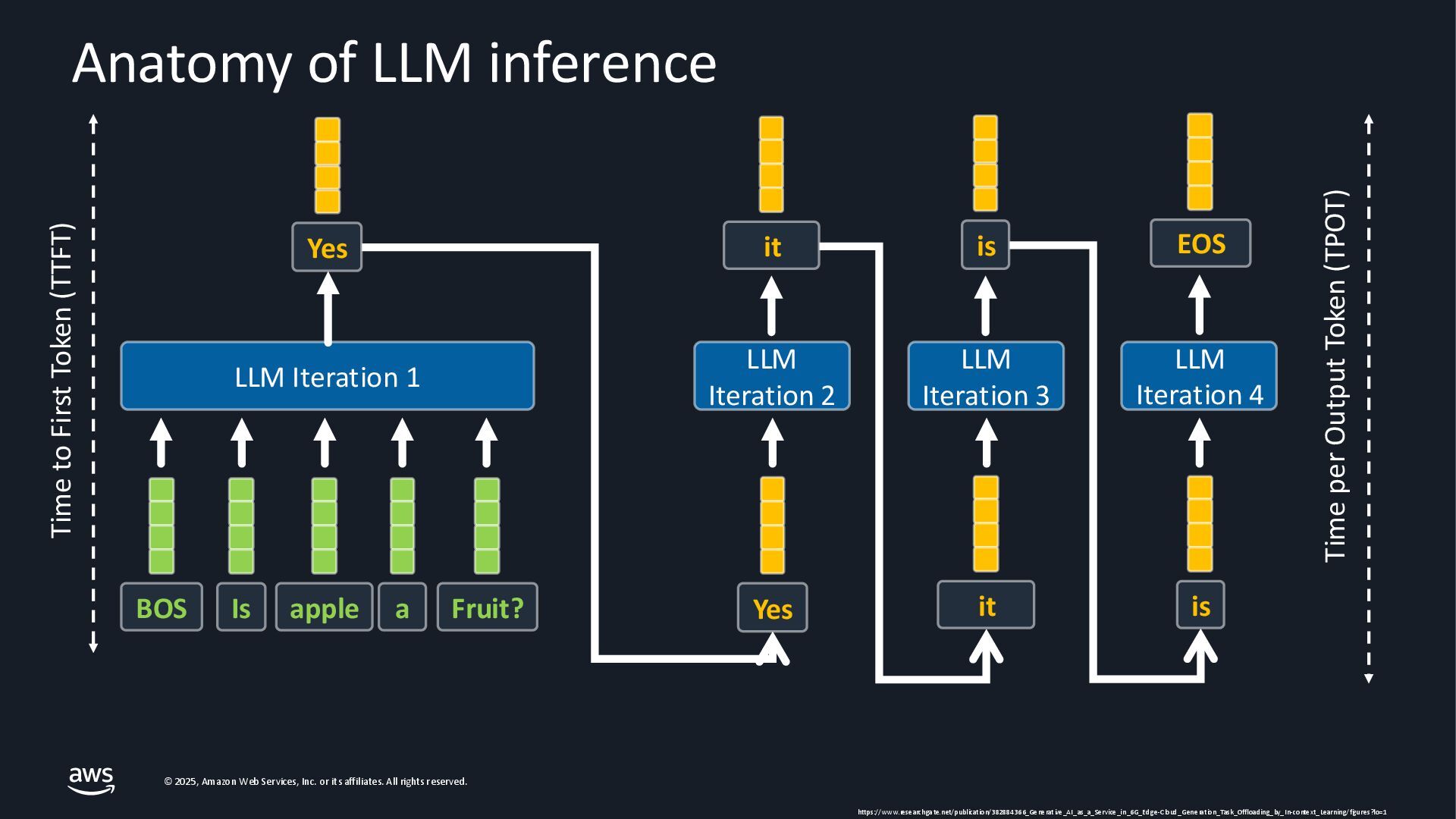
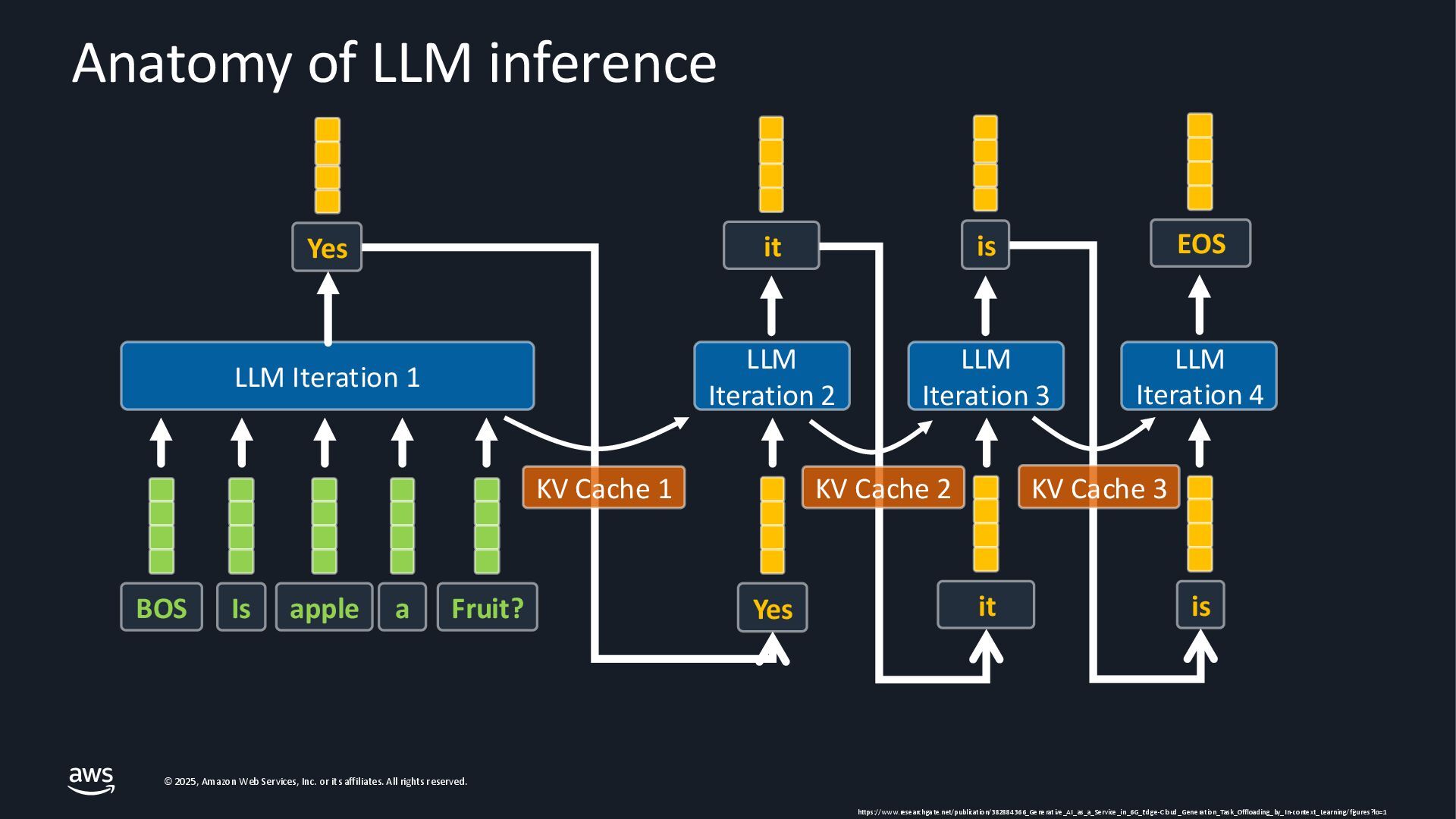
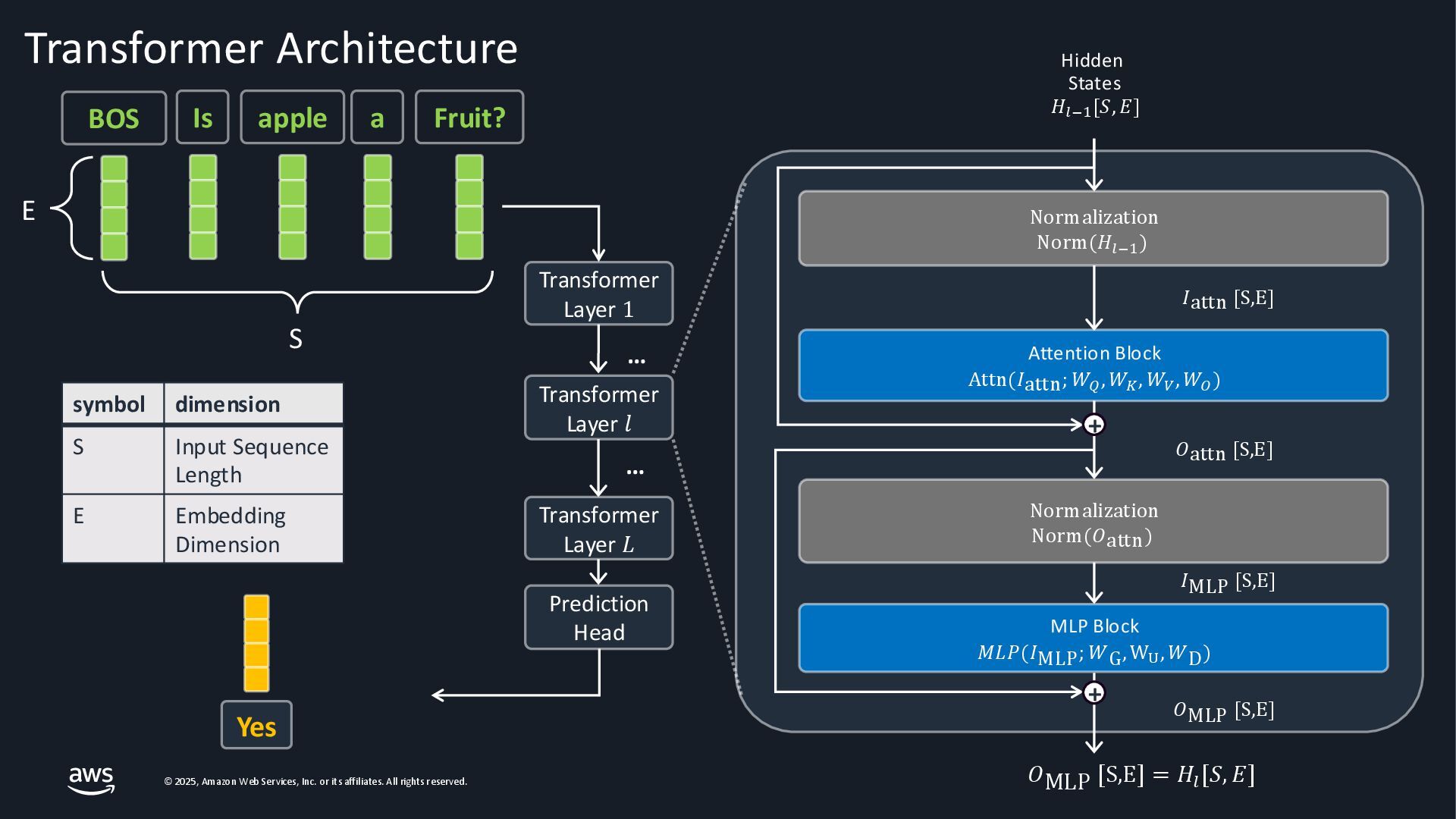
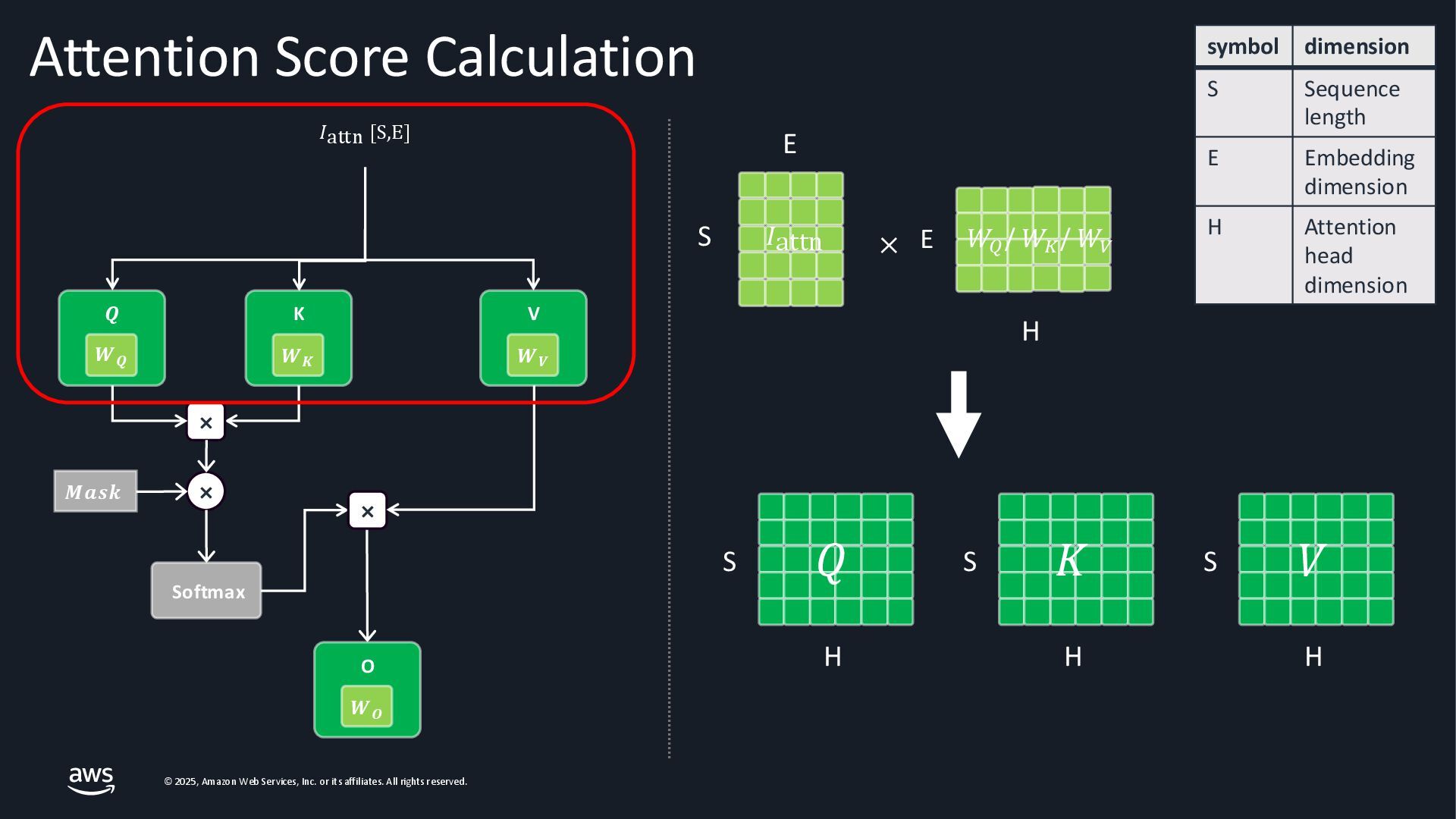
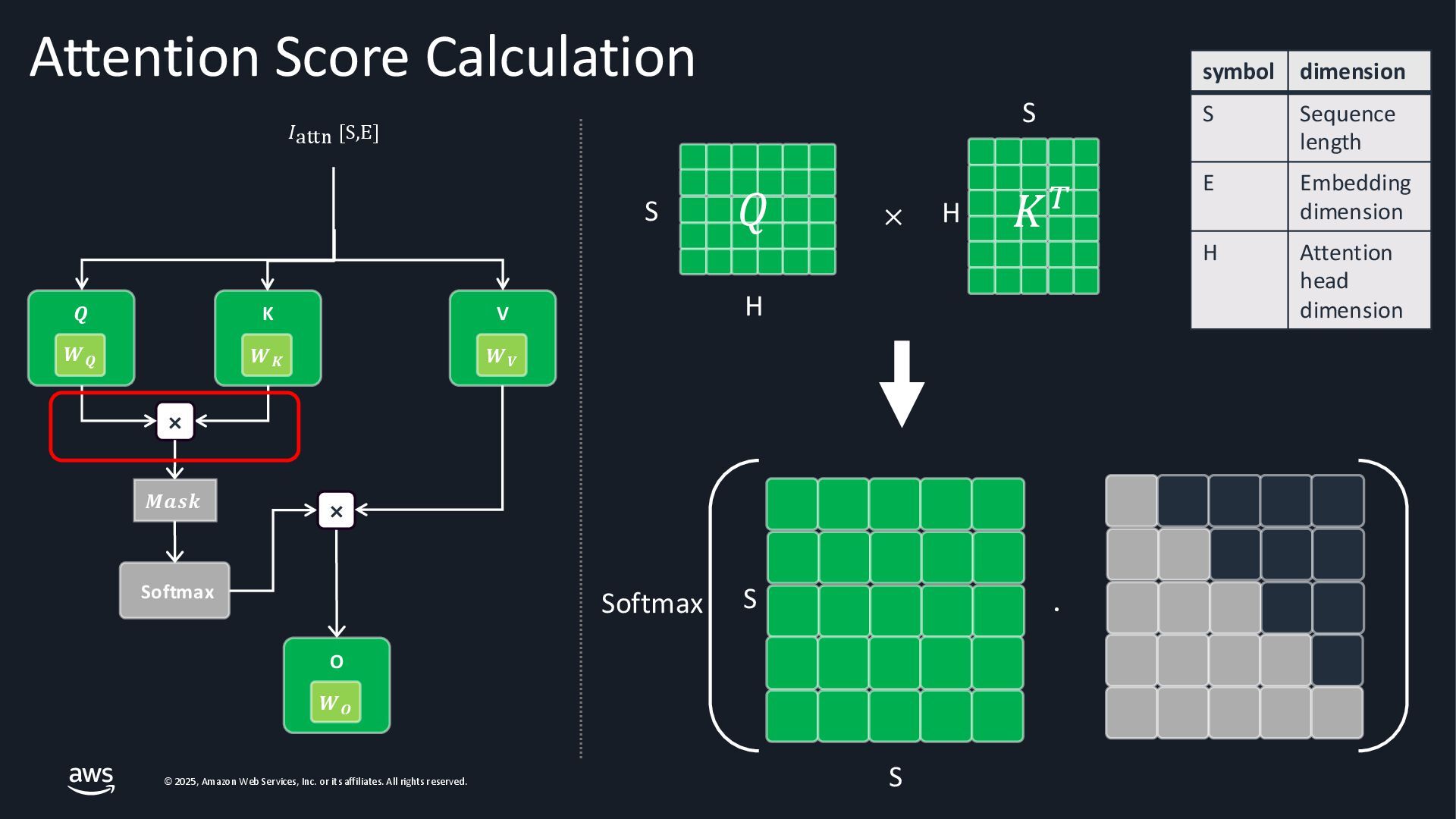
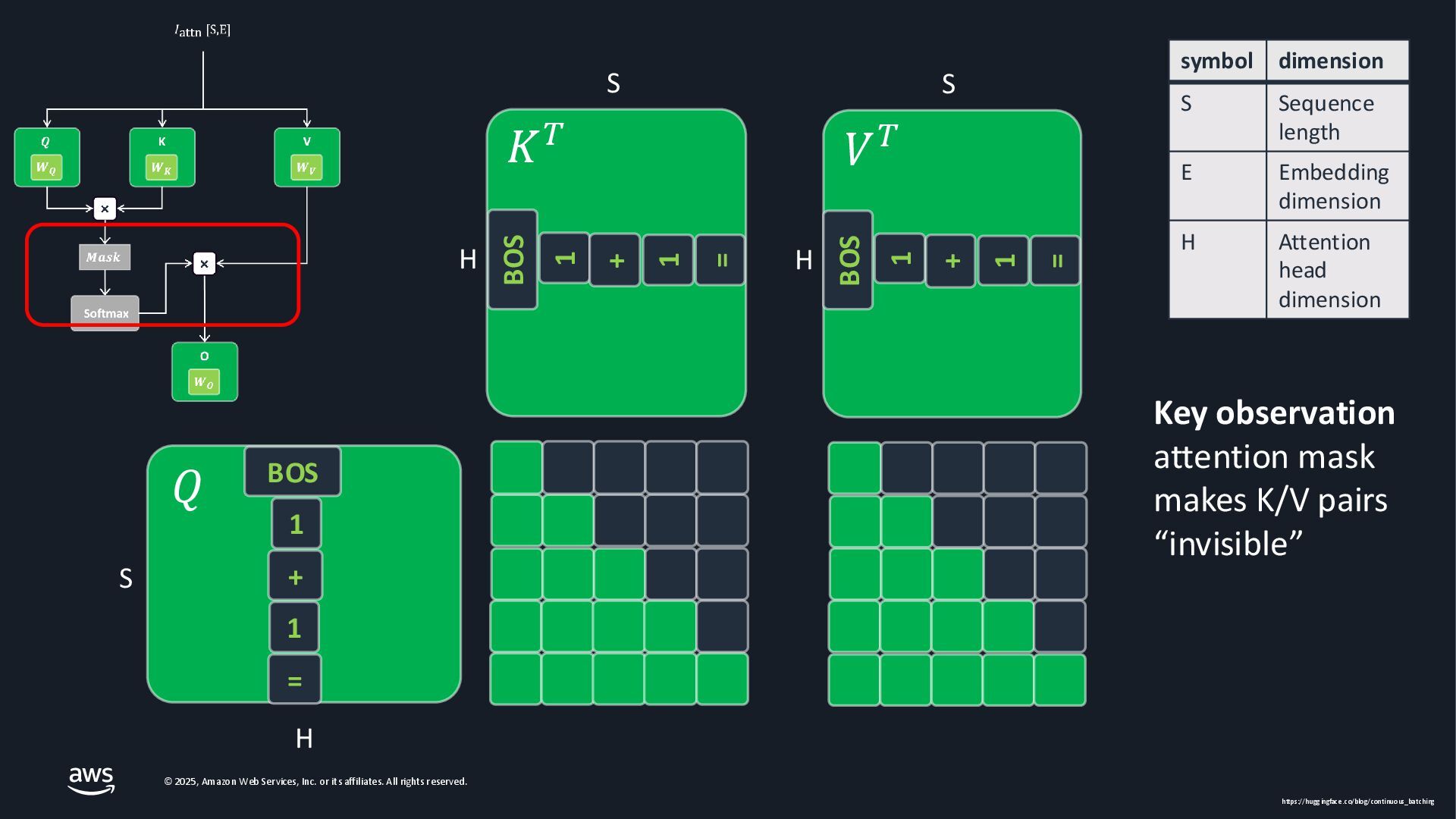
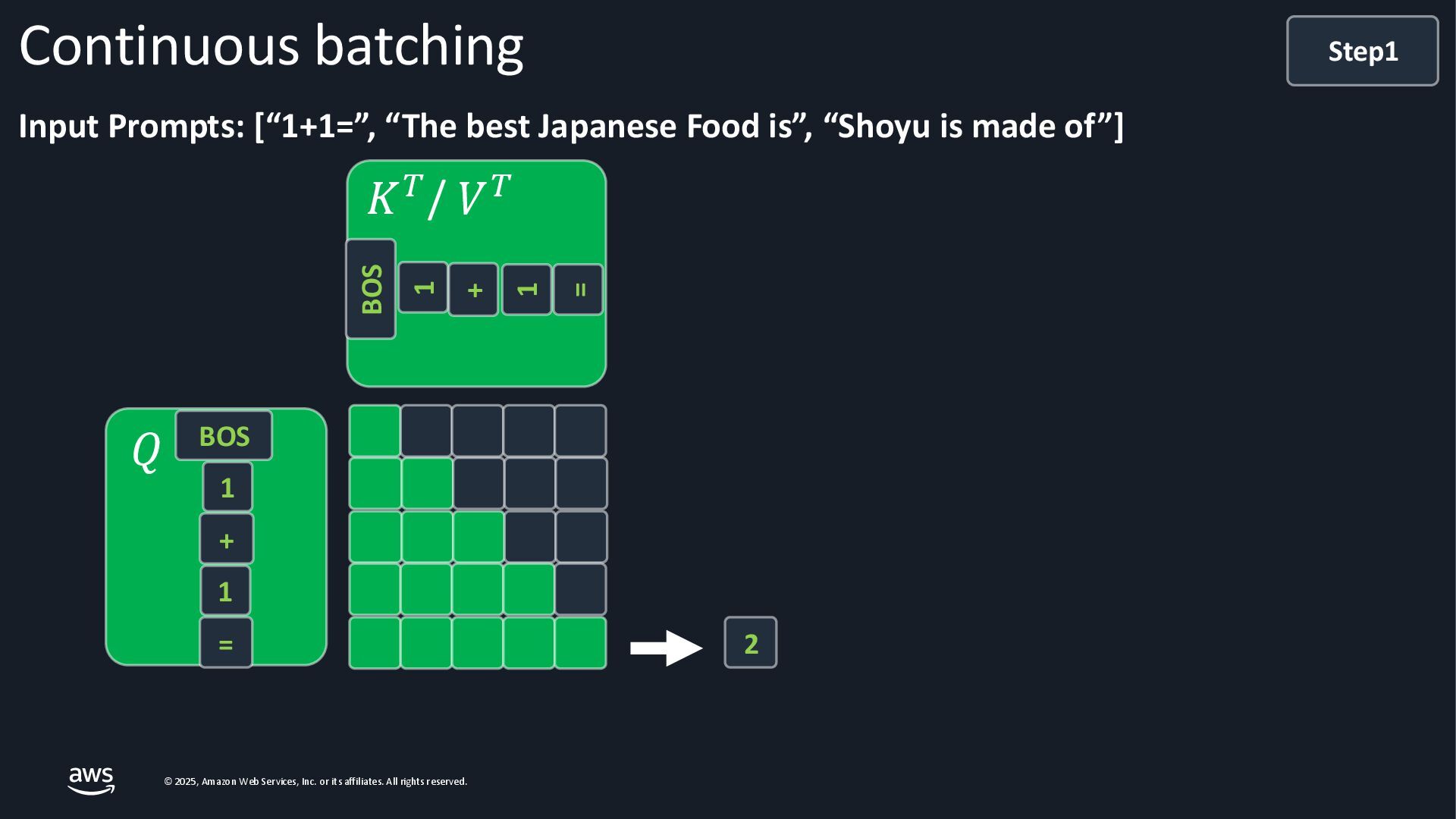
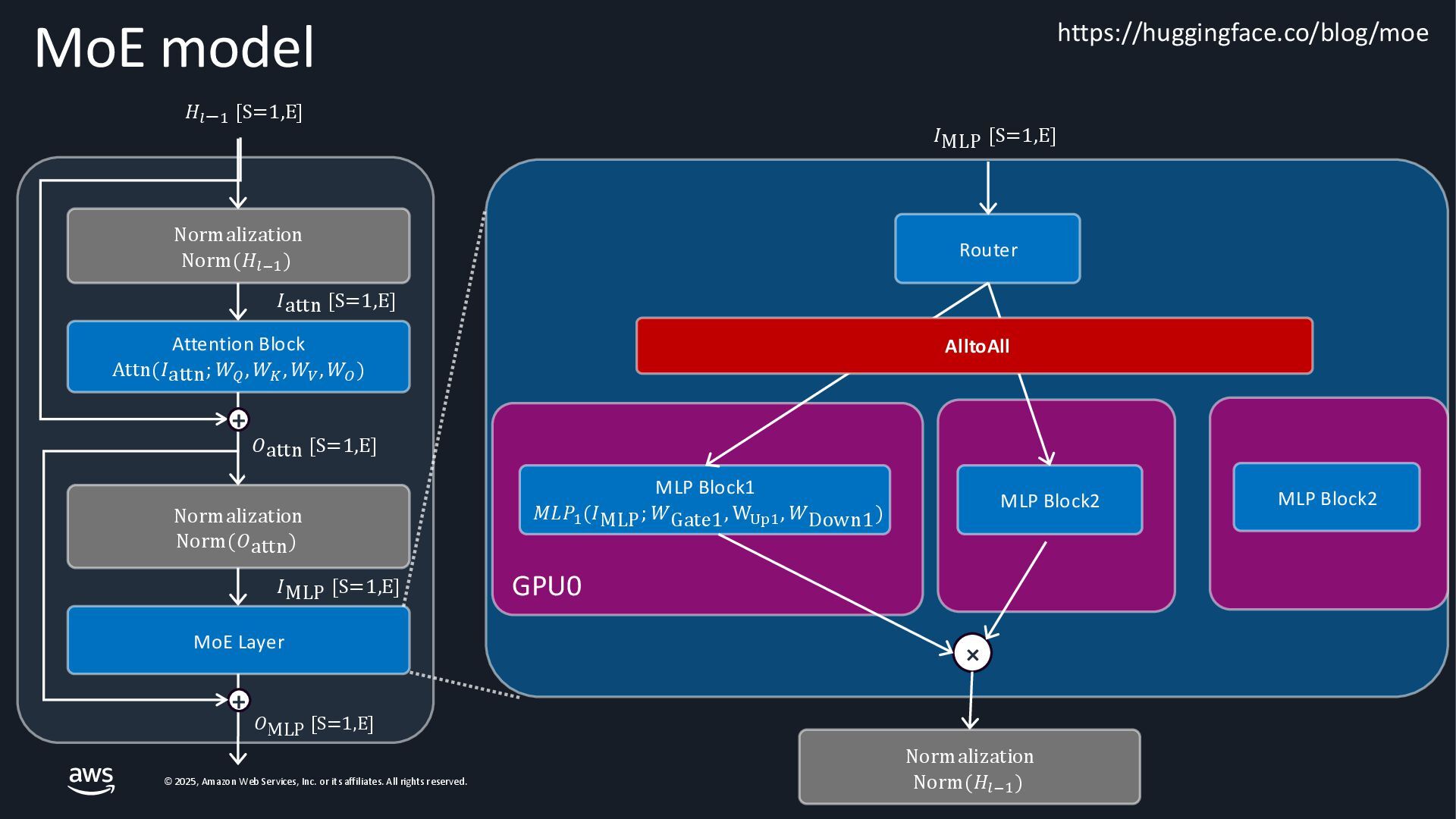
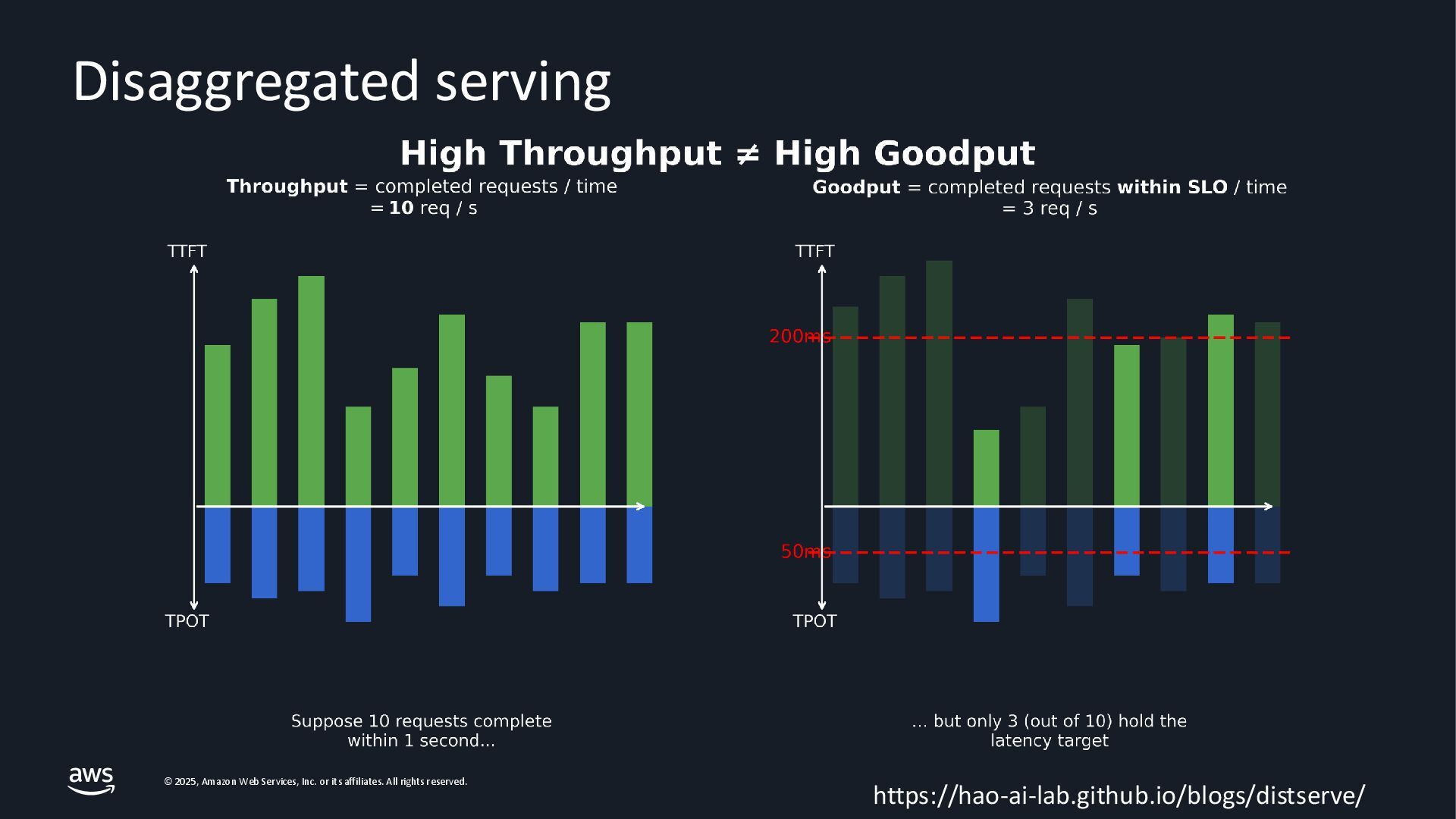
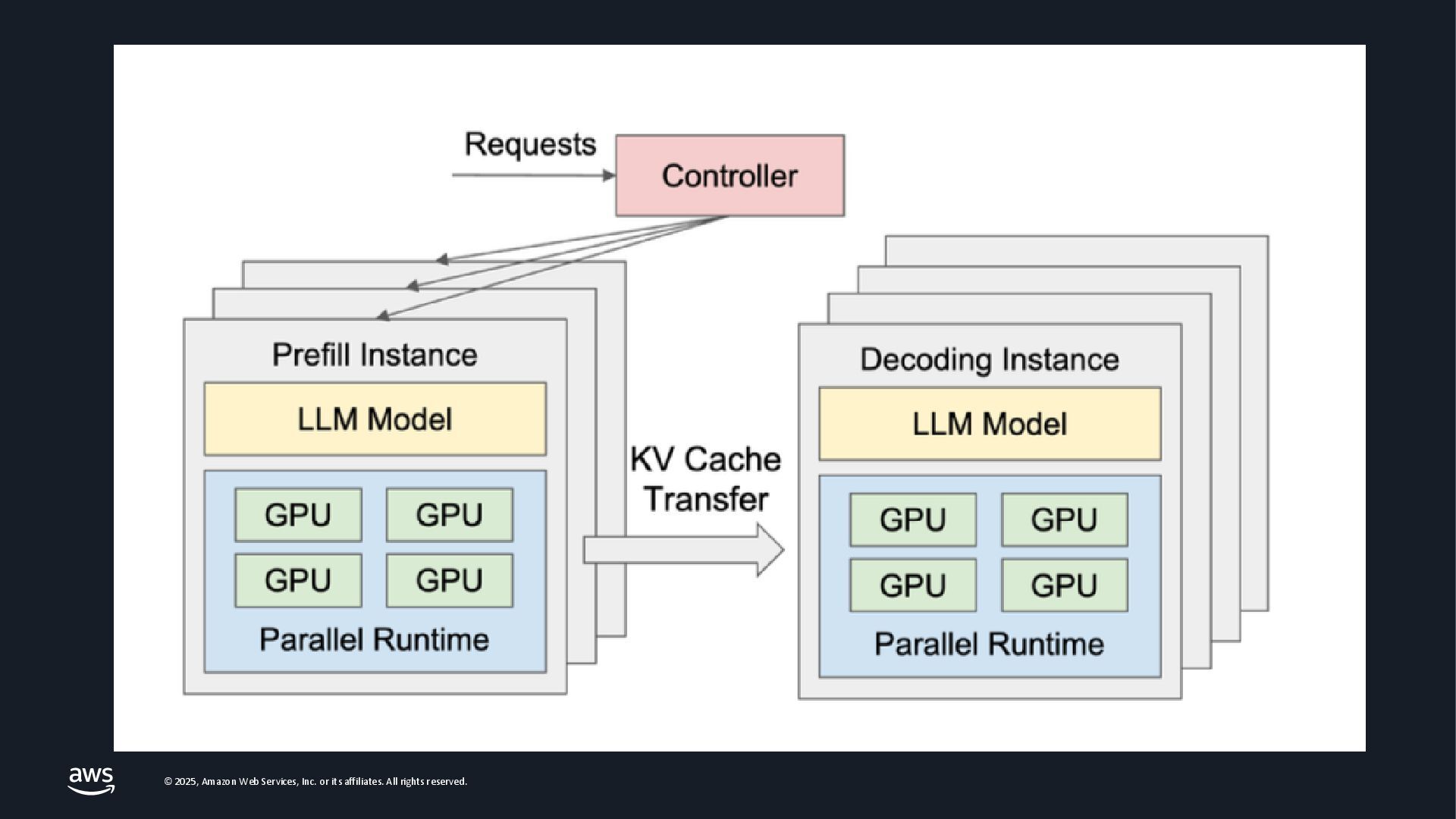
As Large Language Models (LLMs) become integral to applications, optimizing inference performance is paramount, especially at scale. This session delves into cutting-edge techniques, research and frameworks that enhance LLM serving efficiency, focusing on KV-cache management, PagedAttention mechanisms, and disaggregated serving architectures. We will cover best practices for self-managed inference on AWS: use cases with architecture diagrams, deep dive into how ML inference works on accelerated compute, and common patterns of optimizations in the field. Attendees will gain a comprehensive understanding of the current landscape and future directions in inference optimization, with the knowledge to implement these advancements in distributed systems.
{kind=link}
{kind=link}
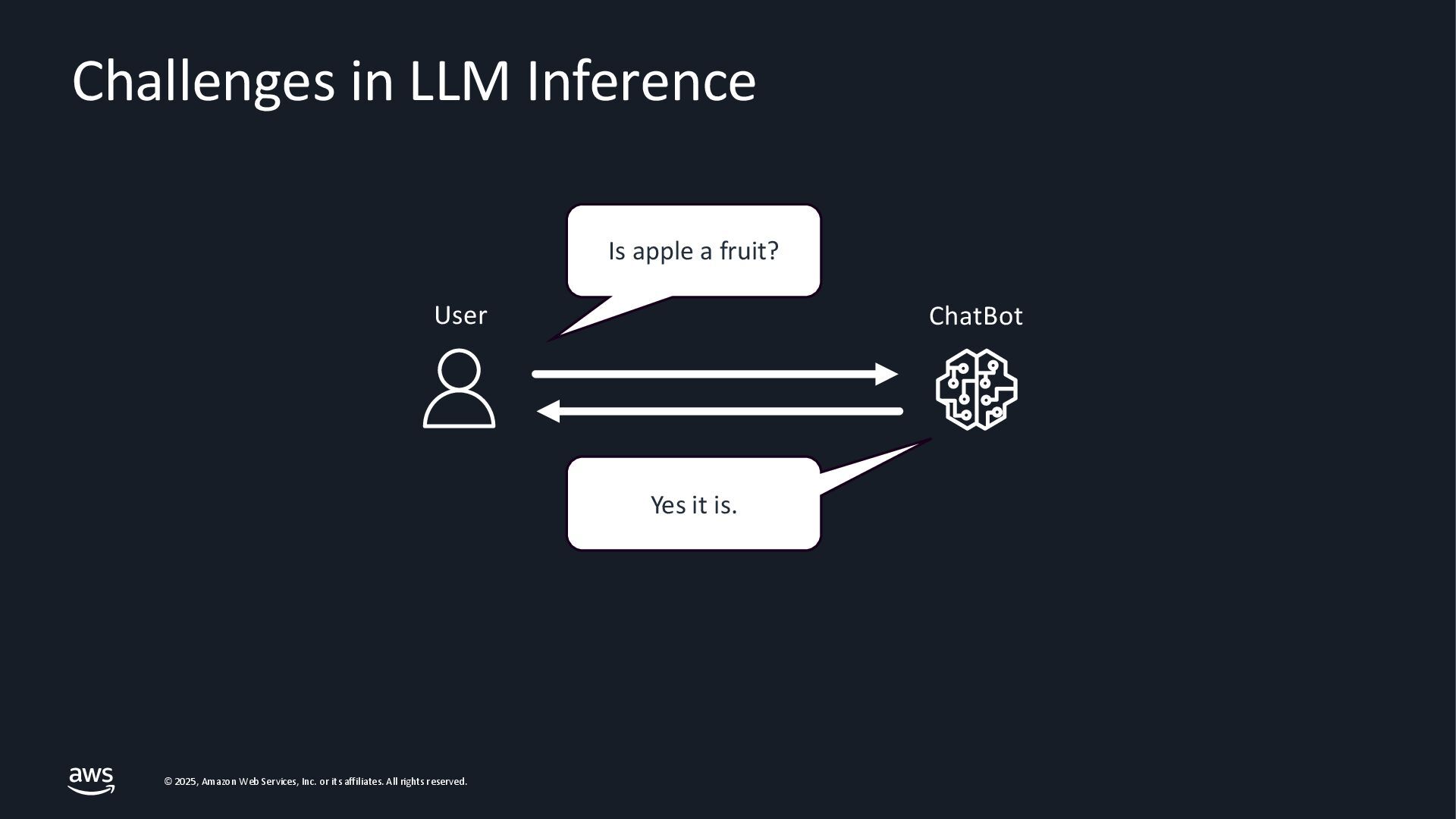{kind=link}
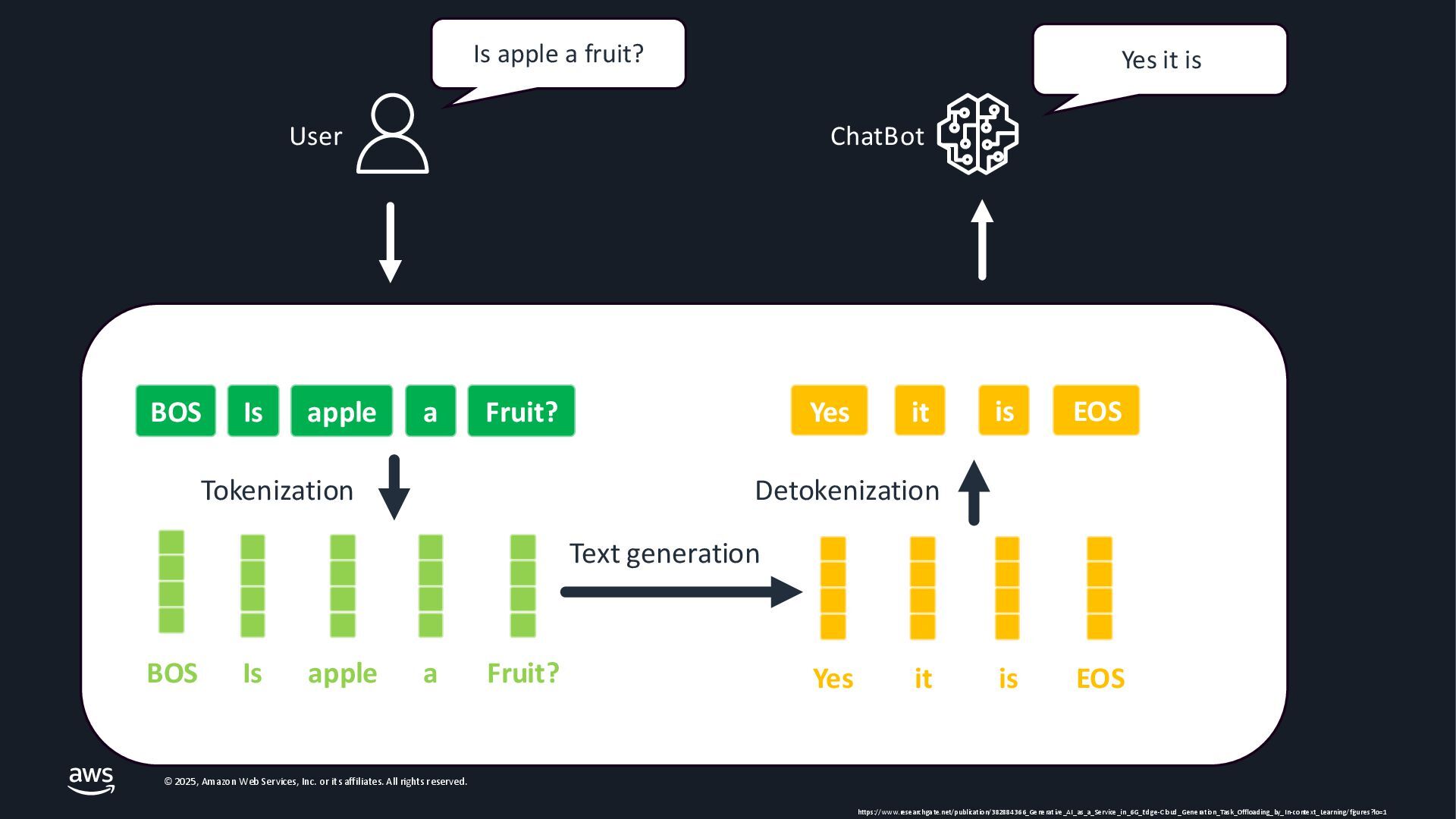{kind=link}
{kind=link}
{kind=link}
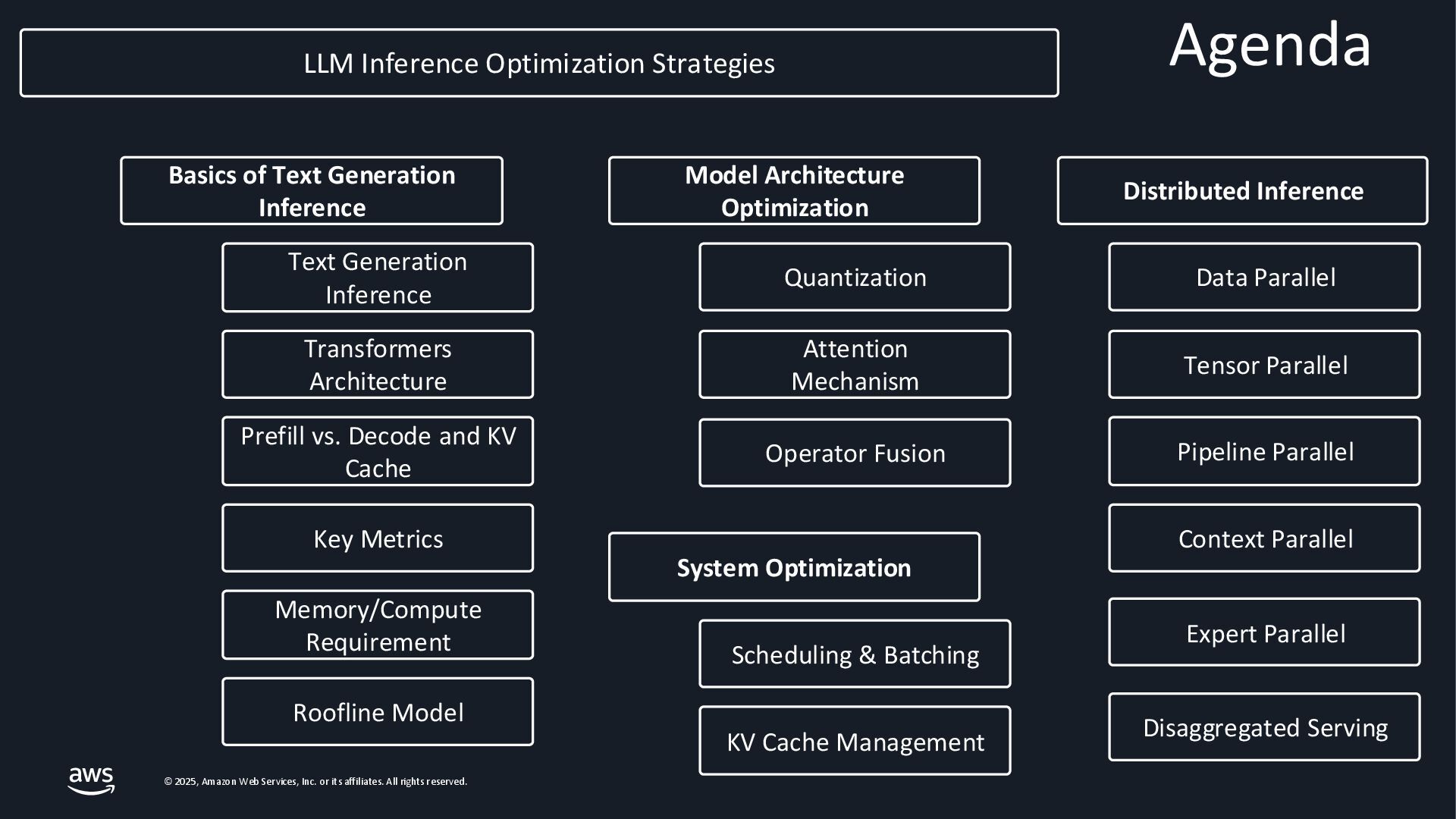{kind=link}
{kind=link}
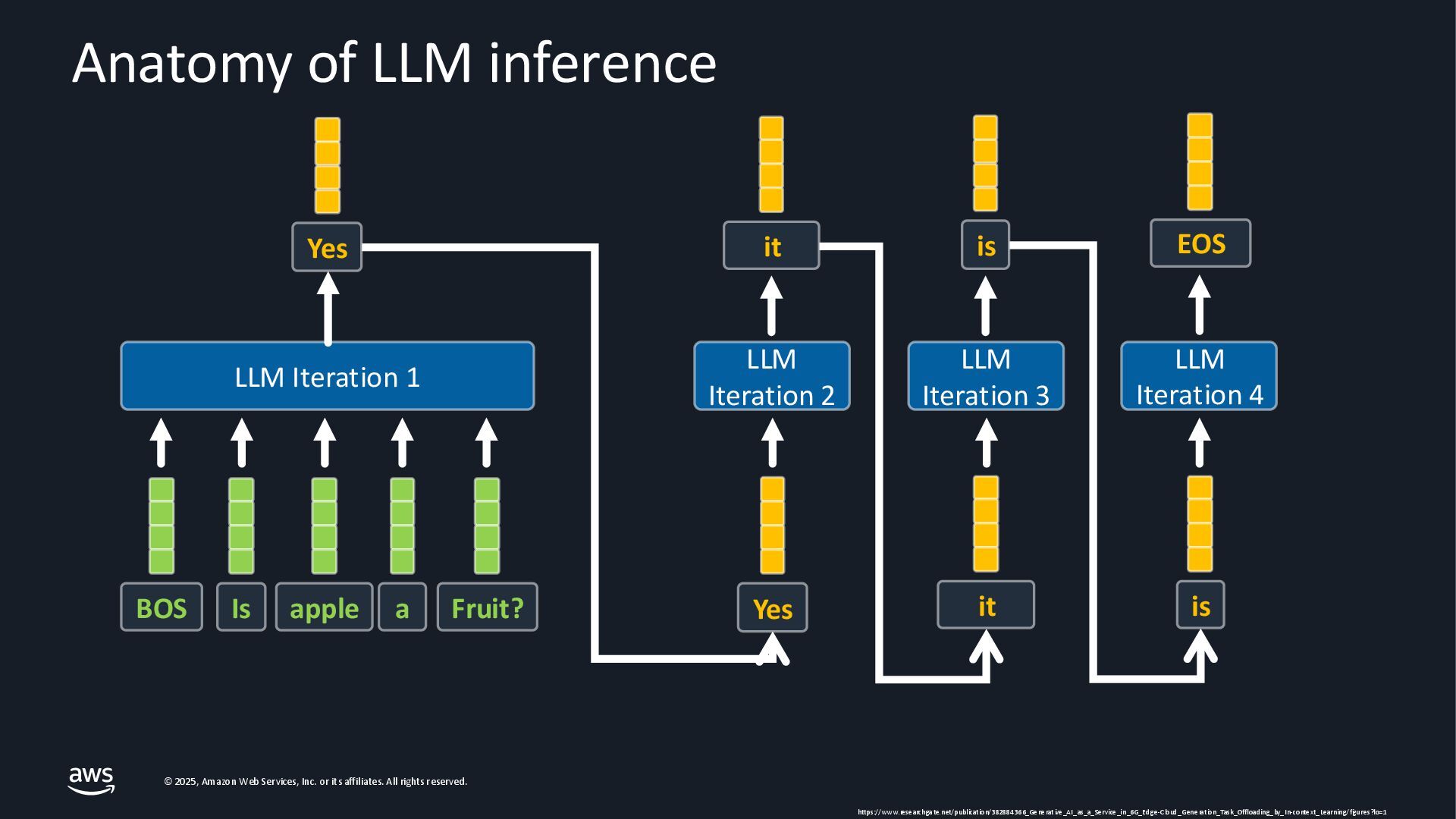{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
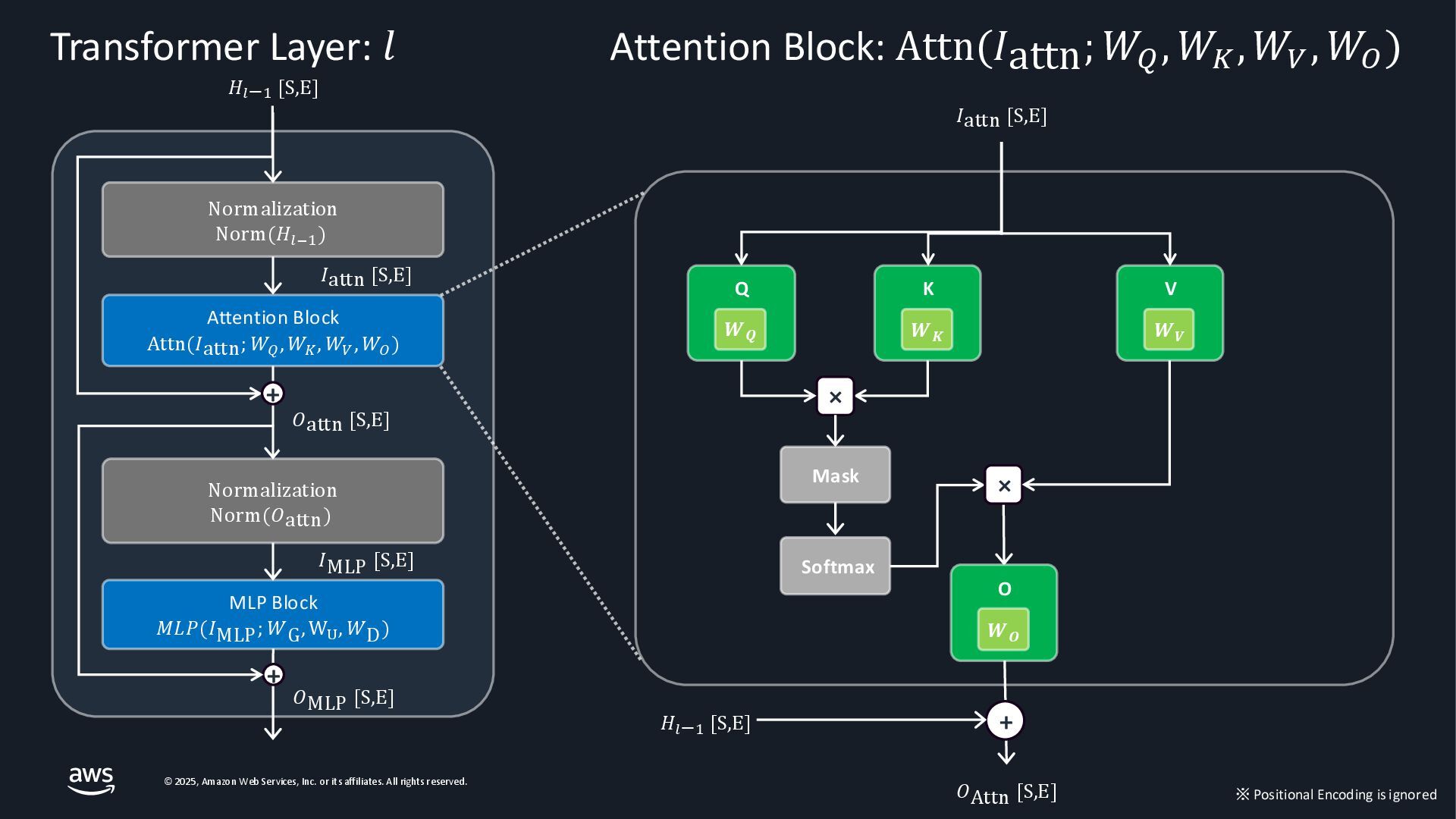{kind=link}
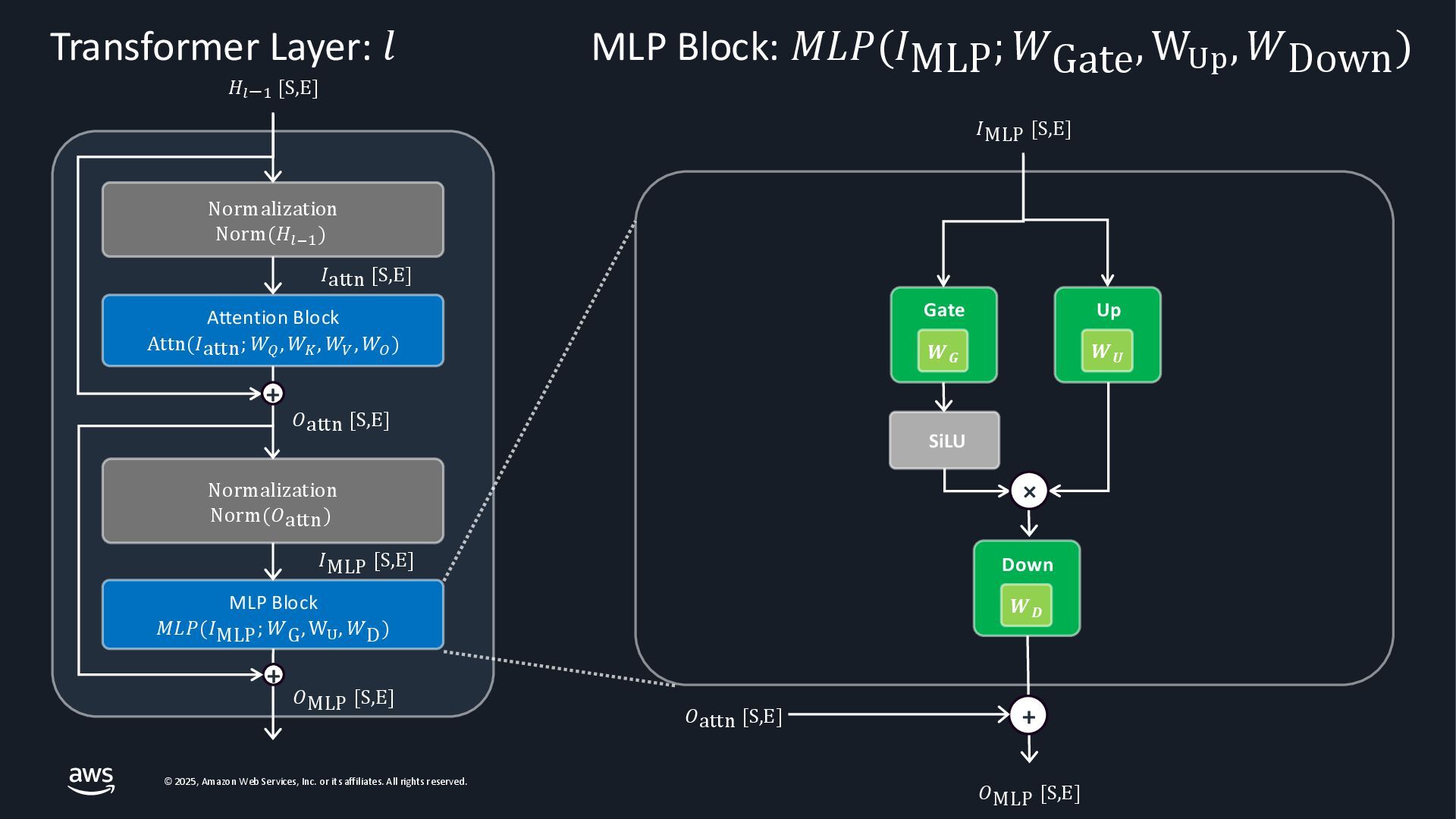{kind=link}
{kind=link}
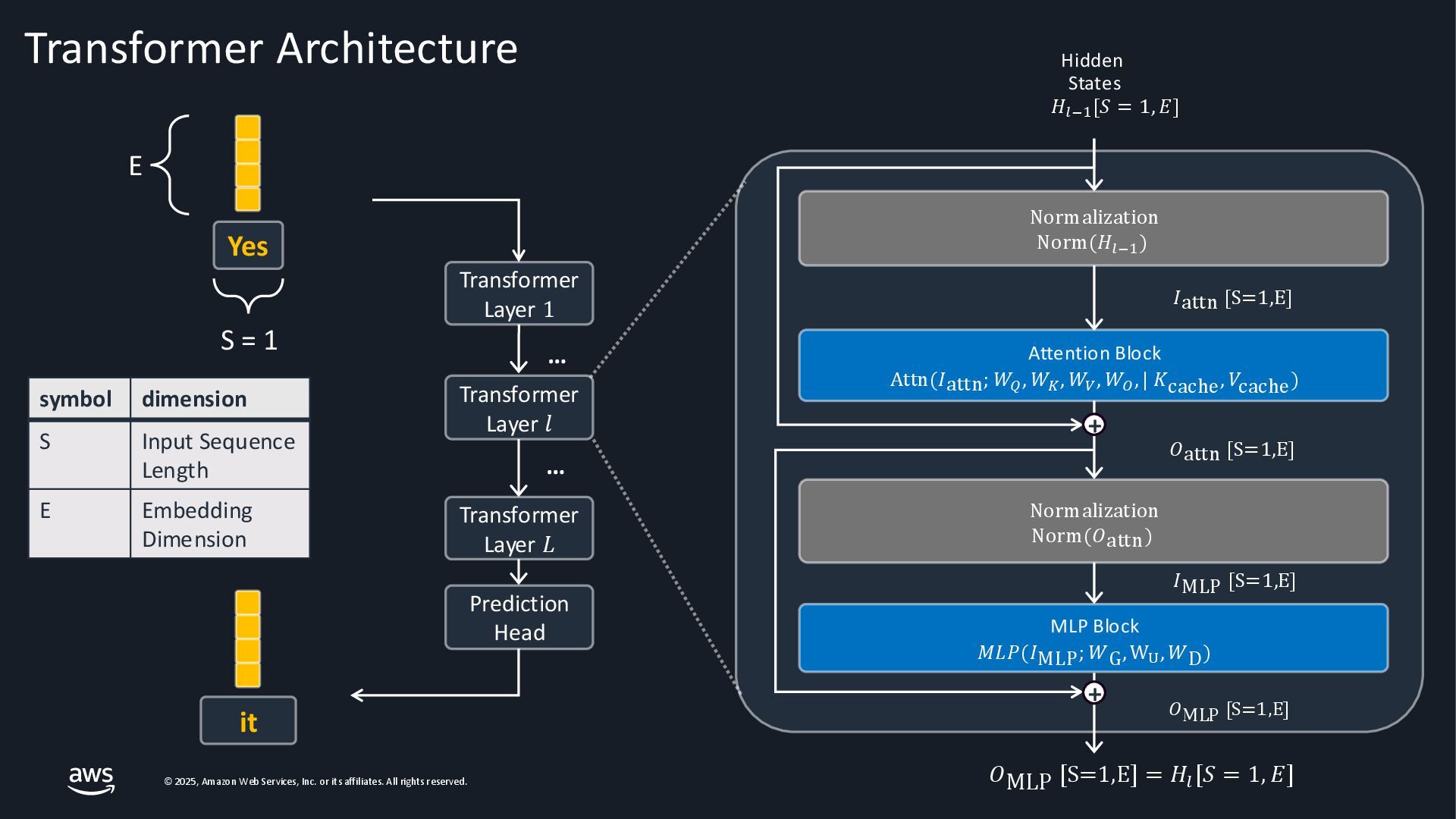{kind=link}
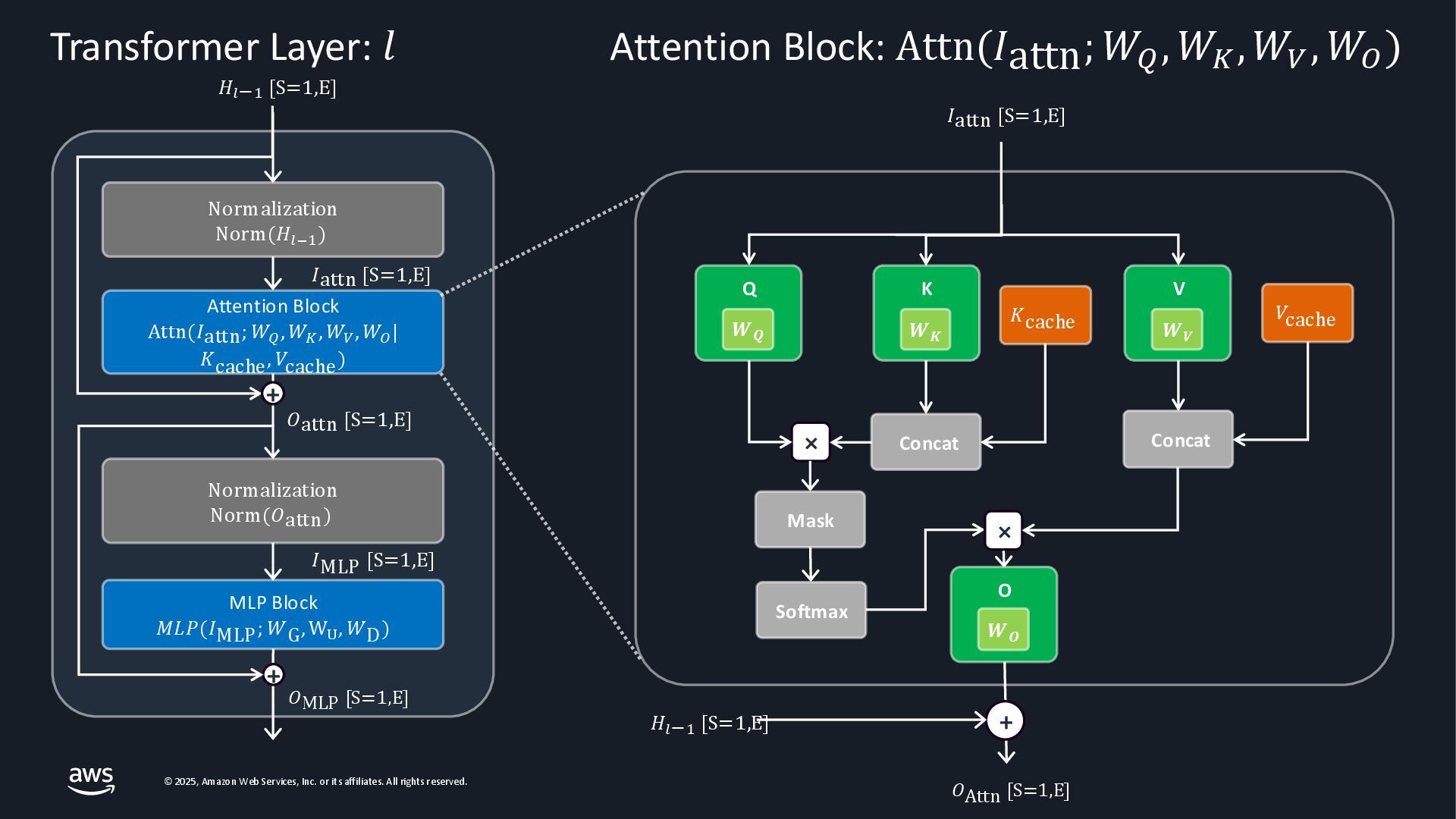{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
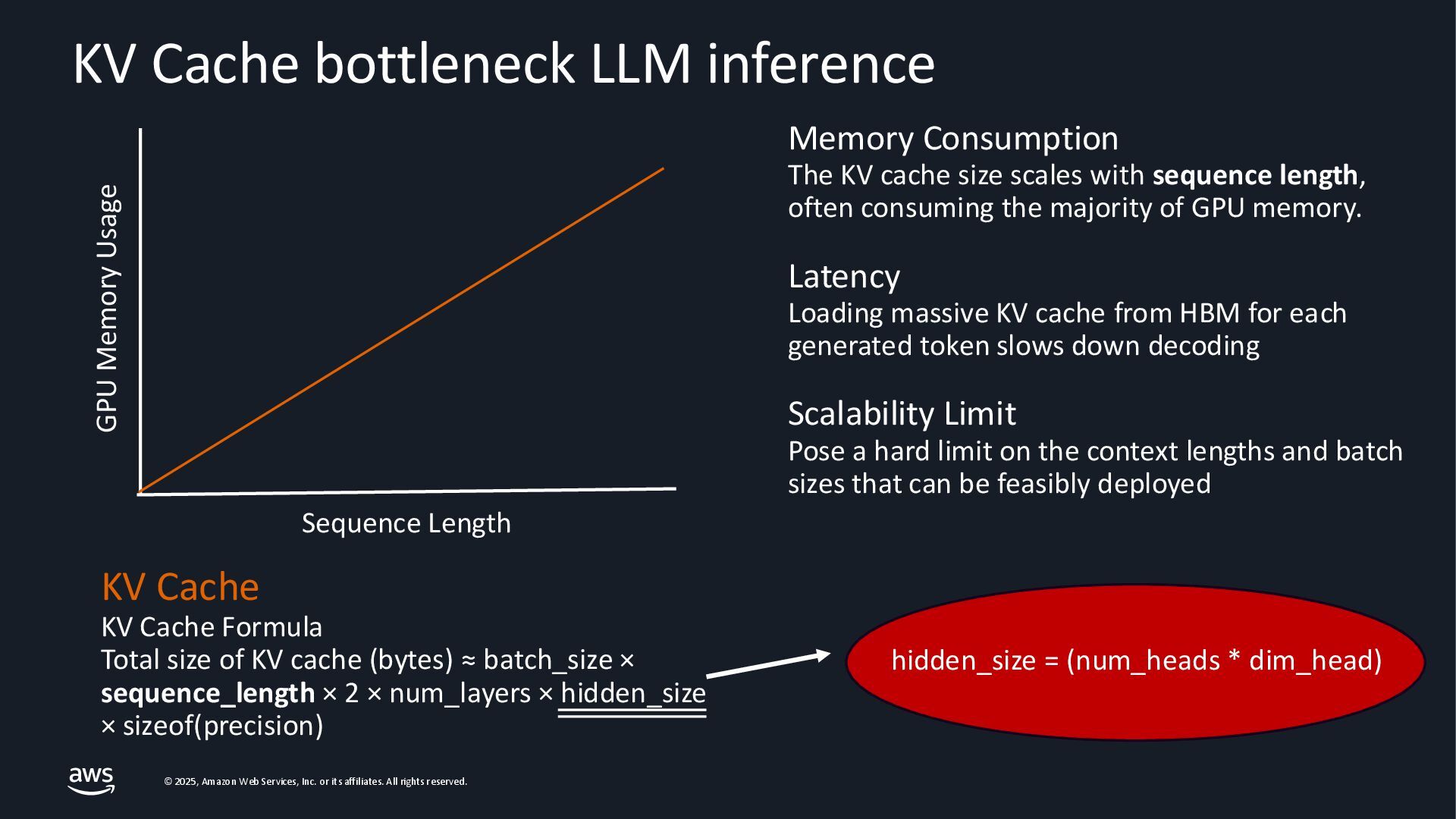{kind=link}
{kind=link}
{kind=link}
{kind=link}
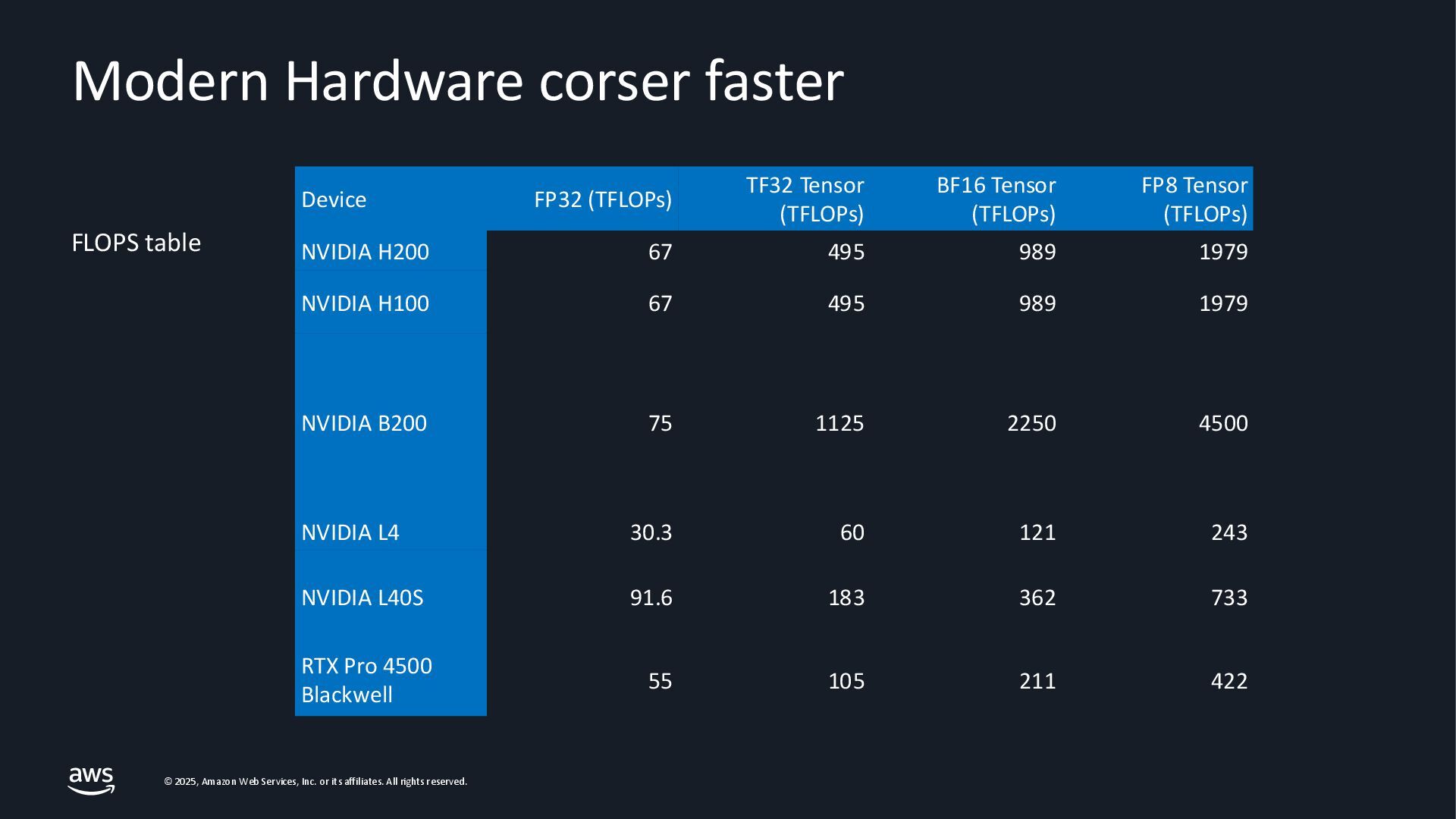{kind=link}
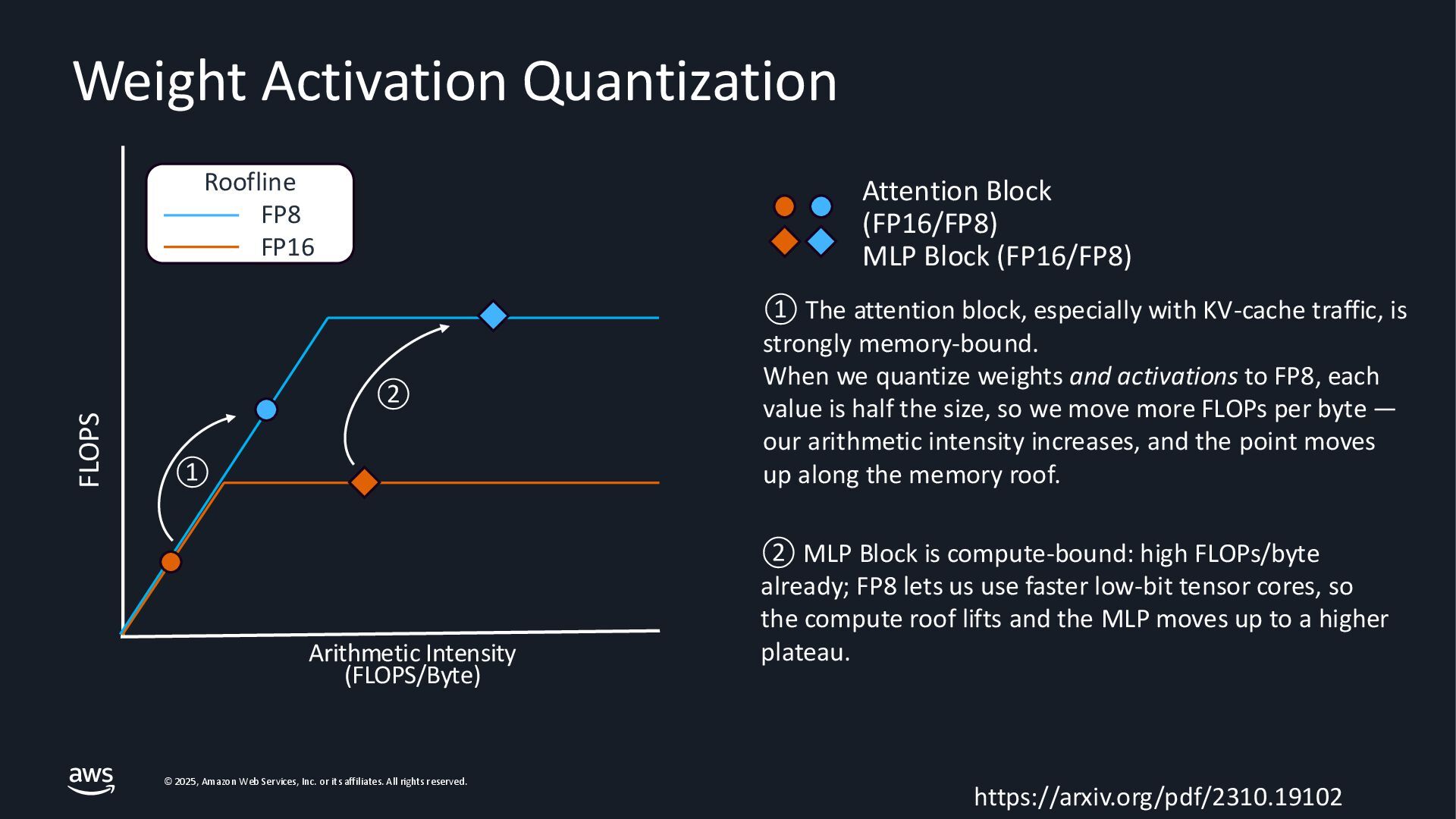{kind=link}
{kind=link}
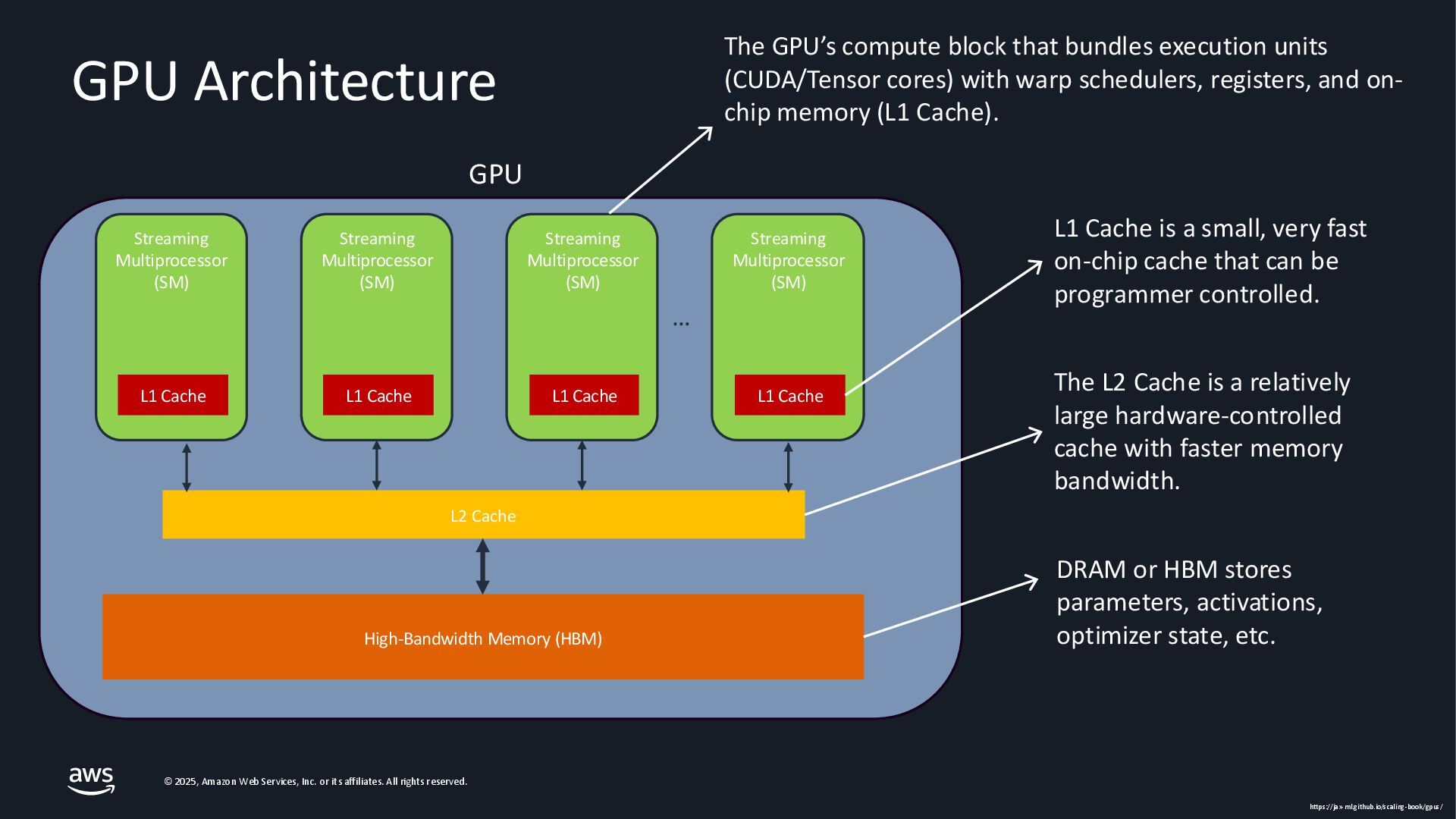{kind=link}
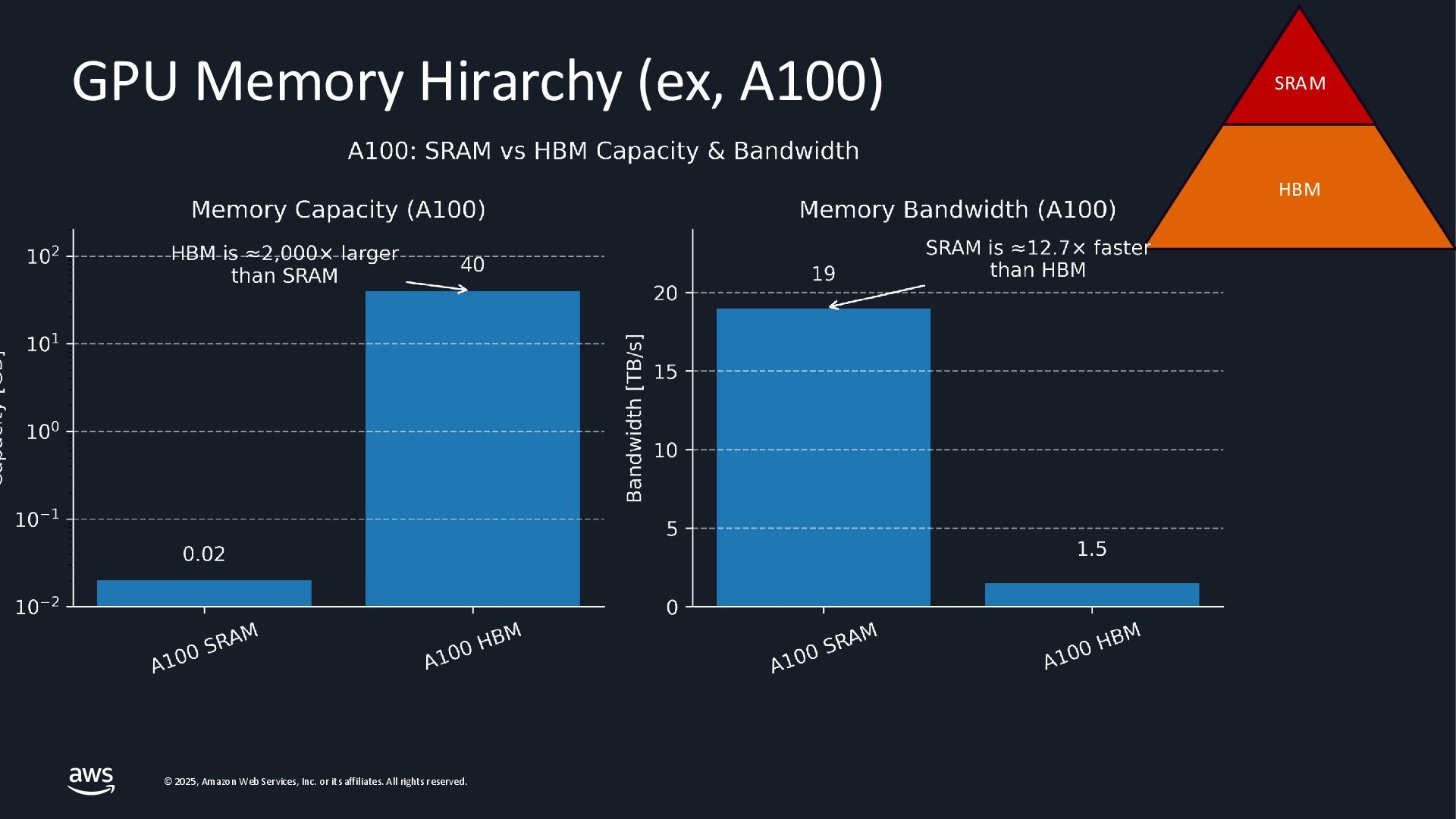{kind=link}
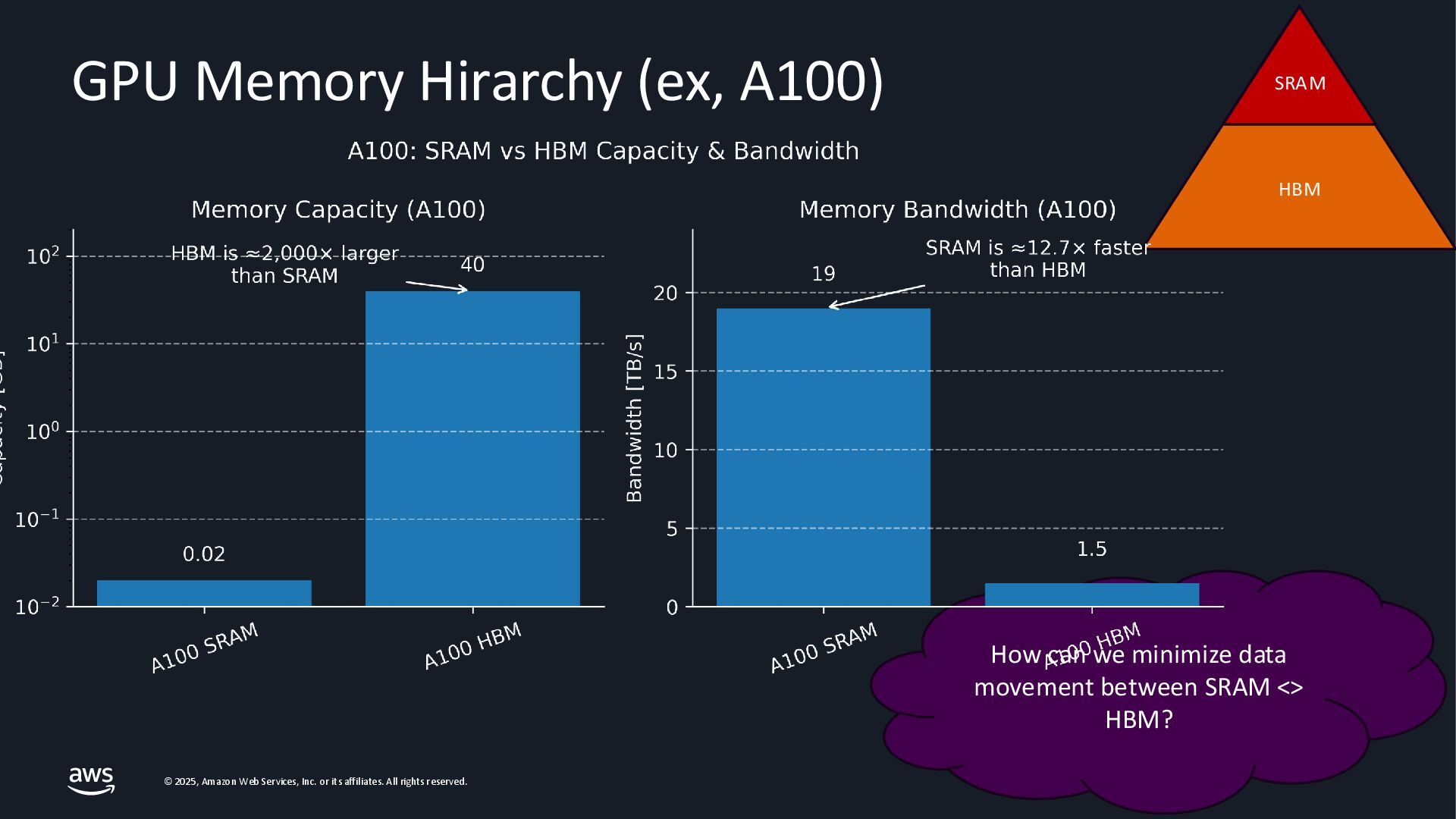{kind=link}
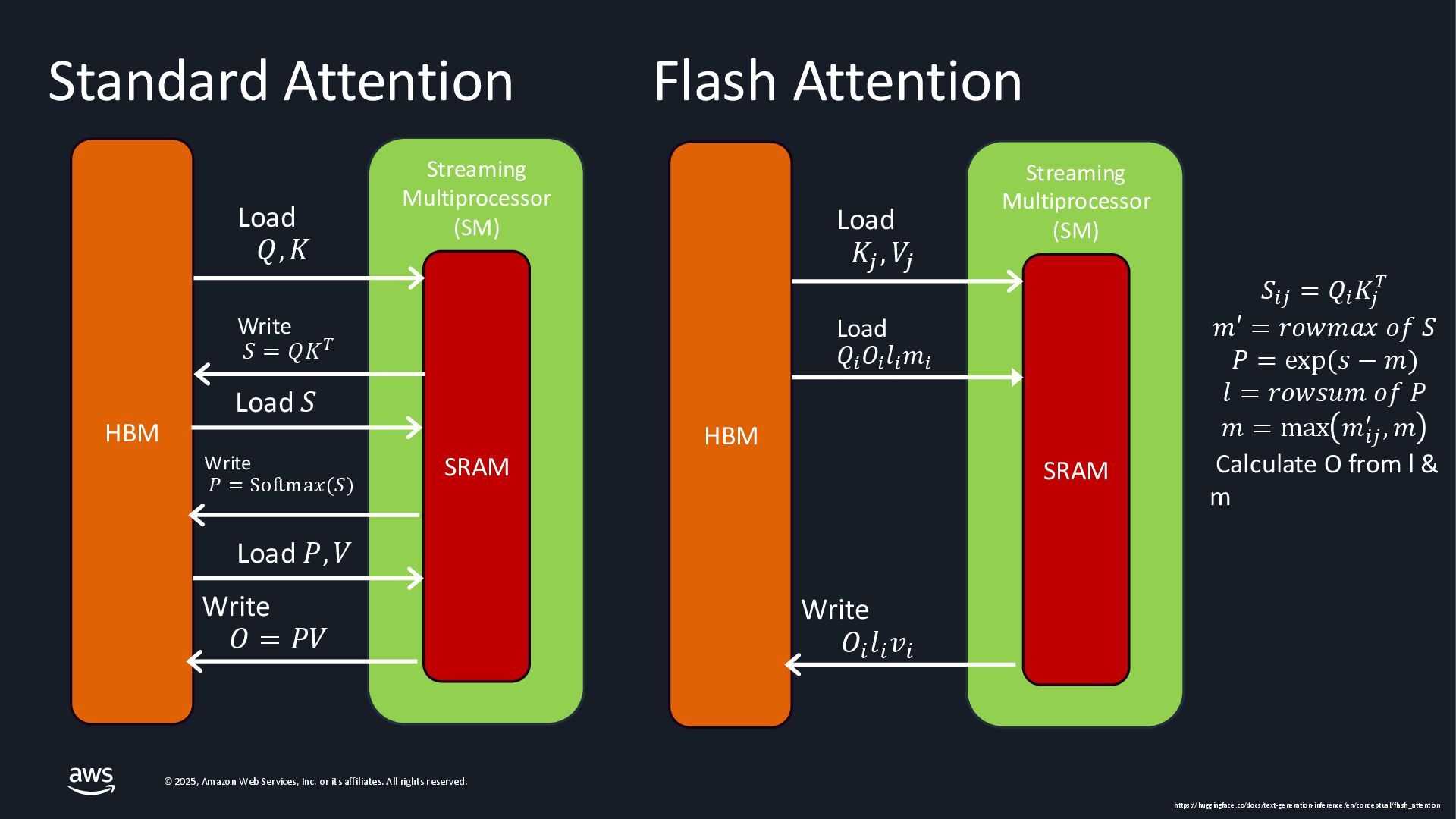{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
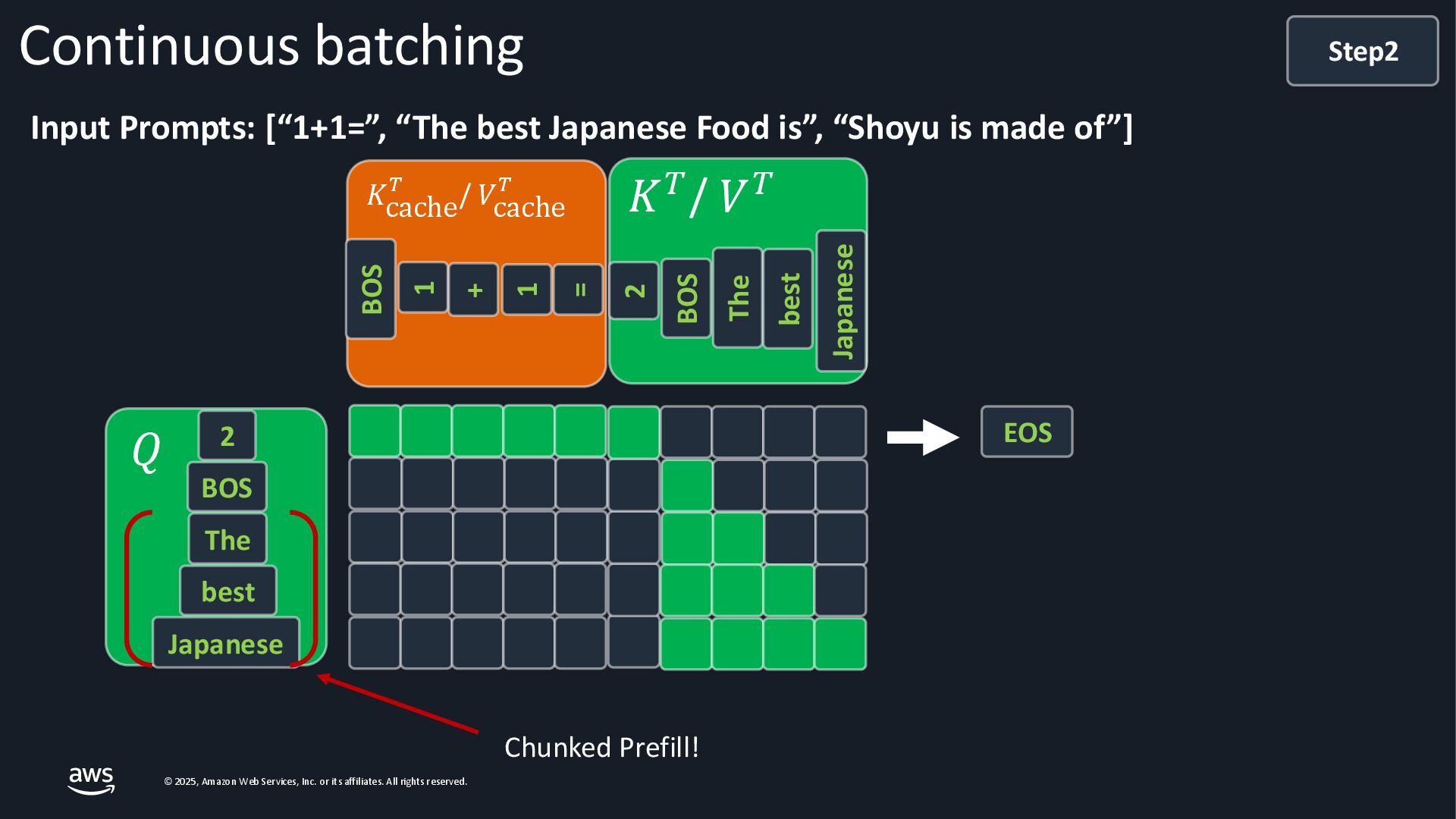{kind=link}
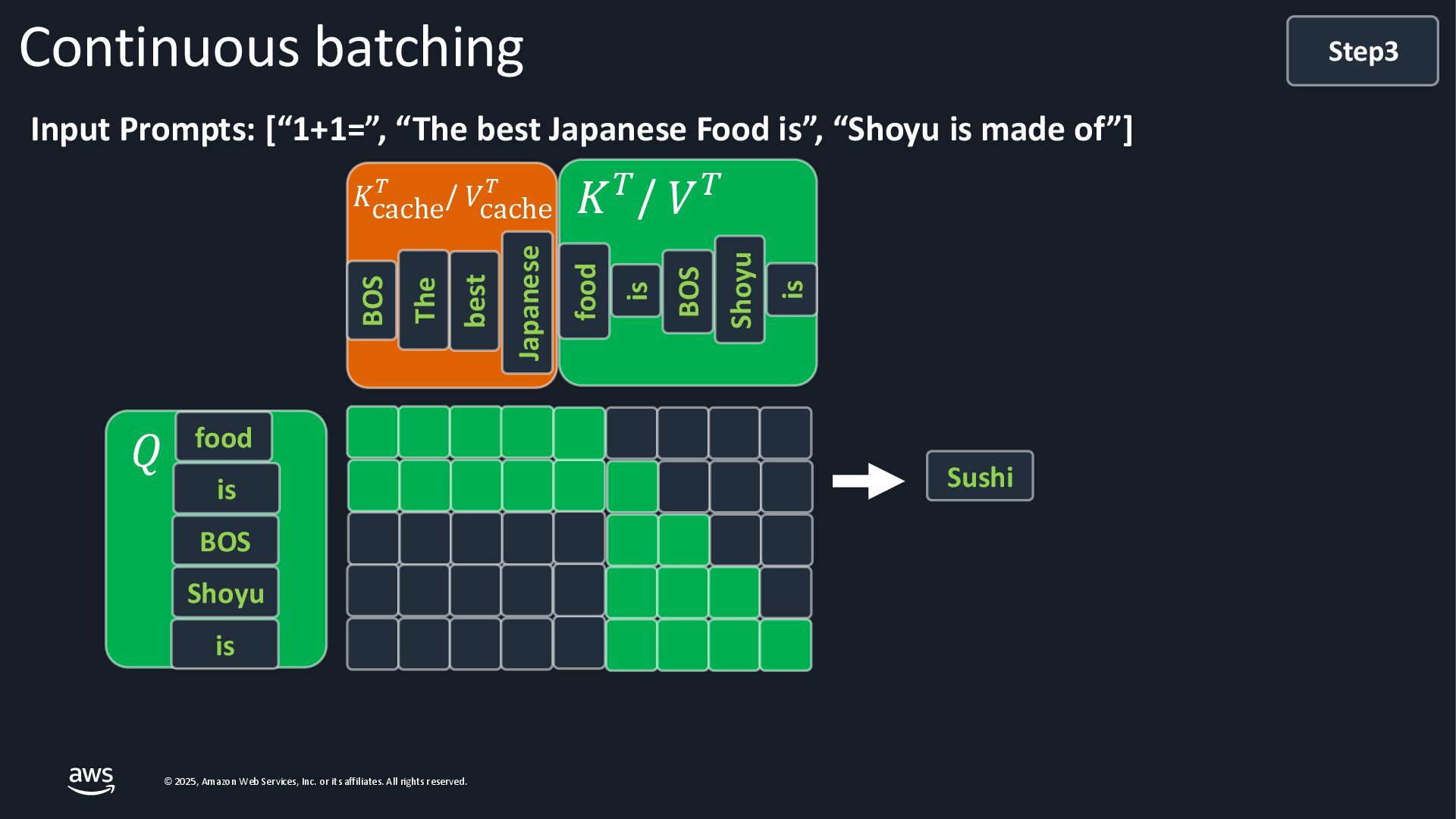{kind=link}
{kind=link}
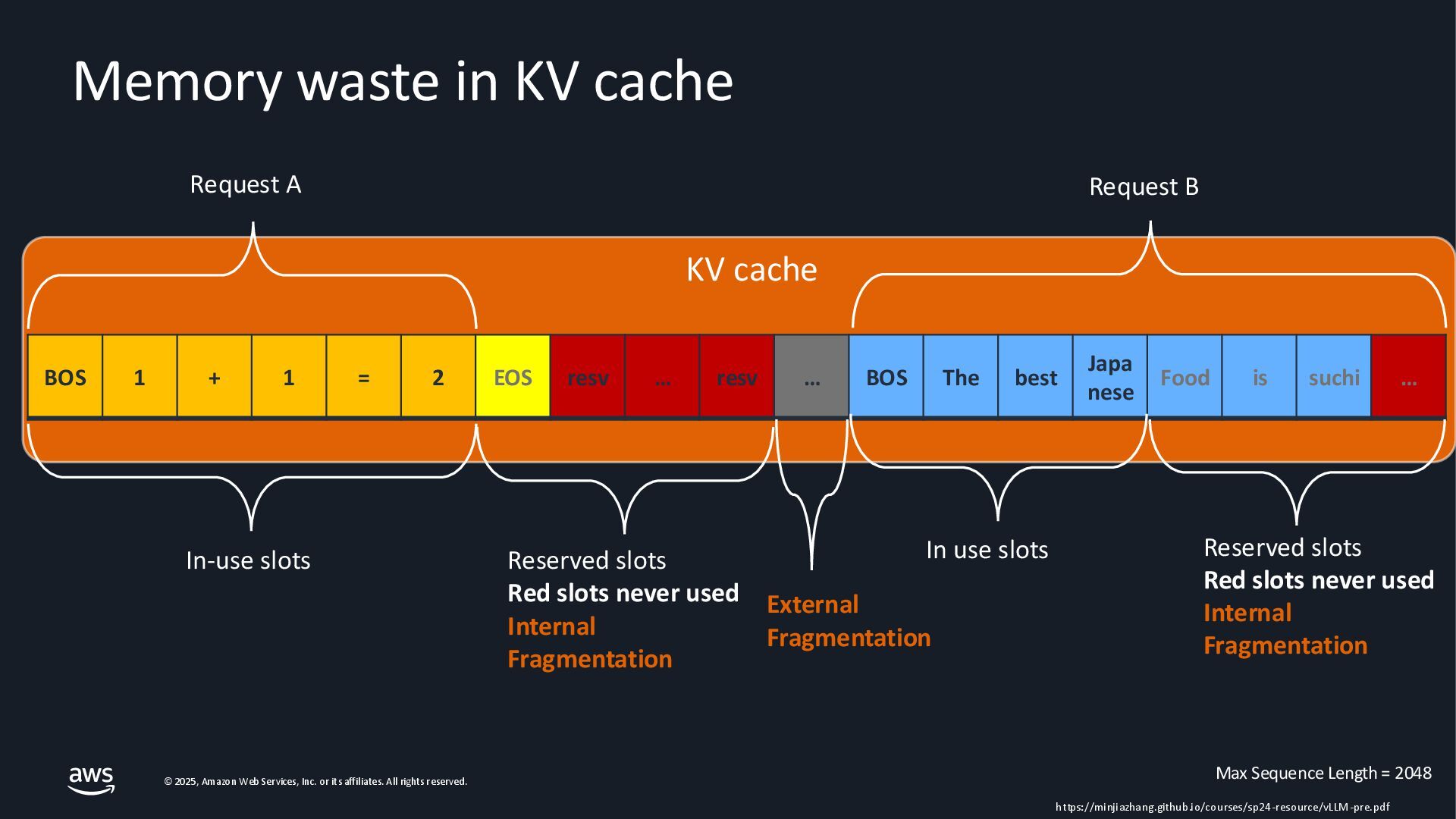{kind=link}
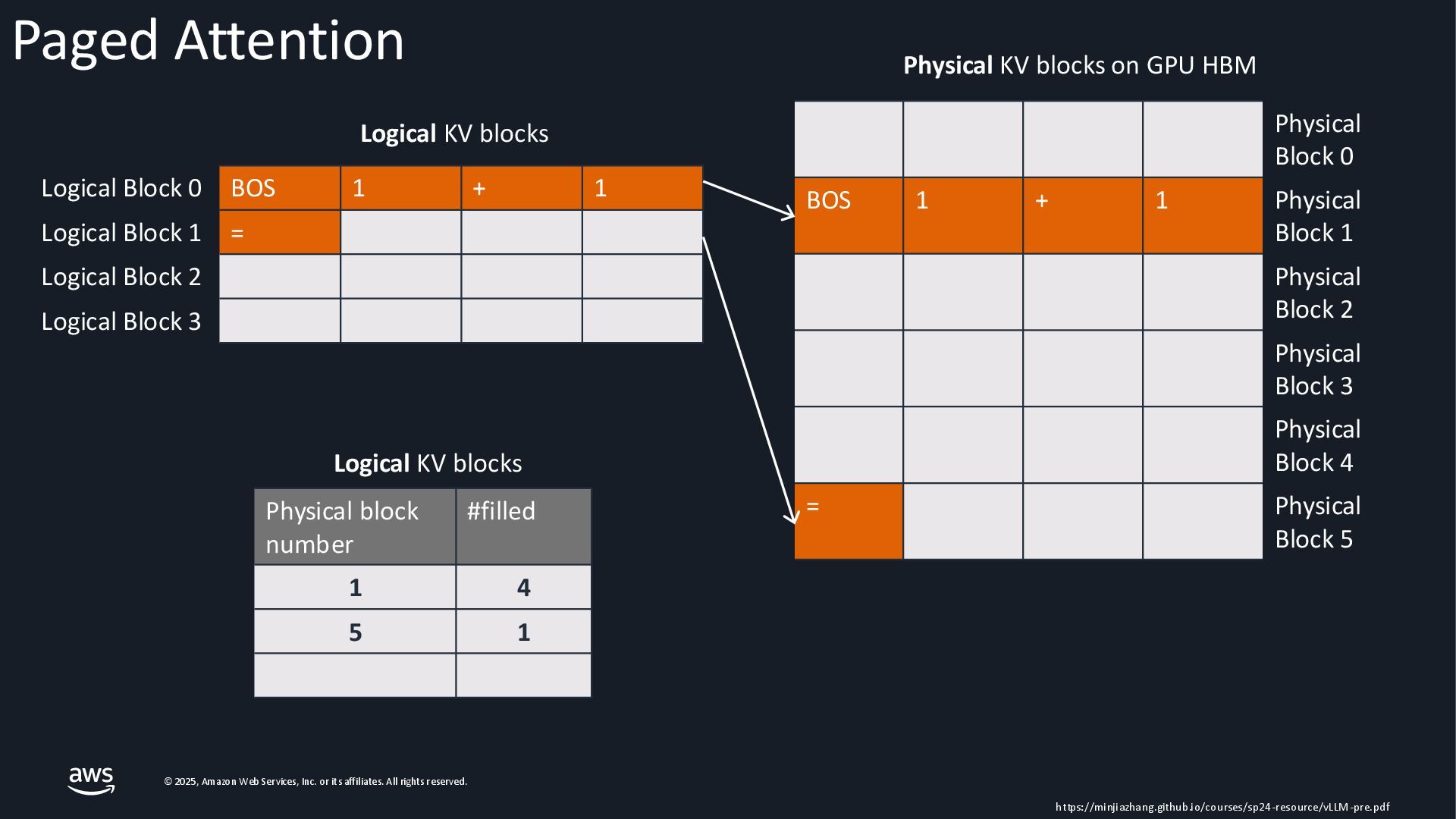{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}