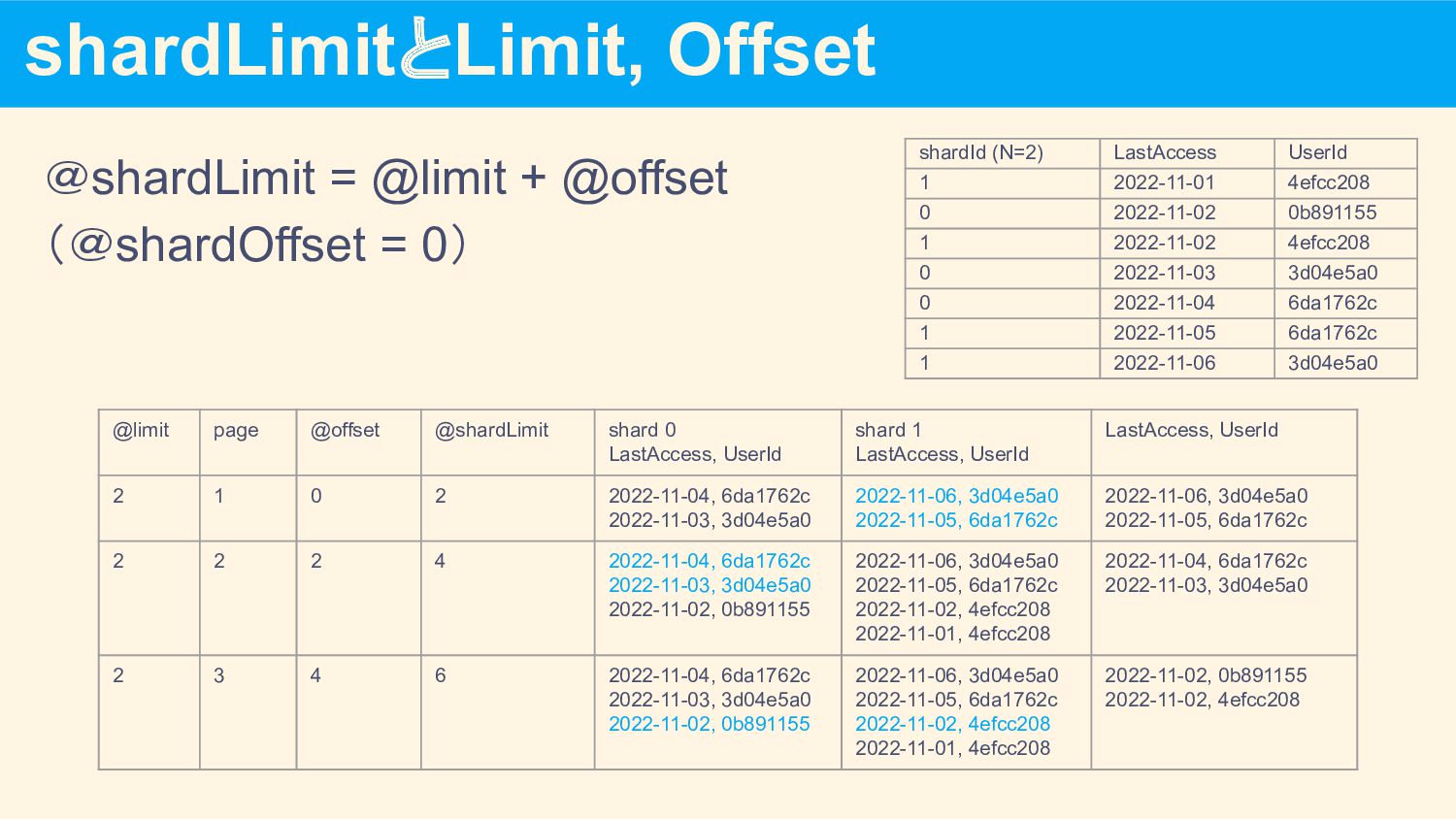
shardId (N=2) LastAccess UserId 1 2022-11-01 4efcc208 0 2022-11-02 0b891155 1 2022-11-02 4efcc208 0 2022-11-03 3d04e5a0 0 2022-11-04 6da1762c 1 2022-11-05 6da1762c 1 2022-11-06 3d04e5a0 @limit page @offset @shardLimit shard 0 LastAccess, UserId shard 1 LastAccess, UserId LastAccess, UserId 2 1 0 2 2022-11-04, 6da1762c 2022-11-03, 3d04e5a0 2022-11-06, 3d04e5a0 2022-11-05, 6da1762c 2022-11-06, 3d04e5a0 2022-11-05, 6da1762c 2 2 2 4 2022-11-04, 6da1762c 2022-11-03, 3d04e5a0 2022-11-02, 0b891155 2022-11-06, 3d04e5a0 2022-11-05, 6da1762c 2022-11-02, 4efcc208 2022-11-01, 4efcc208 2022-11-04, 6da1762c 2022-11-03, 3d04e5a0 2 3 4 6 2022-11-04, 6da1762c 2022-11-03, 3d04e5a0 2022-11-02, 0b891155 2022-11-06, 3d04e5a0 2022-11-05, 6da1762c 2022-11-02, 4efcc208 2022-11-01, 4efcc208 2022-11-02, 0b891155 2022-11-02, 4efcc208
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GENERATE_ARRAY, UNNEST Goで雰囲気を表現してみると、 for _, OneShardId := range []int{0, 1,](https://files.speakerdeck.com/presentations/1da04419f3fa4266a6516c38b32c8b2d/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}