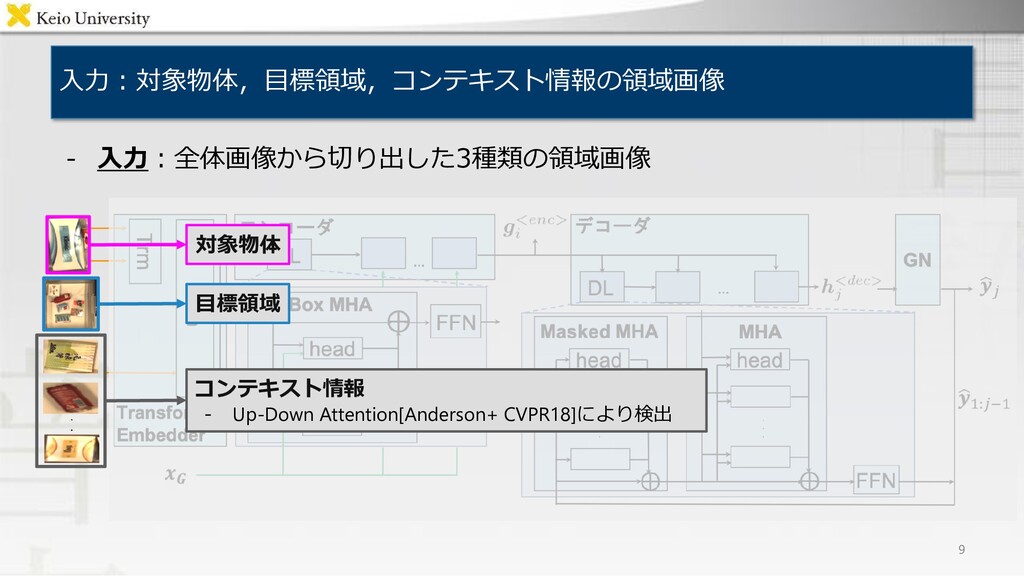
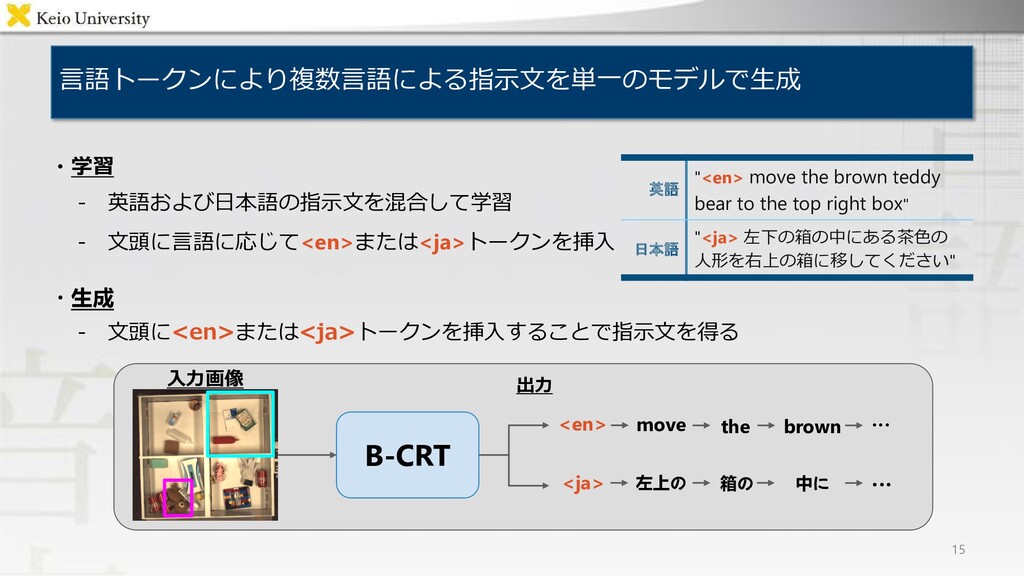
対象物体および目標領域についての物体操作指示文付与タスク • 出力:英語および日本語の物体操作指示文 英語 "move the brown teddy bear to the top right box" 日本語 "左下の箱の中にある茶色の人形を 右上の箱に移してください" • 入力:対象物体および目標領域を含む画像 入力例)
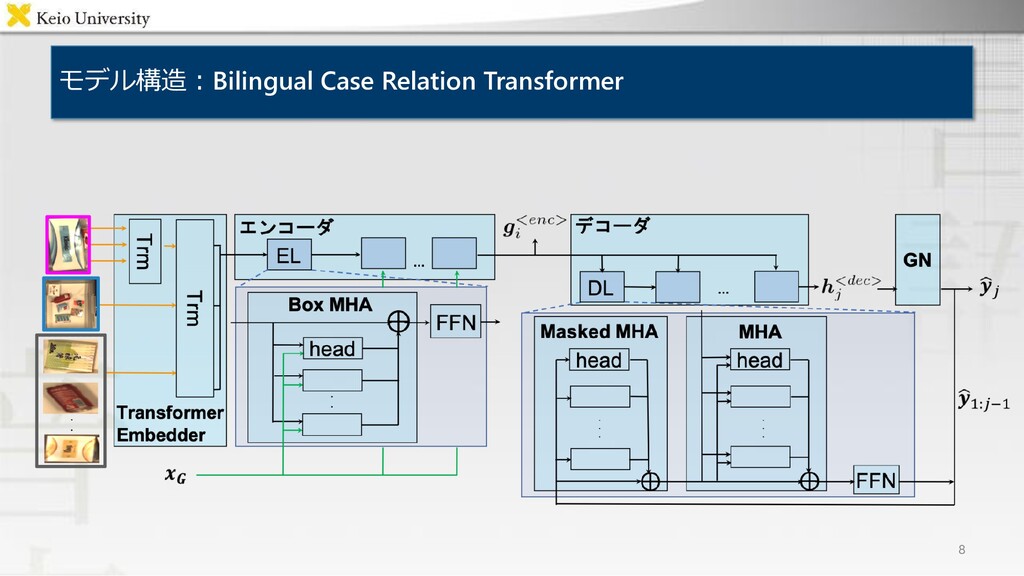
the brown teddy bear to the top right box" 日本語 "<ja> 左下の箱の中にある茶色の 人形を右上の箱に移してください" ・生成 - 文頭に<en>または<ja>トークンを挿入することで指示文を得る B-CRT 入力画像 <en> <ja> move 左上の ... 出力 the 箱の brown 中に ...
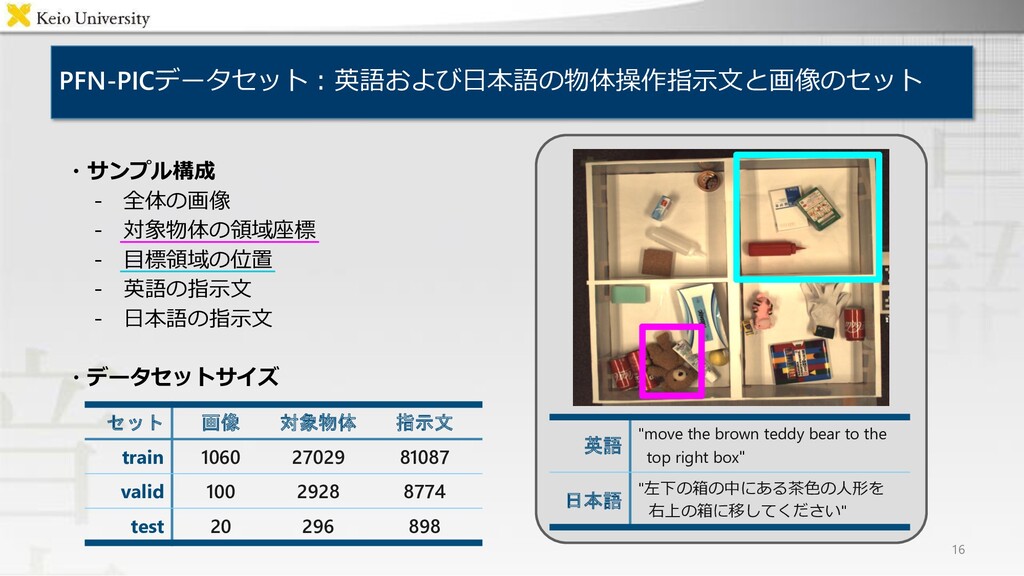
valid 100 2928 8774 test 20 296 898 英語 "move the brown teddy bear to the top right box" 日本語 "左下の箱の中にある茶色の人形を 右上の箱に移してください" ・サンプル構成 - 全体の画像 - 対象物体の領域座標 - 目標領域の位置 - 英語の指示文 - 日本語の指示文 ・データセットサイズ
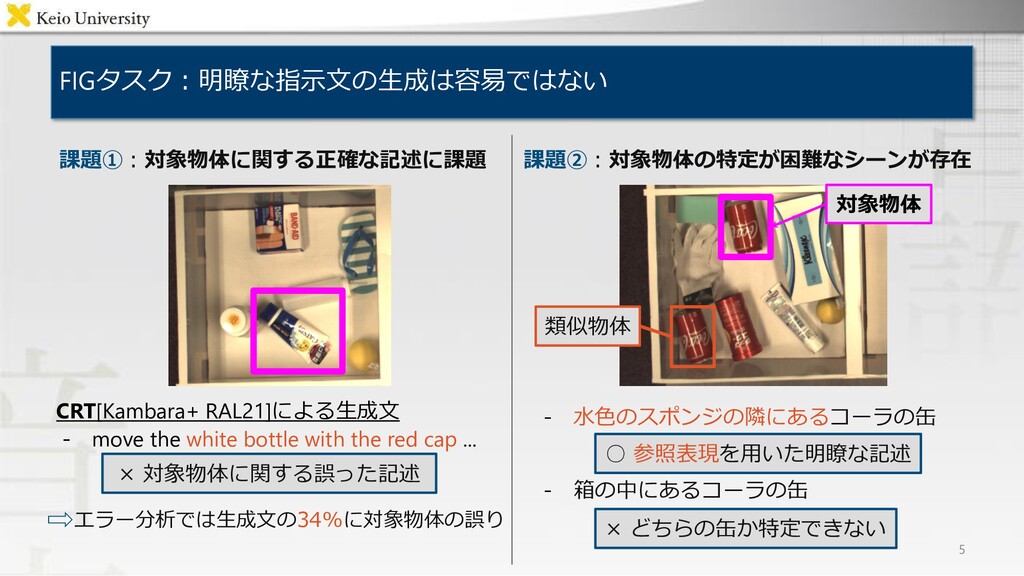
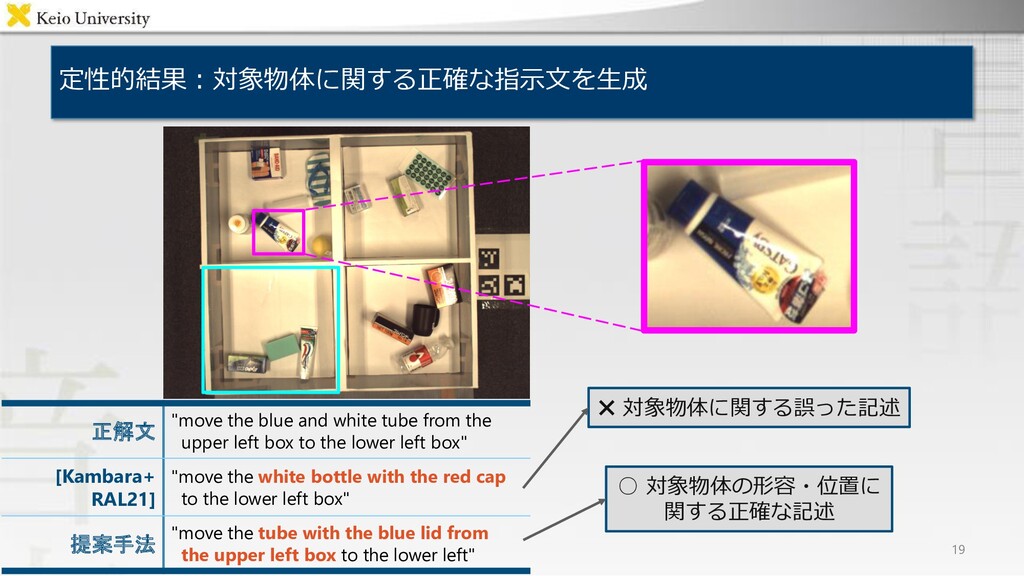
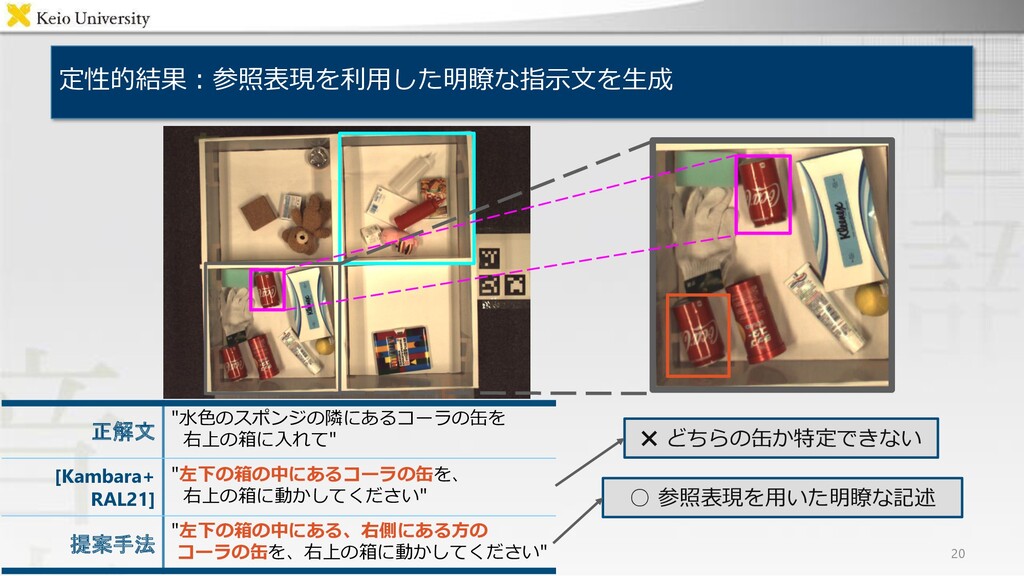
the upper left box to the lower left box" "水色のスポンジの隣にあるコーラの缶を 右上の箱に入れて" [Kambara+ RAL21] "move the white bottle with the red cap to the lower left box" "左下の箱の中にあるコーラの缶を、 右上の箱に動かしてください" 提案手法 "move the tube with the blue lid from the upper left box to the lower left" "左下の箱の中にある、右側にある方の コーラの缶を、右上の箱に動かしてください"
blue and white tube from the upper left box to the lower left box" [Kambara+ RAL21] "move the white bottle with the red cap to the lower left box" 提案手法 "move the tube with the blue lid from the upper left box to the lower left"
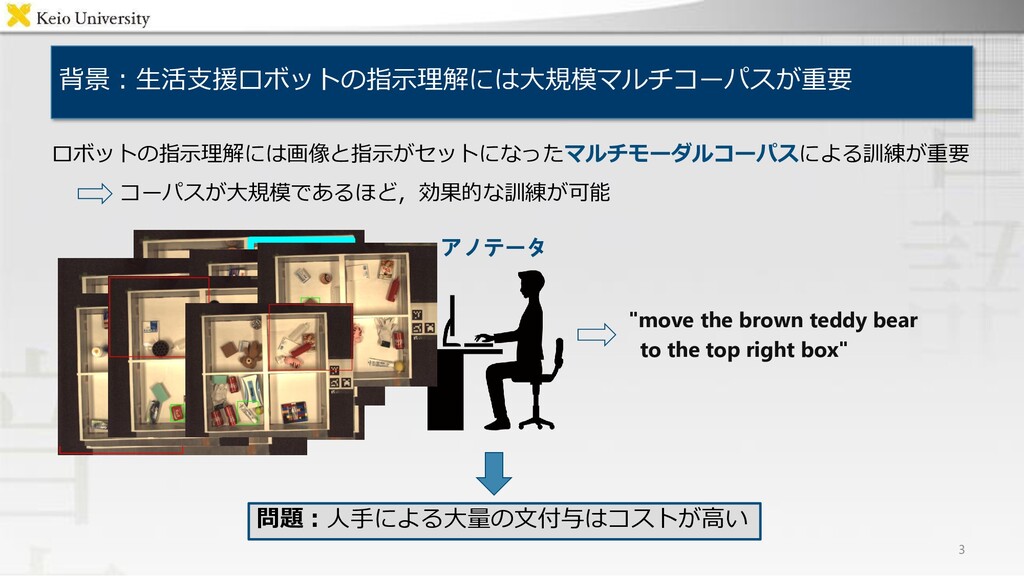
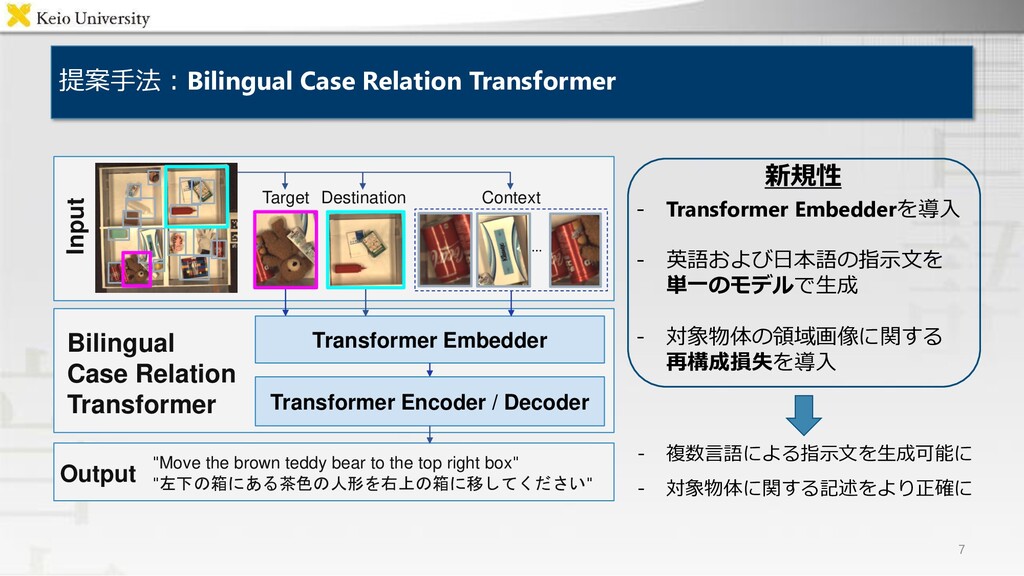
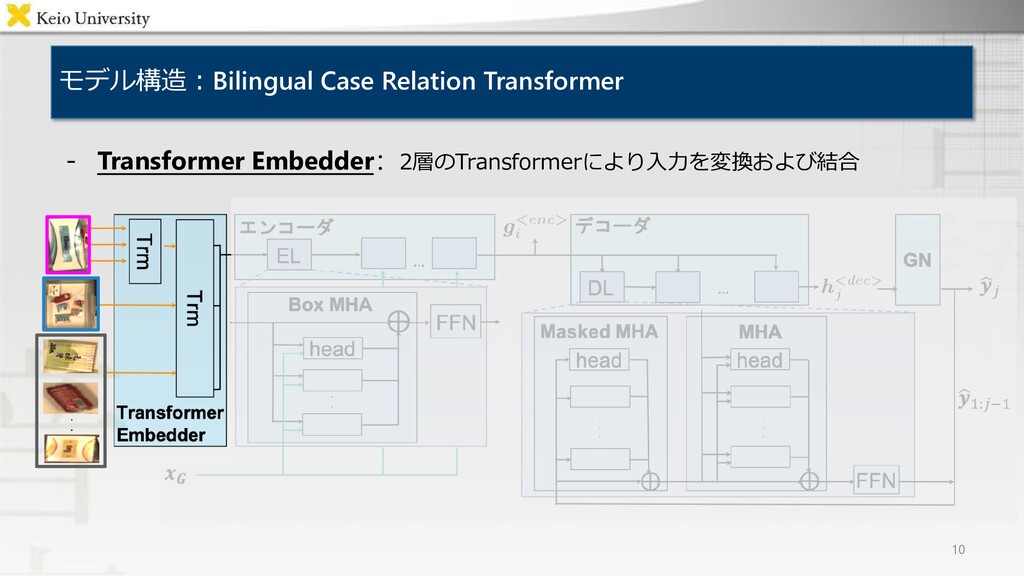
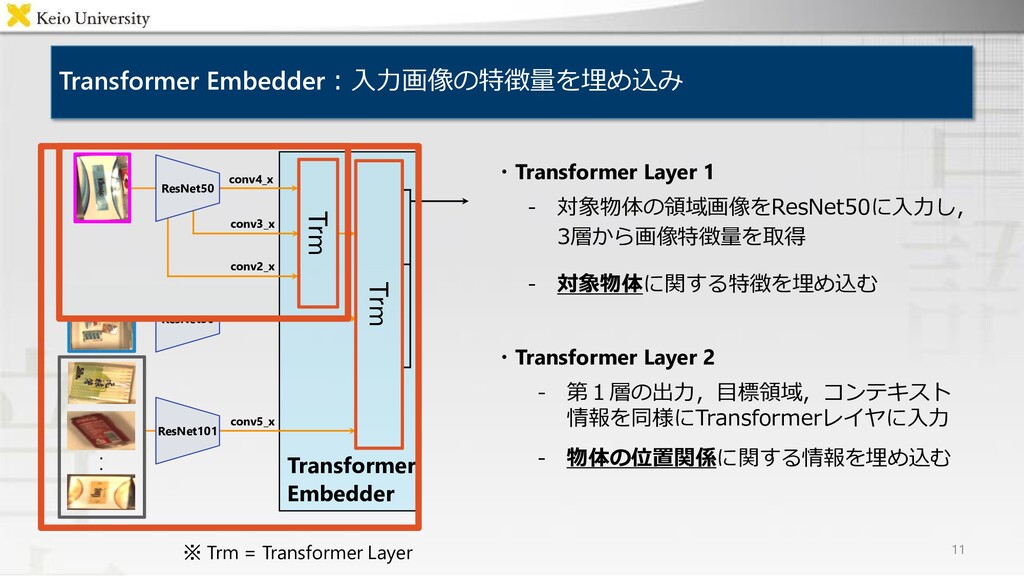
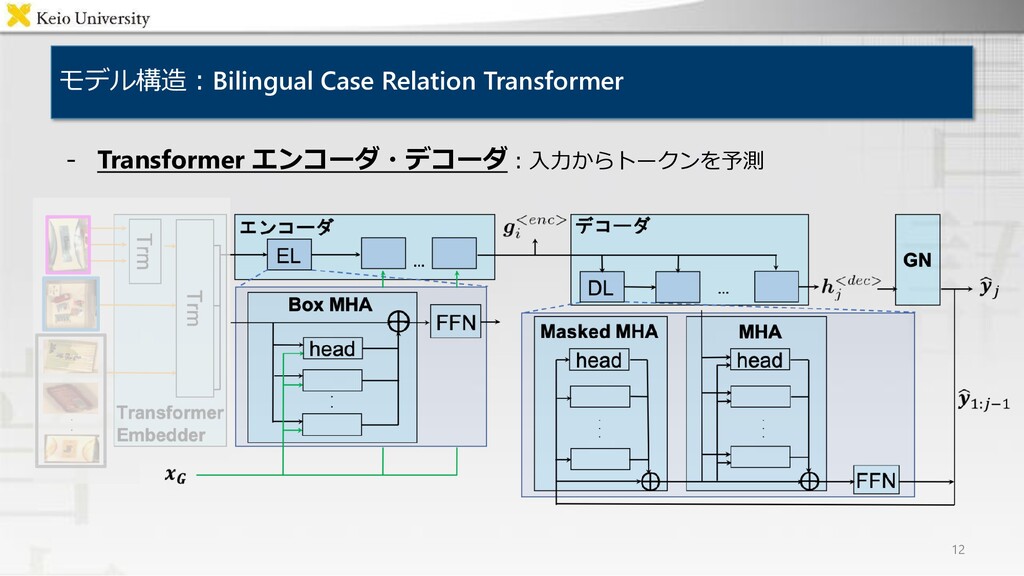
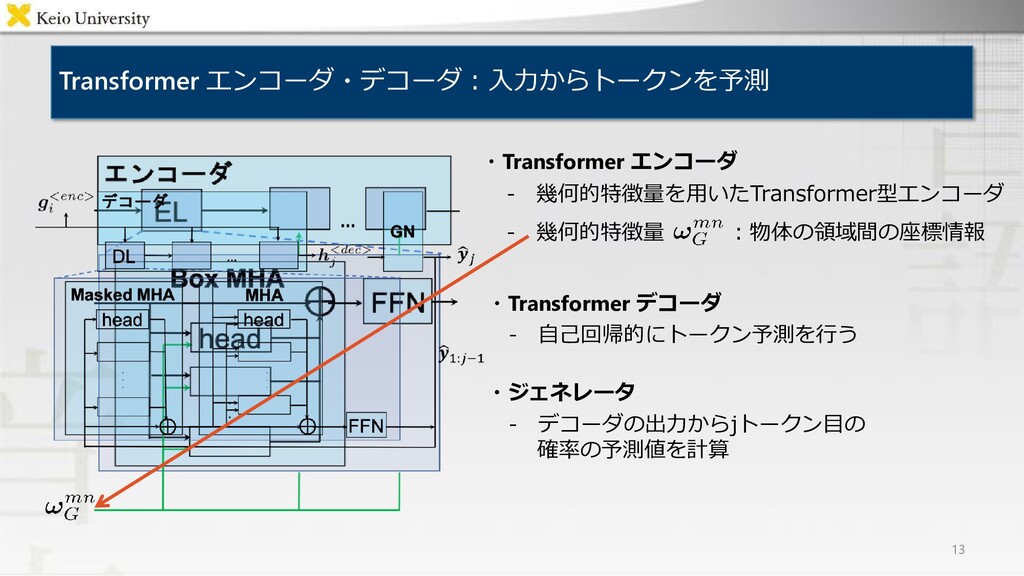
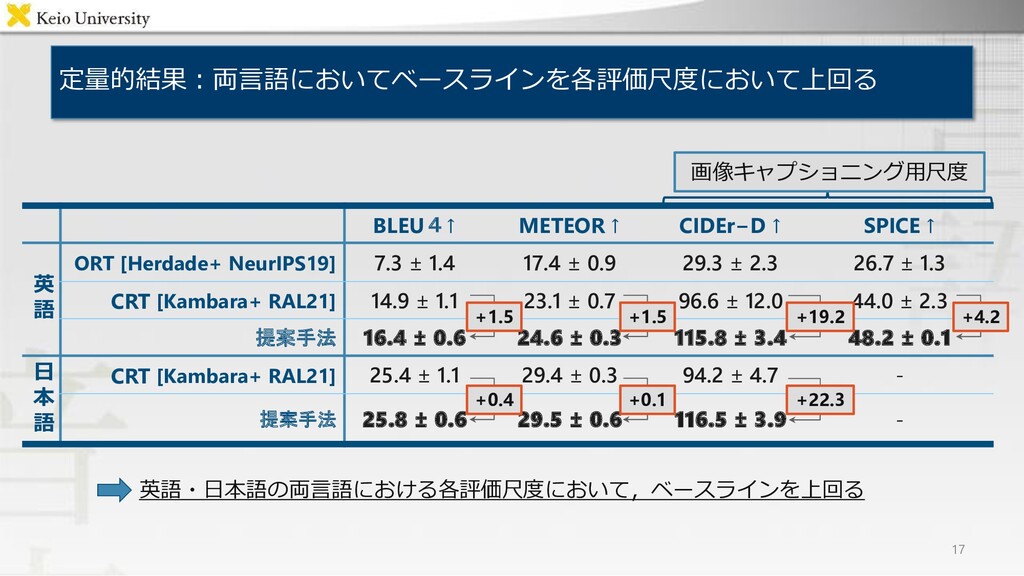
Encoder / Decoder "Move the brown teddy bear to the top right box" "左下の箱にある茶色の人形を右上の箱に移してください" Output Bilingual Case Relation Transformer ・背景 ・提案手法 ・結果 マルチモーダルデータセットのaugmentation 複数言語による物体操作指示文を単一のモデルで 生成するマルチモーダル言語生成モデル Bilingual Case Relation Transformer 各評価尺度においてベースライン手法を上回り, 被験者実験においても人間の付与した指示文に 近い品質の生成文を得ることを確認
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}