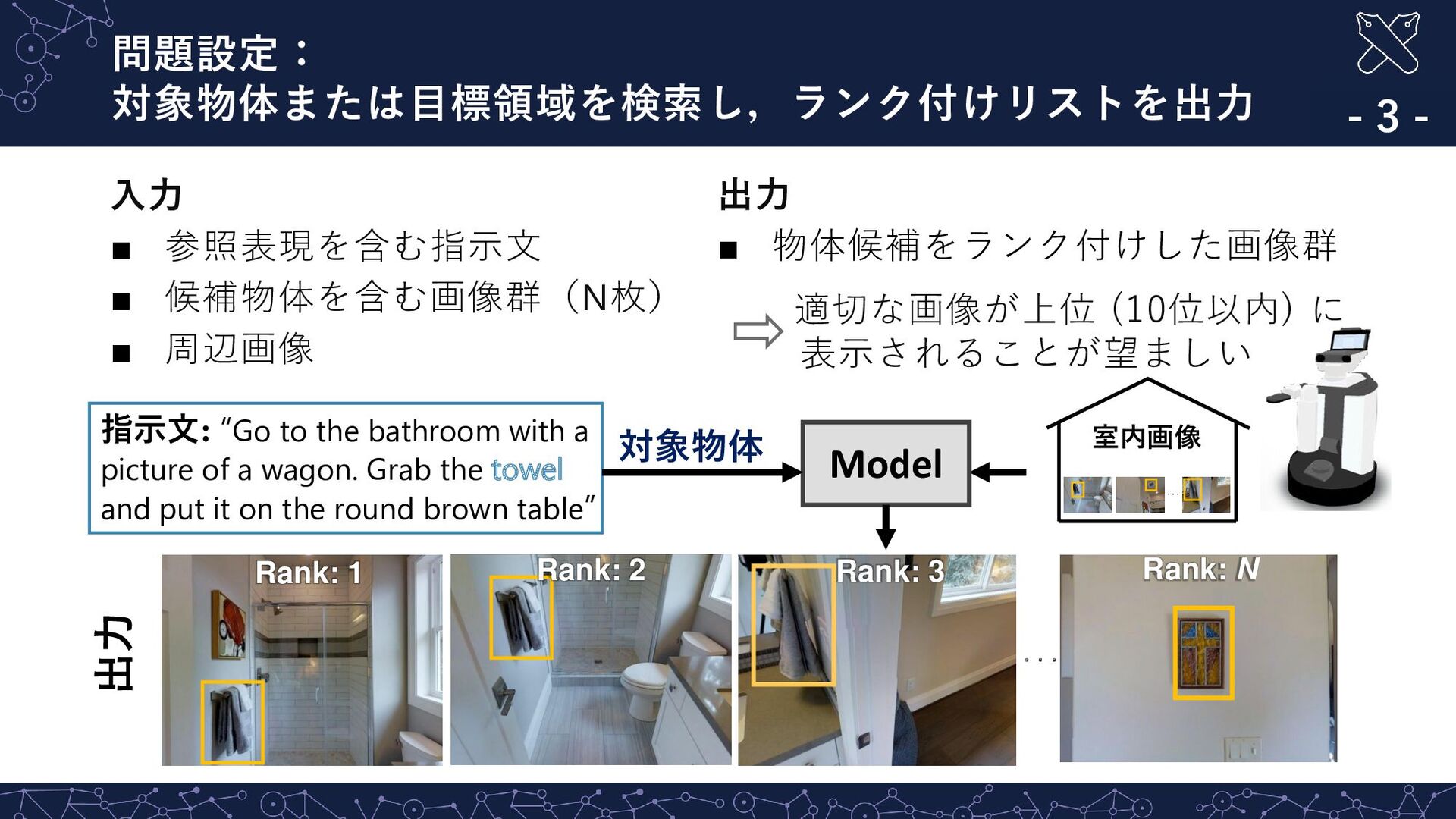
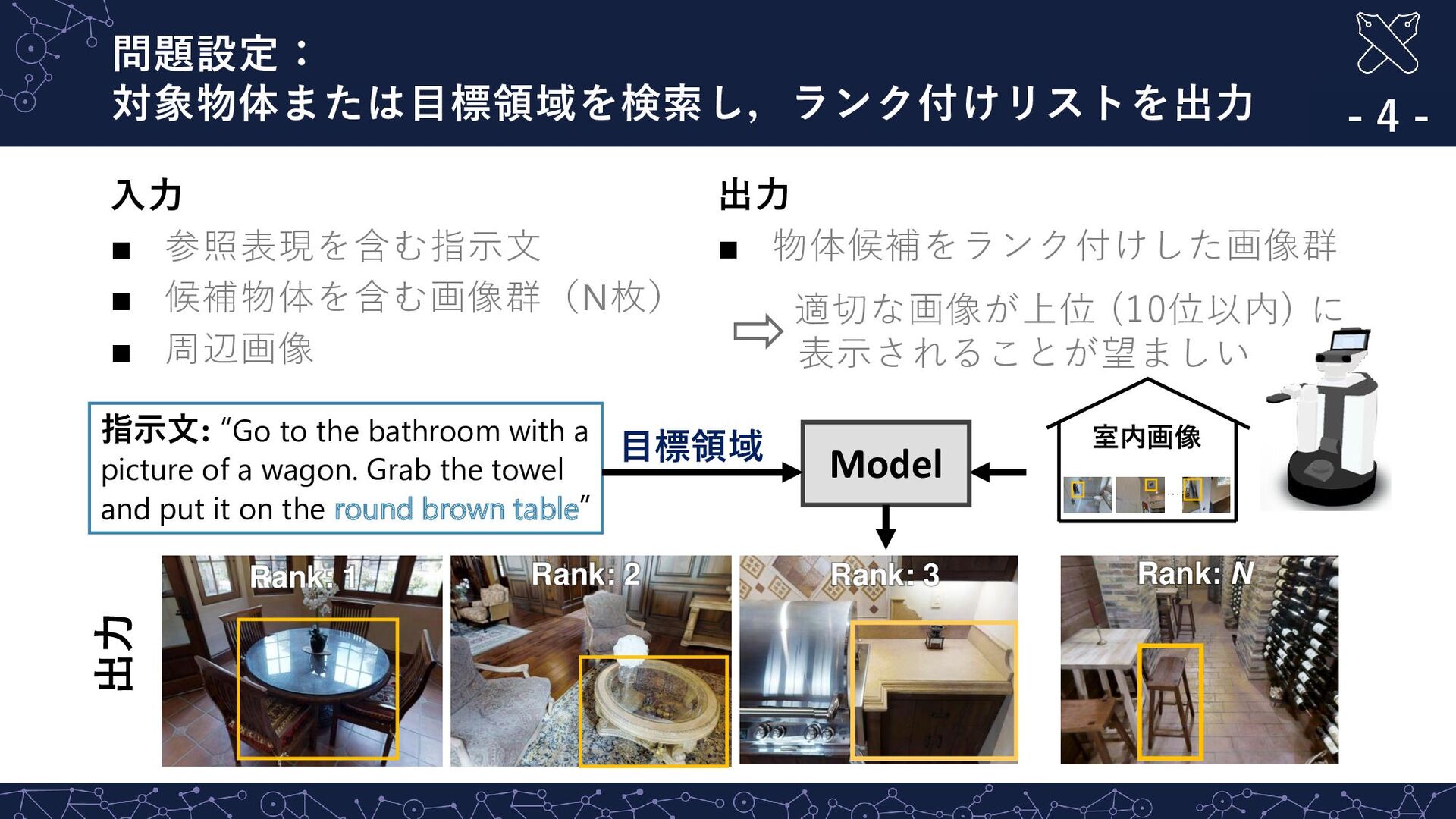
3 Rank: 2 ・・・ 室内画像 Rank: 1 対象物体 出力 指示文: “Go to the bathroom with a picture of a wagon. Grab the towel and put it on the round brown table” 入力 ▪ 参照表現を含む指示文 ▪ 候補物体を含む画像群(N枚) ▪ 周辺画像 出力 ▪ 物体候補をランク付けした画像群 適切な画像が上位 (10位以内) に 表示されることが望ましい
Rank: N Rank: 3 Rank: 2 Rank: 1 指示文: “Go to the bathroom with a picture of a wagon. Grab the towel and put it on the round brown table” 入力 ▪ 参照表現を含む指示文 ▪ 候補物体を含む画像群(N枚) ▪ 周辺画像 出力 ▪ 物体候補をランク付けした画像群 適切な画像が上位 (10位以内) に 表示されることが望ましい
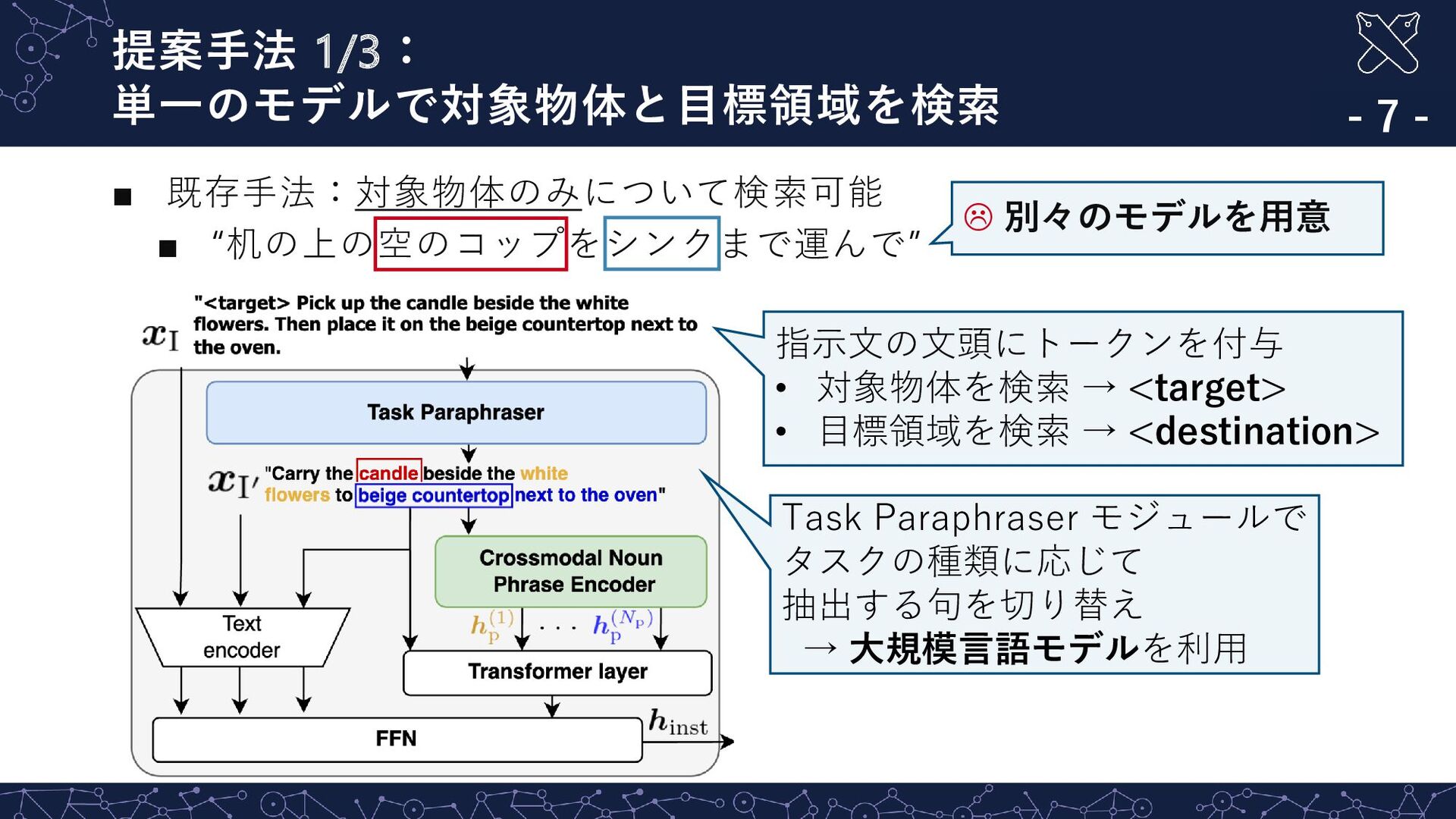
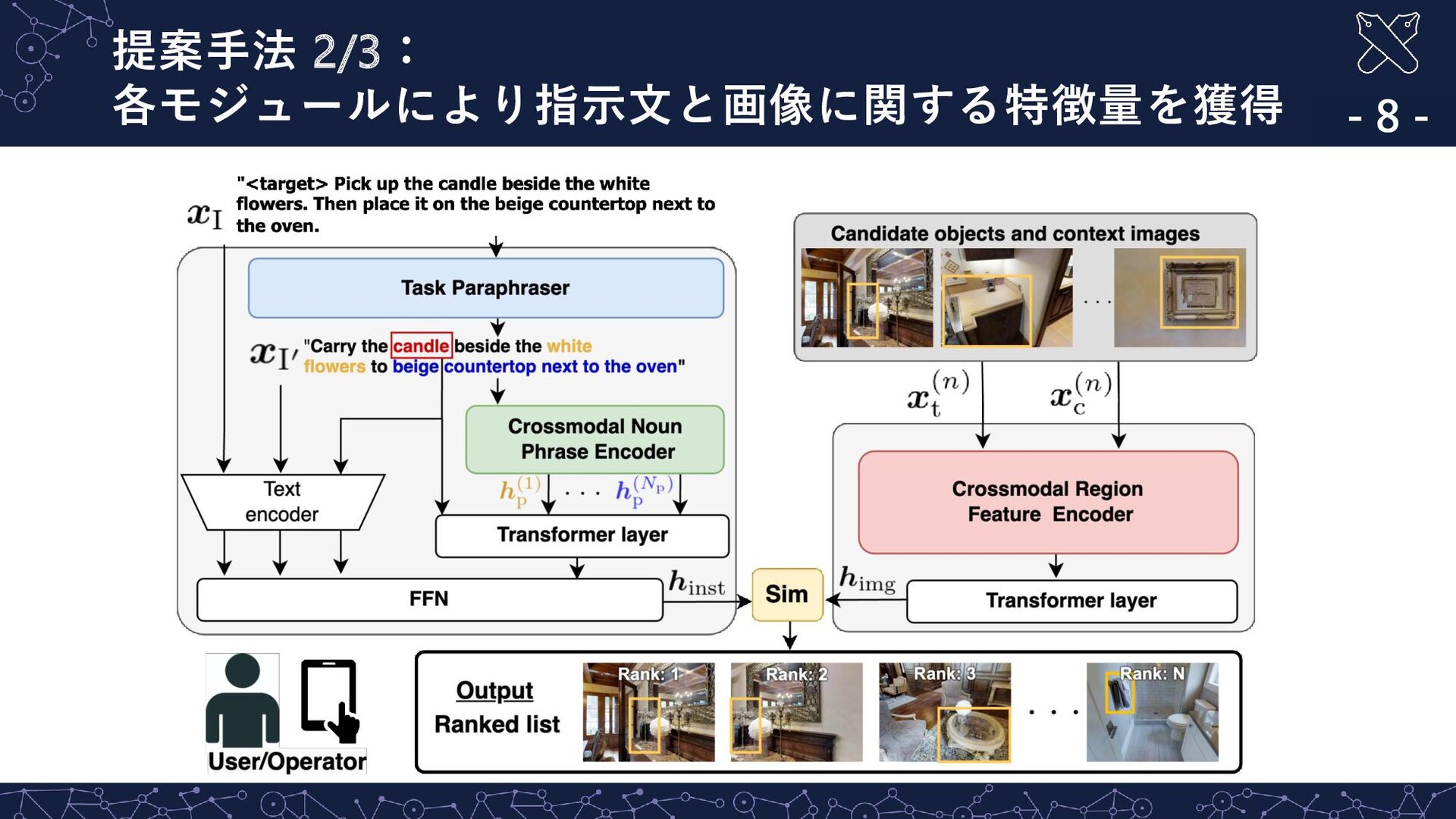
spread. Open the window to the left of the tallboy as wide as possible” 定性的結果 ②: 冗長かつ文法的な誤りを含む指示文について適切に検索 - 13 - … 正解画像 (対象物体) Rank: 4 Rank: 5 Rank: 6 ☺ Task Paraphraser の導入により,適切な画像を上位に検索 Rank: 1 Rank: 2 Rank: 3 指示文:”Go to the bedroom with the where curtains and bed spread. Open the window to the left of the tallboy as wide as possible”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}