Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
“Cost-efficient and scalable ML-experiments in ...
Search
Keigo Hattori
May 28, 2020
Technology
2
2.7k
“Cost-efficient and scalable ML-experiments in AWS with spot-instances, Kubernetes and Horovod” の紹介と感想
MLCT #12
https://mlct.connpass.com/event/172550/
Keigo Hattori
May 28, 2020
Tweet
Share
More Decks by Keigo Hattori
See All by Keigo Hattori
Rekcurd update and demo
keigohtr
0
600
What we need for MLOps
keigohtr
0
3.3k
Introduction of Machine Learning Production Pitch#1
keigohtr
0
3.5k
自動でツイッター要約をする執事ボット作った (API Meetup #28)
keigohtr
0
19k
API Meetup Tokyo #24 スマートスピーカーとAPI連携 LINE Clova
keigohtr
0
8k
API Meetup #22 LT大会(Apitore)
keigohtr
0
1.3k
AI x WebAPI もくもく会 Vol.1 イントロダクション
keigohtr
0
330
OneJapan企画提案ピッチ-大企業ハッカソン-
keigohtr
0
1.1k
API Meetup #17でのLT
keigohtr
0
620
Other Decks in Technology
See All in Technology
OpenShiftでllm-dを動かそう!
jpishikawa
0
140
Claude_CodeでSEOを最適化する_AI_Ops_Community_Vol.2__マーケティングx_AIはここまで進化した.pdf
riku_423
2
610
マネージャー視点で考えるプロダクトエンジニアの評価 / Evaluating Product Engineers from a Manager's Perspective
hiro_torii
0
190
M&A 後の統合をどう進めるか ─ ナレッジワーク × Poetics が実践した組織とシステムの融合
kworkdev
PRO
1
520
SREが向き合う大規模リアーキテクチャ 〜信頼性とアジリティの両立〜
zepprix
0
480
インフラエンジニア必見!Kubernetesを用いたクラウドネイティブ設計ポイント大全
daitak
1
390
Amazon Bedrock Knowledge Basesチャンキング解説!
aoinoguchi
0
170
会社紹介資料 / Sansan Company Profile
sansan33
PRO
15
400k
StrandsとNeptuneを使ってナレッジグラフを構築する
yakumo
1
130
AWS Network Firewall Proxyを触ってみた
nagisa53
1
250
22nd ACRi Webinar - ChipTip Technology Eric-san's slide
nao_sumikawa
0
100
猫でもわかるKiro CLI(セキュリティ編)
kentapapa
0
130
Featured
See All Featured
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
1
110
Reality Check: Gamification 10 Years Later
codingconduct
0
2k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
310
Product Roadmaps are Hard
iamctodd
PRO
55
12k
WENDY [Excerpt]
tessaabrams
9
36k
Mind Mapping
helmedeiros
PRO
0
90
First, design no harm
axbom
PRO
2
1.1k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
120
Principles of Awesome APIs and How to Build Them.
keavy
128
17k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Optimizing for Happiness
mojombo
379
71k
Transcript
“Cost-efficient and scalable ML-experiments in AWS with spot-instances, Kubernetes and
Horovod” の紹介と感想 MLOps enthusiast, @keigohtr #MLCT
Today’s topic “Cost-efficient and scalable ML-experiments in AWS with spot-instances,
Kubernetes and Horovod” について、ABEJA Platformの経験を踏まえて、ど こが良いと思ったかを紹介します 2
Who am I Keigo Hattori Software Engineer 3 2009.3 Tohoku
Univ / M.S. (Information Science) 2009.4~2017.10 Fuji Xerox / ML Engineer (NLP), etc 2017.11~2019.5LINE / Senior Software Engineer / Clova 2019.6~2020.5 ABEJA / Software Engineer / Platform 2020.5~ ??? MLOps 大好きです! @keigohtr
機械学習に関わる仕事とは? 4 学習 / Training 運用 / Operation
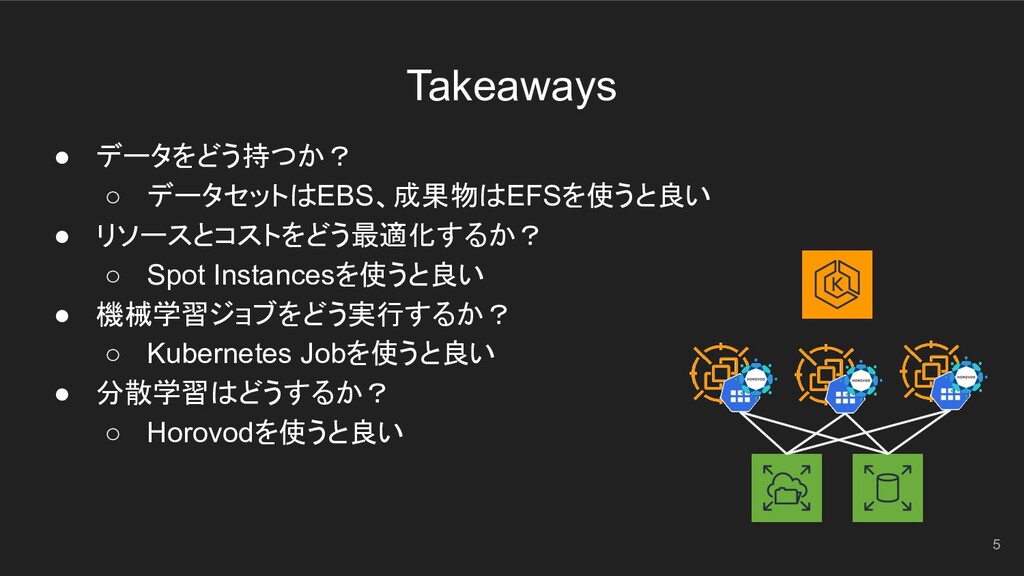
• データをどう持つか? ◦ データセットはEBS、成果物はEFSを使うと良い • リソースとコストをどう最適化するか? ◦ Spot Instancesを使うと良い •
機械学習ジョブをどう実行するか? ◦ Kubernetes Jobを使うと良い • 分散学習はどうするか? ◦ Horovodを使うと良い Takeaways 5
データをどう持つか? 6
AWSのストレージと特徴 7 S3 • 安い • 容量無限 • 堅牢性と可用性 が高い
• ファイル単位でア クセス EFS • 高い • 容量無限 • Multi-AZ • 複数インスタンス からマウント可能 EBS • 安い (S3よりは高い) • 容量は事前申告 • 単一 AZ • 単一インスタンス からマウント可能
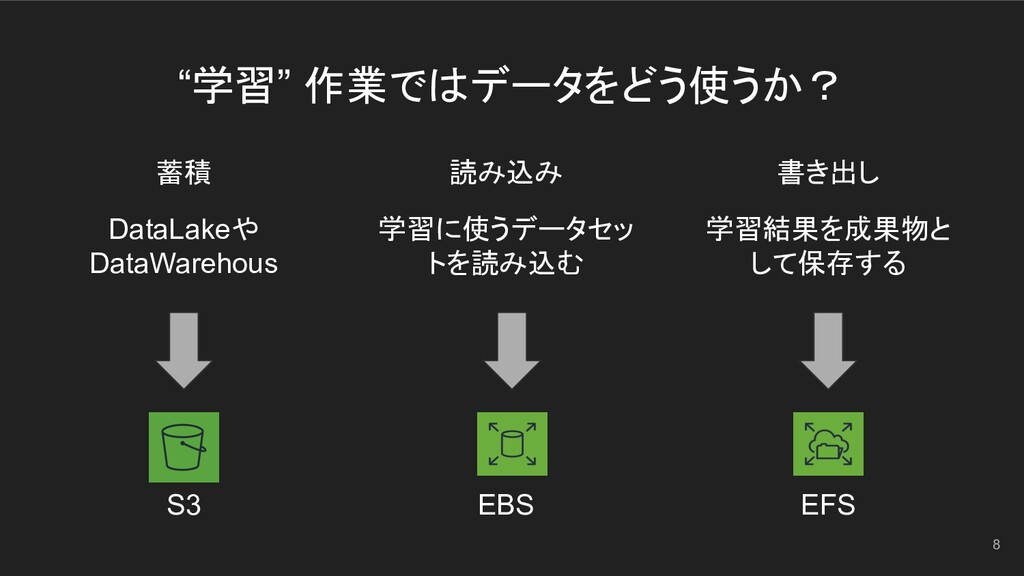
“学習” 作業ではデータをどう使うか? 8 蓄積 DataLakeや DataWarehous S3 書き出し 学習結果を成果物と して保存する
EFS 読み込み 学習に使うデータセッ トを読み込む EBS
“読み込み” にEBSを使う理由 9 学習における総実行時間が短縮できる • 機械学習(特に深層学習)では大量のデータを扱う = ファイル読み込みが多数発生する 他に選択肢がない •
goofys等でS3をマウントするのは安定しないので論外 • EFSと比べて早い O ur Experience
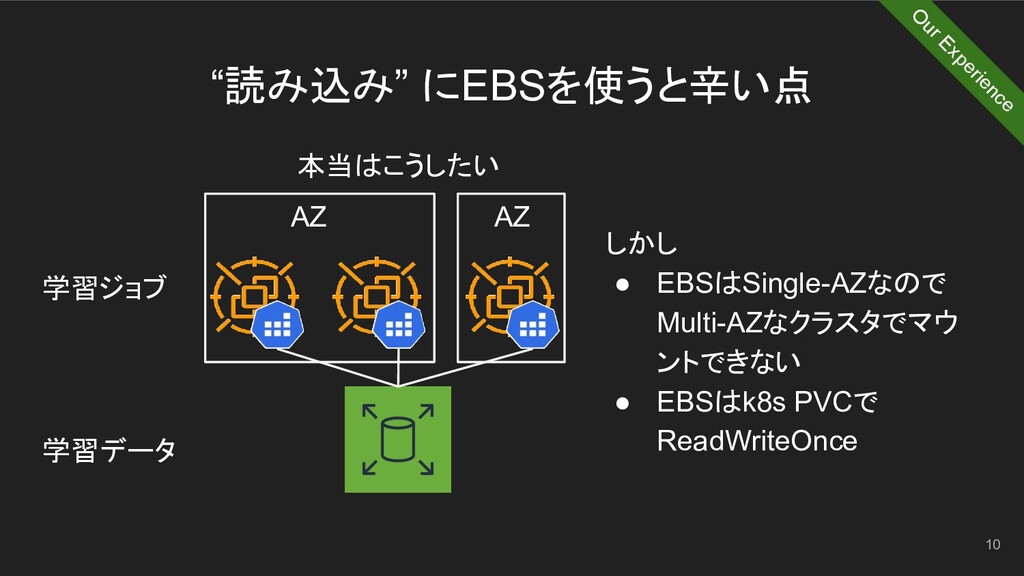
“読み込み” にEBSを使うと辛い点 10 本当はこうしたい AZ AZ 学習ジョブ 学習データ O ur
Experience しかし • EBSはSingle-AZなので Multi-AZなクラスタでマウ ントできない • EBSはk8s PVCで ReadWriteOnce
文献 (Rosebud AI) ではどうしたか? 11 • ジョブ毎にEBSを作成し、データセットをS3からコピーする • ジョブにマウントしたEBSはReadOnlyとして扱う •
ジョブが完了したらEBSは廃棄するか、次のジョブで再利用する ◦ EBSを再利用するとデータセットのコピーが省略できる = 次のジョブをすぐに走らせられる
ABEJA Platformではどうしているか? 12 • EBSを使わず、EFSを使っている ◦ EFSはMulti-AZかつMulti-attach ◦ ジョブがデータセットをS3からEFSにダウンロード ◦
EFSのダウンロード先はデータセット毎に固定し、並列するジョブが協 力してデータセットをダウンロード ※ 学習時にデータセット読み込みが非常に遅いので、見直し中 O ur Experience
“書き込み” にEFSを使う理由 13 成果物のサイズが予想できない • モデルのサイズはパラメータ次第 • 何を成果物に含めるかはユーザー次第 (e.g. ログファイル、ログの内容、中間モデル)
Disk fullでジョブが死ぬことを避けたい • 成果物のサイズが見積もれない(上記) • インスタンスで複数のジョブが同時に走ることもある = 他のユーザーのジョブでDisk fullになりうる O ur Experience
“書き込み” にEFSを使うと辛い点 14 • 気をつけないとクラウド破産する ◦ ユーザーはランニングコストを気にしない (容量は使えるだけ使う) ◦ 例えば、自然言語処理の場合、成果物が数十GBになることも。
試行錯誤やバージョニングで積み重なると・・・ O ur Experience
文献 (Rosebud AI) ではどうしたか? 15 • 成果物はEFSに置く • チェックポイントを設けて中間出力をEFSに置く •
ファイルはEFSの決められた場所に置く • 実験が中断したときに、中断したところから再開する • TensorBoardで各ジョブの結果を俯瞰できる
ABEJA Platformではどうしているか? 16 (文献に加え) • EFSを定期的に掃除して、ランニングコストを下げる • EFS掃除で成果物をロストしないように、ジョブ完了後に成果物を圧縮して S3にアップロードする •
(TensorBoardだけじゃなく、Jupyterも起動できる) O ur Experience
リソースとコストをどう最適化するか? 機械学習ジョブをどう実行するか? 17
やりたいこと • 可能な限りコストを抑え、しかし安定した計算クラスタを作る • スケーリングを自動化する ◦ 必要に応じてインスタンスが追加され、必要なければインスタンスが削 除されてほしい(スケールアウト、スケールイン) ◦ ↑をGPUサーバーでもやりたい
• 可能な限り効率的に機械学習ジョブを実行する ◦ 計算クラスタに詰め込めるだけ詰め込みたい = ジョブのキューイングとスケジューリング 18
文献 (Rosebud AI) ではどうしたか?(1/2) 19 • Spot Instancesを使った ◦ Spot
Instancesで安価な計算資源を確保 ◦ EKSで計算クラスタを構築 • Kubernetes Jobを使った ◦ ジョブのキューイングとスケジューリングはk8s
文献 (Rosebud AI) ではどうしたか?(2/2) 20 • Kubernetes Jobの突然死に対応した ◦ Spot
Instancesのインスタンスは取り上げられることがある = KubernetesのJobが突然死する ◦ そこで、少なくとも10分に1度、チェックポイントとして学習の途中経過 をEFSに保存した ◦ Jobが失敗/突然死した場合、KubernetesはJobを再実行する ◦ JobはEFSを参照し、チェックポイントから学習を再開する
ABEJA Platformではどうしているか?(1/3) 21 • Spot Instancesを管理するSpotInstを利用した ◦ Ref: スポットインスタンスを効率的に管理するSpotinstを使おう O
ur Experience
ABEJA Platformではどうしているか?(2/3) 22 • インスタンスに使うイメージを固定した ◦ ユーザーがどのCUDAを使うか分からないので、All-in-Oneな機械学 習用のAMIを使う • インスタンスの種類を固定した
◦ CPU/メモリをユーザーに選ばせると、インスタンスの利用効率(e.g. Podがうまくハマらない)が悪くなる = ランニングコストが悪くなる ◦ “インスタンスのスペック” ≒ ”Podのスペック” にした O ur Experience
ABEJA Platformではどうしているか?(3/3) 23 • ユーザーのコードはEFS上で動かした ◦ ユーザーのコードサイズが見積もれない = Disk fullで死ぬ可能性がある
◦ そこで、PodにEFSをマウントする ◦ EFS上にユーザーのコードをダウンロードし、実行する O ur Experience
分散学習はどうするか? 24
やりたいこと • 複数のGPUを使った分散学習をやりたい • ただし既存のコードはなるべく変更したくない 25
文献 (Rosebud AI) ではどうしたか?(1/2) 26 • Horovodを採用した ◦ 複雑性を回避するため、複数のインスタンスは使わない ◦
Multi-GPUを搭載したインスタンスで分散学習をする ◦ Horovodが提供するDocker Imageとサンプルコードが大変便利
文献 (Rosebud AI) ではどうしたか?(2/2) 27 (Spot InstancesによるJobの突然死への対応として) • master-workerに以下を担当させた ◦
masterが他のworkerの変数を初期化する ◦ チェックポイントの書き出しをする ◦ チェックポイントからの復元をする • 乱数を固定する ◦ シャッフリングやdata splitを再現させるため
ABEJA Platformではどうしているか? 28 • To Be Continued ◦ 現在、分散学習を公式にはサポートしていない (ただし、自分でやれば使える)
O ur Experience
• データをどう持つか? ◦ データセットはEBS、成果物はEFSを使うと良い • リソースとコストをどう最適化するか? ◦ Spot Instancesを使うと良い •
機械学習ジョブをどう実行するか? ◦ Kubernetes Jobを使うと良い • 分散学習はどうするか? ◦ Horovodを使うと良い Retrospective 29
Thank you! 30
• Cost-efficient and scalable ML-experiments in AWS with spot-instances, Kubernetes
and Horovod • スポットインスタンスを効率的に管理するSpotinstを使おう • 顧客のアプリケーションコードが動くマルチテナント環境における課題と EKSにたどり着くまで Reference 31
32 Q & A
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}