in advance • Still might not be fast to scan +1M / +1B rows CREATE TABLE requests ( KEY uuid PRIMARY KEY, timestamp text, url text, response_status integer, … )
in advance • Still might not be fast to scan +1M / +1B rows • Not possible with Keen - schema is implicitly defined by customers, and not enforced at write-time CREATE TABLE requests ( KEY uuid PRIMARY KEY, timestamp text, url text, response_status integer, … )
in advance • Still might not be fast to scan +1M / +1B rows • Not possible with Keen - schema is implicitly defined by customers, and not enforced at write-time • Keen has 500,000+ user-defined collections today, stored in 1 Cassandra column family CREATE TABLE requests ( KEY uuid PRIMARY KEY, timestamp text, url text, response_status integer, … )
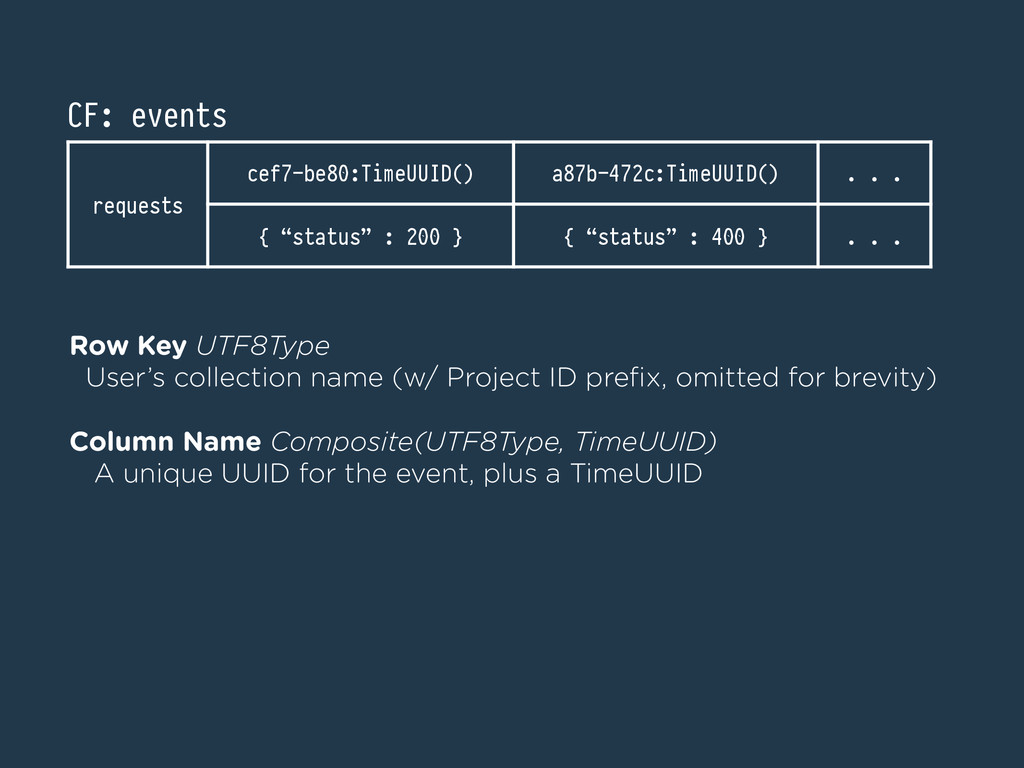
} { “status” : 400 } . . . Row Key UTF8Type User’s collection name (w/ Project ID prefix, omitted for brevity) ! Column Name Composite(UTF8Type, TimeUUID) A unique UUID for the event, plus a TimeUUID CF: events
is unbounded; hot spots for big collections •Can only filter on time by > or <, not both •Little gains from parallelizing b/c row is the same •JSON deserialization in queries is expensive Bad CF: events requests cef7-be80:TimeUUID() a87b-472c:TimeUUID() . . . { “status” : 200 } { “status” : 400 } . . .
logical data model. Define an ideal logical model first. Then find a way to implement it using a physical data store. This was not obvious coming from the relational or document store worlds.
logical data model. Define an ideal logical model first. Then find a way to implement it using a physical data store. This was not obvious coming from the relational or document store worlds. It felt dirty. But it doesn’t have to be.
requests-1 timestamp response.status url [“2014-07-21…”, “2014-07-21…”] [200, 400] [“keen.io”, “keen.io”] Row Key UTF8Type User’s collection name with a ‘bucket’ sequence number ! Column Name UTF8Type The dotted.name of the property ! Column Value BytesType A Kryo-serialized, compressed Object[] containing ~5000 property values CF: events
requests-1 timestamp response.status url [“2014-07-21…”, “2014-07-21…”] [200, 400] [“keen.io”, “keen.io”] Notes Order of properties in the Object[] arrays is *very* important! ! timestamp[5], response.status[5] and url[5] must be properties from the same event CF: events
• Kryo deserialization (fast!) • parallelism via bucketing Tradeoffs • Application code is more complicated. • Writes and reads must understand this structure. The Good
• Kryo deserialization (fast!) • parallelism via bucketing Tradeoffs • Application code is more complicated. • Writes and reads must understand this structure. The Good Worth it!
Design a logical data model first with the characteristics you need (columnar, compressible, partition-able), then figure out how to project it onto physical storage. ! • Don’t be afraid to try crazy stuff that would feel unnatural in the relational or document worlds
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• Turned ‘requests’ into ‘requests-[0…n]’ requests-0 cef7-be80:TimeUUID() a87b-472c:TimeUUID() . .](https://files.speakerdeck.com/presentations/0eb4bd49cecf42308dad2b77d167da12/slide_90.jpg){kind=link}
![• Turned ‘requests’ into ‘requests-[0…n]’ • No more unbounded row](https://files.speakerdeck.com/presentations/0eb4bd49cecf42308dad2b77d167da12/slide_91.jpg){kind=link}
![• Turned ‘requests’ into ‘requests-[0…n]’ • No more unbounded row](https://files.speakerdeck.com/presentations/0eb4bd49cecf42308dad2b77d167da12/slide_92.jpg){kind=link}
![• Turned ‘requests’ into ‘requests-[0…n]’ • No more unbounded row](https://files.speakerdeck.com/presentations/0eb4bd49cecf42308dad2b77d167da12/slide_93.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![requests-0 timestamp response.status url [“2014-07-21…”, “2014-07-21…”] [200, 400] [“keen.io”, “keen.io”]](https://files.speakerdeck.com/presentations/0eb4bd49cecf42308dad2b77d167da12/slide_111.jpg){kind=link}
![requests-0 timestamp response.status url [“2014-07-21…”, “2014-07-21…”] [200, 400] [“keen.io”, “keen.io”]](https://files.speakerdeck.com/presentations/0eb4bd49cecf42308dad2b77d167da12/slide_112.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}