Decoderにて拡散モデルによる画像生成 3 • Imagen[Chitwan+, May, 2022] – 段階的な拡散モデルで画像生成 • txt2img, super-resolution A photo of a hedgehog wearing a red coat reading a book sitting on a lounge chair in the middle of a lush forest. https://imagen.research.google/
Decoderにて拡散モデルによる画像生成 4 • Imagen[Chitwan+, May, 2022] – 段階的な拡散モデルで画像生成 • txt2img, super-resolution A photo of a hedgehog wearing a red coat reading a book sitting on a lounge chair in the middle of a lush forest. https://imagen.research.google/ 拡散モデルによって,高次元である画像のピクセル空間を直接扱う ⇒パラメータ数の増大によるコストの増加 DALL·E-2:3.5B Imagen:2B(txt2img), 600M and 400M(super-resolution)
ram skull. beautiful intricately detailed japanese crow, kitsune mask and clasical japanese kimono. betta fish, jellyfish phoenix, bio luminescent, plasma, ice, water, wind, creature, artwork by tooth wu and wlop and beeple and greg rutkowski 14 現時点での最新版 v1.4 LAION-5Bによる学習
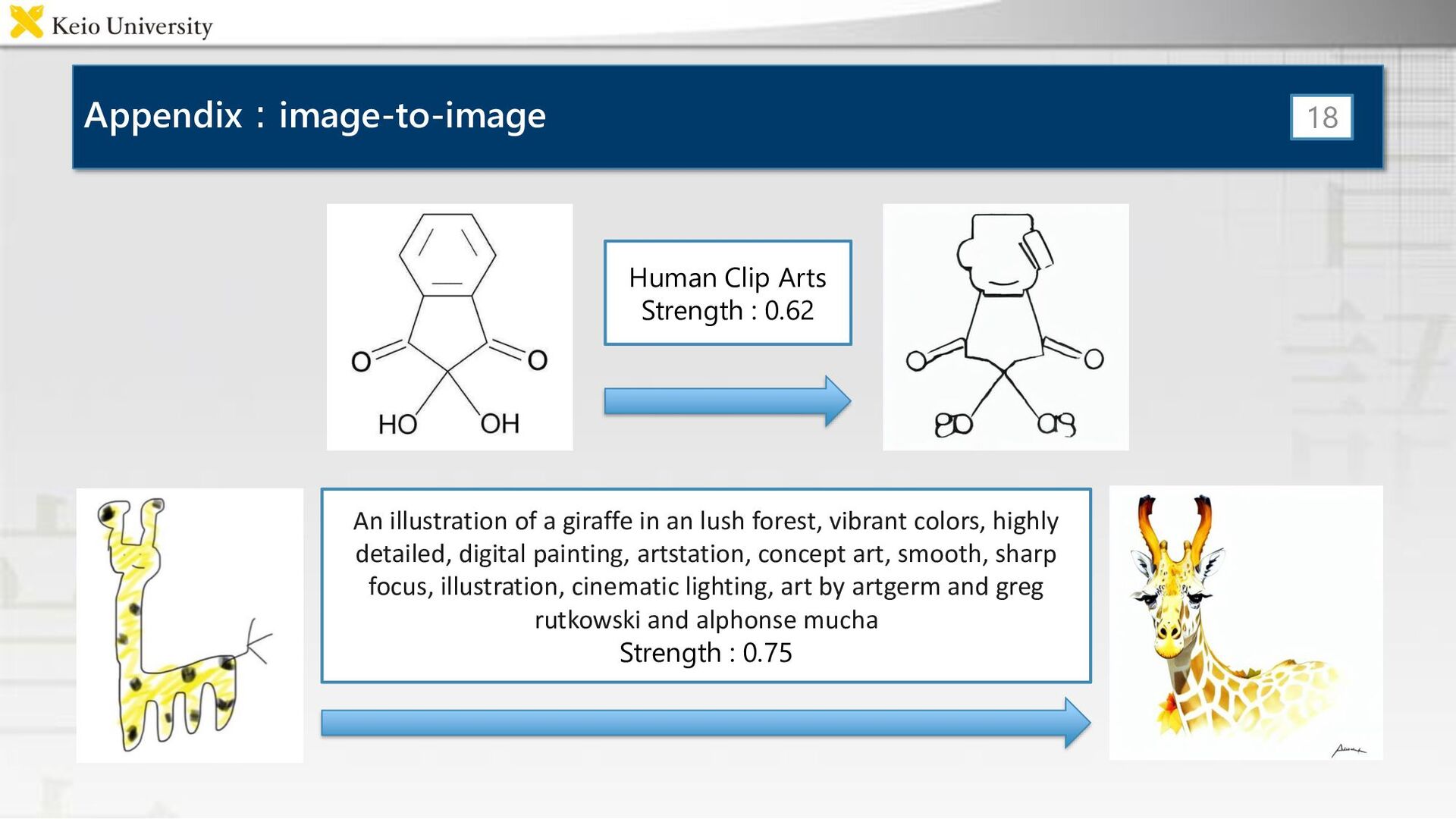
of a giraffe in an lush forest, vibrant colors, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, cinematic lighting, art by artgerm and greg rutkowski and alphonse mucha Strength : 0.75
{kind=link}
{kind=link}
![背景:画像分野の急速な発展 • DALL·E-2[Aditya+, April, 2022] – CLIP[Alec+, 2021]によるImage Embedding –](https://files.speakerdeck.com/presentations/f2e2256cdeed418bbcff34f4af8e0107/slide_2.jpg){kind=link}
![背景:画像分野の急速な発展 • DALL·E-2[Aditya+, April, 2022] – CLIP[Alec+, 2021]によるImage Embedding –](https://files.speakerdeck.com/presentations/f2e2256cdeed418bbcff34f4af8e0107/slide_3.jpg){kind=link}
{kind=link}
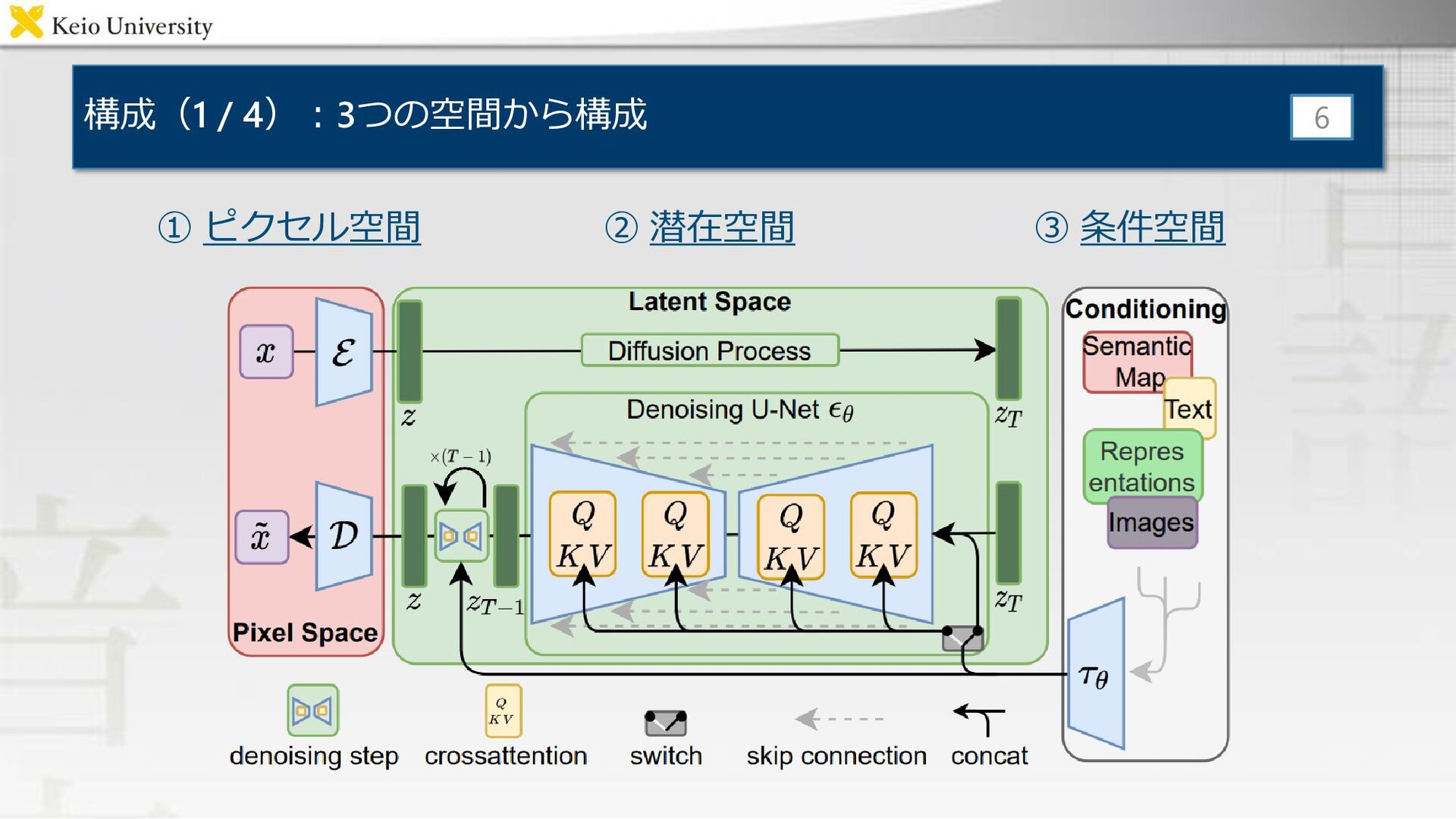{kind=link}
![構成(2 / 4):ピクセル空間 • Autoencoderによって低次元に圧縮 – VAE[Kingma+, ICLR14]の構造を採用 • 本モデルは1/8に圧縮](https://files.speakerdeck.com/presentations/f2e2256cdeed418bbcff34f4af8e0107/slide_6.jpg){kind=link}
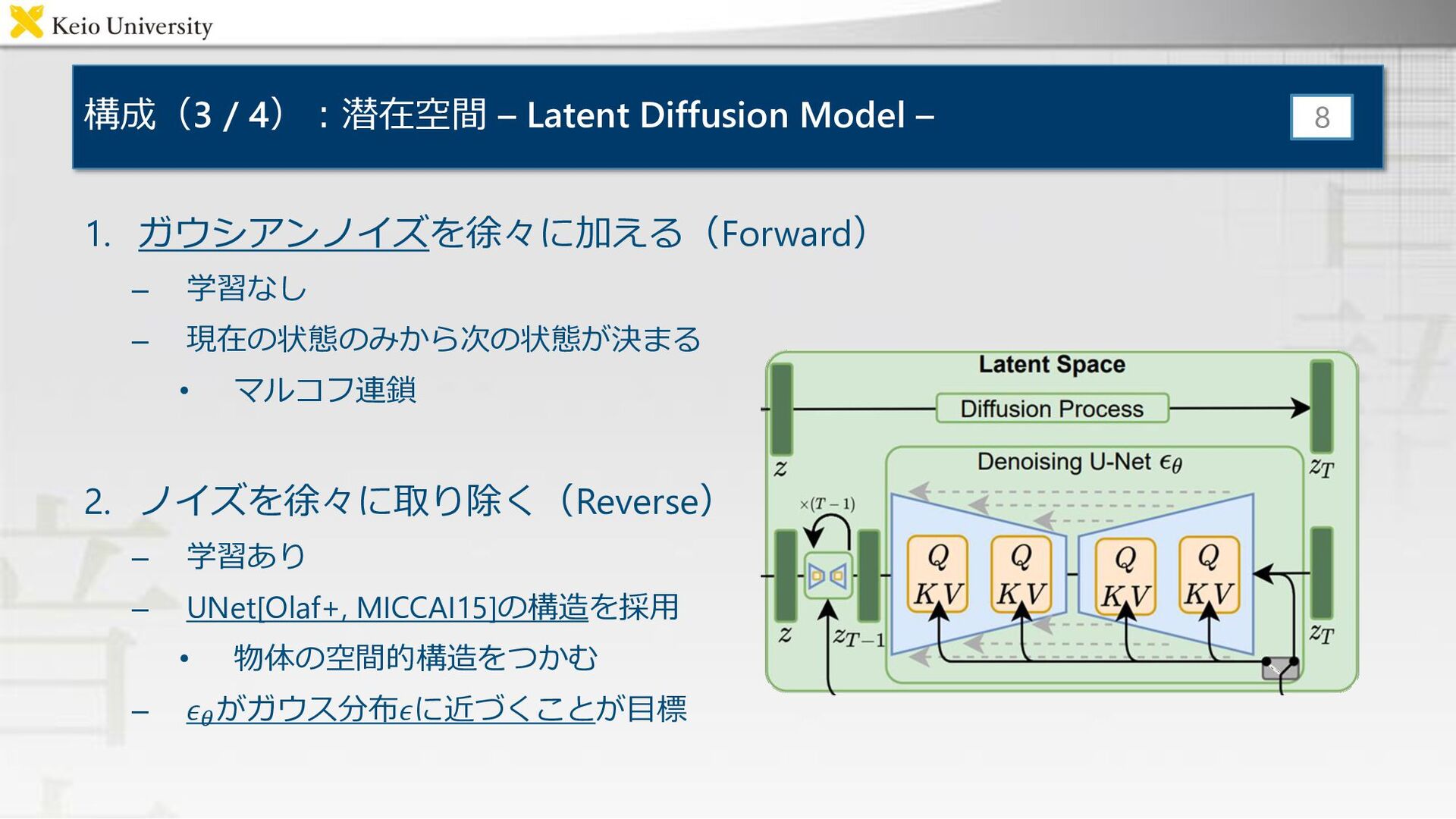{kind=link}
{kind=link}
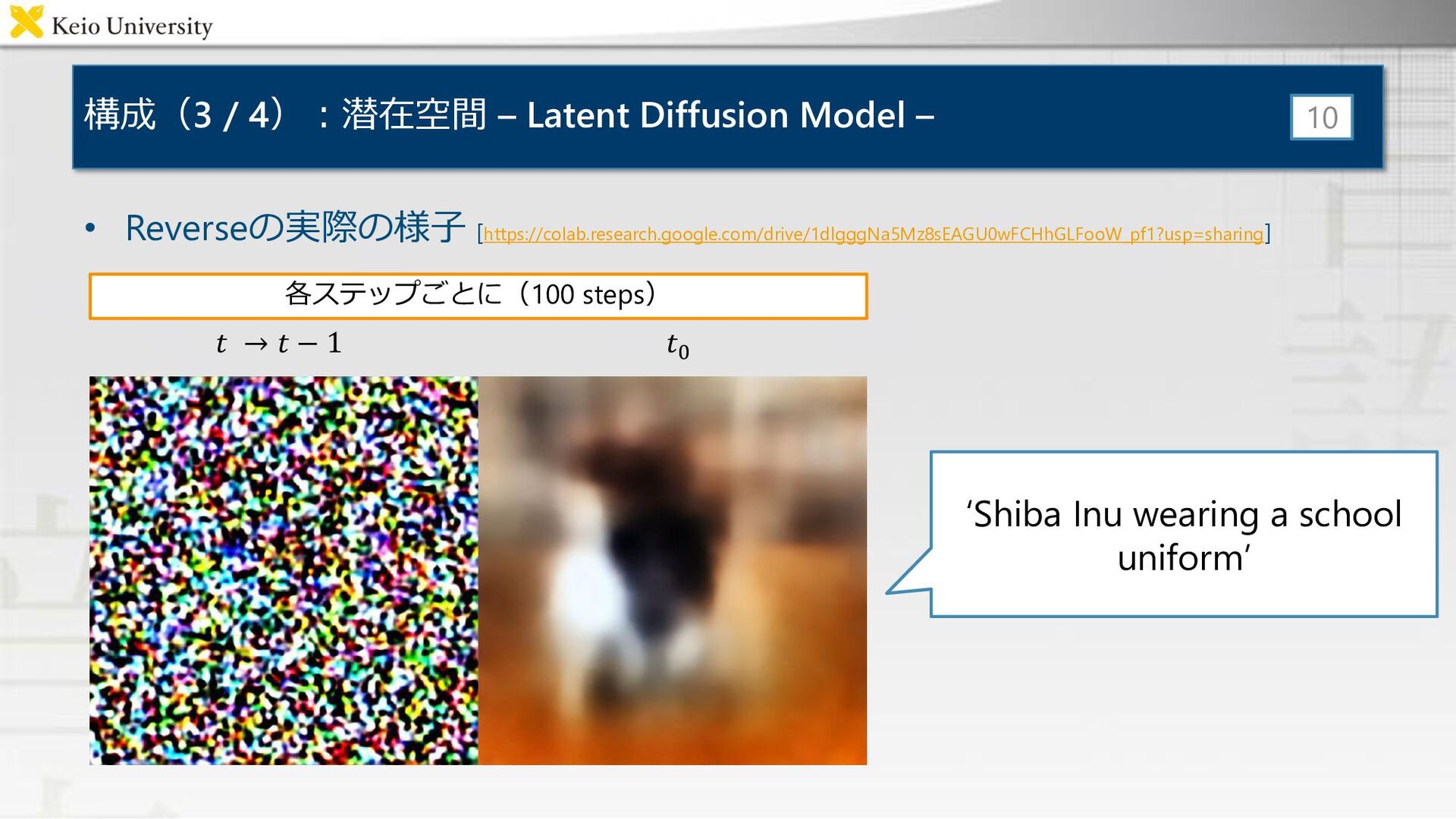{kind=link}
{kind=link}
![実験設定:Text-to-Image • 訓練データセット – LAION-400M[Christoph+, 2021] • 画像とテキストのペア • 評価データセット](https://files.speakerdeck.com/presentations/f2e2256cdeed418bbcff34f4af8e0107/slide_11.jpg){kind=link}
![定量的結果:既存手法を上回る性能 13 FID↓ IS↑ DALL-E [Aditya+, CoRR21] 27.5 17.9 Cog](https://files.speakerdeck.com/presentations/f2e2256cdeed418bbcff34f4af8e0107/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}