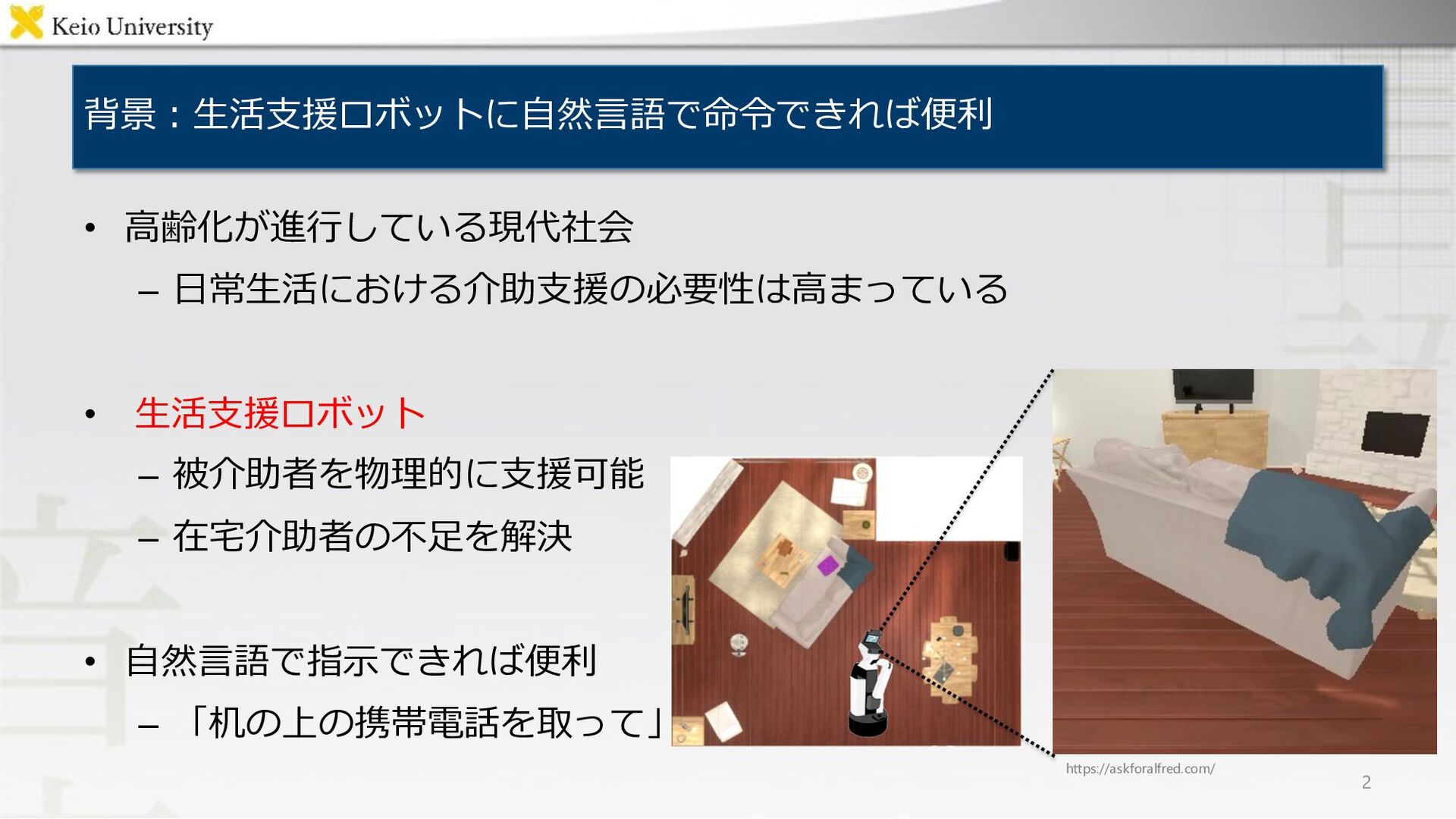
– 複数のサブゴールが逐次的に設定、それぞれに命令⽂が存在 • 問題点︓物体を運ぶ際、カメラ画像に空中に浮かんだ物体が表⽰され不⾃然 18 Goal︓Move a book from a desk to a sofa. Low-level instruction “Turn around and walk to the book on the desk.” “Pick up the book from the desk.” “Turn around and walk to the sofa on the left.” “Put the book on the middle of the sofa, to the right of the keys.” https://askforalfred.com/ 物体運搬時の画像
19 “Pick up the book from the desk.” Goal︓Move a book from a desk to a sofa. Low-level instruction “Turn around and walk to the book on the desk.” “Pick up the book from the desk.” “Turn around and walk to the sofa on the left.” “Put the book on the middle of the sofa, to the right of the keys.” https://askforalfred.com/ Name Image Instruction Vocabulary size Average sentence length ALFRED-fetch 3428 3227 884 12.5
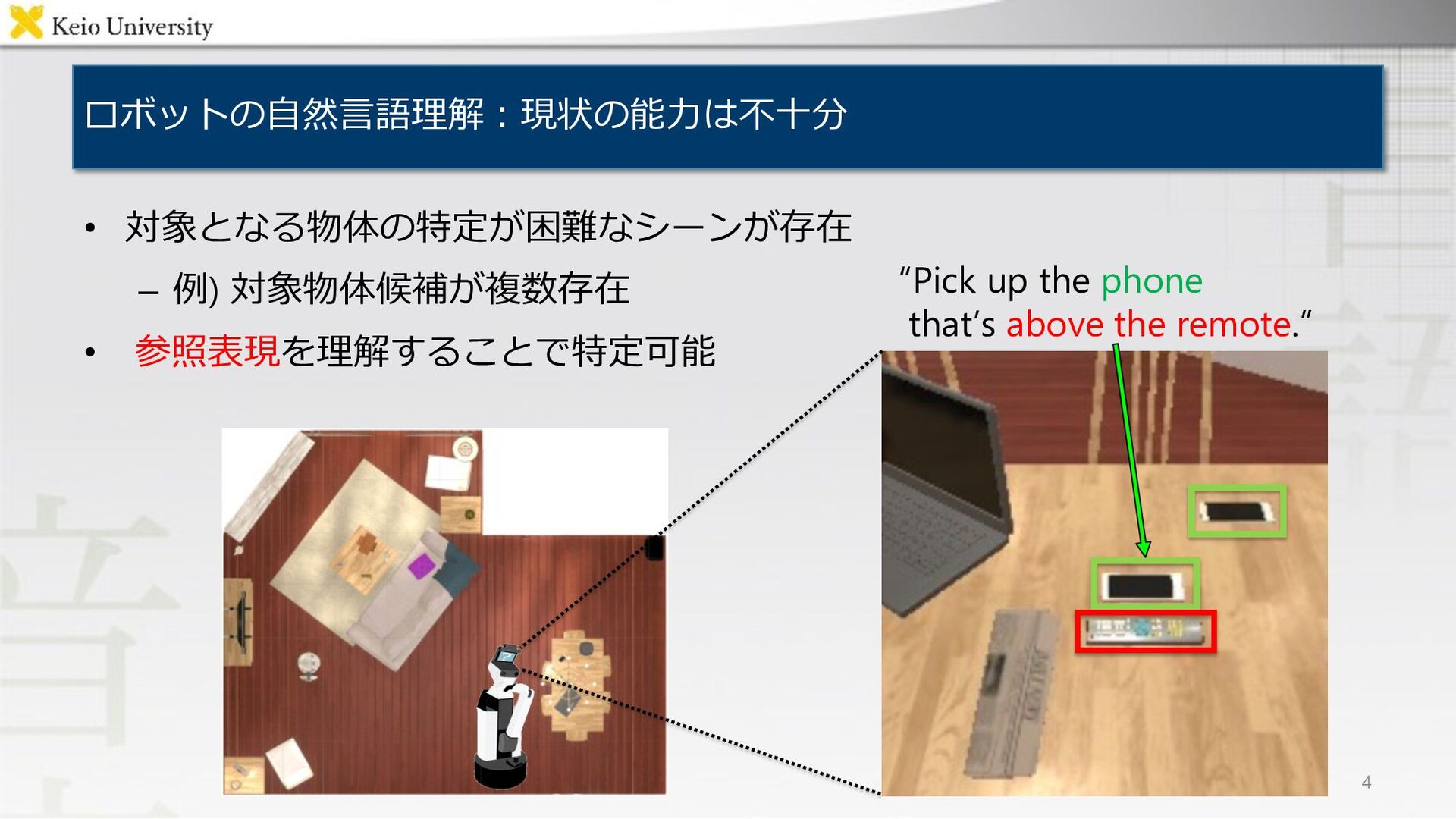
comprehension errors for handling visual and linguistic information 73 RE Reference/Exophora resolution errors for linguistic information 30 SR The candidate region was very small 7 SO Confusion with similar objects in the image 6 OE Other errors 3 Total - 119
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
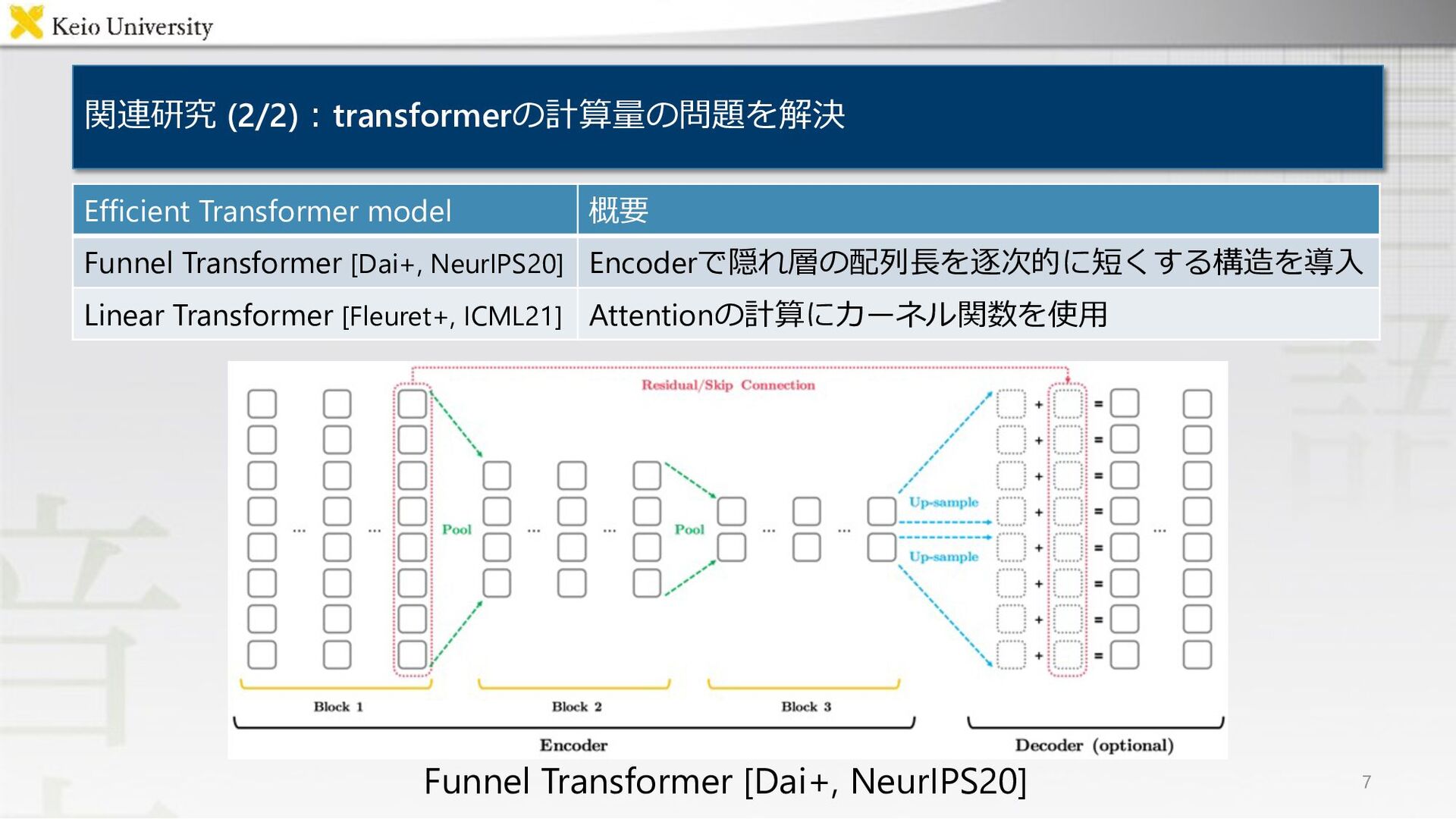
![関連研究 (1/2)︓既存⼿法は計算コストが⾼く,精度が不⼗分 • 6 MLU-FI model 概要 MTCM [Magassouba+, IROS19]](https://files.speakerdeck.com/presentations/4f9b75bf79084339b17dd657399e12ab/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
![Image Embedder︓画像の埋め込み処理を実⾏ • 𝑥!"#$ , 𝑥$%& ︓Faster R-CNN [Ren+, PAMI16]より抽出した領域の特徴量](https://files.speakerdeck.com/presentations/4f9b75bf79084339b17dd657399e12ab/slide_8.jpg){kind=link}
![Image Embedder︓画像の埋め込み処理を実⾏ • 𝑥!"#$ , 𝑥$%& ︓Faster R-CNN [Ren+, PAMI16]より抽出した領域の特徴量](https://files.speakerdeck.com/presentations/4f9b75bf79084339b17dd657399e12ab/slide_9.jpg){kind=link}
![Image Embedder︓画像の埋め込み処理を実⾏ • 𝑥!"#$ , 𝑥$%& ︓Faster R-CNN [Ren+, PAMI16]より抽出した領域の特徴量](https://files.speakerdeck.com/presentations/4f9b75bf79084339b17dd657399e12ab/slide_10.jpg){kind=link}
![Image Embedder︓画像の埋め込み処理を実⾏ • 𝑥!"#$ , 𝑥$%& ︓Faster R-CNN [Ren+, PAMI16]より抽出した領域の特徴量](https://files.speakerdeck.com/presentations/4f9b75bf79084339b17dd657399e12ab/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ALFRED dataset の問題点︓物体操作において不⾃然な画像が存在 • ALFRED dataset [Shridhar+, CVPR20] – ⾃然⾔語による指⽰と⼀⼈称視点からエージェントの⾏動を学習](https://files.speakerdeck.com/presentations/4f9b75bf79084339b17dd657399e12ab/slide_17.jpg){kind=link}
{kind=link}
![定量的結果︓提案⼿法はベースライン⼿法を精度、学習時間で上回る • Binary Accuracy [%] ︓対象物体候補が対象物体か否かに関する精度 • Training Time [fps]︓学習において、1秒間で処理可能な画像の枚数](https://files.speakerdeck.com/presentations/4f9b75bf79084339b17dd657399e12ab/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![付録1︓Funnel Transformer [Dai+, NeurIPS20] • Transformerモデルの冗⻑性を検討、新たなコスト削減⼿法を提⽰ • シーケンスの⻑さを徐々に圧縮することで計算量を削減 – Encoder︓Poolingによってシーケンスを徐々に圧縮](https://files.speakerdeck.com/presentations/4f9b75bf79084339b17dd657399e12ab/slide_25.jpg){kind=link}
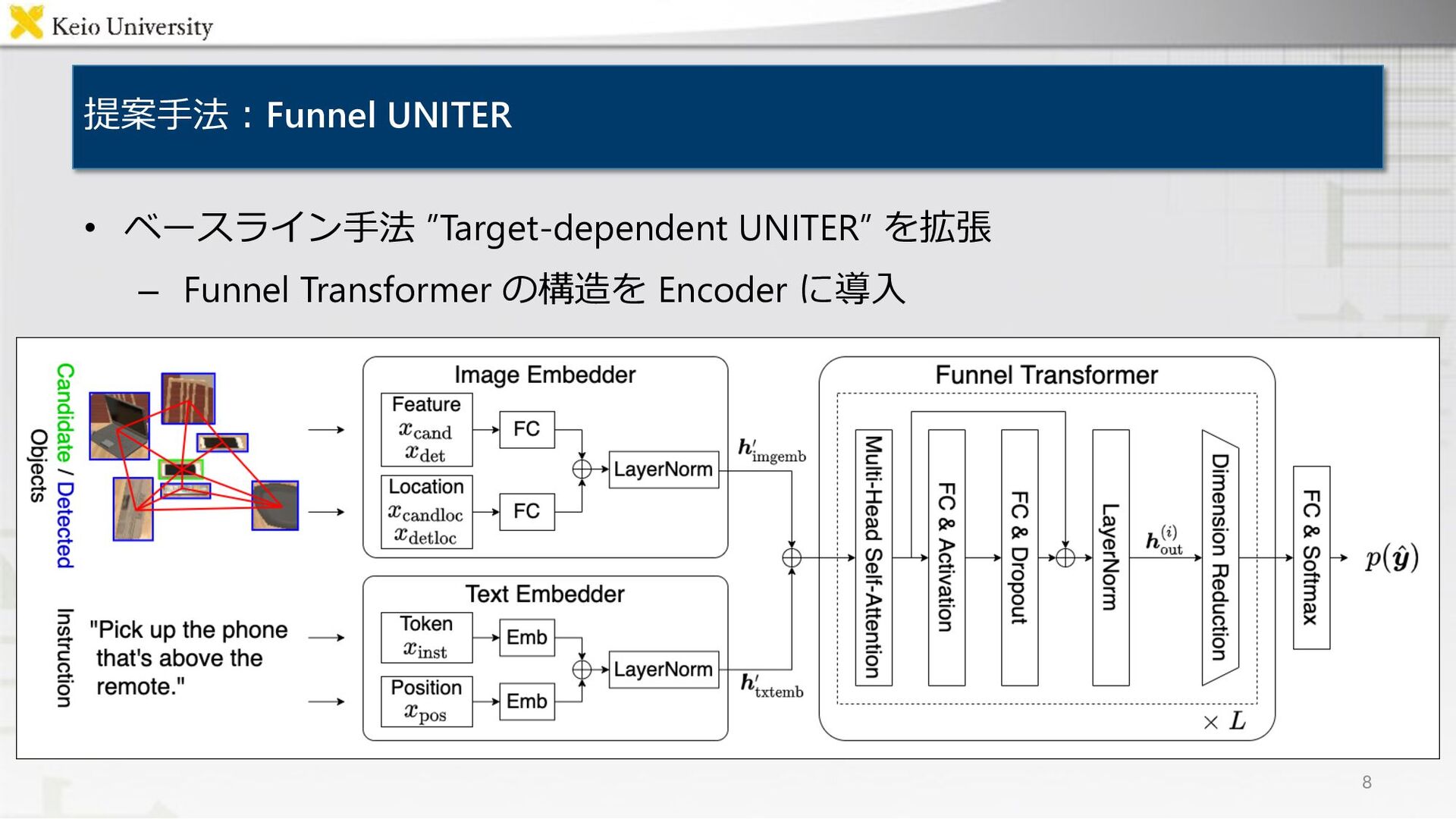
![付録2︓Target-dependent UNITER [Ishikawa+, IROS21] • 画像とテキストの共同理解にUNITER [Chen+, ECCV20]を採⽤ • 対象物体候補候補を⼊⼒として新たに導⼊](https://files.speakerdeck.com/presentations/4f9b75bf79084339b17dd657399e12ab/slide_26.jpg){kind=link}
{kind=link}