Sucheng Ren1 Qihang Yu2 Ju He2 Xiaohui Shen2 Alan Yuille1 Liang-Chieh Chen2 1Johns Hopkins University 2ByteDance ICML2025 Ren, Sucheng, et al. “FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching.” Proceedings of the Forty-second International Conference on Machine Learning, 2025
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
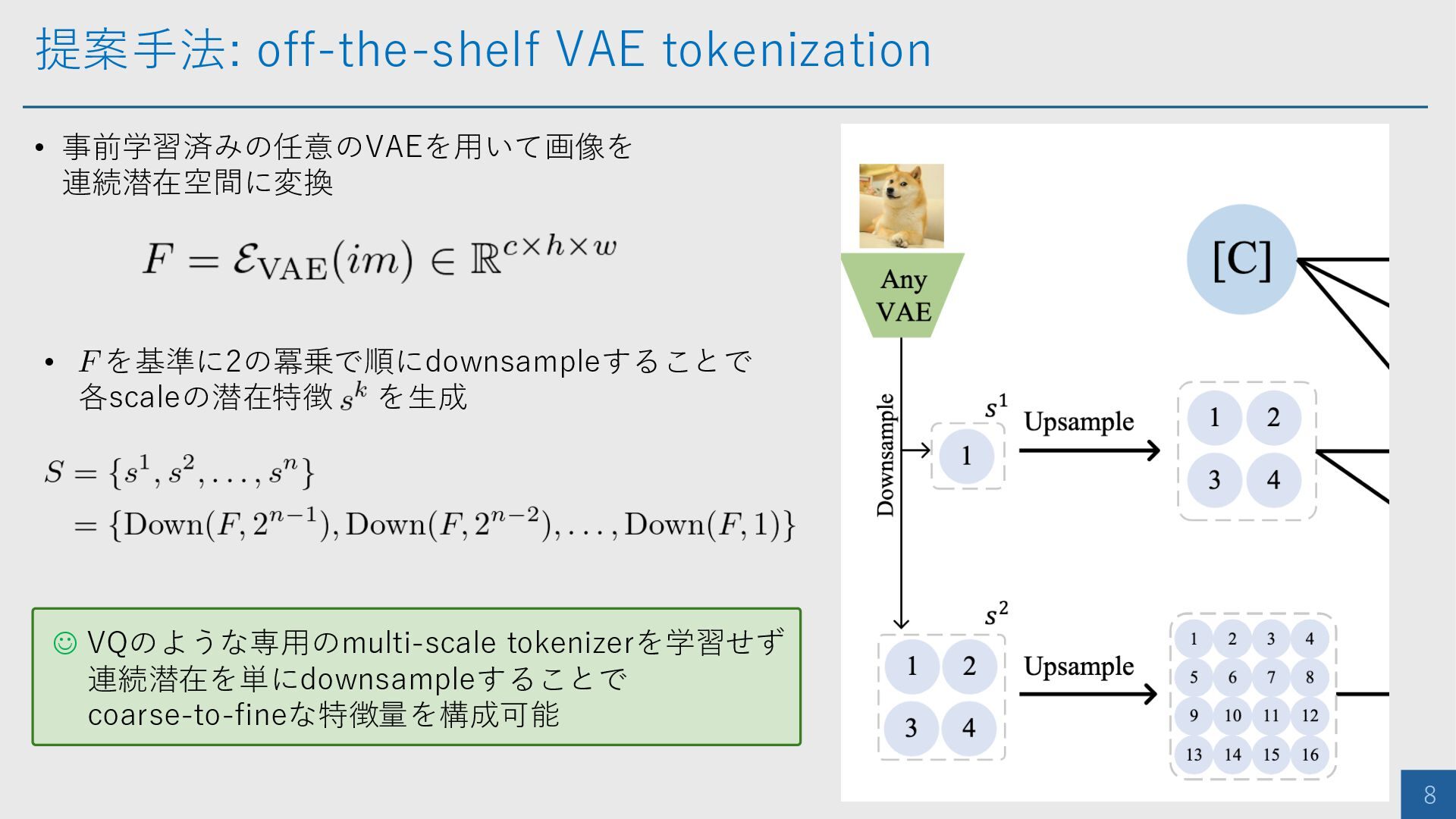
![提案手法: Scale-wise AR generation 9 • Scale においてcondition token [C]](https://files.speakerdeck.com/presentations/99dd4336df2d4409bda4070c82c2b48a/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}