Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] MetaFormer is Actually What You ...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 29, 2022
Technology
200
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] MetaFormer is Actually What You Need for Vision
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 29, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
84
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
130
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
210
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
780
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
430
VPCセキュリティ対応の最新事情
nagisa53
1
270
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
130
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
890
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
270
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
380
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
210
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
370
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
300
Featured
See All Featured
Mind Mapping
helmedeiros
PRO
1
290
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
Odyssey Design
rkendrick25
PRO
2
730
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
RailsConf 2023
tenderlove
30
1.5k
Deep Space Network (abreviated)
tonyrice
0
230
Leo the Paperboy
mayatellez
8
1.9k
A Modern Web Designer's Workflow
chriscoyier
698
190k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Building the Perfect Custom Keyboard
takai
2
820
Transcript
慶應義塾大学 杉浦孔明研究室 松尾榛夏 Yu, Weihao, et al. "Metaformer is actually
what you need for vision." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
概要 • Transformerのtoken mixerを特定しない一般的な構造としてMetaFormerを提案 • token mixerを一番シンプルなpoolingにしたPoolFormerで実験 • PoolFormerは他のtoken mixerのモデルより効率よく同程度の精度
• Transformerが優れた結果を出せる理由は、MetaFormerであると言える 2
• Transformer[Vaswani+, 17]は翻訳タスクで提案 • 自然言語処理タスクで人気に • Computer Visionタスクに適用 • Transformerのtoken
mixerはAttention機構 • token mixer : 画像パッチ(token)の特徴量をmixする • Transformerの成功はAttention機構が原因であると考察 • Transformerのtoken mixingの改良に焦点 背景: TransformerのComputer Visionタスクへの適用 3
関連研究: token mixerを改良したモデルが存在 4 モデル 特徴 ViT [Dosovitskiy+, ICPL21] •
コンピュータビジョンタスクにTransformerを適用 • 画像パッチを単語のように扱う DeiT [Touvron+, ICML21] • 知識蒸留の利用 • ViTの学習データやパラメータを削減 ResMLP [Touvron+, 21] • Transformerのtoken mixerとしてMLPを採用した モデル
課題: Attention機構の優位性について疑問が生まれる • ResMLPのようにtoken mixerへのMLPの使用によりTransformerに匹敵する性能を達成 • MLP(多層パーセプトロン) : パーセプトロンの入力層と出力層の間に中間層を足したもの •
Attention機構の優位性や、最適なtoken mixerについての議論が発生 仮説 「特定のtoken mixer moduleではなく、 Transformerの一般的な構造が優れた性能を出すために重要」 5
提案手法: MetaFormer(1/3) 一般的な構造を定義 • Token mixerを特定しないTransformerの一般的な構造 • それ以外はTransformerと同じ • 入力画像をViTのPatch
Embeddingによって処理 • 画像パッチを単語のように扱う 𝑋 = InputEmb 𝐼 𝑋 ∈ ℝ𝑁×𝐶 𝑁: 画像の分割数 𝐶: 画像のchannel数 6
提案手法: MetaFormer(2/3) 画像をパッチに分割 • Token mixerを特定しないTransformerの一般的な構造 • それ以外はTransformerと同じ • 入力画像をViTのPatch
Embeddingによって処理 • 画像パッチを単語のように扱う 𝑋 = InputEmb 𝐼 𝑋 ∈ ℝ𝑁×𝐶 𝑁: 画像の分割数 𝐶: 画像のchannel数 7
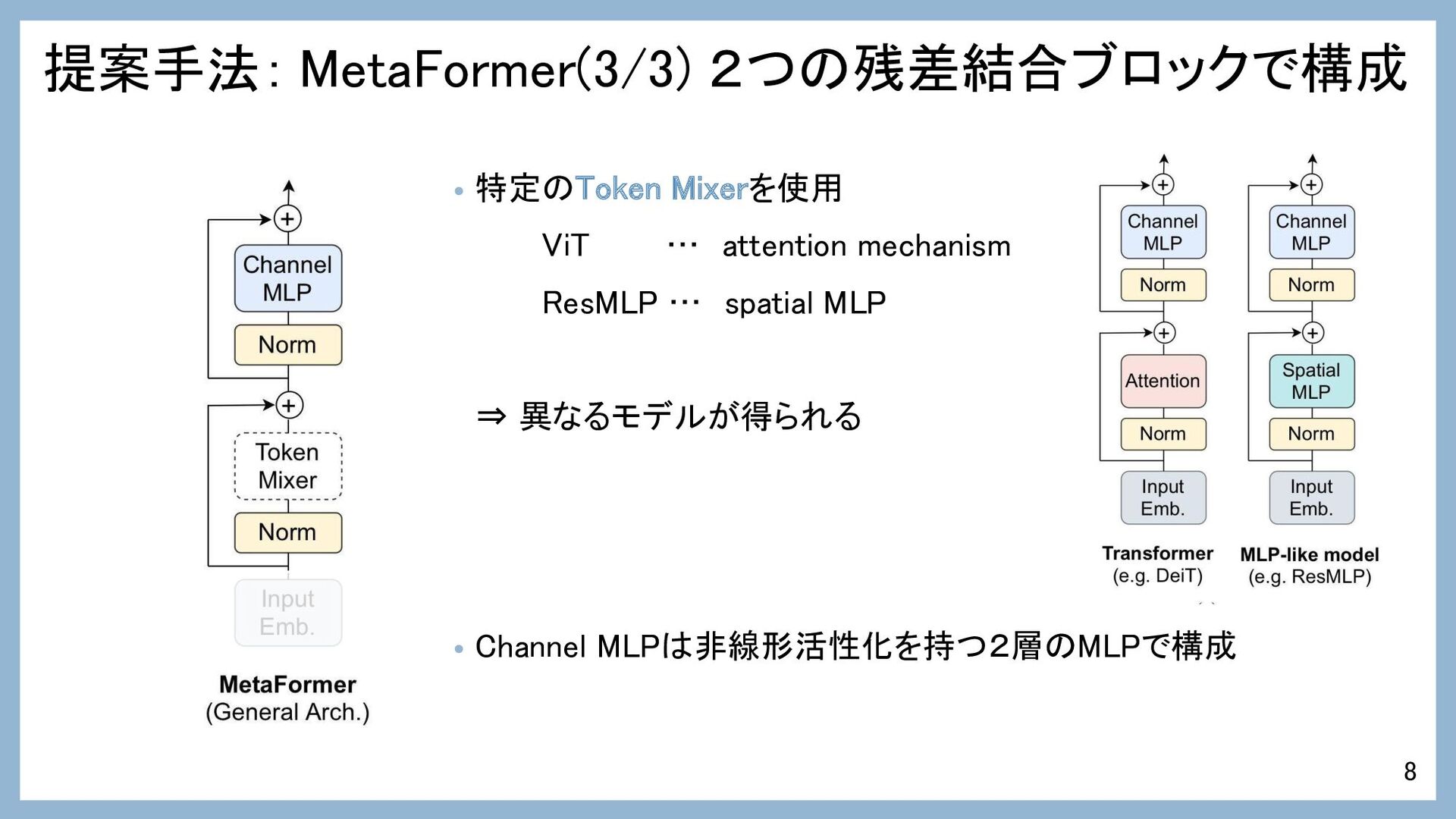
提案手法: MetaFormer(3/3) 2つの残差結合ブロックで構成 • 特定のToken Mixerを使用 ViT … attention mechanism
ResMLP … spatial MLP ⇒ 異なるモデルが得られる • Channel MLPは非線形活性化を持つ2層のMLPで構成 8
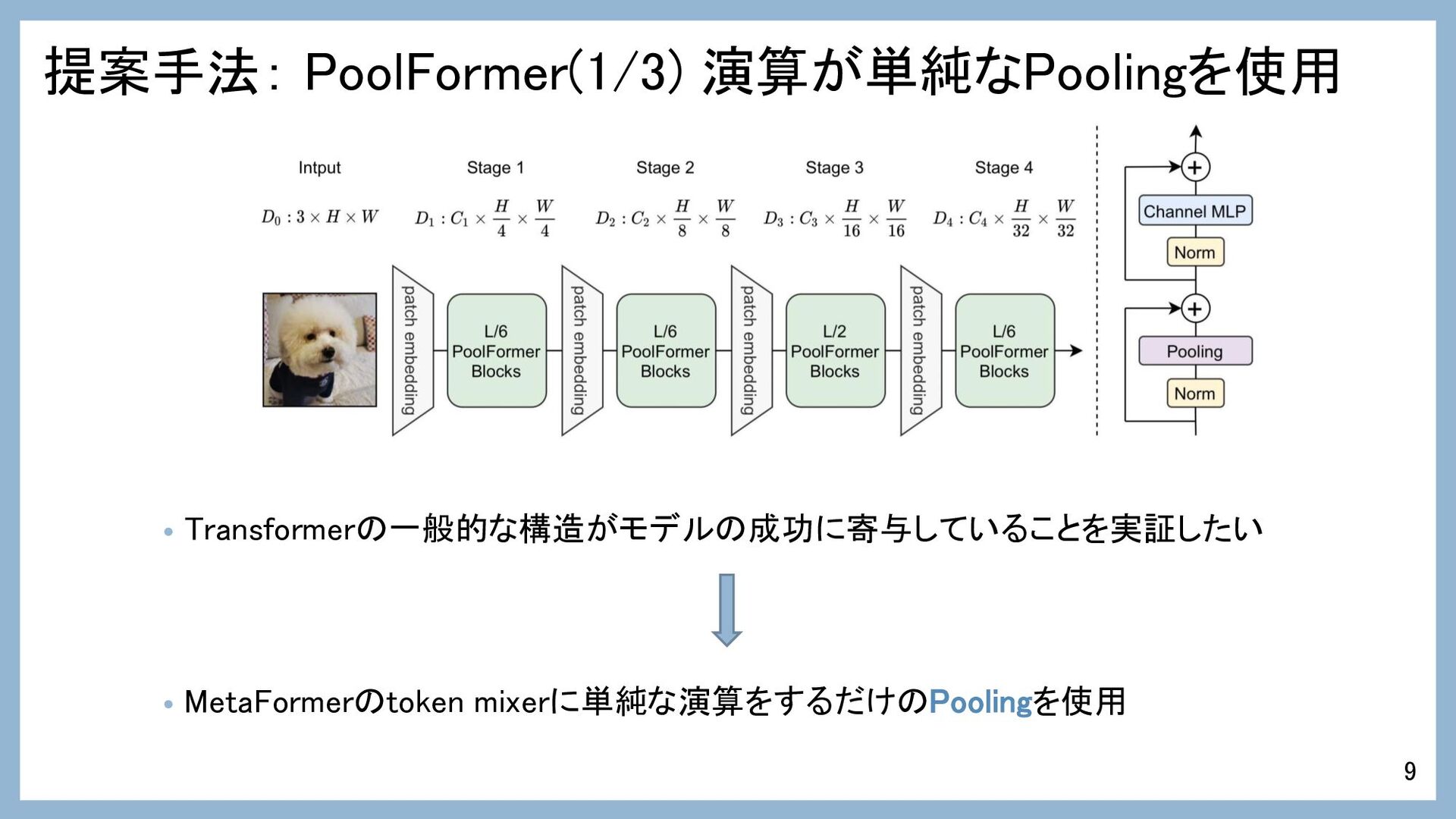
提案手法: PoolFormer(1/3) 演算が単純なPoolingを使用 • Transformerの一般的な構造がモデルの成功に寄与していることを実証したい • MetaFormerのtoken mixerに単純な演算をするだけのPoolingを使用 9
提案手法: PoolFormer(2/3) 平均プーリングと減算 • Poolingはそれぞれのtokenとその近くのtokenの特徴を平均的にまとめる 𝑇:,𝑖,𝑗 ′ = 1 𝐾
× 𝐾 𝑝,𝑞=1 𝐾 𝑇 :,𝑖+𝑝− 𝐾+1 2 ,𝑗+𝑞− 𝐾+1 2 − 𝑇:,𝑖,𝑗 入力 𝑇 ∈ ℝ𝐶×H×W (𝐶: channel数 𝐻: 画像の高さ 𝑊: 画像の幅) ☆入力自体の減算 MetaFormer構造内に既にある残差を打ち消すため 10 位置(𝑖, 𝑗)での平均プーリング (𝐾: プーリング層のカーネルサイズ) ☆
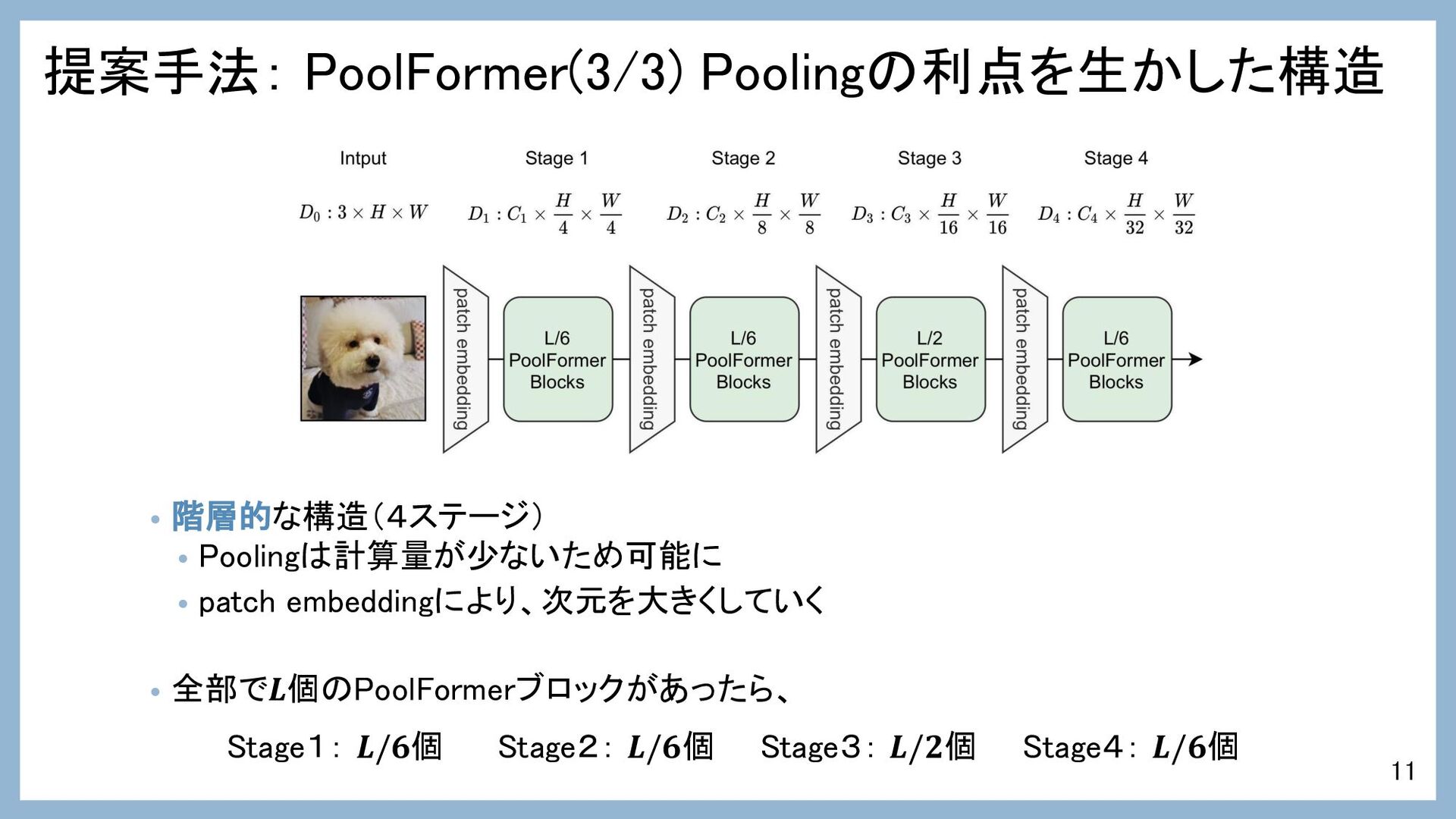
提案手法: PoolFormer(3/3) Poolingの利点を生かした構造 • 階層的な構造(4ステージ) • Poolingは計算量が少ないため可能に • patch embeddingにより、次元を大きくしていく
• 全部で𝑳個のPoolFormerブロックがあったら、 Stage1: 𝑳/𝟔個 Stage2: 𝑳/𝟔個 Stage3: 𝑳/𝟐個 Stage4: 𝑳/𝟔個 11
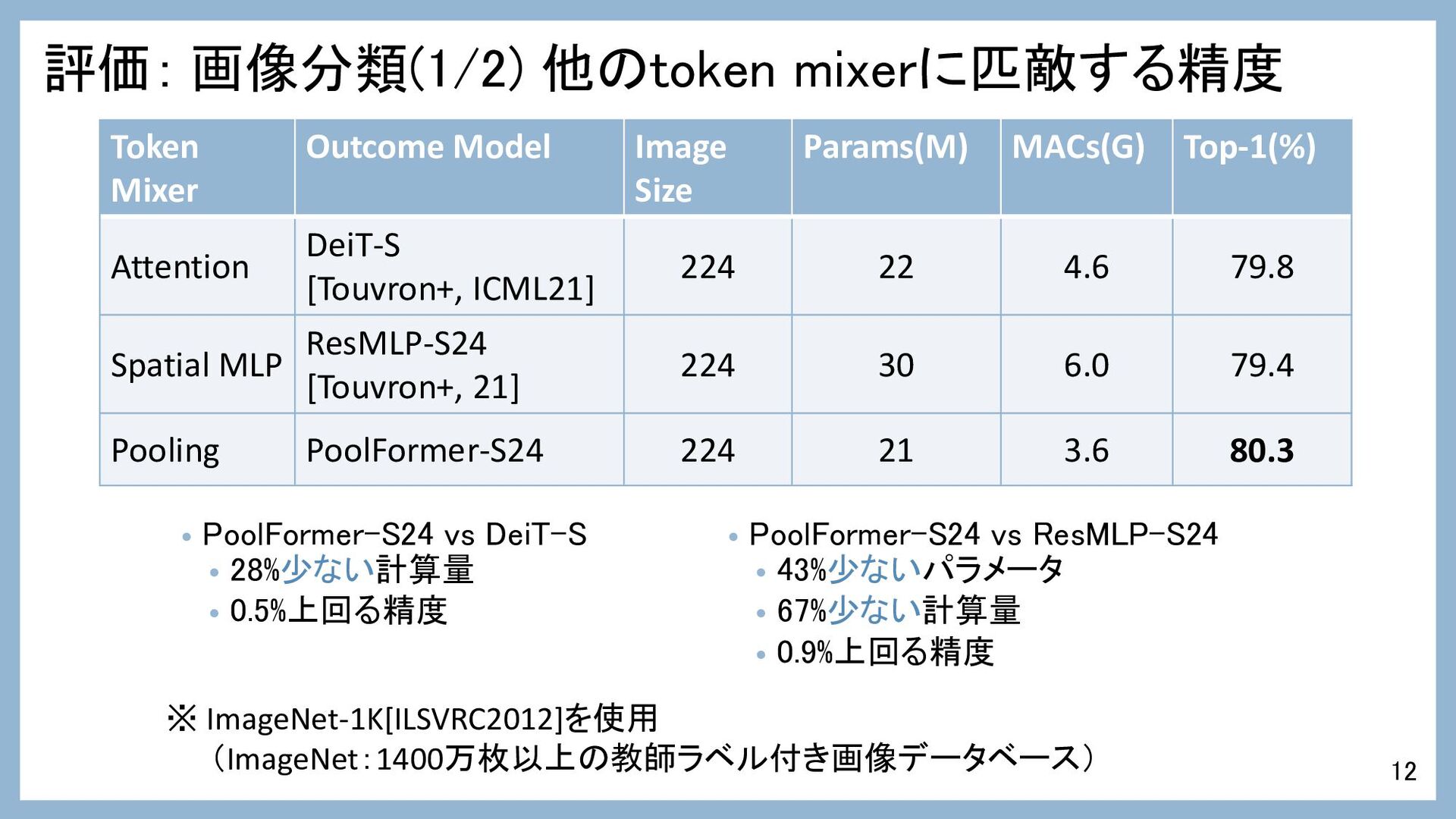
評価: 画像分類(1/2) 他のtoken mixerに匹敵する精度 • PoolFormer-S24 vs DeiT-S • 28%少ない計算量
• 0.5%上回る精度 • PoolFormer-S24 vs ResMLP-S24 • 43%少ないパラメータ • 67%少ない計算量 • 0.9%上回る精度 12 ※ ImageNet-1K[ILSVRC2012]を使用 (ImageNet:1400万枚以上の教師ラベル付き画像データベース) Token Mixer Outcome Model Image Size Params(M) MACs(G) Top-1(%) Attention DeiT-S [Touvron+, ICML21] 224 22 4.6 79.8 Spatial MLP ResMLP-S24 [Touvron+, 21] 224 30 6.0 79.4 Pooling PoolFormer-S24 224 21 3.6 80.3
評価: 画像分類(2/2) 少ない計算量とパラメータ • 他の手法より少ない計算量とパラメータで良い精度 • Poolingは学習可能なパラメータを持たず、線形な演算のみ • 最も基本的なtoken mixerでも高い性能を獲得
⇒MetaFormerは高い精度を出すために必要で汎用的な構造 13
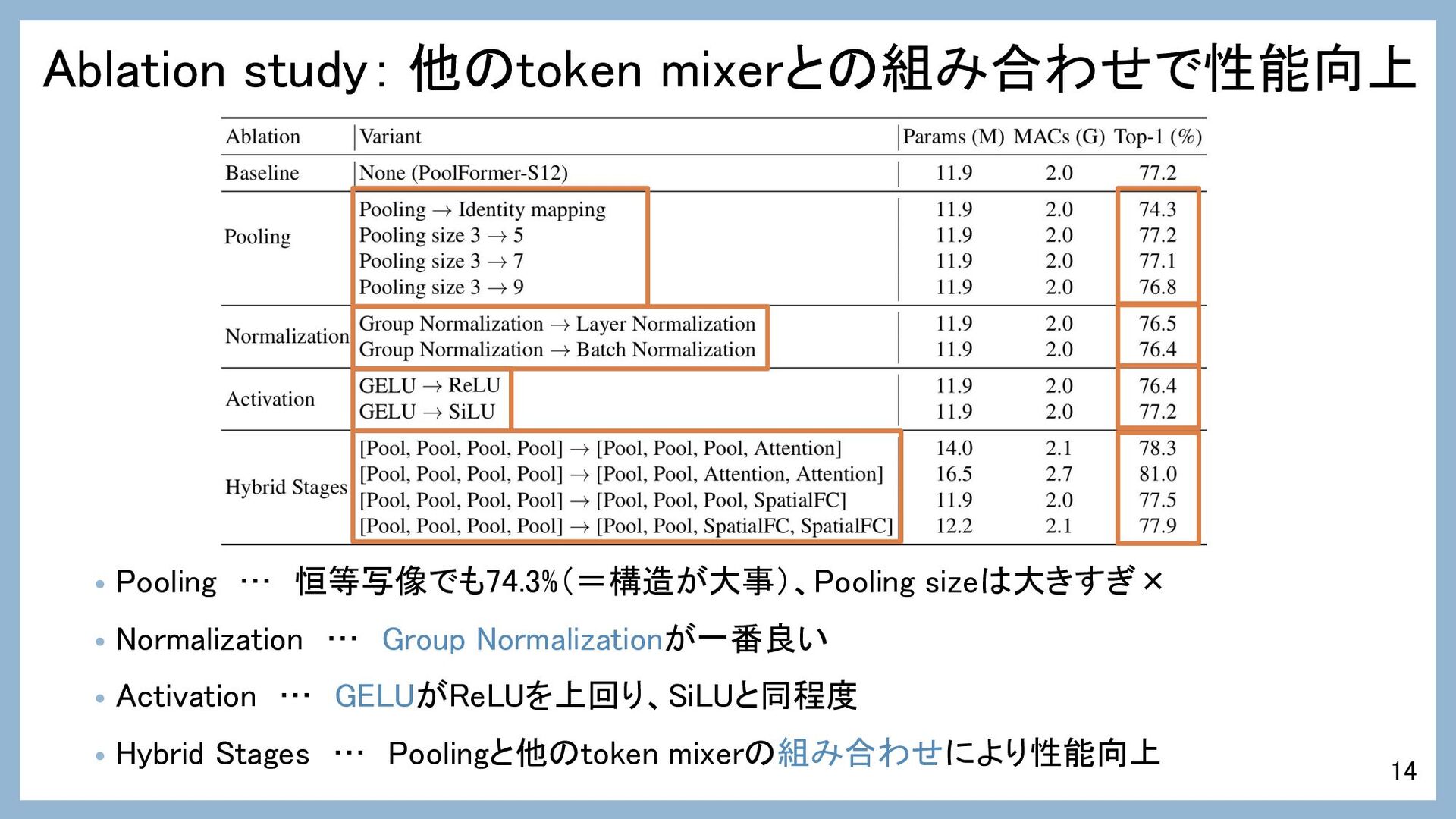
Ablation study: 他のtoken mixerとの組み合わせで性能向上 • Pooling … 恒等写像でも74.3%(=構造が大事)、Pooling sizeは大きすぎ× •
Normalization … Group Normalizationが一番良い • Activation … GELUがReLUを上回り、SiLUと同程度 • Hybrid Stages … Poolingと他のtoken mixerの組み合わせにより性能向上 14
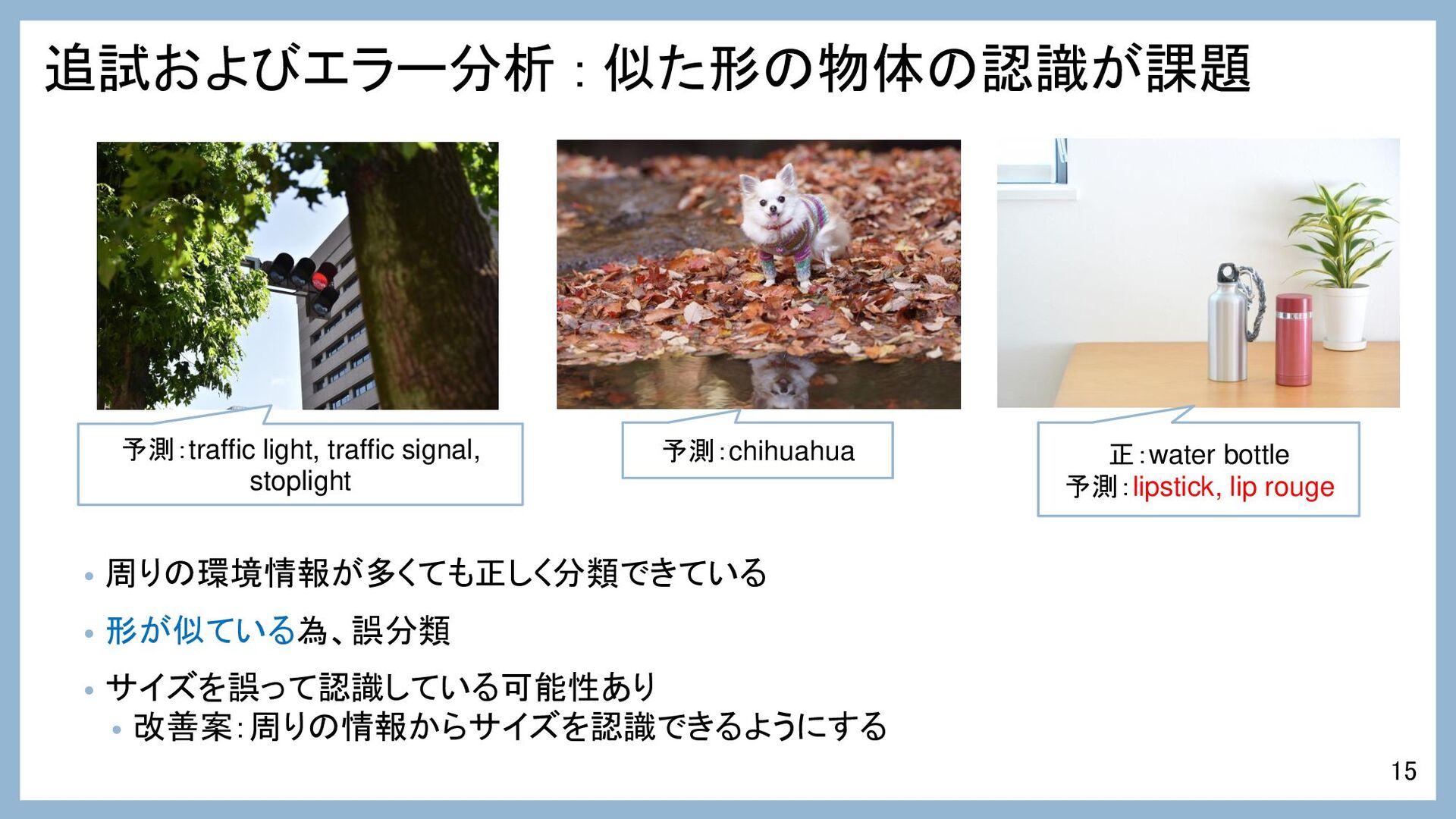
追試およびエラー分析 : 似た形の物体の認識が課題 • 周りの環境情報が多くても正しく分類できている • 形が似ている為、誤分類 • サイズを誤って認識している可能性あり •
改善案:周りの情報からサイズを認識できるようにする 15 予測:traffic light, traffic signal, stoplight 予測:chihuahua 正:water bottle 予測:lipstick, lip rouge
まとめ: • Transformerのtoken mixerを特定しない一般的な構造としてMetaFormerを提案 • token mixerを一番シンプルなpoolingにしたPoolFormerで実験 • PoolFormerは他のtoken mixerのモデルより効率よく同程度の精度
• Transformerが優れた結果を出せる理由は、MetaFormerであると実証 16
Appendix: PoolFormerのハイパーパラメータ 17
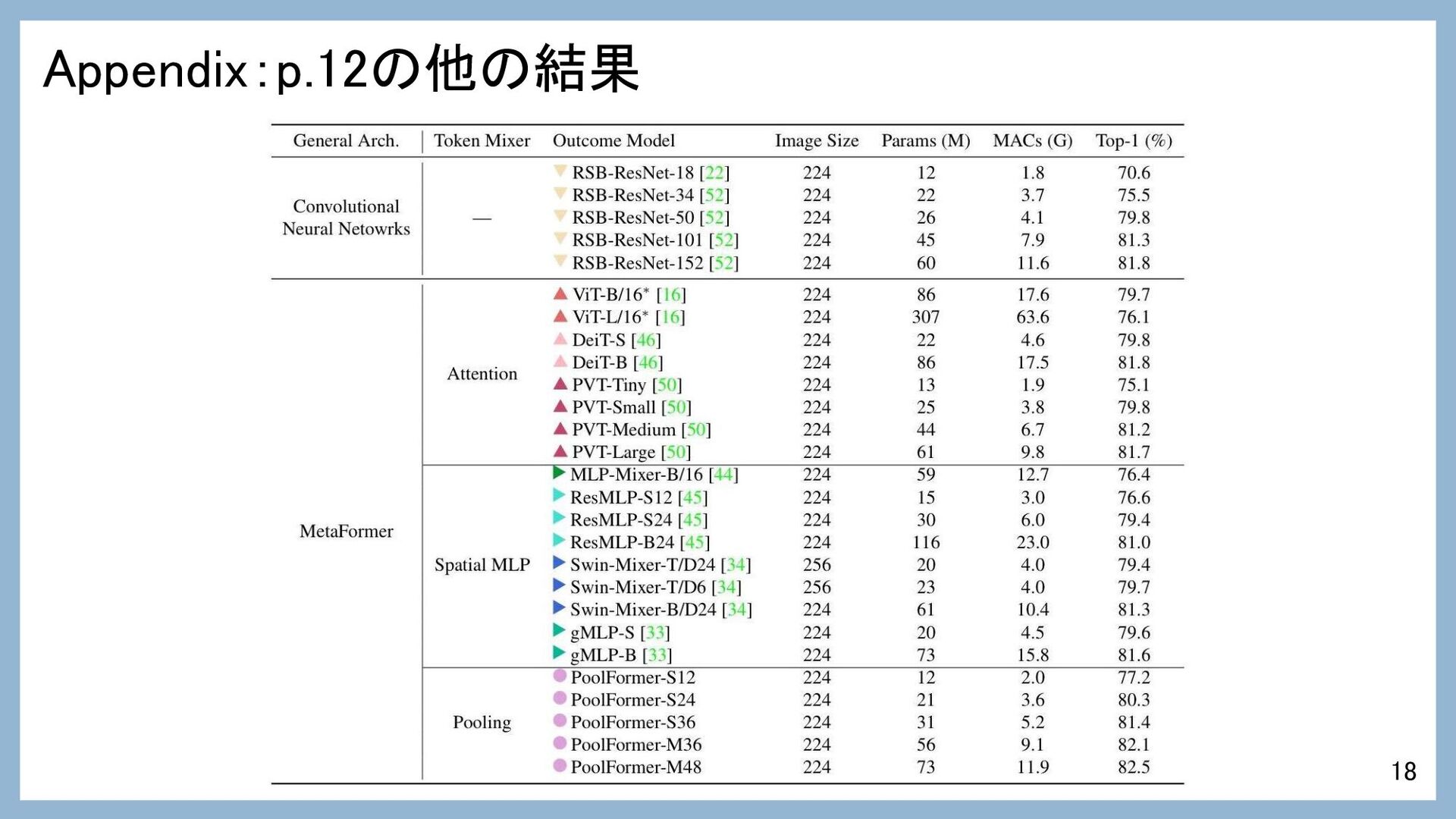
Appendix:p.12の他の結果 18
Appendix: 画像分類(追加) CNNよりも上回る精度を達成 • PoolFormer-S24 vs ResNet-34 • ほぼ同じパラメータ数 •
ほぼ同じ計算量 • 4.8%上回る精度 19
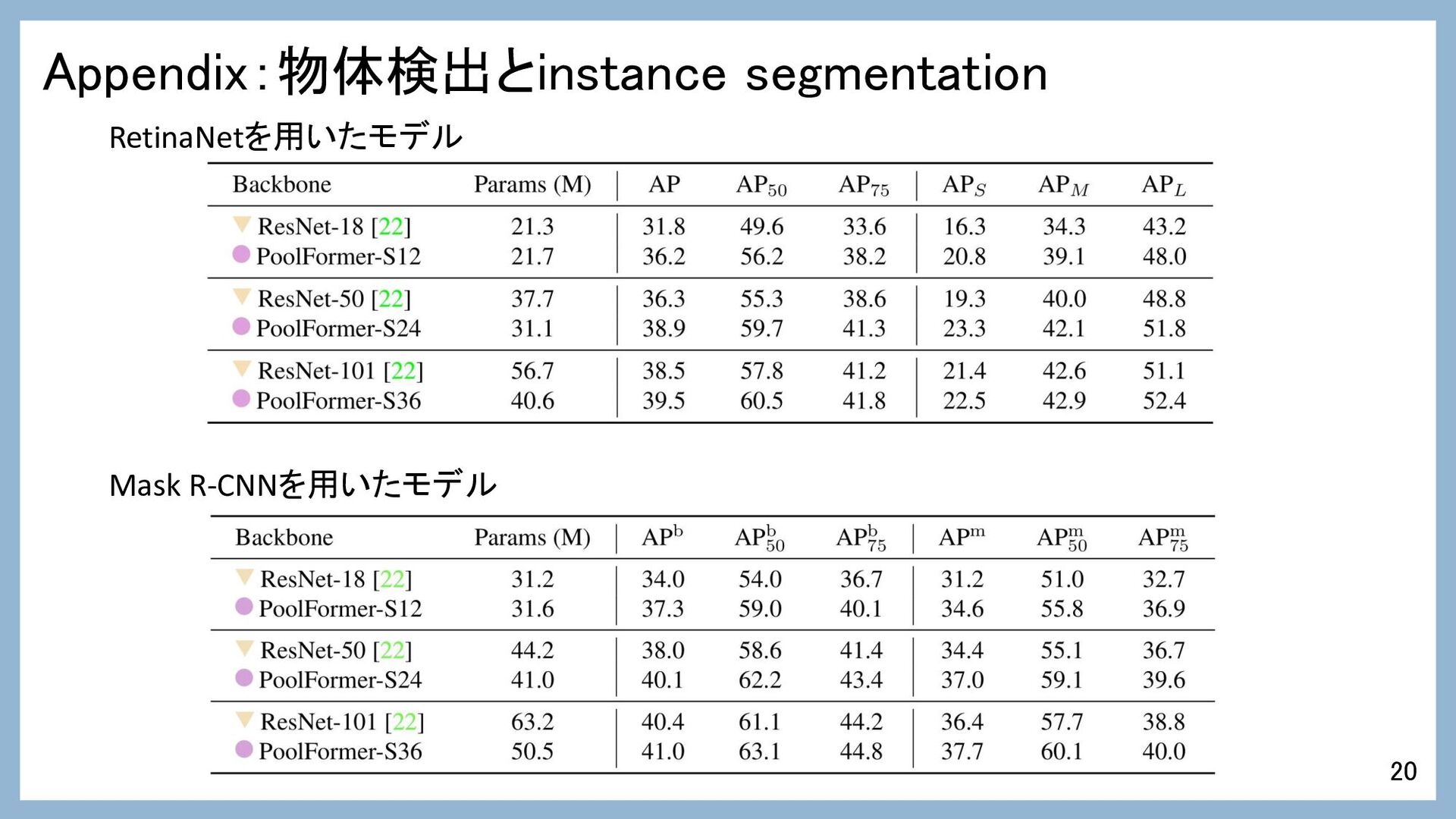
Appendix:物体検出とinstance segmentation 20 Mask R-CNNを用いたモデル RetinaNetを用いたモデル
Appendix: semantic segmentation 21
{kind=link}
{kind=link}
![• Transformer[Vaswani+, 17]は翻訳タスクで提案 • 自然言語処理タスクで人気に • Computer Visionタスクに適用 • Transformerのtoken](https://files.speakerdeck.com/presentations/1ab985f5daa544f88a41bb7c2d5d6d1e/slide_2.jpg){kind=link}
![関連研究: token mixerを改良したモデルが存在 4 モデル 特徴 ViT [Dosovitskiy+, ICPL21] •](https://files.speakerdeck.com/presentations/1ab985f5daa544f88a41bb7c2d5d6d1e/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}