Hairong Shi 1 Jinhui Ye1*†, Zihan Wang2∗, Haosen Sun2, Keshigeyan Chandrasegaran1, Zane Durante1, Cristobal Eyzaguirre1, Yonatan Bisk3, Juan Carlos Niebles1, Ehsan Adeli1, Li Fei-Fei1, Jiajun Wu1, Manling Li1,2 1Stanford University 2Northwestern University 3Carnegie Mellon University
with locating relevant frames in long videos ▪ Visual search techniques can effectively conduct spatial search in large images ▪ Natural Question: How can we efficiently find key frames? ❖ Method: LV-HAYSTACK & T* ▪ LV-HAYSTACK: First benchmark for temporal search (keyframe selection) ▪ T* Framework: Lightweight framework that reframes temporal search as spatial search ❖ Result ▪ T* efficiently outperforms other keyframe selection methods ▪ Integrating T* with VLMs significantly improves SOTA long-form video understanding
Neurips 24] Long-form QA Only evaluates downstream task performance, not search capability Video-MME [Fu+, CVPR25] Comprehensive video tasks No temporal search evaluation Ego4D [Grauman+, CVPR22] Egocentric understanding Lacks search-specific metrics Key Insight: Most previous works focus on downstream task performance while overlooking the fundamental temporal search capabilities that enable these tasks LongVideoBench [Wu+, NeurIPS24] Video-MME [Fu+, CVPR25]
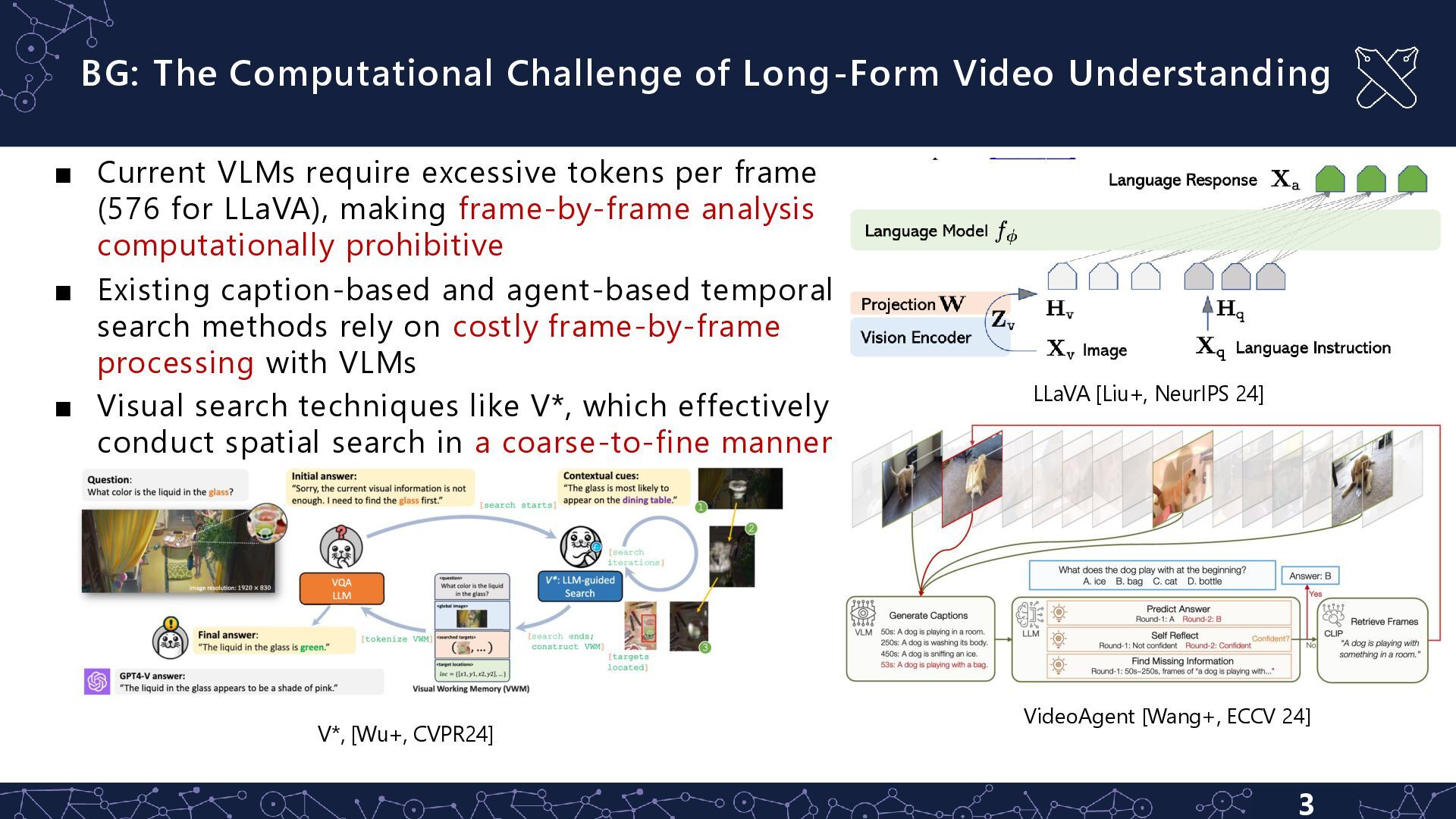
Coarse-to-fine manner’s success in visual search suggests that temporal search could be performed similarly. However, previous methods are mainly caption based, which make it ineffective for temporal search V* , [Wu+, CVPR24] VideoEspresso [Han+, CVPR25]
Metrics ▪ Frame-to-Frame Level: ▪ Temporal Similarity: Binary threshold for timestamp difference ▪ Visual Similarity: SSIM for structural/appearance matching ▪ Set-to-Set Level: ▪ Precision: What portion of predicted frames align with reference frames? ▪ Recall: What portion of reference frames are captured by predictions? ▪ F1 Score: Harmonic mean of Precision and Recall ▪ Search Efficiency Metrics ▪ Frame Cost: Total number of frames processed ▪ FLOPs: Computational complexity ▪ Latency: Total search time
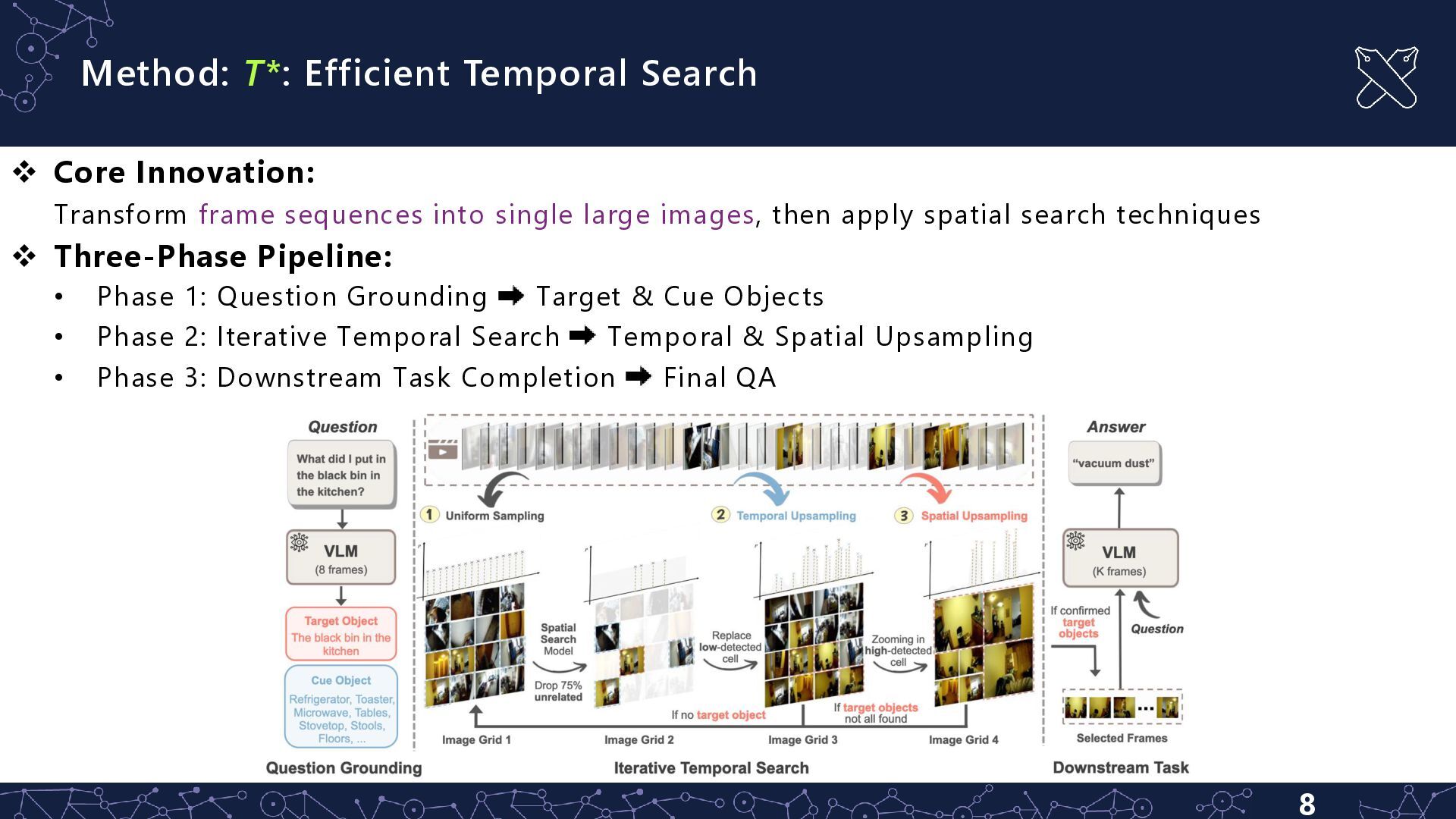
Grounding ▪ Sample N frames uniformly from video ▪ VLM Grounding Object Decision: ▪ Target Objects: Directly relevant to answering question ▪ Cue Objects: Contextual elements indicating regions of interest ▪ Example: "What did I put in the black bin?" → Target: black bin, Cues: kitchen furniture
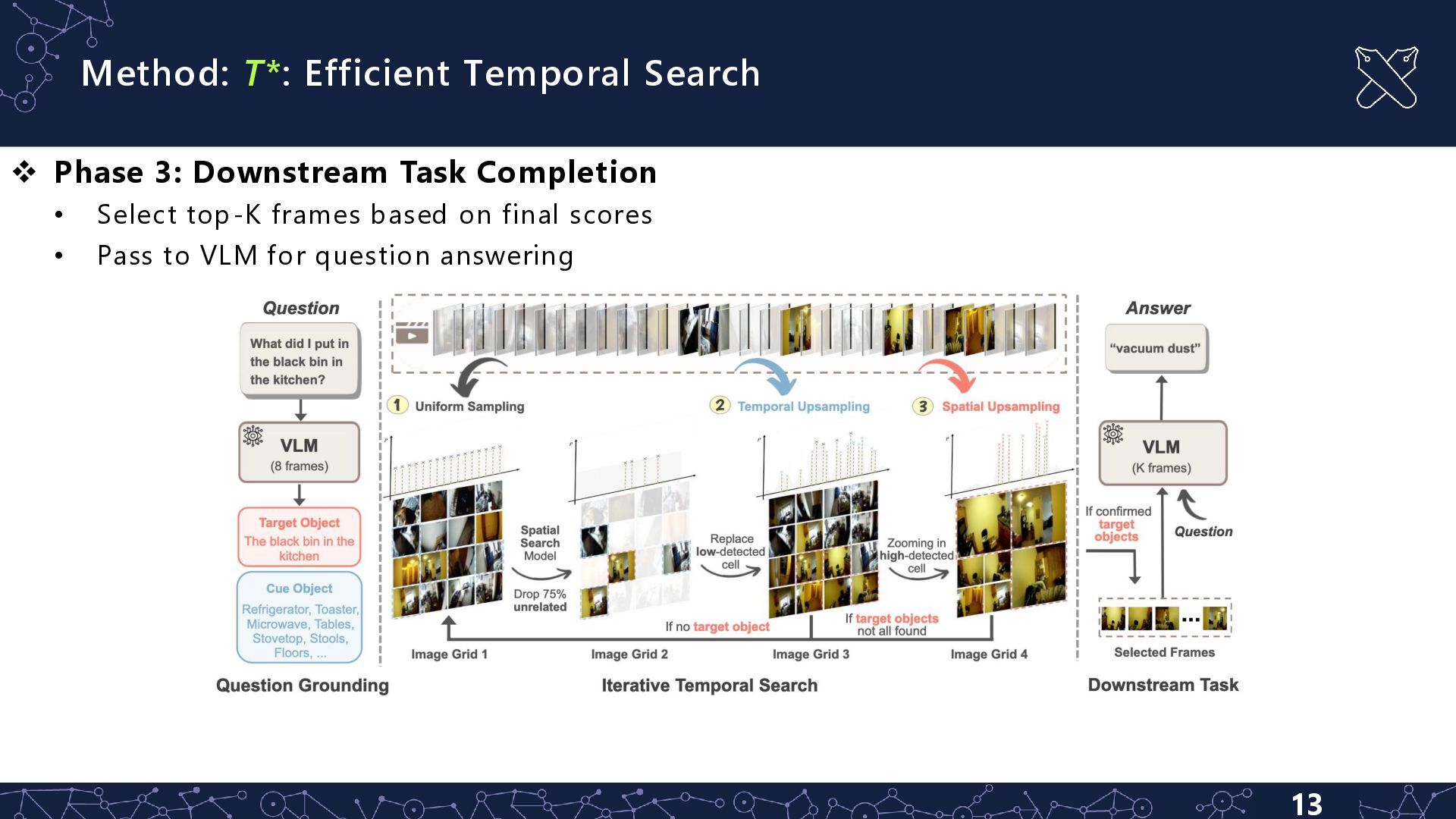
Temporal Search • 1. Initialize uniform probability distribution over all frames • 2. Sample frames according to current distribution • 3. Arrange sampled frames into g×g grid image • 4. Perform object detection on grid • 5. Zoom into high-confidence temporal regions • 6. Update confidence scores and sampling distribution • 7. Repeat until targets found or budget exhausted
Temporal Search • 1. Initialize uniform probability distribution over all frames • 2. Sample frames according to current distribution • 3. Arrange sampled frames into g×g grid image • 4. Perform object detection on grid • 5. Zoom into high-confidence temporal regions • 6. Update confidence scores and sampling distribution • 7. Repeat until targets found or budget exhausted
Temporal Search • 1. Initialize uniform probability distribution over all frames • 2. Sample frames according to current distribution • 3. Arrange sampled frames into g×g grid image • 4. Perform object detection on grid • 5. Zoom into high-confidence temporal regions • 6. Update confidence scores and sampling distribution • 7. Repeat until targets found or budget exhausted
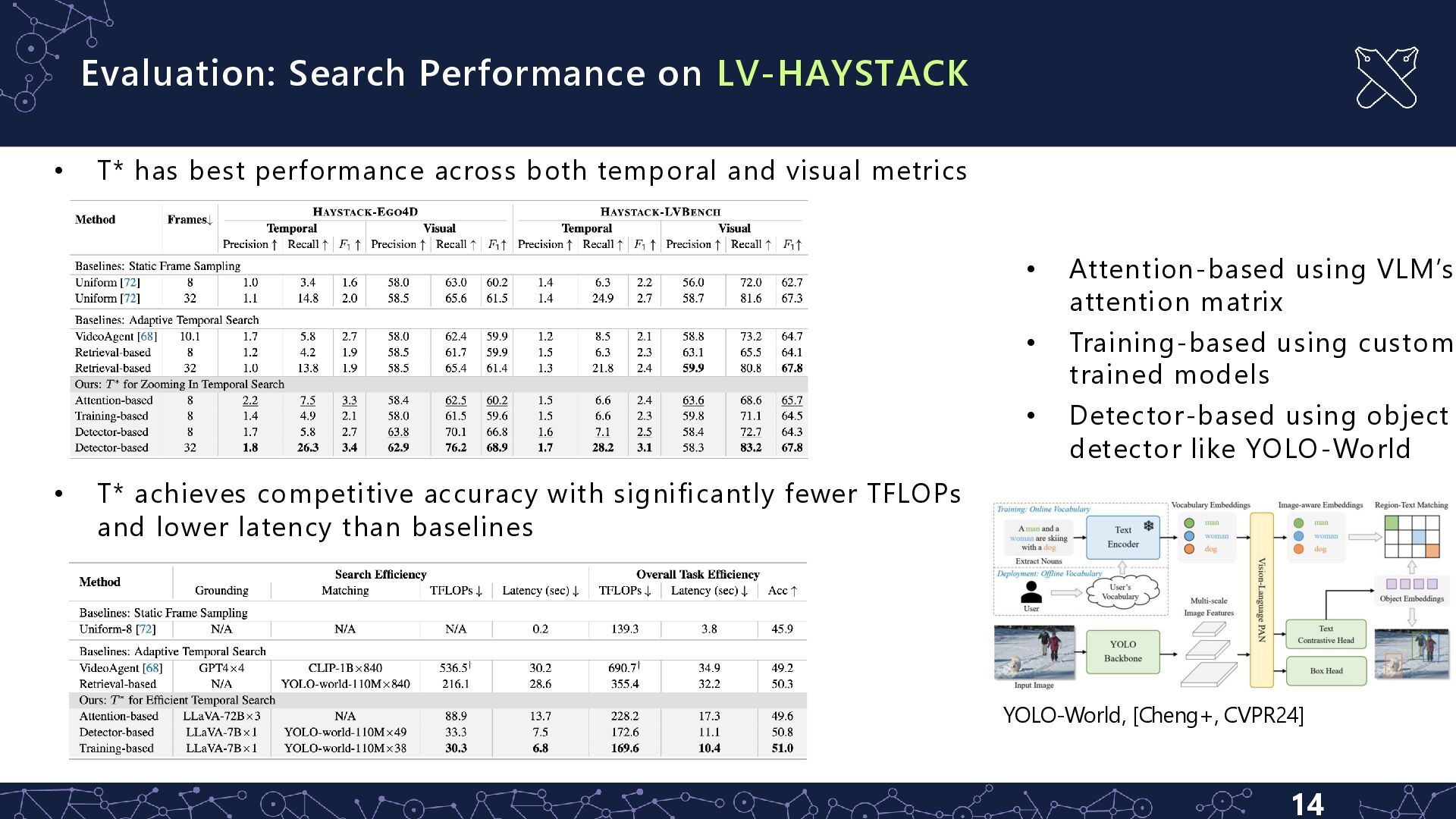
performance across both temporal and visual metrics • T* achieves competitive accuracy with significantly fewer TFLOPs and lower latency than baselines • Attention-based using VLM’s attention matrix • Training-based using custom trained models • Detector-based using object detector like YOLO-World YOLO-World, [Cheng+, CVPR24]
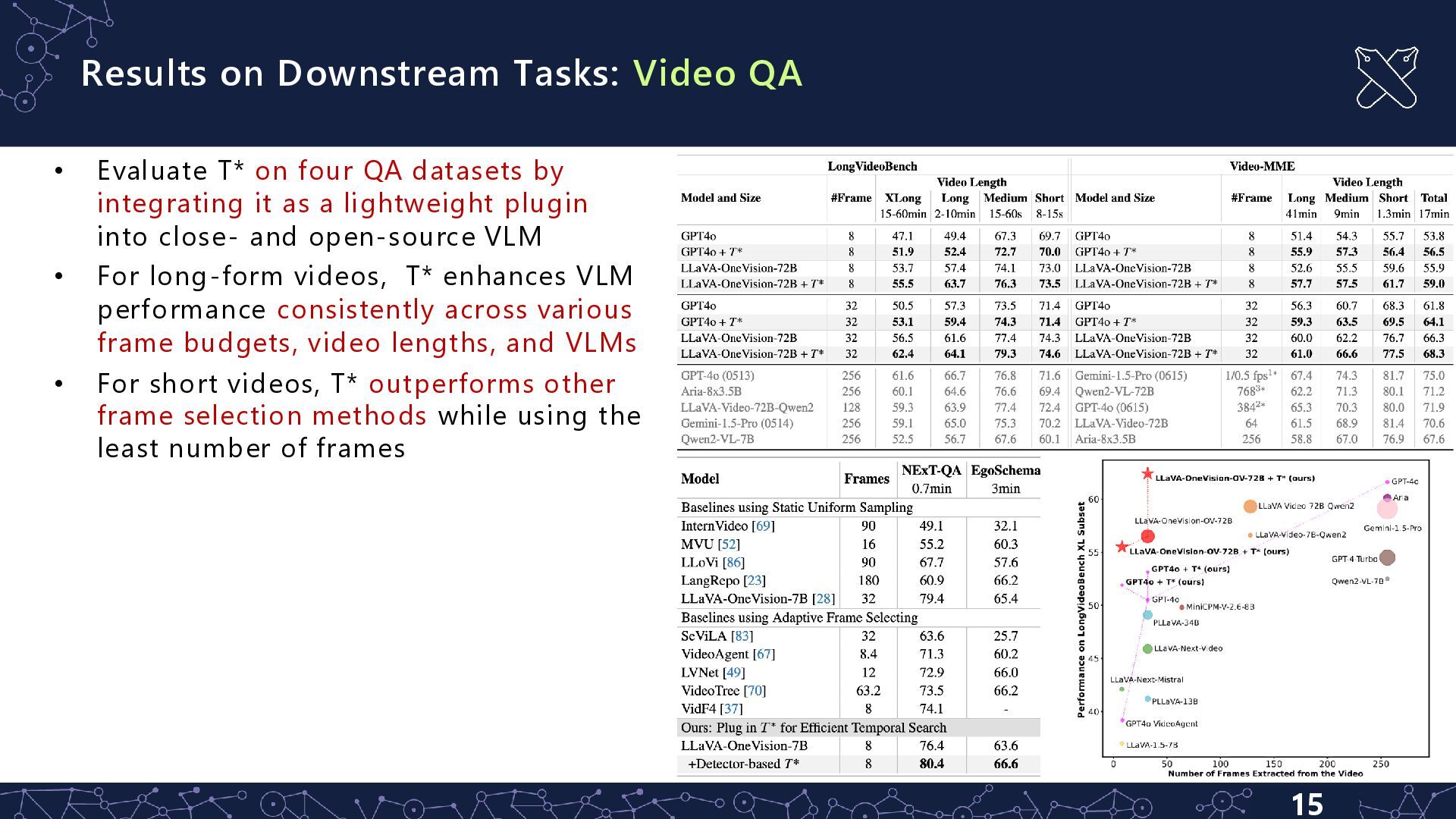
on four QA datasets by integrating it as a lightweight plugin into close- and open-source VLM • For long-form videos, T* enhances VLM performance consistently across various frame budgets, video lengths, and VLMs • For short videos, T* outperforms other frame selection methods while using the least number of frames
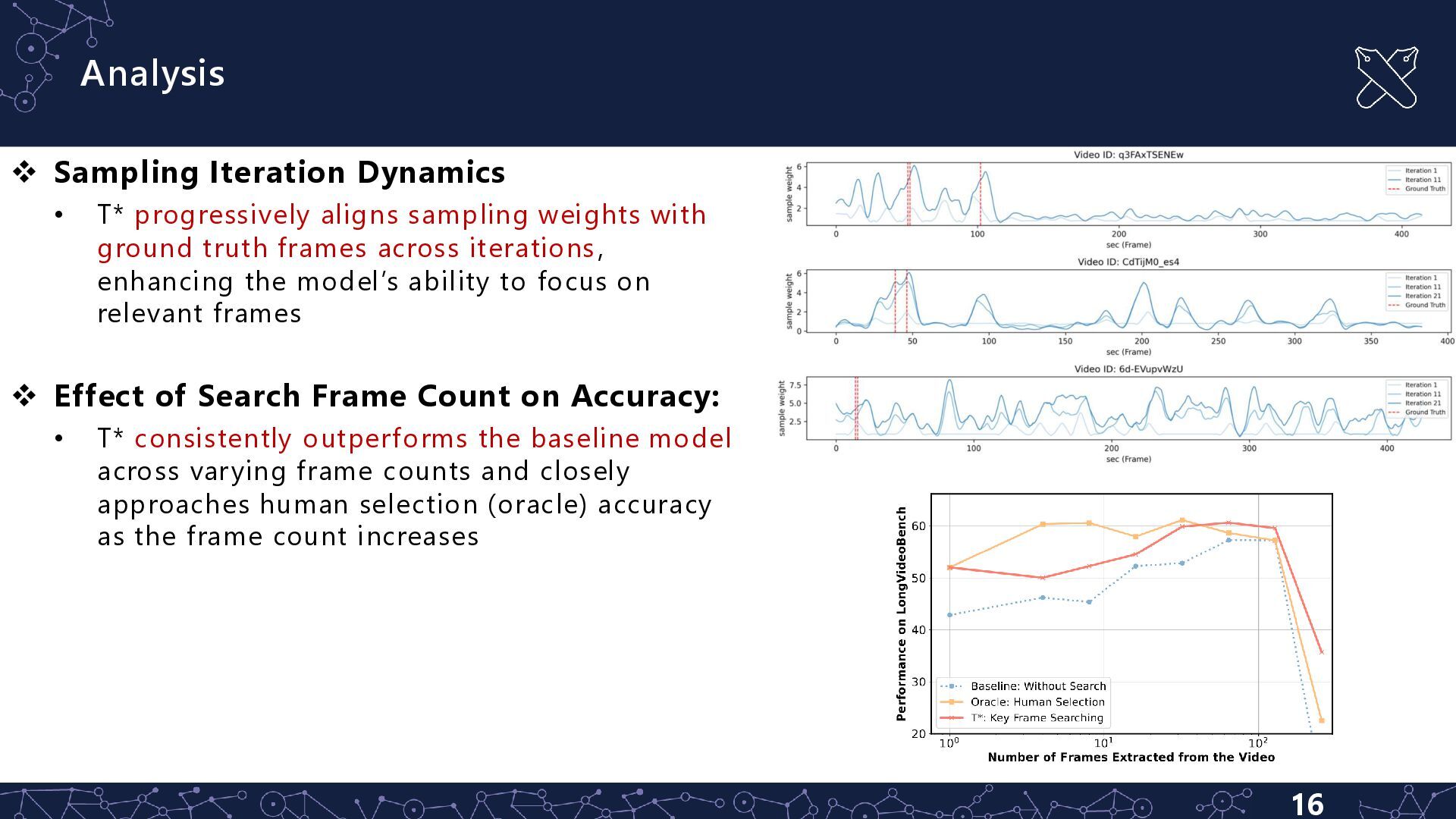
sampling weights with ground truth frames across iterations, enhancing the model’s ability to focus on relevant frames ❖ Effect of Search Frame Count on Accuracy: • T* consistently outperforms the baseline model across varying frame counts and closely approaches human selection (oracle) accuracy as the frame count increases
with locating relevant frames in long videos ▪ Visual search techniques like V*can effectively conduct spatial ❖ Method: LV-HAYSTACK & T* ▪ LV-HAYSTACK: First benchmark for temporal search (keyframe selection) ▪ T* Framework: Lightweight framework that reframes temporal search as spatial search ❖ Result ▪ T* efficiently outperforms other keyframe selection methods ▪ Integrating T* with VLMs significantly improves SOTA long-form video understanding
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}