Matt Le1 1Meta AI (FAIR) 2Weizmann Institute of Science Flow Matching for Generative Modeling 2025 杉浦孔明研究室 妹尾 幸樹 LIPMAN, Yaron, et al. Flow Matching for Generative Modeling. In: 11th International Conference on Learning Representations, ICLR 2023. 2023. ICLR23
{kind=link}
{kind=link}
{kind=link}
![関連研究 4 ⼿法 特徴 Neural ODE [Chen+, NeurIPS18] Normalizing Flow](https://files.speakerdeck.com/presentations/2a131e42c1424103b6cacc10de7adab0/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
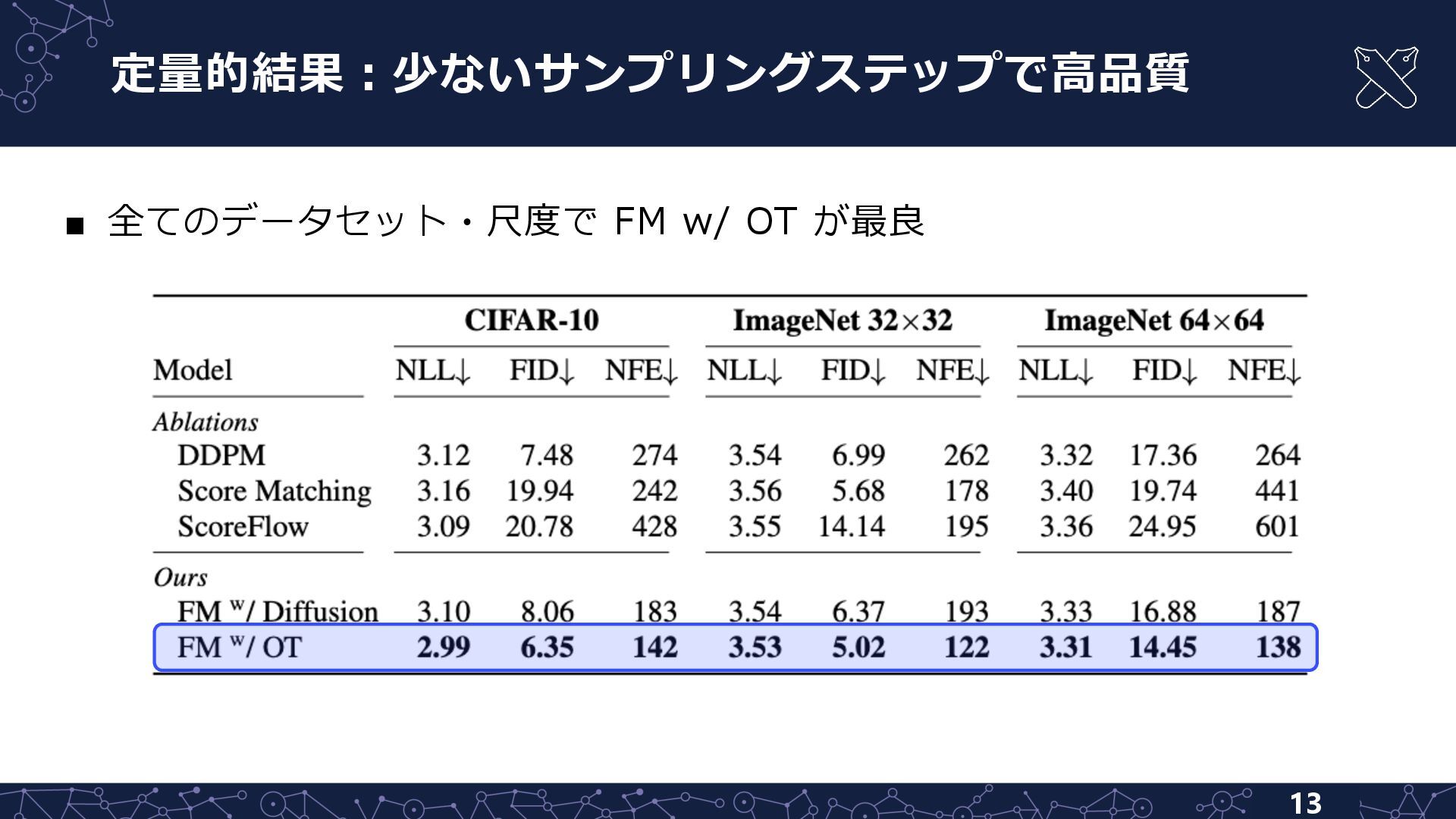{kind=link}
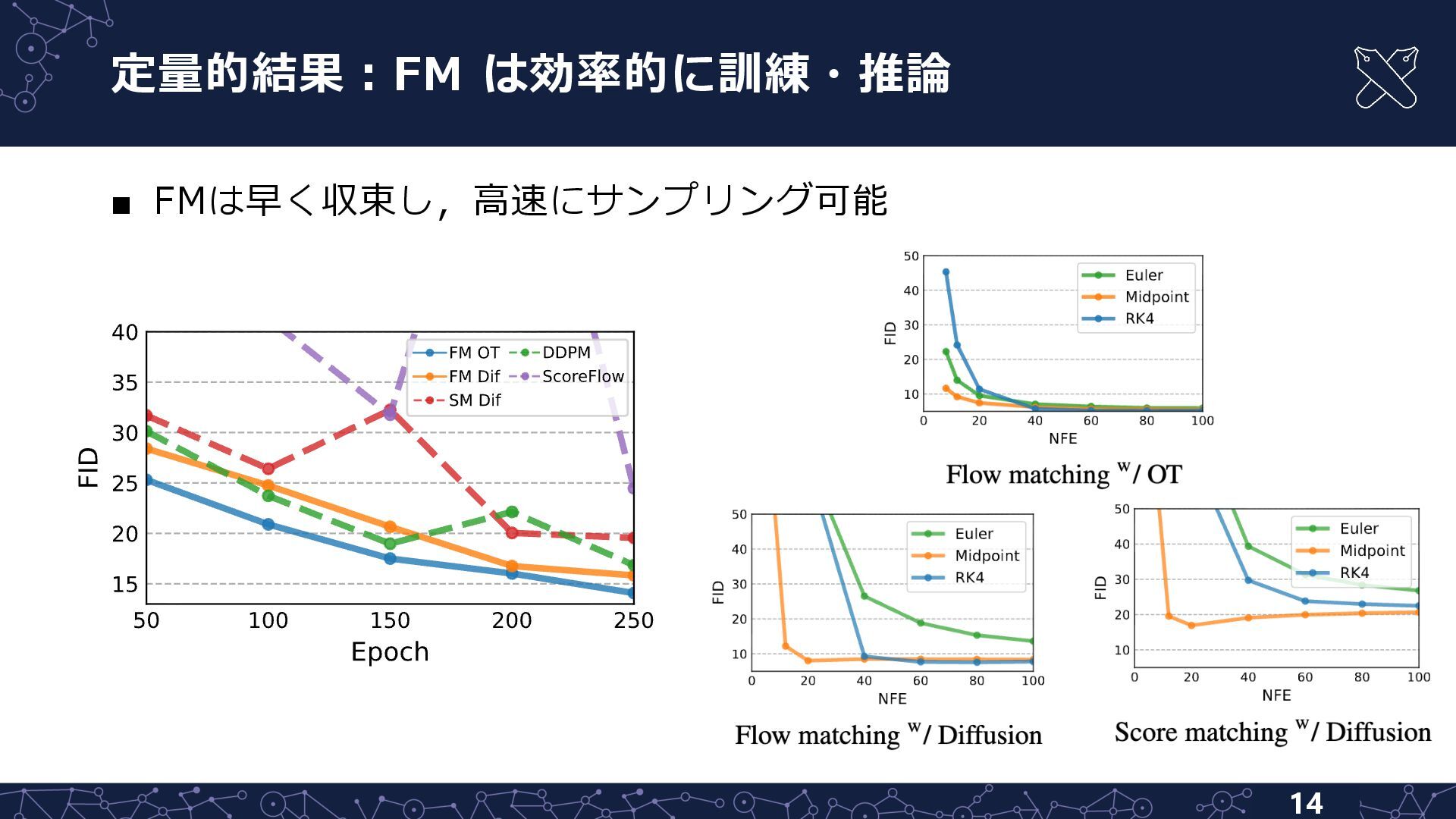{kind=link}
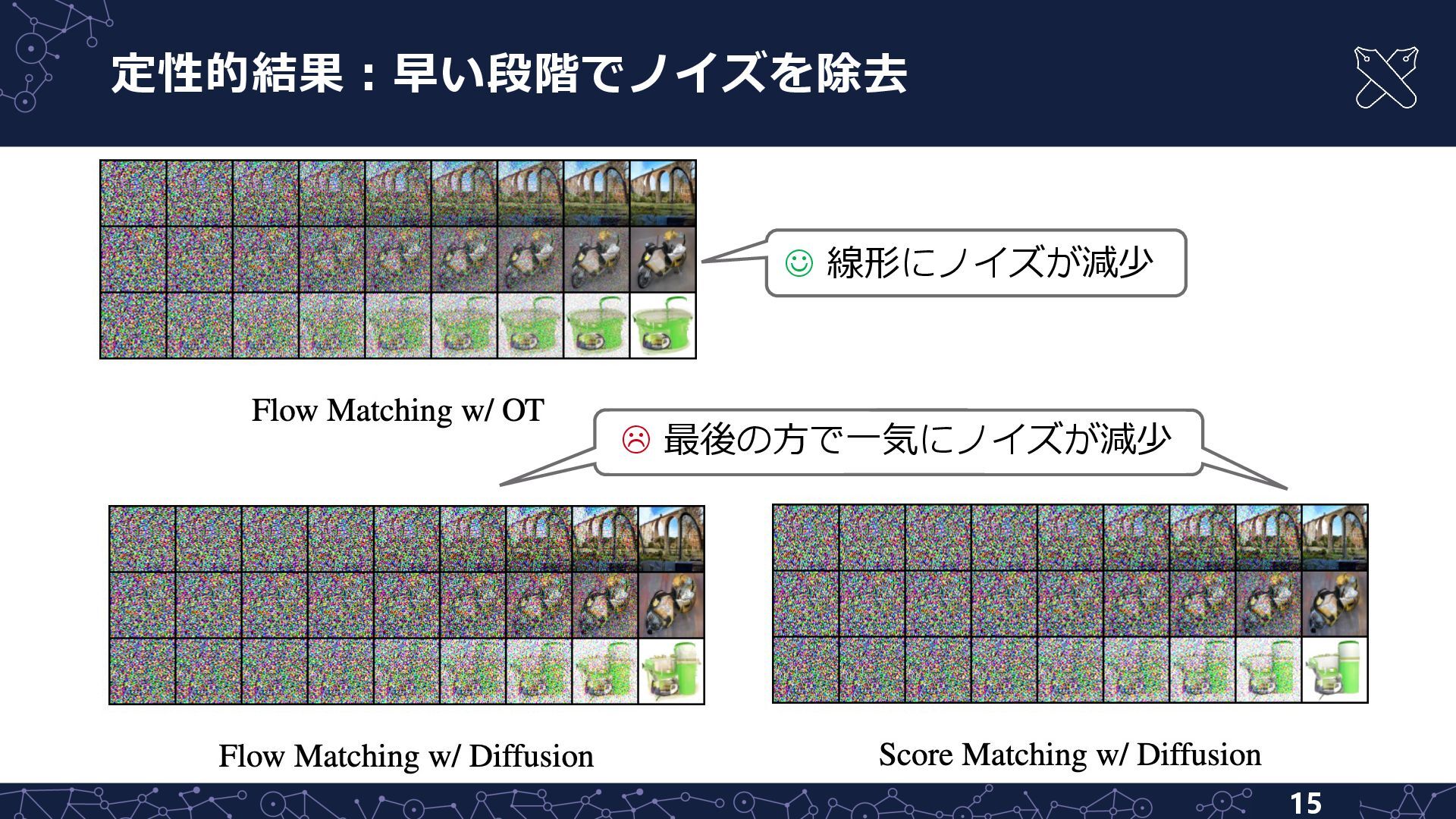{kind=link}
{kind=link}