Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] UNITER: UNiversal Image-TExt Rep...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
May 20, 2022
Technology
1.6k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] UNITER: UNiversal Image-TExt Representation Learning
Semantic Machine Intelligence Lab., Keio Univ.
PRO
May 20, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
76
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
85
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
96
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
シンガポールで登壇してきます
yama3133
0
300
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
300
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
450
kaonavi Tech Night#1
kaonavi
0
130
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
430
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
人とエージェントが高め合う協業設計
kintotechdev
0
450
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
970
世界、断片、モデル。そして理解
ardbeg1958
1
140
実践!既存 Project への AI-Driven Development 適用〜 一ヶ月で Project 唯一のフロントエンドエンジニアを作り出せ〜
lycorptech_jp
PRO
0
360
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
300
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
560
Featured
See All Featured
Leo the Paperboy
mayatellez
8
1.9k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
350
Crafting Experiences
bethany
1
230
30 Presentation Tips
portentint
PRO
1
350
Typedesign – Prime Four
hannesfritz
42
3.1k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
Designing for humans not robots
tammielis
254
26k
Side Projects
sachag
455
43k
Paper Plane
katiecoart
PRO
2
52k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
360
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Transcript
慶應義塾大学 杉浦孔明研究室 是方諒介 UNITER: UNiversal Image-TExt Representation Learning Yen-Chun Chen,
Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, Jingjing Liu (Microsoft Dynamics 365 AI Research) ECCV 2020 Chen, Yen-Chun, et al. "UNITER: UNiversal Image-TExt Representation Learning." ECCV 2020.
概要 背景 ✓ 画像と言語の汎用的な共同表現の需要 提案 ✓ transformerを中核とした大規模な事前学習済みモデル ✓ 4種の自己教師あり事前学習タスクで共同表現を学習 結果
✓ fine-tuningにより、6種のタスクでSOTAを達成 2
背景:画像と言語の汎用的な共同表現の需要 ◼ Vision and Language (V&L) において、画像・言語間の関係性の学習は必須 ◼ 一般に、共同表現は各タスクに特化 タスク間で共有できず不便
3 Model Task MCB [Fukui+ EMNLP17] ・Visual Question Answering (VQA) BAN [Kim+ NeurIPS18] SCAN [Lee+ ECCV18] ・Image-Text Retrieval ・Referring Expression Comprehension MAttNet [Yu+ CVPR18] 欠点:学習された表現はタスクに強く依存 既存モデル例 MCB
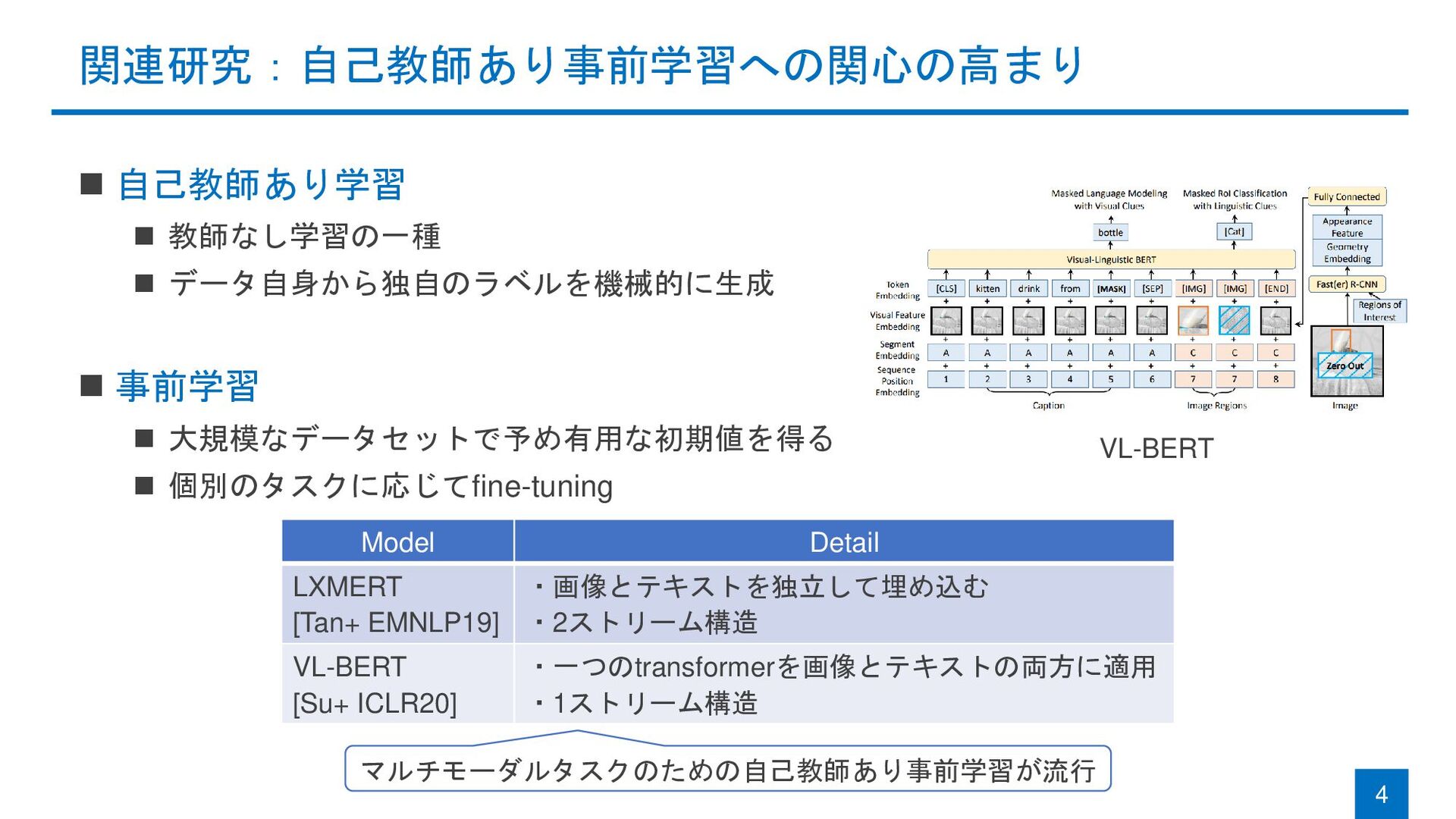
関連研究:自己教師あり事前学習への関心の高まり ◼ 自己教師あり学習 ◼ 教師なし学習の一種 ◼ データ自身から独自のラベルを機械的に生成 ◼ 事前学習 ◼
大規模なデータセットで予め有用な初期値を得る ◼ 個別のタスクに応じてfine-tuning 4 Model Detail LXMERT [Tan+ EMNLP19] ・画像とテキストを独立して埋め込む ・2ストリーム構造 VL-BERT [Su+ ICLR20] ・一つのtransformerを画像とテキストの両方に適用 ・1ストリーム構造 マルチモーダルタスクのための自己教師あり事前学習が流行 VL-BERT
提案手法:UNITER (UNiversal Image-TExt Representation) ◼ transformer [Vaswani+ NeurIPS17] を中核とした事前学習済みモデル 1.
Image Embedder:画像特徴, 領域検出 2. Text Embedder:言語表現 3. Transformer:画像と言語の一般化可能な共同表現を学習 ◼ 4種の自己教師あり事前学習 1. Masked Language Modeling 2. Masked Region Modeling 3. Image-Text Matching 4. Word-Region Alignment 5
transformerへの入力:画像・テキストを埋め込み表現に変換 ◼ Image Embedder:Faster R-CNN [Ren+ NeurIPS15] で物体検出 ◼ 以下2つを「FC層
結合 正規化」で変換 1. 領域の特徴:ROI-pool特徴 2. 領域の位置:7次元ベクトル [𝑥1 , 𝑦1 , 𝑥2 , 𝑦2 , 𝑤, ℎ, 𝑤 × ℎ] ◼ Text Embedder:BERT [Devlin+ 18] と同様にWordPieceでトークン化 ◼ 以下2つを「結合 正規化」で変換 1. 単語埋め込み 2. 位置埋め込み 6
1. Masked Language Modeling (MLM):マスクされた単語を予測 ◼ 入力単語の15%に対して以下の処理 ◼ 80%:[MASK]に置換 ◼
10%:ランダムな単語に置換 ◼ 10%:そのまま ◼ 非マスク単語・画像領域から予測 ◼ 負の対数尤度を最小化 7 ℒMLM 𝜃 = −𝔼 𝐰,𝐯 ~𝐷 log 𝑃𝜃 (𝐰𝐦 |𝐰∖𝐦 , 𝐯) 𝐰𝐦 :マスクされた単語 𝐰∖𝐦 :それ以外の単語 𝐯 = {𝐯1 , … , 𝐯𝐾 }:画像領域 dog 例:[MASK]をdogと予測 MASKトークンに置換
2. Masked Region Modeling (MRM):マスクされた画像領域を予測 ◼ 入力画像領域の15%に対して以下の処理 ◼ 80%:マスク(0に置換) ◼
10%:ランダムな領域に置換 ◼ 10%:そのまま ◼ 非マスク領域・テキストから予測 ◼ 𝑓𝜃 を最小化 3パターンを提案 8 ℒMRM 𝜃 = 𝔼 𝐰,𝐯 ~𝐷 𝑓𝜃 (𝐯𝐦 |𝐯∖𝐦 , 𝐰) マスク処理 例:犬の領域を予測 𝐯𝐦 :マスクされた画像領域 𝐯∖𝐦 :それ以外の画像領域 𝐰 = {𝐰1 , … , 𝒘𝐾 }:テキスト
2. 3パターンのMRM (1/2):マスク領域の特徴量へ回帰 ① Masked Region Feature Regression (MRFR) ◼
マスク領域に対するtransformerの出力 𝐯𝐦 (𝑖) をFC層で領域特徴 ℎ𝜃 𝐯𝐦 𝑖 へ変換 ◼ 領域特徴の正解 𝑟(𝐯𝐦 (𝑖)) はROI-pool特徴 ◼ L2回帰 9 𝑓𝜃 𝐯𝐦 𝐯∖𝐦 , 𝐰 = Σ𝑖=1 𝑀 ℎ𝜃 𝐯𝐦 𝑖 − 𝑟 𝐯𝐦 𝑖 2 2 Faster R-CNNの処理過程で得たもの
2. 3パターンの MRM (2/2):マスク領域のクラスへ分類 ② Masked Region Classification (MRC) ◼
𝐯𝐦 (𝑖) をFC層・softmax関数で領域のクラス予測分布 𝑔𝜃 𝐯𝐦 𝑖 へ変換 ◼ 「正解 𝑐 𝐯𝐦 𝑖 はFaster R-CNNの検出結果(one-hotベクトル)」と仮定 ◼ 両者の交差エントロピー誤差(CE)を算出 ③ Masked Region Classification with KL-Divergence (MRC-kl) ◼ ②の仮定は領域に真の正解ラベルが存在しないことに反するため、一部を変更 ◼ one-hotベクトル 𝑐 𝐯𝐦 𝑖 予測確率分布 ǁ 𝑐 𝐯𝐦 𝑖 ◼ 交差エントロピー誤差 KLダイバージェンス 10 𝑓𝜃 𝐯𝐦 𝐯∖𝐦 , 𝐰 = Σ𝑖=1 𝑀 CE 𝑐 𝐯𝐦 𝑖 , 𝑔𝜃 𝐯𝐦 𝑖 𝑓𝜃 𝐯𝐦 𝐯∖𝐦 , 𝐰 = Σ𝑖=1 𝑀 𝐷𝐾𝐿 ǁ 𝑐 𝐯𝐦 𝑖 ‖ 𝑔𝜃 𝐯𝐦 𝑖
MLM, MRM における工夫:画像・言語の片方だけマスク 11 従来:Joint Random Masking ◼ 対応する画像領域と単語が同時にマスクされる可能性 共同表現の学習に悪影響
提案:Conditional Masking ◼ 画像領域か単語のどちらかが観測できる条件下でのみ、もう一方をマスク処理
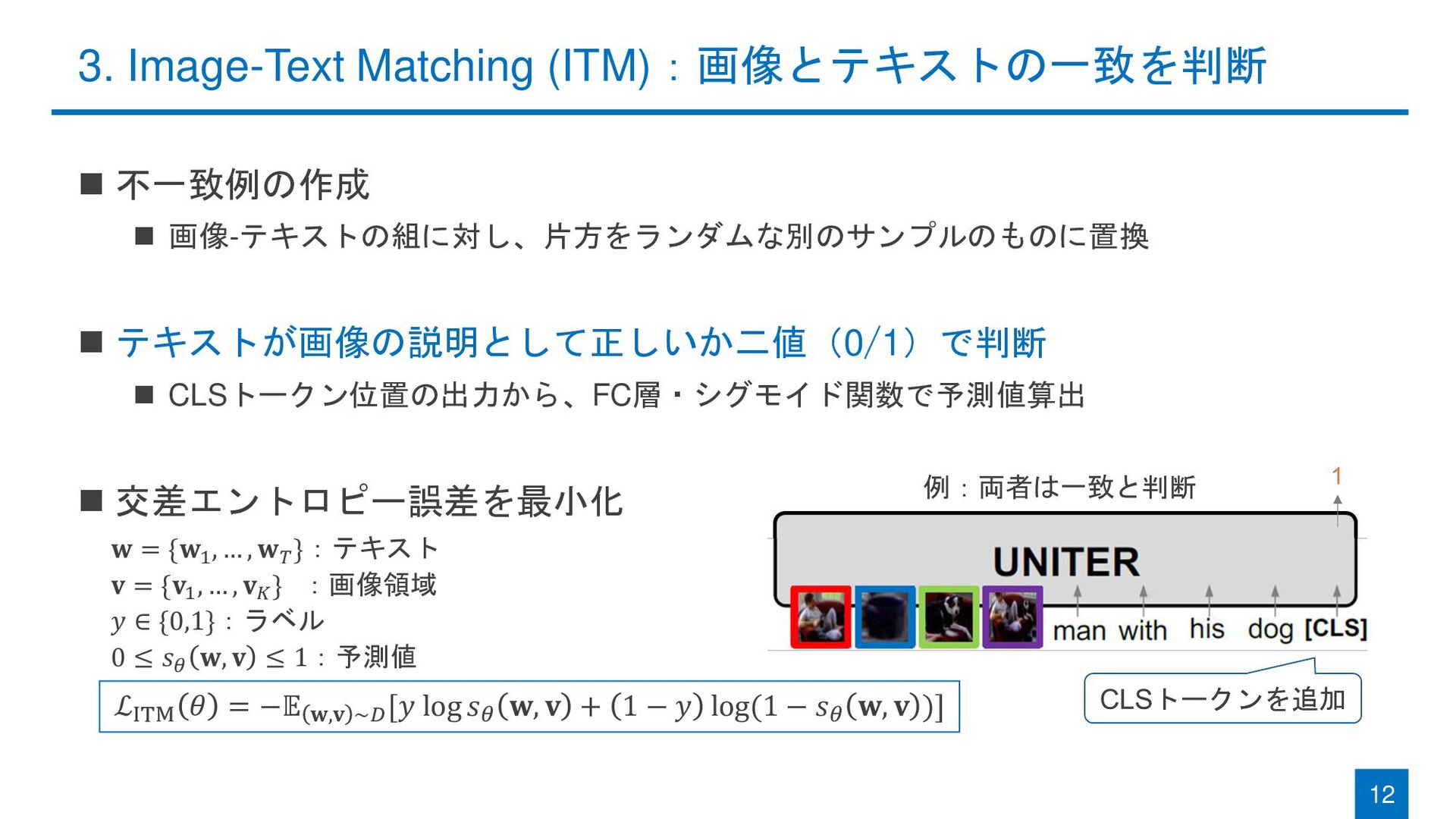
◼ 不一致例の作成 ◼ 画像-テキストの組に対し、片方をランダムな別のサンプルのものに置換 ◼ テキストが画像の説明として正しいか二値(0/1)で判断 ◼ CLSトークン位置の出力から、FC層・シグモイド関数で予測値算出 ◼ 交差エントロピー誤差を最小化
3. Image-Text Matching (ITM):画像とテキストの一致を判断 12 ℒITM 𝜃 = −𝔼 𝐰,𝐯 ~𝐷 [𝑦 log 𝑠𝜃 𝐰, 𝐯 + 1 − 𝑦 log(1 − 𝑠𝜃 𝐰, 𝐯 )] 𝐰 = {𝐰1 , … , 𝐰𝑇 }:テキスト 𝐯 = {𝐯1 , … , 𝐯𝐾 } :画像領域 𝑦 ∈ {0,1}:ラベル 0 ≤ 𝑠𝜃 𝐰, 𝐯 ≤ 1:予測値
◼ 画像領域と単語の対応度合いを学習 ◼ それぞれ分布 𝝁, 𝝂 とみなし、最適輸送問題(OT [Monge 1781] )に落とし込む
◼ 総輸送コストを最小化 4. Word-Region Alignment (WRA):画像とテキストのマッチング最適化 13 ℒWRA 𝜃 = 𝒟𝑜𝑡 (𝝁, 𝝂) = min 𝐓∈𝛱(𝒂,𝒃) Σ𝑖=1 𝑇 Σ𝑗=1 𝐾 𝐓𝑖𝑗 ⋅ 𝑐(𝐰𝑖 , 𝐯𝑗 ) 𝐓 ∈ ℝ𝑇×𝐾:OTの解(最適輸送プラン) 𝑐(𝐰𝑖 , 𝐯𝑗 ) :コサイン類似度
◼ 4種の大規模データセットで事前学習 ◼ COCO, Visual Genome, Conceptual Captions, SBU Captions
◼ 6種のタスクに応じてfine-tuning ◼ UNITER-largeモデルは、 全てのベンチマークで他に勝る ◼ Base:12層 / Large:24層 定量的結果:6種のV&LタスクでSOTAを達成 14 ① ② ③ ④ ⑤ ⑥
Ablation Study:全ての事前学習タスクが有効 ◼ 4種のタスクで「事前学習タスク」について評価 ◼ 考察 ✓ 全事前学習タスクが有効 ✓ MRM3種の内では、
MRC-klが最も優位 ✓ Conditional Maskingも 精度向上に寄与 15 全タスクの総和
まとめ 16 背景 ✓ 画像と言語の汎用的な共同表現の需要 提案 ✓ transformerを中核とした大規模な事前学習済みモデル ✓ 4種の自己教師あり事前学習タスクで共同表現を学習
結果 ✓ fine-tuningにより、6種のタスクでSOTAを達成
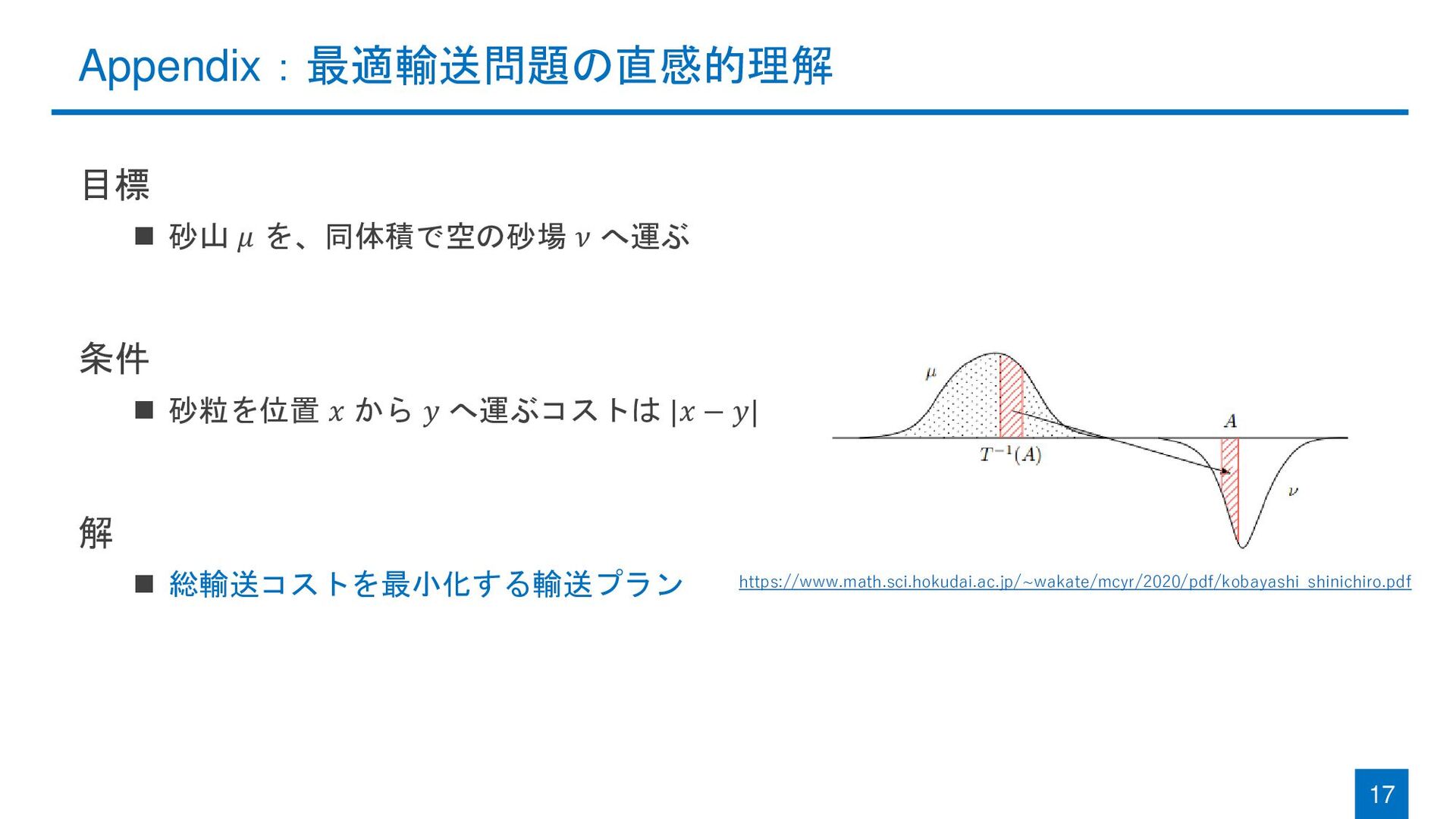
Appendix:最適輸送問題の直感的理解 17 https://www.math.sci.hokudai.ac.jp/~wakate/mcyr/2020/pdf/kobayashi_shinichiro.pdf 目標 ◼ 砂山 𝜇 を、同体積で空の砂場 𝜈 へ運ぶ
条件 ◼ 砂粒を位置 𝑥 から 𝑦 へ運ぶコストは |𝑥 − 𝑦| 解 ◼ 総輸送コストを最小化する輸送プラン
Appendix:SOTAを達成した6種のV&Lタスク (1/3) ① Visual Question Answering (VQA) - 画像 +
それに対する質問 → 質問の答え ② Visual Commonsense Reasoning (VCR) - 画像 + それに対する質問 → 質問の答え + 根拠 18 https://openaccess.thecvf.com/content_CVPR_2019/papers/Zellers_From_Recognition_to_Cognition_Visual_Commonsense_Reasoning_CVPR_2019_paper.pdf 入力 → 出力
Appendix:SOTAを達成した6種のV&Lタスク (2/3) ③ Natural Language for Visual Reasoning for Real
2 (NLVR2) - 画像のペア + 説明文 → 説明文が正しいかどうか ④ Visual Entailment (SNLI-VE) - 画像 + 説明文 → 画像が説明文を含意しているか3段階評価 19 https://lil.nlp.cornell.edu/nlvr/NLVR2BiasAnalysis.html 入力 → 出力
Appendix:SOTAを達成した6種のV&Lタスク (3/3) ⑤ Image-Text Retrieval (IR, TR) - クエリテキスト →
ターゲット画像 - クエリ画像 → ターゲットテキスト ⑥ Referring Expression Comprehension - 参照表現 + 画像領域候補 → 指し示す画像領域 20 入力 → 出力
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![提案手法:UNITER (UNiversal Image-TExt Representation) ◼ transformer [Vaswani+ NeurIPS17] を中核とした事前学習済みモデル 1.](https://files.speakerdeck.com/presentations/f48d829d5bbb41fdadd96044c2e45025/slide_4.jpg){kind=link}
![transformerへの入力:画像・テキストを埋め込み表現に変換 ◼ Image Embedder:Faster R-CNN [Ren+ NeurIPS15] で物体検出 ◼ 以下2つを「FC層](https://files.speakerdeck.com/presentations/f48d829d5bbb41fdadd96044c2e45025/slide_5.jpg){kind=link}
![1. Masked Language Modeling (MLM):マスクされた単語を予測 ◼ 入力単語の15%に対して以下の処理 ◼ 80%:[MASK]に置換 ◼](https://files.speakerdeck.com/presentations/f48d829d5bbb41fdadd96044c2e45025/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![◼ 画像領域と単語の対応度合いを学習 ◼ それぞれ分布 𝝁, 𝝂 とみなし、最適輸送問題(OT [Monge 1781] )に落とし込む](https://files.speakerdeck.com/presentations/f48d829d5bbb41fdadd96044c2e45025/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}