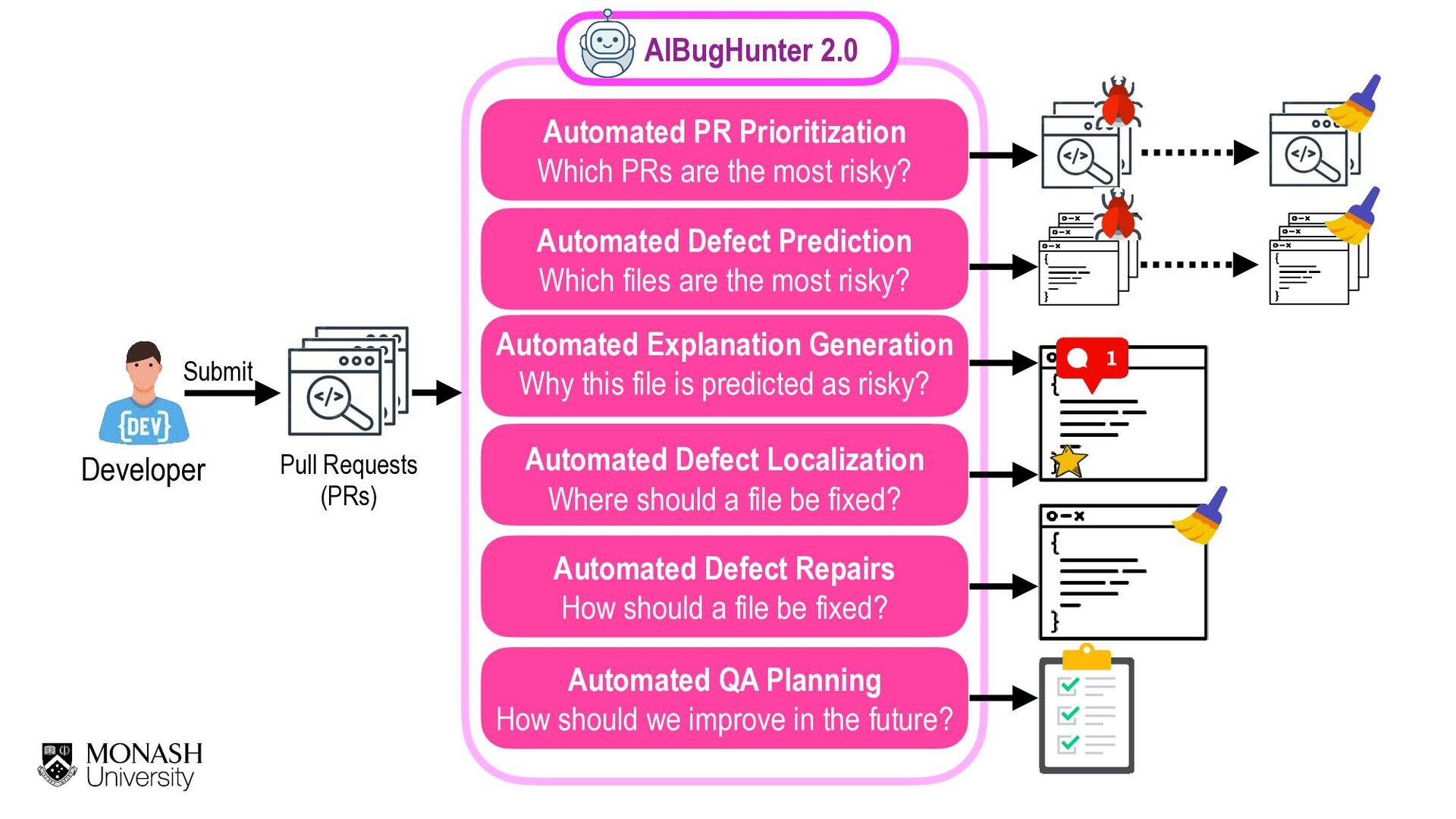
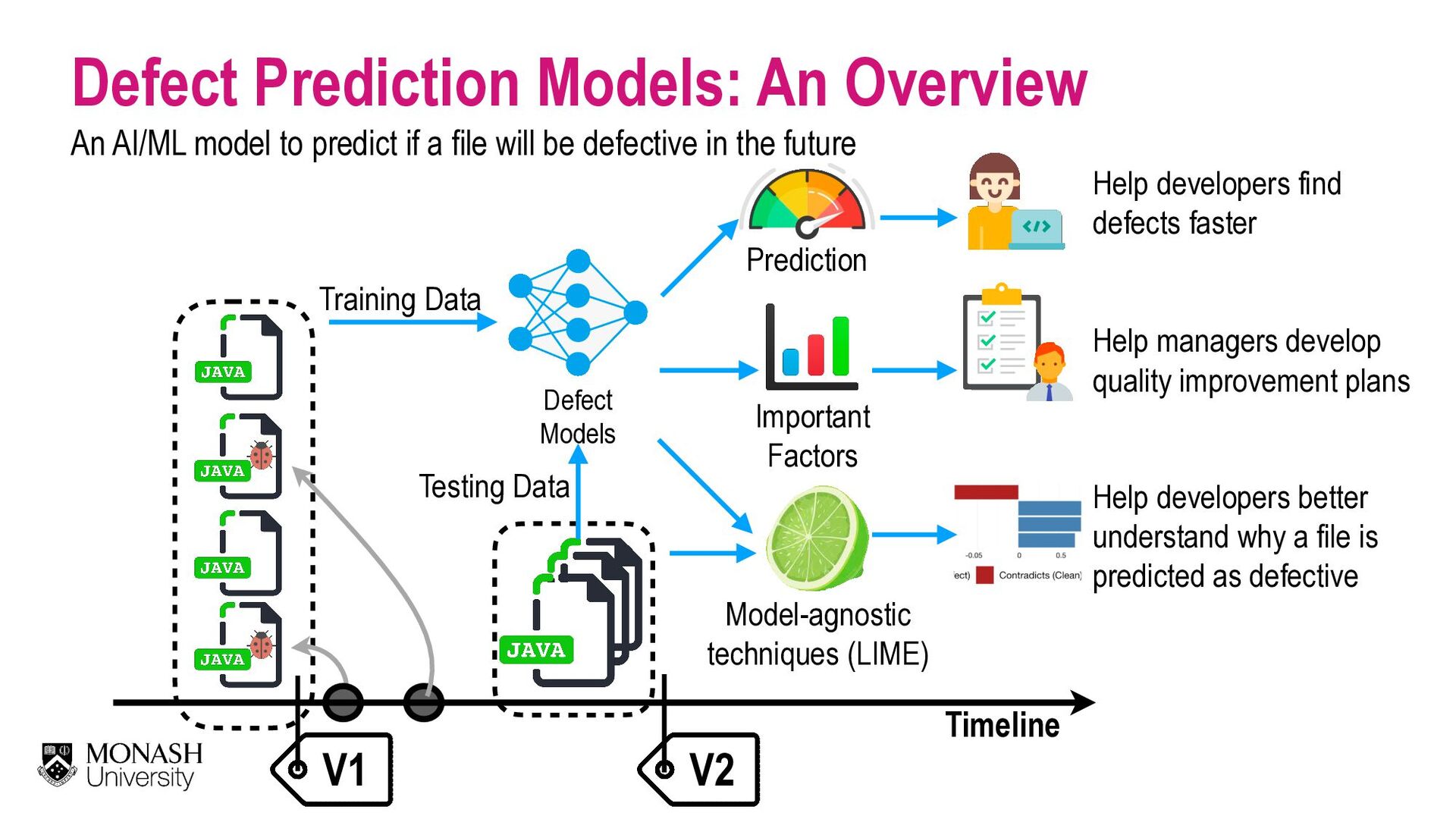
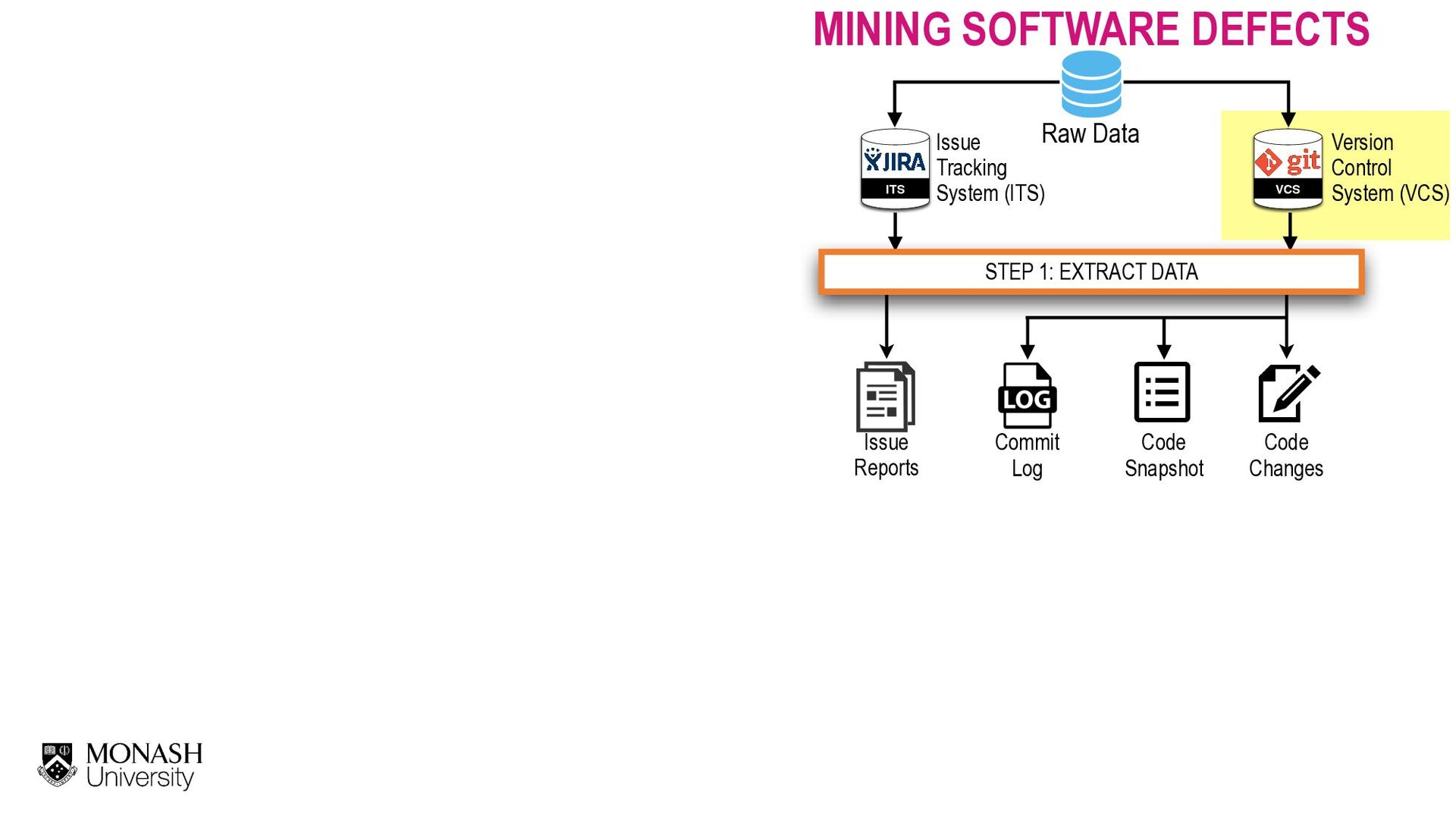
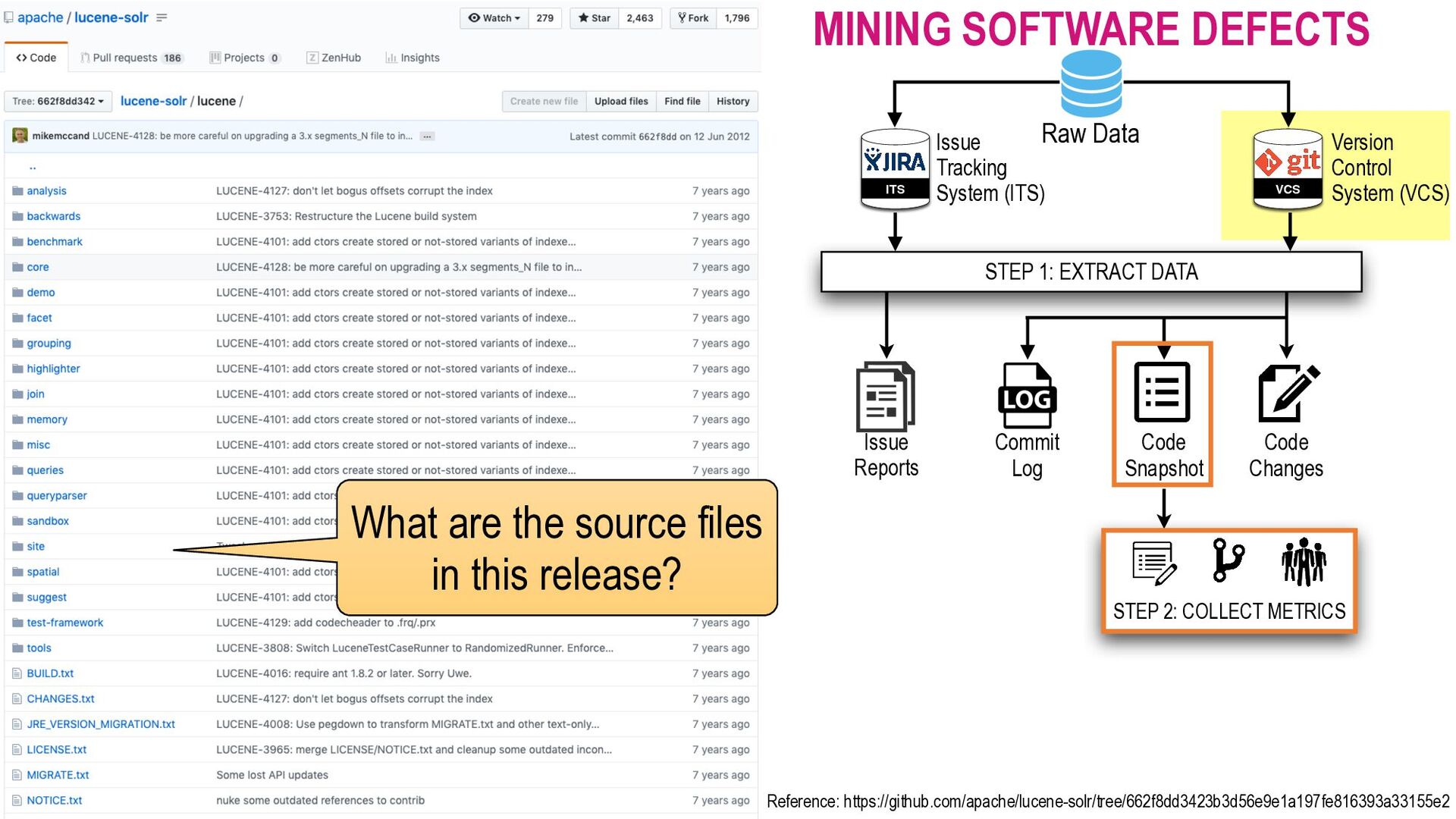
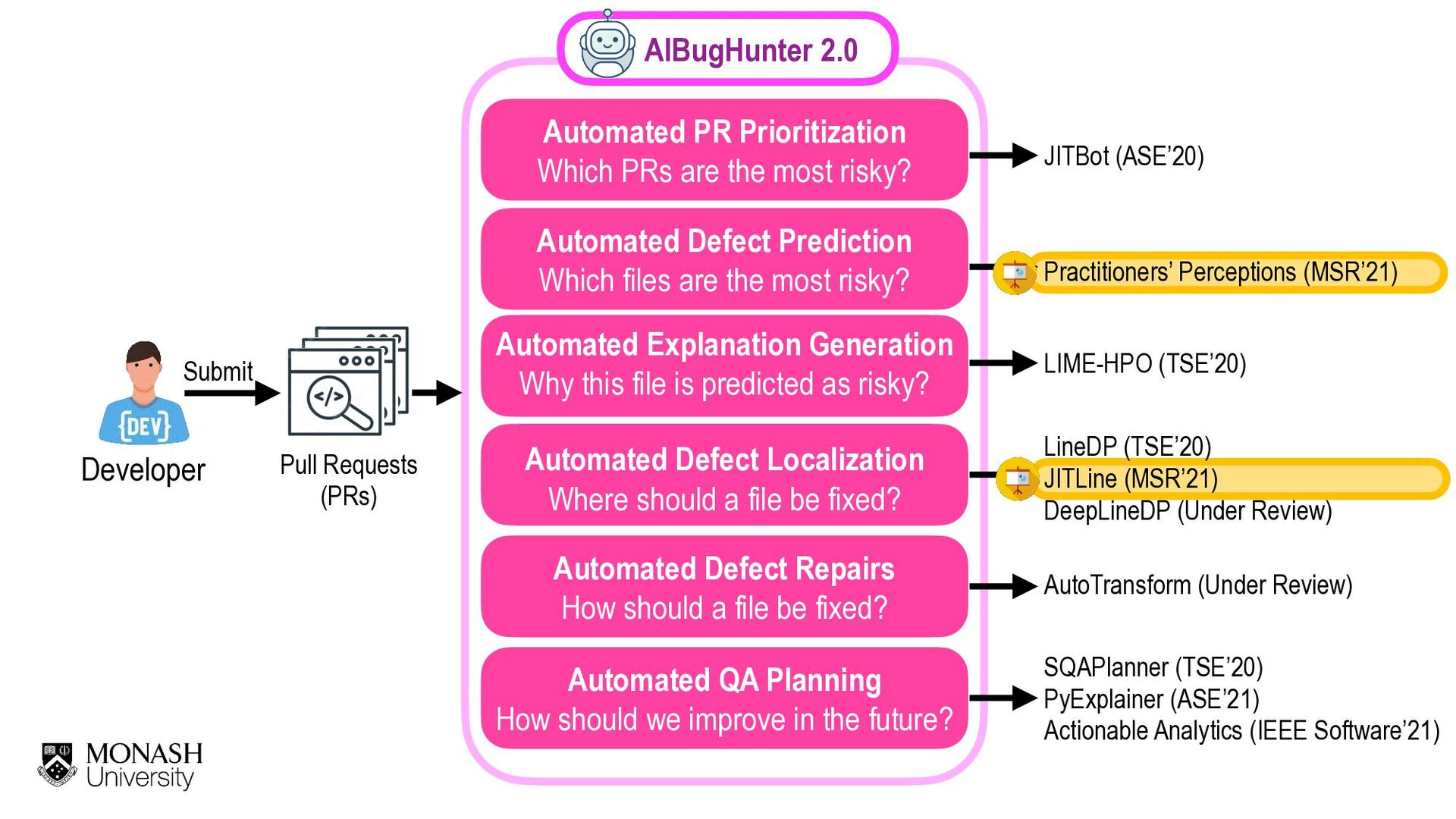
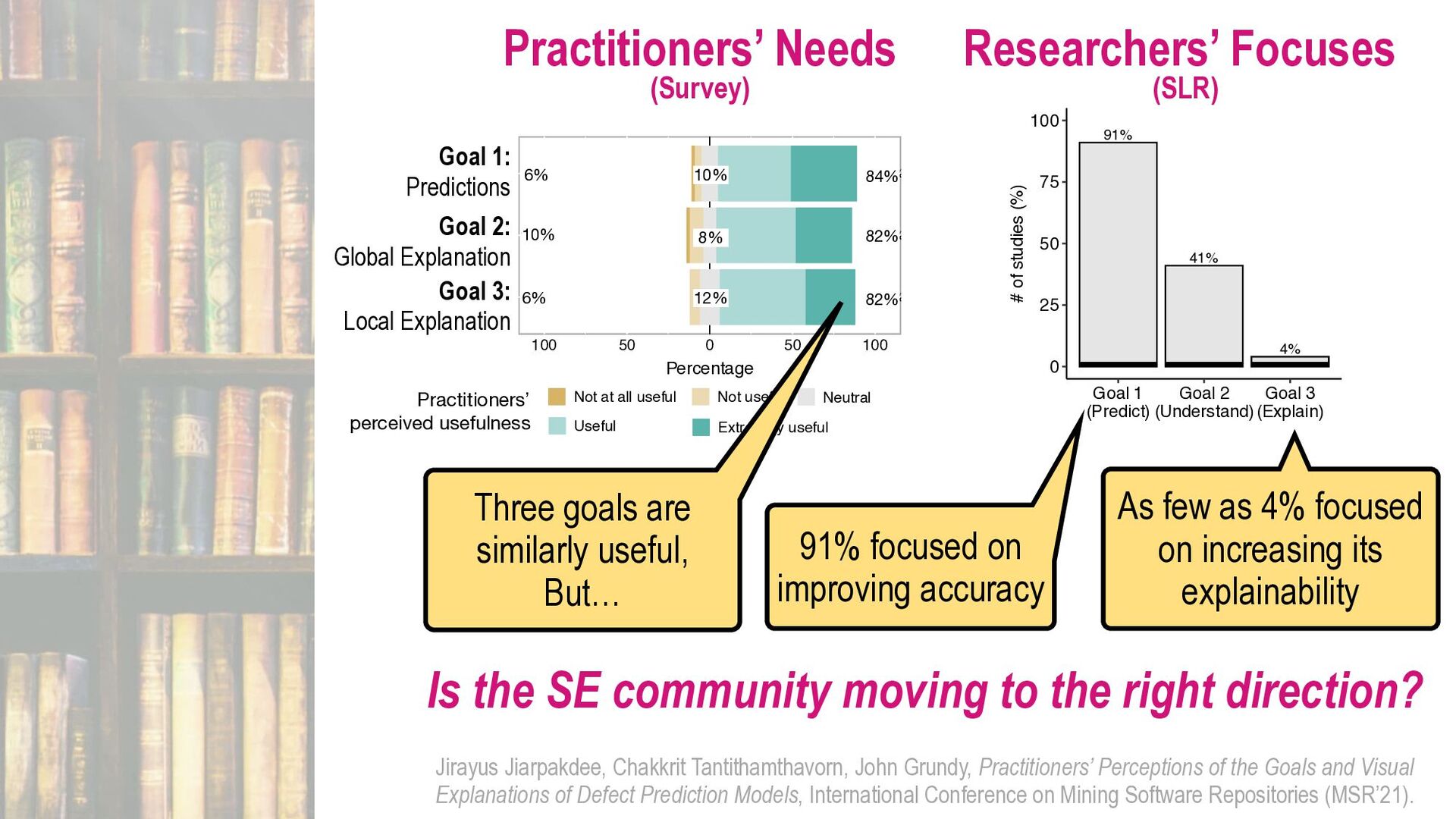
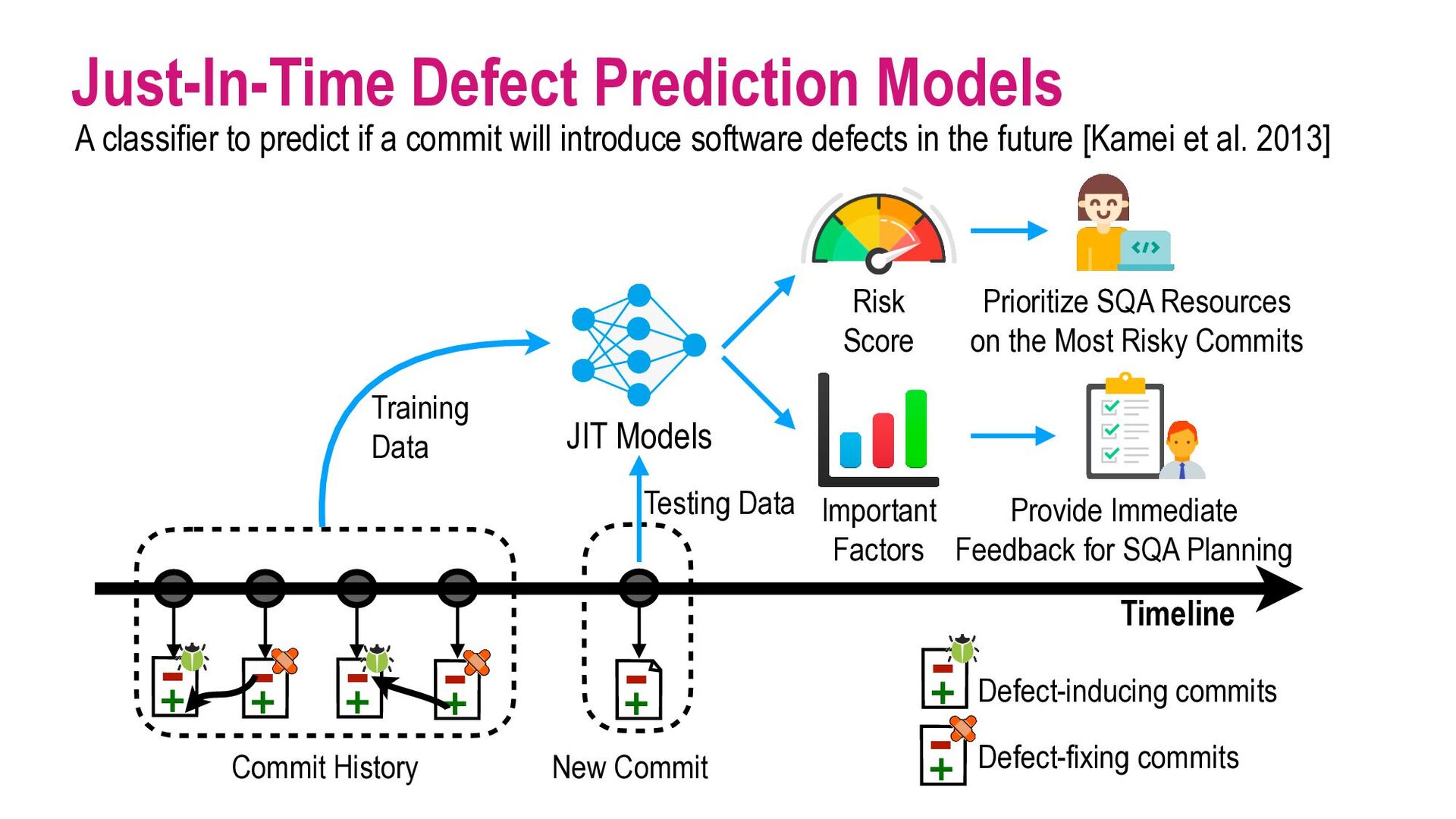
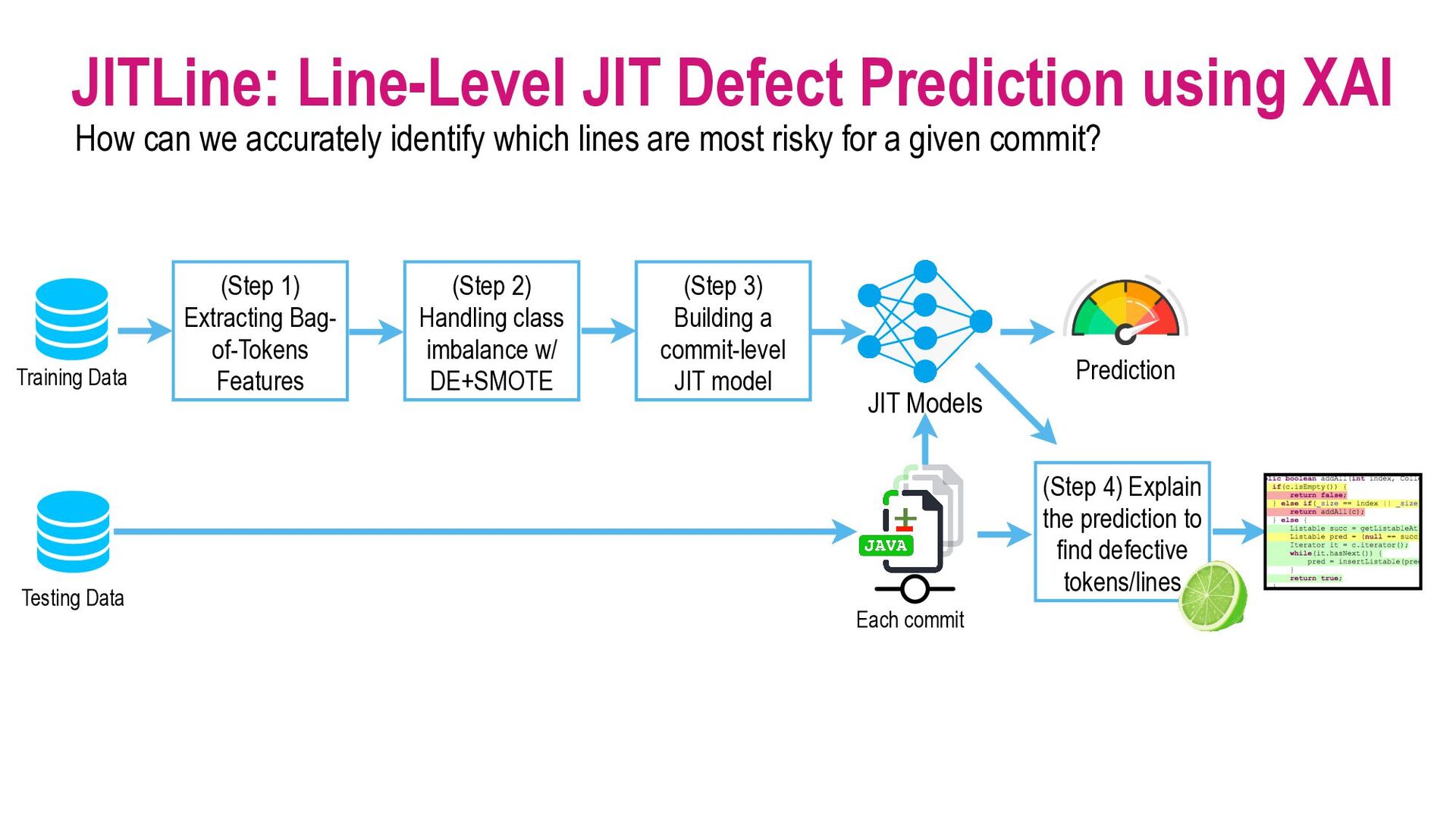
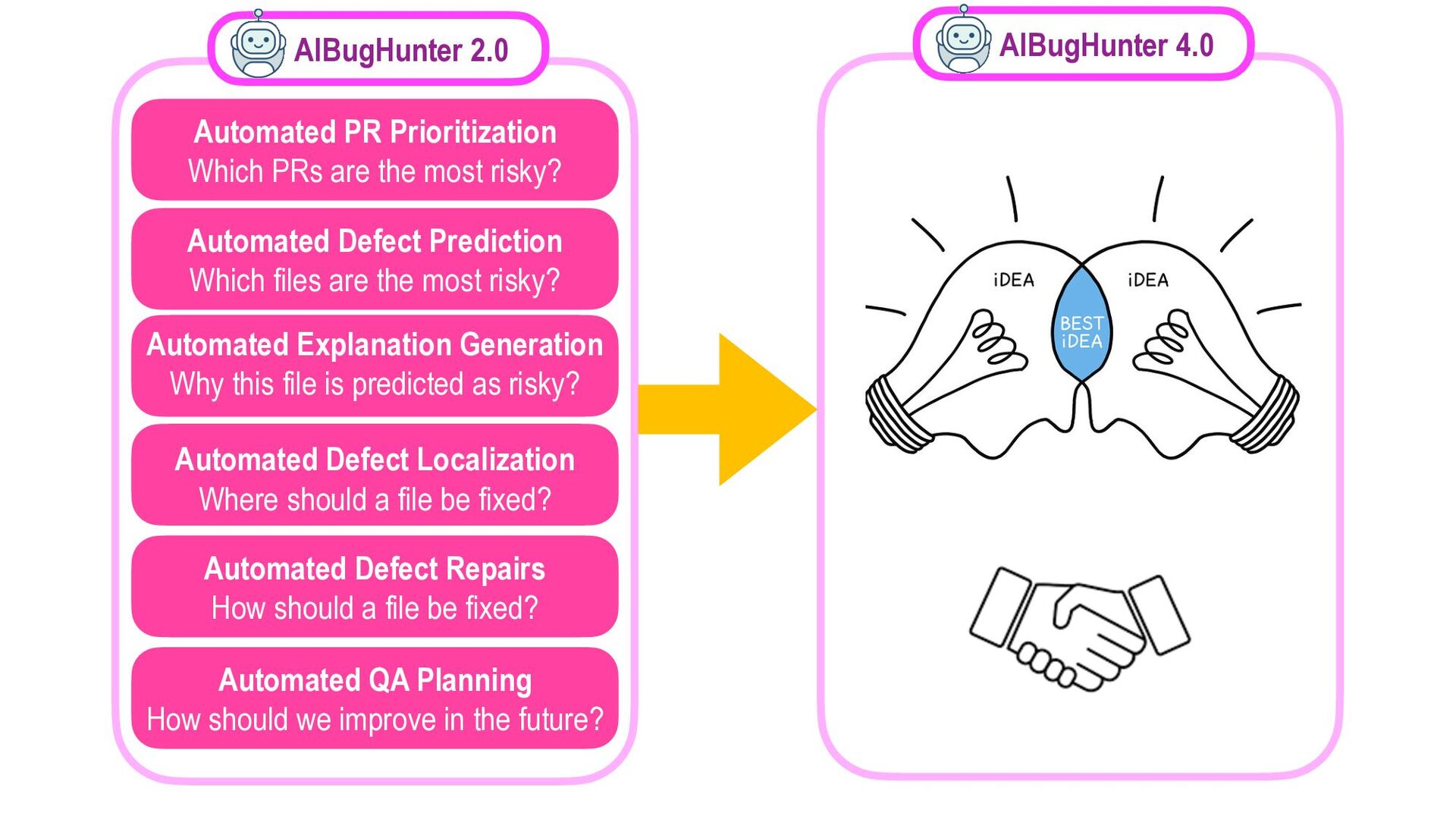
Our society is now driven by software. However, software defects and technology glitches are very expensive which could result in serious injuries and even deaths (e.g., a massive overdose of radiotherapy of Therac-25 to an explosion of the Ariane 5 rocket). Yet, current software quality assurance practices (e.g., modern code review) are still time-consuming and expensive. Imagine you are a developer working on a software project with million lines of code. Reviewing every single line of code to ensure that software is of high quality is infeasible due to the limited SQA resources. Funded by an Australia Research Council's DECRA award (2020-2023), I'm leading an AIBugHunter project to develop the next generation AI technologies to help developers to (1) predict if a file will be defective in the future; (2) explain why it is predicted as defective; (3) locate which lines of code are problematic and where to fix; and (4) suggest possible repairs. In this talk, I will briefly present the problem motivations, technologies, and potential benefits to enable developers to find software defects faster and enable managers to better develop software quality improvement plans to prevent defects in the future.
Bio: Dr. Chakkrit (Kla) Tantithamthavorn is the Monash Software Engineering Group Lead, and a Senior Lecturer in Software Engineering in the Faculty of Information Technology, Monash University, Australia. He is also affiliated with Monash Data Futures Institute and Digital Health Initiatives. His research is focused on developing AI-enabled software development techniques (e.g., AI for Software Defects, AI for Code Review, and AI for Agile) and tools (e.g, AIBugHunter, JITBot) in order to help developers find defects faster, improve developers' productivity, make better data-informed decisions, and better improve the quality of software systems. His work has been recognized by many prestigious awards e.g., Australian Research Council (ARC)'s DECRA Award (2020-2023), and Japan Society for the Promotion of Science (JSPS-DC2). Recently, he pioneered a new research direction of Explainable AI for Software Engineering, i.e., making software analytics more practical, explainable, and actionable. His research has been published at flagship software engineering venues, such as TSE, ICSE, EMSE, MSR, ICSME, IST.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![McIntosh & Kamei [TSE’17] #Commits #Tokens %Defective Commits Average](https://files.speakerdeck.com/presentations/6a8d941a57524005b669f7972ce887c8/slide_28.jpg){kind=link}
{kind=link}
{kind=link}