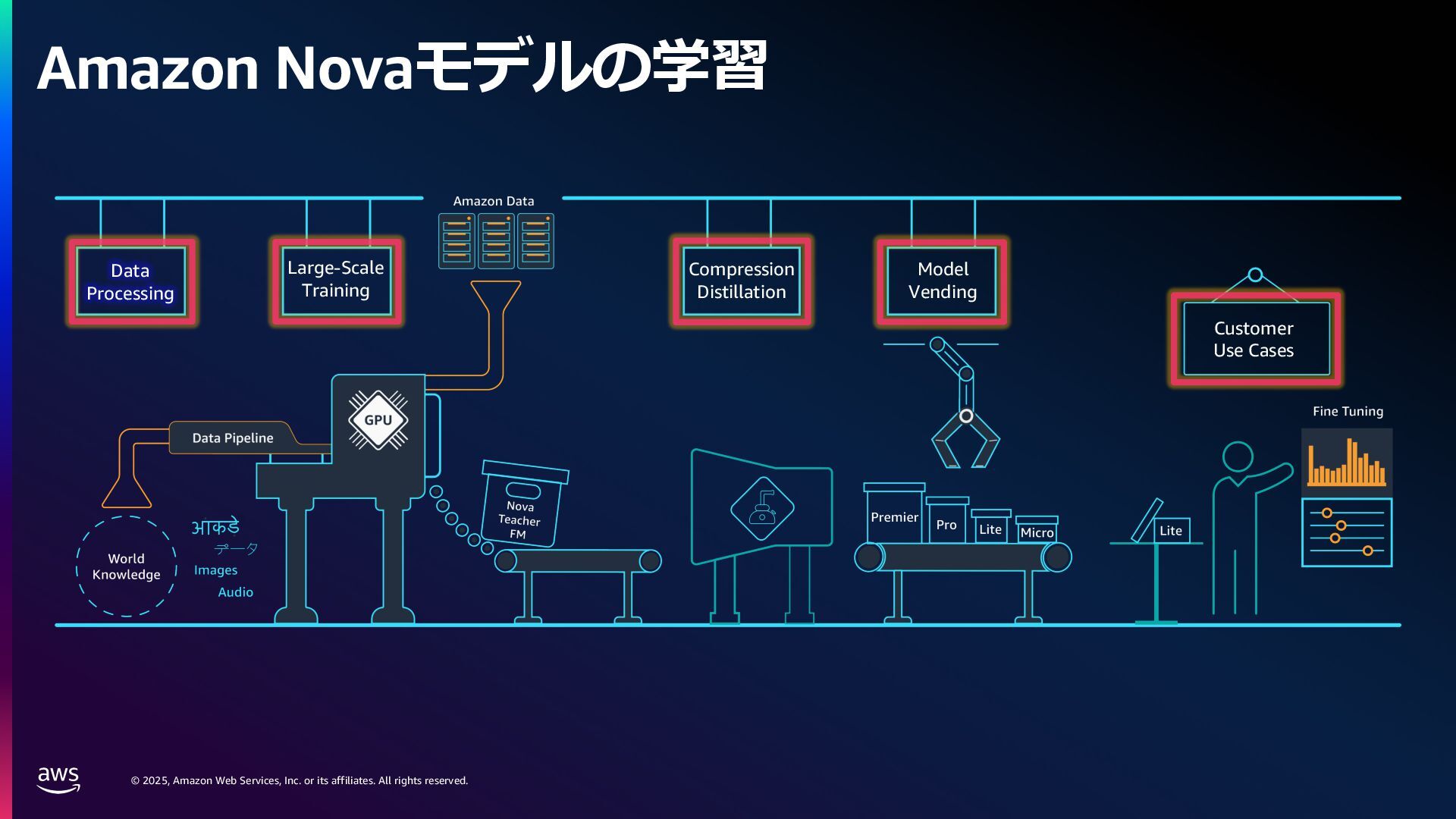
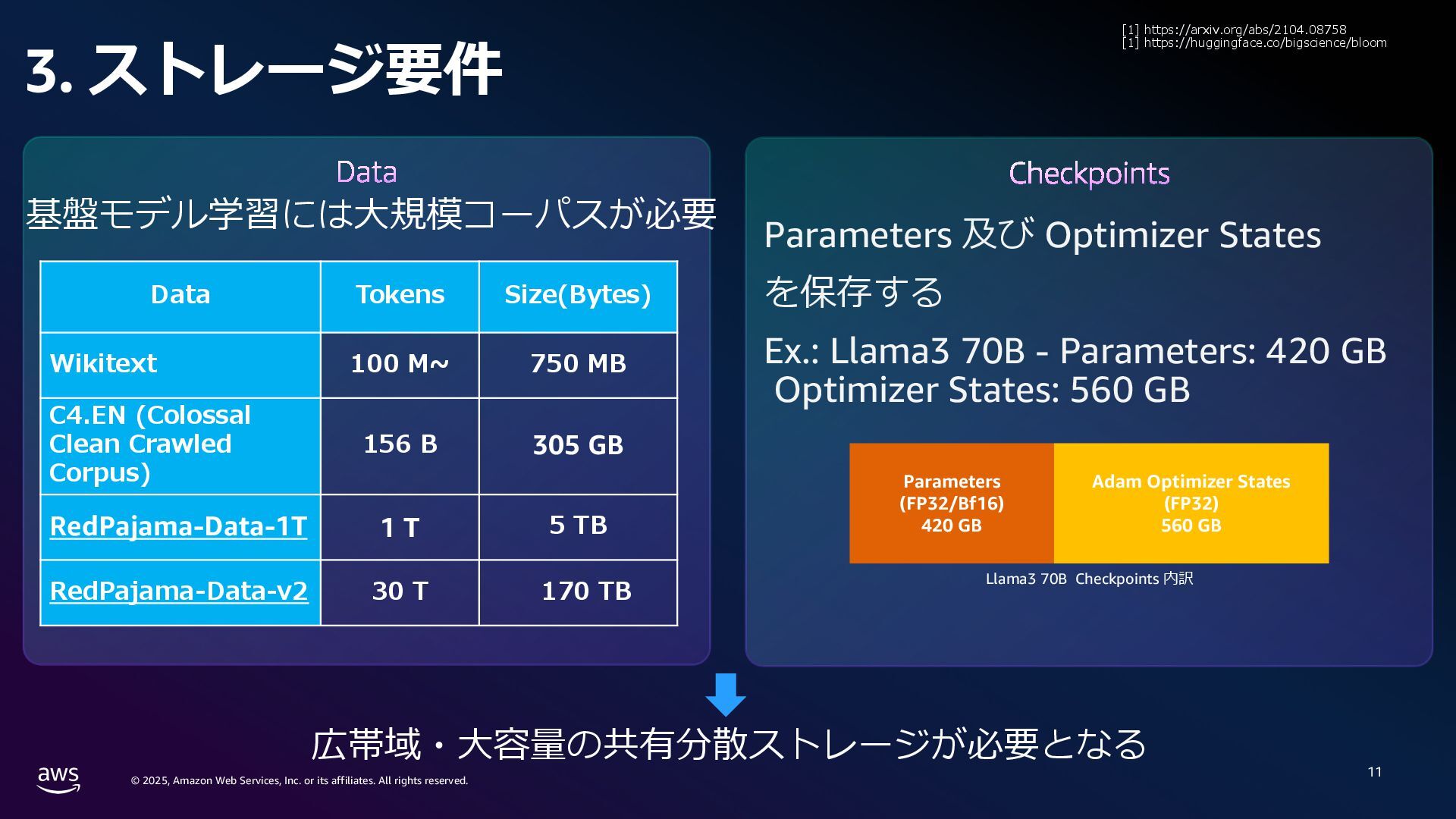
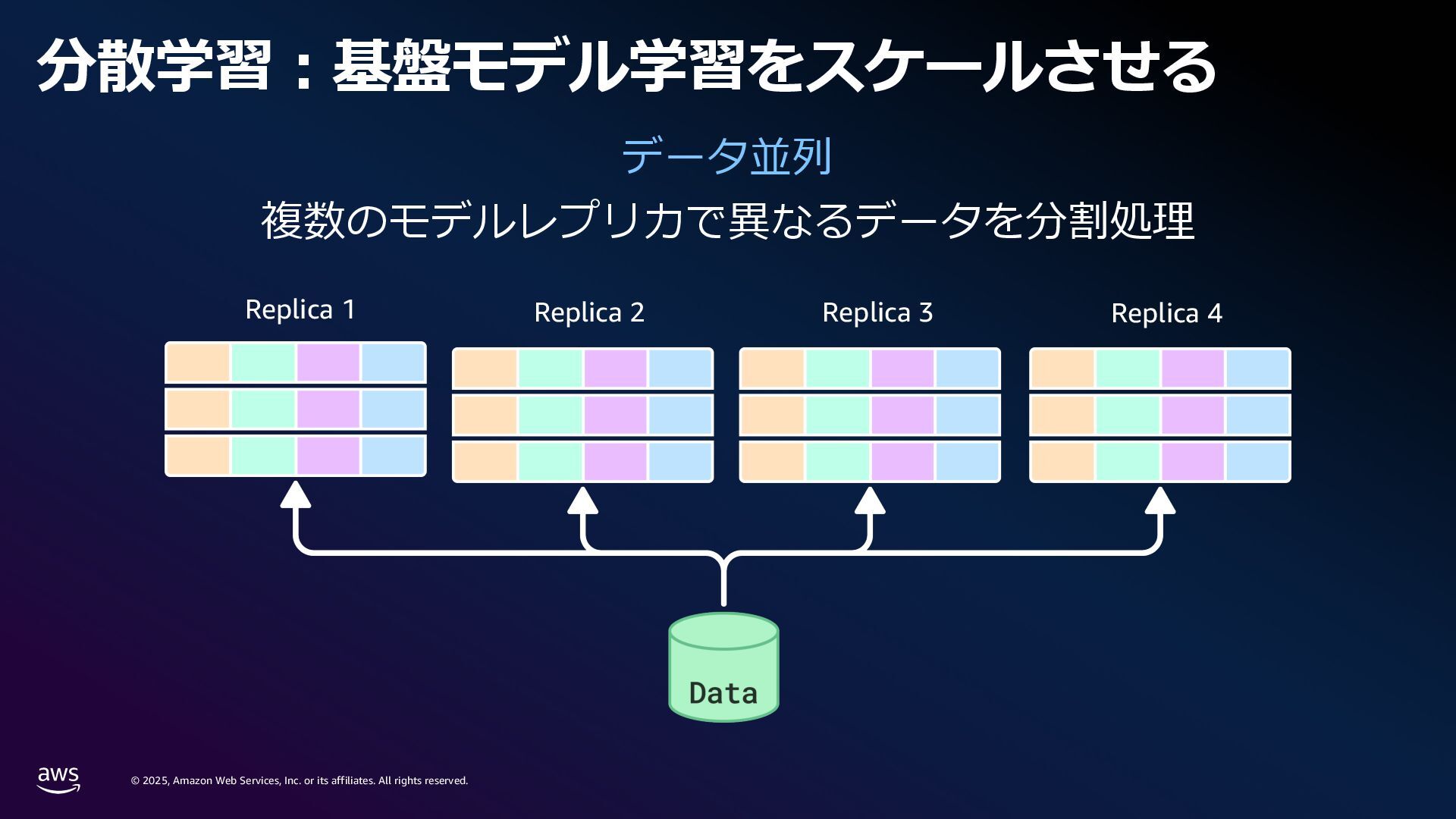
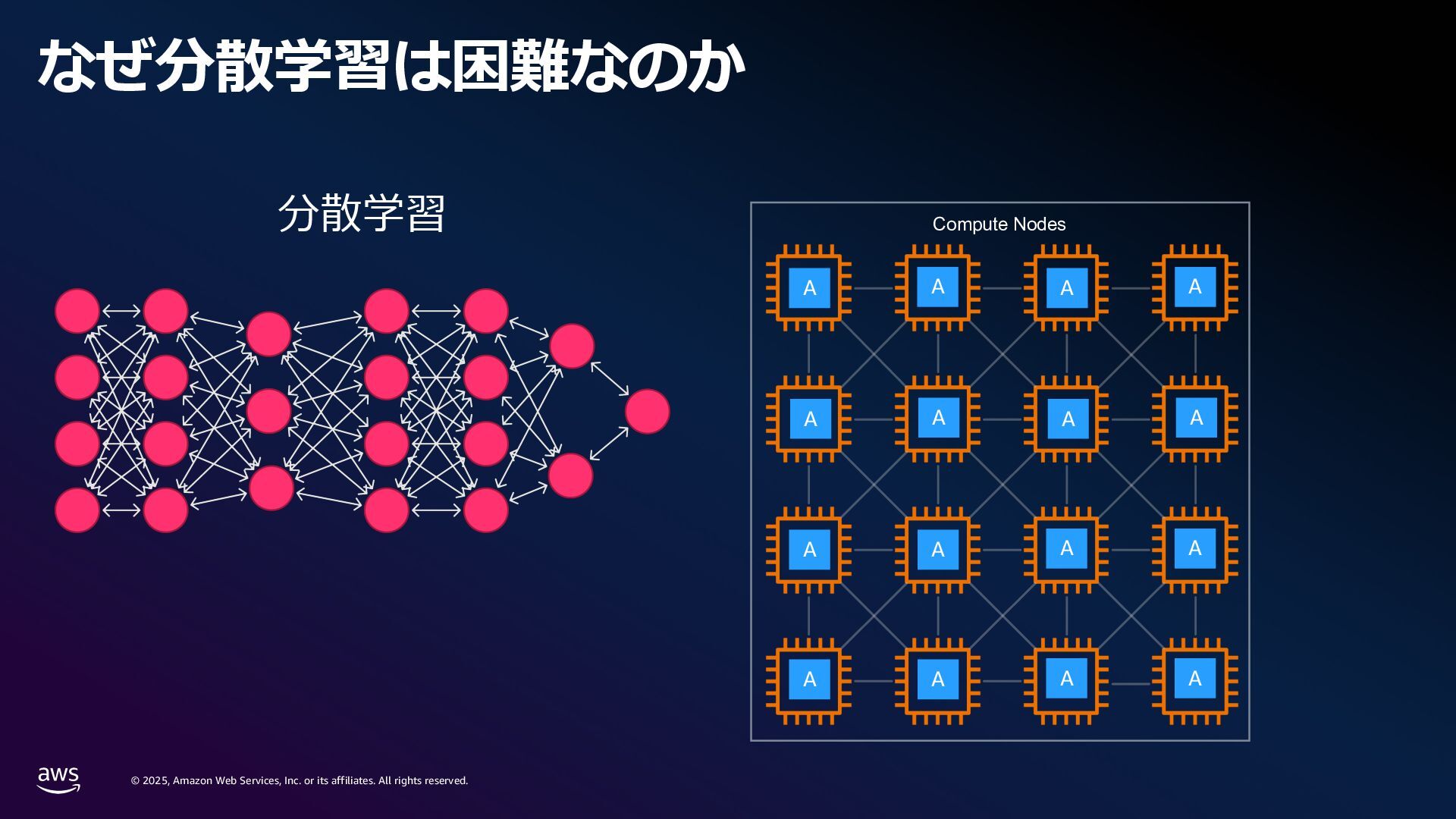
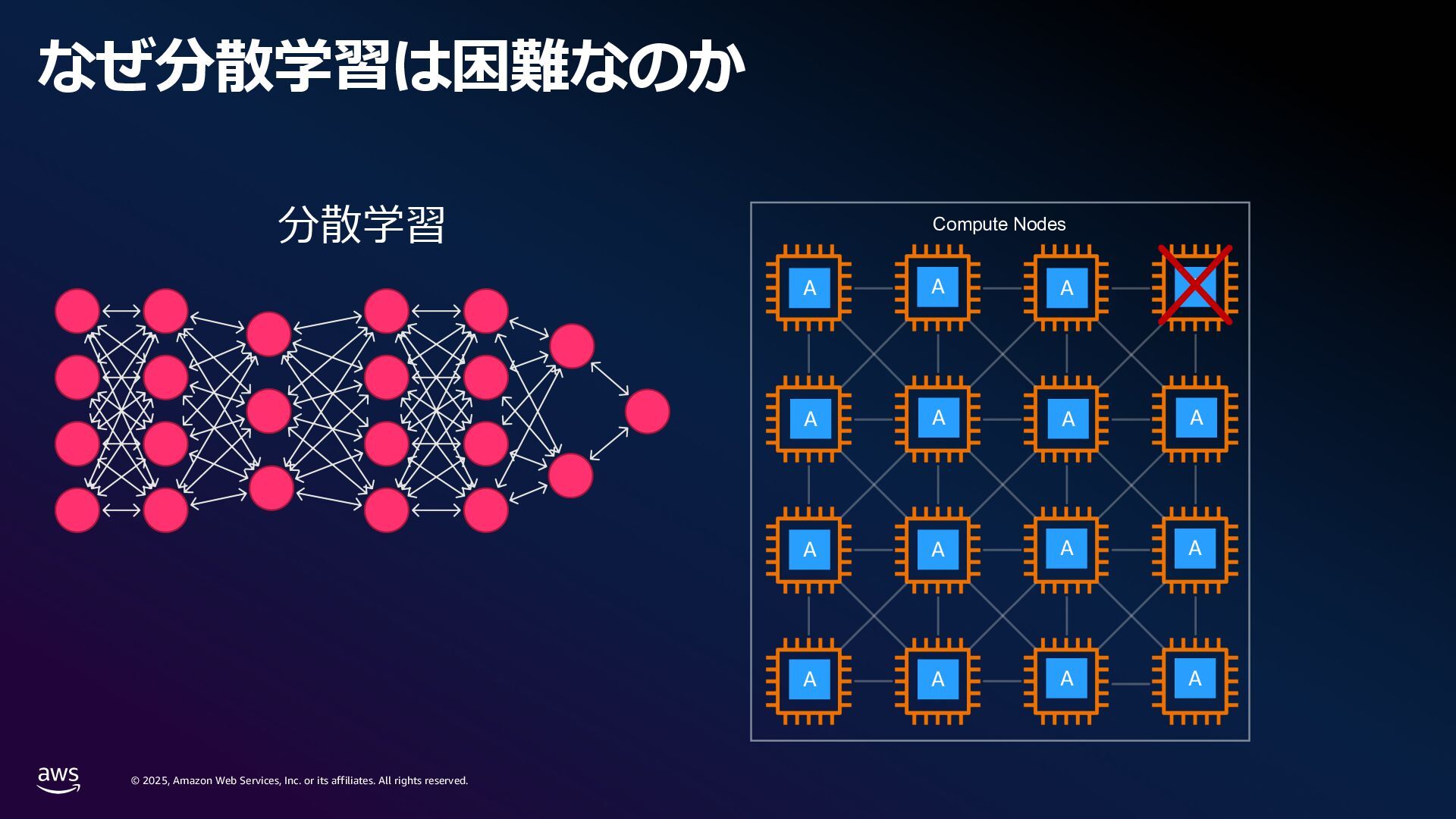
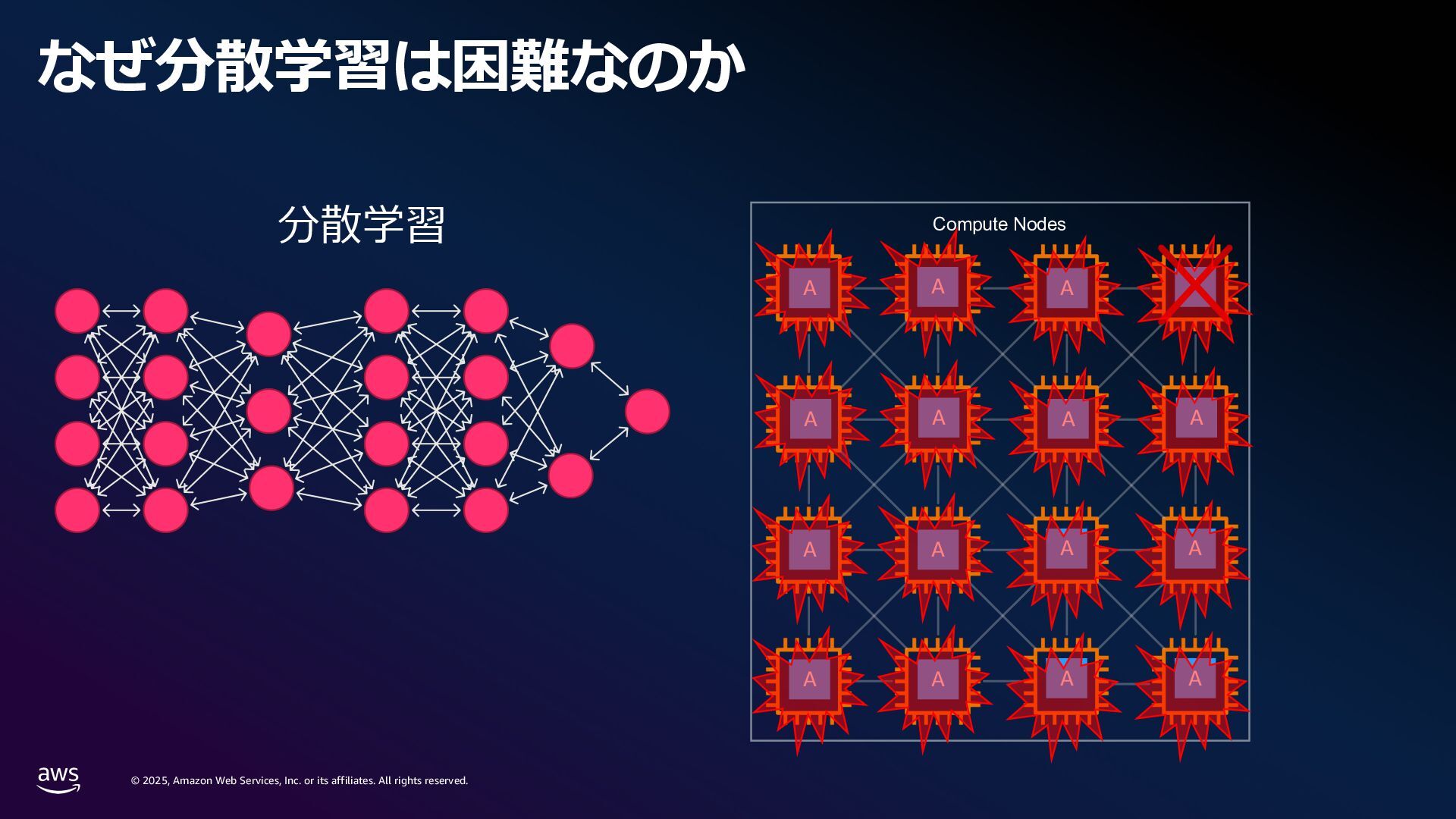
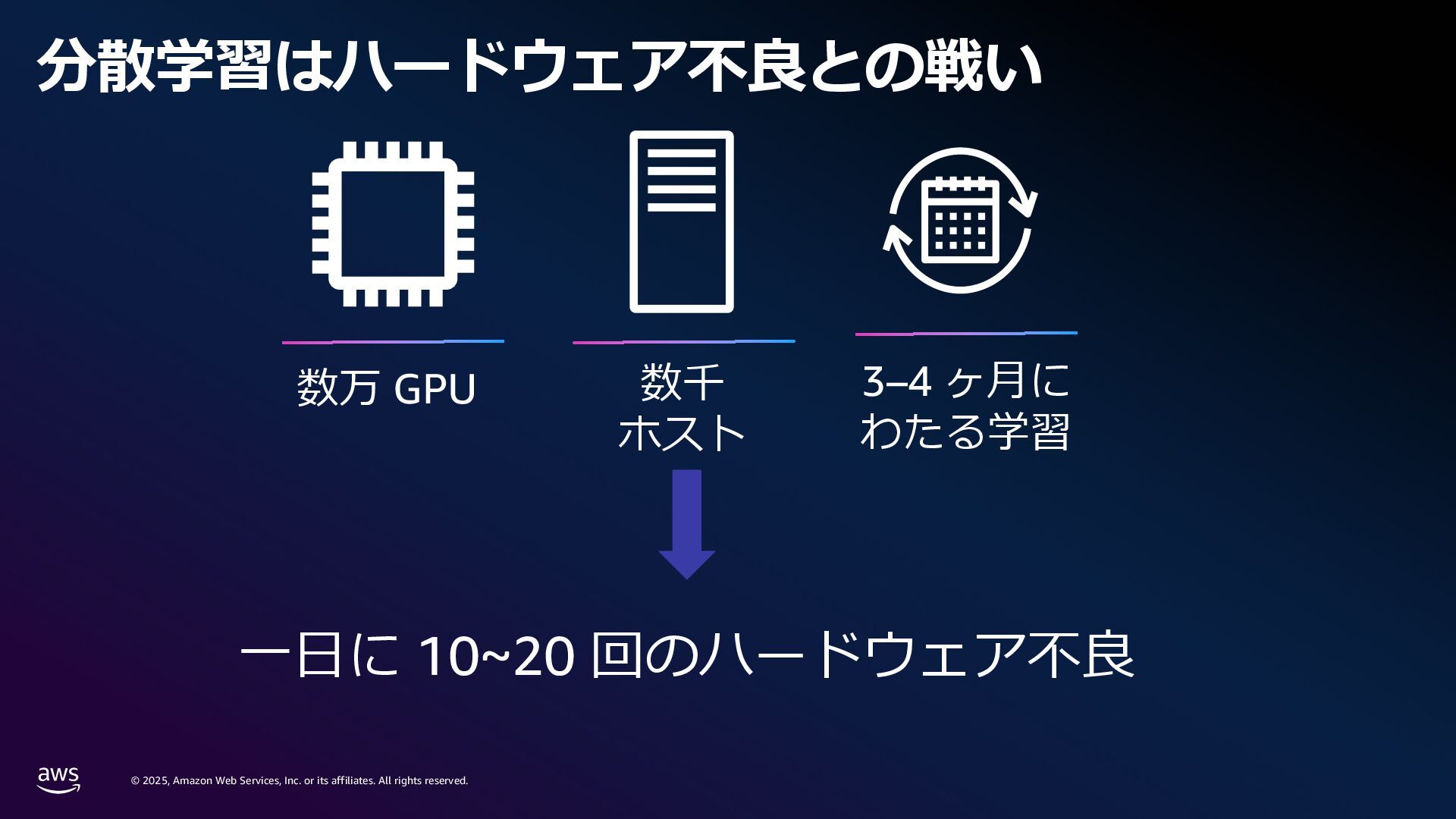
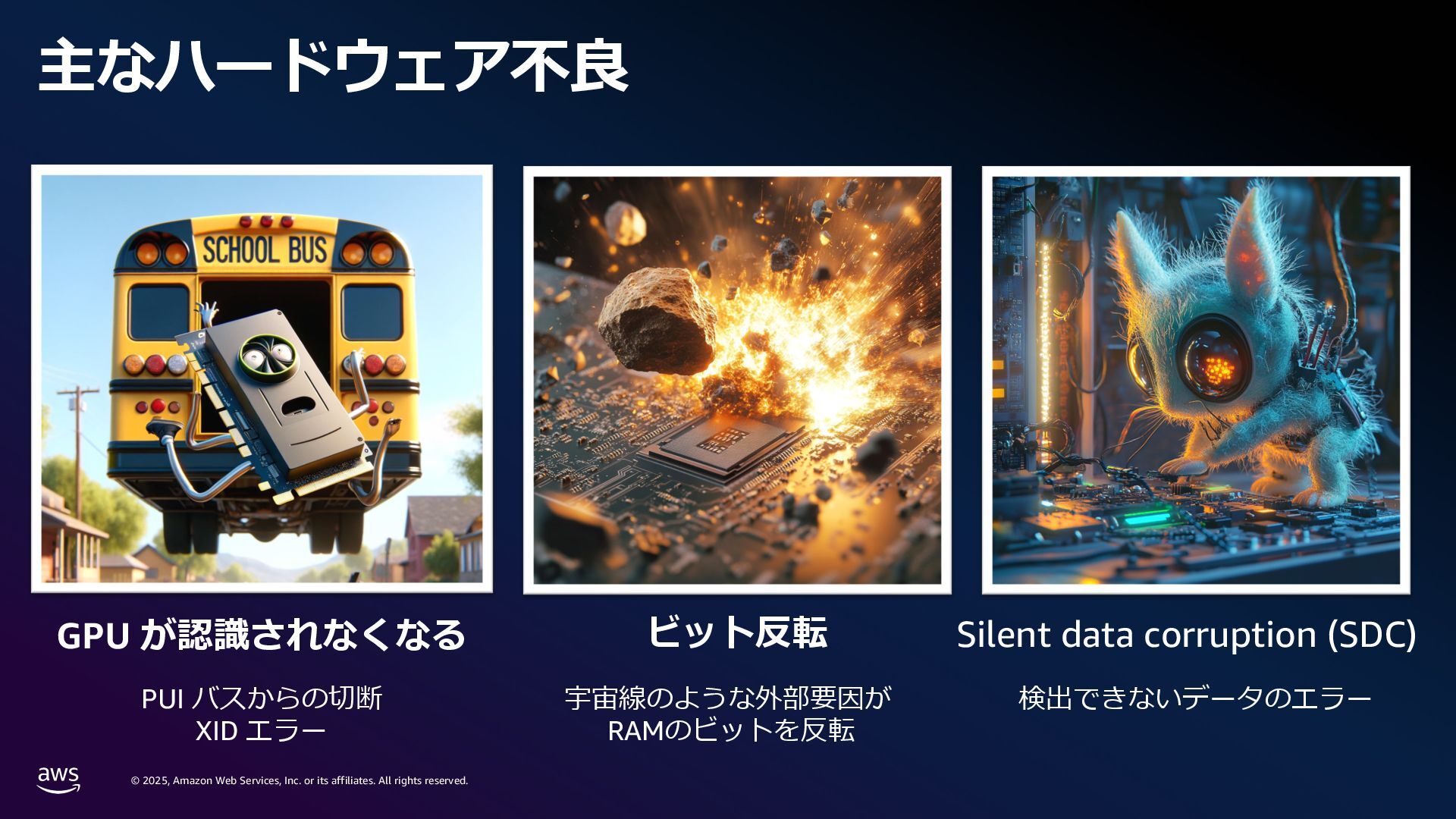
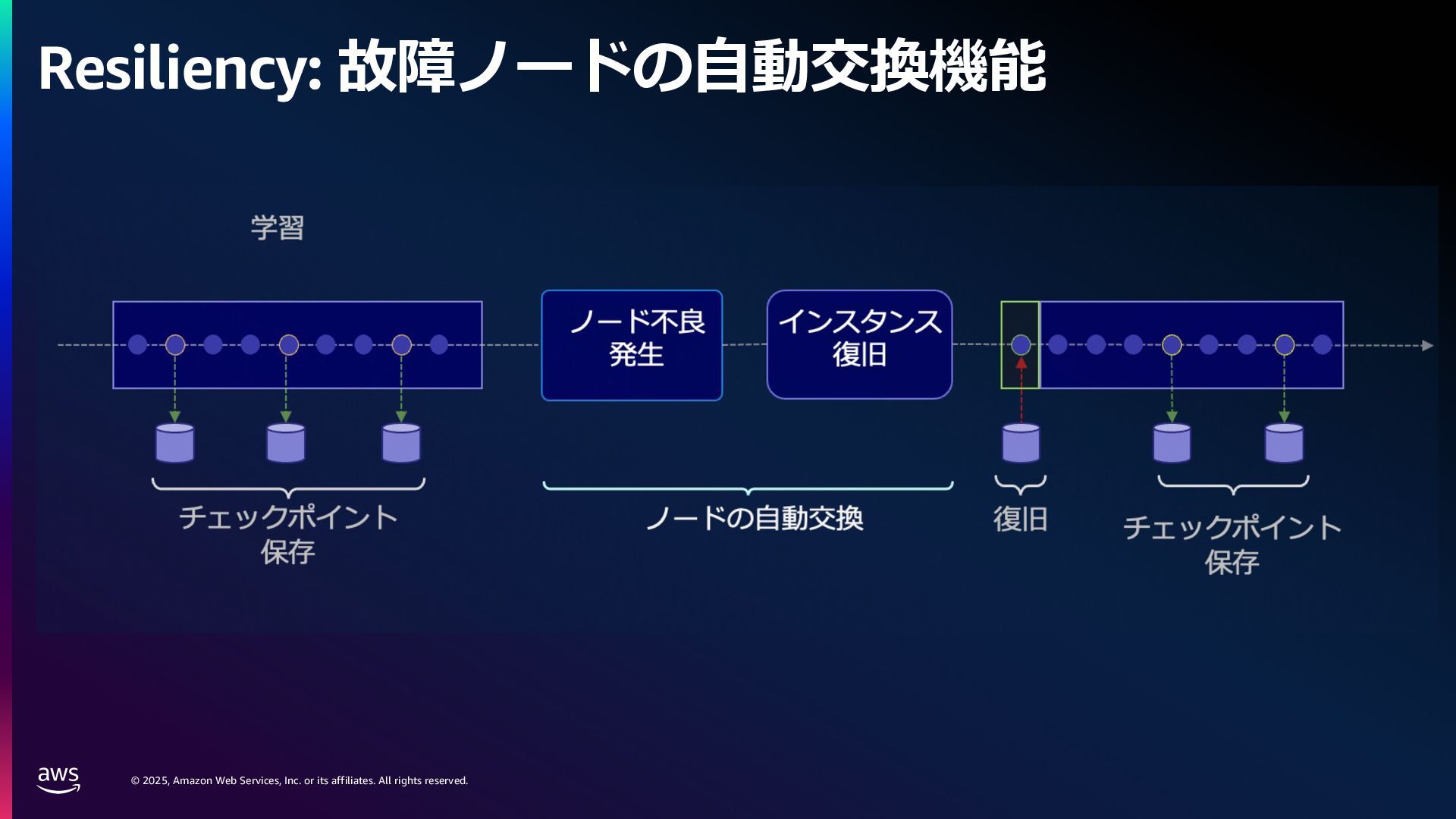
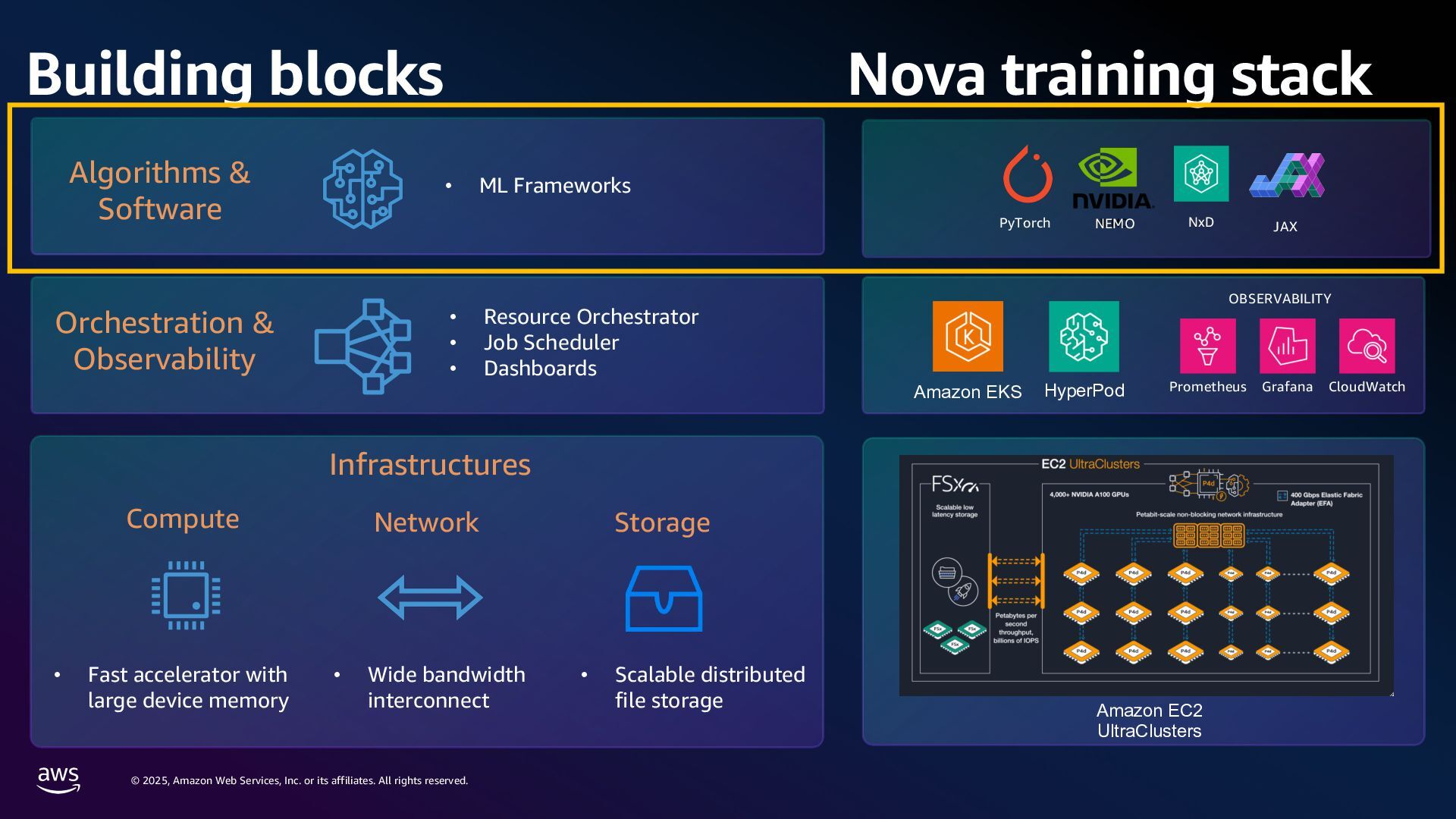
rights reserved. 1. Compute 要件 学習に必要なメモリ: Mixed precision 学習 18 bytes/param Llama3 70B → 1.2 TB~ スケーリング則[1]: FLOPS ≈ 6 x Parameters x Tokens Chinchilla 則[2]: モデルの学習には 20 tokens/parameter 必要 Parameters (FP32/Bf16) 420 GB Gradients (FP32) 280 GB Adam Optimizer States (FP32) 560 GB VRAM consumption Llama3 70B (Without Activations etc.) [1] Kaplan, J., McCandlish, S., Henighan, T., Brown, T.B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J. and Amodei, D., 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361. [2] Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D.D.L., Hendricks, L.A., Welbl, J., Clark, A. and Hennigan, T., 2022. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556. 6 × 70B 70 B x 20 × 0.6 million exaflops = ※ 近年のモデルではより多くの token 数を費やして学習している
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}