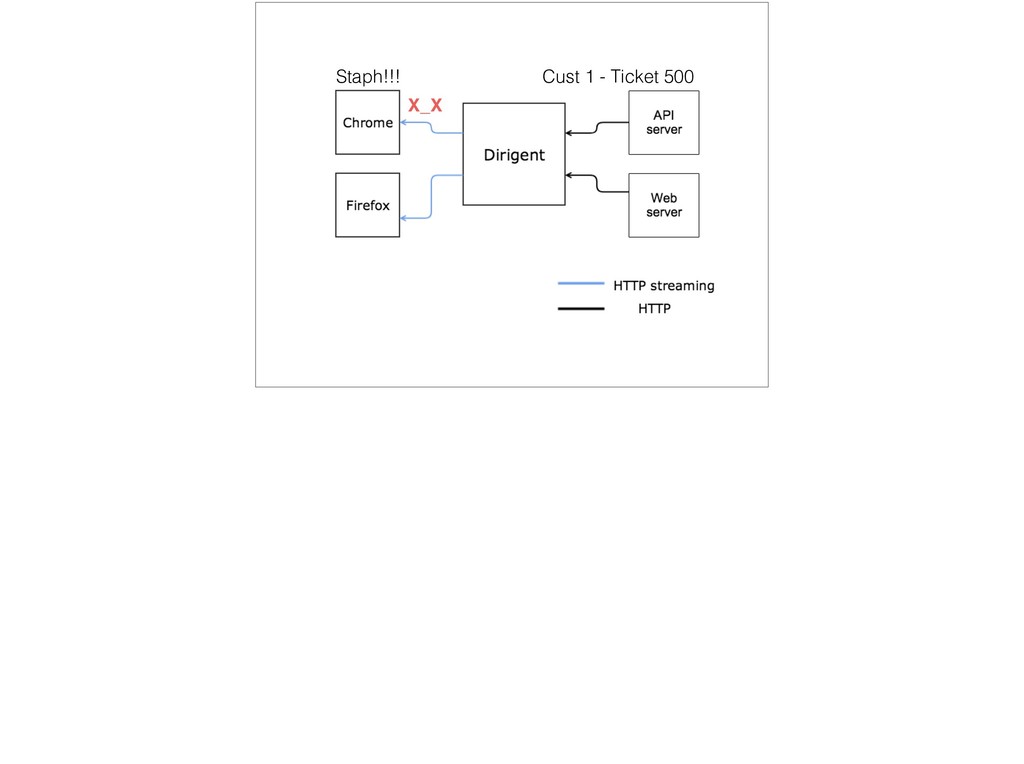{kind=link}
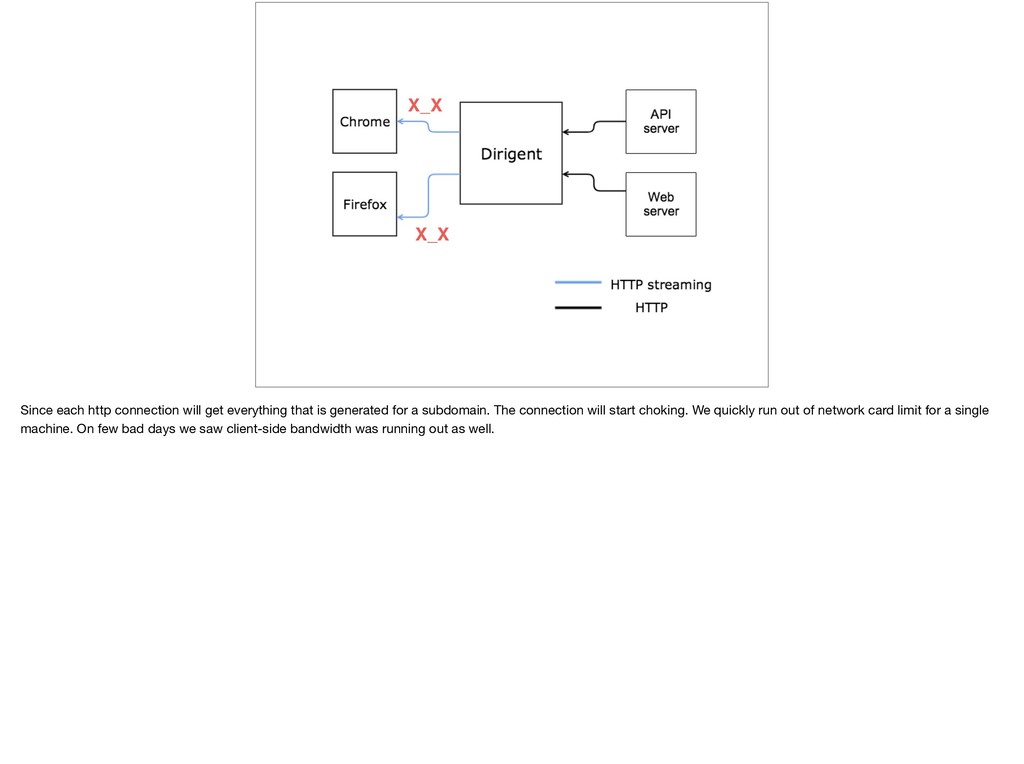{kind=link}
{kind=link}
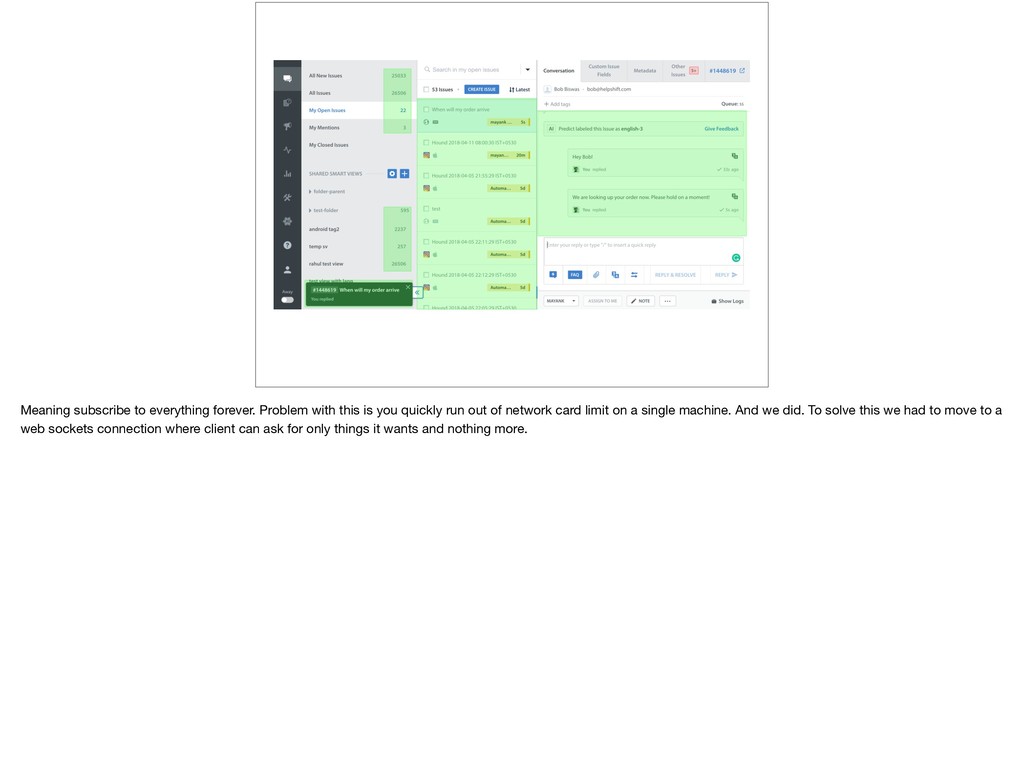{kind=link}
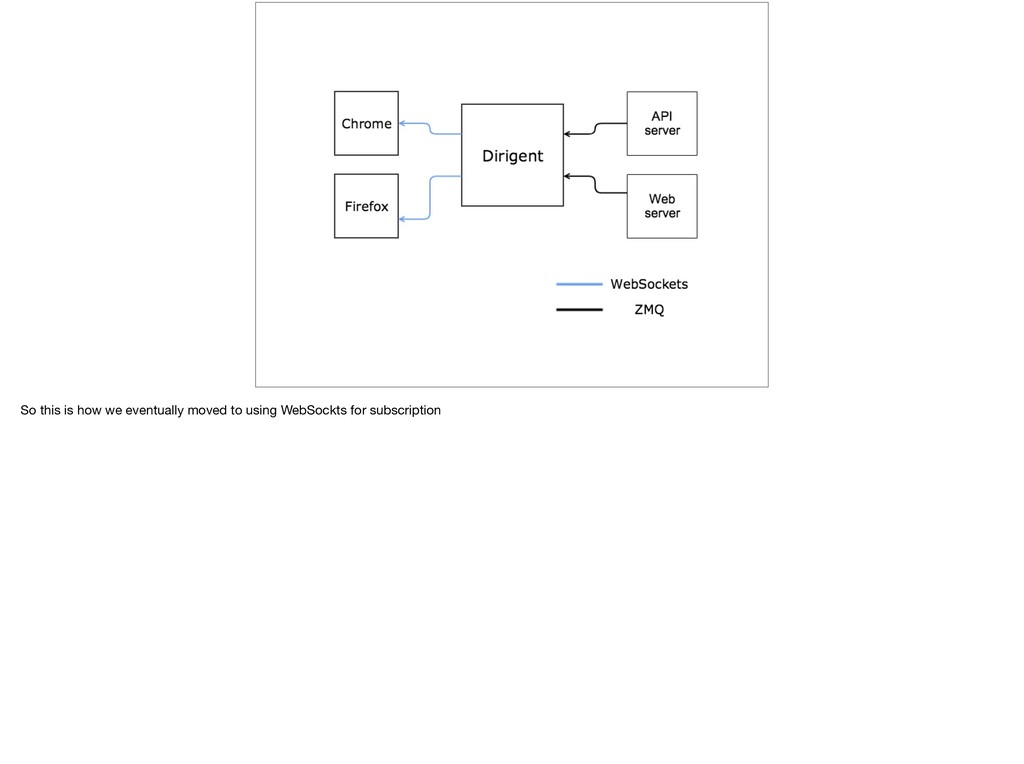{kind=link}
{kind=link}
{kind=link}
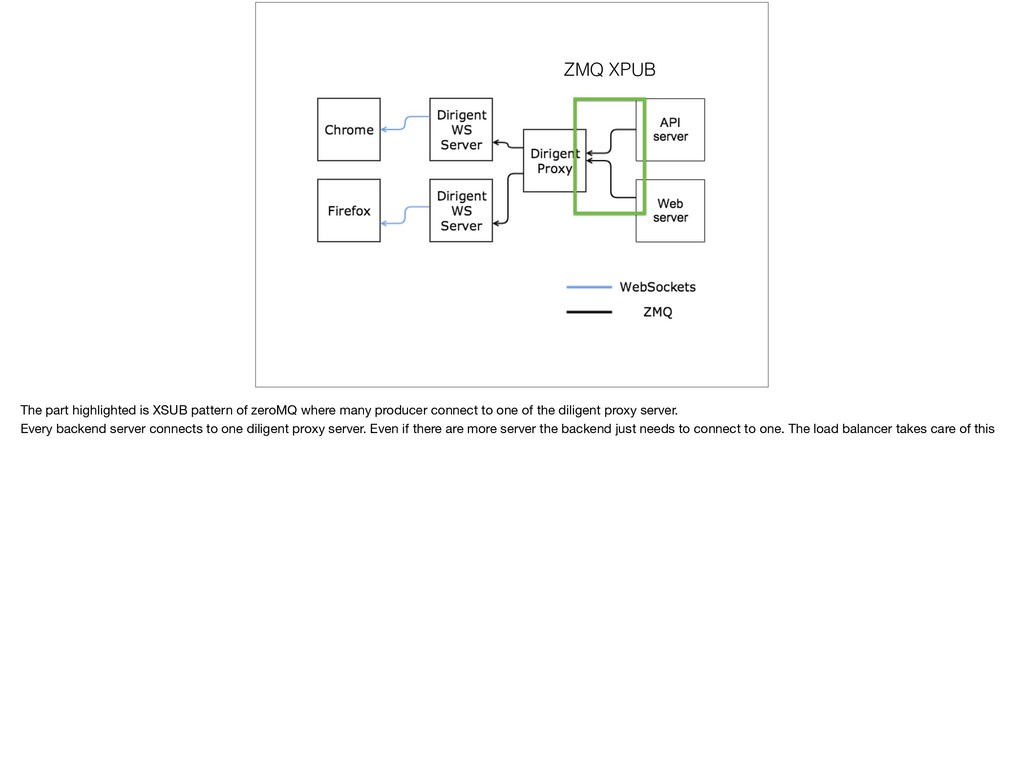{kind=link}
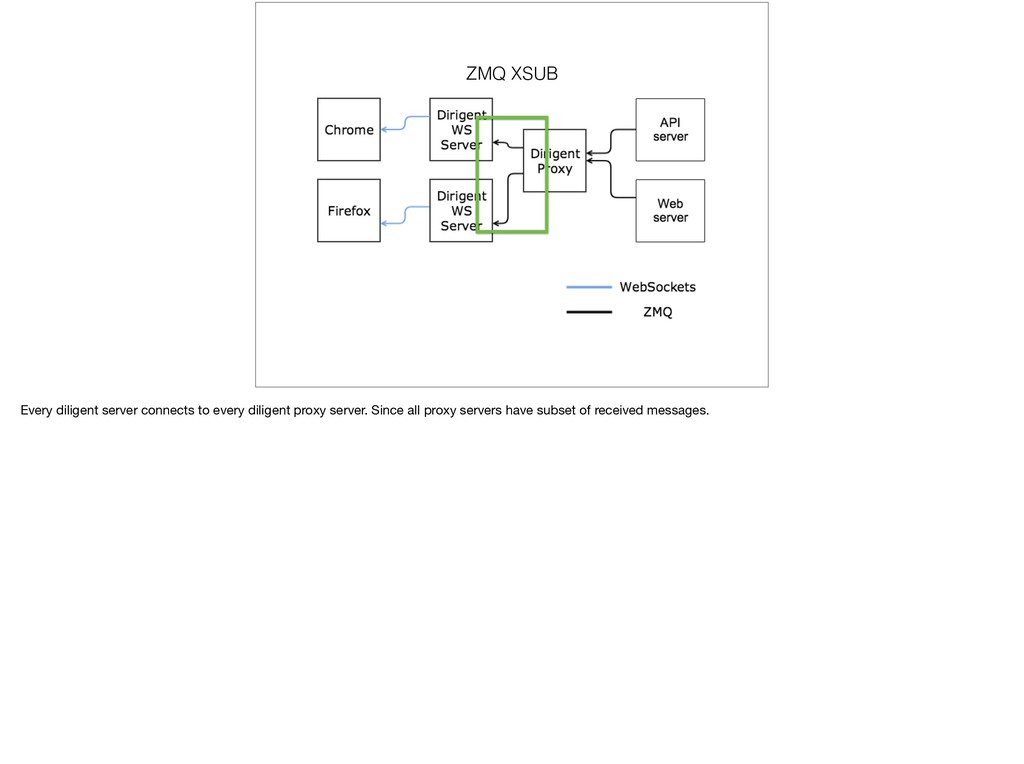{kind=link}
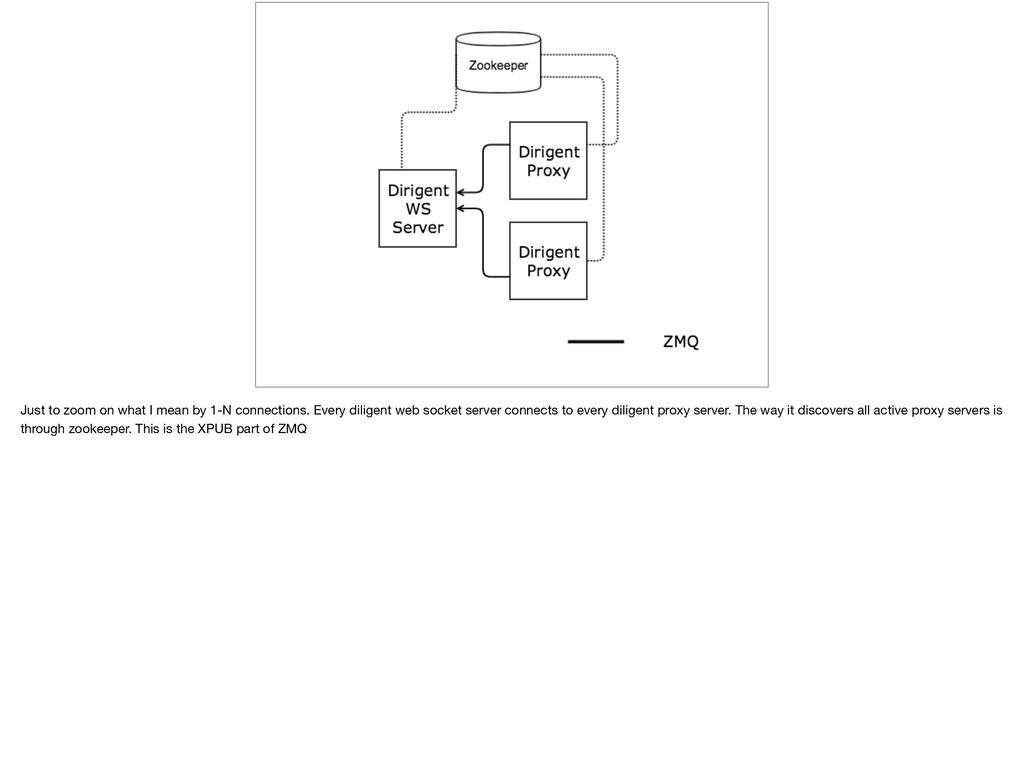{kind=link}
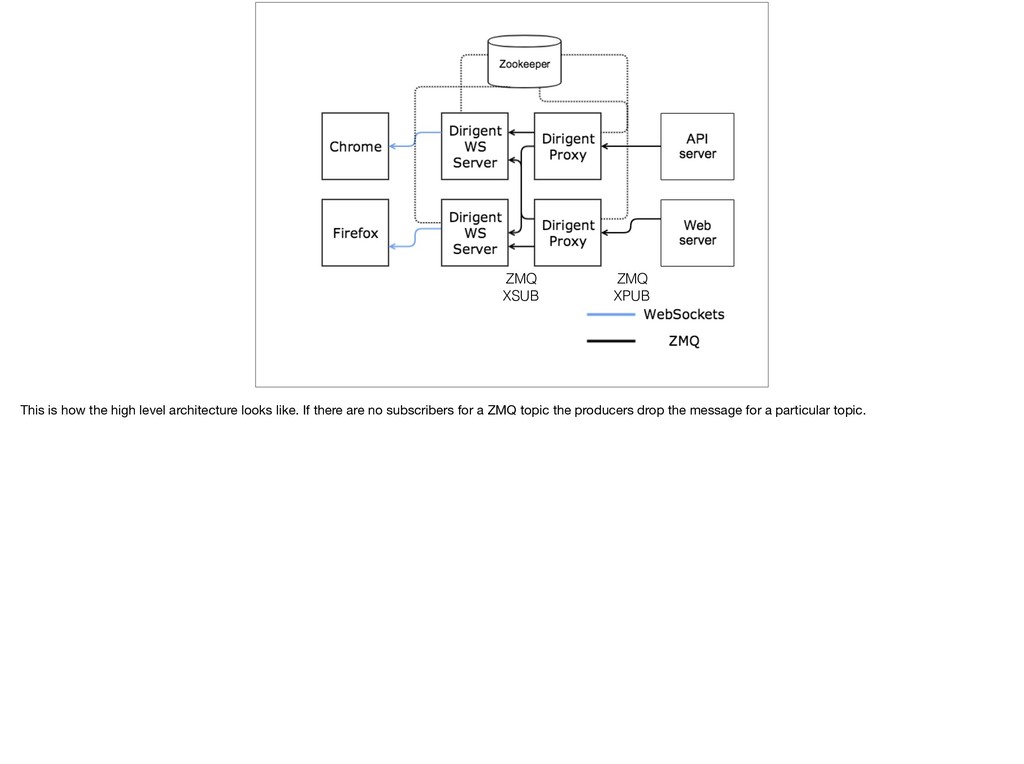{kind=link}
{kind=link}
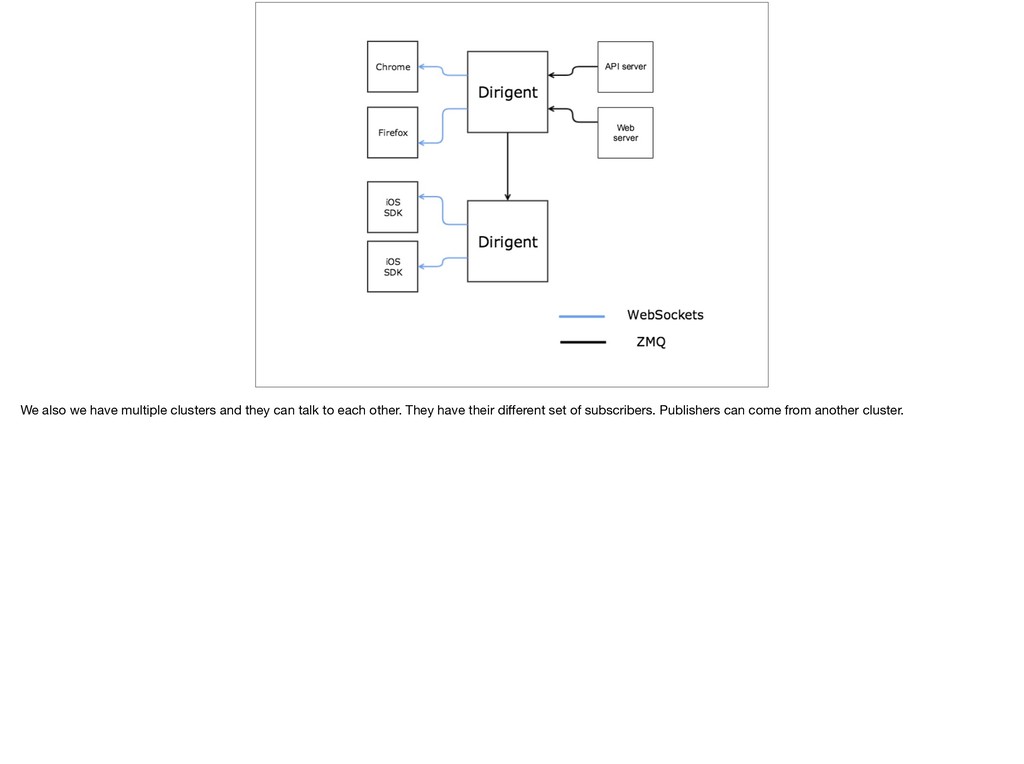{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
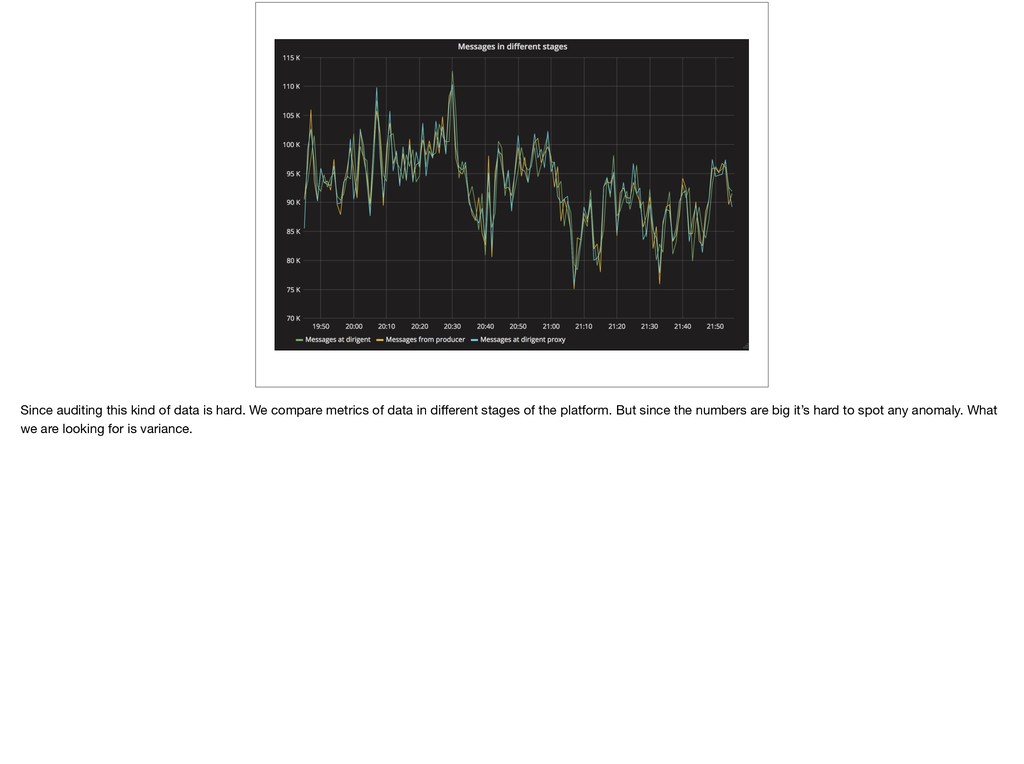{kind=link}
{kind=link}
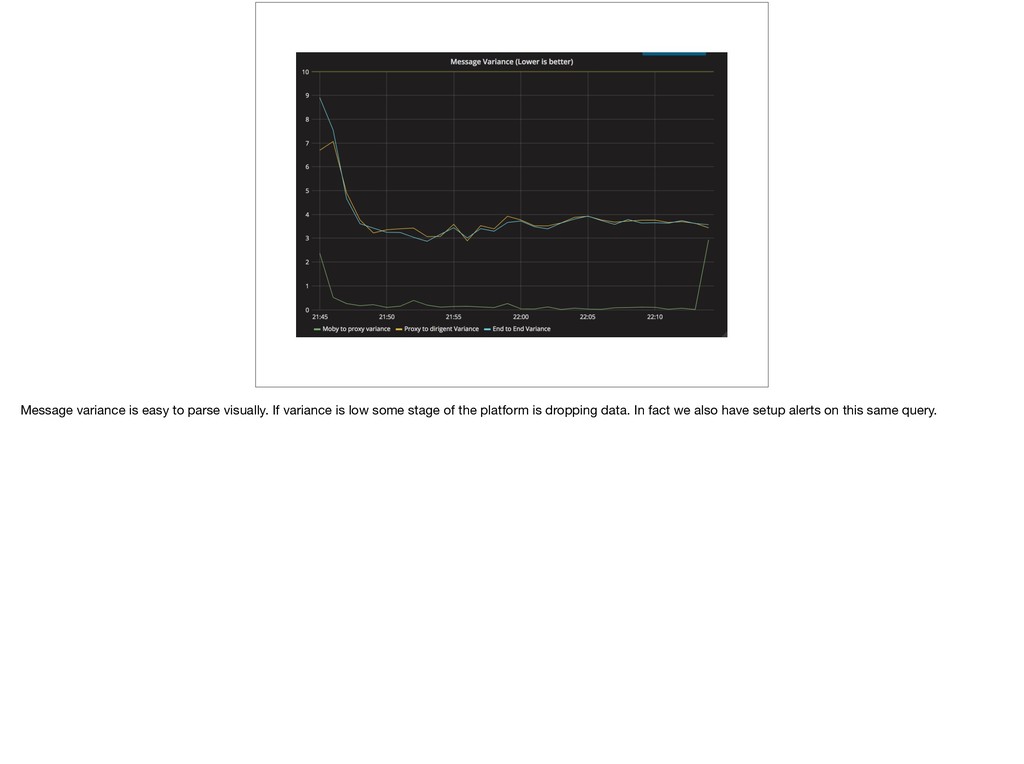{kind=link}
{kind=link}
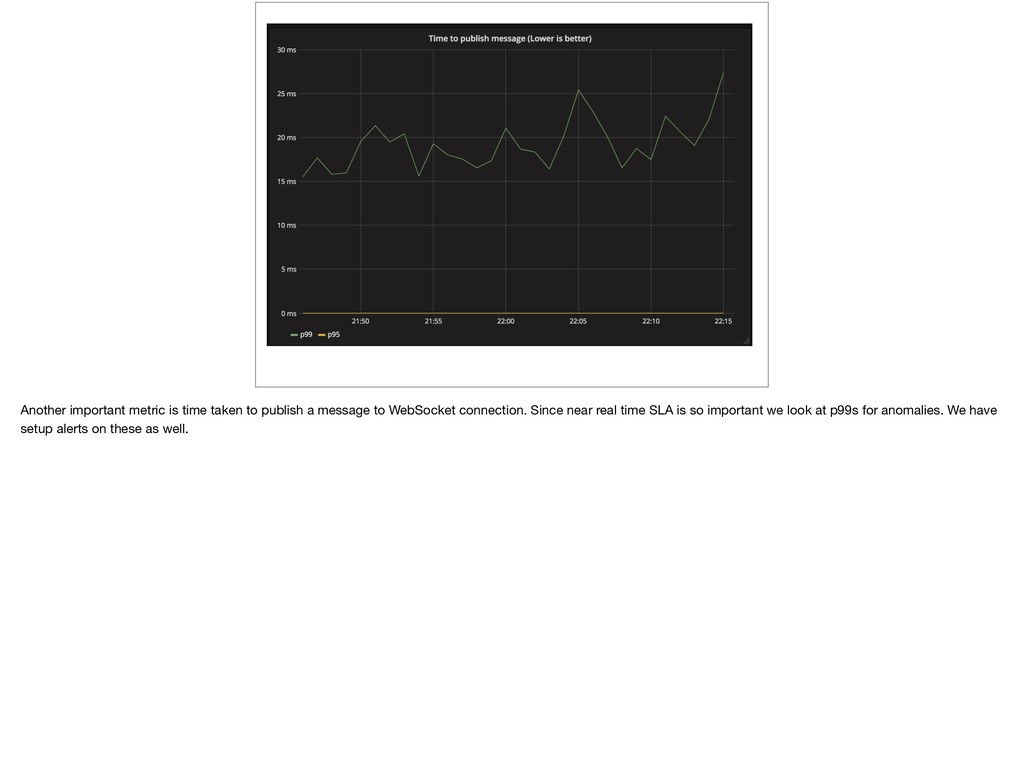{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
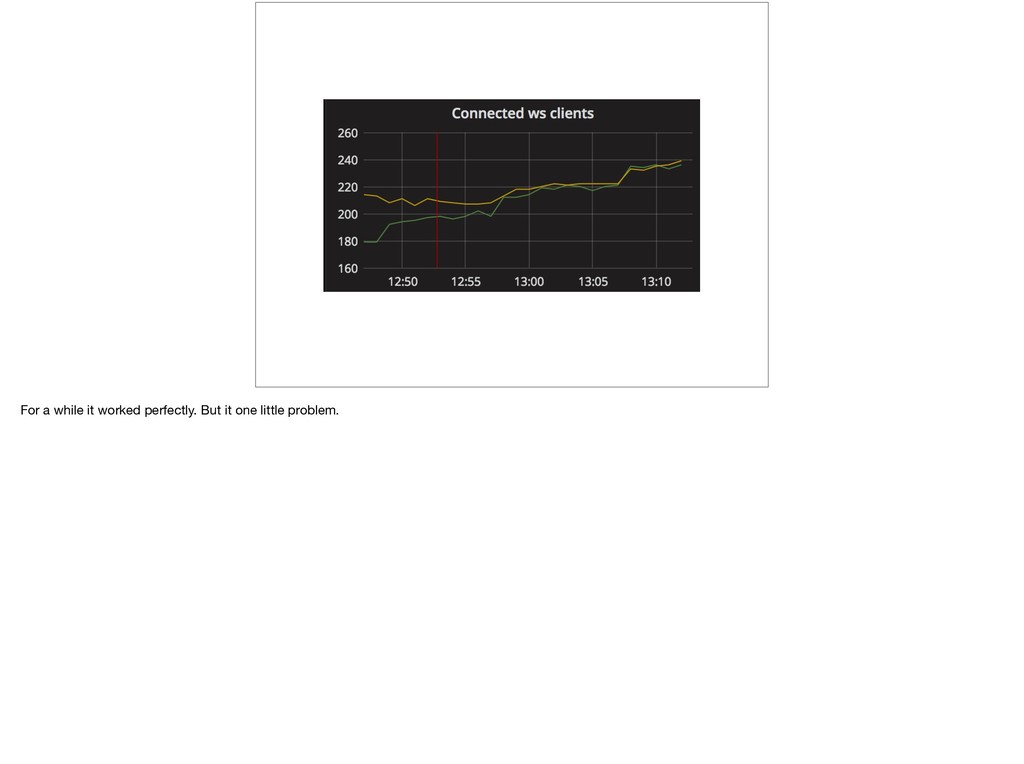{kind=link}
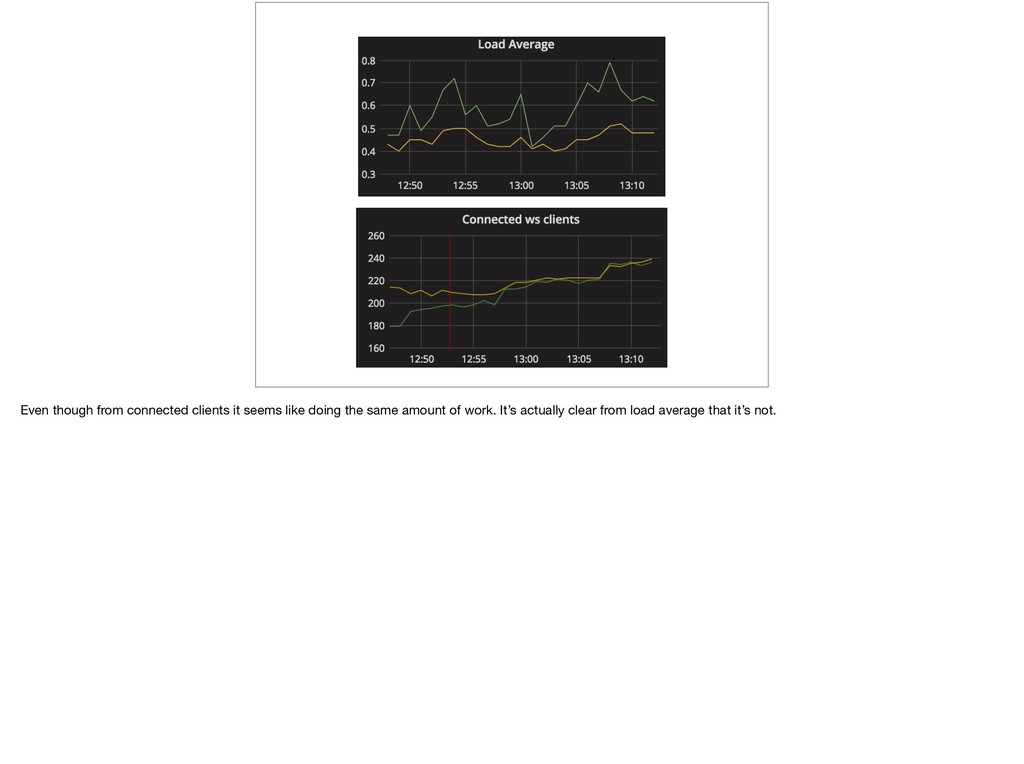{kind=link}
{kind=link}
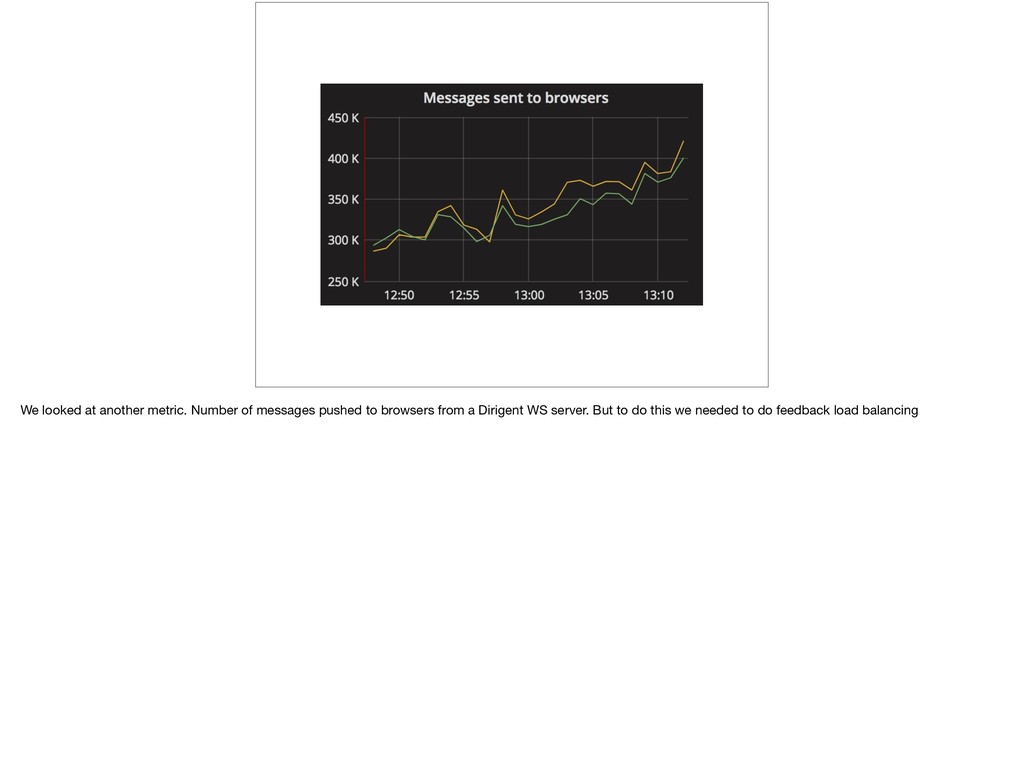{kind=link}
{kind=link}
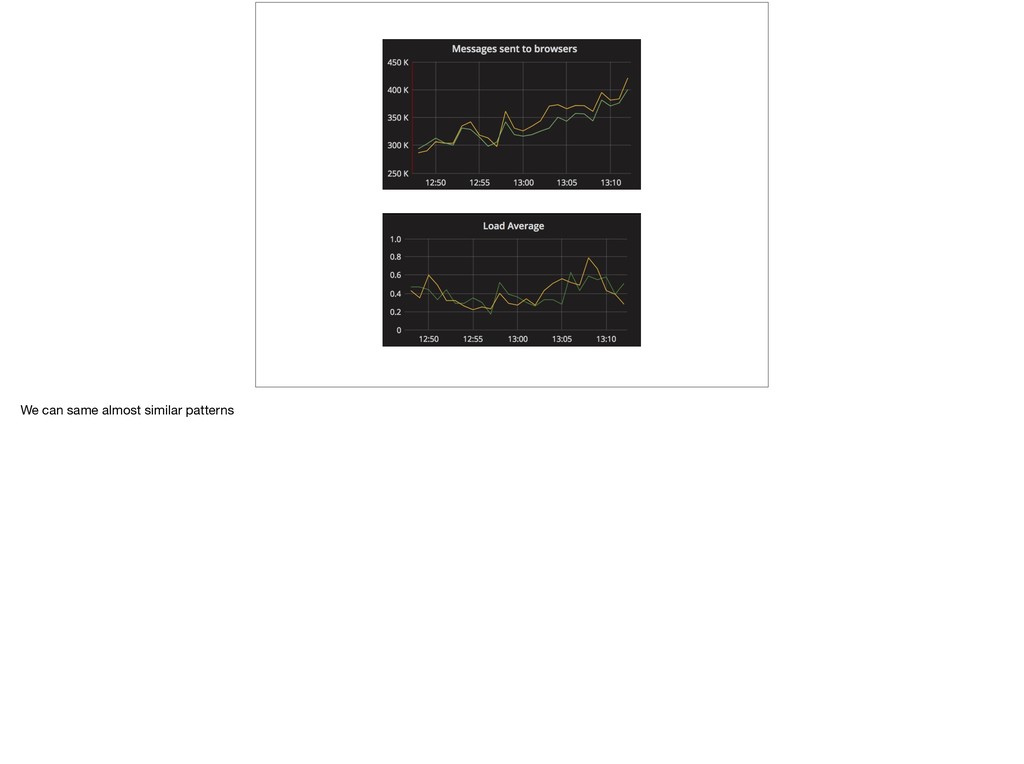{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
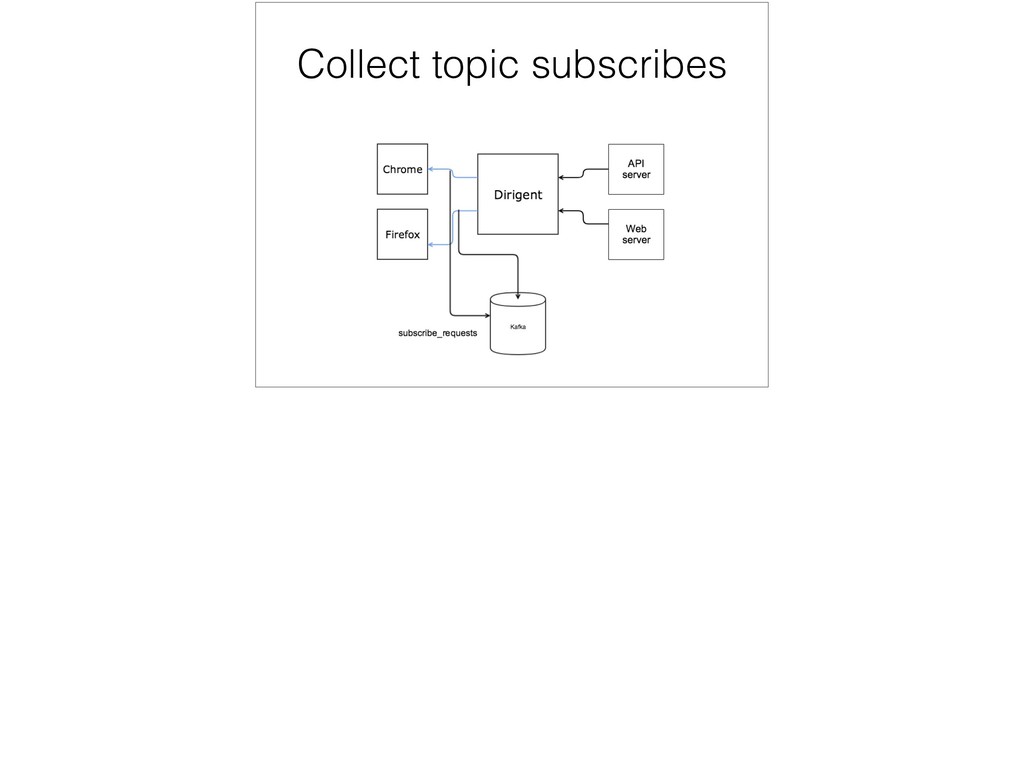{kind=link}
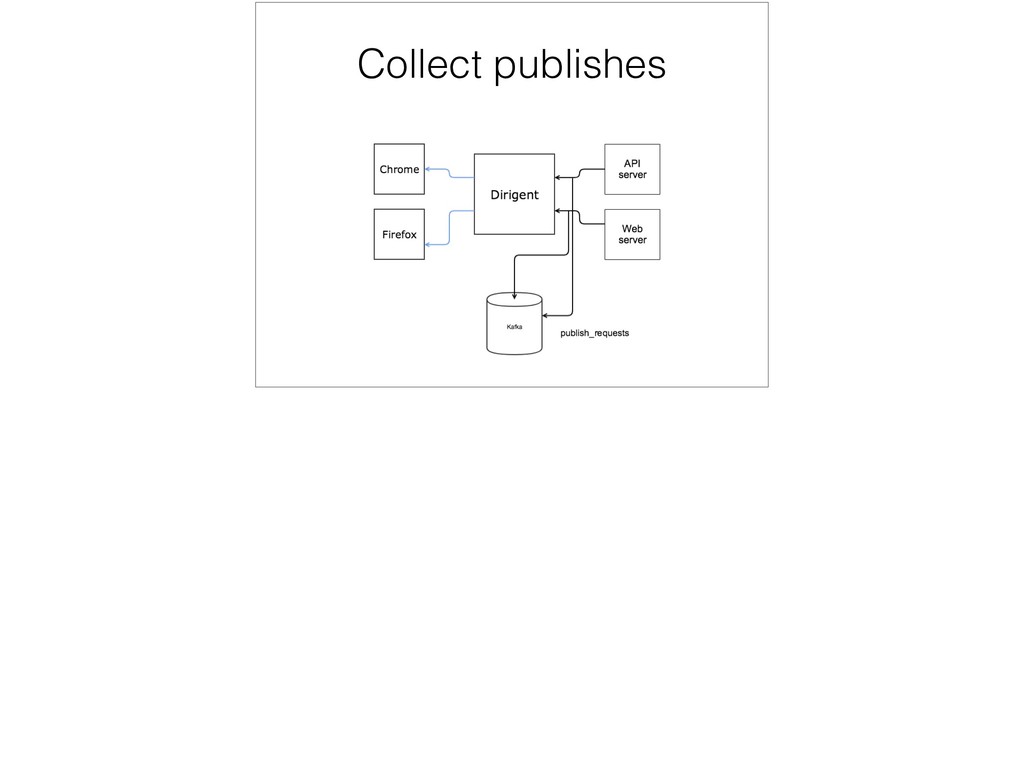{kind=link}
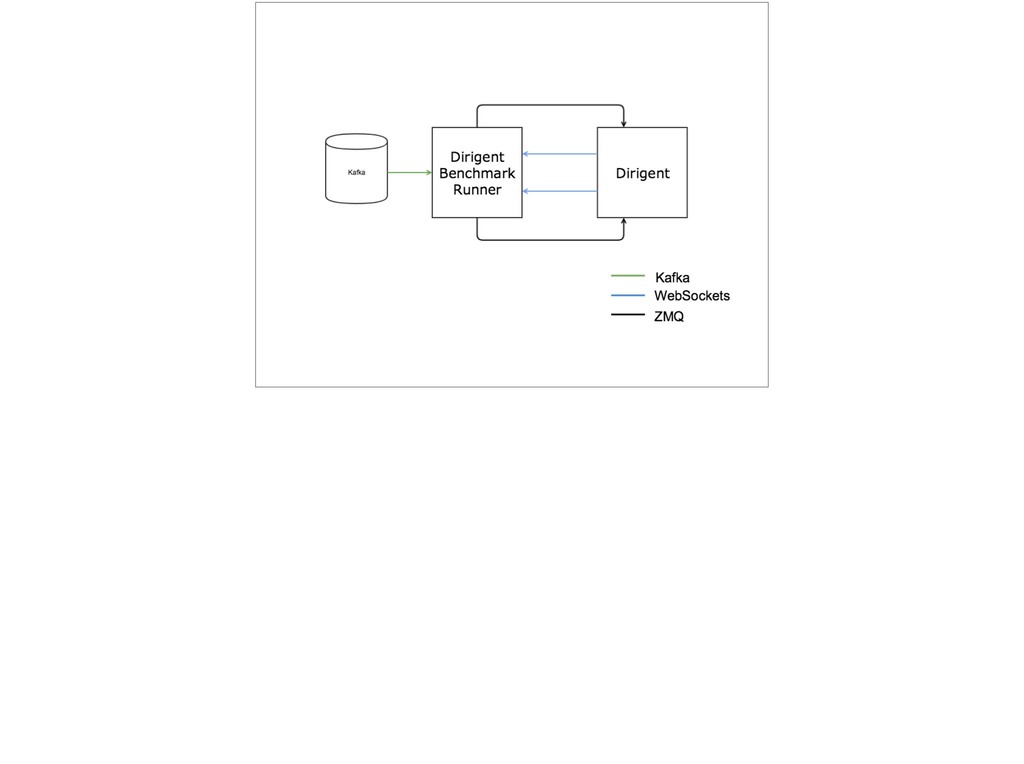{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}