(1:Seoul National University 2:Coxwave) 1 EXPERT: An Explainable Image Captioning Evaluation Metric with Structured Explanations 慶應義塾⼤学 杉浦孔明研究室 ⼩⼭修⽣ Hyunjong Kim et al., “EXPERT: An Explainable Image Captioning Evaluation Metric with Structured Explanations,” in Findings of ACL, 2025. ACL25 Findings
n Score binning n ⼈⼿評価は複数のアノテータによる評価値を平均化→⼩数点以下が⻑い値の傾向 L MLLMは評価値の各桁を個別のトークンとして扱うため,些細な数値の違い(e.g., 0.59375 vs 0.60)は不必要に複雑で,学習しづらい可能性 J 事前にscore binningを⾏い安定して性能向上 スコアの理由のデータ スコアのデータ
n エポック数︓1 n バッチサイズ︓8 n ベンチマーク n Flickr8k-Expert & Flickr8k-CF [Hodosh+, IJCAI13], Composite [Hodosh+, IJCAI15], Polaris [Wada+, CVPR24], Nebula [Matsuda+, ACCV24], Pascal-50S [Vedantam+, CVPR15] n 実験環境 n NVIDIA A100 GPU n SFTに2h LLaVA-1.5
{kind=link}
{kind=link}
![背景︓既存のMLLM-as-a-Judgeは説明の品質に課題 3 L 画像キャプション⽣成における既存の⾃動評価尺度 (e.g., PAC-Score [Sarto+, CVPR23] )の多くは 評価値に対する説明を⽋く](https://files.speakerdeck.com/presentations/a7b75eae606746bba11add5b3e50d3ee/slide_2.jpg){kind=link}
![関連研究 4 PAC-Score ⼿法 概要 PAC-Score [Sarto+, CVPR23] PAC-Score++ [Sarto+,](https://files.speakerdeck.com/presentations/a7b75eae606746bba11add5b3e50d3ee/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
![提案: スコアに対する説明を含むデータセット 7 L 既存の画像キャプション⽣成の評価尺度⽤のデータセットは評価値に対する説明を含まない →Polaris [Wada+, CVPR24], Nebula [Matsuda+,](https://files.speakerdeck.com/presentations/a7b75eae606746bba11add5b3e50d3ee/slide_6.jpg){kind=link}
![提案: Polaris-exp, Nebula-expを⽤いてMLLMをSFT 8 n Polaris-exp, Nebula-expの評価値および理由を⽤いてLoRA [Edward+, ICLR22] でFine-Tuning](https://files.speakerdeck.com/presentations/a7b75eae606746bba11add5b3e50d3ee/slide_7.jpg){kind=link}
![実験設定 9 n MLLM n LLaVA-1.5 [Liu+, NeurIPS23] n 学習設定](https://files.speakerdeck.com/presentations/a7b75eae606746bba11add5b3e50d3ee/slide_8.jpg){kind=link}
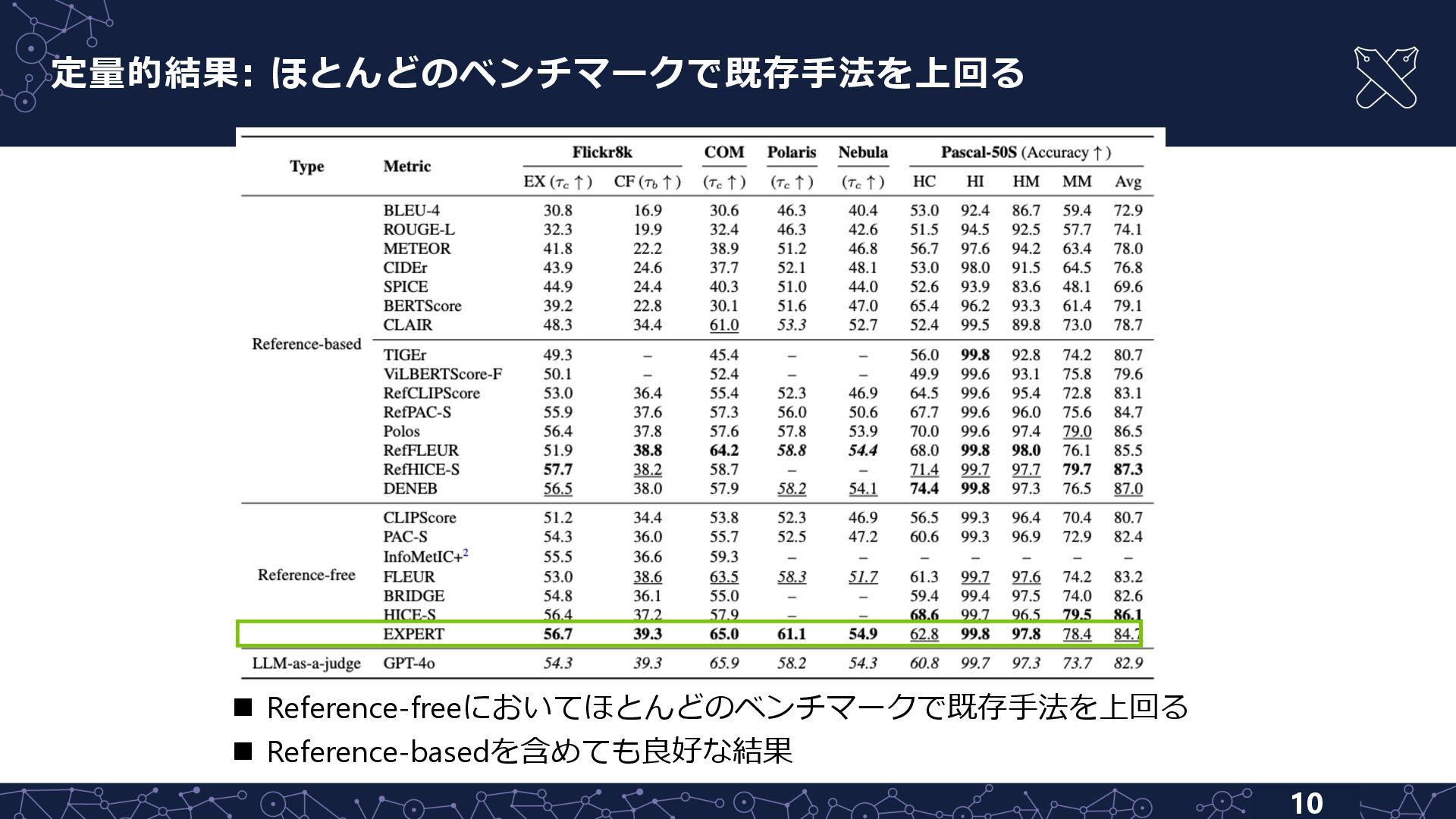{kind=link}
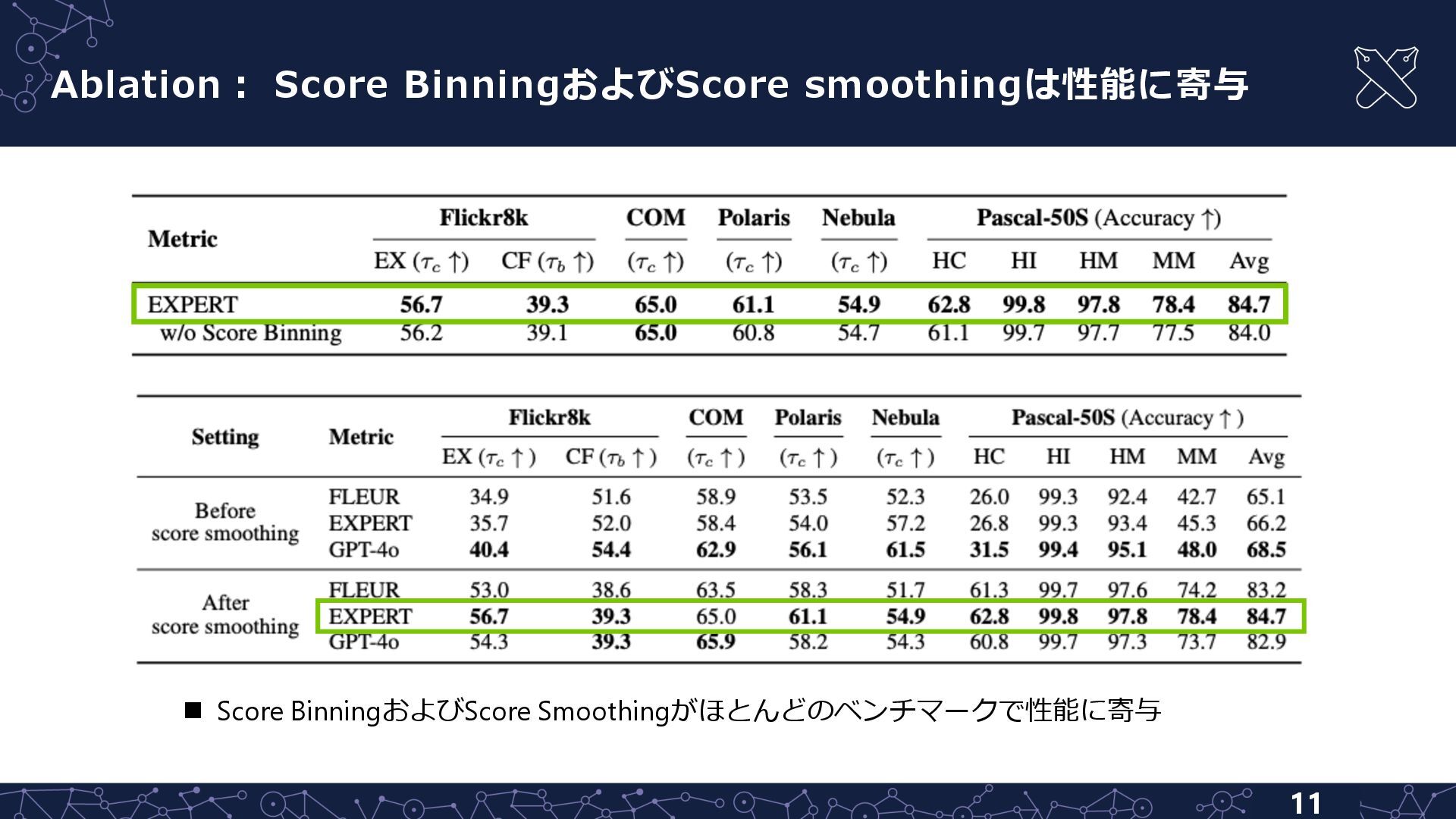{kind=link}
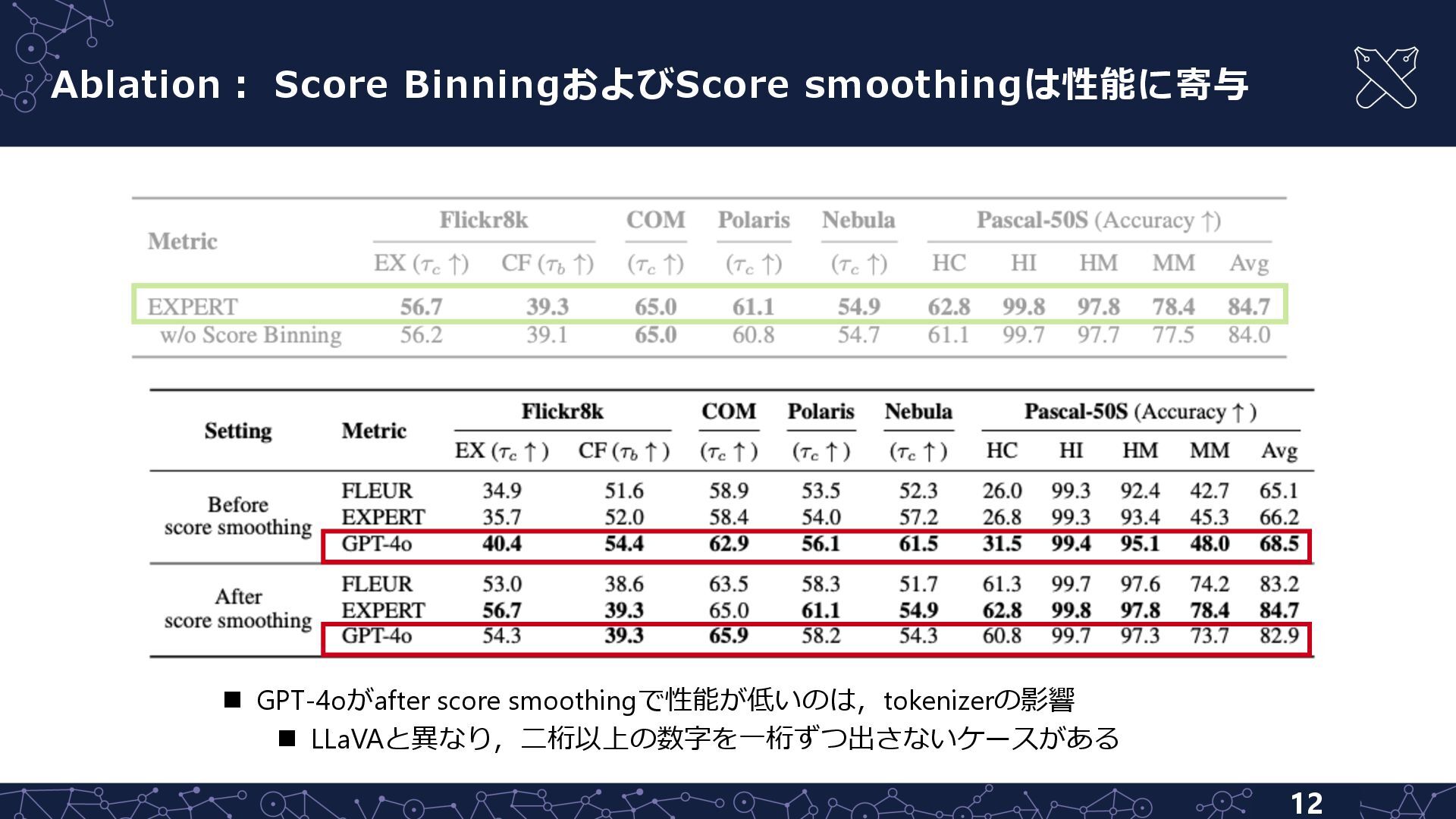{kind=link}
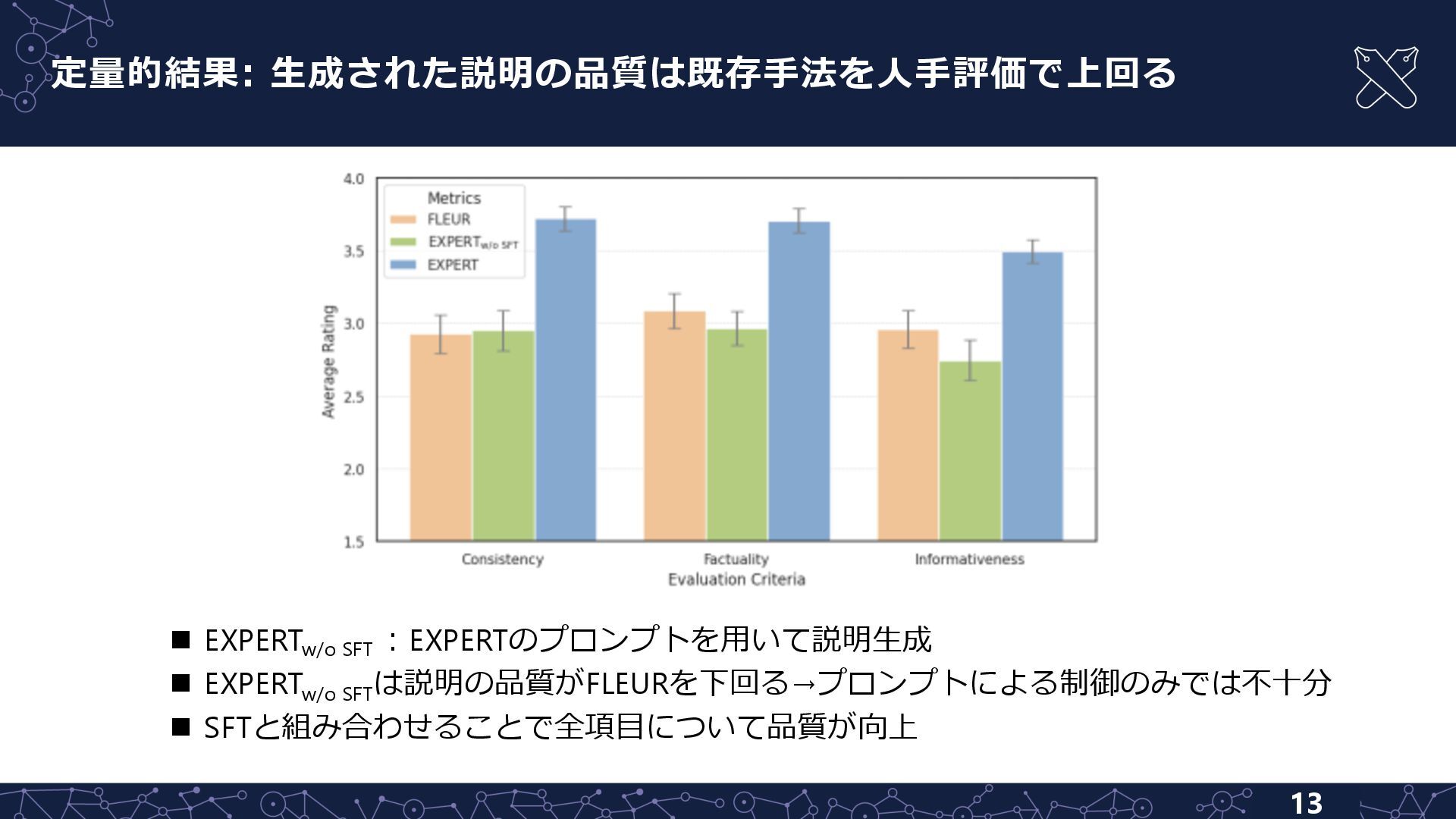{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}