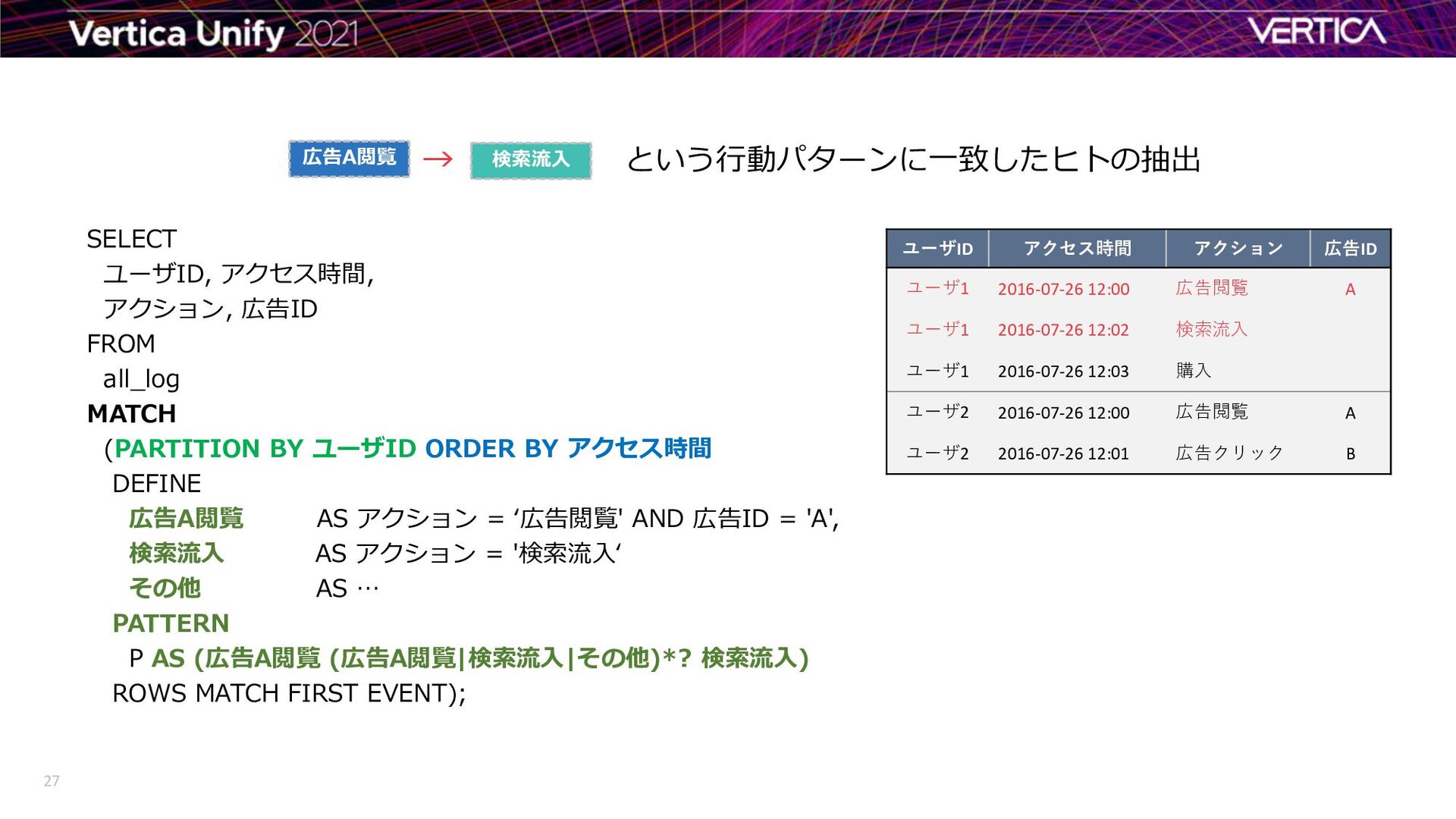
BY ユーザID ORDER BY アクセス時間 DEFINE 広告A閲覧 AS アクション = ‘広告閲覧' AND 広告ID = 'A', 検索流入 AS アクション = '検索流入‘ その他 AS … PATTERN P AS (広告A閲覧 (広告A閲覧|検索流入|その他)*? 検索流入) ROWS MATCH FIRST EVENT); ユーザID アクセス時間 アクション 広告ID ユーザ1 2016-07-26 12:00 広告閲覧 A ユーザ1 2016-07-26 12:02 検索流入 ユーザ1 2016-07-26 12:03 購入 ユーザ2 2016-07-26 12:00 広告閲覧 A ユーザ2 2016-07-26 12:01 広告クリック B という行動パターンに一致したヒトの抽出 広告A閲覧 検索流入 →
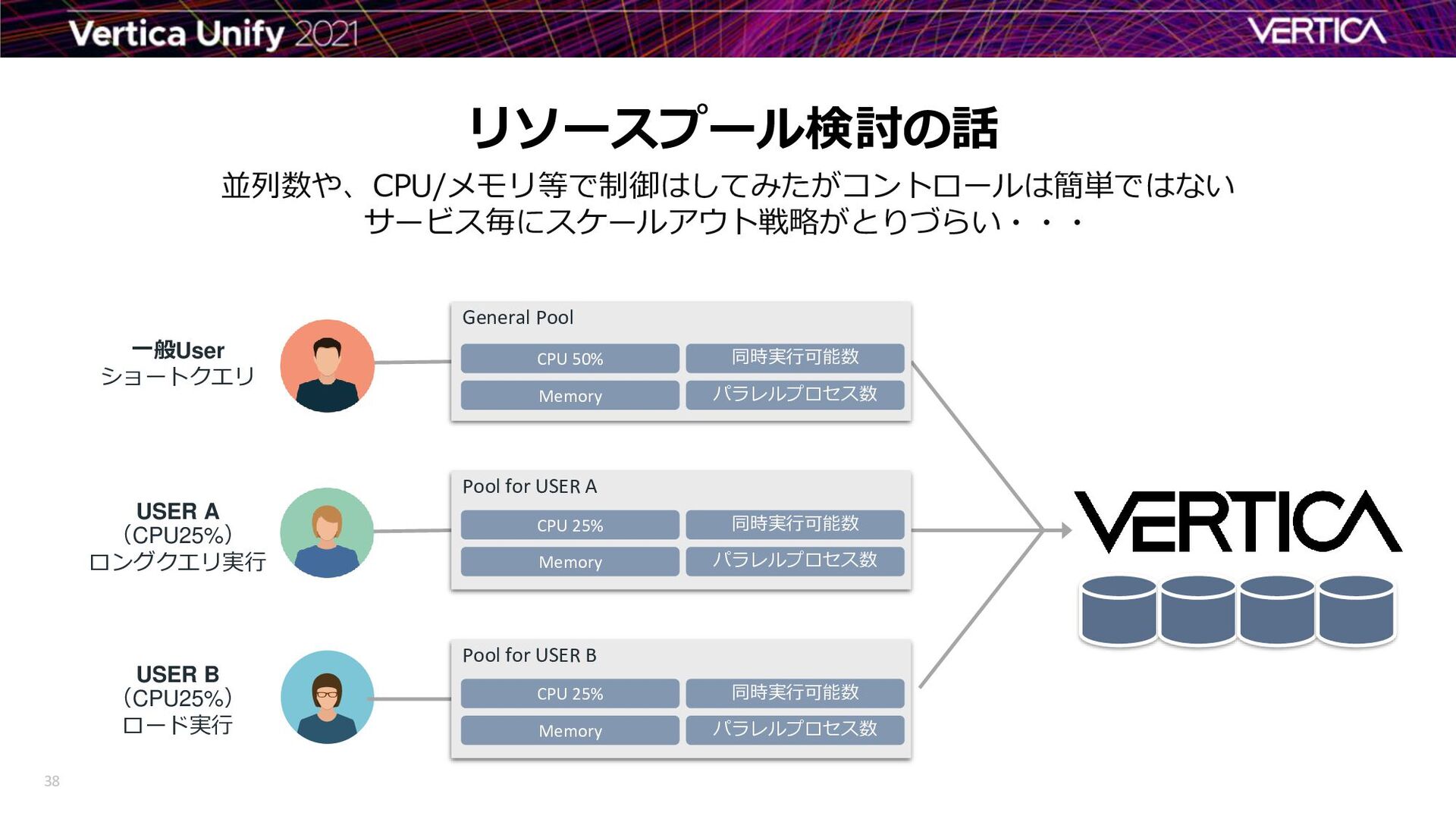
(CPU25%) ロード実行 一般User ショートクエリ General Pool パラレルプロセス数 Memory 同時実行可能数 CPU 50% Pool for USER A パラレルプロセス数 Memory 同時実行可能数 CPU 25% Pool for USER B パラレルプロセス数 Memory 同時実行可能数 CPU 25%
{kind=link}
{kind=link}
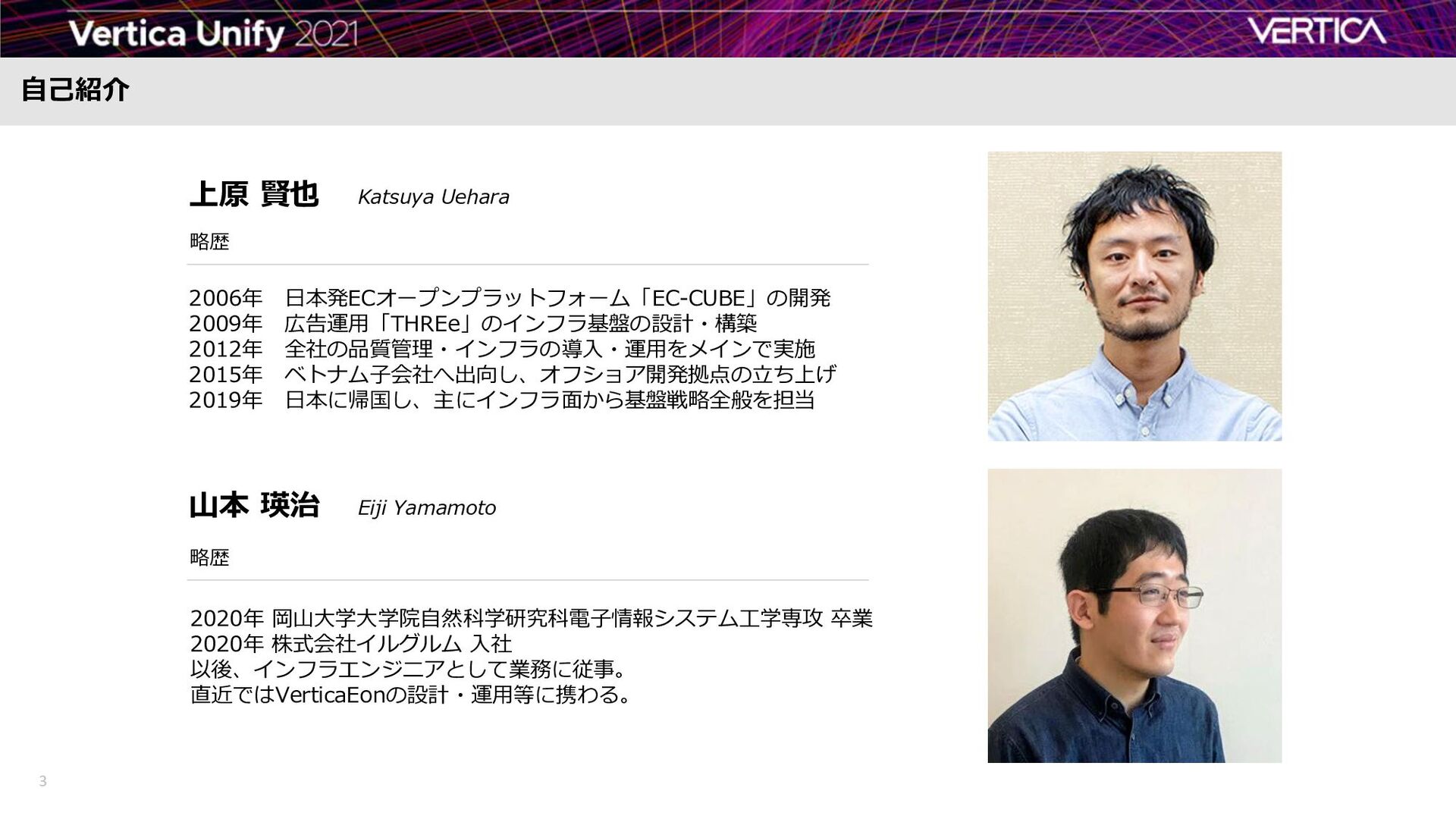{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
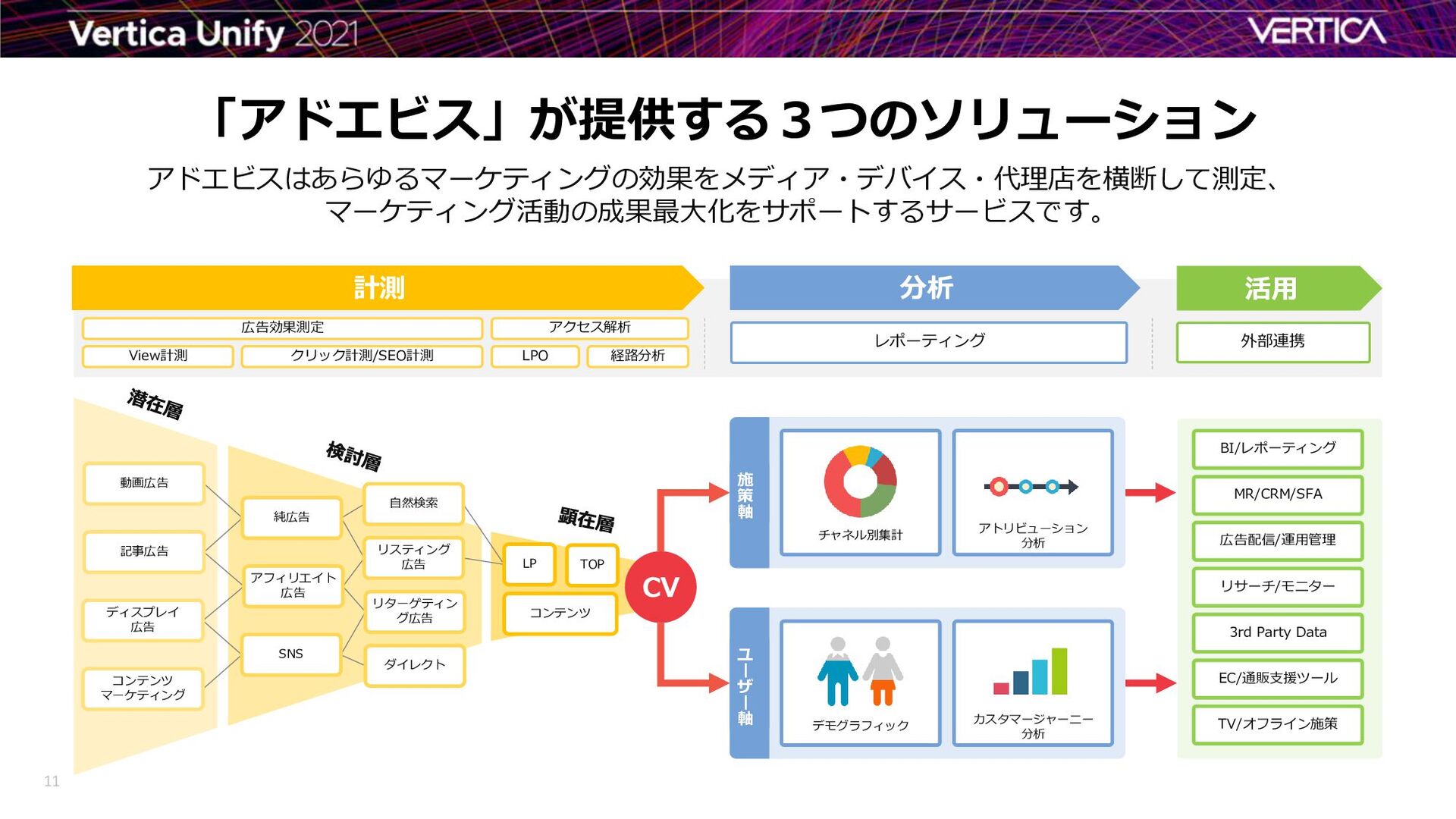{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
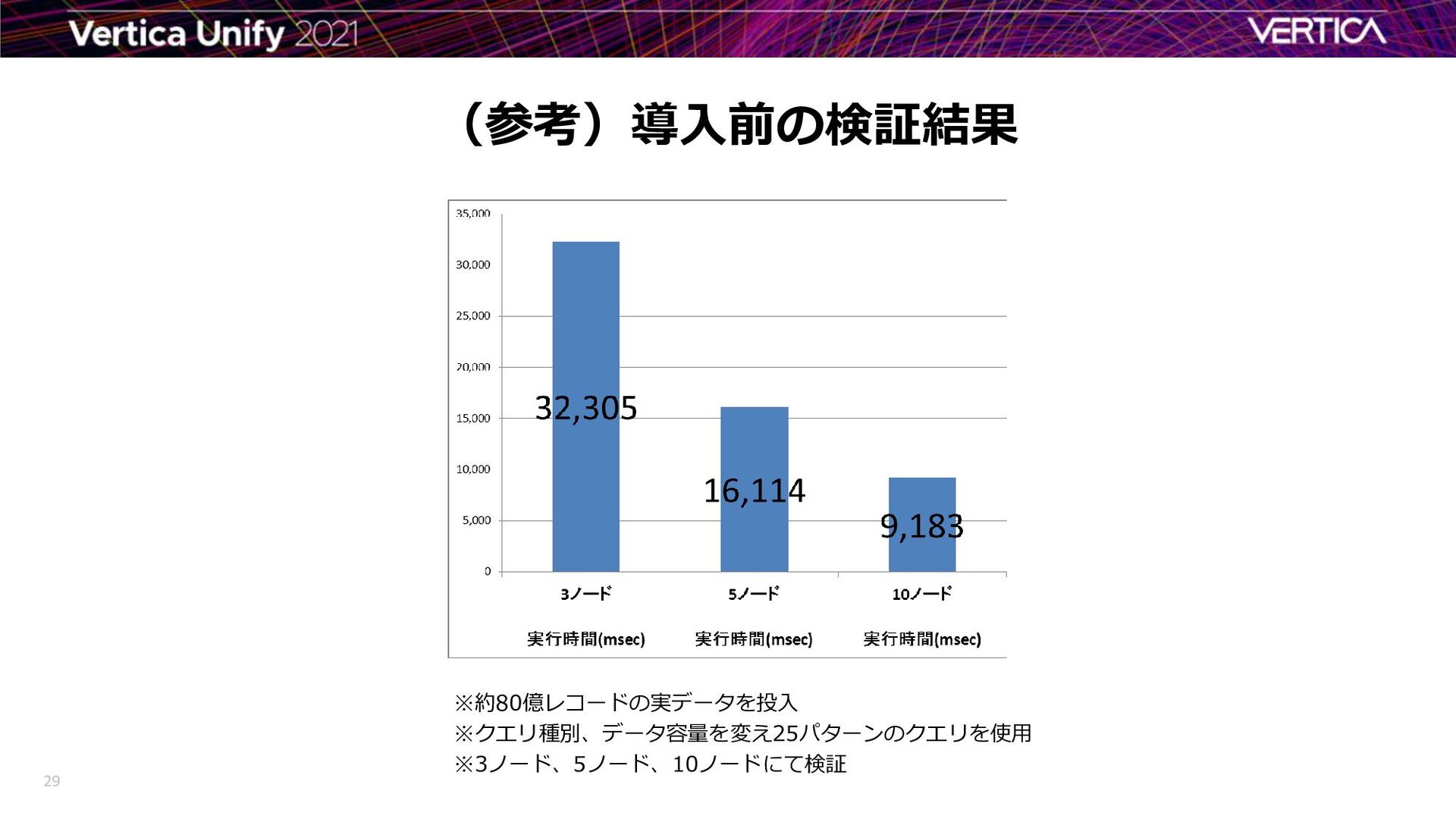{kind=link}
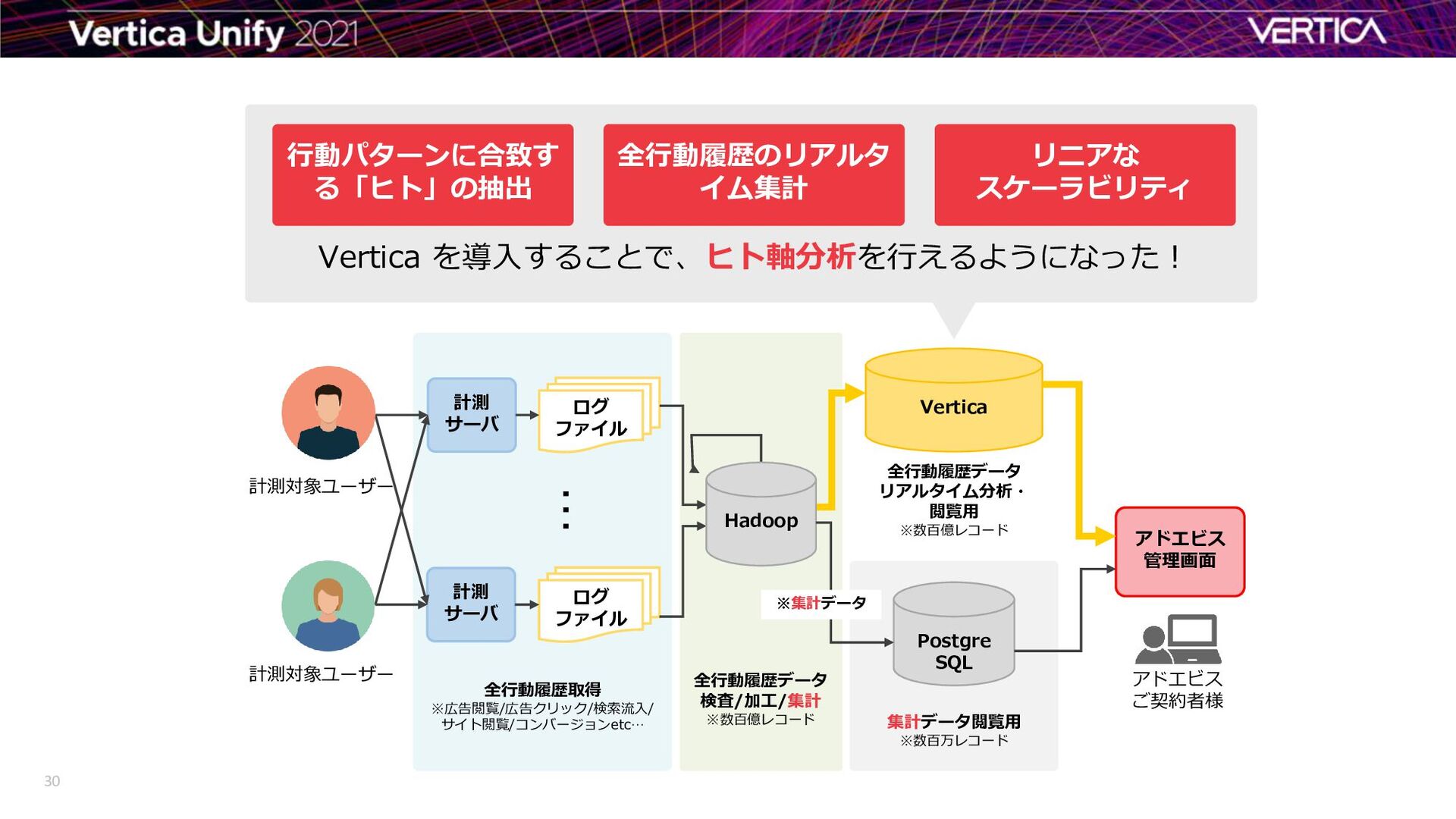{kind=link}
{kind=link}
{kind=link}
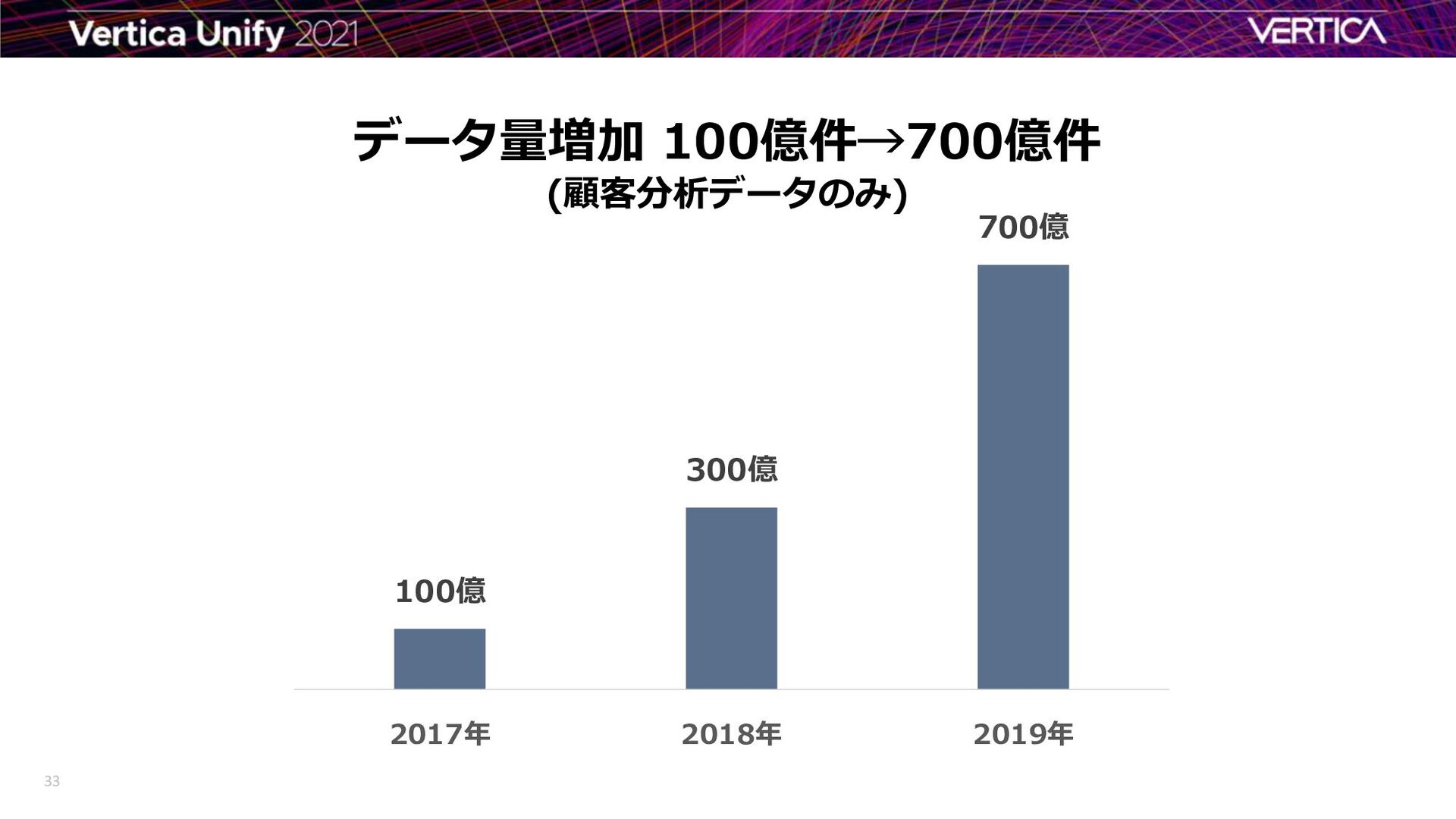{kind=link}
{kind=link}
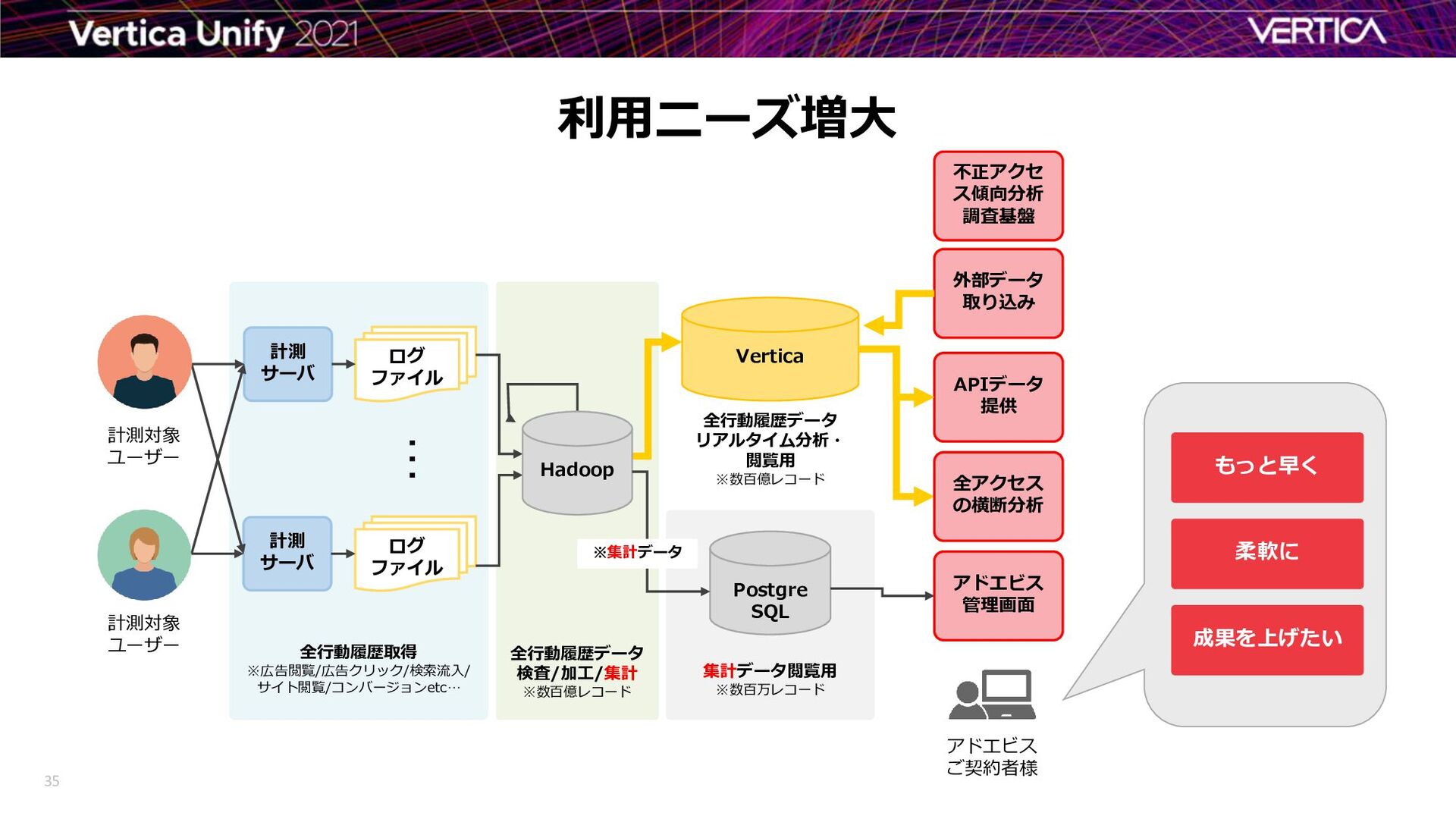{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
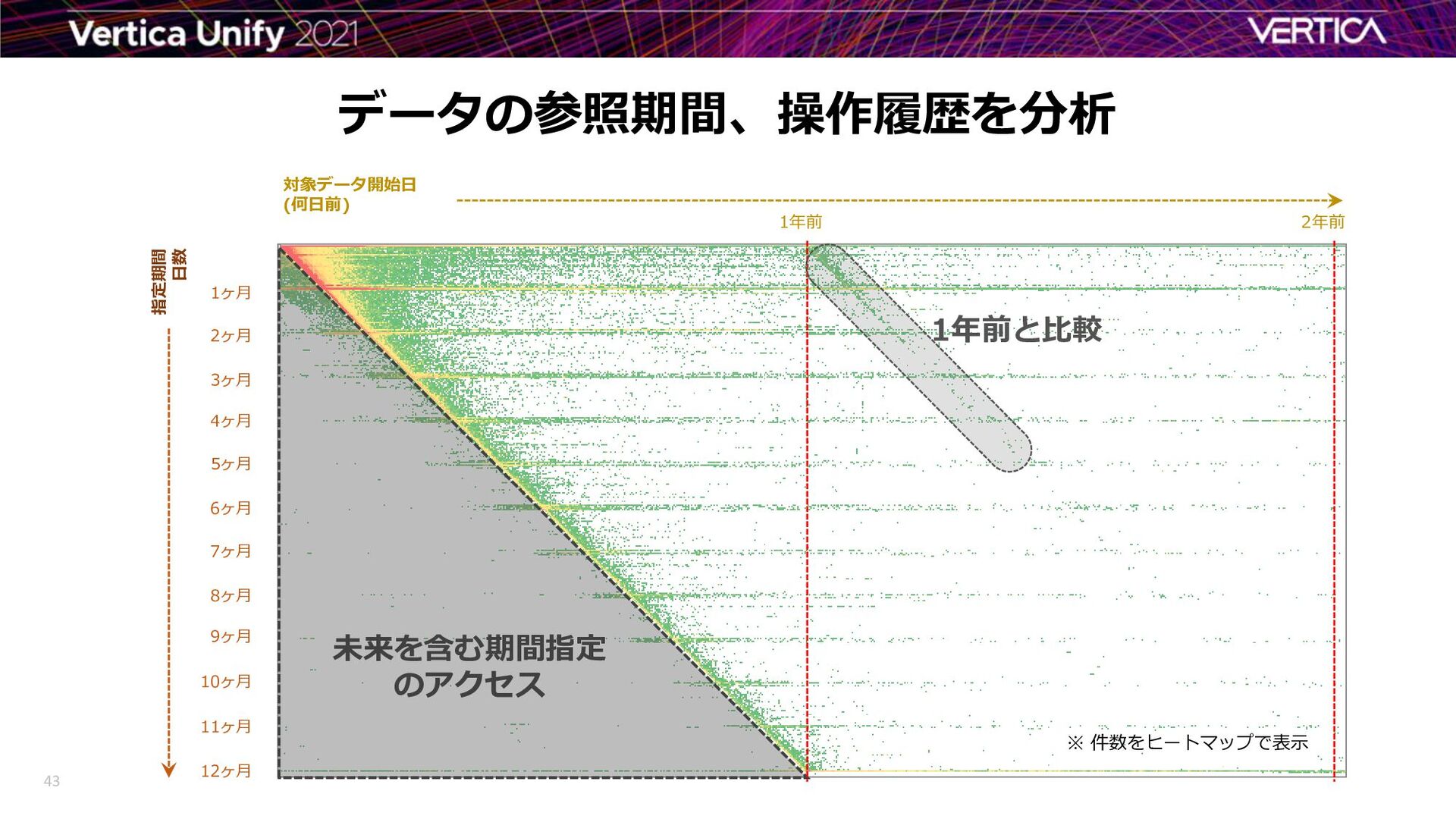{kind=link}
{kind=link}
{kind=link}
{kind=link}
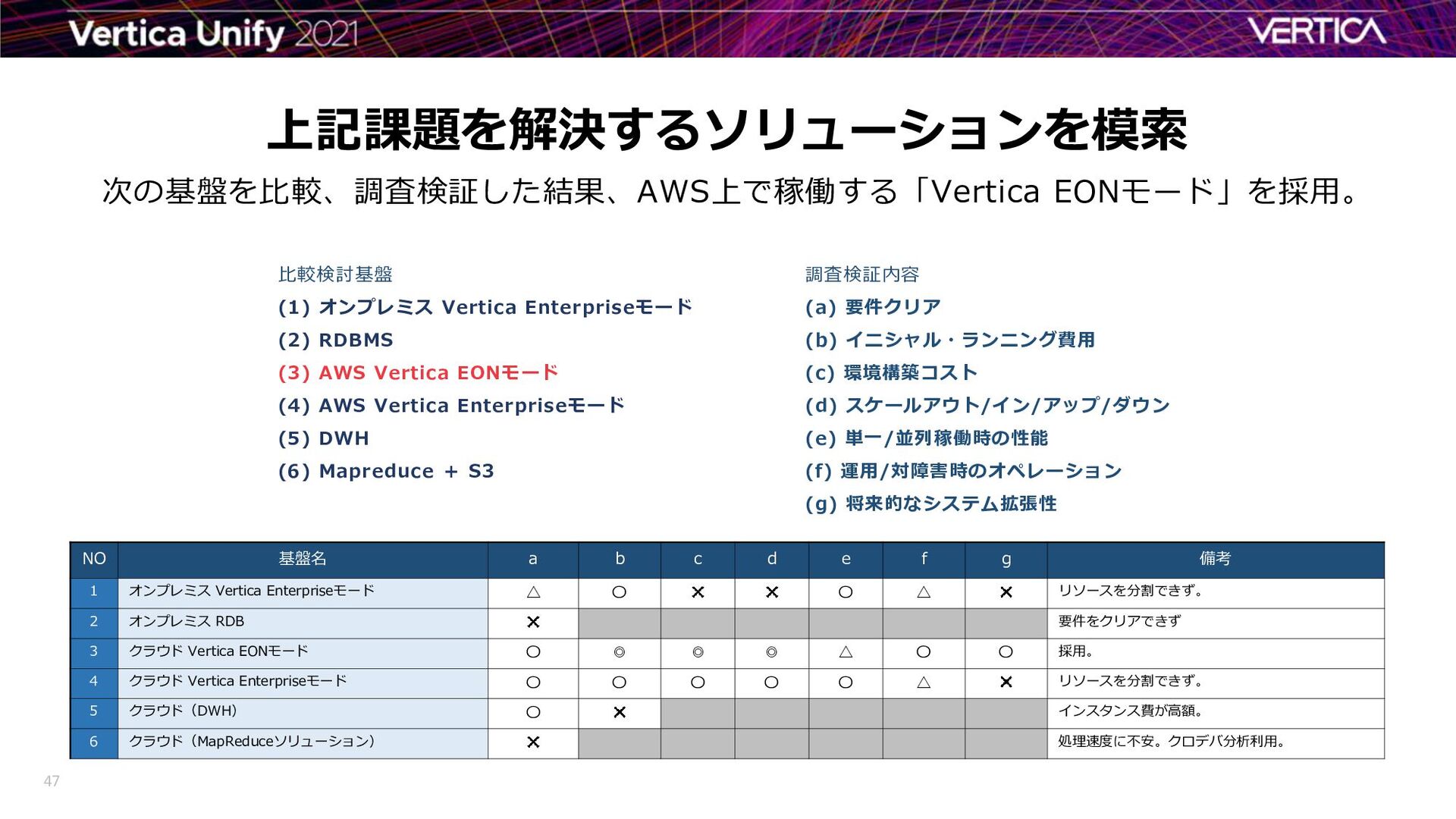{kind=link}
{kind=link}
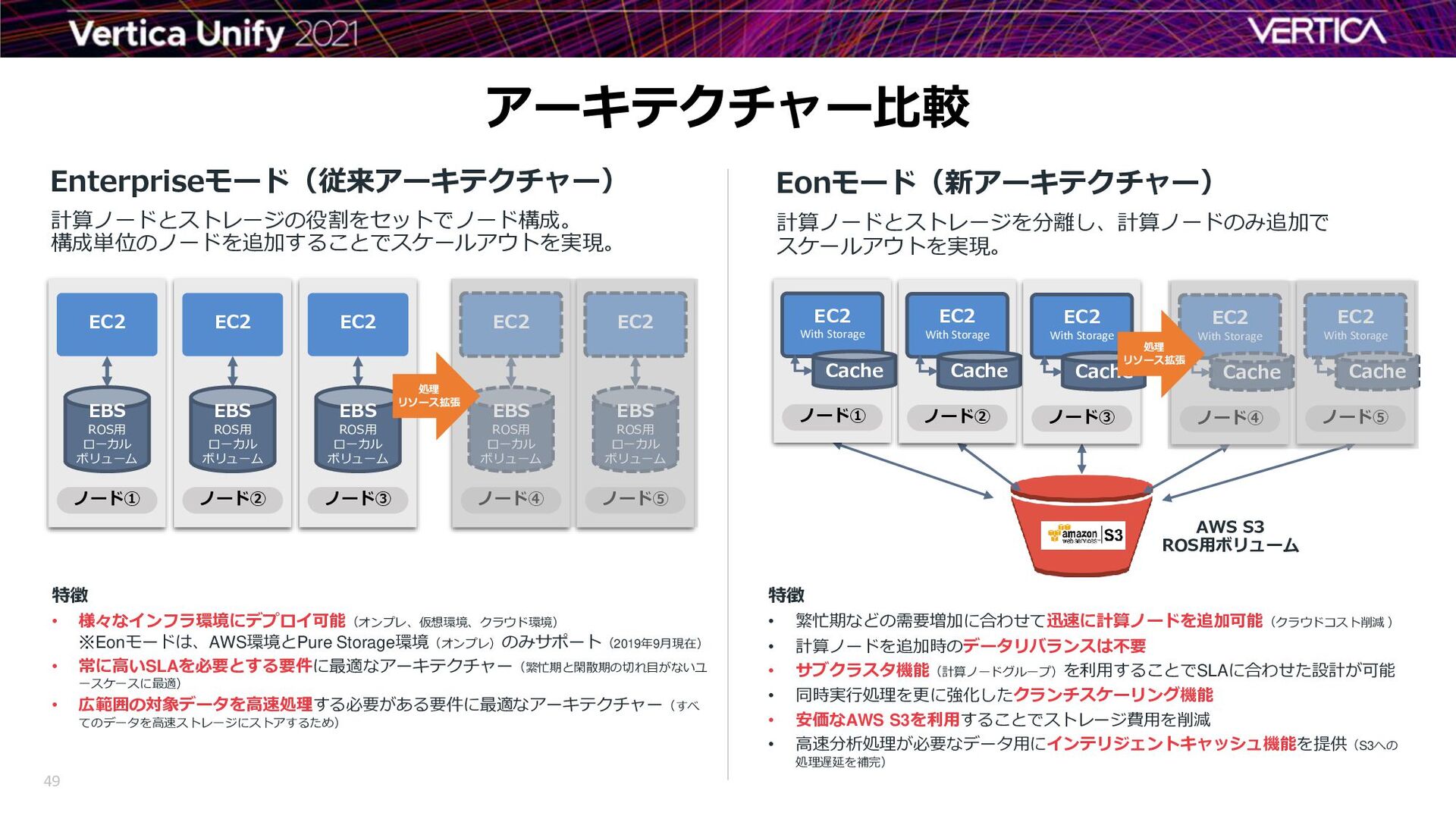{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
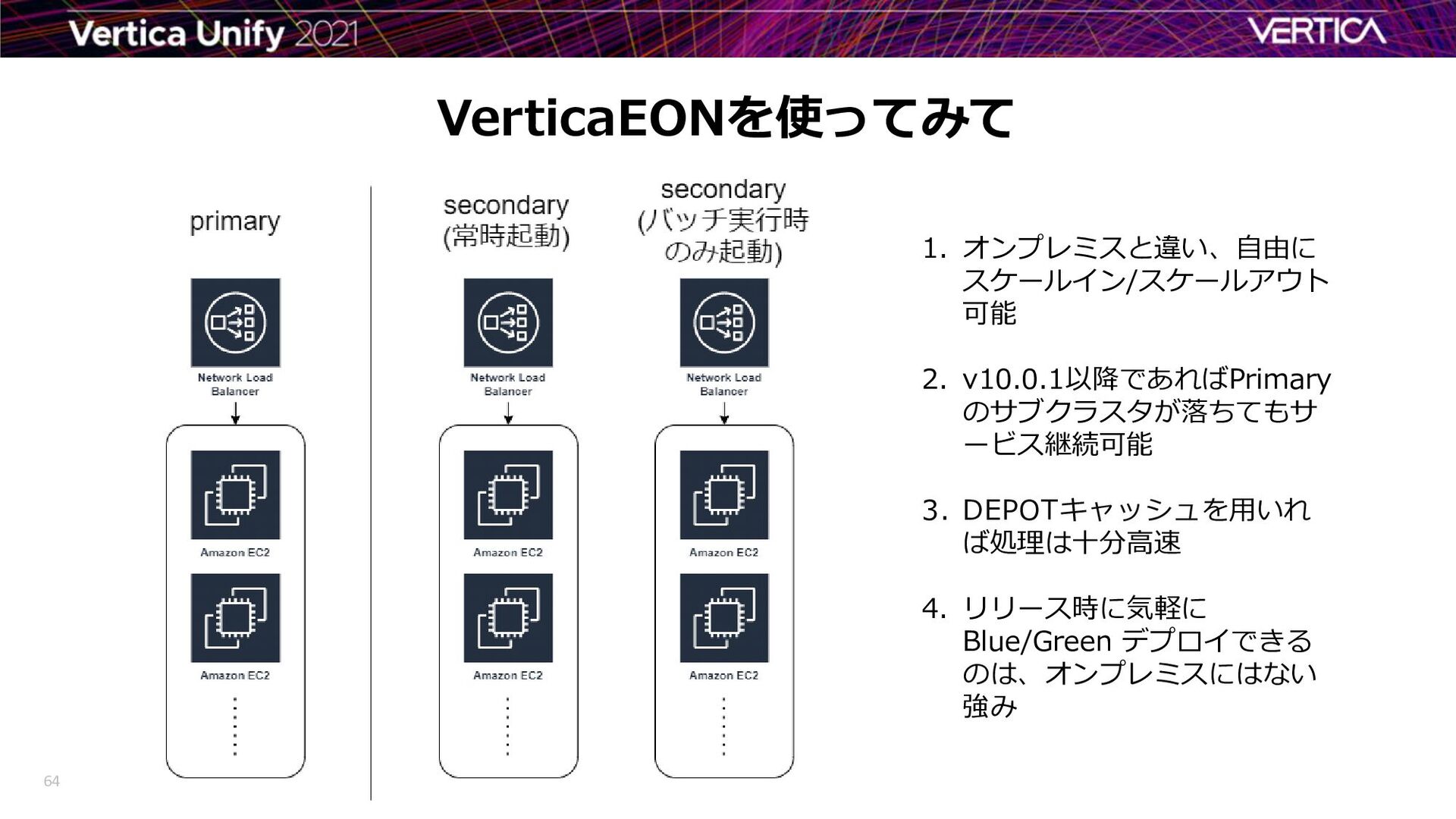{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}