official, yet still optional, way to run Python without the Global Interpreter Lock (GIL). What does it mean? True parallelism for your threads. Before After Thread 1 Thread 2 Thread 3 CPU Cores GIL ü Officially supported in Python 3.14 Thread 1 Thread 2 Thread 3
recap of concurrency concepts. 2.The Evidence Head-to-head benchmarks: threading vs. multiprocessing. 3.The Real World Applying it to a Machine Learning workload. 4.Your Playbook How to choose the right tool and avoid common pitfalls.
recap of concurrency concepts. 2.The Evidence Head-to-head benchmarks: threading vs. multiprocessing. 3.The Real World Applying it to a Machine Learning workload. 4.Your Playbook How to choose the right tool and avoid common pitfalls.
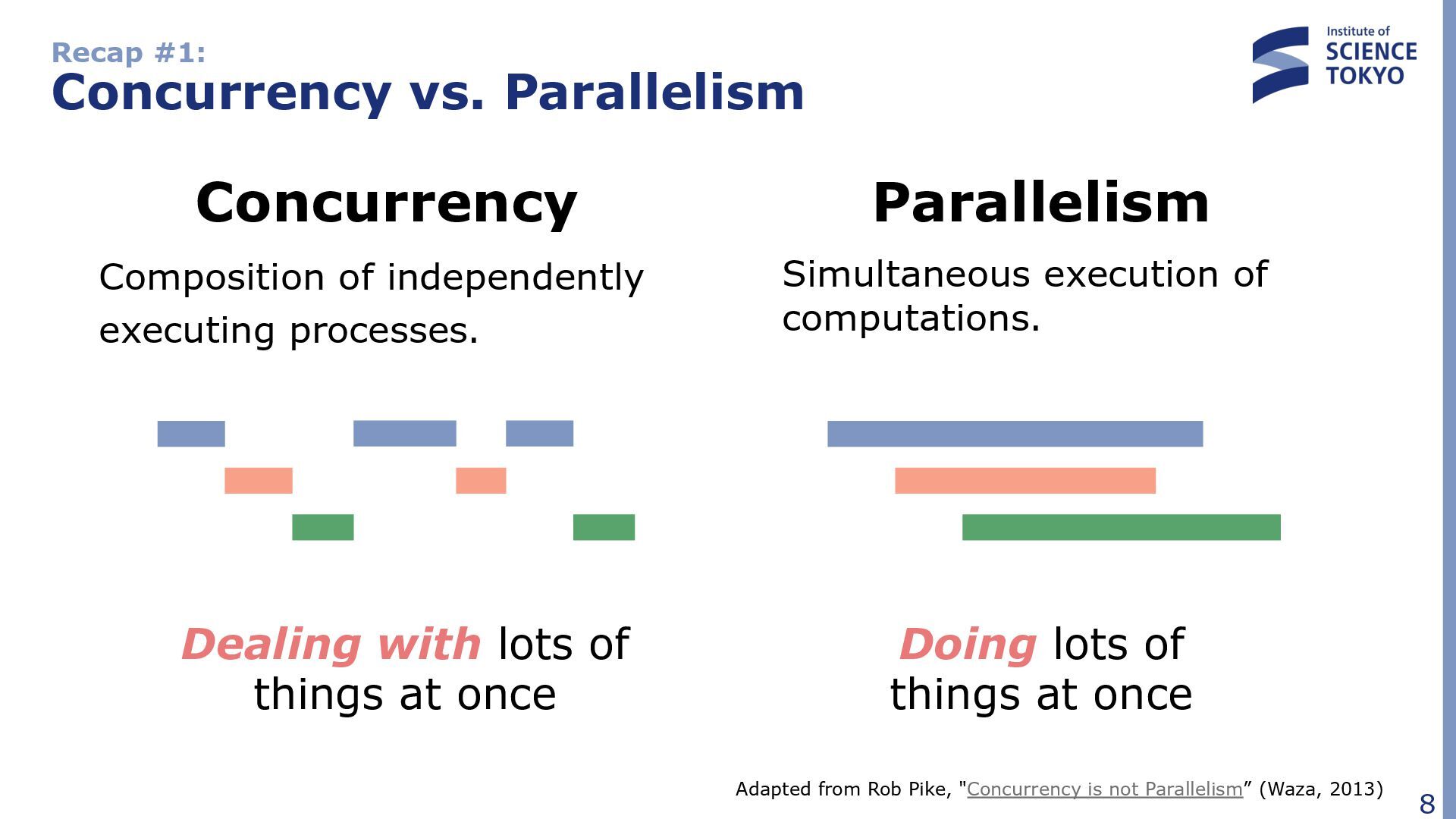
vs. Parallelism Adapted from Rob Pike, "Concurrency is not Parallelism” (Waza, 2013) Parallelism Simultaneous execution of computations. Dealing with lots of things at once Doing lots of things at once
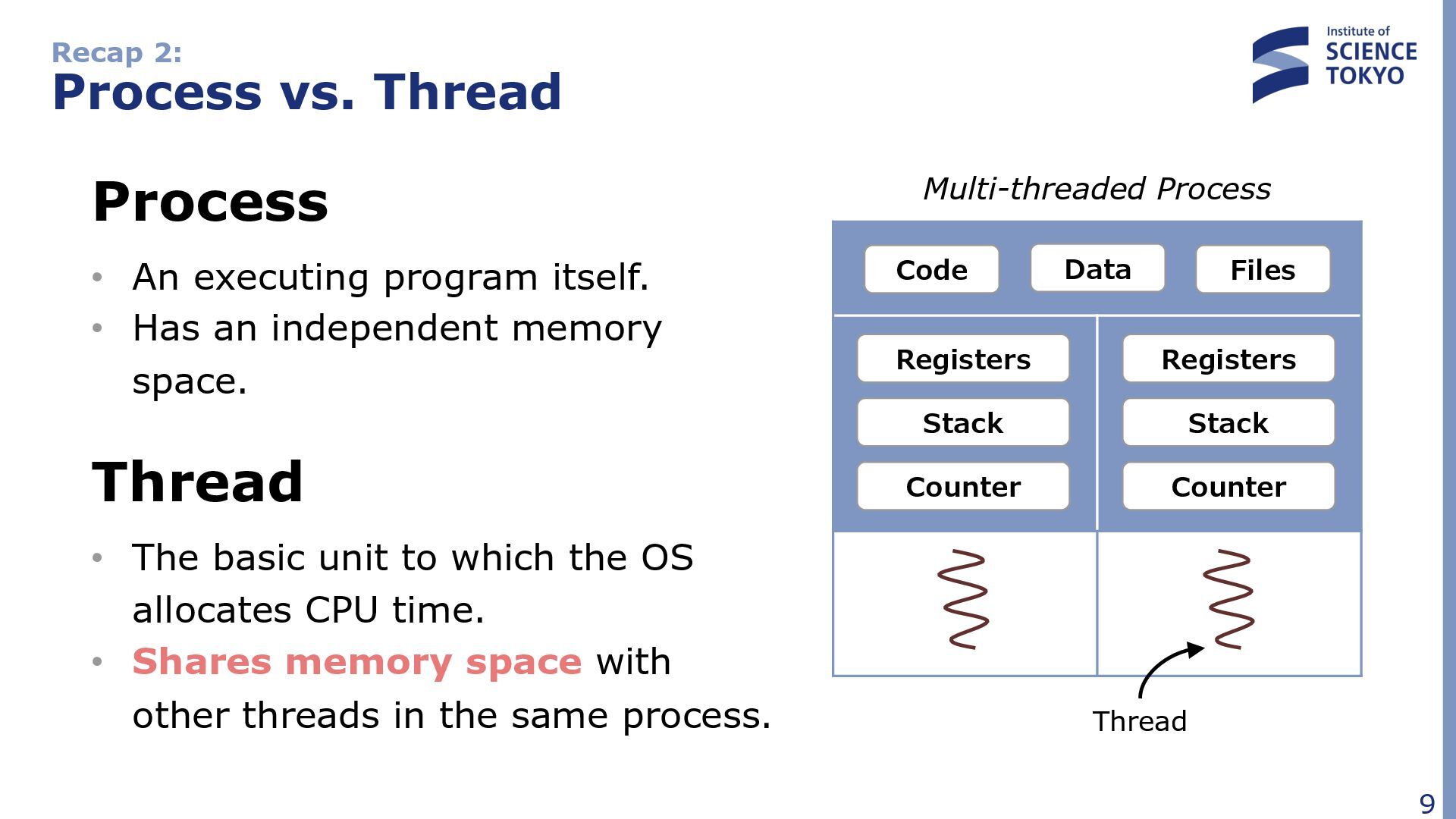
program itself. • Has an independent memory space. Thread • The basic unit to which the OS allocates CPU time. • Shares memory space with other threads in the same process. Code Data Files Registers Registers Stack Stack Counter Counter Multi-threaded Process Thread
Model Concurrent Parallel Parallel Unit Thread Process GIL Impact Yes No No Best For I/O-Bound + CPU-Bound CPU-Bound Memory Space Shared Independent Overhead Low High Free-threading fundamentally changes the game for the threading module, making it a true parallel contender.
recap of concurrency concepts. 2.The Evidence Head-to-head benchmarks: threading vs. multiprocessing. 3.The Real World Applying it to a Machine Learning workload. 4.Your Playbook How to choose the right tool and avoid common pitfalls.
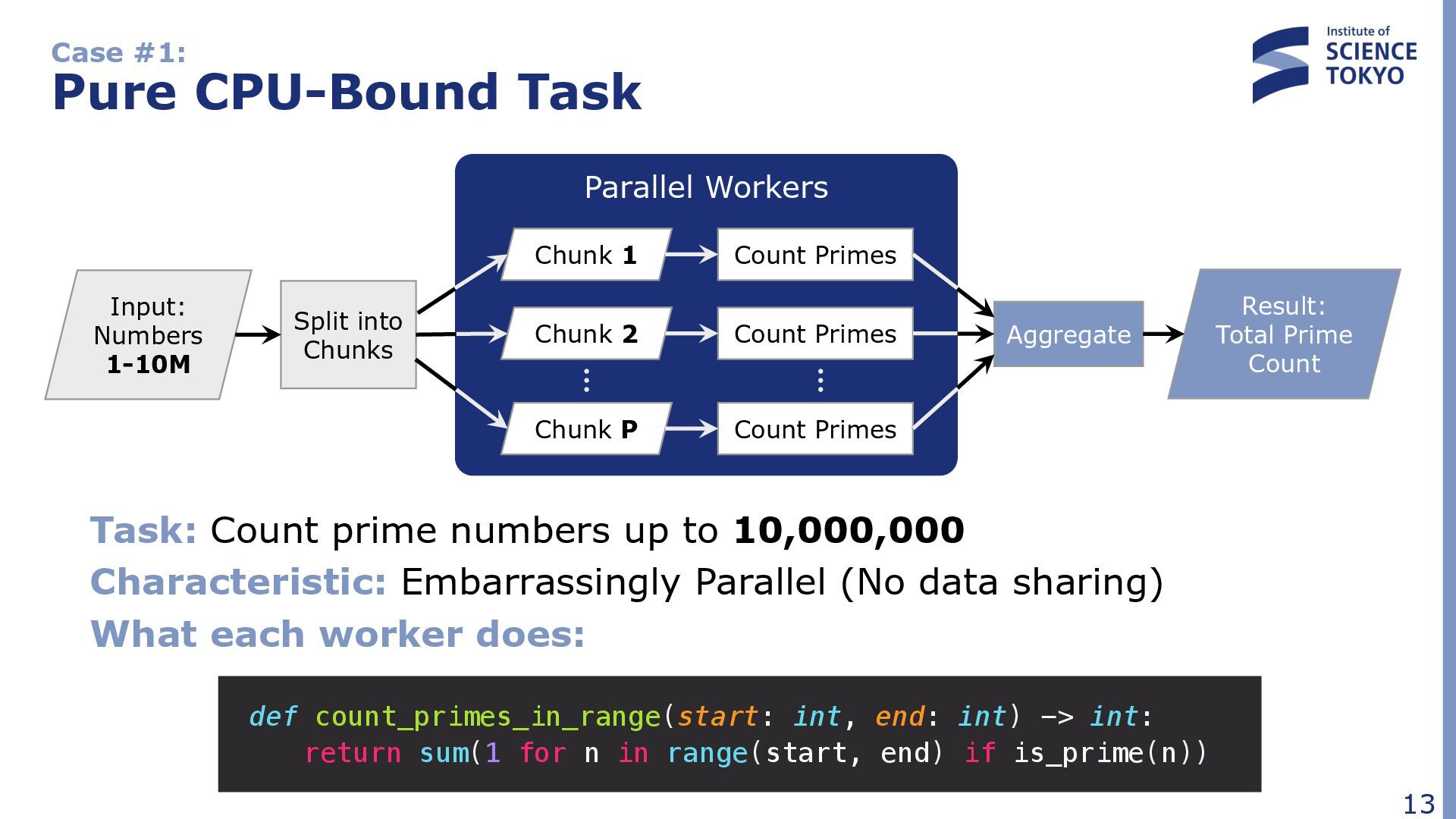
up to 10,000,000 Characteristic: Embarrassingly Parallel (No data sharing) What each worker does: Input: Numbers 1-10M Split into Chunks Chunk 1 Chunk 2 Chunk P Count Primes Aggregate Result: Total Prime Count Parallel Workers Count Primes Count Primes def count_primes_in_range(start: int, end: int) -> int: return sum(1 for n in range(start, end) if is_prime(n))
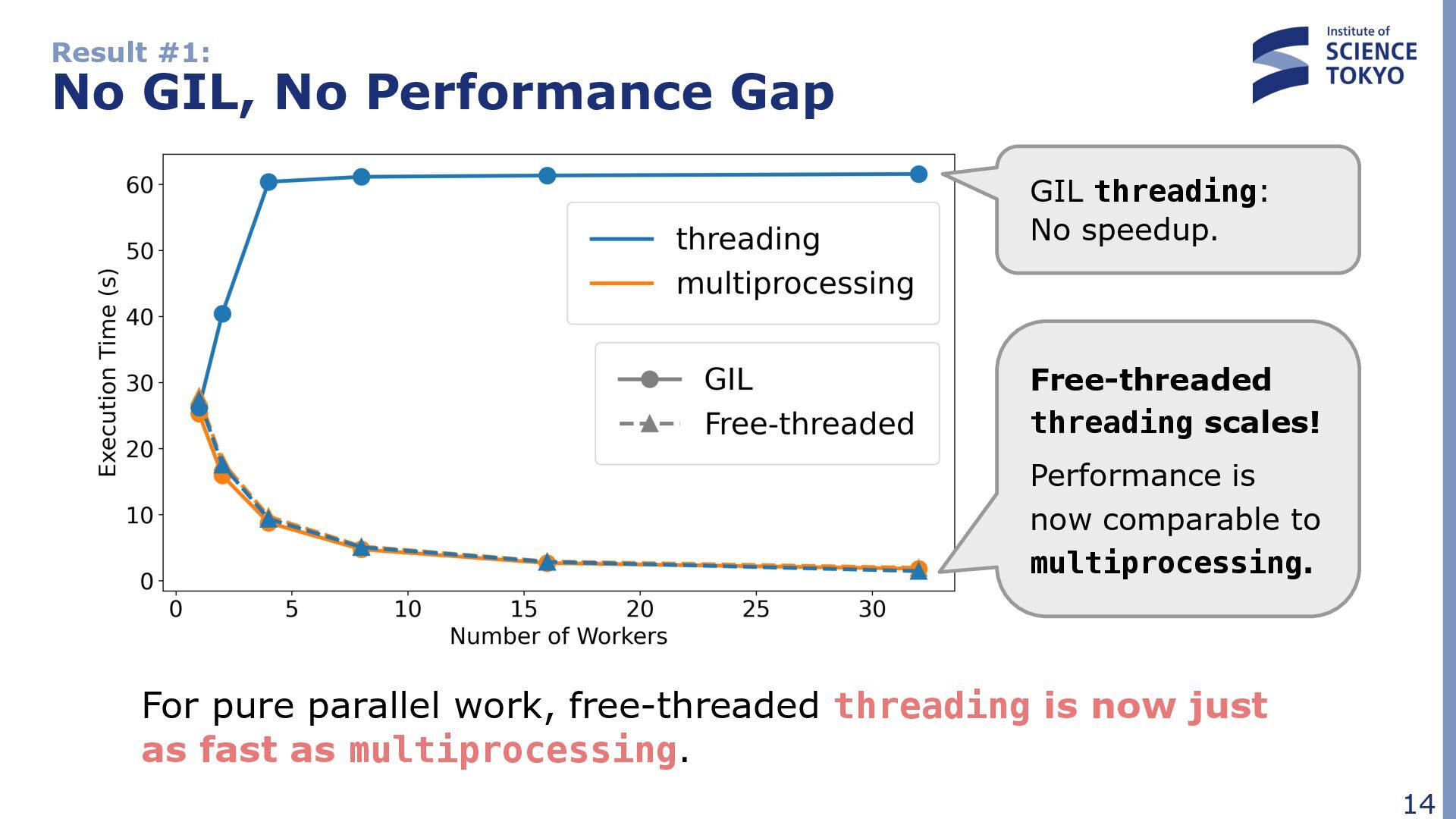
No speedup. Free-threaded threading scales! Performance is now comparable to multiprocessing. For pure parallel work, free-threaded threading is now just as fast as multiprocessing.
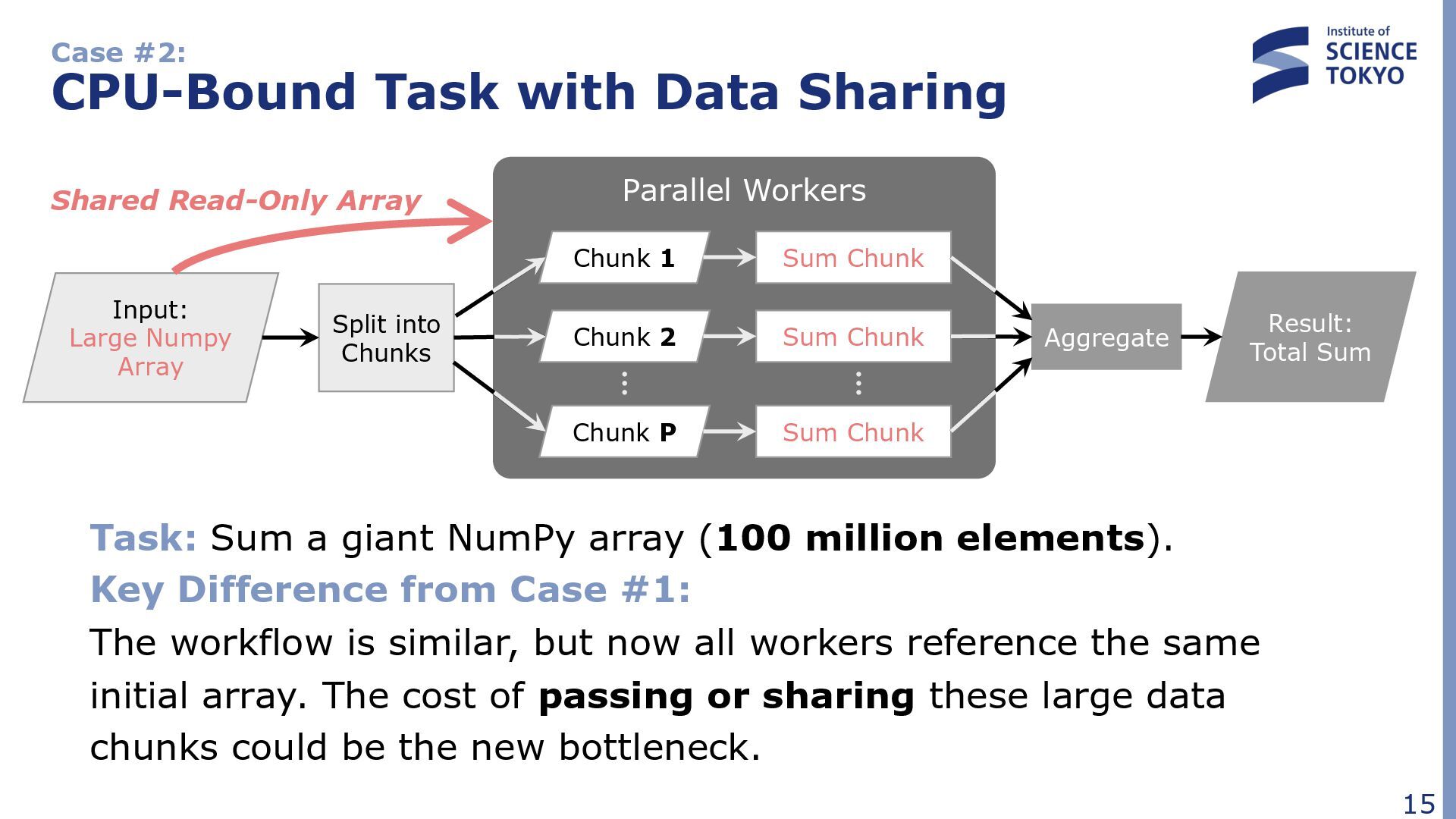
a giant NumPy array (100 million elements). Key Difference from Case #1: The workflow is similar, but now all workers reference the same initial array. The cost of passing or sharing these large data chunks could be the new bottleneck. Input: Large Numpy Array Split into Chunks Chunk 1 Chunk 2 Chunk P Sum Chunk Aggregate Result: Total Sum Parallel Workers Sum Chunk Sum Chunk Shared Read-Only Array
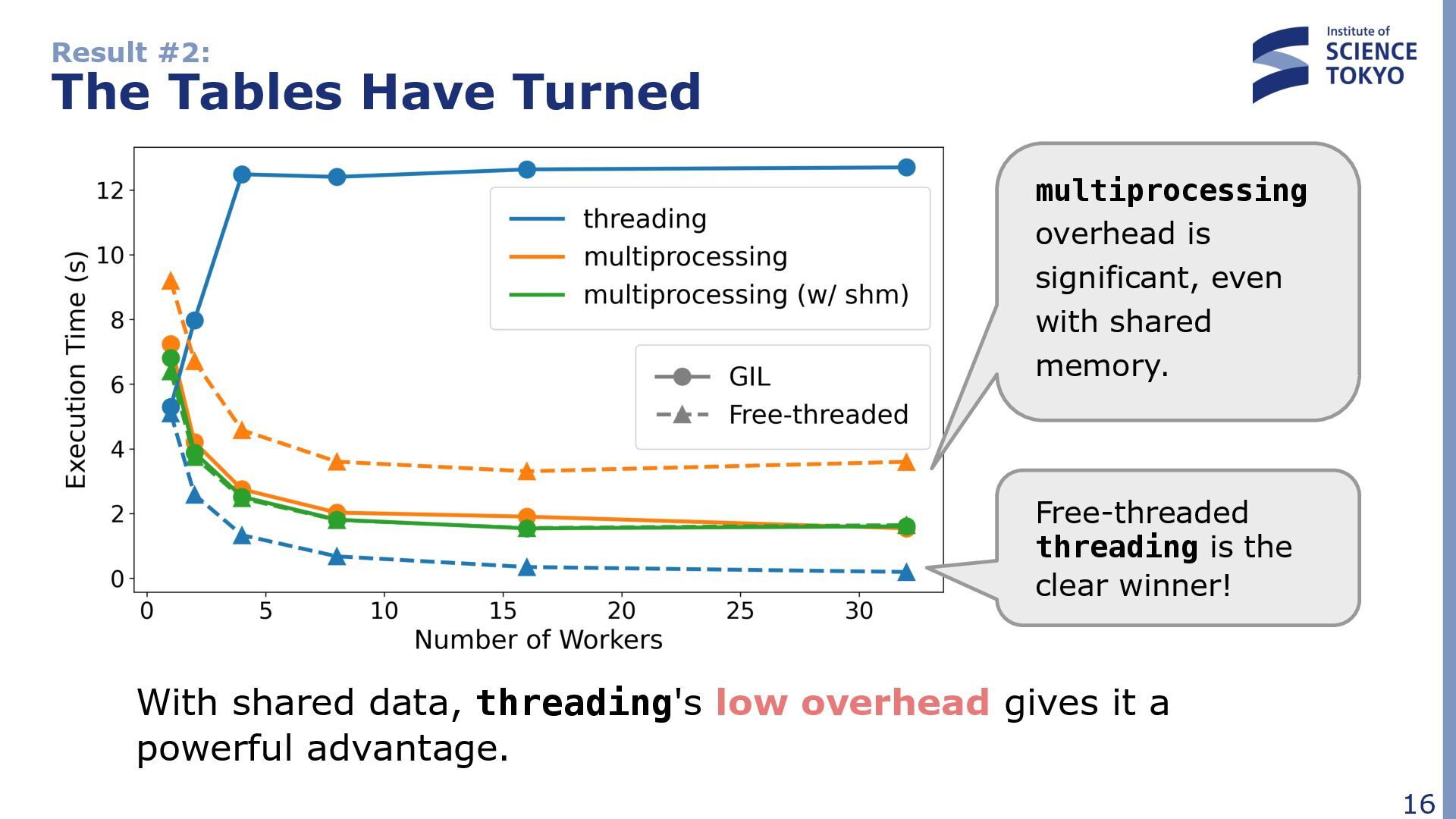
significant, even with shared memory. Free-threaded threading is the clear winner! With shared data, threading's low overhead gives it a powerful advantage.
recap of concurrency concepts. 2.The Evidence Head-to-head benchmarks: threading vs. multiprocessing. 3.The Real World Applying it to a Machine Learning workload. 4.Your Playbook How to choose the right tool and avoid common pitfalls.
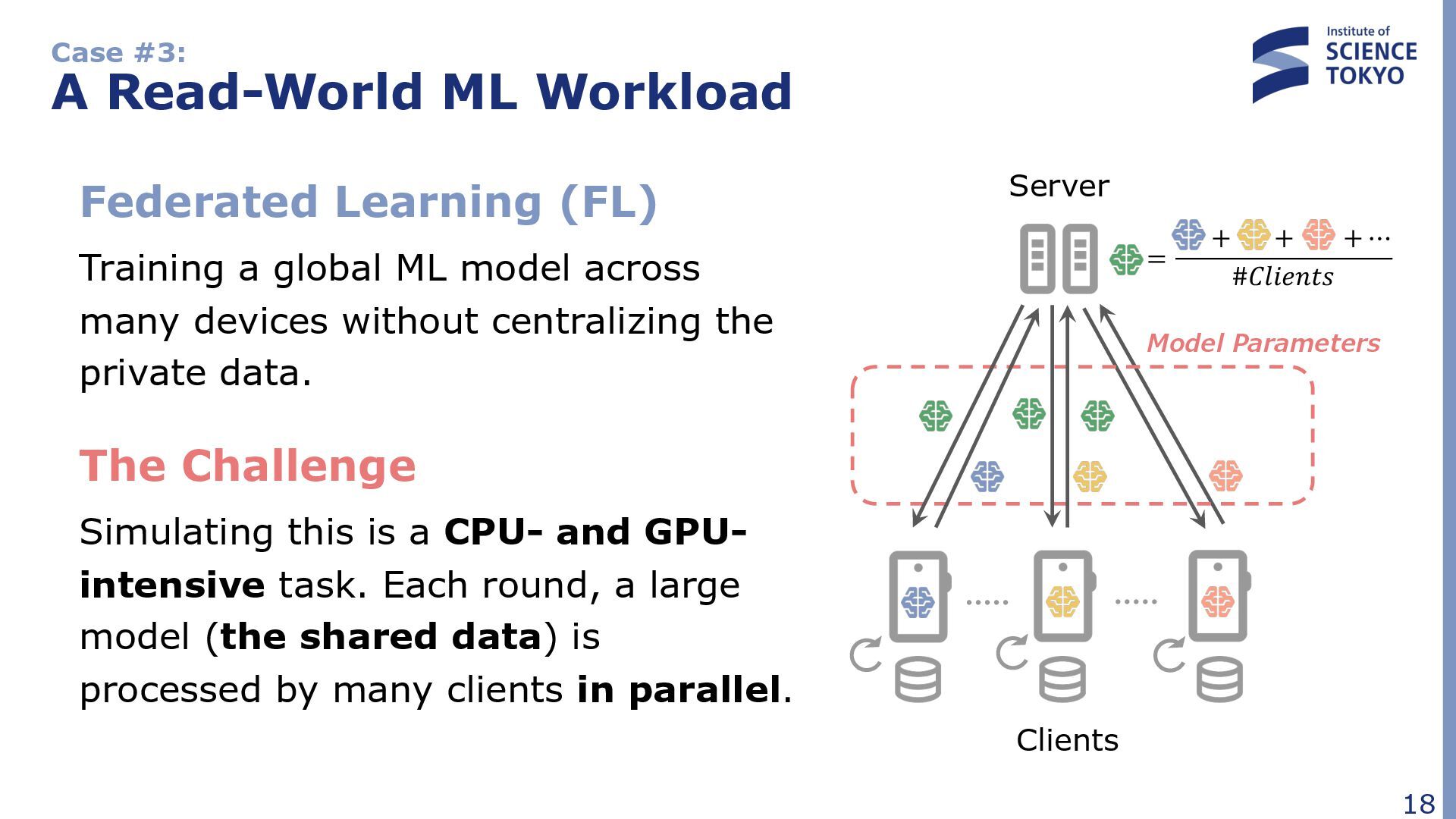
Training a global ML model across many devices without centralizing the private data. The Challenge Simulating this is a CPU- and GPU- intensive task. Each round, a large model (the shared data) is processed by many clients in parallel. Server Clients = + + + ⋯ #𝐶𝑙𝑖𝑒𝑛𝑡𝑠 Model Parameters
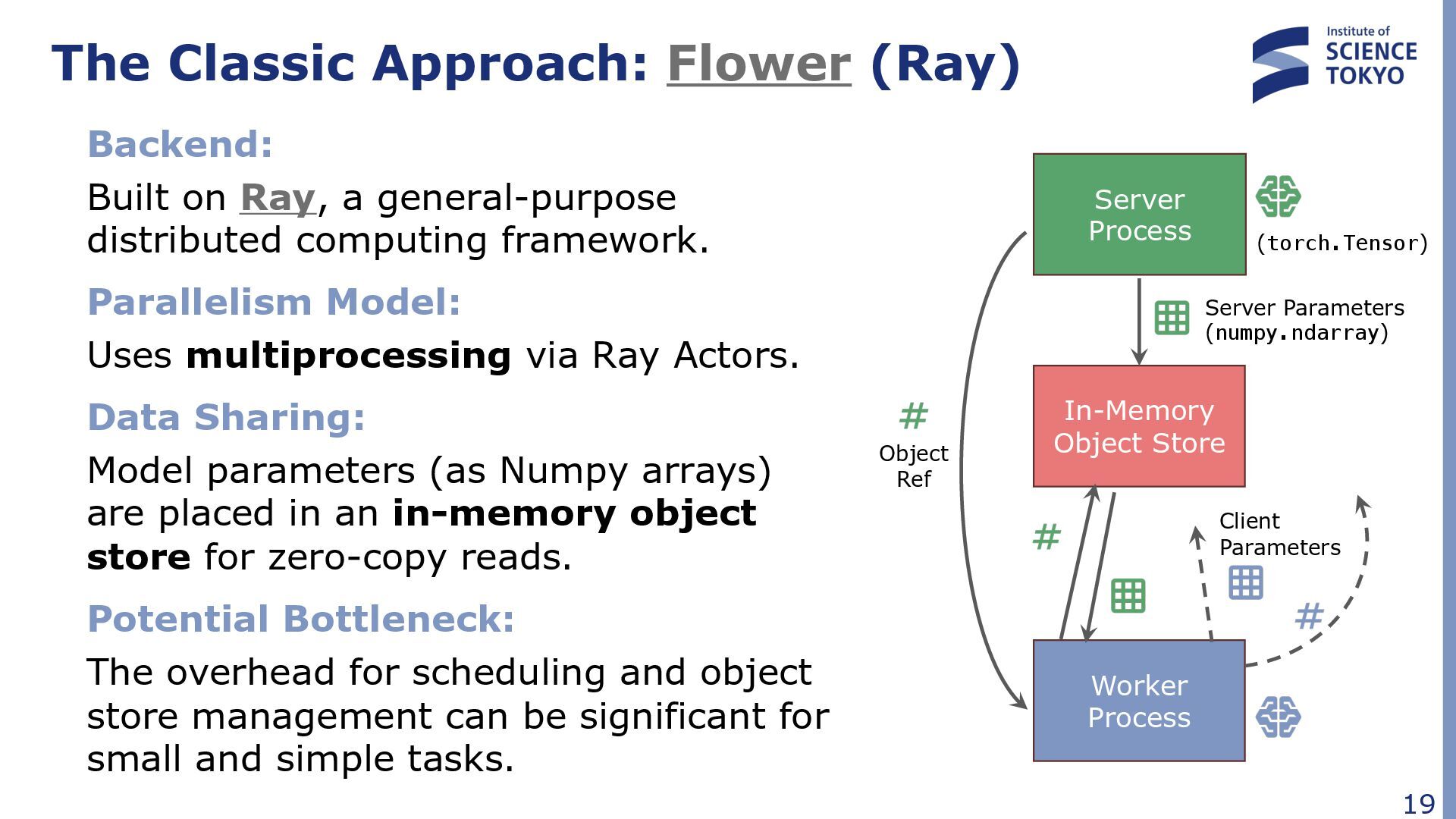
a general-purpose distributed computing framework. Parallelism Model: Uses multiprocessing via Ray Actors. Data Sharing: Model parameters (as Numpy arrays) are placed in an in-memory object store for zero-copy reads. Potential Bottleneck: The overhead for scheduling and object store management can be significant for small and simple tasks. In-Memory Object Store (torch.Tensor) Worker Process Server Process Object Ref Server Parameters (numpy.ndarray) Client Parameters
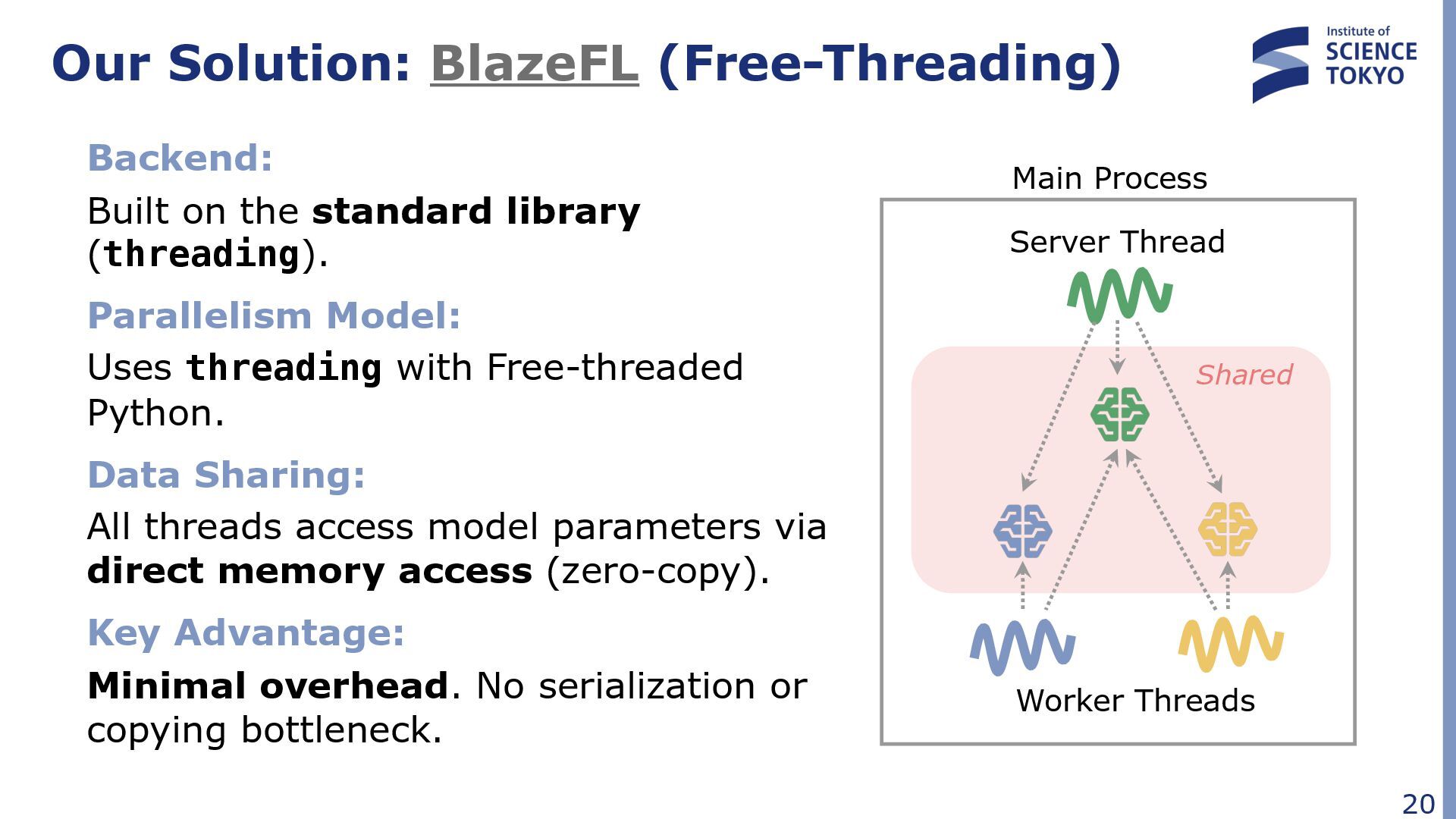
library (threading). Parallelism Model: Uses threading with Free-threaded Python. Data Sharing: All threads access model parameters via direct memory access (zero-copy). Key Advantage: Minimal overhead. No serialization or copying bottleneck. Main Process Server Thread Worker Threads Shared
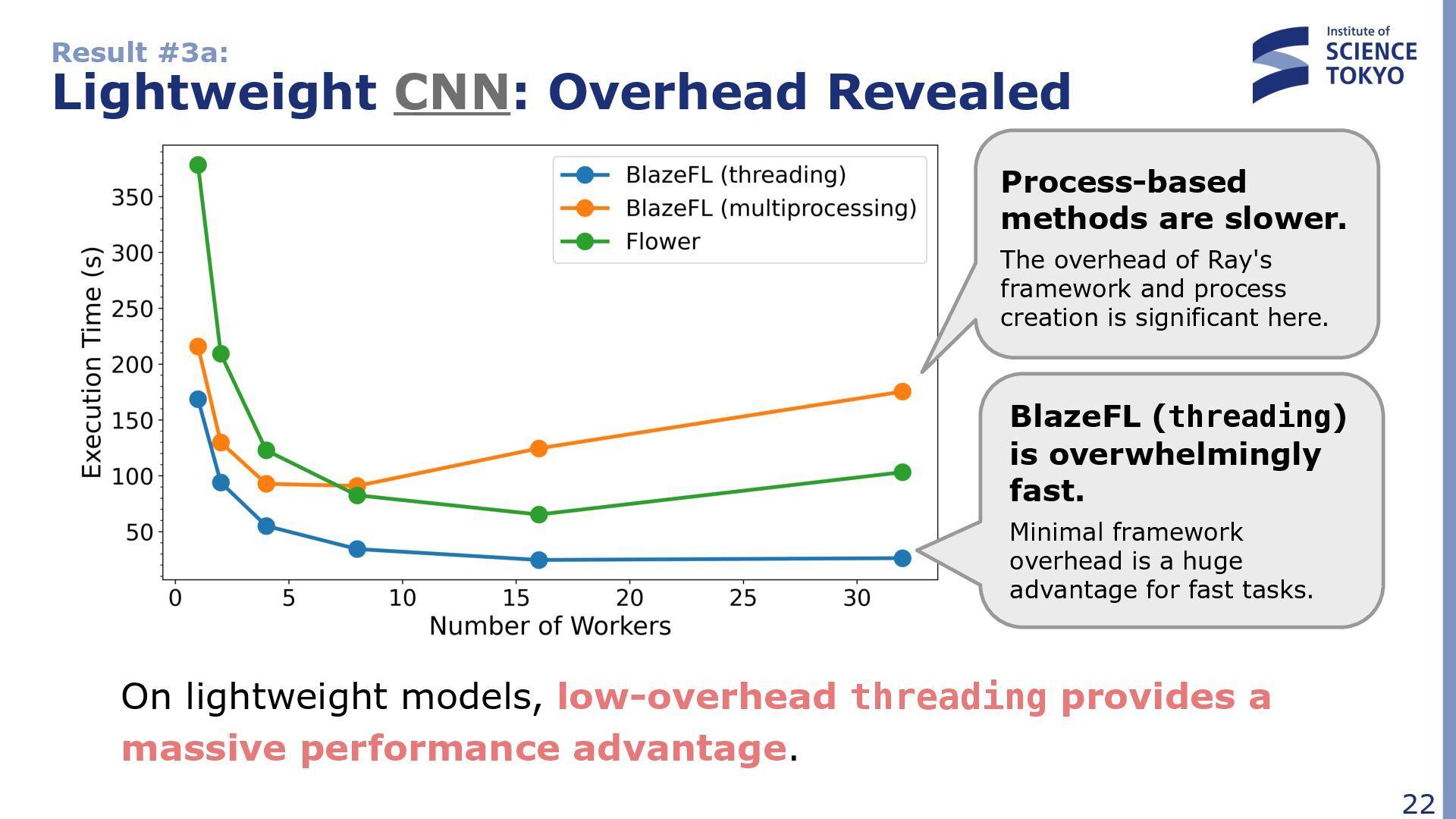
low-overhead threading provides a massive performance advantage. BlazeFL (threading) is overwhelmingly fast. Minimal framework overhead is a huge advantage for fast tasks. Process-based methods are slower. The overhead of Ray's framework and process creation is significant here.
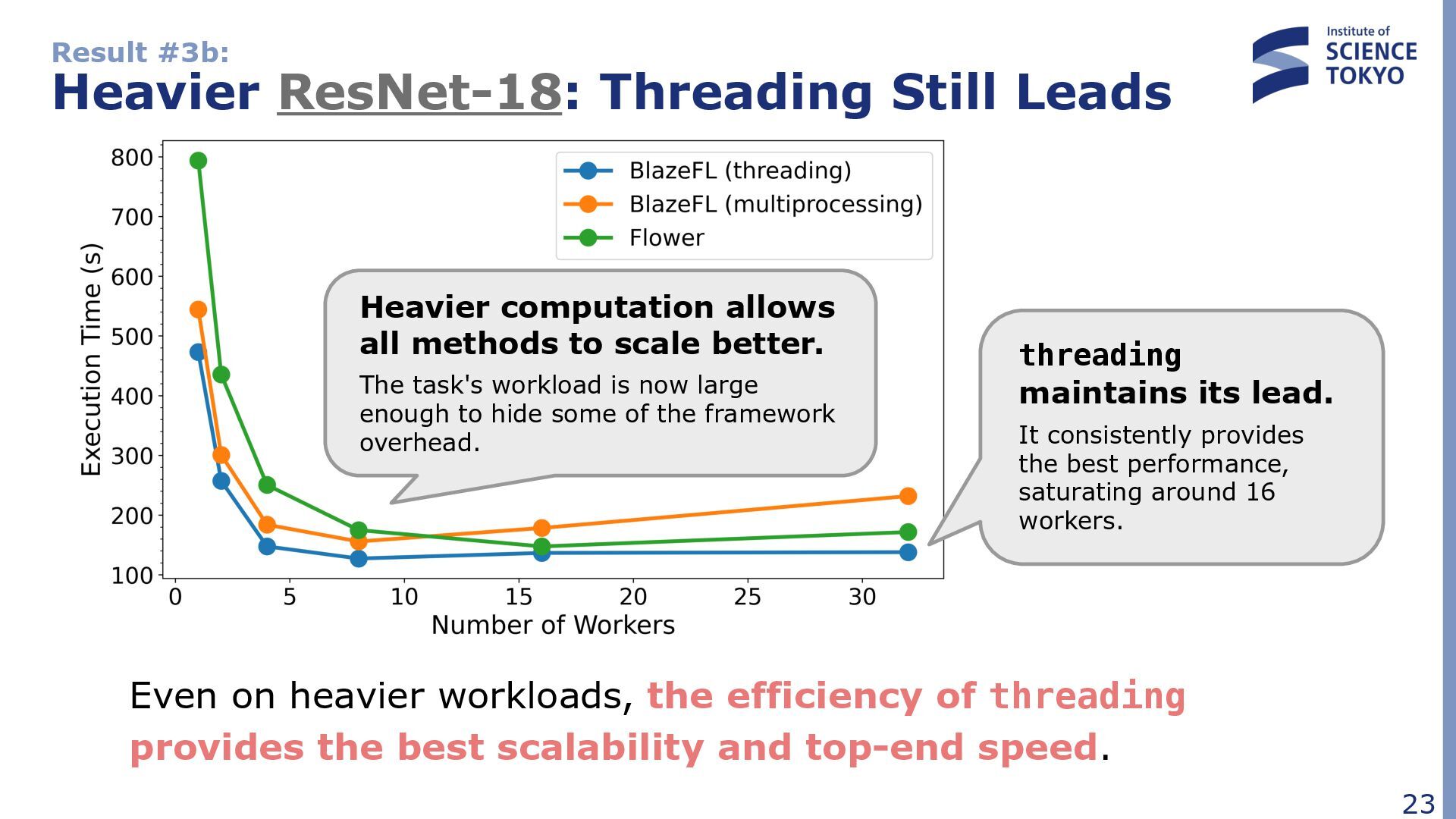
heavier workloads, the efficiency of threading provides the best scalability and top-end speed. Heavier computation allows all methods to scale better. The task's workload is now large enough to hide some of the framework overhead. threading maintains its lead. It consistently provides the best performance, saturating around 16 workers.
Sharing): Free-threaded threading catches up. It's now just as fast as multiprocessing for simple parallel tasks. • Case #2 (With Data Sharing): Free-threaded threading pulls ahead. Its direct memory access gives it a massive advantage over multiprocessing. • Case #3 (Real-World ML): Free-threaded threading is the champion. In complex, single-node simulations, its minimal overhead leads to the best performance.
recap of concurrency concepts. 2.The Evidence Head-to-head benchmarks: threading vs. multiprocessing. 3.The Real World Applying it to a Machine Learning workload. 4.Your Playbook How to choose the right tool and avoid common pitfalls.
is what makes threading fast, but it also opens the door to a classic problem: Race Conditions. What is it? When multiple threads access shared data at the same time, leading to unpredictable results. Why now? The GIL often hid this problem. With free-threading, true parallelism makes race conditions far more likely to occur. Thread 1 Thread 2
It Fails: It's Not One Operation counter += 1 is actually three steps: READ → MODIFY → WRITE. Without the GIL, another thread can interrupt between this process, causing a "lost update". The Fix: Use threading.Lock A lock protects this critical section, ensuring it runs atomically. + + + − import threading counter = 0 lock = threading.Lock() def worker(n: int) -> None: global counter for _ in range(n): counter += 1 with lock: counter += 1
WHAT is Slow Measures the total execution time to show which approach is faster overall. Profiling: Tells You WHY it’s Slow Looks inside your code to find the true bottleneck. § A specific function? § Memory allocation? § Lock contention? Don't optimize without data!
A Solution: System-Level Samplers samply Scalene py-spy Many popular profilers rely on GIL internals and are currently incompatible with free-threaded builds. It works by sampling the call stack at fixed intervals, independent of the GIL.
I/O-Bound? → Use asyncio or threading. Is your task CPU-Bound? Does it require heavy data sharing? Yes → Start with free-threaded threading. No → multiprocessing and free-threaded threading are both good. Benchmark them! Do you need to scale across multiple machines? → Use a distributed framework like Ray, Dask or Horovod.
single-node tasks, free-threading makes threading a first-class citizen for parallelism —often simpler and faster than multiprocessing. 2. Measure, don't guess. Benchmark and profile your code to find the real bottlenecks before you optimize.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}