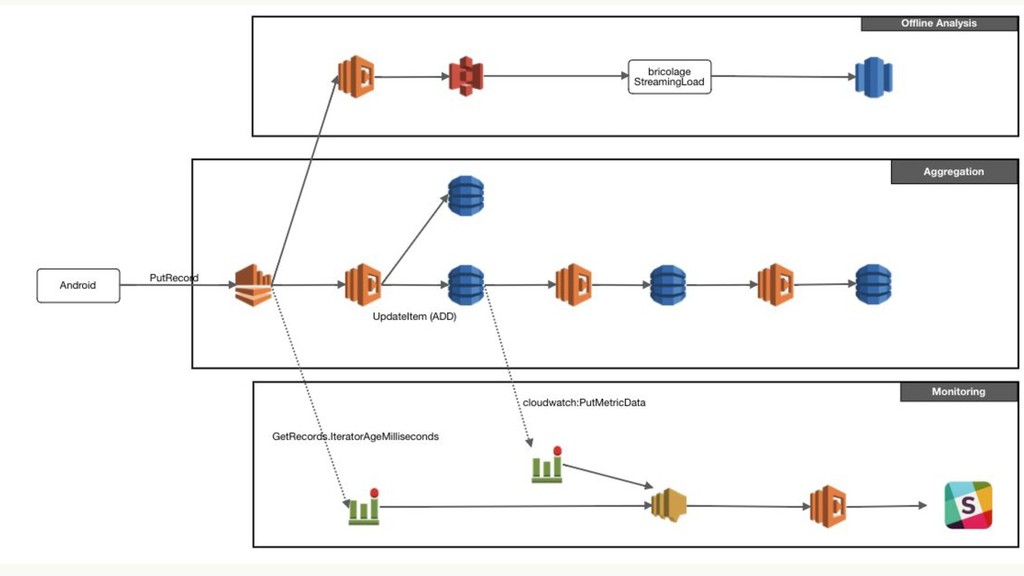
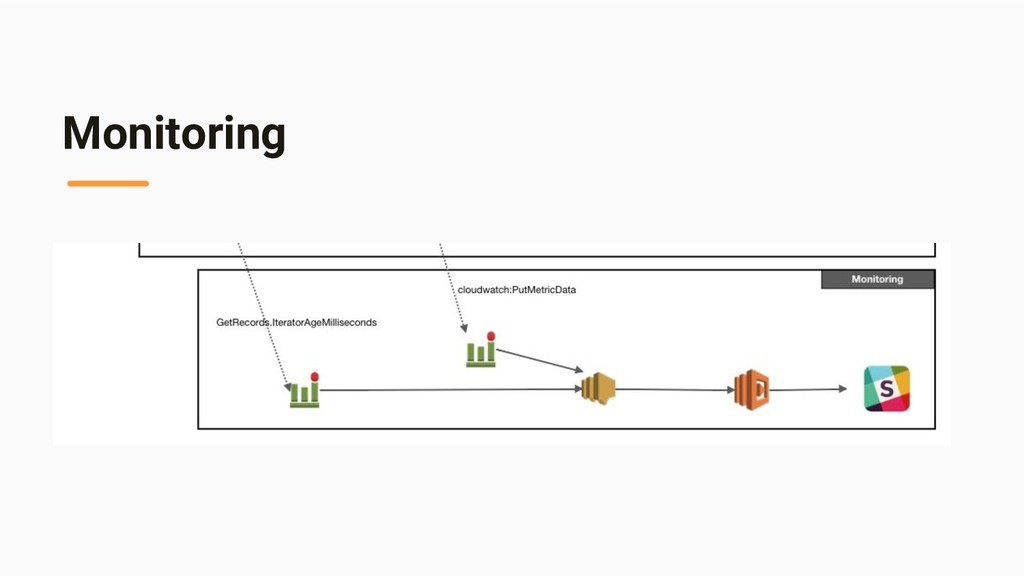
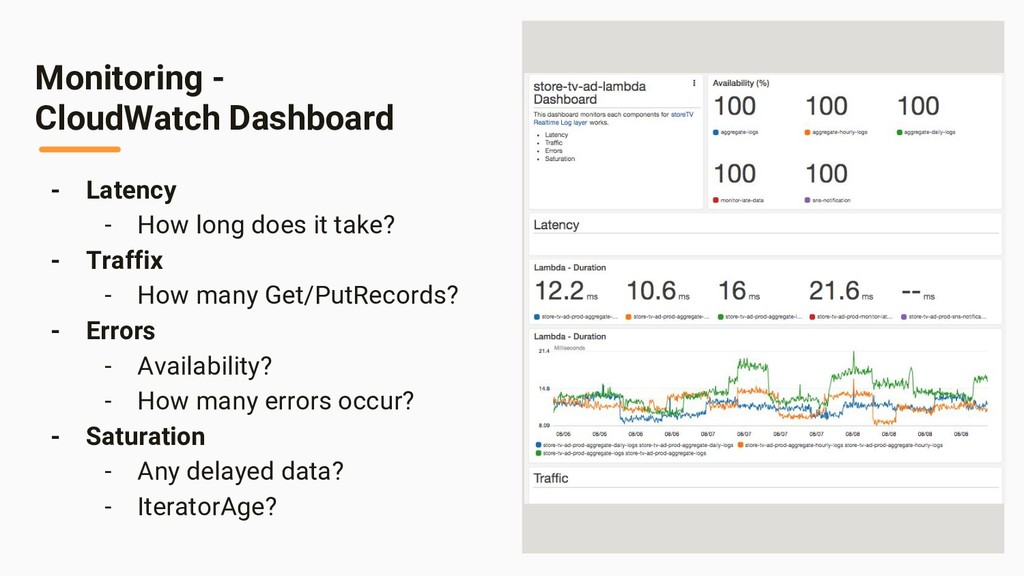
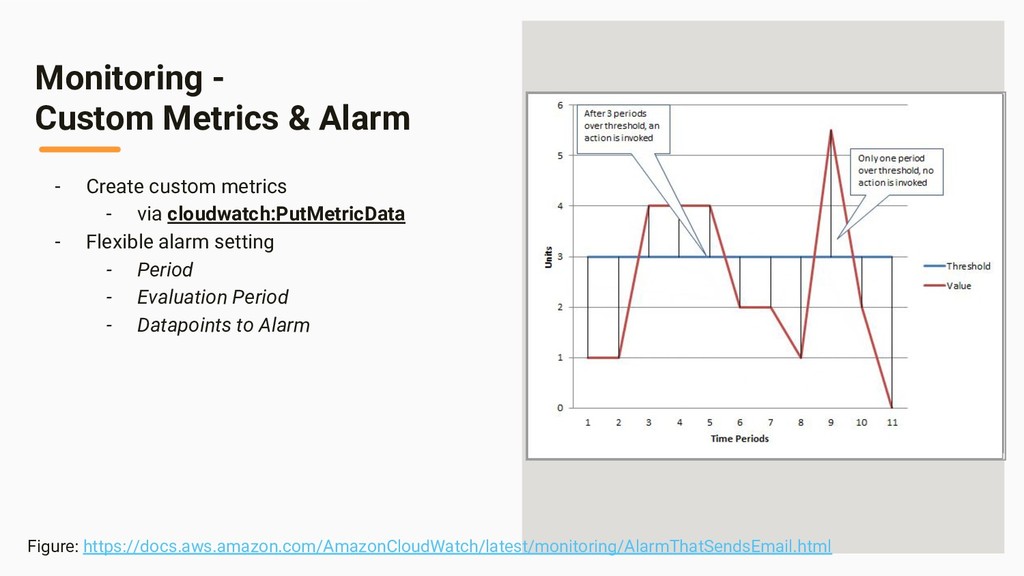
- “Batch” vs “Streaming” - “Event Time” vs “Processing Time” - Lambda Architecture - Kappa Architecture - Apache Hadoop/Storm/Spark/Kafka/Flink - Late Logs - Discarding, Watermark, Trigger, Accumulation Part II … Practice - Overall Data-flow - Watermark Implementation - Aggregation - Kinesis -> Lambda -> DynamoDB - DynamoDB Streams -> Lambda -> DynamoDB - Monitoring - “GetRecords.IteratorAgeMilliseconds” - DynamoDB Streams -> Lambda -> Slack - Misc (Cognito, Golang, Serverless Framework)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Watermark Implementation func (sr *StreamRecords) watermark(eventTimes []EventTime) (median EventTime) {](https://files.speakerdeck.com/presentations/85efd011db5545629180ec2ef69fb6af/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
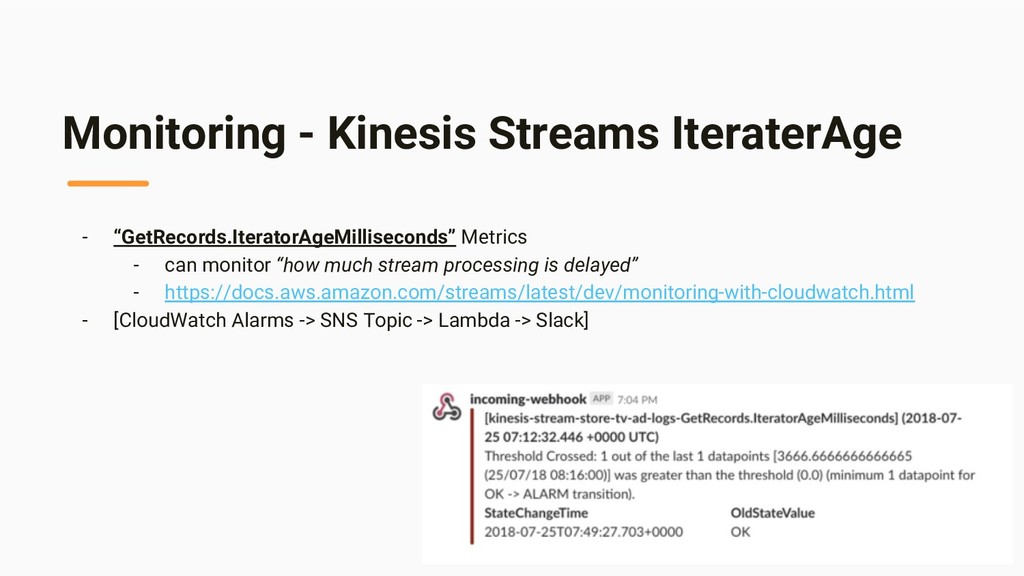{kind=link}
{kind=link}
{kind=link}
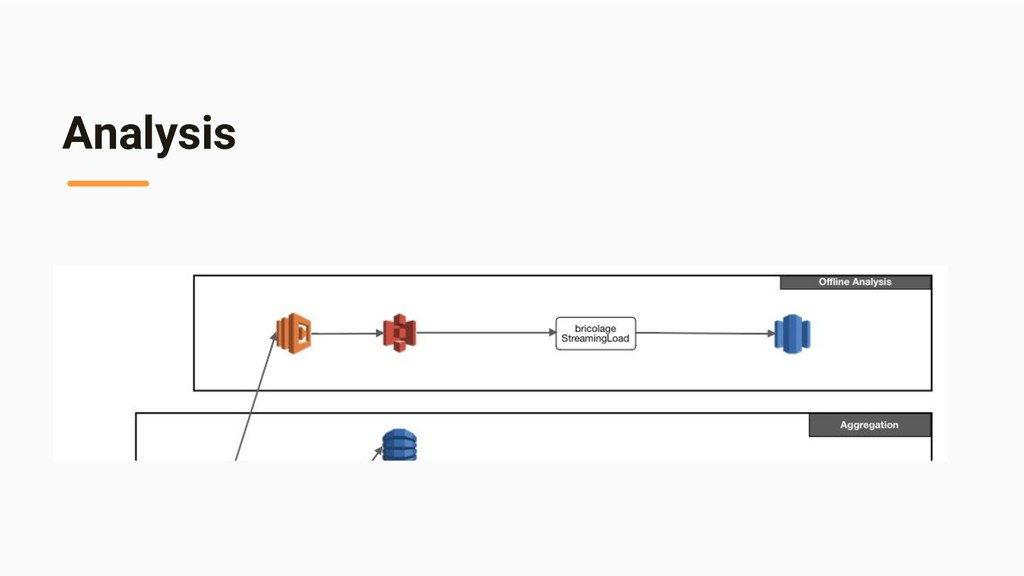{kind=link}
{kind=link}
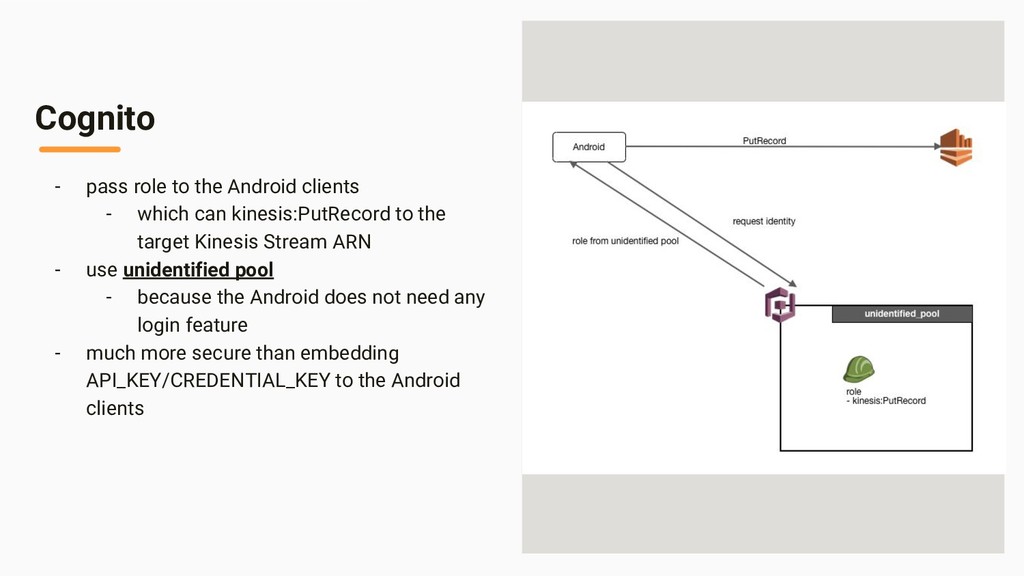{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[NOTE] Golang dependencies $ dep status PROJECT CONSTRAINT VERSION REVISION](https://files.speakerdeck.com/presentations/85efd011db5545629180ec2ef69fb6af/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}